Moin Moin
Ich versuche die Wandlung einer 64Bit unsigned int in ASCII.
Folgende Funktion liefert leider falsche Werte
snr=0;
ItoA(snr,teststring);
draw_string_8x16_normal(10,210,teststring);
-> Ausgabe zeigt 125729
void ItoA( uint64_t z, char* Buffer )
{
int i = 0;
int j;
char tmp;
uint64_t u; // In u bearbeiten wir den Absolutbetrag von z.
// ist die Zahl negativ?
// gleich mal ein - hinterlassen und die Zahl positiv machen
// die einzelnen Stellen der Zahl berechnen
do
{
Buffer[i++] = '0' + u % 10;
u /= 10;
}
while( u > 0 );
// den String in sich spiegeln
for( j = 0; j < i / 2; ++j )
{
tmp = Buffer[j];
Buffer[j] = Buffer[i-j-1];
Buffer[i-j-1] = tmp;
}
Buffer[i] = '\0';
}
Benjamin S. schrieb:> uint64_t u;Benjamin S. schrieb:> do> {> Buffer[i++] = '0' + u % 10;> u /= 10;> }> while( u > 0 );
u ist nicht initialisiert, damit erhälst du logischer weise schrott.
Hannes J. schrieb:> Von der großartig im Kommentar angekündigten Behandlung negativer Zahlen> ist auch nichts zu sehen.
Hätte mich auch gewundert wenn ein Unsinged Integer negativ Vorbehaftet
ist. ;-)
... schließe mich den Vorrednern komplett an (die schlicht eben
schneller waren als ich während ich den Code angesehen und modifiziert
hab).
Irgendwie ... bin ich wohl definitiv zu langsam !
Ralph S. schrieb:>...während ich den Code angesehen und modifiziert hab...
Fast korrekt. Hat noch mit (int64_t) 0x8000000000000000 Probleme.
Für den kleinsten (negativen) Integer gibt es kein positives Pendant.
Wilhelm M. schrieb:> Jens G. schrieb:> Sorry, ich kann einfach nicht nachvollziehen, dass man das in C++ mit> C-Arrays macht, deren (hoffentlich ausreichende) Größe einer Annahme> unterliegt, die der Compiler ja nicht prüfen kann!
Ich verstehe die Nachfrage nicht. Der Quelltext ist getestet und
funktioniert. .. ist bei Arduino etwa doppelt so schnell wie itoa();
ltoa(); .. und geht mit allen Datentypen von 8_bit bis 64_bit, mit und
ohne Vorzeichen.
Bei VisualStudio gibt es Warnungen, da mehrmals Typumwandlungen
angenommen werden. Es ist alles mit Bedacht verwendet worden. Dieser
Test: https://github.com/miloyip/itoa-benchmark lief fehlerfrei bei mir
durch.
Jens G. schrieb:> Wilhelm M. schrieb:>> Jens G. schrieb:>> Sorry, ich kann einfach nicht nachvollziehen, dass man das in C++ mit>> C-Arrays macht, deren (hoffentlich ausreichende) Größe einer Annahme>> unterliegt, die der Compiler ja nicht prüfen kann!>> Ich verstehe die Nachfrage nicht. Der Quelltext ist getestet und> funktioniert. .. ist bei Arduino etwa doppelt so schnell wie itoa();> ltoa(); .. und geht mit allen Datentypen von 8_bit bis 64_bit, mit und> ohne Vorzeichen.
Der Compiler wirds compilieren:
>> Aber was passiert?
Das Programm wird fehlerhaft ausgeführt werden, da zur Laufzeit nicht
überprüft wird, wo in den Buffer geschrieben wird. Der Programmierer
steht in der Verantwortung den Buffer entsprechend der zu erwartenden
Zahlen zu wählen. .. bei Pascal war alles noch anders - da gab es eine
Typprüfung. Heute darf der Programmierer selbst darauf achten was ER
tut.
>>>> Aber was passiert?> Das Programm wird fehlerhaft ausgeführt werden, da zur Laufzeit nicht> überprüft wird, wo in den Buffer geschrieben wird.
Genau. Und das kann man bei C++ ja ganz elegant verhindern! Sowas macht
man meinetwegen in C, aber nicht in C++!
Wilhelm M. schrieb:> Genau. Und das kann man bei C++ ja ganz elegant verhindern! Sowas macht> man meinetwegen in C, aber nicht in C++!
Na dann freue ich mich auf die Verbesserungen meines Quelltextes. In C++
bin ich noch Anfänger, lerne gerne auch von anderen Profis. Ich habe den
vorliegenden Quelltext einfach etwas erweitert und von Fehlern
(Portierbarkeit) beseitigt. Hoffenlich funktioniert .. nach der
Veränderung .. der Quelltext noch beim Arduino.
Jens G. schrieb:> Wilhelm M. schrieb:>> Genau. Und das kann man bei C++ ja ganz elegant verhindern! Sowas macht>> man meinetwegen in C, aber nicht in C++!> Na dann freue ich mich auf die Verbesserungen meines Quelltextes. In C++> bin ich noch Anfänger, lerne gerne auch von anderen Profis.
Ok, habe ich mir gedacht.
Nun, dann schnapp Dir ein paar gute Bücher (Breymann, alle von Scott
Meyers sowie von Herb Sutter und Josuttis, oder schau auf Youtube die
Serie von Jason Turner) und los geht's. Aber auf dieser Stufe solltest
Du nicht stehen bleiben, wenn Du wirklich C++ machen möchtest und nicht
nur C-Code mit einem C++-Compiler übersetzen.
Wilhelm M. schrieb:> Aber auf dieser Stufe solltest Du nicht stehen bleiben,> wenn Du wirklich C++ machen möchtest und nicht> nur C-Code mit einem C++-Compiler übersetzen.
Ich denke Du meinst man sollte anstelle von "array of char" lieber den
Typ String verwenden und bei 8-bit µC kann dann nur dies zur Anwendung
kommen: http://www.etlcpp.com/string.html
Ist das gemeint -- lieber "String" anstelle von "array of char" ?
