//Suspend until we get the semaphore from the ISR back.
29
xSemaphoreTake(xUSART1RXSemaphore,portMAX_DELAY);
30
31
//Lade Struktur aus Array
32
info=(structpaketType*)&rxBufferA[0];
33
34
info->Address=info->Idenfitifier;
35
}
36
}
Meine Daten liegen in rxBufferA ab position 0
Diese möchte ich mit einem Strukt verarbeiten.
Deshalb versuche ich über diese Daten ein Strukt zu legen.
Grundsätzlich funktioniert dies jedoch scheint irgendwas schief zu
gehen.
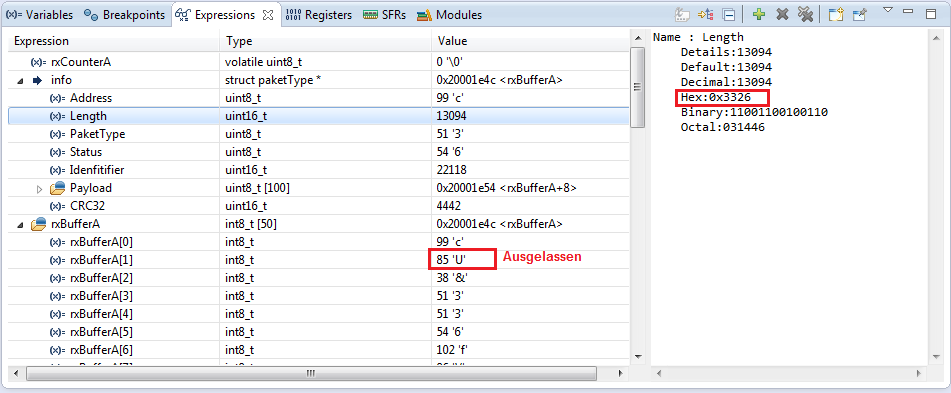
Als Daten habe ich 0x63, 0x55, 0x26, 0x33 etc...
Im Strukt info befindet sich bei addresse 0x63
Bei Length sind es die Bytes: 0x33 und 0x26
Obwohl beide elemente nacheinander im Strukt vorkommen wird das Byte
0x55 übergangen.
Wie im Bild im Anhang ersichtlich ist, sind die Daten vorhanden.
Was mache ich falsch?
Controller STM32, ARM GCC
Danke schonmal
vermutlich werden die Members allign. Das ist zur Optimierung, damit die
zugriffe schneller gehen. Du kannst nicht davon ausgehen, das eine Stuct
keine Lücken hat.
Wenn du das brauchst, musst du für deinen Compiler nachlesen, wie man
das machen kann. Vermutlich muss das irgendwo ein "packt" als
Eigenschaft gesetzt werden.
Ich frage mich aber, wie man dies sonst hätte lösen können?
Anscheinen ist ein packed struct einiges langsamer in der verarbeitung
als ein alignes struct.
Holger K. schrieb:> Ich frage mich aber, wie man dies sonst hätte lösen können?
in dem man die Daten einzeln in die Stuktur kopiert. Also jeden Wert
einzeln zuweist.
Da ist man auch flexibler, wenn man etwas am Protokoll geändert werden
muss.
@ Peter II (Gast)
>Da ist man auch flexibler, wenn man etwas am Protokoll geändert werden>muss.
Nicht nur das, es sit vor allem SAUBER!!! In C greift man möglichst
IMMER über Namen einer Variablen oder Strukturmember zu, nie über
selbstberechnete Offsets!!!
Falk B. schrieb:> @ Peter II (Gast)>>>Da ist man auch flexibler, wenn man etwas am Protokoll geändert werden>>muss.>> Nicht nur das, es sit vor allem SAUBER!!! In C greift man möglichst> IMMER über Namen einer Variablen oder Strukturmember zu, nie über> selbstberechnete Offsets!!!
Aber wie kopiere ich dann die Werte aus dem Bytearray in das Strukt?
Zudem kostet dies einiges an speicherplatz.
Ich nutze das Strukt ja nur zur interpretation der Daten.
Diese liegen im Buffer.
Wenn ich nun ein Strukt anlege, belegt dieser erneut speicher.
Nun soll ich byte um byte manuell in das Strukt kopieren?
Zumal es bei uint16_t und uint32_t noch maskierereien gibt etc.
