Hallo
folgendes Problem.
Angenommen, wir haben einige Daten physikalischen Ursprungs.
Einfachheitshalber betrachten wir ein eindimensionales Array ganzer
Zahlen. Obwohl alle Zahlen in diesem Array unterschiedlich sein können,
gehen wir davon aus, dass einige Werte zusammen gehören und sich nur
wegen Messfehler bzw. Quantisierungsfehler (Digitalisierungsfehler)
minimal unterscheiden. Diese Werte werden gesucht.
Die Aufgabe ist für einen 8-Bit µC.
Verdeutlichung:
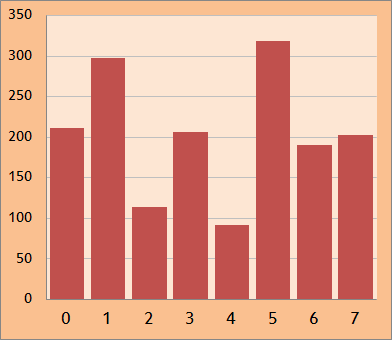
a = {212, 298, 114, 207, 92, 319, 191, 203}
Hier würden uns interessieren: a[0], a[3], a[6], a[7].
Mit welchem Verfahren realisieren wir das am schnellsten?
Angehängte Dateien:
-

array_analysis.png
1,8 KB
Ich habe schon Autos ausgeschlachtet, und einige Elektrogeräte, aber wie man Arrays ausschlachtet verstehe ich jetzt nicht wirklich. Was ist dein eigentliches Problem?
Georg M. schrieb: > Obwohl alle Zahlen in diesem Array unterschiedlich sein können, > gehen wir davon aus, dass einige Werte zusammen gehören und sich nur > wegen Messfehler bzw. Quantisierungsfehler (Digitalisierungsfehler) > minimal unterscheiden. Also wollt ihr die Messwerte an eure Wunchvorstellungen schön rechnen? Davon kann man nur abraten. Macht ne vernünftige Fehlerabschätzung, also eine Abschätzung wie genau Eure Messwerte höchstens sein können. Systematische Messfehler kann man nicht rausrechnen, nur eingrenzen.
Jim M. schrieb: > Array einfach sortieren Dieses. Oder falls "schnell" "on-the-fly" bedeutet und die Ausreißer normalverteilt sind, moving average.
Der Andere schrieb: > Wie man Arrays ausschlachtet verstehe ich jetzt nicht wirklich. Ist das nicht ein inzwischen ausgestorbener Vogel aus Neuseeland oder so? :-)
Angehängte Dateien:
-

Georg_M.filtering.png
4,4 KB
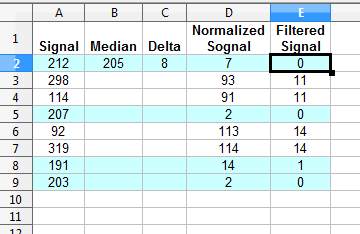
Hallo Georg, Ich würde erst nach der "Median" suchen (Wert/Gewicht dass spielt die Wichtigste Role in dem Signal), dann die "Delta" sich auswählen - (wie unterschiedlich "darft" unsere Signal in beide Richtungen abweichend sein) und Median von jeden Wer von Array substrhieren und gegen Delta vergleichen (ob es passt zum unseren Akzeptanz Kriteria oder nicht). In Pseudocode:
1 | a = {212, 298, 114, 207, 92, 319, 191, 203}; |
2 | |
3 | median = (212 + 298 + 114 + 207 + 92 + 319 + 191 + 203) / 8 = 204,5 (~205) |
4 | delta = 1, 2, 3, 4... /* Experimentell hier */ |
5 | |
6 | for (i 0..ArraySize-1) { |
7 | if( abs( a[i] - median) / delta > 0 ) { |
8 | /* Dieses Weri is uns interresant */
|
9 | }
|
10 | }
|
Angehängt ist Excel test mit diese Signal, und Filter wirkung. Falls brauchen Sie hilfe mit implementierung - einfach sagen. Entschuldigung für meine Deutsch Sprache :)
Oleh P. schrieb: > Entschuldigung für meine Deutsch Sprache :) OT: Obwohl man Unbekannte in D typischerweise mit "Sie" anspricht, ist es hier im Forum üblich, sich mit "Du" anzusprechen.
