Hallo,
ich versuche hier aus meinem Buch. Die Aufgabe.... Arbeiten mit C und H
dateien... nach zu vollziehen. Jetzt habe ich aber ein Problem, und
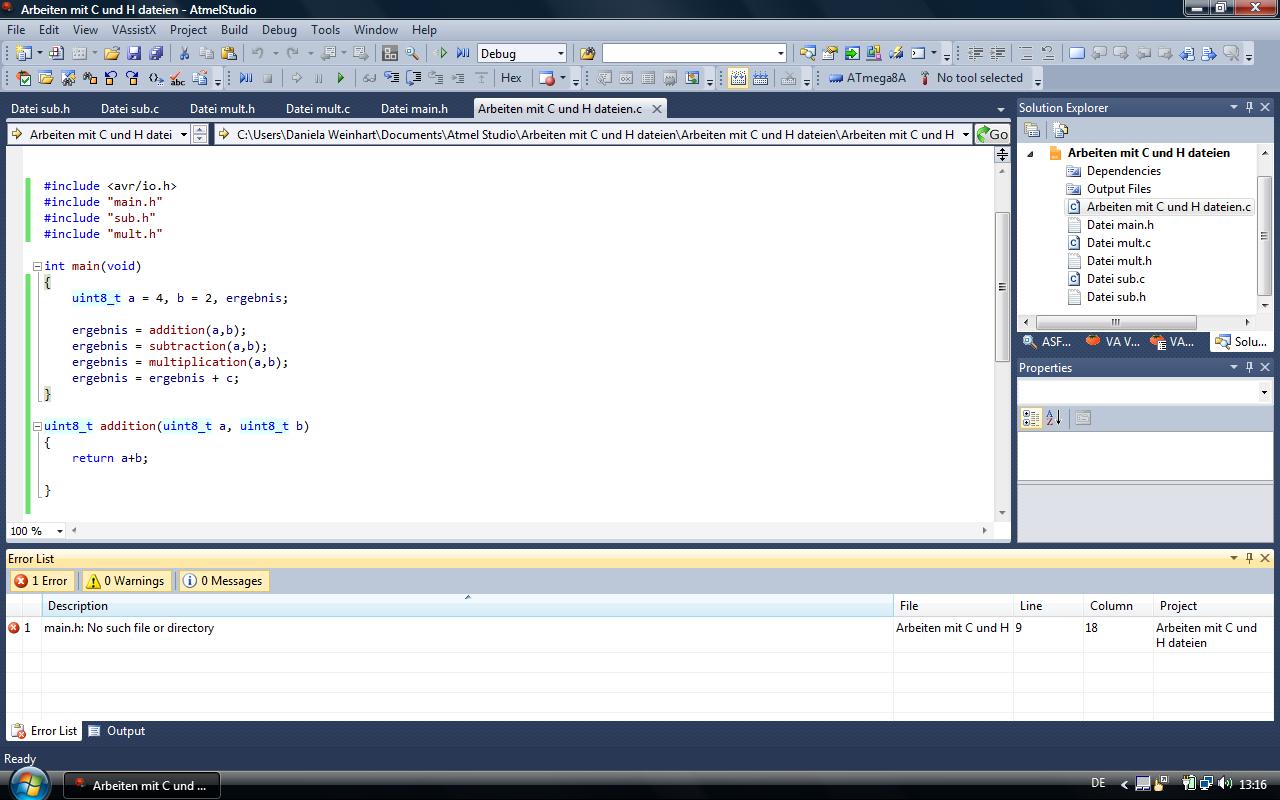
zwar, wenn ich das ganze compiliere kommt gleich ein Fehler (bild1)
und ich komme nicht darauf was ich da falsch mache. Ich habe die ganzen
C und H dateien Erstellt und abgespeichert. Und dann wie im (bild1) zu
sehen rechts im soloution expolorer geAdded.
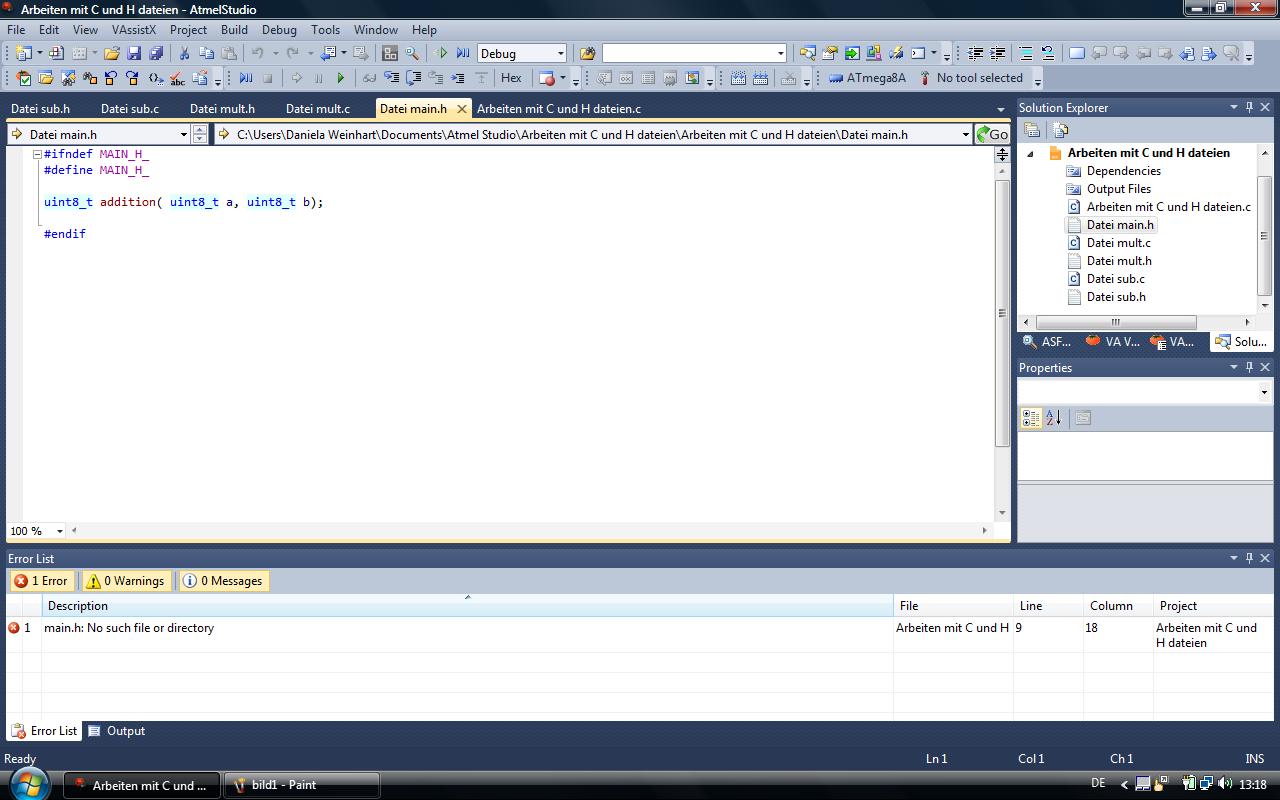
im (bild2) habe ich die main.h datei mal wie ich sie geschreieben
habe..Das müsste doch alles so stimmen ? könnte mir bitte jemand
weiterhelfen?