Ich kann mir nicht vorstellen, dass dies der übliche Weg sein soll...
GCC wird auf ARM per dfault immer Alignment machen. Manche STM32 können
mit unaligned access umgehen, kostet dann aber zwei Buszugriffe (halbe
Geschwindigkeit) und ist nicht atomar. Andere schmeißen einen usage
fault. Oder war das bus fault? Naja jedenfalls ein fault.
Alignment heißt, daß Variablen mit mehr als 1 Byte gerade ausgerichtet
werden. Eine 16-bit-Variable muß also an einer geraden Adresse stehen,
eine 32-bit an einer durch 4 teilbaren. Dazwischen wird das Struct mit
unsichtbaren Variablen aufgefüllt.
Annahme, Grundausrichtung des Structs sei auf einer durch vier teilbaren
Adresse, was GCC tun wird, weil die größte Teilvariable 32bit hat.
Vereinfacht sei die Startadresse 0.
uint8_t Address; //0xFF ist Broadcast
uint16_t Length; //Länge in Bytes inklusive CRC32
Wenn Address auf einer durch vier teilbaren Adresse liegt, muß danach
ein Füllbyte unsichtbar eingefügt werden, damit Length auf eine gerade
Adresse kommt. Also liegt Length auf Adresse 2. Pakettype kommt damit an
Adresse 4, weil Length 2 Bytes belegt.
uint8_t PaketType;
uint8_t Status;
uint16_t Idenfitifier;
Wenn Length schon auf einer geraden Adresse liegt, kommt Identifier ohne
Füllbytes auf eine gerade Adresse. Payload liegt dann an Adresse 8.
uint8_t Payload[100];
CRC32 kommt auf Adresse 108, das ist ohne Füllbytes durch 4 teilbar.
uint16_t CRC32;
Nächste Überlegung: Man kann structs optimieren, indem man die
Mitglieder immer entweder von klein nach groß oder von groß nach klein
sortiert hält. Aber nicht durcheinander Bytes, Words und Dwords. Bringt
hier so nur dann was, wenn Du die Payload reduzieren oder erweitern
würdest.
Aufgepaßt: Du wirst früher oder später mit sowas über die Endianess
stolpern. Identifier und CRC32 müssen definiert entweder big- oder
little endian sein, das definiert das Protokoll. Wenn Du einen PC als
Gegenstelle nutzt, dann ist der ebenfalls little endian, das klappt
dann.
Normalerweise hat man aber noch Funktionen wie "HostToNetworkOrder" bzw,
"NetworkOrderToHost" dazwischen, die sich um die Endianess kümmern. Oder
Du definierst das Protokoll gleich byteweise, auch die 32bit-Variablen.
Das geht dann mit Bitmasking und Shiften.
Aber Binärdaten direkt in ein struct zu lesen ist ganz grundsätzlich
eine genauso falsche Idee, wie sie in ein Bitfield einzulesen.
Falk B. schrieb:> Nicht nur das, es sit vor allem SAUBER!!! In C greift man möglichst> IMMER über Namen einer Variablen oder Strukturmember zu, nie über> selbstberechnete Offsets!!!
Man beachte die Anzahl der Ausrufezeichen.
Nach deren Zählung schätze ich dass Falk kurz vor dem Explodieren
steht .... zumindest steht er bereits unter Hochspannung!!!
Und Holger, wenn du jetzt nicht seinem Willen folgst dann wird
es ziemlich ungemütlich! Das "Immer" war nämlich schon sehr laut.
Ich mache das IMMER!!!!! mit einer _packed_ Union ...
Da kommt das Bytearry=Rec/Trans-Buffer rein, und eine struct mit der
Interpretation der Daten...
Das Ganze kann man noch mit weiteren Attributen oder Union-Members bzgl.
der Prozessorarchitektur optimal in den Speicher legen.
Einfacher und fehlerfreier geht's doch wirklich nicht...
Für die Endianess gibt's einfache Funktionen die beim Schreiben/Lesen
der Struct-Members dann angewandt werden.
Holger K. schrieb:> Aber wie kopiere ich dann die Werte aus dem Bytearray in das Strukt?
1
x.Address=rxBufferA[0];
2
x.Length=rxBufferA[1]<<8|rxBufferA[2];
> Zudem kostet dies einiges an speicherplatz.
ist es wirklich so knapp bemessen?
