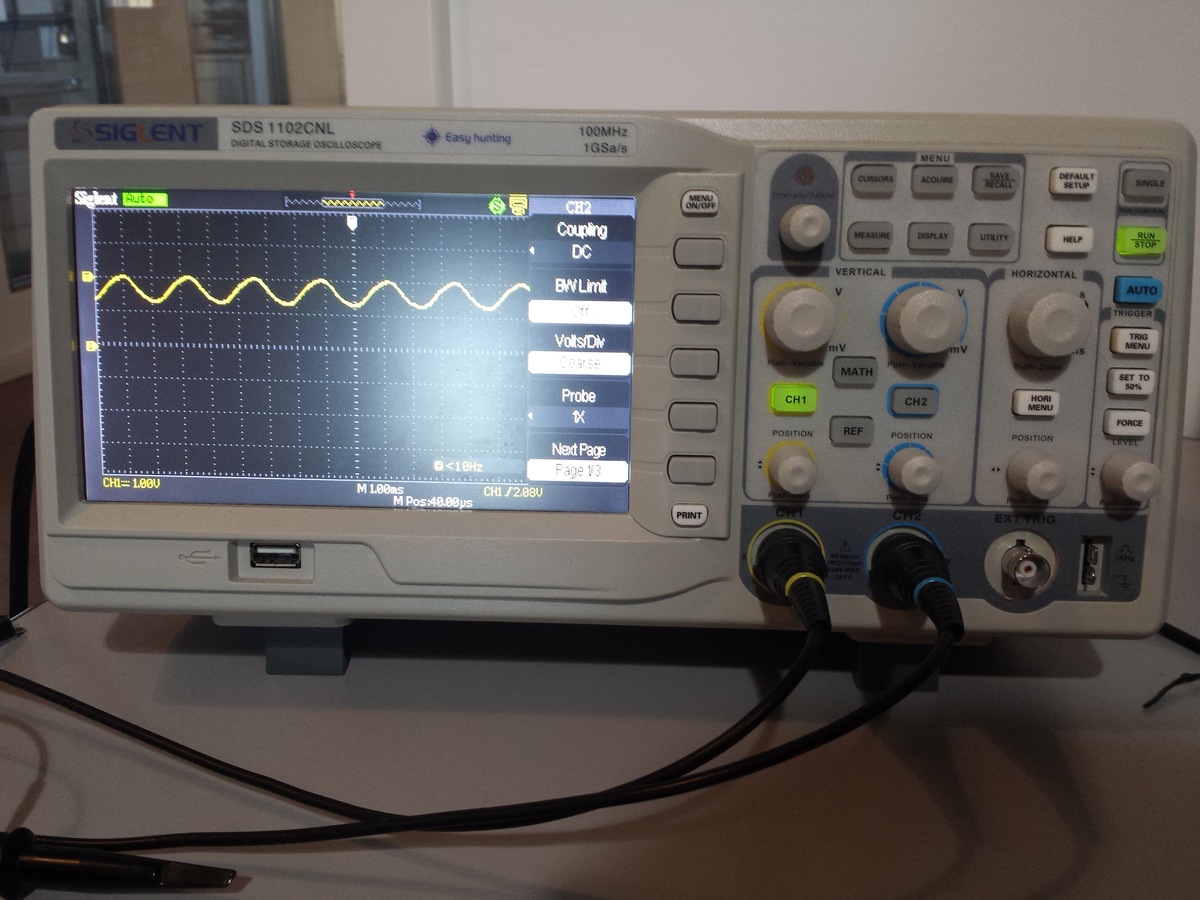
Hallo Zusammen :=) Bin kürzlich neu eingestiegen mit dem Konfigurieren von FPGAs in VHDL. Mein Einsteigerboard: Arty - Artix 7 -xc7a35tcsg324-1 Entwicklungsumgebung: Vivado 2016.4 Nun habe ich einige Einsteigerkurse(Video und Lehrbuch) durchgearbeitet und sitze momentan fest. Mein Ziel ist es das Mikrofon ADMP441 mit der I2S Schnittstelle auszulesen, finde aber keinen richtigen Einstieg/Ansatz dafür. Eine Datenverbindung vom Board zum PC via Ethernet konnte ich bereits mit dem Code von Hamsterworks aufbauen. Versuche: Habe die Takte WS und SCK erzeugt und an 2 Ausgänge geschaltet. Oszilloskop zeigt Rauschen auf +2V Offset an. Falls einer mal was in der Richtung I2S und FPGA in VHDL gemacht hat, würde mich sehr über Tipps freuen :) Habe zwar Code zu I2S auf Opencores und anderen Seiten gefunden, aber konnte nicht viel damit anfangen.