Ich habe jetzt gerade keinen konkreten Algorithmus im Kopf, aber unter den Stichwörtern "Clustering", "Clusteranalyse" und "Cluster Analysis" findest du jede Menge davon. Bitwurschtler schrieb: > Also wollt ihr die Messwerte an eure Wunchvorstellungen schön rechnen? > Davon kann man nur abraten. Was hat das mit "Schönrechnen" zu tun? Edit: Willst du alle Cluster ähnlicher Werte oder nur den größten finden? Beispiel: { 99, 100, 201, 199, 97, 105, 203, 103 } Hier gibt es zwei Cluster, nämlich { 99, 100, 97, 105, 103 } und { 201, 199, 203, } Interessiert dich jetzt nur der erste (mit 5 Elementen) oder alle beide? Je nach Datensatz können es natürlich auch mehr als zwei sein. Um nur den größten Cluster zu finden, brauchst du keine Cluster-Analyse im eigentlichen Sinn, sondern ein Verfahren, das Ausreißer ermittelt, wie z.B. RANSAC.
Les Dir mal die hier vorgestellten Verfahren durch: http://www.statistics4u.info/fundstat_germ/cc_outlier_tests.html Wichtig ist, * wodurch die Ausreisser in Deinem Array entstehen, * wieviel% der Messwerte in Deinem Array wahrscheinlich Ausreisser sind, * ob die Ausreisser in beide Richtungen oder nur in eine ausschlagen. Gruß, Stefan
Yalu X. schrieb: > Bitwurschtler schrieb: >> Also wollt ihr die Messwerte an eure Wunchvorstellungen schön rechnen? >> Davon kann man nur abraten. > > Was hat das mit "Schönrechnen" zu tun? Ich lese das Post Original: "... gehen wir davon aus, dass einige Werte zusammen gehören und sich nur wegen Messfehler ..." so: Da sind Ausreisser drin die nicht zu dem passen was wir: a) von dem gemessenden Prozess erwarten b) was unsere Messequipment bringen müsste. c) wir keine vertrauenswürdiger referenzmessung mit genaueren Equipment haben. Da sollte man doch erst klären ob es sich tatsächlich um Messfehler handelt oder mglw doch die zu messende Größe "schwingt". Mit der falschen Messwertaufbereitung kann man nicht nur dem Messfehler sondern auch die Realität "wegmitteln". Da gibt es doch diesen Sinnspruch von "Obwohl der See im Mittel nur 1m tief ist, ertrank Paul Naseweiss beim Versuch ihn zu durchwaten ..." Es ist schon mancher von falschdimensionierten Anitaliasingfiltern oder anderen groben Schnitzern bei der AD-Wandlung genarrt worden.
Oleh P. schrieb: > Ich würde erst nach der "Median" suchen Ja, danke, richtig, ich habe auch gedacht, dass die Berechnung durch den Mittelwert schneller gehen sollte, als mit dem langweiligen Sortieren. Nur brauchte ich eine Bestätigung bzw. Widerlegung. Auch das subjektiv festgesetzte Delta ist etwas bedenklich. Yalu X. schrieb: > Ich habe jetzt gerade keinen konkreten Algorithmus im Kopf, aber unter > den Stichwörtern "Clustering", "Clusteranalyse" und "Cluster Analysis" > findest du jede Menge davon. Gefunden: https://de.wikipedia.org/wiki/K-Means-Algorithmus Yalu X. schrieb: > Willst du alle Cluster ähnlicher Werte oder nur den größten finden? Momentan geht es nur um die Mehrheit. Später vielleicht auch andere Gruppierungen.
> Mit welchem Verfahren realisieren wir das am schnellsten?
Wie wäre es, wenn Du zu Deiner Datenreihe die statistischen Werte
"Mittelwert" und "Standardabweichung" ermittelst, und zusammengehörende
Werte beispielseise so definierst:
Die Werte, die weniger als die halbe Standardabweichung vom Mittelwert
entfernt liegen, gehören zusammen?
Hallo Georg,
> Auch das subjektiv festgesetzte Delta ist etwas bedenklich.
Was ich meinte mit Delta ist - einfach Signal/Quelle-specifische
Ausfilterung zu verwenden.
Da hast du Recht - es ist festgesetzt, aber es "beschreibt" die
characteristische Merkmalen von Signal, wie ein "effektives Bereich" und
"Enderungstärke".