grüsse huber
Die Datei scheint nicht "main.h" sondern "Datei main.h" zu heißen.
Vielleicht fängst Du erstmal damit an die ganzen Ordnernamen und
Dateinamen in den Griff zu bekommen, und wenn Du schon dabei bist dann
ist es auch nützlich gleich mal dafür zu sorgen daß die Ordner-Namen und
Dateinamen kürzer werden und vor allen Dingen auch keine Leerzeichen
drin vorkommen, die Leerzeichen sind im besten Falle zu nichts nütze und
im schlechtesten Falle führen sie zu Fehlern in Tools die damit nicht
zurechtkommen.
Danke das war ein wertvoller Tipp. Somit hat sich das problem gleich
erledigt.
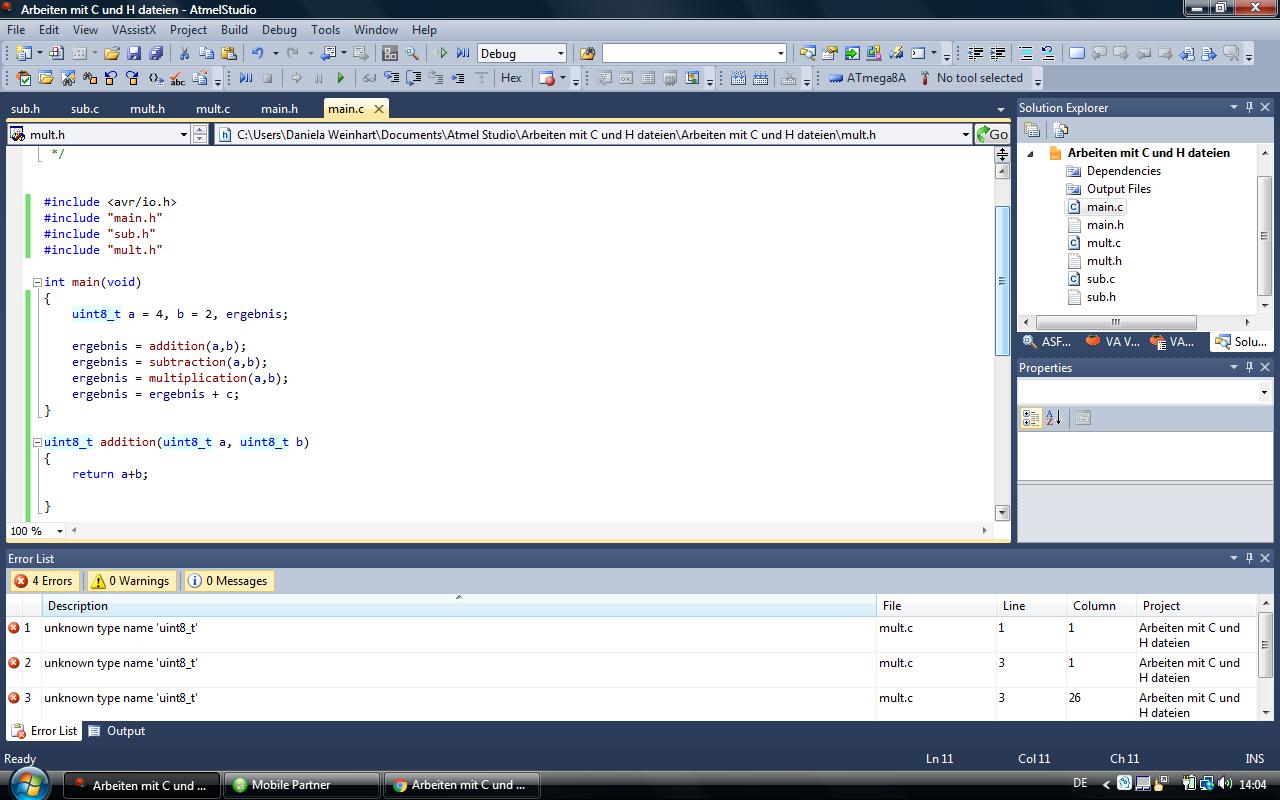
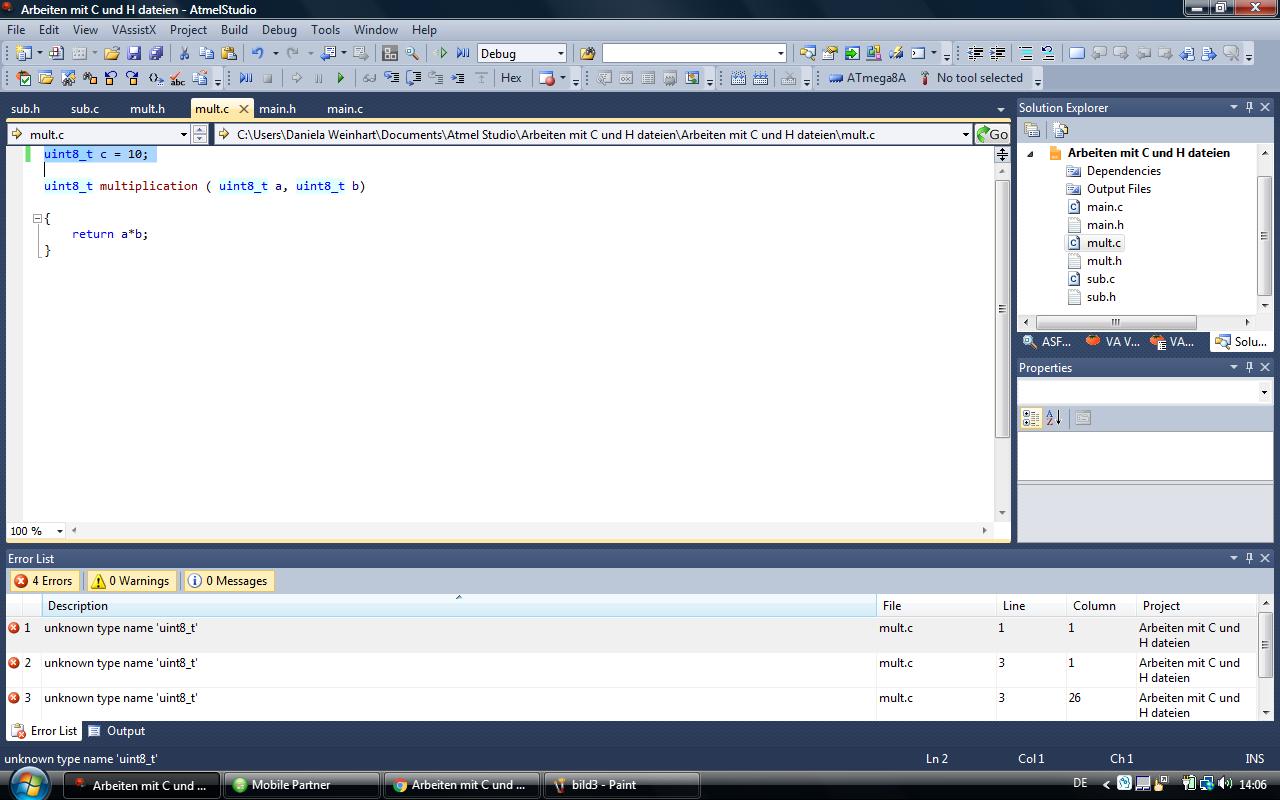
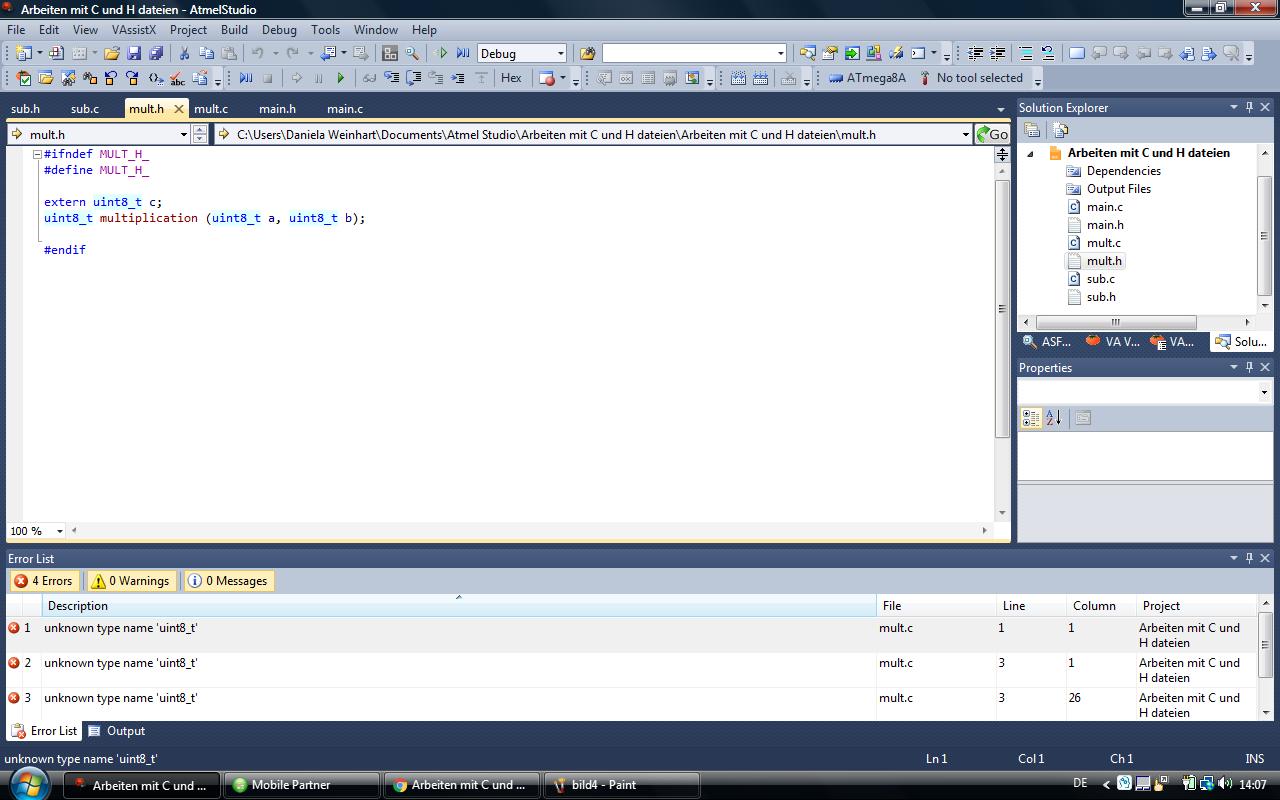
Jetzt kommt aber gleich noch ein problem(bild3), warum meckert er jetzt
bei den variablen uint8_t c = 10; zb. die habe ich ja auch noch mit
extern uint_t c;
deklariert, damit er sie überall erkennt. es scheint wohl alles mit
uint8_t nicht mehr zu stimmen
Timmo H. schrieb:> Steht da doch "unknown type..." du musst noch die stdint.h includen um> die typen zu benutzen
Ja das steht da. habe es probiert mit der stdint.h das ändert nichts.
Und die funktionieren ja sonst auch immer, auch ohne dieser stdint.h
datei.
Huber M. schrieb:> und einmal so #include <stdint.h>
so ist es richtig
Und in welchen Quell-File hast du es included? vermutlich nur in er
main.c. Das hilft aber z.B. noch lange nicht der mult.c und auch nicht
der mult.h, sofern du es nicht direkt vor dem include der mult.h gemacht
hast.
Ok das ist logisch, jetzt kommt kein fehler mehr, puh das kam jetzt die
letzten 0 - 100 seiten nicht vor mit der stdint.h . ich habe sie jetzt
in jeder C und H datei ganz oben eingebunden. Dann hat mir jetzt zweimal
der Präprozessor gemeckert ?