Jens G. schrieb:> Der Programmierer steht in der Verantwortung den Buffer entsprechend> der zu erwartenden Zahlen zu wählen.
Bei integer Datentypen bekannter Größe ist die maximale Größe der
möglichen Zahlen und damit auch die maximale Größe des erforderlichen
Zeichen-Arrays doch wohl nicht ganz unberechenbar. Was erwartest du da
für Unwägbarkeiten, die der Programmierer entscheiden muss?
Jens G. schrieb:> Wilhelm M. schrieb:>> Aber auf dieser Stufe solltest Du nicht stehen bleiben,>> wenn Du wirklich C++ machen möchtest und nicht>> nur C-Code mit einem C++-Compiler übersetzen.>> Ich denke Du meinst man sollte anstelle von "array of char" lieber den> Typ String verwenden und bei 8-bit µC kann dann nur dies zur Anwendung> kommen: http://www.etlcpp.com/string.html
Nicht notwendigerweise. Der wichtige Punkt ist: wird die Schnittstelle
von
itoa() falsch benutzt, d.h. hier: verwendet der Anwender einen zu
kleinen
Buffer / Container als Output-Parameter für den zu wandelnden
Ganzzahltyp, dann darf das nicht kompilieren(!).
Da kann man sicher etl::string<> nehmen, aber auch std::array<> (oder
auch char[N]) oder stringview<> oder eigene Container Realisierungen.
Daran erkennt man, dass der Typ des Containers eigentlich egal ist unter
der Voraussetzung, das der Elementtyp und die Größe passt. Also ein
generischer Algorithmus.
Das führt dazu, dass man itoa() als template schreiben kann. Das
template
leitet die Größe des Containers ab und compiliert nicht, wenn die zu
klein / nicht passend ist im Vergleich zur Ganzzahl.
> Ist das gemeint -- lieber "String" anstelle von "array of char" ?
s.o. ... nein.
Wilhelm M. schrieb:> Nicht notwendigerweise. Der wichtige Punkt ist: wird die Schnittstelle> von itoa() falsch benutzt, d.h. hier: verwendet der Anwender einen zu> kleinen Buffer / Container als Output-Parameter für den zu wandelnden> Ganzzahltyp, dann darf das nicht kompilieren(!).
Nicht "zu klein für den Typ", sondern "zu klein für den Wertebereich".
Wenn ich einen Wert im Bereich 0 bis 80000 in einen String wandeln
will, brauche ich nicht einen 12 Bytes großen Puffer dafür, nur weil der
Wert in einer 32-Bit-Variable gespeichert sein muss. Es reicht auch ein
halb so großer Puffer. Dass man diesen Wertebereich nicht verlässt, muss
man dann natürlich sicherstellen.
Rolf M. schrieb:> Wilhelm M. schrieb:>> Nicht notwendigerweise. Der wichtige Punkt ist: wird die Schnittstelle>> von itoa() falsch benutzt, d.h. hier: verwendet der Anwender einen zu>> kleinen Buffer / Container als Output-Parameter für den zu wandelnden>> Ganzzahltyp, dann darf das nicht kompilieren(!).>> Nicht "zu klein für den Typ", sondern "zu klein für den Wertebereich".> Wenn ich einen Wert im Bereich 0 bis 80000 in einen String wandeln> will, brauche ich nicht einen 12 Bytes großen Puffer dafür, nur weil der> Wert in einer 32-Bit-Variable gespeichert sein muss. Es reicht auch ein> halb so großer Puffer. Dass man diesen Wertebereich nicht verlässt, muss> man dann natürlich sicherstellen.
Ein klares Nein. Eine Funktion, die einen domänen-unspezifischen Typ wie
etwa uint32_t in irgendwas wandeln soll, MUSS davon ausgehen, das der
Wertebereich ausgenutzt wird. Bei solchen Datentypen gibt es keine
"ungültigen" Werte aus Sicht der verarbeitenden Funktion.
Man kann das aber natürlich mit spezielleren Typ als die primitiven
machen: etwa in der Art uint_bounded<uint32_t, 999>. Dafür reichen dann
bei itoa() char-Container der Länge 3. Das kostet auch gar keine
Laufzeit - das ist ja gerade die Stärke von C++, dass man
domänen-spezifische DT "kostenneutral" bilden kann. Damit bildet man
möglichst viel Semantik in den Typen ab, was der Compiler zur
Compile-Zeit prüfen kann. Zusicherungen zur Laufzeit sind immer die
zweite Wahl.
Natürlich ist uint_bounded<> auch noch ein unspezifischer DT. Bspw. für
Kalendermonate sollte man dann etwas wie Date::Month haben, statt int.
Man kann natürlich eine entsprechende Funktion wie itoa() schreiben, der
man beliebige, auch zur kurze Container übergibt. Dann muss man zur
Laufzeit prüfen und ggf. abschneiden. Die würde ich dann aber anders
nennen. Aber wichtig ist eben, das itoa_xxx() das prüfen kann. Und das
kann sie als
Ungeachtet aller "Formfehler" bezüglich der Nutzung von C++, so sollte
das Stück Software auch zuverlässig funktionieren. Das hat es leider
nicht. Ich habe Fehler bereinigt und noch etwas Zeitoptimierung gemacht.
Habs auch mal auf einem ATMega1284p-Testboard (20Mhz) laufen lassen:
1
0:V:0,0ms
2
1:V:1,2ms
3
2:V:10,2ms
4
3:V:100,6ms
5
4:V:1000,19ms
6
5:V:10000,29ms
7
6:V:100000,50ms
8
7:V:1000000,79ms
9
8:V:10000000,81ms
10
9:V:100000000,109ms
11
10:V:1000000000,109ms
12
11:V:10000000000,154ms
13
12:V:100000000000,159ms
14
13:V:1000000000000,190ms
15
14:V:10000000000000,198ms
16
15:V:100000000000000,237ms
17
16:V:1000000000000000,266ms
18
17:V:10000000000000000,268ms
19
18:V:100000000000000000,318ms
20
19:V:1000000000000000000,319ms
Allerdings sind die Routinen nicht für jedermann geeignet, das sie wegen
der LookUp-Tabelle 200 Byte RAM zusätzlich verbrauchen.
