
Hallo zusammen, in einer MySQL Datenbank erfasse ich etwa alle fünf Sekunden Werte von einem digitalen Stromzähler. Bsp.-Daten: # Zeit, L1_Volt, L2_Volt, L3_Volt, P_TOT_W 2017-04-25 19:30:03, 232.627228, 231.493378, 232.665558, 252.527847 2017-04-25 19:30:08, 232.753128, 231.586182, 232.804398, 260.947083 2017-04-25 19:30:14, 232.534912, 231.665314, 232.898071, 251.369705 2017-04-25 19:30:19, 232.350647, 231.383728, 232.694733, 250.758667 2017-04-25 19:30:24, 232.350647, 231.383728, 232.694733, 252.172333 2017-04-25 19:30:30, 232.211853, 231.569550, 232.744980, 252.789536 2017-04-25 19:30:35, 231.965744, 231.628235, 232.639053, 250.593048 Dargestellt werden die Daten mittels PHP/JavaScript im Zeitfenster von 1h. (siehe Anhang, Chart zeigt nur P_TOT_W) Gerne möchte ich nun auch längere Zeiträume (z.B. einen Tag) in diesem Chart "schön" anzeigen lassen. Aufgrund der Auflösung (5sek.) kommen da pro Tag 17280 Datensätze rein. Problem: Darstellung/Erstellung des Charts dauert bei einem Tag recht lang und selbiger sieht dann schrecklich aus. Nur jeden x-ten Datensatz darstellen fällt weg da zu Ungenau. Meine Idee wäre es, x Datensätze zusammen zu fassen (Gruppe bilden) und aus diesen Werten der Gruppe einen Durchschnittswert zu ermitteln welcher dann an den Chart geht. Hier weiß ich bloß nicht mehr weiter. Gerne würde ich das ganze direkt mit MySQL abbilden. Habt Ihr eine Idee/Vorschlag wie ich das lösen könnte? Herzlichen Dank! Grüße Michael
Angehängte Dateien:
-

chart.JPG
36 KB
wäre das nicht eine ideale Anwendung für die RRD-Tools? https://de.wikipedia.org/wiki/RRDtool -> http://oss.oetiker.ch/rrdtool/
Thomas S. schrieb: > wäre das nicht eine ideale Anwendung für die RRD-Tools? Ich denke, es ist eher eine absolute Standardanwendung für den Nachweis der grundlegenden Beherrschung von SQL... Riecht sogar fast nach Hausaufgabe und stinkendfaulem Studiosi...
Danke schon mal für Eure Antworten! @thoern & @Jan Hansen: Also AVG wäre soweit klar, mit GROUP BY benötige ich wohl aber noch eine weitere Information in der Tabelle, oder? Also sowas wie eine weitere Spalte mit einer durchnummerierung (z.B. bei drei gruppierten Werten: 1,1,1,2,2,2,3,3,3,4,4,4,...), danach darauf dann die GROUP BY Funktion anwenden? @Thomas Sch.: Dieses mächtige Tool hatte ich bereits auf dem Schirm. Bin davon bloß wieder abgekommen da ich eine "interaktivere" Darstellung als Chart wollte (anstelle eines gerenderten Bildes). Zusätzlich kann man mit JavaScrip recht einfach weitere Daten-Manipulationen im Browser des Client durchführen lassen ohne den Server zu belasten. @c-hater: Haters gonna hate
c-hater schrieb: > Thomas S. schrieb: > >> wäre das nicht eine ideale Anwendung für die RRD-Tools? > > Ich denke, es ist eher eine absolute Standardanwendung für den Nachweis > der grundlegenden Beherrschung von SQL Wenn du auch nur einen Hauch einer Ahnung von rrdtool hättest, dann würdest du nicht so einen Unsinn schreiben. Das kann nämlich bedeutend mehr als nur Grafiken aus Zeitreihen bauen. MySQL (und die meisten anderen relationalen Datenbanken) sind eher lausig, wenn es um die Speicherung und Verarbeitung von Zeitreihendaten geht. Man kann das zwar hinklöppeln (BTDT) aber es ist alles andere als schön. Oder resourcenschonend. Wenn man das professioneller als mit rrdtool angehen will, dann sollte man sich Prometheus oder InfluxDB ansehen.