Huber M. schrieb:> ich habe sie jetzt in jeder C und H datei ganz oben eingebunden.
In die .h-Dateien musst Du sie nicht einbinden, wenn Du dafür sorgst,
daß Du in allen C-Dateien vorher die stdint.h einbindest.
Wenn Du sie aber in die .h-Dateien einbindest, brauchst Du sie in die
.c-Dateien nicht mehr einzubinden. Das wäre redundant.
Und ja: Lerne den Unterschied in der Bedeutung zwischen
#include "xxx"
und
#include <xxx>
Rufus Τ. F. schrieb:> Huber M. schrieb:>> ich habe sie jetzt in jeder C und H datei ganz oben eingebunden.>> In die .h-Dateien musst Du sie nicht einbinden, wenn Du dafür sorgst,> daß Du in allen C-Dateien vorher die stdint.h einbindest.
Abhängigkeiten von Include-Reihenfolgen sind zu vermeiden. Am
sinnvollsten ist es daher, sie in allem einzubinden, in dem der Typ
benutzt wird. Wobei ein .c-File sein dazugehöriges .h-File sowieso
sinnvollerweise immer inkludiert, also braucht man es in dem Fall nur in
einem der beiden Files zu tun.
Rufus Τ. F. schrieb:> In die .h-Dateien musst Du sie nicht einbinden, wenn Du dafür sorgst,> daß Du in allen C-Dateien vorher die stdint.h einbindest.
Das wäre schlechter Stil. Jeder Header sollte all das selbst
inkludieren was er benötigt, ein Header soll nicht voraussetzen daß er
nur in irgendeinem bestimmten Kontext inkludiert werden darf, er muss
vollkommen autark funktionieren.
Bernd K. schrieb:> Das wäre schlechter Stil.
Das ist eine Stilfrage. Es gibt die "jeder includiert
alles"-Philosophie, und es gibt das Gegenteil.
Letzteres hilft möglicherweise etwas besser beim Erkennen von
Abhängigkeiten.
Rufus Τ. F. schrieb:> Das ist eine Stilfrage. Es gibt die "jeder includiert> alles"-Philosophie
Im Realleben fängt man sich damit aber auch schon Krankheiten aller Art
ein. ;-)
Rufus Τ. F. schrieb:> Das ist eine Stilfrage. Es gibt die "jeder includiert> alles"-Philosophie, und es gibt das Gegenteil.
Nein, die mein ich nicht, das ist Chaos pur. Ich meine die "Jeder Header
includiert genau das war er braucht, nicht mehr und nicht weniger
Philosophie", damit geht einher daß es nun keine Rolle mehr spielt in
welcher Reihenfolge man die Header includiert und daß jeder header für
sich vollkommen autark betrachtet und verwendet werden kann weil er oben
alle seine Abhängigkeiten explizit erklärt.
Beispiel: Du verwendest Posix-Typen in Deinem Header? Dann includiert
der header stdint.h. Er verlässt sich nicht drauf daß das irgendwo
anders geschehen muss oder daß eine bestimmte Reihenfolge eingehalten
werden muss, denn die Abhängigkeiten "sortieren" sich bei dieser Methode
wie von Zauberhand selbst über die include guards.
Wir reden wohl aneinander vorbei. Du hast Dich auf eine Formulierung
von mir festgebissen, die ich als Option erwähnte.
Es ist natürlich sinnvoll, die "jeder Header includiert, was er
braucht"-Philosophie anzuwenden, aber um sie anwenden zu können, muss
der Benutzer erst mal verstehen, was er da macht - wie z.B. er
herausfinden kann, welche Header er denn wirklich für seine Headerdatei
braucht.
Ohne diese Fähigkeit, ohne dieses Verständnis wird wild alles, was
irgendwo nach *.h aussieht, irgendwo reingeklatscht. Und hier gibt es
oft noch viel elementarere Verständnisprobleme - im Sprachgebrauch viel
zu vieler Nutzer hier etabliert sich "lib" oder "library" als Synonym
für Headerdatei, was natürlich kompletter Blödsinn ist und bei der
Hilfesuche jedesmal zu Konfusion führt.
Und um eine Arbeitsphilosophie anzuwenden, ist es sinnvoll, sie zu
verstehen. Und das Verstehen entwickelt sich nicht aus dem
luftleeren Raum heraus, oder weil das in "nem Tut" drinstand, sondern
weil man das durch Ausprobieren und Betrachten der Resultate
nachvollziehen konnte.
Ansonsten, wenn man mit einem Compiler arbeitet, der das Konzept der
"präcompilierten Headerdateien" kennt, dann ist dafür die Einhaltung der
Include-Reihenfolge wichtig. Funktional ist sie bei sauberer Gestaltung
der Dateien mit entsprechenden Include-Guards nicht nötig, aber die
"präcompilierten Header" fallen dann als Mittel zur Beschleunigung des
Übersetzungsvorganges aus.
(Allerdings: Das ist kein Anfängerthema, wer begreifen will, wie
Headerdateien arbeiten, sollte von so einem Werkzeug die Finger lassen -
bei den Projektgrößen, mit denen da gearbeitet wird, ist das auch
komplett überflüssig)
Hallo,
mal wieder, also ich komme immer noch nicht klar mit den includen von h
und c Dateien. Bzw. das Grundprinzip ist mir schon einigermassen klar,
aber wie die hier im Anhang, die ich allerdings bekommen habe. Versuche
ich verzweifelt zu Verknüpfen. Denn hier kannte er die Bool Variablen
nicht die ich mit #include stdbool allerdings behoben habe, aber jetzt
erkennt er mir die Byte variablen nicht.
ich benutze das Atmel Studio 6.2 könnte mir vielleicht anhand des
Anhangs mal zeigen wie mann das richtig macht. Ich würde am liebsten
alle includes bei den includeguards nochmal raus Löschen und neu machen.
grüsse Huber
In jeder Datei (.c oder .h) in der du bool benutzt, muss das bool auch
bekannt sein
I.A. reicht da ein #include <stdbool> in der Datei aus.
byte ist keine Definition vom Standard. Die musst du also selber
definieren.
Das kann ein signed char oder unsigned char sein, je nachdem ob es ein
Vorzeichen hat.
Evtl sind int8_t bzw. uint8_t aus <stdint> besser.
