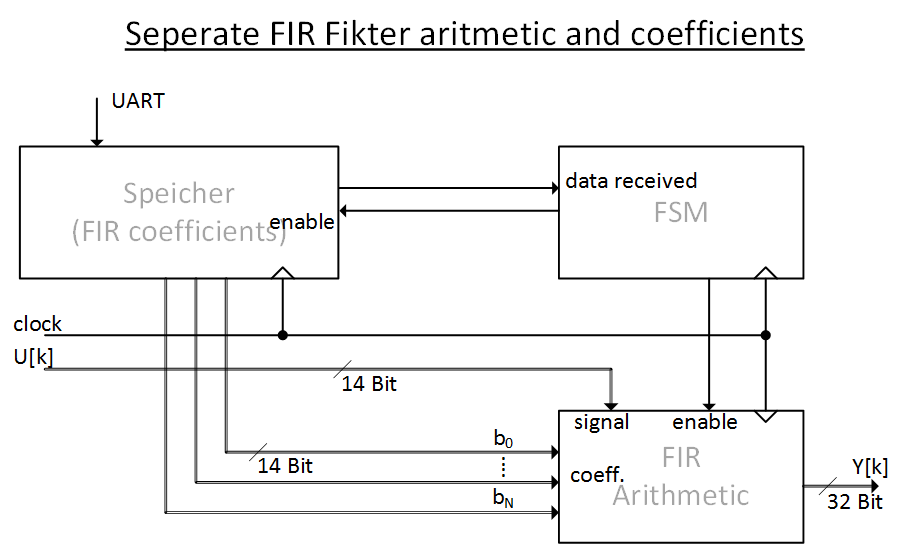
Hallo liebes Forum, Ich stelle mir folgende Frage: Ist es sinvoll möglich die Filterkoeffizienten von der Filterarithmetik bei einem FPGA zu trennen, sodass die Koeffizienten im Nachhinein, nach der Synthes über bspw. eine UART-Verbindung, in gewissen Grenzen, geändert werden können? Dem Anhang ist eine kleine Skizze beigefügt, auf dieser ist eine FSM, ein Speicher für die Koeffizienten und ein Block für die Filterarithmetik zu sehen. Dabei steuert die FSM die Freigabe der Koeffizienten, sollte einmal der Fall auftreten, dass diese während des Betriebes, also online, verändert werden. In meiner Vorstellung also: - Nun gibt es zwei denkbare Arbeitsweisen des FIR Filters - Parallel und Seriell. - Bei serieller Arbeitsweise könnte man, wenn die Taktrate der Clock und die Abtastrate des Filter es zulassen, mit einer Datenleitung für die Koeffizienten und weiteren Zwischenspeichern auskommen. Bei paralleler Arbeitsweise hingegen müssen bei jedem Takt die Koeffizienten bereits anliegen und man benötigt dem entsprechend so viele Datenleitungen wie Koeffizienten (Multipliziert mit der Wortbreite der Koeffizienten). Ein Beispiel: 3 Koeffizienten á 14 Bit (3*14 = 42) Bei der Synthese/Verdrahtung werden folglich für die Verbindung zw. Koeffizienten und Arithmetik 42 Leitungen verdrahtet. Meine Fragen an dieser Stelle: - Stelle ich mir den Sachverhalt richtig vor? - Ist nicht dann der Ressourchenverbrauch bei der Verdrahtung extrem! hoch? Bspw. bei einer Filterordnung von N = 50-100. - Gibt es auch andere Möglichkeiten dies zu realisieren oder die Filtereigenschaften, explizite die Koeffizienten, ohne ein erneutes Synthetisieren zu ändern? Bisher waren die Koeffizienten als Konstannten mit synthetisiert worden. Dies soll jedoch in Zukunft anders realisiert werden. Daher meine Frage an die experten. Lieben Dank schoneinmal im Vorfeld.
Angehängte Dateien:
-

FIR_Koeffizienten.png
12 KB
Stephan K. schrieb: > Bisher waren die Koeffizienten als Konstannten mit synthetisiert worden. Ich bin mir nicht sicher, ob die Idee eines FIR im FPGA wirklich gut ist. Immerhin benötigst du pro Tap ja eine Multiplikation und für alle zusammen eine Addition über alle Produkte. Wenn man das parallel ausführen will, kommt ne Menge Holz zusammen und meine Befürchtung ist, daß das den Rahmen sprengt ode du einen Chip brauchst, der weit außerhalb meines Finanzhorizonts liegt. Über wieviel Taps im Kernel reden wir denn? Bei 201 Taps brauchst du 201 Multiplikatoren und einen 201 Input-Adder. Da nützen auch Ideen zum Pipelining garnix, um das zu verringern. Wenn du das Ganze seriell machen willst, an was für eine Taktfrequenz hattest du dabei gedacht? Immerhin muß diese dann Tapanzahl*Samplerate sein und auch da kommt ne Menge Holz zusammen - diesmal nicht LUT's, sondern MHz. Aber wenn deine bisherigen Entwürfe durchgelaufen sind und funktionieren, dann sollte es durchaus möglich sein, die Koeffizienten ladbar zu machen. Die würden dann ja ohnehin als verteiltes RAM mitten im Logikmeer stehen und mir würde dazu nur einfallen, selbige seriell zu laden, also quasi als großes Schieberegister quer durch den ganzen Chip. W.S.