Eine primitiv-Variante erreicht:
1
0:V:0,0ms
2
1:V:1,10ms
3
2:V:10,17ms
4
3:V:100,24ms
5
4:V:1000,51ms
6
5:V:10000,63ms
7
6:V:100000,189ms
8
7:V:1000000,219ms
9
8:V:10000000,251ms
10
9:V:100000000,281ms
11
10:V:1000000000,313ms
12
11:V:10000000000,822ms
13
12:V:100000000000,951ms
14
13:V:1000000000000,1083ms
15
14:V:10000000000000,1214ms
16
15:V:100000000000000,1363ms
17
16:V:1000000000000000,1515ms
18
17:V:10000000000000000,1688ms
19
18:V:100000000000000000,1859ms
20
19:V:1000000000000000000,2050ms
ohne zusätzlichen RAM Verbrauch durch Lookup-Tabelle.
Space <-> Speed-Tradeoff
Wilhelm M. schrieb:> Allerdings sind die Routinen nicht für jedermann geeignet, das sie wegen> der LookUp-Tabelle 200 Byte RAM zusätzlich verbrauchen.>
Macht es Sinn die LookUp-Tabelle im Pgm-Space zu halten?
Habe meine Lösung nochmal umgebaut. Es ist nun einen generische
Variante, die für alle Basen (2 ... 16) wandeln kann und eine
Lookup-Tabelle verwendet (Space-Speed-Tradeoff).
Das sind die Zahlen (at328p@12MHz):
1
O:0:V:,0,0,0ms
2
O:1:V:,1,1,2ms
3
O:2:V:,1,10,4ms
4
O:3:V:,1,100,11ms
5
O:4:V:,2,1000,21ms
6
O:5:V:,2,10000,37ms
7
O:6:V:,3,100000,102ms
8
O:7:V:,3,1000000,147ms
9
O:8:V:,3,10000000,150ms
10
O:9:V:,3,100000000,195ms
11
O:10:V:,3,1000000000,198ms
12
O:11:V:,4,10000000000,258ms
13
O:12:V:,4,100000000000,304ms
14
O:13:V:,4,1000000000000,325ms
15
O:14:V:,4,10000000000000,365ms
16
O:15:V:,4,100000000000000,382ms
17
O:16:V:,4,1000000000000000,431ms
18
O:17:V:,4,10000000000000000,434ms
19
O:18:V:,4,100000000000000000,498ms
20
O:19:V:,4,1000000000000000000,500ms
Es ist eine vollständig reguläre Lösung für alle Datentypen (uint8_t ...
uint64_t sowie signed) mit Längenbestimmung über binäre Auswahl, die mit
templates realisiert ist.
Wilhelm M. schrieb:> Habe meine Lösung nochmal umgebaut. Es ist nun einen generische> Variante, die für alle Basen (2 ... 16) wandeln kann und eine> Lookup-Tabelle verwendet (Space-Speed-Tradeoff).>> Es ist eine vollständig reguläre Lösung für alle Datentypen (uint8_t ...> uint64_t sowie signed) mit Längenbestimmung über binäre Auswahl, die mit> templates realisiert ist.>
Der Quelltext zu bekommen, währe nicht schlecht ;-) .
Jens G. schrieb:> Wilhelm M. schrieb:>> Habe meine Lösung nochmal umgebaut. Es ist nun einen generische>> Variante, die für alle Basen (2 ... 16) wandeln kann und eine>> Lookup-Tabelle verwendet (Space-Speed-Tradeoff).>>>> Es ist eine vollständig reguläre Lösung für alle Datentypen (uint8_t ...>> uint64_t sowie signed) mit Längenbestimmung über binäre Auswahl, die mit>> templates realisiert ist.>>> Der Quelltext zu bekommen, währe nicht schlecht ;-) .
Hier der erste Wurf (s.a. Anhang):
Jens G. schrieb:> Wilhelm M. schrieb:>> Habe meine Lösung nochmal umgebaut. Es ist nun einen generische>> Variante, die für alle Basen (2 ... 16) wandeln kann und eine>> Lookup-Tabelle verwendet (Space-Speed-Tradeoff).>>>> Es ist eine vollständig reguläre Lösung für alle Datentypen (uint8_t ...>> uint64_t sowie signed) mit Längenbestimmung über binäre Auswahl, die mit>> templates realisiert ist.>>> Der Quelltext zu bekommen, währe nicht schlecht ;-) .
Bei Deinem Code solltest Du unbedingt noch für die switch-cases ein
fallthrough attribute ergänzen. Ansonsten bekommt einen Haufen von
Warnungen ...
Beim der Menge von Warnungen ist mir das in Deinem Code auch nicht
aufgefallen: es gibt Funktionen, die haben ein switch-case mit
fallthrough und ohne default. In diesem Fall gibt es die Warnung, dass
ein return für diese non-void Funktion fehlt. Zwar kann der Fall (im
Moment) in Deinem Code nicht vorkommen, doch das weiß ja der Compiler so
nicht. Deswegen ein default-case einbauen mit einem assert(false) und
auch ein return p; (falls das assert()-Macro eine noreturn-Funktion
aufruft)
Wilhelm M. schrieb:> Beim der Menge von Warnungen ist mir das in Deinem Code auch nicht> aufgefallen: es gibt Funktionen, die haben ein switch-case mit> fallthrough und ohne default. In diesem Fall gibt es die Warnung, dass> ein return für diese non-void Funktion fehlt.
danke für den Tip - default switch-case verwenden. Das hat den
Maschinencode verringert und die Laufzeit etwas verbessert.
https://github.com/JensGrabner/snc98_Slash-Number-Calculator
Wilhelm M. schrieb:> Lookup-Tabelle verwendet (Space-Speed-Tradeoff).> Das sind die Zahlen (at328p@12MHz):> O:19 : V : ,4,1000000000000000000,500ms
Irgendwas kann da doch nicht stimmen. Bei 12MHz und 500ms wären das
6.000.000 Cycles. Eine Umwandlung nach ASCII Dezimal in in 1/1000 der
Zeit machbar, und zwar ohne Splatz durch Lookup-Tabelle zu
verschwenden.