SELECT AVG(L1_Volt), AVG(L2_Volt), ... FROM TABELLE GROUP BY Zeit Wenn denn dein Zeit schon ein Datum ist und damit der entsprechende Tag nach dem du gruppieren willst. Ansonsten halt DATE_FORMAT verwenden.
Axel S. schrieb: > Wenn man das professioneller als mit rrdtool angehen will, dann sollte > man sich Prometheus oder InfluxDB ansehen. Oder ein ELK-Stack um völlig zu übertreiben. Bei MySQL sollte man die Daten allerdings wirklich irgendwann aggregieren / zusammenfassen.
Michael F. schrieb: > > @Thomas Sch.: > Dieses mächtige Tool hatte ich bereits auf dem Schirm. Bin davon bloß > wieder abgekommen da ich eine "interaktivere" Darstellung als Chart > wollte (anstelle eines gerenderten Bildes). Zusätzlich kann man mit > JavaScrip recht einfach weitere Daten-Manipulationen im Browser des > Client durchführen lassen ohne den Server zu belasten. > > in einer MySQL Datenbank erfasse ich etwa alle fünf Sekunden Werte > von einem digitalen Stromzähler. Über welchen Zeitraum (1 Tag/ 1 Woche/ ..) benötigst Du die Daten mit einer gleichbleibenden Auflösung von 5 sec ? Wie groß wird dadurch Deine Datenbank Im Lauf der Zeit? Bei "richtiger" Definition liefert Dir eine RRD-"Datenbank" sowohl die benötigte Zeitauflösung als auch eine sinnvolle Größenbegrenzung. Alternative: Du erzeugst Dir individuelle RRD-Sets, und fütterst diese mit Abfragen aus der SQL-DB. Die Grafik kannst Du dann immer noch interaktiv aufbereiten. DIe RRDtools-Tutorials sind da hilfreich. Edit: Lösung(s-Skizze) mit Abfrage; http://www.office-loesung.de/ftopic252086_0_0_asc.php Beitrag von Willi Wipp; 13. Aug 2008, 12:56 Edit: Es wäre hilfreich, wenn Du Deine (Zwischen-)Lösung hier vorstellst.
Angehängte Dateien:
-

Stromverbrauch.PNG
60 KB
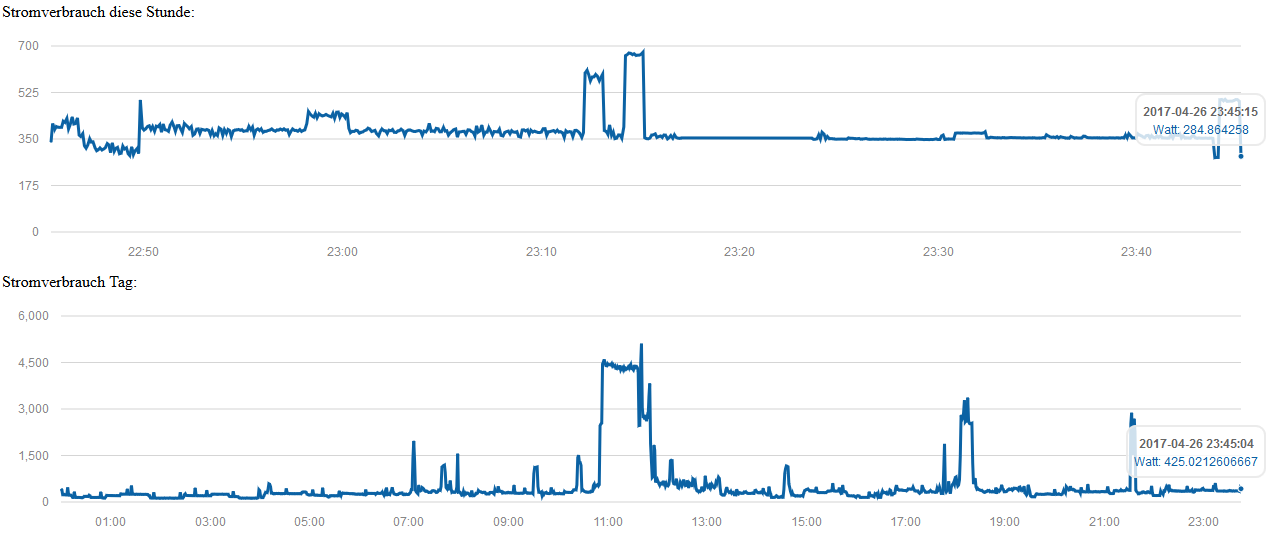
>Thomas Sch.: >Über welchen Zeitraum (1 Tag/ 1 Woche/ ..) benötigst Du die Daten mit >einer gleichbleibenden Auflösung von 5 sec ? So genau habe ich mir das noch gar nicht überlegt - Ich würde jetzt einfach mal auf einen Monat tendieren, nach diesem Monat dann AVG auf eine Minute und nach einem Jahr AVG auf eine Stunde. - Ja glaub das hört sich nicht schlecht an :) >Thomas Sch.: >Wie groß wird dadurch Deine Datenbank Im Lauf der Zeit? Die Datenbank läuft nun etwa einen Monat und hat eine Größe von ca. 65MB - DBDump wird jeden Tag erstellt. Dein Link (http://www.office-loesung.de/ftopic252086_0_0_asc.php) hat mich weitergebracht und behandelt eigentlich genau mein Problem. Habe nun den Access/MSSQL Query vom letzten Post (von ukug14) auf MySQL umgeschrieben. Folgendes ist dabei raus gekommen:
1 | SELECT DAY(Zeit) AS tag, |
2 | HOUR(Zeit) AS stunde, |
3 | MINUTE(Zeit) AS minut, |
4 | Zeit, |
5 | Avg(P_TOT_W) AS VarValue |
6 | FROM Energie.data |
7 | WHERE Zeit >= cast((now()) as date) AND Zeit < cast((now() + interval 1 day) as date) |
8 | GROUP BY DATE(Zeit), |
9 | HOUR(Zeit), |
10 | MINUTE(Zeit) |
11 | ORDER BY DATE(Zeit), |
12 | HOUR(Zeit), |
13 | MINUTE(Zeit); |
Bsp. Output: # tag, stunde, minut, Zeit, VarValue 26, 0, 0, 2017-04-26 00:00:00, 429.2319717500 26, 0, 1, 2017-04-26 00:01:03, 393.0951662727 26, 0, 2, 2017-04-26 00:02:02, 233.4331887273 26, 0, 3, 2017-04-26 00:03:00, 232.3503825000 26, 0, 4, 2017-04-26 00:04:03, 242.4057950000 26, 0, 5, 2017-04-26 00:05:02, 228.5809590000 26, 0, 6, 2017-04-26 00:06:00, 226.7020874167 26, 0, 7, 2017-04-26 00:07:03, 226.1996791818 26, 0, 8, 2017-04-26 00:08:02, 476.4118790909 26, 0, 9, 2017-04-26 00:09:00, 272.0727144167 ... Soweit sieht das ja schon mal nicht schlecht aus. Die ehemals 12Werte/Min. werden nun mittels Durchschnittsberechnung auf eine Minute verdichtet (Habe dies sicherheitshalber einmal händisch nachgerechnet - passt :) ) Im Anhang findet man die Chart-Darstellung der Daten über den gesamten Tag. Morgen nach der Arbeit versuche ich noch ein paar andere Auflösungen darzustellen, z.B. alle 30sek. (also AVG mit 6 Values). Eine gute Nacht! Bis dahin Michael
Prima, das schaut doch schon recht gut aus! Ich bin an der weiteren Entwicklung interessiert. Gruß Thomas
Axel S. schrieb: > Wenn du auch nur einen Hauch einer Ahnung von rrdtool hättest, dann > würdest du nicht so einen Unsinn schreiben. Unsinn schreibst du. Ich habe zwar tatsächlich keine Ahnung davon, was rrdtool kann, ja ich kenne das Dingens nicht einmal dem Namen nach, aber der Punkt ist: man braucht es für die Anwendung des TO auch schlicht nicht. Wahrscheinlich braucht man es sogar nie wirklich, sonst hätte ich nämlich vermutlich schon zumindest mal davon gehört... Wenn man sowieso eine SQL-DB hat, kann die die geforderte Datenaggregation bereits ganz hervorragend alleine. Man muß ihr einfach bloß in ihrer Sprache sagen können, was sie tun soll. > Das kann nämlich bedeutend > mehr als nur Grafiken aus Zeitreihen bauen. Das