Wenn du in tea56xx.c Funktionen aus i2c.c benutzt, die in i2c.h
deklariert sind, dann musst du in tea56xx.c auch i2c.h ber include
einbinden.
Und ein extern ist bei der Deklaration von Funktionen nicht nötig.
Huber M. schrieb:> mal wieder, also ich komme immer noch nicht klar mit den includen von h> und c Dateien. Bzw. das Grundprinzip ist mir schon einigermassen klar,> aber wie die hier im Anhang, die ich allerdings bekommen habe.
O je. Ich hatte wirklich nicht vermutet, daß du bereits mit den
Fundamenten des Ganzen derartige Probleme hast. Zunächst mal zieh dir
die StdTypes.h aus dem Anhang und guck sie dir an.
Das ist meine Typologie, die ich konsequent benutze, weil ich auch noch
anderes als bloß C-Programmieren zu tun habe. Guck ruhig auch mal in
deine "stdint.h" die sich irgendwo in deinen Compiler-Verzeichnissen
befindet. Dort wirst du sehen, daß dort der uint8_t auch bloß auf's
unsigned char heruntergebrochen wird, bevor der Compiler ihn zu fressen
kriegt. (ob das nun per #define oder per typedef passiert, ändert am
finalen unsigned char nix.)
Andere Leute mögen jetzt aufkreischen und schreiben, daß man doch
unbedingt ein uint8_t für's byte nehmen sollte, aber das ist mir zu
doof, schließlich fragst du deinen PC-Händler ja auch nicht, wieviel
Giga-uint8_t's der an RAM drinne hat. Vermutlich würde sich der Handler
an den Kopf fassen und dich ganz vorsichtig aus dem Laden befördern...
So und nun zum Verhältnis .c und .h etwas:
C-Quellen heißen für gewöhnlich "irgendwas.c". Aber normalerweise
klatscht man ja nicht alles und jedes in eine riesige "elefant.c",
sondern trennt die verschiedenen Programmteile in einzelne Quellen auf.
Nach welchen Gesichtspunkten ist erstmal egal, da gibt es
untershiedliche Geschmäcker.
Nun will man ja dann auch in einer Quelle mal auf Funktionen und
Variablen zugreifen, die in einer anderen Quelle stehen. Genau DAFÜR
sind die .h Dateien da. Man schreibt in so eine .h sogenannte
Prototypen, was hochtrabend klingt, aber ganz einfach ist: es ist eben
genau das, was man aus der betreffenden C-Quelle für andere Quellen
zugänglich machen will.
Steht nun in deiner Quelle ottokar.c etwa sowas:
int Egon;
void Joerg(int Hausnummer)
{......}
dann setzt man in die Headerdatei ottokar.h das Folgende hinein:
extern int Egon;
extern void Joerg(int Hausnummer);
und bindet diese Datei in alle anderen Quellen ein, die diesen Krempel
benötigen. Also z.B. in der Quelle karlheinz.c etwa so:
#include "ottokar.h"
und schon kann man in karlheinz.c die Funktion Joerg aufrufen. Merke,
daß mit #include schlichtweg der Inhalt der angegebenen Datei eingefügt
wird. Merke auch, daß bei "ottokar.h" der Compiler im Verzeichnis der .c
nach der Datei sucht, während er bei <ottokar.h> im Verzeichnis des
Compilers für die standardmäßigen Headerdateien suchen würde.
Ach ja: Auch in ottokar.c bindet man den selben Header ein, also so:
#include "ottokar.h"
int Egon;
void Joerg(int Hausnummer)
{......}
Der Zweck ist, daß es der Compiler merken kann, wenn sich zwischen der
.c und der .h eine Ungereimtheit eingeschlichen haben sollte.
Soweit klaro?
Du hattest in meinen Quellen erstmal die StdTypes.h rausgeschmissen,
weswegen der Compiler die Typen bool und byte nicht kennt und dich
angepfiffen hat. Ist logisch, gelle?
W.S.
W.S. schrieb:> Zunächst mal zieh dir> die StdTypes.h aus dem Anhang und guck sie dir an.
warum erfindest Du einen (zweitklassigen) Ersatz für die Standard-Header
stdint.h und stdbool.h?
Markus F. schrieb:> W.S. schrieb:>> Zunächst mal zieh dir>> die StdTypes.h aus dem Anhang und guck sie dir an.>> warum erfindest Du einen (zweitklassigen) Ersatz für die Standard-Header> stdint.h und stdbool.h?
Um ehrlich zu sein, finde ich den nicht nur zweitklassig. Ich würde
praktisch alles darin anders machen, als es dort gemacht ist - wenn der
Header nicht eh schon komplett überflüssig wäre. Das einzige, was C
nicht schon in besserer Form mitliefert, sind der T-Punkt und das
T-Rechteck - was auch immer die jetzt zu so grundlegenden Dingen macht,
dass sie auch in diesem Header stehen müssen.
Die Definition von "TRUE" als "1" ist zudem grob fahrlässig.
Dieser Header ist als wunderbares Negativbeispiel zu gebrauchen und
sollte nach Möglichkeit nirgends verwendet werden.
W.S. schrieb:> Andere Leute mögen jetzt aufkreischen und schreiben, daß man doch> unbedingt ein uint8_t für's byte nehmen sollte, aber das ist mir zu> doof,
Du siehst und argumentierst hier viel zu kurzsichtig. Intention der
stdint.h ist es, eine verlässliche Typenbreite für 8, 16, 32 und 64 Bit
zu bekommen. Für 8 Bit magst Du mit "unsigned char" in 99,9% aller Fälle
recht haben, aber das hier aus Deiner StdTypes.h:
1
#define integer short int
2
#define word unsigned short int
3
#define byte unsigned char
4
#define dword unsigned long
5
#define qword unsigned long long
6
#define int64 long long
ist höchst unportabel. Je nach Prozessor bekommst Du verschiedene
Typenbreiten heraus. Deine StdTypes.h verdient ihren Namen nicht.
Beispiel:
1
#include<stdio.h>
2
3
#define dword unsigned long
4
5
intmain()
6
{
7
printf("%ld\n",sizeof(dword));
8
return0;
9
}
Ergebnis auf 32-Bit-Linux:
1
$ cc a.c && ./a.out
2
4
Ergebnis auf 64-Bit-Linux:
1
$ cc a.c && ./a.out
2
8
Sinn und Zweck der echten stdint.h ist es, immer die richtige Typbreite
zu erhalten - unabhängig von der Zielplattform. Das kann Dein "Ersatz"
überhaupt nicht leisten.