W.S. schrieb: > Idee eines FIR im FPGA Also in Büchern habe ich diesen Ansatz schon merhfach gelesen, zuletzt in "VHDL-Synthese" von "Jürgen Reichardt". Möglich schon und auch relativ schnell. > Über wieviel Taps im Kernel reden wir Wir reden von so an die 88 Taps. Ich arbeite mit einem CycloneIV (DE2-115 Dev-Board), dieser hat 266 14x14 Multiplikatoren. Ich benötige letzlich 3 FIR Filter bei N=88 (88*3=264) ist somit also schluss. Das Signal kommt von einem ADA-Daugtherboard mit max. 65 MSPS, diess kann ich jedoch nicht gänzlich ausreizen, da sonst die Ordnungen des FIR zu hoch werden würden. > was für eine Taktfrequenz hattest du dabei gedacht? Im Umkehrschluss würde dies bedeuten, dass ich bei einer Taktrate von 65 MHz mit ca. 738 kHz (65e6/88) sampeln könnte. Wobei ich über ne PLL auch die Taktfrequenz auf ca. 100 MHz erhöhen könnte, danach wirds zu ungenau denke ich. Danke für die bisherige Meinung!! Gruß.
Klar geht das, prinzipiell macht man das so auch. Aber: Du musst ev. was zu deinen Randbedingungen (Clock, Resourcen) erzählen. Typischerweise frisst dir der serielle Ansatz die wenigsten Resourcen (DSP slices) weg, wenn aber die Geschwindigkeit nicht reicht, musst du dein Problem a la divide et impera behandeln. Wenn du hochparallel arbeiten musst, kommst du mit den MAC-Units bzw. den harten DSP-Slices ev. ans Limit, dann läuft das typischerweise auf eine distributed-RAM-Geschichte für die Koeffizienten raus, und das mit dem zweiten Port oder Muxer zum Reinschreiben von aussen wirkt ab einer gewissen Anzahl sehr "verstopfend" beim Routing. Beim klassischen seriellen Ansatz nimmst du typischerweise ein Dualport-BlockRAM, und kannst über den zweiten Port im laufenden Betrieb die Parameter ändern.
Sicher wird das gemacht und das nicht nur bei FPGAs. Die Filterkoeffizienten stehen dann in Registern, in RAMs oder in der pipeline. Bei FPGAs ist diese Betrachtung deshalb interessant, weil bei der Synthese strukturelle Optimierungen vorgenommen werden können, d.h. jegliche Multiplikation kann bei bekannten Koeffizienten vereinfacht werden. D.h. bedeutet Runterbrechen auf stufenweise Additionen, die an ihrerseits in LUTs aufgespalten werden und zur Mehrfachtermnutzung führen. Ob und wieviel das bringt, hängt von den Koeffizienten und der Abspaltung ab. Manches geht automatisch und wird von der Synthese beschreibungsunabhängig gefunden, manches aber eben auch nicht. Man kann die K's ja entsprechend der Aufgabe und der Architektur skalieren und optimieren, um zu besonders einfachen Koeffizienten und damit kleinen Filtern zu gelangen, die trotzdem noch in der Spec sind. Die Auflösung der Daten, die Aussteuerung und der Bandverlauf des Filters, vor allem auch der Frequenzgang der Daten sind dabei zu beachten. Ein Messtechnikfilter für 0 .. 20kHz und 16 Bit, ist das z.B. aufwändiger, als eines für 20Hz bis 20kHz bei 20Bit, wenn es Audiodaten mit typischem Frequenzgang sind. Das ist die eigentliche Aufgabe bei der Signalverarbeitung mit FPGAs. Ansonsten einfach die Steinzeit-Hammer-Methode und die Standard-Koeffizienten von MATLAB oder dem CoreGen berechnen lassen und nehmen, was man kriegt.