mag durchaus sein, war aber überhaupt nicht gefordert. Naja: typischer Fall von: "Wenn einer als einziges Werkzeug einen Hammer kennt, sieht für ihn jedes Problem irgendwie wie ein Nagel aus" > MySQL (und die meisten anderen relationalen Datenbanken) sind eher > lausig, wenn es um die Speicherung und Verarbeitung von Zeitreihendaten > geht. Das kommt wohl nur Leuten so vor, die schlicht keine Ahnung von der Macht von SQL haben, weil sich ihre Kenntnisse auf Abfragen der Art "select elephant from africa where tail=short" beschränken... Typisch: eingefleischte C-ler. Die neigen sehr stark dazu, alles, was die DB schon lange kann, nochmal neu zu schreiben. Einfach deswegen, weil sie zu faul waren, SQL wirklich zu erlernen... Und dann fallen sie regelmäßig spätestens dann heftig auf die Fresse, sobald es um Mehrbenutzeranwendungen geht und transaktionale Integrität gewahrt werden muss...
c-hater schrieb: > Axel S. schrieb: > >> Wenn du auch nur einen Hauch einer Ahnung von rrdtool hättest, dann >> würdest du nicht so einen Unsinn schreiben. > > Unsinn schreibst du. Ich habe zwar tatsächlich keine Ahnung davon Dieser Halbsatz ist der einzige in deinem Post, dem ich zustimmen kann. > Wenn man sowieso eine SQL-DB hat, kann die die geforderte > Datenaggregation bereits ganz hervorragend alleine. Man muß ihr einfach > bloß in ihrer Sprache sagen können, was sie tun soll. > >> Das kann nämlich bedeutend >> mehr als nur Grafiken aus Zeitreihen bauen. > > Das mag durchaus sein, war aber überhaupt nicht gefordert. Naja: > typischer Fall von: "Wenn einer als einziges Werkzeug einen Hammer > kennt, sieht für ihn jedes Problem irgendwie wie ein Nagel aus" LOL. Wenn hier einer von uns beiden eine "nur ein Tool für alles" Philosophie vertritt, dann bist das ja wohl du. >> MySQL (und die meisten anderen relationalen Datenbanken) sind eher >> lausig, wenn es um die Speicherung und Verarbeitung von Zeitreihendaten >> geht. > > Das kommt wohl nur Leuten so vor, die schlicht keine Ahnung von der > Macht von SQL haben Nochmal LOL. Du darfst gerne meine Vita checken und dir dann überlegen, ob ich wirklich "keine Ahnung von SQL" habe. Deine Arroganz wäre nur dann halbwegs erträglich, wenn du wüßtest, wovon du redest. So bist du einfach nur peinlich. Du erscheinst mir wie ein Blinder, der partout nicht begreifen will, daß Malerei eine eigenständige Kunstform ist.
