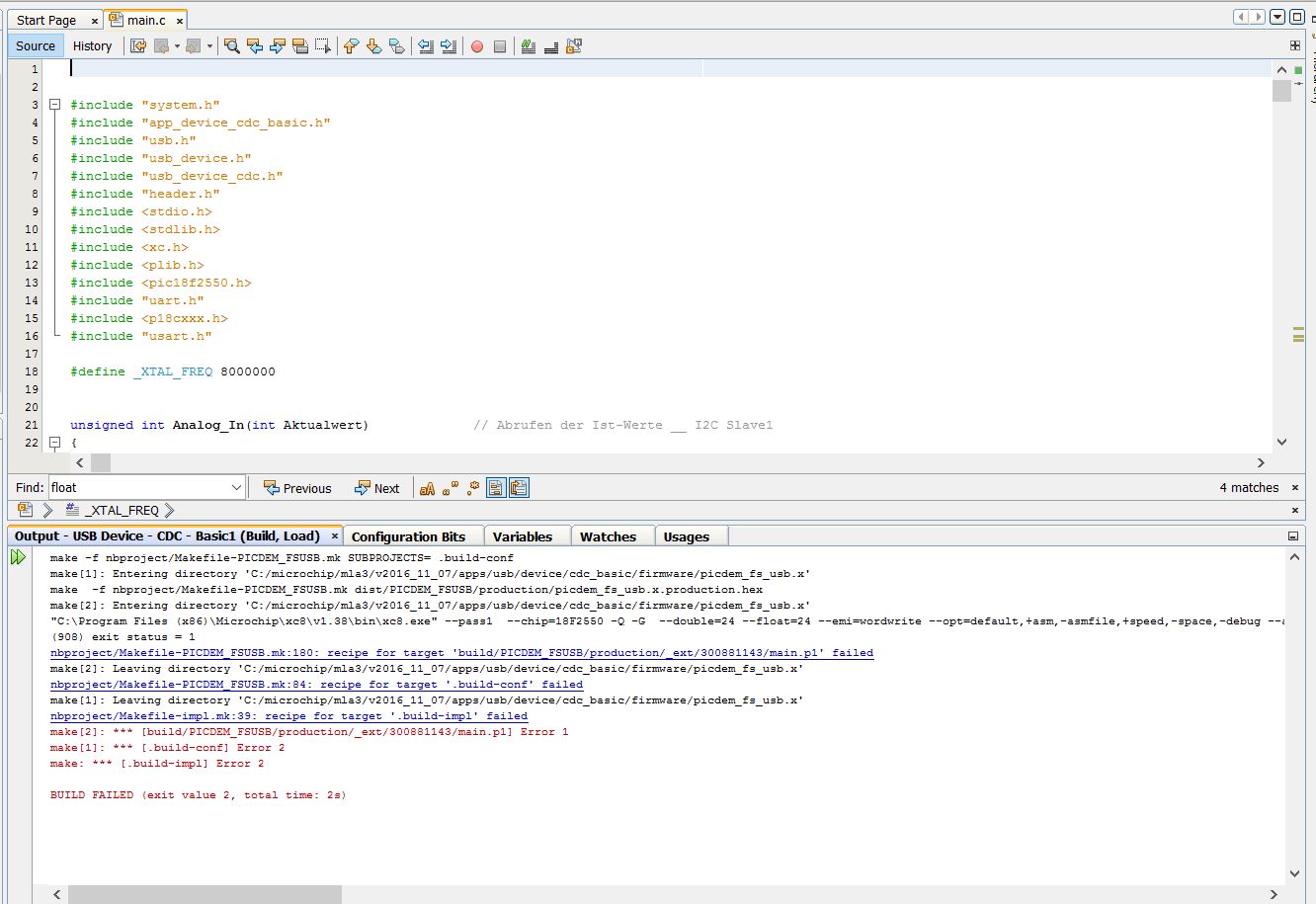
Hallo zusammen, ich bekomme neuerdings "Makefile" Fehlermeldungen (s. Anhang). Ich habe eigentlich gar nichts am Quelltext geändert. Eben hat er noch alles Fehlerlos kompiliert. Weiß jemand, was das ist? Compiler: XC8 PIC: 18F2550 Gruß Simon (sorry für den Doppelpost, habe mich im Unterforum vertan)
Angehängte Dateien:
-

bild.JPG
150 KB
Logs postet man als Textdateien, nicht als Screenshot. Lerne es! Dein Screenshot sagt, dass xc8.exe mit einem Rückgabewert von 1 (= Fehler) endet. Vollkommen überraschend wertet make diesen Wert aus und stellt die weitere Verarbeitung ein. Ein Zwischenschritt ist schließlich misslungen. Vielleicht findest du irgendwo auch die Ausgaben des Compilers. Da könnte vielleicht sogar drinstehen, warum er einen Fehler zurückgibt.