> Ich nutze das Strukt ja nur zur interpretation der Daten.
ja, aber genau das macht man nicht.
> Zumal es bei uint16_t und uint32_t noch maskierereien gibt etc.
genau, damit kann man gleich das Problem mit der byte-order verhindern.
> Ich kann mir nicht vorstellen, dass dies der übliche Weg sein soll...
wenn man es richtig machen will, ja.
Das funktioniert aber auch nur wenn Sender und Empfänger sich einig sind
ob LSB oder MSB-first übertragen wird. Portabeler, wenn auch ein bissl
umständlicher, wäre:
Chriss X. schrieb:> Einfacher und fehlerfreier geht's doch wirklich nicht...
scheinbar sind andere - andere Meinung. Ich finde es nicht einfach und
fehlerfrei.
Eine Stuktur im Ram hat für mich keine echten Bezug zu den Daten. Damit
bin ich unabhängig vom Übertragungsprotokoll.
@ Holger Krähenbühl (holgerkraehe)
>> Nicht nur das, es sit vor allem SAUBER!!! In C greift man möglichst>> IMMER über Namen einer Variablen oder Strukturmember zu, nie über>> selbstberechnete Offsets!!!>Aber wie kopiere ich dann die Werte aus dem Bytearray in das Strukt?
Ganz nach Lehrbuch.
>Zudem kostet dies einiges an speicherplatz.>Ich nutze das Strukt ja nur zur interpretation der Daten.
Dafür gibt es Unions. Aber auch dort muss man den Struct packen, sonst
klappt das nicht.
Aber selbst dieser Trick ist offiziell eher nicht erlaubt, wenn gleich
er oft genutzt wird ;-)
Aber irgendwo muss ich die Beziehung der Bytes zu den Klarnamen doch
definieren...
Was ist denn noch einfacher, als die Klarnamen als Struct-Member einfach
der Reihe nach von oben nach unten hinzuschreiben ???
Ich bin gespannt...
Eben nicht...
Ich würde gern mal sehen, wie Du ankommende Bytes(oder meinentwegen ein
Bytearray) von einer beliebigen Schnittstelle in deine UNPACKED STRUCT
schreibst und einsortierst ...
Chriss X. schrieb:> Ich würde gern mal sehen, wie Du ankommende Bytes(oder meinentwegen ein> Bytearray) von einer beliebigen Schnittstelle in deine UNPACKED STRUCT> schreibst und einsortierst ...
Dann noch einmal für dich:
Nächste Idee: Du kannst das auch gleich alles mit Bytes machen, außer
der CRC. Das Längenfeld muß nicht 16bit sein, wenn Deine Payload eh nur
100 lang sein kann. Bei Identifier mußt Du gucken, aber ein Byte ergäbe
auch schon 256 Identifier. Dann kann sich das Handling der Endianess auf
die CRC beschränken, wenn Du da nicht optimalerweise auch gleich eine
mit 8bit nimmst, denn 32bit CRC für so kleine Pakete ist schon arg
überdimensioniert.
Überhaupt, was soll den "Länge in Bytes inklusive CRC32" werden? Wie
willst Du denn das struct mit einer fest definierten Payloadgröße (100)
über ein Paket legen, das eine kürzere Payload haben kann, wenn am Ende
hinter der Payload auch noch die CRC stehen kann?
Das wird so nichts mit dynamischen Paketlängen und Drüberlegen.
Also Vorschlag, wenn es schon quick & dirty sein soll:
uint8_t Address;
uint8_t Length;
uint8_t PaketType;
uint8_t Status;
uint8_t Idenfitifier;
uint8_t CRC8;
uint8_t Payload[100];
Und voila, schon kannst Du ein struct drüberlegen, was dann auch IMO
recht sicher ist. Allerdings beim Auslesen der Payload kann der hintere
Teil natürlich in den Wald zeigen, wenn die maximale Payload nicht
ausgenutzt wurde.
Nop schrieb:> Also Vorschlag, wenn es schon quick & dirty sein soll:
es hat schon ein Grund warum die CRC meist hinten ist. Dann sie braucht
man überhaupt nicht in der Struct. Beim senden kann man sie on-the-fly
berechnen und dann einfach als letztes senden.