Hallo, ja geht problemlos, habe ich schon gemacht. Wenn man das FIR Filter in eine eigene Componente auslagert muss man dorthin aber die Koeffizienten weiterreichen. Man baut sich halt eine Logik die das macht. Stephan K. schrieb: > Wir reden von so an die 88 Taps. > Ich arbeite mit einem CycloneIV (DE2-115 Dev-Board), dieser hat 266 > 14x14 Multiplikatoren. Ich benötige letzlich 3 FIR Filter bei N=88 > (88*3=264) ist somit also schluss. > Das Signal kommt von einem ADA-Daugtherboard mit max. 65 MSPS, diess > kann ich jedoch nicht gänzlich ausreizen, da sonst die Ordnungen des FIR > zu hoch werden würden. Brauchst Du wirklich so viele Taps? Stephan K. schrieb: > Im Umkehrschluss würde dies bedeuten, dass ich bei einer Taktrate von 65 > MHz mit ca. 738 kHz (65e6/88) sampeln könnte. Wobei ich über ne PLL auch > die Taktfrequenz auf ca. 100 MHz erhöhen könnte, danach wirds zu ungenau > denke ich. Wenn Du das Filter parallel baust kannst Du die volle Samplerate (65MSamples/s) in Echtzeit filtern.
Strubi schrieb: > Du musst ev. was zu deinen Randbedingungen (Clock, Resourcen) erzählen. Die Randbedingungen sind das Entwicklerboard DE2-115 und ein ADA-Daughterboard von Terasic. D.h. ich arbeite mit einem Cyclone IV Modell: EP4CE115) und einem parallelen 14 Bit AD-Wandler mit 65 MSPS. Zum Cyclone IV: -LEs: 114,480 -Memory: 3,888 Kbits -I/O: 528 -18x18 Multiplyer: 266 -Clock networks: 20 -PLLs: 4 -Clocks: 4 -Clock speed: 50 MHz Jürgen S schrieb: > Ein Messtechnikfilter für 0 .. 20kHz und 16 Bit, ist das z.B. aufwändiger. Und genau um so einen handelt es sich. Der Frequenzbereich passst auch einigermaßen. Jürgen S schrieb: > ..die Steinzeit-Hammer-Methode und die Standard-Koeffizienten von MATLAB. Gustl Buheitel schrieb: > Brauchst Du wirklich so viele Taps? Wie komme ich denn besser an Koeffizienten, wenn nicht über Matlab? In den bisherigen Büchern wurde letztlich immer empfohlen, die Koeffizienten über diesen Weg zu berechnen. Ist dies die Ursache für die vielen benötigten/errechneten Taps? Ich mein, wenn die Koeffizienten symmetrisch sind kann ich prinzipiell mit halb so vielen Taps arbeiten, wenn ich den Begriff "Taps" richtig verstehe. Gustl Buheitel schrieb: > Wenn Du das Filter parallel baust kannst Du die volle Samplerate > (65MSamples/s) in Echtzeit filtern. Hierzu: Jürgen S schrieb: > Die Auflösung der Daten, die Aussteuerung und der Bandverlauf des > Filters, vor allem auch der Frequenzgang der Daten sind dabei (bei der > Berechnung der Koeffizienten)zu beachten. Insbesondere bei der erhöhung der Samplerate meiner akquirierten Daten am AD-Wandler (auf 65 MSPS), sprich die Auflösung steigt, muss zwangsläufig auch die Ordnung des Filters erhöht werden. Ich würde sogar soweit gehen und behaupten, dass die Ordung des Filters mit der Auflösung der zu filternden Daten proportional einher geht. Lieben Dank noch einmal an alle, für die bisher sehr konstruktiven Antworten!! =)
Stephan K. schrieb: > Insbesondere bei der Erhöhung der Samplerate meiner akquirierten Daten > am AD-Wandler (auf 65 MSPS), sprich die Auflösung steigt, muss > zwangsläufig auch die Ordnung des Filters erhöht werden. Ich würde sogar > soweit gehen und behaupten, dass die Ordnung des Filters mit der > Auflösung der zu filternden Daten proportional einher geht. OK, du willst also langsamer sampeln? Kann man da nicht einen Kompromiss machen aus schnell sampeln, dann erstmal ein schlechtes billiges Filter wie einen gleitenden Mittelwert der keine Multiplizierer kostet, und danach dann das FIR Filter.
Gustl B. schrieb: > OK, du willst also langsamer sampeln? Kann man da nicht einen Kompromiss > machen aus schnell sampeln, dann erstmal ein schlechtes billiges Filter > wie einen gleitenden Mittelwert der keine Multiplizierer kostet, und > danach dann das FIR Filter. Hmm, der Ansatz scheint mit garnicht mal blöde! Ich denke, das versuche ich mal. Das langsamer sampeln war angedacht um eine geringere Ordung und evtl. ein serielles FIR zu realisieren.