Frage: Warum nimmst Du von Deinem Auto die passenden Reifen (stdint.h)
ab und montierst Holzräder (StdTypes.h)? Und warum machst Du auch noch
vehement Werbung für die Holzräder?
EDIT:
Wenn Du tatsächlich mit "byte", "word", "dword" usw. arbeiten willst,
weil Dir die Typen uint8_t, uint16_t usw. zu "doof" erscheinen, dann
schreibe doch in Deine StdTypes.h:
1
#include<stdint.h>
2
#define integer int16_t
3
#define word uint16_t
4
#define byte uint8_t
5
#define dword uint32_t
6
#define qword uint64_t
7
#define int64 int64_t
Damit wird auch Deine StdTypes.h portabel und Du musst die "doofen"
Typen nicht weiter im Quelltext benutzen.
Sehr interessant ist übrigens Dein Kommentar:
1
/* rausgenommen wegen Chan's FF
2
...
3
*/
Das lässt erkennen, dass Du mit Deinen selbstgefrickelten Typen bereits
mit Chans selbstgefrickelten Typen in einen Konflikt gelaufen bist. Mit
stdint.h wäre das nicht passiert.
Rolf M. schrieb:> Ich würde> praktisch alles darin anders machen
Ein echter W.S. halt. Wie immer gilt: Wenn man von allem das Gegenteil
tut, ist man zu 99.7% auf dem richtigen Weg.
Frank M. schrieb:> Sinn und Zweck der echten stdint.h ist es, immer die richtige Typbreite> zu erhalten - unabhängig von der Zielplattform. Das kann Dein "Ersatz"> überhaupt nicht leisten.
Das ist nicht der Punkt. Wenn man sich genügend bemüht, kann man auch
adäquaten Ersatz schreiben.
Der Punkt ist: wenn man (der Hase) auf einer neuen Plattform ankommt,
ist stdint.h (der Igel) immer schon da. Man kann nur verlieren.
Markus F. schrieb:> warum erfindest Du einen (zweitklassigen) Ersatz für die Standard-Header> stdint.h und stdbool.h?
Feuerzangenbowle: Weil ich zuerst dagewesen bin.
Mal im Ernst: Ich programmiere nun schon einige Jahrzehnte und meine
Standard-Typen, die ich eben auch in C verwende, sind älter als stdint
und sie sind umfassender. Ich sollte also eher die Frage stellen, warum
die C-Leute auf so einen Kruscht kommen anstatt sich an das zu halten,
was bereits seit langem üblich ist.
W.S.
Frank M. schrieb:> Du siehst und argumentierst hier viel zu kurzsichtig. Intention der> stdint.h ist es, eine verlässliche Typenbreite für 8, 16, 32 und 64 Bit> zu bekommen.
Hör zu, mein Lieber, höre mir mal GENAU zu!
Eine verläßliche Datenbreite hätte man als Normungsgremium allein
dadurch festlegen können, daß man eben die Grund-Datentypen int, long
usw. endlich mal wirklich für alle Compiler echt festlegt. Ist aber
nicht geschehen. Die Intention sehe ich sehr wohl, aber es ist ein für
die µC-Szene völlig unnützer Rohrkrepierer draus geworden.
Stattdessen hat man vor den C-Betonköpfen kapituliert, hat die
wabbeligen Festlegungen für die Compiler eben NICHT auf präzise
Bitgrößen festgenagelt und die Kapitulationsurkunde in Form einer
Header-Datei unterschrieben, die in keiner Weise ein Teil der
eigentlichen Toolchain ist, sondern eben nur ein Beiwerk, das
prinzipiell ein jeder sich nach seinem Gusto editieren könnte - so er
wollte.
Die bekannten "U8", "U16" und so weiter sind da nichts anderes und von
Dingen wie Endianness können wir mal ganz absehen, da ist der Horizont
derer, die hier sich wild aufführen, einfach zu klein. Ich habe genug
Motorola, Fujitsu, NEC und ARM zu gleicher Zeit unter den Fingern
gehabt, um zu wissen, was ich mit den diversen Integertypen tue oder
lieber bleiben lasse. Da ist auch eine <stdint.h> nicht wirklich
hilfreich.
Kurzum, es ist da bei C99 ein Haufen heißer Luft entstanden, der
lediglich zu unleserlichen Bezeichnungen geführt hat, aber das
Kernproblem überhaupt nicht tangiert. Schaumschlägerei.
Also laß diese unnütze Diskussion. Ich habe aus gutem Grunde dies
bereits weiter oben dediziert geschrieben.
Meinen Code wird garantiert niemand auf einem 64 Bit Linux einsetzen
wollen und ein Stück Code, was für einen µC geschrieben wurde, hat auch
niemals den Anspruch, in einer dafür völlig ungeeigneten Umgebung
eingesetzt zu werden - also ist diese Argumentation überflüssig.
Nochmal im Klartext: Wir reden hier in diesem Forum nicht über 64 Bit
Linux, sondern über Mikrocontroller - und zwar solche von der eher
kleineren Sorte, also keine aus der Riege a la 64Bit-Cortexe oder
64Bit-MIPSe.
Dieses Abschweifen ist in diesem Thread ohnehin völlig überflüssig, denn
hier geht es um was ganz anderes. Also!!
Und nun solltet ihr euch lieber den Nöten des TO zuwenden, das wäre
insgesamt hilfreicher. Immerhin will er sein Radio in Gang kriegen - und
das hängt nicht von der Verwendung von <stdint.h> ab, sondern von ganz
anderen Verständnisproblemen, wie z.B. dem Verständnis von .h Dateien.
W.S.
Nochwas:
Frank M. schrieb:> Das lässt erkennen, dass Du mit Deinen selbstgefrickelten Typen bereits> mit Chans selbstgefrickelten Typen in einen Konflikt gelaufen bist. Mit> stdint.h wäre das nicht passiert.
Das hast du grandios MISSVERSTANDEN.
Diese Datentypen sind bei mir in exakt gleicher Weise wie bei Chan
deklariert, aber da ich dessen exakt gleichlautende #defines nicht aus
seinen Quellen herauslöschen wollte, habe ich sie bei mir
auskommentiert. Du wirst - hoffentlich - verstehen, was passiert, wenn
man zwei gleichlautende #define's für denselben Datentyp im Code hat.
Klaro jetzt?