Beim empfangen das gleiche, man rechnen gleich die CRC aus und
vergleicht sie am ende mit dem gelieferten CRC. Wenn es nicht passt,
kann man da Paket gleich verwerfen.
Chriss X. schrieb:> Und das siehst du wirklich als einfacher und fehlerfreier an???
ja. Zumindest viel besser als wenn ich an mehre stellen im Programm auch
noch die byte-order beachten muss.
> Bin raus...
schade, also bis du nicht bereit anderen Meinungen zu akzeptieren
Peter II schrieb:> es hat schon ein Grund warum die CRC meist hinten ist. Dann sie braucht> man überhaupt nicht in der Struct.
Der OP wollte, so wie ich das verstanden habe, die struct über den
Speicherbereich legen und dann über die struct alles auslesen. Auch die
CRC32, deswegen ist die ja in der struct. Das Auswerten über diese
struct wäre damit in der Empfangsschicht anzusiedeln, wo man die CRC32
schon noch braucht.
Aber wenn die Payload dynamisch ist, wird das mit dem Drüberlegen halt
nichts, dann muß man für die CRC32 nämlich noch eine separate Routine
schreiben.
Genaugenommen sollte man die CRC32 bei so einer Anwendung am besten
gleich ganz nach vorne legen, dann kann man den CRC-Algorithmus nämlich
ab struct+4 loslaufen lassen, bis struct+Length.
Das ganze basiert ja nicht auf Meinungen, sondern auf Fakten...
Richtig mächtig wird ja die Union Methode erst, wenn die Nutzlast z.B.
je nach CMD's verschieden Interpretiert wird...
Dann ist das einfach eine weitere Union anstelle der Nutzdaten, mit
Structuren als Member je nach CMD.
Wie lösen Sie das dann?
Die Kopiererei ist dann in Ihre! Zusatz-Buffer! (Mehrzahl!) für alle
Kommandos nötig!
Wird Zeit und Speicherfressend...
Genau dafür gibt es UNIONS, und hier sind sie ungeschlagen effektiv.
Chriss X. schrieb:> Dann ist das einfach eine weitere Union anstelle der Nutzdaten, mit> Structuren als Member je nach CMD.
wenn es verschieden CMD sind, nehme ich verschieden structs.
Verstehe nicht wo da das Problem sein soll.
Wie löst du denn das Problem der unterschiedlichen byte-order? Musst du
dann im code immer wissen, das die Daten von außen kommen und dann
irgendwie drehen?
@Chriss X
oder wie löst du das Problem wenn die längen nicht konstant sind? Es
gibt Protokolle, das ist das z.b. das Längenfeld nicht konstant.
das erste Bit gibt an, ob das nächste Byte noch zu länge gehört.
Dein ganzer Ansatz mit der Strukt würde bei ASN.1 (DER) komplett
versagen.
Chriss X. schrieb:> Genau dafür gibt es UNIONS, und hier sind sie ungeschlagen effektiv.
Genau dafür gibt es unions NICHT.
unions sind dafür gedacht, mehrere Datenstrukturen übereinanderzulegen,
wenn man nur eine dieser Strukturen zu einer Zeit braucht. Das spart
Speicher.
Es gibt sogar die Regel, dass man, wenn man in einer dieser
übereinandergelegten Datenstrukturen schreibt, danach auch nur über
diese eine Datenstruktur die Daten wieder auslesen darf.
Wie Falk schon schrieb:
Falk B. schrieb:> Aber selbst dieser Trick ist offiziell eher nicht erlaubt, wenn gleich> er oft genutzt wird ;-)
Und da hat er vollkommen recht.
Schau Dir mal an, wie IP-Stacks portabel arbeiten. Da wird auf die
Struct-Member einzeln zugegriffen und Makros wie htons() und htonl()
benutzt, um die Byteorder auch portabel abzufackeln. Keineswegs legt man
da eine Datenstruktur mittels union über ein Array.
Die Methode:
1
x.Address=rxBufferA[0];
2
x.Length=rxBufferA[1]<<8|rxBufferA[2];// hier wäre htons() eine geeignete Alternative
ist der einzig richtige Weg, um portabel zu sein. Übrigens sind diese
packed-Anweisungen an den Compiler absolut spezifisch. Der Compiler -
wenn er diese übrhaupt versteht, muss sich NICHT daran halten!