Eine hitzige Diskussion - wo ist mein Popcorn? Ach egal, ich mach einfach mal weiter: Ein gutes Stück weiter bin ich heute gekommen. Mein Ziel war es ja eine Auflösung feiner als ein Minute zu bekommen. Nach einigen Versuchen ist nun folgendes dabei heraus gekommen:
1 | SELECT |
2 | DAY(Zeit) AS tag, |
3 | HOUR(Zeit) AS stunde, |
4 | MINUTE(Zeit) AS minut, |
5 | SECOND(Zeit) AS sec, |
6 | truncate(round(SECOND(Zeit) / 21,1), 0) as rounded, |
7 | Zeit, Avg(P_TOT_W) AS VarValue |
8 | FROM Energie.data |
9 | WHERE Zeit >= cast((now()) as date) AND Zeit < cast((now() + interval 1 day) as date) |
10 | GROUP BY DATE(Zeit), |
11 | HOUR(Zeit), |
12 | MINUTE(Zeit), |
13 | rounded |
14 | ORDER BY DATE(Zeit), |
15 | HOUR(Zeit), |
16 | MINUTE(Zeit), |
17 | rounded; |
Resultat: # tag, stunde, minut, sec, rounded, Zeit, VarValue 28, 0, 0, 1, 0, 2017-04-28 00:00:01, 254.6620255000 28, 0, 0, 23, 1, 2017-04-28 00:00:23, 254.2812727500 28, 0, 0, 44, 2, 2017-04-28 00:00:44, 254.6805826667 28, 0, 1, 0, 0, 2017-04-28 00:01:00, 254.7782975000 28, 0, 1, 21, 1, 2017-04-28 00:01:21, 254.1857337500 28, 0, 1, 42, 2, 2017-04-28 00:01:42, 252.3029402500 28, 0, 2, 3, 0, 2017-04-28 00:02:03, 256.1330412500 28, 0, 2, 24, 1, 2017-04-28 00:02:24, 251.7199972500 28, 0, 2, 46, 2, 2017-04-28 00:02:46, 254.6502276667 ... Kurze Erläuterung: Ich nehme jetzt einfach die Sekunden des timestamps 'Zeit' zur Hand und berechne neue Gruppe nach denen ich dann gruppiere. Besser sichtbar wird es, wenn eine Ergebnistabelle ohne dem "GROUP BY rounded" und "ORDER BY rounded" erstellt wird: # tag, stunde, minut, sec, rounded, Zeit, VarValue 28, 0, 0, 1, 0, 2017-04-28 00:00:01, 260.1326600000 28, 0, 0, 7, 0, 2017-04-28 00:00:07, 253.1130220000 28, 0, 0, 12, 0, 2017-04-28 00:00:12, 253.8610690000 28, 0, 0, 17, 0, 2017-04-28 00:00:17, 251.5413510000 28, 0, 0, 23, 1, 2017-04-28 00:00:23, 252.9790340000 28, 0, 0, 28, 1, 2017-04-28 00:00:28, 260.8338320000 28, 0, 0, 33, 1, 2017-04-28 00:00:33, 251.8879390000 28, 0, 0, 38, 1, 2017-04-28 00:00:38, 251.4242860000 28, 0, 0, 44, 2, 2017-04-28 00:00:44, 252.2796780000 28, 0, 0, 49, 2, 2017-04-28 00:00:49, 251.9911040000 28, 0, 0, 54, 2, 2017-04-28 00:00:54, 259.7709660000 28, 0, 1, 0, 0, 2017-04-28 00:01:00, 260.4844970000 ... Im obigen Beispiel erhalte ich die AVG Werte im 20sek. Zeitfenster mit drei Gruppen (0,1,2).
1 | truncate(round(SECOND(Zeit) / 21,1), 0) as rounded, |
Die Zeile aufgeschlüsselt mit Sekunde: 7: 7 / 21 = 0.33333... round(0.33333 ,1) = 0.3 (Auf eine Nachkommastelle runden) truncate(0.3 ,0) = 0 (Nachkommastelle wegschmeißen) Bei 30sek (==6Werte) erhält man zwei Gruppen (0,1) damit würde die rounded Zeile folgendermaßen lauten:
1 | truncate(round(SECOND(Zeit) / 31,1), 0) as rounded, |
Höhere Werte als 30sek. machen keinen Sinn. (Zumindest in dieser Berechnungs- & Verwendungsweise). Die nächsthöhere Vergröberung wäre demnach wieder 1sek. Ich weiß jetzt nur nicht ob das besonders gut gelöst ist, vielleicht hat jemand eine bessere/performantere Vorgehensweise für mich... Ich werde jedenfalls noch weiter experimentieren und gegebenenfalls weiter Berichten. Ein schönes Wochenende Michael
>Ich weiß jetzt nur nicht ob das besonders gut gelöst ist, vielleicht hat >jemand eine bessere/performantere Vorgehensweise für mich... Für das SQL nicht. Aber der Tabelle kannste evtl. einen Index auf die Spalte Zeit spendieren, falls noch nicht vorhanden. Sollte die Perf. um so mehr erhöhen, je selektiver die WHERE clause ist.