Waldi3141 schrieb: > Habe die Takte WS und SCK erzeugt und an 2 Ausgänge geschaltet. > Oszilloskop zeigt Rauschen auf +2V Offset an. Du misst offenbar einen offenen CMOS-Eingang. Kannst du diese 2V mit einem 10k Widerstand auf GND oder 3V3 ziehen? Falls ja, dann hat vermutlich was mit der Pinzuordnung nicht geklappt.
HI , danke für die Antwort, In Vivado habe ich mit dem Clock Wizard testweise ein 50 MHz Clock erzeugt und einfach an PIN U12 Header JC geschaltet mittels Constraint-File. Dieses Rauschen ist tatsächlich eine Sinusschwingung mit +2V offset. Habe das jetzt getestet, nein ich kann dieses Signal (was eigentlich 50 MHz sein sollten) nicht mit einem 10K Widerstand auf GND noch auf VCC ziehen.
Waldi3141 schrieb: > Dieses Rauschen ist tatsächlich eine Sinusschwingung mit +2V offset. Zeig mal ein Bild davon. BTW: welche analoge Bandbreite hat denn dein Oszi? Denn zum halbwegs rechteckigen Darstellen eines rechteckigen 50MHz Signals brauchst du mindestens 350MHz analoge Bandbreite und eine entsprechend schnelle Abtastung...
Angehängte Dateien:
-

20170213_154840.jpg
240 KB
100MHz - Bandbreite Dazu sei gesagt, dass ich auch versucht habe immer geringere Output Clocks zu erzeugen und ab 3Mhz wurde das signal langsam zum Taktsignal (also rechteckig) Siehe Bild zum 50Mhz Takt