Bzgl. Endian...
Wenn ich vom ganzen Code verstreut auf die Daten zugreife, habe ich
sowieso ein Problem.
Natürlich wird der Zugriff gekapselt, und es gibt evtl. dann auch
Zugriffsfunktionen für jedes Element. Siehe oben.
Innerhalb der Kapselung weiß ich dann sehrwohl wo die Daten herkommen.
Bzgl. Variabler Länge...
Natürlich kann man immer einen Fall konstruieren, der nicht
funktioniert.
Dann muss ich die Daten natürlich der Reihe nach Parsen, und sortieren.
Dies ist aber hier doch überhaupt nicht gegeben.
Hier in diesem Fall, und wahrscheinlich bei 90% der Anwendungen die hier
im Forum zu lösen sind, sind die Unions ganz klar im Vorteil.
Chriss X. schrieb:> sind die Unions ganz klar im Vorteil.
Nein. Unaligned Zugriffe auf Packed-Structs erzeugen größeren und
langsameren Code oder führen sogar zu einem Fault.
Wo ist da der Vorteil? Ich sehe keinen. Wenn Du Pech hast, passt Deine
Packed-Struct mit der nächsten Compiler-Version oder bei Umstieg auf
einen anderen Compiler nicht mehr. Viel Spaß bei der Fehlersuche!
Frank M. schrieb:> Es gibt sogar die Regel, dass man, wenn man in einer dieser> übereinandergelegten Datenstrukturen schreibt, danach auch nur über> diese eine Datenstruktur die Daten wieder auslesen darf.
Seit C99 sind unions für type punning zugelassen. Da pointer type
punning wegen aliasing nicht zugelassen ist, sind unions die einzig
legale Methode dafür. Type punning braucht man halt manchmal einfach.
Chriss X. schrieb:
> Innerhalb der Kapselung weiß ich dann sehrwohl wo die Daten herkommen.
Ein sehr fragiles Design. Normalerweise hat man genau eine Stelle, an
der man Daten von außen unter die Lupe nimmt, und das ist bei der
Eingabe. Ansonsten hat man früher oder später so lustige Fehler in der
Art wie z.B. SQL injection. Das passiert nämlich, wenn man die
Validierung der Daten nicht an einer Stelle macht, sondern quer über den
ganzen Code beim Zugriff erst.
Besonders bei packed structs, selbst wenn der Prozessor das kann, dann
ist es langsam. Besonders auf ARM, und hier geht es um STM32. Und die
Zugriffe auf die einzelnen members sind dann auch nicht mehr atomic,
selbst wenn sie es "an sich" (wie z.B. 32bit-ints) wären.
Chriss X. schrieb:> Richtig mächtig wird ja die Union Methode erst, wenn die Nutzlast z.B.> je nach CMD's verschieden Interpretiert wird...
Genau dies ist bei mir der Fall
Das ganze führe ich seit Jahren erfolgreich in vielen Projekten durch...
Natürlich parst man die Daten nach Erhalt der Message dann 1x innerhalb
der Kapselung, wie denn sonst...
Header und Tail werden zum Fehlehandling herangezogen und ausgewertet,
danach kann man das vergessen...
Und die reinen Nutzdaten werden 1x entsprechend an EINER Stelle
formatiert, und entsprechend in einen weiteren Buffer zur
Weiterverarbeitung geschrieben.
Fertig.
Da stört mich kein Nicht Atomic oder sonstwas... da der komplette
Buffer(ggf. FIFO) erst am Schluß valid gesetzt wird.
Ich zweifele sehr stark an, dass das beschriebene Zwischenkopieren
schneller sein soll als unaligned Zugriffe.
So kann ich formatieren(Endiess) und kopieren in einem Schritt!
Chriss X. schrieb:> Das ganze führe ich seit Jahren erfolgreich in vielen Projekten durch...
ja, es gibt Leute die machen immer die gleichen Fehler und merken es
nicht. Das sagt also wenig aus.
Wenn du nur so einfache Protokolle hast, dann mag das ja auch
funktionieren. Ich mache es anderes und komme auch mit Protokollen
zurecht die keine festen längen haben.
> Und die reinen Nutzdaten werden 1x entsprechend an EINER Stelle> formatiert, und entsprechend in einen weiteren Buffer zur> Weiterverarbeitung geschrieben.
also noch einmal umkopieren?