Wilhelm M. schrieb:> Die Zeit gilt für 900 Konvertierungen (bitte lies weiter oben) wegen> Vergleich zum Ausgangscode ...
in jede Dekade werden bei meinem Test 900 unterschiedliche Zahlen
erzeugt. Ab der Zahl 100 ist es +1, ab 1000 ist es +10 ... das macht 17
Dekaden bei dem vollen Zahlenumfang den ich teste -- bei meiner
Testroutine werden 15300 Zahlen erzeugt - so konnte ich Fehler finden.
Noch eine interessante Beobachtung
(für uint32_t, uint64_t geht mit ltoa() ja nicht mehr):
1
textdatabssdechexfilename
2
252087339153bm02a.elf
3
3740874611cdbm03a.elf
4
82820287111745dbm04a.elf
bm02a: meine template Variante (auch die schnellste)
bm03a: aus avr-libc
bm04a: von jensg
(Bei den Beispielen oben ist jeweils noch eine Text-Ausgabe dabei):
Wilhelm M. schrieb:> Noch eine interessante Beobachtung> (für uint32_t, uint64_t geht mit ltoa() ja nicht mehr):>>
1
>textdatabssdechexfilename
2
>252087339153bm02a.elf
3
>3740874611cdbm03a.elf
4
>
>> bm02a: meine template Variante (auch die schnellste)> bm03a: aus avr-libc
Lass einfach mal "constexpr uint8_t Base = 10;" weg und übergib Base als
Parameter, das mach den Vergleich mit der avr-libc etwas realistischer.
>>>> bm02a: meine template Variante (auch die schnellste)>> bm03a: aus avr-libc>> Lass einfach mal "constexpr uint8_t Base = 10;" weg und übergib Base als> Parameter, das mach den Vergleich mit der avr-libc etwas realistischer.
Schau Dir den Code noch mal genauer an!
Hallo Wilhelm M. .. Arduino kennt nur eine Teilmenge von C++. Womit
programmierst Du? Damit ich einen Weg zu Arduino finde, deinen Quelltext
zu testen.
Jens G. schrieb:> Hallo Wilhelm M. .. Arduino kennt nur eine Teilmenge von C++. Womit> programmierst Du? Damit ich einen Weg zu Arduino finde, deinen Quelltext> zu testen.
Mit Arduino hat das ganze nichts zu tun ...
Du brauchst einen g++ mit variadic-templates und fold-expressions (ab
Version 6) und concepts-lite (glaube ab Version 6.3.1 vorhanden,
Schalter -fconcepts nicht vergessen) und einiges von C++17, was erst mit
g++ >= 7.0 dabei ist, v.a. constexpr-lambda-expressions sowie
Selektionen mit initializern, inline-static Variablen, constexpr-if und
wahrscheinlich noch ein paar mehr Sachen aus c++17, die ich mir so
angewöhnt habe (ich denke, structured bindings könnten auch dabei sein
sowie variablen-templates).
Jens G. schrieb:> Wird dein Stück Software auf Atmel AVR 8-bit lauffähig sein? C++17 ist> um einiges entfernt von C++11 der auf Atmel portiert wurde.
Es IST auf AVR-8Bit lauffähig - und läuft. Sonst hätte ich Dir kaum die
Zeiten und Code-Größen sagen können ... ;-)
Wie das mit ATmel-Studio oder Arduino-IDE geht, kann ich Dir allerdings
nicht sagen. Als IDE bzw. Editor nehme ich QtCreator und den Rest
erledigen ein paar Makefiles.
Wilhelm M. schrieb:> Jens G. schrieb:>> Wird dein Stück Software auf Atmel AVR 8-bit lauffähig sein? C++17 ist>> um einiges entfernt von C++11 der auf Atmel portiert wurde.>> Es IST auf AVR-8Bit lauffähig - und läuft. Sonst hätte ich Dir kaum die> Zeiten und Code-Größen sagen können ... ;-)>
Sorry, wollte Deine qualitativ hochwertige Arbeit nich schmälern. Ich
selbst kann Deine Arbeit nicht bewerten, da ich in meinem
Open-Source-Projekt Lösungen brauche die einfach auf der
Arduino-Plattform zum laufen zu bringen sind. Wie das technisch auf
Arduino geht -- da bin ich fachlich überfordert und werde deinen Ansatz
nicht weiter verfolgen (können). Schade....
Jens G. schrieb:> Wilhelm M. schrieb:>> Jens G. schrieb:>>> Wird dein Stück Software auf Atmel AVR 8-bit lauffähig sein? C++17 ist>>> um einiges entfernt von C++11 der auf Atmel portiert wurde.>>>> Es IST auf AVR-8Bit lauffähig - und läuft. Sonst hätte ich Dir kaum die>> Zeiten und Code-Größen sagen können ... ;-)>>> Sorry, wollte Deine qualitativ hochwertige Arbeit nich schmälern. Ich> selbst kann Deine Arbeit nicht bewerten, da ich in meinem> Open-Source-Projekt Lösungen brauche die einfach auf der> Arduino-Plattform zum laufen zu bringen sind. Wie das technisch auf> Arduino geht -- da bin ich fachlich überfordert und werde deinen Ansatz> nicht weiter verfolgen (können).
Du brauchst doch einfach nur eine neuere Version des avr-g++ zu
installieren. Das ist alles. Es ist ja alles abwärtskompatibel bis zu
C++98. Das Compilieren eines avr-gcc besteht doch nur aus
configure ...
make
make install
Und dann musst Du Deiner IDE nur sagen, dass sie einen anderen Compiler
benutzen soll ...
Wilhelm M. schrieb:> Und dann musst Du Deiner IDE nur sagen, dass sie einen anderen Compiler> benutzen soll ...
Tja, und genau das ist die Frage, ob das bei Arduino so einfach geht.