Stephan K. schrieb: > Ich würde sogar soweit gehen und behaupten, dass die Ordung des > Filters mit der Auflösung der zu filternden Daten proportional einher geht. Da bist Du nicht der einzige, der diese Erkenntnis hat :-) Ich wiederum würde soweit gehen, zu behaupten, dass auch die Abtastfrequenz (in-)direkt in die Ordnungszahl eingeht. Aber jetzt mal im Ernst: Wer sich näher mit der Wirkung der FIR-Filter befasst, der erkennt eigentlich durchs Anschauen der Filterkoeffizienten, wie sie wirken und die Schlussfolgerung, dass steigende Anforderungen an Genauigkeit, Spektrum, Trennvermögen der Bänder und eine erhöhte Abtastrate unweigerlich eine steigende Dichte dieser Punkte zur Folge haben müssen! Es ist freilich so, dass nicht mit allen Parametern linear erfolgt, d.h.die Forderungen nach gleichzeitig doppelter Abtastfrequenz und Genauigkeit erfordert nicht etwa auch gleichsam einer Verdopplung der Koeffizientengenauigkeit UND - anzahl. Da dominiert oft ein Faktor den anderen. Wie man zu optimalen Koeffizienten gelangt: Viele Filter bauen, Länge und Tiefe variieren, durchsimulieren und Messen und das Ganze mit Anforderungen vergleichen und daran Prinzipien erkennen. Ein paar einfache Regeln gibt es freilich: Wenn Du z.B. 16 Bit Daten mit 20Hz bis 20kHz erfassen möchtest und mit 48kHz abtastest, dann ist irgendwie schlüssig, dass 128 TAPs ein bissl wenig sein werden, weil der Überdeckungsbereich von 48000/128 gerade mal 375Hz Auflösung sind. Du darfst jetzt mal schätzen, wieviele FilterTAPs man braucht, um auf unter 16Hz "runterzukommen" und dann mit 384KHz abzutasten und dabei 24Bit Audio zu verarbeiten, dass es studiotauglich wird und welche Systemtaktfrequenz ein FPGA haben muss, um das vollsequenziell zu lösen. Dann musst Du noch abschätzen, wie genau diese Mimik aus "analoger" Sicht ist, d.h. wieviel Fehler die Restwelligkeit bringt und kannst daraus die nötige Koeffizientengenauigkeit berechnen. Wenn man das richtig "dick" baut, kommt man auch Filter, die an die 20Bit Güte haben. Wenn man die Architektur klug aufbaut und die Koeffizienten optimiert, kommt man auf eine Architaktur, die im pipeline Betrieb mit 128 Multipliern auskommt und 32 Kanäle mit voller Bandbreite gleichzeitig berechnen kann. http://www.96khz.org/htm/spectrumanalyzer2.htm Mit etwas Gehirnschmalz auch als Kompressor: http://www.96khz.org/htm/multibandcompressor2.htm
Stephan K. schrieb: > Ist es sinvoll möglich die Filterkoeffizienten von der Filterarithmetik > bei einem FPGA zu trennen, sodass die Koeffizienten im Nachhinein, nach > der Synthes über bspw. eine UART-Verbindung, in gewissen Grenzen, > geändert werden können? Wenn du die FIR nicht parallel berechnen muss, sondern per MAC, dann ist das trivial. Man nimmt dazu ein Dual-Port-RAM. Ein Port zum Beschreiben, der andere liest für den MAC. Parallel ist es schwieriger, aber nicht unmöglich ... Die Antwort ist: It depends ... Du musst dir vorher Gedanken darüber machen, wie lang dein FIR ist und wie schnell du Ergebnisse benötigst, dann kannst du dich entscheiden. Ich hab schon 1024-Tap FIR Filter als MAC implementiert (44,1kHz), ich hab auch schon 64-Tap-FIR-Filter parallel implementiert (4,318...MHz) ... Kommt halt drauf an, was du brauchst.
Jürgen S. schrieb: > Du darfst jetzt mal schätzen, wieviele FilterTAPs man braucht, um auf > unter 16Hz "runterzukommen" und dann mit 384KHz abzutasten und dabei 24Bit Audio > zu verarbeiten, dass es studiotauglich So an die 24000 Taps, wenn nicht es doppelte, wenn ich bedenke, dass für eine so große Bittiefe ein Multiplier (bsp.: 18x18) alleine nicht reicht. Das ist eine ganz schöne Menge an Holz! Da gehört bei eine FIR mit 128 Multiplier bei 32 Kanälen mit voller Bandbreit sicher einiges an Erfahrung und Gehirnschmalz dazu. Wie ja auch schon erwähnt: > Viele Filter bauen, Länge und Tiefe variieren, durchsimulieren und > messen und das Ganze mit Anforderungen vergleichen und daran Prinzipien > erkennen. Zu einem endgültigen Resultat bin ich zwar noch nicht gekommen, aber ich habe mich mal weiter mit dem Erfahrungsgewinn befasst. Ein großes Dankeschön nochmal an euch alle für die schnelle und sehr hilfreiche Disskusion! In diesem Sinne noch allen miteinander einen hohen Wirkungsgrad. ;)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.