Jens G.: >Für das SQL nicht. Aber der Tabelle kannste evtl. einen Index auf die >Spalte Zeit spendieren, falls noch nicht vorhanden. Sollte die Perf. um >so mehr erhöhen, je selektiver die WHERE clause ist. Danke für die Info. Habe danach mal weiter geforscht. Einige Informationen lieferte folgende Seite: http://techblog.tilllate.com/2007/01/07/optimierung-von-mysql-abfragen-verwendung-des-index/ Bei der Prüfung meiner Datenbankabfrage mit vorangestelltem EXPLAIN stellte ich erstaunt fest, dass ein Index bereits verwendet wird. (Deshalb waren auch immer die Abfragen recht flott) Dies hat folgenden selbst verursachten Grund: Als ich damals die MySQL Tabellenstruktur entwarf, dachte ich mir es wäre eine gute Idee den Timestamp (Zeit) als PRIMARY KEY zu verwenden, da ja Sensorwerte zeitliche Abläufe nie in der Vergangenheit eintreffen und somit doppelte Einträge ja nicht möglich wären. Den zusätzlichen overhead für eine weitere Spalte mit einer fortlaufenden UINT-ID könnte ich mir sparen. Da wohl der PRIMARY KEY automatisch von MySQL als Index verwendet wird, war dieser daher bereits aktiv. Nachdem die Tabelle fertig erstellt war und die ersten Datensätze eintrafen, kam ich selbst drauf, dass dieses Design wohl nicht ganz klug war: 1. Das System besitzt keine Pufferbatterie für die Systemzeit. 2. Zeitumstellung von Sommer- auf Winterzeit 3. ... Ich denke da muss ich der Tabelle nachträglich eine Spalte mit einer fortlaufenden ID spendieren, sehe ich das richtig? :/
Oder halt gleich eine GUID/UUID als Primärschlüssel, statt einer fortlaufenden Id. Dann kannst du auch Clientseitig oder anderswo Einträge erstellen und damit arbeiten, auch ohne zu wissen, was die nächste Nummer ist oder ob du die bekommst. So machen wir das auf Arbeit bei uns auch und fahren damit ziemlich gut (ERP mit >700 Tabellen). Generell würde ich dem Primärschlüssel immer abstrakt halten und nicht auf realen Daten beruhen lassen, da sich dessen Anforderungen auch im laufe der Zeit ändern können. (Beispiel bei dir: du willst Daten aus mehreren Zählern speichern, welche ja zufällig auvh mal zu selben Milli-/Mikrosekunde die Daten speichern wollen. Müsstest du dann den Primärschlüssel erweitern auf mehrere Spalten, was sich in den Abfragen und bei Kindtabellen schlecht macht.)
Nur bringt eine extra GUID-Spalte für obiges Scenario überhaupt nix. Wenn Du wegen Somer/Winterzeit doppelte Werte bekommst in der Zeit-Spalte, die mit dem Unique Index (primary Key) in Konflikt gerät, dann könntest Du auch einen normalen Index (nich unique) definieren. Es ist aber sicherlich von der Anwendungslogik her ein Problem, wenn die ZEiten mal Winter-, mal Sommerzeiten sind. Da würde ich eher versuchen, die Zeiten beim Insert bereits auf UTC umrechnen zu lassen. Da gibt's doch sicherlich eine Funktion dafür in MySQL. Oder definierst eine weitere Spalte, die Sommer-/Winterzeit angibt, und nimmst die zusammen mit der Zeitspalte mit in den unique key.