Wozu dann überhaupt die Stuct?
Dann formatiere es doch gleich beim erhalt der Daten.
> Ich zweifele sehr stark an, dass das beschriebene Zwischenkopieren> schneller sein soll als unaligned Zugriffe.
es ist zumindest portabler
Nop schrieb:> Besonders bei packed structs, selbst wenn der Prozessor das kann, dann> ist es langsam. Besonders auf ARM, und hier geht es um STM32.
Grund ist das packed und weil ARM eine stric-alinment Plattform ist.
Evtl. hilft dann ein __attribute__((__aligned__(4))) so dass der
Komponenten wieder entsprechendes Alignment haben (und das dem Compiler
auch mitgeteilt wird).
Voraussetzung ist dann aber auch, dass die Struktur kein "schräges"
Layout hat so wie im Beispiel. Generell sollte man das Layout der
Komponenten so gestalten, dass der Offset, an der eine Komponente
beginnt, von deren natürlichem Alignment (beides in Bytes gerechnet)
geteilt wird, d.h.:
uint8_t beginnt an Offset, der 0 mod 1 ist (trivial)
uint16_t beginnt an Offset, der 0 mod 2 ist (im Beispiel nicht
erfüllt)
uint32_t beginnt an Offset, der 0 mod 4 ist
etc.
Ein letzter Satz...
Die Daten erhalte ich zumeist in IRQ's...
Da kopiere ich nur Bytes, oder lass von einer DMA oder sonstwas
kopieren...
Im IRQ wird da bei mir nichts formatiert.
Chriss X. schrieb:> Ein letzter Satz...
Aber schon dem Beispiel von oben, sobald die Payload keine feste länge
mehr hat (was wohl auf 99% der Protokolle zutrifft) hat man ein Problem
mit der Struct weil die CRC nicht an einer festen Stelle ist.
Nun gut, ich danke euch für die vielen Posts.
Da ARM eine Alignes Struktur zu sein scheint und der workaround mittels
compiler anweisung wohl eher zufällig funktioniert, muss ich wohl oder
übel die Strukte manuell befüllen.
Da meine Payload wiederum ein "strukt" enthält welches je nach paketType
unterschiedlich ist, muss ich wohl eine funktion machen, welche mir
diese strukts je nach typ manuell befüllt.
Ich dachte mir dies in etwa so, dass ich das strukt dynamisch zur
laufzeit je nach erhaltenem paket typ erstelle und dann entsprechend
befülle.
Macht dies so sinn?
Johann L. schrieb:> Generell sollte man das Layout der> Komponenten so gestalten, dass der Offset, an der eine Komponente> beginnt, von deren natürlichem Alignment (beides in Bytes gerechnet)> geteilt wird
Jepp. Mit der Option -Wpadded warnt GCC dankenswerterweise ja, wo
structs gefüllt werden. Besonders, wenn man Arrays aus solchen structs
hat, kann man durch einfaches Umsortieren der Komponenten oftmals
beachtlich Speicher sparen und zugleich aligned bleiben.
Löst das Umsortieren das Problem auch nicht, kann man das struct auch
auseinanderreißen in zwei passende structs, aus denen man dann zwei
verschiedene Arrays baut. Das ist von der Codestruktur her zwar etwas
häßlich, aber manchmal geht's nicht anders, wenn man speichermäßig arg
knapp dran ist.
Holger K. schrieb:> Ich dachte mir dies in etwa so, dass ich das strukt dynamisch zur> laufzeit je nach erhaltenem paket typ erstelle und dann entsprechend> befülle.
Richtig.
Eine struct in C ist ein Tuple von (ggf. unterschiedlichen) Typen
innerhalb der C-Sprachdefinition.
Bei einer Datenübertragung geht es um einen Bit- oder Bytestrom (der nix
mit einer Programmiersprache zu tun habe muss).
https://en.wikipedia.org/wiki/Bitstream
(A) Wenn man "Glück" hat, paßt das 1:1. D.h., die Datenübertragung paßt
genau in die C-struct.
(B) Häufig paßt das nicht. Man kann aber zumindest eine 1:1 Zuordnung in
eine C-struct vornehmen. (https://en.wikipedia.org/wiki/Serialization)
(C) Bei komplexeren Datendefinitionen benötigt man dynamische
Datenstrukturen (bspw. DOM für XML).