Waldi3141 schrieb: > 100MHz - Bandbreite Bei einer x1 Probe. Da sieht das Signal doch noch ganz gut aus. > Dazu sei gesagt, dass ich auch versucht habe immer geringere Output > Clocks zu erzeugen und ab 3Mhz wurde das signal langsam zum Taktsignal > (also rechteckig) Nimm mal x10 Tastköpfe, du belastet den Pin mit den x1 Probes kapazitiv ziemlich stark... > Siehe Bild Ähm, das Ding kann doch Screenshots, oder nicht?
Angehängte Dateien:
-

20170213_162321.jpg
240 KB -

20170213_162109.jpg
240 KB
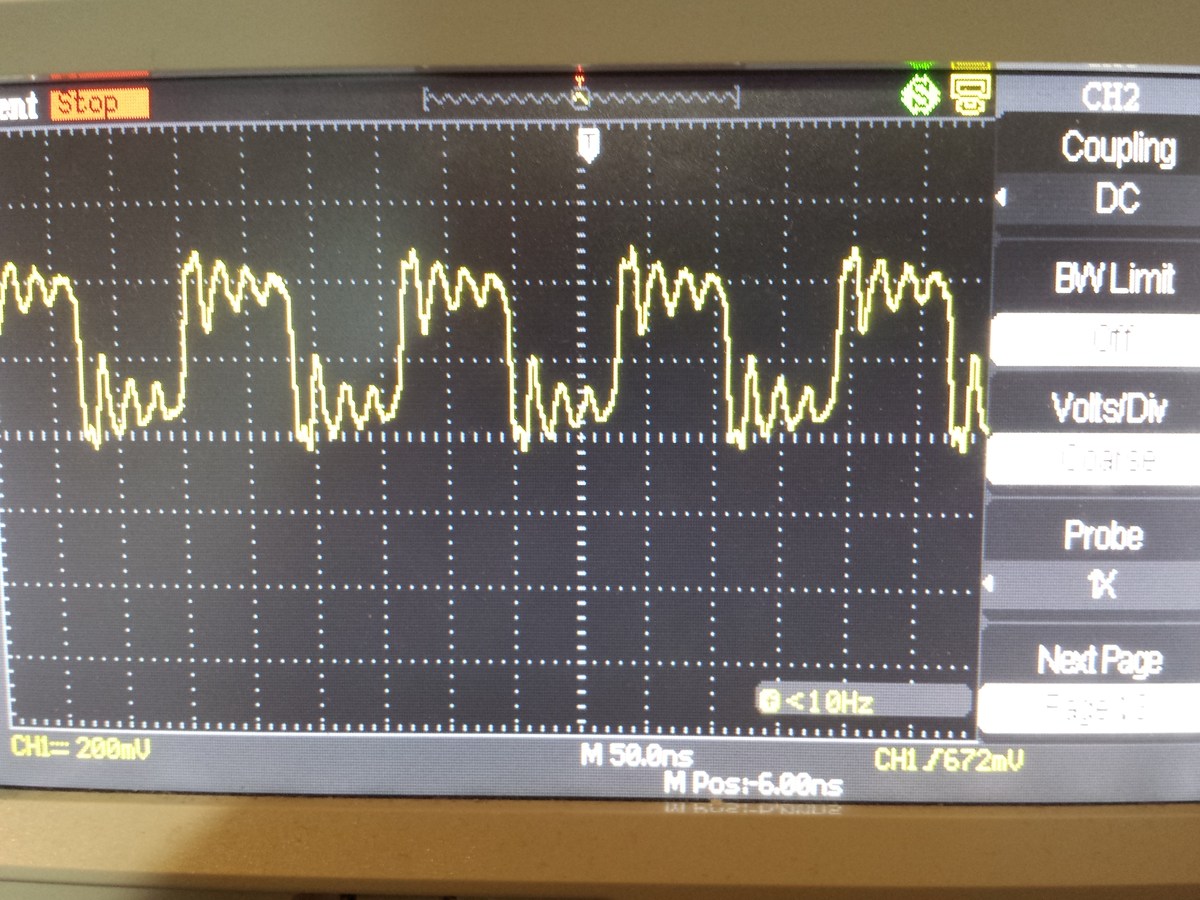
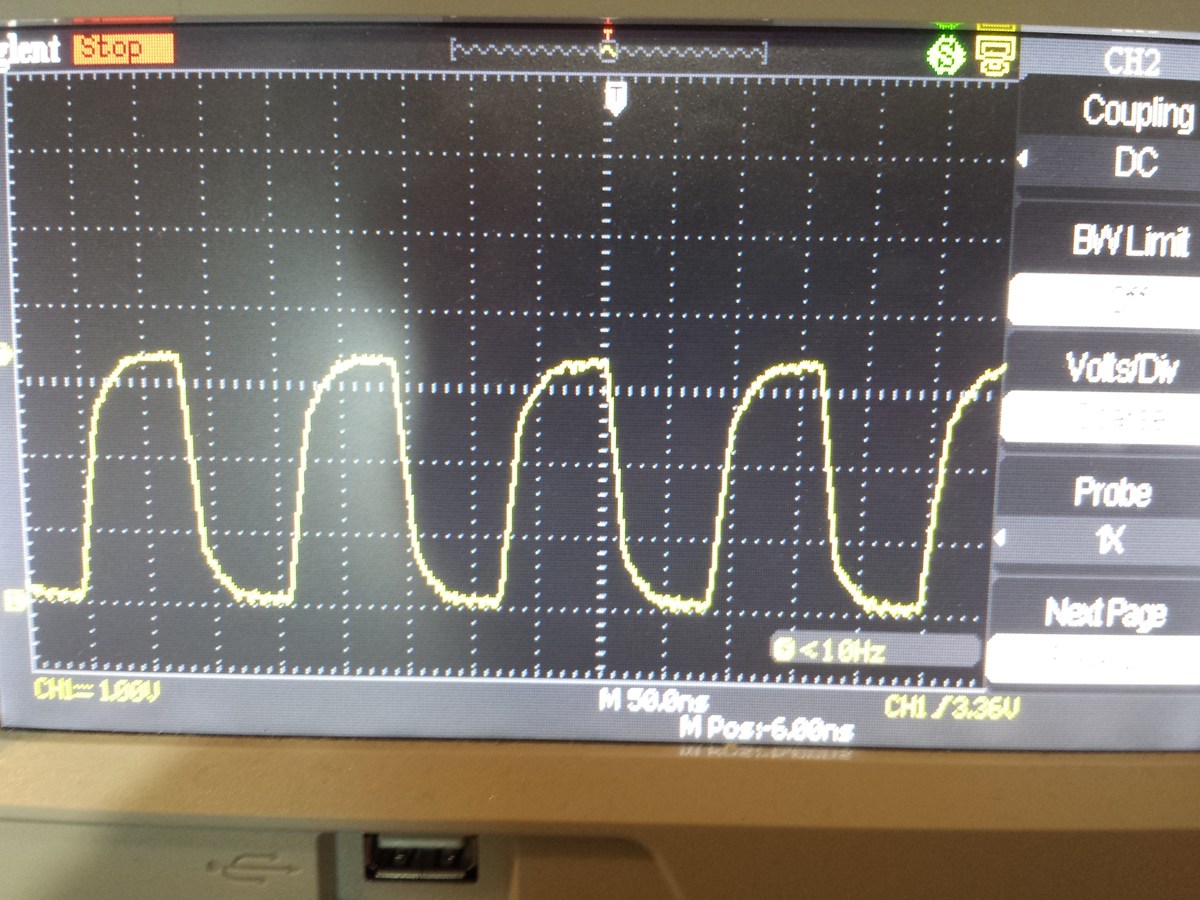
>Nimm mal x10 Tastköpfe, du belastet den Pin mit den x1 Probes kapazitiv ziemlich stark... Ich habe jetzt mal ein 6,144 MHZ Takt mit dem Clock Wizard erzeugt Bild 1 mit 1x Tastkopf , Bild 2 mit 10x sieht eigentlich, besser aus :)... aber weiß nicht ob die Rundungen jetzt am FPGA-Board liegen oder ich meinem Oszi nicht mehr trauen darf :S >Ähm, das Ding kann doch Screenshots, oder nicht? Doch das kann auch Screenshots aber habe gerade kein USB Stick zur Hand.
Seite 9 im Datenblatt zeigt doch sehr schön wie man die Samplewerte aus dem Stein herausbekommt. Das lässt sich auch prima simulieren.
:D ich bedanke mich jetzt erst mal, verstehe nicht warum ich vorher ein viel stärkeres Rauschen hatte, auch bei niedrigeren Frequenzen, aber die Taktraten 3,072 Mhz und 48KHz sehen jetzt zumindest gut aus. Auch bei x1 Tastkopf