W.S. schrieb:> Feuerzangenbowle: Weil ich zuerst dagewesen bin.
Dann wäre langsam der Zeitpunkt gekommen, deine StdTypes.h auf die
moderneren Typen umzustricken. Alternativ kannst du auch deinen Code auf
Typnamen umstricken, die nicht schon seit Windows 95 inhaltlich falsch
sind.
Wenn du das nicht willst, dann bitte veröffentliche das nie wieder.
W.S. schrieb:> Du wirst - hoffentlich - verstehen, was passiert, wenn> man zwei gleichlautende #define's für denselben Datentyp im Code hat.
Wenn sie exakt gleich sind, akzeptiert gcc das.
W.S. schrieb:> Feuerzangenbowle: Weil ich zuerst dagewesen bin.>> Mal im Ernst: Ich programmiere nun schon einige Jahrzehnte und meine> Standard-Typen, die ich eben auch in C verwende, sind älter als stdint> und sie sind umfassender. Ich sollte also eher die Frage stellen, warum> die C-Leute auf so einen Kruscht kommen anstatt sich an das zu halten,> was bereits seit langem üblich ist.
Vielleicht einfach deswegen, weil "die C-Leute" im
Standardisierungsgremium sitzen und Du nicht?
Wenn Du unbedingt deine eigenen Typen haben willst, spricht ja überhaupt
nichts dagegen, die auf Grundlage der stdint.h neu zu definieren anstatt
den alten Schrott weiter mit sich rumzuschleppen (und ihn auch noch in
Foren als den Stein der Weisen zu verkaufen).
Man kann immer auf C schimpfen (was Du ja regelmäßig und anscheinend mit
Genuß tust), aber dann sollte man nach meiner Meinung vernünftige
Verbesserungen im Standard auch annehmen, wenn sie denn mal kommen.
W.S. schrieb:> Meinen Code wird garantiert niemand auf einem 64 Bit Linux einsetzen> wollen
Das mit dem 64-Bit-Linux war lediglich ein Beispiel. Du meinst also,
dass bei 32 Bit bei den µCs bereits Schluss ist? Da sollte man durchaus
weitsichtiger sein.
Was gefällt Dir denn nicht an uint16_t? Da weiß ich auf den ersten
Blick, dass es sich um 16 Bit handelt. Bei "word" oder "dword" muss ich
zweimal nachdenken. Und witzigerweise schreibst Du dann in Deiner
StdTypes.h selbst "int64". Sollte das nicht konsequenter dann "qword"
heißen? Oder besser noch "sqword" - für "signed quad word". Aber Moment,
da muss man erstmal rechnen:
sqword = signed quad word = 4 x 2 Bytes = 8 Bytes
Uff, da kann man schon mal beim Lesen eines Quellcodes ins Schwitzen
kommen. Gut, dass Du auf "qword" verzichtet hast. Jedoch führst Du mit
der Verwendung von "int64" statt "qword" bzw. "sqword" Dein eigenes
System ad absurdum. ;-)
W.S. schrieb:> Du wirst - hoffentlich - verstehen, was passiert, wenn> man zwei gleichlautende #define's für denselben Datentyp im Code hat.
Gar nichts.
1
#define dword unsigned long
2
#define dword unsigned long
3
#define dword unsigned long
4
#define dword unsigned long
5
#define dword unsigned long
6
#define dword unsigned long
7
8
intmain()
9
{
10
printf("%u\n",sizeof(dword));
11
return0;
12
}
1
$ cc -Wall -Wextra a.c && ./a.out
2
8
Kein Fehler, keine Warnung.
> Klaro jetzt?
Ich verstehe Deine Betonkopfhaltung durchaus. Ich selbst programmiere in
C seit 1984, habe auch ziemlich viele C-Compiler erlebt - gute wie
schlechte. Trotzdem sollte man bestimmte Innovationen auch als älterer
Mensch durchaus akzeptieren. Ja, ich bin auch ein alter Knochen, aber
stdint.h ist gerade für die µC-Programmierung ein gewaltiger
Fortschritt, den man nicht ablehnen sollte. Da kann man durchaus auch
mal selbstgefrickelte Datentypen über Bord werfen. Den Schritt habe ich
bereits vor Jahren gemacht. Und darüber bin ich froh.
W.S. schrieb:> Eine verläßliche Datenbreite hätte man als Normungsgremium allein> dadurch festlegen können, daß man eben die Grund-Datentypen int, long> usw. endlich mal wirklich für alle Compiler echt festlegt.
Nein, das wäre fatal gewesen. Dennis Ritchie war damals bereits in den
70er Jahren sehr weitsichtig, als er den Datentyp "int" als die
natürliche Datenbreite des verwendeten Prozessors definierte und sich
NICHT auf eine feste Datenbreite festlegte.
Sonst hätten nämlich im Laufe der Zeit sämtliche C-Programme und
C-Bibliotheken, die jemals entwickelt wurden, immer wieder umgeschrieben
werden müssen, um die Datentypen an die Entwicklung der Hardware
anzupassen. Das wäre ein nicht vertretbarer Aufwand gewesen. Als damals
die PDP11, auf der Unix (und damit auch C) entwickelt wurde, durch
32-Bit-Maschinen abgelöst wurden, musste der Typ "int" einfach an die
Datenbreite des Prozessors angepasst werden und schon liefen alle
C-Programme und Bibliotheken weiter! Dasselbe geschah beim Wechsel auf
64 Bit. Genau diese variable Definition damals vor über 40 Jahren hat C
das Überleben gesichert.
Weitsichtig denken lohnt sich. Nichts vergeht schneller als die aktuelle
Computertechnologie.
Frank M. schrieb:> Was gefällt Dir denn nicht an uint16_t? Da weiß ich auf den ersten> Blick, dass es sich um 16 Bit handelt. Bei "word" oder "dword" muss ich> zweimal nachdenken. Und witzigerweise schreibst Du dann in Deiner> StdTypes.h selbst "int64". Sollte das nicht konsequenter dann "qword"> heißen? Oder besser noch "sqword" - für "signed quad word". Aber Moment,> da muss man erstmal rechnen:
Nö, da brauchst du nix zu rechnen.
Ich bin am PC hauptsächlich mit Pascal in diversen Schattierungen
unterwegs und dort sind für vorzeichenlose Int's eben byte, word, dword,
qword die Mode (auch smallword, wenn man es dedizierter festlegen will)
und für vorzeichehaltiges hat es integer, longint und int64.