Konfigurierbar ist da herzlich wenig. Ich hatte auch schon mehrfach
vergeblich versucht, lediglich ein paar Warning-Levels hochzuschrauben,
weil sonst noch nichtmals unbenutzte Variablen angemeckert werden.
Bei manchen Dingen kann so ein Wohlfühlkissen furchtbar starr werden.
Frank M. schrieb:> Wilhelm M. schrieb:>> Und dann musst Du Deiner IDE nur sagen, dass sie einen anderen Compiler>> benutzen soll ...>> Tja, und genau das ist die Frage, ob das bei Arduino so einfach geht.> Konfigurierbar ist da herzlich wenig.
Da ich ein Open-Source-Projekt für Arduino betreibe, bin ich darauf
angewiesen, alles so zu machen, das es bei Arduino geht. Was ein Vorteil
für den einen (Anfänger) ist, ist ein Nachteil für den anderen (Profi).
Arduino verwendet aktuell: avr-gcc=4.9.2-atmel3.5.4-arduino2.
Jens G. schrieb:> Frank M. schrieb:>> Wilhelm M. schrieb:>>> Und dann musst Du Deiner IDE nur sagen, dass sie einen anderen Compiler>>> benutzen soll ...>>>> Tja, und genau das ist die Frage, ob das bei Arduino so einfach geht.>> Konfigurierbar ist da herzlich wenig.> Da ich ein Open-Source-Projekt für Arduino betreibe, bin ich darauf> angewiesen, alles so zu machen, das es bei Arduino geht. Was ein Vorteil> für den einen (Anfänger) ist, ist ein Nachteil für den anderen (Profi).> Arduino verwendet aktuell: avr-gcc=4.9.2-atmel3.5.4-arduino2.
Oh je: Version 4.9.2 ist aber wirklich alt (vor Juni 2015).
Gerade bei C++ hat sich ja in dieser Zeit SEHR viel geändert, vor allem
in Bezug auf templates und constexpr, was man für µC sehr gut gebrauchen
kann. Und es wird sich in Zukunft ja weiterhin viel ändern!
Da kann ich nur dringend empfehlen, mal zu schauen, ob man dass nicht
ändern kann.
Wilhelm M. schrieb:> Habe gerade einen ganz kurzen Blick da hinein geworfen. Sehe ich das> richtig, dass Du den Code unverändert übernommen hast?
Es kommt drauf an, auf was es sich bezieht - ja < Original:
http://www.naughter.com/int96.html > habe ich weitgehend übernommen. Der
Quallcode ist auf die .. #include <inttypes.h> Konvention angepasst.
Und .. #include <itoa_ljust.h> habe ich von 64bit auf 96bit erweitert.
Es besteht noch Optimierungsbedarf - ab bit 65 wird es 10x langsamer.
Jens G. schrieb:> Und .. #include <itoa_ljust.h> habe ich von 64bit auf 96bit erweitert.> Es besteht noch Optimierungsbedarf - ab bit 65 wird es 10x langsamer.
Ok, der Frage war einfach nur erst einmal reines Interesse.
Bezogen auf die Schnittstelle und auch Teile der Implementierung sehe
ich auch noch Verbesserungsmöglichkeiten. Es ist teilweise nicht sehr
idiomatisch und die Typumwandlungsoperation halte ich für problemtisch
...
Mein Quelltext ist verbessert worden. Die einzig große Division mit
int96 habe ich durch eine Multiplikation ersetzt (* 1/x). Dazu habe ich
eine neue Funktion erstellt (a * b) / 2^95.
Auch wenn dieser Thread schon etwas älter ist...
Beim Durchsehen meiner Platte hab ich eine ältere Konvertierungsroutine
in AVR-Assembler gefunden. Geht also in die andere Richtung als die C++
Fraktion. Weil so eine Konvertierung als low-Level angesehen werden
kann, ist Assembler jedenfalls nicht komplett abwegig.
Vielleicht kann jemand was damit anfangen. Ich hab paar Kommentare
ergänzt und einen C/C++ Header dazu gemacht so dass es einfacher von
C/C++ aus zu verwenden ist.
1
char*ulltoa_base10(uint64_tvalue,char*buf);
2
char*lltoa_base10(int64_tvalue,char*buf);
3
4
/* Slower than expected. Reading from table takes its toll... */
5
char*ulltoa_base10_fast(uint64_tvalue,char*buf);
Hier ein paar Metriken für ulltoa_base10:
* Weniger als 200 Bytes Code, keine Loopup-Tabelle.
* Worst-Case Execution Time unter 3300 Cycles.
* Worst-Case Execution Time unter 2800 Cycles (mit MUL).
* Average Execution Time unter 2000 Cycles (mit MUL).
Rückgabe ist die Adresse des '\0' am Stringende, so dass man leicht
andere Strings anhängen kann. Die Stringlänge ist so einfach per
Zeiger-Differenz bestimmbar.
Umgerechnet auf die Werte von oben mit 900 Runden @ 12MHz sind das
250ms, 210ms und 150 ms. Bezogen auf 20MHz sind es 150ms, 130ms und
90ms.
Jens G. schrieb:> Ich habe Fehler bereinigt und noch etwas Zeitoptimierung gemacht.
1
Test: 900x itoa_() at 12_MHz on ATMEGA_1284p
2
> 17 - 100000000000000000 - 435 ms ( 483 µs )
3
> 18 - 1000000000000000000 - 485 ms ( 539 µs )
4
> 19 - 10000000000000000000 - 544 ms ( 604 µs )
Wilhelm M. schrieb:> Habs auch mal auf einem ATMega1284p-Testboard (20Mhz) laufen lassen:
1
>17:V:10000000000000000,268ms
2
>18:V:100000000000000000,318ms
3
>19:V:1000000000000000000,319ms
> Allerdings sind die Routinen nicht für jedermann geeignet, das sie wegen> der LookUp-Tabelle 200 Byte RAM zusätzlich verbrauchen.
Auch eine Version mit Lookup-Tabelle ist dabei. Was mich etwas
erstaunte, ist dass diese gegenüber der Version ohne Tabelle nur einen
marginalen Zuwachs an Geschwindigkeit brachte.