Waldi3141 schrieb: > :D ich bedanke mich jetzt erst mal, > verstehe nicht warum ich vorher ein viel stärkeres Rauschen hatte, auch > bei niedrigeren Frequenzen, aber die Taktraten 3,072 Mhz und 48KHz sehen > jetzt zumindest gut aus. Auch bei x1 Tastkopf Ich habe festgestellt, dass bei meiner FPGA IDE (Quartus II) manchmal doppeltes Compilieren/Synthetisieren nötig war, bis das das Ergebnis gestimmt hat. Ich habe da verschiedene Vermutungen, die aber nicht stimmen müssen. Evtl. liegt evtl. darin, in welcher Reihenfolge die VHDL-Dateien kompiliert werden, die aufeinander verweisen und dass bei der ersten Runde ggf. alte Versionen von Komponenten landen die in Dateien referenziert werden, die kompiliert werden, bevor diese Komponenten mit dem Kompilieren dran sind. Ein Grund dafür könnte auch sein, dass der Optimierer teilweise zufällig arbeitet und ein falsch optimiertes Timing zu einer Fehlfunktion führen kann - normalerweise sollte sowas aber nur externe Pins betreffen, falls man die Timing Constraints nicht oder nicht richtig konfiguriert hat. Wie auch immer: Wenn was nicht funktioniert, wie man vermutet und es die Zeit erlaubt: am besten nochmal kompilieren und schauen, obs evtl. dann geht... sicher ist sicher!