Bei dir liegt scheinbar der "einfache" Fall (B) vor: Du liest die Daten
als Bytearray ein. Dann parsed du die Daten Byte-für-Byte und füllst mit
dem Ergebnis des Parsings deine Struktur. (Beim Senden umgekehrt.)
> Macht dies so sinn?
"Sinn machen kann man nicht. Unsinn schon." /SCNR ;-)
So ich war aktiv.
Es erscheint mir nach der Diskussion als sinnvoll, auf das Serialisieren
mit Strukten zu verzichten, aufgrund der unvorhersehbarkeit des
Verhaltens.
Mein Code sieht nun so aus:
1
paketHeadercomPaketHeader;
2
uint8_tcomData[100];
3
4
....
5
6
7
structhcl_axis_motion
8
{
9
uint8_tdirection;//CW, CCW
10
uint16_tspeed;//mm/s
11
uint16_tramp;//mm/s2
12
uint16_tsteps;//Steps to move. You can define the way or either the steps. but not both.
13
uint16_tway;// in the configured unit
14
};
15
16
17
uint8_tprot_Parse_Buffer(uint8_t*Buffer)
18
{
19
//CRC Check
20
//Buffer - 1 da in länge auch die CRC enthalten ist.
//Lege Struktur über bereits vorhandenen Speicherbereich
38
data=(structhcl_axis_motion*)&comData[0];
39
40
data->direction=Buffer[5];
41
data->speed=(Buffer[6]<<8)|Buffer[7];
42
data->ramp=(Buffer[8]<<8)|Buffer[9];
43
data->steps=(Buffer[10]<<8)|Buffer[11];
44
data->way=(Buffer[12]<<8)|Buffer[13];
45
}
46
47
}
48
49
//Kann irgendwo ausserhalb des *.c Files sein
50
voidverarbeite(void)
51
{
52
53
if(comPaketHeader.PaketType==AMP)
54
{
55
structhcl_axis_motion*data;
56
//Lege Struktur über bereits vorhandenen Speicherbereich
57
data=(structhcl_axis_motion*)&comData[0];
58
59
60
///.... Arbeite mit den daten
61
62
if(data->direction==1)
63
{
64
//...
65
}
66
67
}
68
}
Dazu hätte ich noch ein paar Fragen.
Ich benutze nun erneut einen bereits vorhandenen Speicherbereich
(comData) über welchen ich ein dynamisches Strukt lege. Bzw ich teile
dem Compiler mit, dass dort mein Strukt liegt.
Dies wollte ich so machen, damit ich immer weiss, wo mein Strukt mit den
Commandos liegt.
Wie man in der Funktion verarbeitung sieht, wird dort wieder comData
benutzt und das Strukt entsprechend positioniert. Falls es nun Padding
gibt, gibt es das ja bei beiden Codestellen. Somit sollte dies kein
Problem sein. Oder liege ich hier falsch?
Nun habe ich noch eine ziemlich blöde Frage.
Was genau ist der unterschied zwischen diesen beiden:
1
typedefstructnameA
2
{
3
}nameB;
4
5
structnameC
6
{
7
}nameD;
Was sind bei diesen beispielen nameA..D genau?
Danke
Holger K. schrieb:> typedef struct nameA> {> } nameB;>> struct nameC> {> } nameD;>> Was sind bei diesen beispielen nameA..D genau?
nameA ist Bezeichner der struct.
nameB ist ist der Datentyp der struct.
nameC ist Bezeichner - analog zu nameA
nameD ist eine Variable mit dem Typ der struct nameC
Du hast noch eins vergessen:
nameB nameX;
nameX ist eine Variable mit dem Typ der struct nameA
Das erste Beispiel macht zwei Sachen auf einmal:
a) Struct definieren
b) Einen neuen Datentyp nameB definieren.
Du kannst auch für das zweite Beispiel einen Datentyp definieren:
typedef struct nameC nameT;
Im ersten Beispiel wird halt beides in einem gemacht.
Das steht aber auch alles in jedem guten C-Buch.
Marc schrieb:> Blöde frage, aber für was ist denn die Zeile> info->Address = info->Idenfitifier;Adress ist 8Bit, Identifier ist 16Bit> und hat im Beispiel den Wert> 22118....