S. R. schrieb: > Logs postet man als Textdateien, nicht als Screenshot. Lerne es! > > Dein Screenshot sagt, dass xc8.exe mit einem Rückgabewert von 1 (= > Fehler) endet. Vollkommen überraschend wertet make diesen Wert aus und > stellt die weitere Verarbeitung ein. Ein Zwischenschritt ist schließlich > misslungen. > > Vielleicht findest du irgendwo auch die Ausgaben des Compilers. Da > könnte vielleicht sogar drinstehen, warum er einen Fehler zurückgibt. Hi svneska, danke für die schnelle Antwort. Könntest du mir etwas genauer beschreiben, wie ich vorgehen kann? Wo finde ich die Ausgabe des Compilers?
simon schrieb: > Könntest du mir etwas genauer beschreiben, wie ich vorgehen kann? Nein, weil ich deinen Compiler, deine IDE und PIC-Microcontroller selbst nie benutzt habe. Da können dir andere vermutlich direkt sagen, wo du schauen musst. Notfalls gibst du den Befehl in einer Eingabeaufforderung (vorher ins richtige Verzeichnis wechseln) ein und schaust, ob dabei was verwertbares rauskommt. Oder du schaust dir mal alle Dateien an, die irgendwie nach Logdateien aussehen.
Ich würde damit anfangen nach dem Fehlercode 908 zu googeln oder im Handbuch nachzuschauen was der bedeutet.
Bernd K. schrieb: > Ich würde damit anfangen nach dem Fehlercode 908 zu googeln oder > im > Handbuch nachzuschauen was der bedeutet. Dieser Fehler bedeutet, dass ein Unterprogramm nicht ausgeführt werden kann. Ich glaube das liegt an dieser Zeile: nbproject/Makefile-PICDEM_FSUSB.mk:180: recipe for target 'build/PICDEM_FSUSB/production/_ext/300881143/main.p1' failed make[2]: Leaving directory 'C:/microchip/mla3/v2016_11_07/apps/usb/device/cdc_basic/firmware/picdem _fs_usb.x' Aber was sagt mir das? Ich finde die Datei "main.p1" gar nicht. Nur eine Datei Namens "main.pre". Fehlt dort was?
simon schrieb: > Ich finde die Datei "main.p1" gar nicht. Natürlich kannst Du diese Datei nicht finden. Genau das hat Dir doch Dein Computer mitgeteilt.
Angehängte Dateien:
-

bild.JPG
29 KB

Es wird wieder alles kompiliert!!! Aus irgendwelchen Gründen (die ich immernoch nicht kenne) verwandeln sich meine Quelltextkommentare in Kauderwelsch (s. Screenshot). Nachdem ich alle Kommentare gelöscht habe, kompiliert er wieder... Ist das ein Compiler Problem?
Eher ein Zeichensatzproblem, vermutlich hat die IDE die Dateien in UTF-8 gespeichert, und der Compiler mag da nicht.
simon schrieb: > Ich glaube das liegt an dieser Zeile: simon schrieb: > Ich glaube das liegt an dieser Zeile: > > nbproject/Makefile-PICDEM_FSUSB.mk:180: recipe for target > 'build/PICDEM_FSUSB/production/_ext/300881143/main.p1' failed Nein, das ist das Symptom. Die Ursache geschieht immer vor der Wirkung, das hat schon Einstein erkannt, deshalb steht die Ursache im Logfile immer weiter oben als die Wirkung.