Das sind dem Compiler eingebaute Typen, sie bedürfen also keinerlei
Benennerei durch einen selbst, wie das hier bei C mit Headerdateien
gemacht wird, die derartige Zweitbenennungen a la typedef beinhalten.
Ich bin es gewohnt, mit ganz anderen Dingen umzugehen, z.B, daß ein char
durchaus nicht immer 8 Bit umfaßt, sondern heutzutage eben 16 Bit und
daß man be Bedarf an einem 8 Bit char eben einen ansichar nehmen muß.
Ebenso, daß man eben nicht char's mit integertypen
durcheinanderpurzeln lassen kann.
Und dieses intxy_t Getue trifft auch nicht die echten Probleme. Mir
reicht es völlig aus, daß ein simpler int mir benutzbare 16 Bit und ein
long benutzbare 32 Bit garantiert. Das reicht. Für alles Weiter sind
ganz andere Sachen zu bedenken: Alignment und Endianness zuvörderst. Was
meinst du, weswegen ich die 16 Bit Offsets in meinen Fonts byteweise
organisiert habe? Eben, weil die Fonts sich sowohl auf FR als auch auf
ARM benutzen lassen müssen. Bei beiden würde mir das erforderliche
Alignement auf die Füße fallen und obendrein haben FR und ARM
unterschiedliche Endianness.
W.S.
W.S. schrieb:> Mir> reicht es völlig aus, daß ein simpler int mir benutzbare 16 Bit und ein> long benutzbare 32 Bit garantiert.
Wie ich oben
Beitrag "Re: Arbeiten mit C und H Dateien"
in meiner zweiten Antwort darlegte, führt eine starre Festlegung der
Basisdatentypen von int, long usw. in eine Sackgasse. Es mag sein, dass
Dir es völlig ausreicht, weil Du viel zu kurzsichtig denkst, d.h. nur
ein oder zwei Jährchen voraus.
Stell Dir mal vor, die C-Bibliotheksfunktion fseek() würde auch heute
noch lediglich 32 Bit für die Positionangabe innerhalb einer Datei
akzeptieren - wie vor 40 Jahren. Dann könntest Du heutzutage nur noch
Filme in HD schauen, die gerade mal ein paar Minuten lang sind.
Die Nicht-Festlegung der Datenbreite von int, long usw. hat dafür
gesorgt, dass man vor 40 Jahren bereits Programme in C erstellen konnte,
die heute noch vernünftig laufen - auch mit Dateien, die nicht mehr
einige KB, sondern viele GB groß sind. Die Stärke von C ist
Portabilität. Nur diese hat dafür gesorgt, dass C bereits seit über 40
Jahren existiert.
W.S. schrieb:> Bitgrößen festgenagelt und die Kapitulationsurkunde in Form einer> Header-Datei unterschrieben, die in keiner Weise ein Teil der> eigentlichen Toolchain ist,
Es bleibt ein Rätsel, warum du nicht begreifen willst, dass das Unsinn
ist. Die ist genauso Teil der Toolchain wie alle anderen
Standard-Header. Es hätte keinen, absolut KEINEN Vorteil gehabt, diese
Namen zu Schlüsselwörtern zu machen. Im Gegenzug dazu ist dein Header
tatsächlich überhaupt nicht Teil der Toolchain.
> sondern eben nur ein Beiwerk, das prinzipiell ein jeder sich nach seinem> Gusto editieren könnte - so er wollte.
Äh, ja, das könnte man wohl, so wie auch jeder den Header stdio.h oder
math.h editieren könnte. Oder man könnte sich je nach Compiler dessen
Quellcode runterladen und kaputt-editieren. Nur: Warum in aller Welt
sollte man das tun wollen?
Du hast insofern recht, dass stdint.h keine Möglichkeit vorsieht, um
Sabotage an der Toolchain zu verhindern. Das gilt aber für den Rest von
C (und so ziemlich jeder anderen Sprache) ganz genauso.
> Kurzum, es ist da bei C99 ein Haufen heißer Luft entstanden, der> lediglich zu unleserlichen Bezeichnungen geführt hat, aber das> Kernproblem überhaupt nicht tangiert. Schaumschlägerei.
Was ist denn an int16_t für einen 16-Bit-Integer unleserlich? Das folgt
einem einheitlichen Namensschema. intX_t für einen vorzeichenbehafteten
Integer mit X Bit, uintX_t für das gleiche ohne Vorzeichen. Bei diesem
tollen StdTypes-Header muss ich für einen vorzeichenbehafteten
16-Bit-Integer den enorm aussagekräftigen Namen "integer" nutzen. Das
gleiche ohne Vorzeichen heißt dann auf einmal völlig anders, nämlich
"word", was sowieso eine schlechte Wahl ist, da dessen Bedeutung
Prozessor-abhängig ist (Bei x86 z.B. ist damit normalweise 16 Bit
gemeint, bei ARM dagegen 32 Bit). Einen vorzeichenbehafteten 32-Bit-Typ
gibt es gar nicht. Bei 64 Bit heißt der Typ mit Vorzeichen int64, der
ohne qword. Was ist denn das für ein bescheuertes Namensschema?
Über den Sinn bzw. Unsinn der Definition eines selbstgefrickelten bool
statt eines auch richtig funktionierenden bool über stdbool.h wurde ja
schon eingegangen.
> Meinen Code wird garantiert niemand auf einem 64 Bit Linux einsetzen> wollen und ein Stück Code, was für einen µC geschrieben wurde, hat auch> niemals den Anspruch, in einer dafür völlig ungeeigneten Umgebung> eingesetzt zu werden - also ist diese Argumentation überflüssig.
Nun, ich teste derweil Algorithmen erstmal auf meinem PC mit
64-Bit-Linux, bevor ich sie in meinen AVR-Code einbinde, weil das viel
einfacher ist als das Programm immer erst draufzubraten und dann dort
auszuprobieren. Wenn man es richtig macht, ist das gar nicht so schwer.
Es gibt sicher Fallstricke, aber das ist mit etwas Erfahrung handhabbar.
Übrigens ist selbst dieser Unsinn bereits von einem Standard-Header
abgedeckt:
1
/* Mist, den ich mir sowieso nicht merken kann */
2
#define MOD %
3
#define XOR ^
4
#define NOT ~
5
#define AND &
6
#define OR |
Aber vermutlich hast du da auch Angst, dass dir jemand den heimlich
verändert.