Das war lediglich dafür da, damit der compiler nicht motzte dass info
unused ist :)
Holger K. schrieb:> typedef struct paketType> {> uint8_t Address; //0xFF ist Broadcast> uint16_t Length; //Länge in Bytes inklusive CRC32
Da fängts schon an. Das zweite Member (Length) käme auf einem "krummen"
Offset zu liegen, der Compiler muss auf den meisten Platformen 1 Byte
Padding einfügen.
Wenn Du Dein Struct so umsortieren würdest daß alle Member self-aligned
wären hättest Du keine Probleme und bräuchtest auch keine
Compilerspezifischen Würgarounds.
Bitte lies den folgenden Text http://www.catb.org/esr/structure-packing/
und überdenke dann die Anordnung Deiner Struct-Member bzw den Aufbau
Deiner Datenpakete im Hinblick auf das Alignment.
Bernd K. schrieb:> bräuchtest auch keine> Compilerspezifischen Würgarounds.
Brauch ich ja auch nicht mehr.
Sieh dir doch bitte mein zuletzt geposteter Code an.
Dort kopiere ich nun manuell..
Holger K. schrieb:> Brauch ich ja auch nicht mehr.>> Sieh dir doch bitte mein zuletzt geposteter Code an.> Dort kopiere ich nun manuell..
Naja, wie gesagt liesse sich das vermeiden (und auch die von Dir
zitierte "Unvorhersehbarkeit des Verhaltens" ist eigentlich durchaus
nicht unvorhersehbar) wenn Du Dein Protokoll (und damit Deine Structs)
von Anfang an so aufgebaut hättest dass alle Elemente darin immer an
ihrer eigenen Größe aligned sind. Den Gedanken daran kannst Du ja (falls
das Kind jetzt schon in den Brunnen gefallen ist) zumindest fürs nächste
Projekt im Hinterkopf behalten. Es spart übrigens auch RAM wenn man
seine Structs grundsätzlich nach diesen Regeln aufbaut.
Bernd K. schrieb:> Naja, wie gesagt liesse sich das vermeiden (und auch die von Dir> zitierte "Unvorhersehbarkeit des Verhaltens" ist eigentlich durchaus> nicht unvorhersehbar) wenn Du Dein Protokoll (und damit Deine Structs)> von Anfang an so aufgebaut hättest dass alle Elemente darin immer an> ihrer eigenen Größe aligned sind.
Das Protokoll sollte sich nicht nach dem µC richten. Es ist üblich das
die CRC am ende im Protokoll ist, wenn dazwischen eine Variabel länge
ist, passt das NIE in eine passenden Struct.
Und was ist wenn man später den µC ändern - dann musst man das Protokoll
ändern?
Es wird doch immer wieder über Kapselung geredet - hier ist das genauso.
Das Protokoll wird an der Schnittstelle in das interne Datenformat
überführt. Und das macht man nicht, in dem man es einfach als Haufen
kopiert.
Holger K. schrieb:> Das war lediglich dafür da, damit der compiler nicht motzte dass info> unused ist :)
Probier mal das:
struct paketType __attribute__((_unused_)) *info;
Das verhindert eine Compilerwarnung.
Viele Grüße, Stefan
Kann man so machen, möchte man aber eigentlich vermeiden, weil daraus
leicht Fehler entstehen können.
Warum nicht gleich hcl_axis_motion? Wenn geteilt mit anderen Daten,
bietet sich ggf. eine union an?!
> Was genau ist der unterschied zwischen diesen beiden:> ...
In C benötigt man beim Anlegen einer struct Instanz immer das
Schlüsselwort "struct".
1
structFoo{/*...*/};
2
structFoofoo;/* we need the keyword "struct" */
Nach einem typedef kann man auf "struct" verzichten.
Peter II schrieb:> Das Protokoll sollte sich nicht nach dem µC richten.
Das schrieb ich auch nicht. Ich schrieb daß das Protokoll so designed
sein soll daß keine Elemente an krummen Offsets zu liegen kommen.
Bernd K. schrieb:> Das schrieb ich auch nicht. Ich schrieb daß das Protokoll so designed> sein soll daß keine Elemente an krummen Offsets zu liegen kommen.
und das geht kaum, da die CRC aus praktischen gründen immer hinten ist.