@Jens G.: Ja, ich denke so werde ich das machen. Ich habe glücklicherweise die Flexibilität, dass die Anwendung welche die Daten vom Stromzähler abruft von mir geschrieben wurde. Daher würde ich nun den Zeitstempel in UTC in die DB schreiben. DB Daten schreiben müsste klar sein, jetzt fehlts nur noch an der Zeichnung des Charts. UTC kennt ja keine Sommer-/Winterzeit daher müsste ich die Umwandlung der Zeit zur lokalen Zeitzone iwann entweder schon in SQL oder in PHP durchführen (Ich denke mittels PHP wär es einfacher)!? Und noch was: Bei der Umstellung von Sommer -> Winter habe ich dann ja theoretisch einen 25h Tag darzustellen mit dem Resultat, dass ich 1h doppelte Datensätze erhalte. Was wäre eine elegante Möglichkeit dieses Problem zu lösen? Danke und beste Grüße Michael
Michael F. schrieb: > @Jens G.: > Ja, ich denke so werde ich das machen. Ich habe glücklicherweise die > Flexibilität, dass die Anwendung welche die Daten vom Stromzähler abruft > von mir geschrieben wurde. Daher würde ich nun den Zeitstempel in UTC in > die DB schreiben. Deutlich geschickter wäre die Wahl des Datentyps TIMESTAMP für diese Spalte. Da speichert die Datenbank intern in UTC und nimmt für die Konvertierung in ein menschenlesbares Format die eingestellte Zeitzone. Auf diese Weise klappt es auch mit Sommer/Winterzeit. Siehe https://dev.mysql.com/doc/refman/5.6/en/datetime.html Außerdem wird man im Normalfall nicht nur Daten von einem Sensor in der Tabelle haben, sondern von mehreren. Die Tabellenstruktur wäre also grob
1 | CREATE TABLE sensordaten {
|
2 | sensor_id INT UNSIGNED, |
3 | sample_time TIMESTAMP, |
4 | sensor_data INT, |
5 | PRIMARY KEY (sensor_id, sample_time) |
6 | } |
TIMESTAMP kann seit einigen Jahren Daten auch mit höherer Auflösung als 1 Sekunde speichern. Das wird für deine Anwendung vermutlich unnötig sein, aber ein andermal könnte das nützlich sein. Die eigentlichen Sensordaten können natürlich auch DOUBLE o.ä. sein. Deine Query kannst du auch übrigens auch deutlich einfacher schreiben: Michael F. schrieb: > SELECT DAY(Zeit) AS tag, > HOUR(Zeit) AS stunde, > MINUTE(Zeit) AS minut, > Zeit, > Avg(P_TOT_W) AS VarValue > FROM Energie.data > WHERE Zeit >= cast((now()) as date) AND Zeit < cast((now() + interval > 1 day) as date) > GROUP BY DATE(Zeit), > HOUR(Zeit), > MINUTE(Zeit) > ORDER BY DATE(Zeit), > HOUR(Zeit), > MINUTE(Zeit); z.B. für die Daten von Sensor Nr. 4711 für den aktuellen Tag mit 5-Minuten Mittelwerten:
1 | SELECT |
2 | AVG(sensor_data) as val, |
3 | UNIX_TIMESTAMP(sample_time)/300 AS ts |
4 | FROM sensordaten |
5 | WHERE sensor_id = 4711 |
6 | AND sample_time >= CURRENT_DATE() |
7 | AND sample_time < CURRENT_DATE() + INTERVAL 1 DAY |
8 | GROUP BY ts |
9 | ORDER BY ts ASC |
Siehe https://dev.mysql.com/doc/refman/5.6/en/date-and-time-functions.html Michael F. schrieb: > Bei der Umstellung von Sommer -> Winter habe ich dann ja theoretisch > einen 25h Tag darzustellen mit dem Resultat, dass ich 1h doppelte > Datensätze erhalte. Was wäre eine elegante Möglichkeit dieses Problem zu > lösen? Das ist gar kein Problem. Wenn du wie in der eben gezeigten Query den Ausschnitt des TIMESTAMPs über CURRENT_DATE() bis CURRENT_DATE() + 1 Tag machst, dann ist der Tag mit dem Zeitsprung automatisch 23 bzw. 25 Stunden lang, weil MySQL das bei der Addition des einen Tages automatisch berücksichtigt. Was dann allerdings passiert: für einen langen Tag kriegst du halt mehr Werte als für einen normalen oder einen kurzen. U.a. deswegen kann es sinnvoll sein, die Mittelwertbildung in der Applikation zu machen. Dann kann man auch besser glätten und besser mit fehlenden Werten umgehen. Noch viel geschickter wäre es allerdings, die Daten mit rrdtool abzuspeichern und zu visualisieren. rrdtool kümmert sich dann u.a. auch darum, alte Daten wegzuwerfen bzw. zu konsolidieren. Mit MySQL mußt du das auch händisch machen, wenn dir nicht eines Tages die Platte bzw. Speicherkarte überlaufen soll. Mit rrdtool hat dein Datenfile eine konstante Größe, was äußerst praktisch ist.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.