Bestimmt wurden die Zeiten mit dem avrtest Simulator. Der unterstützt
Performance-Messung.
ulltoa_base10() braucht weder Lookup noch Division oder Mudulo und
beginnt die Umwandlung mit den höherwertigen Ziffern. Das Verfahren ist
daher einfach auf Fixed-Point übertragbar.
Anbei sind auch 2 Implementierungen in C:
1
/* A C analogon of ulltoa_base10 to show the basic principle. */
2
char*ulltoa_base10_C(uint64_tx,char*buf);
3
4
/* A simple but also typically veeery slooow C implementation. */
Es freut mich, das dieser Thread wieder etwas belebt wird.
Ich werde bald ein anderes Zahlenformat benötigen.
128-bit (64.64) signed fixed-point arithmetic.
https://github.com/fahickman/r128
Da dürfte es sinnvol sein, für dieses Format meine Routinen zu
erweitern.
In C++ gibt es jetzt to_chars und from_chars, die besser als alle
bisherigen string conversions der c/c++ lib für Mikrocontroller geeignet
sind.
Wäre interessant wie die sich im Platz- und Geschwindigkeitsvergleich
schlagen.
c++ ftw schrieb:> In C++ gibt es jetzt to_chars und from_chars, die besser als alle> bisherigen string conversions der c/c++ lib für Mikrocontroller geeignet> sind.
Ist erst mal nur ein Interface, das effiziente Implementierung
prinzipiell ermöglicht, weil keine dynamische Speicherallikierung
notwendig und keine fancy Formatierungen.
Wenn es bislang noch keine effiziente Implementierung von ultoa / utoa
gab, wie sie zum Beispiel die avr-libc enthält, dann wird die neue
Fassade auch nicht dazu führen, dass Effizient plötzlich vom Himmel
fällt. Und wenn, kann das gleiche Verfahren für ultoa etc. verwendet
werden: Ein Integer Typ, dessen String-Darstellung in einer Basis 2...36
zu bestimmen ist.
Hallo,
wie kann man die charconv einbinden? Ich habe Dank Johann einen frisch
compilierten avr-gcc 9.1 zur Verfügung. (seit paar Tagen gibts 9.2) Die
charconv Lib kennt er jedoch nicht. Was tun?
Oliver S. schrieb:> Du könntest mal die fehlende C++-Standardlib für AVR schreiben...
ich lese bei Zeile 1: Primitive numeric conversions (to_chars and
from_chars)
Meine öffentliche Quelle kann "nur" .. to_chars.
Mir ist nicht bekannt, wie man dort mitarbeiten kann.
Hallo,
die charconv benötigt noch andere fehlende Libs. Ich dachte naiv man
könnte die Libs vielleicht beim Toolchain bauen mit einbinden. Habe ich
wohl falsch gedacht.
Wegen der STL schreiben. Wenn ich groß bin und C++ komplett beherrsche
könnte ich damit anfangen. Allerdings befürchte ich das mich die C++
Entwicklung immer überholen wird. :-)
Mal sachlich gefragt. Was ist das Problem an der avr Anpassung der STL?
Ich meine es gab ja schon welche, nur sind die für aktuelle avr-gcc
veraltet. Wofür fürchten sich alle? :-)
Bevor ich diesen Thread entdeckte habe ich mir sowas geschrieben. Damit
kann ich alles bis 32Bit ausgeben. Ohne Funktion überladen zu müssen.
Veit D. schrieb:> Mal sachlich gefragt. Was ist das Problem an der avr Anpassung der STL?> Ich meine es gab ja schon welche, nur sind die für aktuelle avr-gcc> veraltet. Wofür fürchten sich alle? :-)
Fürchten wird sich keiner davor. Es gibt wohl nur keinen, der sowohl
Lust, als auch das Wissen hat, um es zu machen.
Wahrscheinlich warten alle, "bis sie groß sind und C++ komplett
beherrschen" ;-)
Dazu kommt, dass große Teile der Standardbibliothek massiv auf
dynamischen Speicher setzen, den man auf kleinen AVRs eher sparsam bis
gar nicht verwendet. Eine std::map dürfte dort selten sinnvoll sein.
Hallo Rolf,
na wenigstens Einer der eine gesunde Portion Humor mitbringt.
Gut ich verstehe das Problem. Ich dachte wenn man die Möglichkeiten der
STL auf einem kleinen AVR mit Bedacht einsetzt, dann könnte man
wenigstens ein paar wenige Teile zusätzlich nutzen. Man muss nur - wie
immer - wissen was man tut.
Danke für die Antwort.
Veit D. schrieb:> Hallo Rolf,>> na wenigstens Einer der eine gesunde Portion Humor mitbringt.> Gut ich verstehe das Problem. Ich dachte wenn man die Möglichkeiten der> STL auf einem kleinen AVR mit Bedacht einsetzt, dann könnte man> wenigstens ein paar wenige Teile zusätzlich nutzen. Man muss nur - wie> immer - wissen was man tut.
Die C++-Standard-Lib (STL war einmal) auf kleine µC zu portieren, ist
grundsätzlich nicht schwer. Nur ist es so, dass man bspw. die
dynamischen Container bei den üblichen Problemstellungen dieser
Kategorie µC gar nicht benötigt. Auch bei anderen Dingen wünscht man
sich Anpassungen, die noch stärker in Richtung statische Polymorphie
gehen.
Einige der Algorithmen kann man natürlich direkt übernehmen, wenn man
sie braucht. Für meinen Teil habe ich das gemacht. So habe ich zwar
keine C++-Sandard-lib, aber doch die Teile, die ich wirklich brauche.
Allerdings auch noch mehr, z.B. eine TMP-Bibliothek (was meines
Erachtens der Schlüssel zum Erfolg im Small-Embedded ist).
Also: es macht keiner / wird keiner machen, weil man es in der
vorgegebenen Form nicht braucht. Und wenn ich mir diese Diskussionen um
C++ im µC (zumindest in diesem Forum) ansehe, dann scheint auch der
"Markt" gar nicht da zu sein - jedenfalls nicht hier.