Das kenne ich so aber nicht. Ist das bei den neueren Versionen so? So ein Verhalten (Nutzung von altem Müll) kannte ich bisher nur von den früheren ISE-Versionen. Dort musste man regelmässig die files löschen um Unfug zu verhindern. Hat sich Altera da etwa angeglichen?
Stefan K. schrieb: > Wie auch immer: Wenn was nicht funktioniert, wie man vermutet und es die > Zeit erlaubt: am besten nochmal kompilieren und schauen, obs evtl. dann > geht... sicher ist sicher! Das kann ich so erstmal nicht glauben, es gibt aber ein aehnliches "Phaenomen". Zumindest bei Xilinx ist es so, dass der Random Seed fuer die Logik Platzierung ueber das Design berechnet wird. Bei gleichen Design gilt daher: gleicher Seed und damit ist auch das Resultat immer das gleiche. Wenn ich jetzt jedoch kleine Aenderungen habe, z.B. Signalumbenennung, fuehrt das dazu, dass ein neuer Seed generiert wird und allen damit verbundenen Timing Konsequenzen.
Tobias B. schrieb: > Wenn ich jetzt jedoch kleine Aenderungen habe, z.B. Signalumbenennung, > fuehrt das dazu, dass ein neuer Seed generiert wird und allen damit > verbundenen Timing Konsequenzen. Das ist ja eigentlich logisch, bedingt aber nicht, dass damit einmal gute und einmal schlechte Ergebnisse erzielt werden und das scheint das Problem des TE zu sein.
M. W. schrieb: > Das ist ja eigentlich logisch, bedingt aber nicht, dass damit einmal > gute und einmal schlechte Ergebnisse erzielt werden und das scheint das > Problem des TE zu sein. Der Punkt den ich Nahe legen wollte ist, dass es keine "guten" oder "schlechte" Ergebnisse gibt. Sondern nur "erfuellen meine Anforderungen" oder "erfuellen meine Anforderungen nicht". Und wenn man das Gefuehl hat, es ist eine Art Voodoo im Spiel, dann hat meine Erfahrung bisher immer gezeigt, dass fehlende Timing Constraints das Problem sind und nicht-deterministisches Verhalten der Tools ausgeschlossen werden konnte. Daher bricht die obige Fragestellung runter zu: "Anforderungen voellstaendig spezifiziert" oder "Anforderungen nicht vollstaendig spezifiziert". Die Tools koennen nunmal nur so gut Arbeiten, wie den Input den sie vom Anwender bekommen (auch wenn uns die Werbeversprechen der FPGA Hersteller manchmal was anderes weissmachen wollen).
Das sind aber mehrere unterschiedliche Dinge: - Signal hinzufüegen -> Designänderung - Neue Compiulation -> Programmierfileänderung - neuer Seed -> neues Programmierfile - Neue Anforderung -> anderes Design - anderes Constrain -> anderes Ergebnis
Noch eine Bemerkung zur eigentlichen Fragestellung: Waldi3141 schrieb: > Falls einer mal was in der Richtung I2S und FPGA in VHDL gemacht hat, > würde mich sehr über Tipps freuen :) Falls das noch eoin Thema für jemanden ist, hätte ich da etwas. > Habe zwar Code zu I2S auf Opencores und anderen Seiten gefunden, aber > konnte nicht viel damit anfangen. Was daran liegt, dass auch OC meistens Anfänger publizieren, die sich etwas ausdenken, es reinhäcken und dann undokumentiert und ungetestet die Welt mit buggy files versorgen, um schließlich wegzurennen und das Projekt aufzulassen. Genau das also, was in der Industrie niemand gebrauchen kann. Die Industrie meidet OC als Quelle von Cores wie der Teufel das Weihwasser.