HG schrieb: > Eher ein Zeichensatzproblem, vermutlich hat die IDE die Dateien in UTF-8 > gespeichert, und der Compiler mag da nicht. Dafür spricht der andere Kommentar dort, "// DRUCK". Wer auf deutsch Kommentare setzt, der verwendet dabei dann auch noch Umlaute. Mit Pech knallt die IDE dann auch noch eine byte order mark in die ersten drei Zeichen der Textdatei.
HG schrieb: > Eher ein Zeichensatzproblem, vermutlich hat die IDE die Dateien in UTF-8 > gespeichert, und der Compiler mag da nicht. Oder gar noch schlimmeres... Vor etlichen Jahren musste ich mit zwei eher lernresistenten Kollegen (SW-Entwickler!) eine Diskussion darüber führen, dass Word bzw. Wordpad nicht die geeigneten Werkzeuge für die Bearbeitung von Quelltexten sind. Deren Argumentation bestand darin, dass sie doch sonst auch alles mit den o.a. Programmen machten und sich nicht extra in einen anderen Editor einarbeiten wollten. Außerdem könne man doch so die Quelltexte viel besser formatieren. Ich fand deren Quelltexte sogar ziemlich unleserlich, da es kein Syntax-Highlighting gab und die Texte in einer sehr schmalen Proportionalschrift formatiert waren. schauder Naja, wenigstens gehörten die beiden nicht zu der anderen Fraktion, die auf einem völlig veralteten Quellcodestand arbeitet und von diesem aus munter Dateien eincheckt, die sich dann auf keinem anderen System kompilieren lassen. Mit solch einem Mitarbeiter eines Kunden musste ich mich auch einmal über längere Zeit herumschlagen.
Andreas S. schrieb: > und die Texte in einer sehr schmalen Proportionalschrift formatiert > waren. schauder Ich hab das mal ne Zeitlang mit Python unter SciTE so gehabt (Proportionalschtrift). War eigentlich ganz angenehm. Den Einrückungen links tut die Proportinalschrift ja keinen Abbruch und rechts dovon interesierts eh kaum, dort muss man im Wesentlichen nur gut lesen können. Ich muss das gelegentlich mal mit C ausprobieren. Aber leider können viele Texteditoren keine Proportionalschrift sonst wär das bestimmt wesentlich verbreiteter.
Andreas S. schrieb: > Kollegen (SW-Entwickler!) eine Diskussion darüber > führen, dass Word bzw. Wordpad nicht die geeigneten Werkzeuge für die > Bearbeitung von Quelltexten sind Das waren keine Softwareentwickler. Da hast Du bestimmt was verwechselt.
In der deutschen Übersetzung der Ur-Ausgabe des K&R waren die Codebeispiele in einer Proportionalschrift gesetzt. Das war damals schon komplett unbrauchbar.
Bernd K. schrieb: > Das waren keine Softwareentwickler. Da hast Du bestimmt was verwechselt. Nein, die eine war Diplominformatikerin, der andere Elektrotechniker mit Schwerpunkt Technische Informatik. Beide kamen (so wie ich) frisch von der Uni und hatten (im Gegensatz zu mir) keinerlei Projekterfahrung. Beide waren bei dem Unternehmen als reine Softwareentwickler eingestellt worden.
Rufus Τ. F. schrieb: > In der deutschen Übersetzung der Ur-Ausgabe des K&R waren die > Codebeispiele in einer Proportionalschrift gesetzt. im C++ von Stroustrup auch (und zwar absichtlich) > Das war damals schon komplett unbrauchbar. Warum?
Andreas S. schrieb: > Beide kamen (so wie ich) frisch von > der Uni und hatten (im Gegensatz zu mir) keinerlei Projekterfahrung. > Beide waren bei dem Unternehmen als reine Softwareentwickler eingestellt > worden. Also waren es tatsächlich wie ich vermutete keine SW-Entwickler sondern bestenfalls frische SW-Entwickler-Azubis. Warum werden SW-Entwicklerstellen mit ungelernten und noch vollkommen ahnungslosen Azubis besetzt? Jeder weiß doch daß ein SW-Entwickler im Schnitt 35 bis 50+ Jahre alt ist? Das fällt doch normalerweise sofort auf wenn derjenige noch keine Falten auf der Stirn und unter den Augen hat, haben die sich etwa falsche Bärte angeklebt und die Haare grau gefärbt, oder wie sind die da reingekommen?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.