Wilhelm M. schrieb:> wenn ich mir diese Diskussionen um> C++ im µC (zumindest in diesem Forum) ansehe, dann scheint auch der> "Markt" gar nicht da zu sein - jedenfalls nicht hier.
Genau das ist der Punkt.
***********************
C++ ist abstrakt, leistungsfähig und dynamisch. Es ist nicht einfach in
C++ mitzuschwimmen. Man muss sich mit C++ befassen. Das braucht Energie,
Zeit und Durchhaltevermögen.
Schade, dass sich die Diskussionen hier rund um uC und C++ regelmässig
festfahren.
Eine Plattform für Diskussionen, in der sich Interessierte und Experten
konstruktiv über C++ für uC austauschen könnten, ist mikrocontroller.net
leider nicht. Eine andere, geeignetere habe ich noch nicht gefunden.
Greenhorns schreiben manchmal, ohne sich in die Problematik einzudenken
und Experten antworten manchmal auf einem Level, das eher abschreckt als
motiviert ...
Zurück zum Thema
****************
Es ist durchaus möglich, im Netz moderne und leistungsfähige C++
Bibliotheken für uC zu finden ...
Habe vor längerer Zeit auf Basis Mcucpp eine VisualC++Console
application zum ausprobieren erstellt.
Als Beispiel auf Wandbox implementiert. Ist zusammenkopiert, aber
lauffähig und prinzipiell uC tauglich.
https://wandbox.org/permlink/j9bXlNkcy45E1j9Y
Veit D. schrieb:> Hallo,>> wenn ich einzelne Teile der C++-Standard-Lib probieren möchte, in> welchen Ordner der Toolchain müssen die Headerfiles einsortiert werden?
Wo es Dir beliebt: die Option -I ist Dein Freund.
Hallo,
Jens, ich habe mir erlaubt in switch case ein falltrough einzubauen.
Sonst läuft mein Compiler Amok. :-)
Habs ausnahmsweise auf die gleiche Zeile geschrieben damit der Aufbau
optisch nicht unterbrochen wird.
Der Testsketch gibt am Ende eine seltsame Schlusszeile aus. Ich weiß
noch nicht ob es nur an der Formatierung liegt oder etwas anderes Schuld
ist.
1
Time:73ms1000
2
Time:77ms10000
3
Time:102ms100000
4
Time:124ms1000000
5
Time:163ms10000000
6
Time:166ms100000000
7
Time:200ms1000000000
8
Time:246ms10000000000
9
Time:273ms100000000000
10
Time:299ms1000000000000
11
Time:307ms10000000000000
12
Time:342ms100000000000000
13
Time:380ms1000000000000000
14
Time:419ms10000000000000000
15
Time:445ms100000000000000000
16
Time:484ms1000000000000000000
17
Time:537ms10000000000000000000
18
Time:825ms100000000000000000000
19
Time:851ms1000000000000000000000
20
Time:855ms10000000000000000000000
21
Time:879ms100000000000000000000000
22
Time:901ms1000000000000000000000000
23
Time:940ms10000000000000000000000000
24
Time:943ms100000000000000000000000000
25
Time:979ms1000000000000000000000000000
26
Time:1017ms10000000000000000000000000000
27
Time:342ms39600000000000000000000000000
Wofür ist die 96Bit Funktion genau? Beim Atmega ist doch mit 64Bit
Datentyp Schluss wenn ich mich nicht irre?
Im Testsketch kannste noch die includes von int96 und stdint weglassen,
inkludierste schon im Header.
Sind nur freundlich gemeinte Hinweise und Fragen zum Verständnis zum
drumherum.
Ansonsten Danke dafür. Dem "Vater" Arturo Martin-de-Nicolas natürlich
auch.
Wilhelm, dein Einwand mit to_string(i) ist zwar korrekt, nur ist string
mal wieder nicht standardmäßig vorhanden. Das alte Problem. :-)
Danke für den Optionshinweis.
Veit D. schrieb:> Hallo,>> Jens, ich habe mir erlaubt in switch case ein falltrough einzubauen.> Sonst läuft mein Compiler Amok. :-)
Der Hinweis kam schon vor mehr als 2 Jahren ;-)
s.a. Beitrag "Re: ItoA mit Uint64_t"> Wilhelm, dein Einwand mit to_string(i) ist zwar korrekt, nur ist string> mal wieder nicht standardmäßig vorhanden. Das alte Problem. :-)> Danke für den Optionshinweis.
Das bezog sich ja auch nur auf den Einwand mit dem std::stringstream
(vor mehr als 2 Jahren). Die heutige Antwort wäre std::to_chars bzw.
diese wäre eine Stelle, wo ich eben die cppstdlib nicht nachahme würde
sondern statisch dimensionierte Strings / StringBuffer einsetze (s.a.
mein Einwand von oben, dass es aus verschiedenen Gründen nicht sinnvoll
ist, die cppstdlib im small-embedded-Bereich einfach nur kopieren zu
wollen.
Wilhelm M. schrieb:> Veit D. schrieb:>> Hallo,>>>> wenn ich einzelne Teile der C++-Standard-Lib probieren möchte, in>> welchen Ordner der Toolchain müssen die Headerfiles einsortiert werden?>> Wo es Dir beliebt: die Option -I ist Dein Freund.
In dem Falle -isystem, da es System-Header sind.
Ein paar Header hatte ich mal angepasst, um initializer_list und
type_traits zu haben, die ganze STL oder gar libstdc++ ist es natürlich
nicht — ob das sinnvoll auf AVR wäre, sei dahingestellt. Die Header
sind von einem host-g++ v4.7 abgeleitet, also schon was älter.
Generell kann man sagen, dass die Portierung um so aufwändiger und
unangenehmer wird, je weiter man in Richtung low-level geht. Konkret:
Die libstc++-v3 dürfte leicht oder ganz ohne Aufwand zu portieren sein —
bis auf den Basis-Support der libsupc++ und "Feinheiten" im Compiler wie
Exception-Handling.