M. W. schrieb: > Was daran liegt, dass auch OC meistens Anfänger publizieren, Nein. > es reinhäcken und dann undokumentiert und ungetestet > die Welt mit buggy files versorgen, um schließlich wegzurennen und das > Projekt aufzulassen. Nein. > Genau das also, was in der Industrie niemand gebrauchen kann. Nein. > Die Industrie meidet OC als Quelle von Cores wie der Teufel das > Weihwasser. Nein.
M. W. schrieb: > Was daran liegt, dass auch OC meistens Anfänger publizieren, die sich > etwas ausdenken, es reinhäcken und dann undokumentiert und ungetestet > die Welt mit buggy files versorgen, um schließlich wegzurennen und das > Projekt aufzulassen. Nunja, ich kann mich da dunkel an eine Appnote von Xilinx erinnern, wo das wohl ähnlich lief. Der Student/Praktikant war dann auch nicht mehr greifbar... Duke
M. W. schrieb: > Was daran liegt, dass auch OC meistens Anfänger publizieren, die sich > etwas ausdenken, es reinhäcken und dann undokumentiert und ungetestet > die Welt mit buggy files versorgen, um schließlich wegzurennen und das > Projekt aufzulassen. Ob es Anfänger sind, weiß ich nicht, aber "undokumentiert" ist weitgehend richtig. > Die Industrie meidet OC als Quelle von Cores wie der Teufel das > Weihwasser. Was aber vor allem an rechtlichen Fragestellungen liegt.
Stefan K. schrieb: > Ich habe festgestellt, dass bei meiner FPGA IDE (Quartus II) manchmal > doppeltes Compilieren/Synthetisieren nötig war, bis das das Ergebnis > gestimmt hat. Bevor man Vermutungen bezüglich eventueller Fehler anstellt, wäre die vorab zu stellende Frage, wie das denn festgestellt wurde, dass das "Ergebnis stimmt". Es kann auch gut sein, dass unterschiedliche Versionen mit der gleichen Funktion bei unterschiedlichem Compilationläufen deshalb anders arbeiten, weil es grundsätzliche Timingfehler gibt, die mal auftreten und mal nicht, weil die contraints zu schwach- oder nicht richtig gesetzt waren. D.h. ein minimal anderes Timing an einem Ausgang oder Eingang führt zu irgendwelchen internen Fehlern. Das sieht dann durchaus soaus, als ob es ein Problem des grundsätlzichen Compilierens wäre. In Realität ist es nur ein Problem von zu vielen Freiheitsgraden. Und diese Thema verschärft sich mit jedem Schritt hin zu einer abstrakteren Schaltungsunktionsbeschreibung, weil diese immer indirekter wird.
C. A. Rotwang schrieb: >> Was daran liegt, dass auch OC meistens Anfänger publizieren, > Nein. > >> es reinhäcken und dann undokumentiert und ungetestet >> die Welt mit buggy files versorgen, um schließlich wegzurennen und das >> Projekt aufzulassen. > Nein. > >> Genau das also, was in der Industrie niemand gebrauchen kann. > Nein. Der I2C Controller Core von Herveille (https://opencores.org/projects/i2c) ist durchaus brauchbar, gut dokumentiert - und bei mir im Dauereinsatz (nachdem ich ihn vom nicht benötigten Wishbone-Overhead befreit habe).