Falls ändert sich die Datenquelle - Delta soll neu angepasst werden.
Natürlich, ist diese Anwendung nicht für Realtime ausgedacht (sondern
für "Postprocessing") kann Mann viel flexibel sich mit Min/Max Werte was
aussdenken, anstatt diese konstante Delta.
Jürgen S. schrieb: > Die Werte, die weniger als die halbe Standardabweichung vom Mittelwert > entfernt liegen, gehören zusammen? Und was machst du wenn du Messwerte hast mit 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, Da gehört 1zu 2, 2 zu 3, 3 zu 4, ... Also gehören alle zu allen. Wo setzt du jetzt die Grenze ab der ein Wert zu einer anderen "Gruppe" gehört?
Georg M. schrieb: > > Mit welchem Verfahren realisieren wir das am schnellsten? Ich gehe mal von aus, es werden mehr als die paar Messwerte sein. Mittelwert bilden und dann alle raussortieren, die +-(x) davon sind. Oder wenn Gaußverteilung und alle rauswerden die außerhalb des gewünschten %-Fensters sind. Wenn die Messwerte vll. schon eine Überlagerung von anderen Werten sind, vll. eine Fourieranalyse. Gruß
Jürgen S. schrieb: > Die Werte, die weniger als die halbe Standardabweichung vom Mittelwert > entfernt liegen, gehören zusammen? Oleh P. schrieb: > Ich würde erst nach der "Median" suchen Hier ist die Frage nach der Herkunft der Messwerte. Die beiden obengenannten Verfahren könnten funktionieren, wenn es sich um eine unimodale Verteilung mit zB Ausreißern handelt (wobei dabei sich der Median sicherlich stabiler verhalten sollte) Sind die nicht-zusammengehörigen Messwerte möglicherweise tatsächlich relativ unabhängig, dann ist die Verteilung multimodal und beide Verfahren liefern falsche Ergebnisse. Dann wäre möglicherweise tatsächlich ein Clusterverfahren angebrachter. Angenommen da ist ein Temperatursensor im Bereich einer Tür, der immer bei geöffneter Tür zum großen Teil die Außentemperatur misst. Dann ist es mit den obigen Verfahren schwierig die Inntentemperatur zu messen, wenn ich keine Annahmen über das Verhältnis der Offen-Zu-Zu-Verhältnisse habe. Also: @Op: mehr Details bitte
Bitwurschtler schrieb: > Da sollte man doch erst klären ob es sich tatsächlich um Messfehler > handelt ...und es muss geklärt werden, ob es sich um systematische Messabweichungen oder zufällige Messabweichungen handelt.
Georg M. schrieb: > Hallo > folgendes Problem. > Angenommen, wir haben einige Daten physikalischen Ursprungs. > Einfachheitshalber betrachten wir ein eindimensionales Array ganzer > Zahlen. Obwohl alle Zahlen in diesem Array unterschiedlich sein können, > gehen wir davon aus, dass einige Werte zusammen gehören und sich nur > wegen Messfehler bzw. Quantisierungsfehler (Digitalisierungsfehler) > minimal unterscheiden. Diese Werte werden gesucht. > Die Aufgabe ist für einen 8-Bit µC. > > Verdeutlichung: > > a = {212, 298, 114, 207, 92, 319, 191, 203} > Hier würden uns interessieren: a[0], a[3], a[6], a[7]. > > Mit welchem Verfahren realisieren wir das am schnellsten? 1. Sortieren -> 319,298,212,207,203,191,114,92 2. im sortierten Feld differenzen zum nachfolger bilden, 21,86,5,4,12,77,22 3. wenn differenz kleiner 16 (+/- 3 bit quantisierungsfehler) elementzähler inkrement, sonst null -> 0,0,1,2,3,0,0 4. wo der elementezähler hochläuft, liegt der gesuchte bereich. Nicht erwähnt bei dem Algorithmus sind proben an der Intervallgrenze in entgegengesetzte Indexrichtung und die Indexspeicherung um den originalen Index der Messwerte zu ermitteln. Ob das verfahren das schnellset ist, hängt mit davon ab wie schnell die anderen implementiert werden können und damit ob der µC schnell dividieren kann, wenn benötigt. Einfach mal 2 verschiedene Verfahren implementieren und gegeneinander an real data antreten lassen. Sollte nicht länger als einen Tag benötigen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.