Ob das aktuelle nicht-Standard double (32-Bit) Probleme machen würde,
kann ich nicht sagen, dito für den eigenwilligen Ansatz der avr-libc,
float-Funktionen zu implementieren wie:
1
externdoublelog(double__x)__ATTR_CONST__;
2
#define logf log /**< The alias for log(). */
Wenn mal also eine Funktion / Template o.ä. mit logf verwenden will,
dann verwendet man ohne es zu merken die double-Version. Besonders
heimtückisch wenn man eine Klasse implementiert, die
double-Funktionalität liefert.
Der beste Weg ist m.E.
1
__ATTR_CONST__externdoublelog(double);
2
__ATTR_CONST__externfloatlogf(float)__asm("log");/**< The alias for log(). */
So dann man korrekte Identifier und Prototypen ohne extra Call-Overhead
hat. Bzw noch besser wäre
1
__ATTR_CONST__externfloatlogf(float);
2
__ATTR_CONST__externdoublelog(double)__asm("logf");/**< The alias for logf(). */
Die Umstellung des Compiler auf 64-Bit double ist hingegen leicht
machbar — beim Linken einer Applikation bekäme man einfach nur undefined
References vom Linker z.B. für __adddf3 (Addition) die man dann selbst
zur Verfügung stellen könnte.
GCC hat 2 unterschiedliche Implementationen für
Soft-Float/Double/LongDouble, ob die sinnvoll sind... würd ich eher auf
"wenig" plädieren.
Ich hab hier eine double-Implementierung in Assembler/C/C++ die soweit
gut funktioniert; ist allerding nur die Basis-Ausstattung
(Konvertierung, Vergleiche, +, -, *, /, floor, round, ceil, ldexp, sqrt,
log, exp). Wenn ich Zeit hab kommen als nächsten asin, acos und atan
und atan2.
A. B. schrieb:> Experten antworten manchmal auf einem Level, das eher abschreckt> als motiviert ...
Amen.
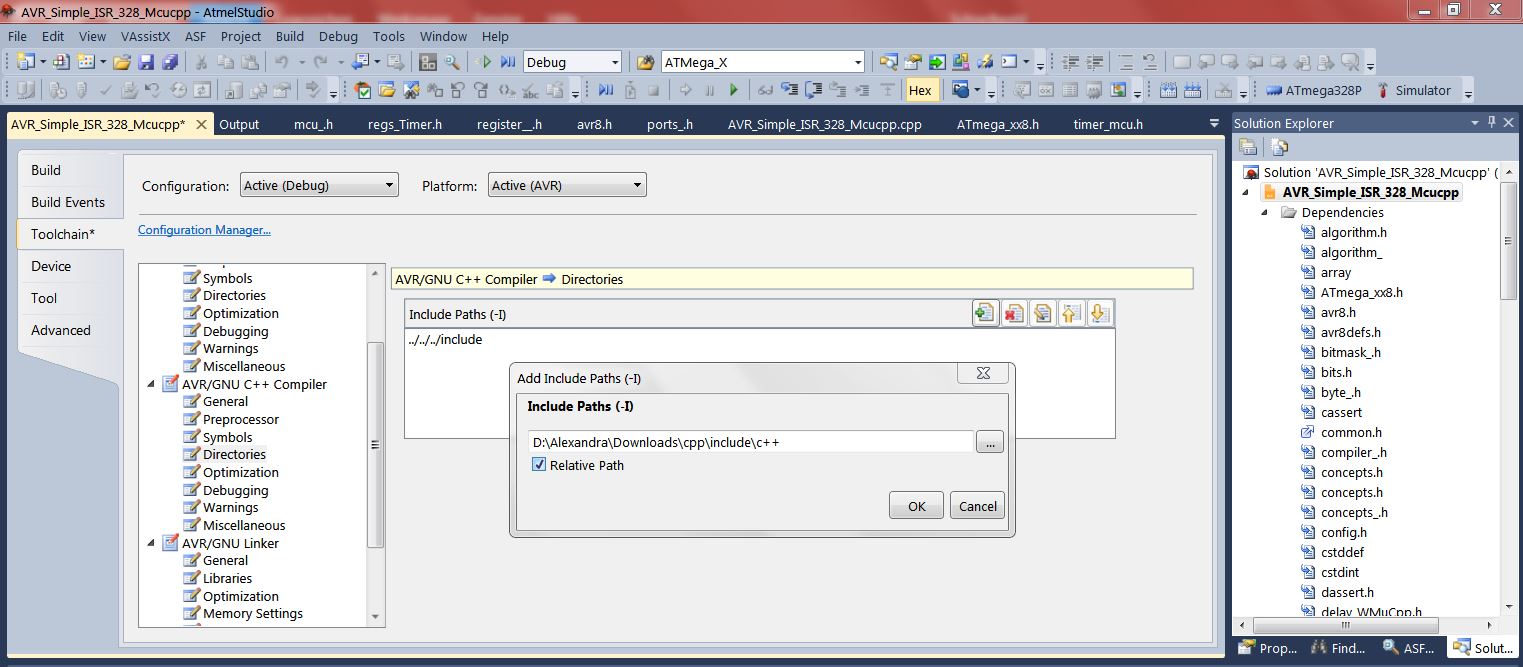
Hallo,
ich würde deine Lib gern ausprobieren. Stehe jedoch vor dem Problem,
dass ich nicht weiß wo ich den Eintrag in AS machen soll? Im Optionsfeld
-I funktioniert es nicht.
Es gibt keinen Grund, warum das nicht gehen sollte.
Ist ja c++ header only.
In | AS| SolutionExplorer(*) | Toolchain |AVR-GNU_c++_complier |
Directories |
mit dem Icon |+| einen neuen Pfad anlegen
mit dem Icon |...| Datei Explorer öffnen und den Include Pfad suchen und
eintragen.
(*) falls unsichtbar in VIEW sichtbar machen
Hallo,
Danke. Scheint zu funktionieren, es meckert nichts. :-)
Hatte bestimmt wieder irgendwas vermehrt.
Jetzt muss ich schauen was man damit so machen kann ...