Jürgen S. schrieb: > M. W. schrieb: >> Was daran liegt, dass auch OC meistens Anfänger publizieren, die sich >> etwas ausdenken, es reinhäcken und dann undokumentiert und ungetestet >> die Welt mit buggy files versorgen, um schließlich wegzurennen und das >> Projekt aufzulassen. > Ob es Anfänger sind, weiß ich nicht, aber "undokumentiert" ist > weitgehend richtig. "Weitgehend" ist genau das Stichwort, je nachdem was der "OC-Downloader" gerade in seiner Selbstgerechtigkeit als "gut dokumentiert" ansieht, ist jeder Core mehr oder weniger schlecht dokumentiert. Aber abgesehen davon , das schon mal die Offenlegung des Quelltextes eine Art der Dokumentation ist, insbesonders wenn man die Dokumentiert-sich-Selbst Eigenschaft des geschwätzigen VHDL nutzt, sind die Interface der Obencores-Module -der Wishbone-Anteil- m.E. umfassend beschrieben. Weil eben OpenCores mit der Spezifikation einer standardisierten Schnittstelle für alle Module begann. Aber ich befürchte, die wenigstens OC-Downloader haben dieses Dokument gesehen oder durchgearbeitet: https://cdn.opencores.org/downloads/wbspec_b4.pdf Und die andere Seite der Schnittstelle I2S, I2C, DDR, etc. pp. ist auch dokumentiert, nur muss man sich eben die Mühe machen, die Standardbeschreibung ausfindig zu machen. Hinzu kommt, das, egal wieviel "Papier" ein Zulieferteil von sich aus mitbringt, derjenige, der es in sein System integriert, diesen, seinen eigenen, Integrationsschritt (also welchen Funktionsumfang er nutzt, wo die Source-files abgelegt sind, wie die Funktion und Qualität der Integration getestet wurde, Testbench, Testcases, Entwicklungshistorie,..)" nachvollziehbar, konkret aber nicht ausschweifend beschreibt. Aber dazu kommt es auch eher selten, jedenfalls seltener als die Neignung bei jedem "geschenkten" Gaul erstmal kräftig schimpfend über das geistige Vermögen des Spenders herziehen. (Wohl aus einem Reflex des Feilschens heraus, wobei sich die Frage stellt, an welchen Preis man hier feilschen will - Monty Python lässt grüssen https://youtu.be/R1s_5toNsrs?t=14 ) Da hat man das Konzept des "Open Source" meines Erachtens gründlich missverstanden. Open Source bedeutet nicht "Rundum sorglos Pakt", eher im Gegenteil. "Offener Quelltext " sieht sich nicht als Fertigproduct wie "Freeware", sondern als "Werkzeug" das der User mach eigenen Vorgaben selbst benutzen kann, um das für ihn passende Produkt selbst zu bauen. Und Open Source schliesst den Gedanken ein, das der "Open Source" Autor (oder jemand anders der sich darin eingearbeitet hat) durch den Support also der Unterstützung des Kunden bei der Integration seinen Unterhalt verdient. Aber die Bereitschaft diese entgeltliche Zuarbeit überhaupt anzufragen, ist wohl eher nicht von "Downloadern" zu erwarten die pauschal loswettern, die Autoren wären unfähig, testen nix und rennen weg sobald sich Nachfragen ergeben könnten. BTW: IMHO ist eine Diskussion wie man bei der Integration von Fremdcores, bspw die von OC, sinnvollerweise vorgeht sehr wohl angebracht, aber das sprengt den Rahmen dieses I2S-Threads.
C. A. Rotwang schrieb: > IMHO ist eine Diskussion wie man bei der Integration von Fremdcores, > bspw die von OC, sinnvollerweise vorgeht sehr wohl angebracht, Bei mir gibt es jeweils pro Projekt ein Verzeichnis "contrib", wo Fremcode fein säuberlich sortiert aufbewahrt wird. Da braucht man doch keine Diskussion dafür... Duke
M. W. schrieb: > Was daran liegt, dass auch OC meistens Anfänger publizieren, die sich > etwas ausdenken, es reinhäcken und dann undokumentiert und ungetestet > die Welt mit buggy files versorgen, um schließlich wegzurennen und das > Projekt aufzulassen. > Mit etwas genau hingucken sollte eigentlich jeder die Spreu vom Weizen trennen können. Und sonst schreibt man die Autoren mal eben an. > Genau das also, was in der Industrie niemand gebrauchen kann. > > Die Industrie meidet OC als Quelle von Cores wie der Teufel das > Weihwasser. Das kann ich nicht bestätigen. Es gibt einige sehr gute Cores auf OC. Und halt auch etwas Schrott, den kann man aber auch von namhaften Firmen geliefert kriegen. Als erstes steckt man das Zeug sowieso in den Simulator. Was schlicht immer wieder - sogar von den grosse Drei-Buchstaben-Siliziumhirschen missverstanden wird: Opensource heisst nicht: Kostenlos. Viele Opensource-Provider ziehen sich irgendwann auch einfach zurück, weil sie nicht Lust haben, der 20-ten "ich hätte gern kostenlosen Support" -Anfrage nachzugeben, oder sich bei einer klaren Aufwandsabschätzung (wenn sich der kommerzielle Hintergrund des Fragestellers erst mal offenbart) anmaulen zu lassen: "Aber das ist doch Opensource!". Zum Thema I2S: Wo steckt genau das Problem? Wir wollen ja gerne helfen, aber ich zumindest würde vorher auch gerne eine Simulation/Modell oder wenigstenz Block-Konzept sehen. Wenn du gute Doku zu I2S-Betriebsarten suchst, schau dir mal z.B. die Blackfin BF537-Hardware-Referenz an. So einen Core nachzustricken ist keine Riesen-Arbeit (BTDT), mal von der DMA-Geschichte abgesehen. P.S. Beim Blackfin heisst das Ding 'SPORT'.
Martin S. schrieb: > Blackfin BF537-Hardware-Referenz an. So > einen Core nachzustricken ist keine Riesen-Arbeit (BTDT), mal von der > DMA-Geschichte abgesehen DMA und die Vermittlung der Datenpakete ist aber doch das Thema bei der Verwendung von Mikrocontrollern und DSPs wie dem blackfin, weil diese noch andere Dinge tun müssen und viel davon zeitkritisch ist. Das bläht die Anwendung auf und führt nicht selten zu hektischem Interruptgefummel, wenn der DSP nicht ein I2S fest eingebaut hat. Deshalb schiebt man ja das lolevel-Gedöhns nicht umsonst in einen digitalen Baustein. I2S im FPGA sollte kein Problem sein. Mehr, als ein paar Zähler und Schieberegister sind es nicht. Die Probleme liegen meistens im Verständnis des Datenformats und der richtigen Interpretation der Verschiebung beim z.B. dem LJ-Mode. Habe mir den Code von Drange auf open Cores mal angesehen: Das meiste davon ist wishbone-Interface und zum Ankoppeln an z.B. SOC-Systeme gedacht. Das mag nutzvoll sein für Leute, die unsbedingt mit DSPs arbeiten wollen und nur Software können, aber bei einer harten Verarbeitung der Daten ist das alles overhead und kann weggelassen werden.
Markus W. schrieb: > DMA und die Vermittlung der Datenpakete ist aber doch das Thema bei > der Verwendung von Mikrocontrollern und DSPs wie dem blackfin, weil > diese noch andere Dinge tun müssen und viel davon zeitkritisch ist. Das > bläht die Anwendung auf und führt nicht selten zu hektischem > Interruptgefummel, wenn der DSP nicht ein I2S fest eingebaut hat. Der Gag ist doch grade an DMA, dass es ohne IRQ-Handling läuft. Kennst du einen DSP, der I2S nicht hardwaremässig und ohne DMA macht? Ich würde behaupten: es gibt keinen. Optimale DMA-Queues schmeissen nur dann einen Interrupt, wenn ein Fehler auftritt. Beim Blackfin ist das optimal gelöst, ich kann nur empfehlen, sich das Konzept fürs FPGA zu 'kopieren'. Das Interface als solches zu implementieren ist ja nicht das Knifflige, sondern die Klassiker: - Übergang in andere Taktdomänen - Abrissfreier Datentransfer - Allenfalls Clock-Synchronisation zw. Sender/Empfänger Um jetz aber nich zig Sachen zusammenzuwerfen, würde ich halt mal mit den I2S-Optionen anfangen, erst mal Testsignale generieren, simulieren, simulieren... Wie dann die obigen Klassiker vernudelt werden, muss jeder selber wissen. Ich würde auf jeden Fall sowas nie von Hand in HDL giessen (ausser, wenn unbedingt erforderlich), mit einer embedded CPU und sauberen SGDMA-Engine hat man die beste Kontrolle über Datenfluss, Protokolle und Timeouts und es ist für alle möglichen Protokolle (GigE, USB, ...) wiederverwertbar.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.