Hallo ihr alle,
ich habe aus dem Forum eine Routine für 8bit Zufallszahlen genutzt und
etwas abgeändert, so dass ich einen Bereich für die Zufallszahlen
vorgeben kann.
An sich tut die Funktion auch was sie soll, lediglich ist die
Häufigkeitsverteilung noch nicht ok. Der Seed (also Startwert) ist
bisher noch statisch, beliebig gewählt zu 173. Wird später noch durch
eine Zeit zwischen Tastendrücken ersetzt.
Wenn ich die Verteilung mitzähle und über UART ausgeben lasse, sieht man
dass
die Häufigkeit der Zahlen soweit ganz ok aussieht, nur die untere Grenze
wird deutlich öfter getroffen als alle anderen.
wo liegt denn mein Denkfehler?
Vielen Dank!
Johann
Die Funktion Zufallszahl:
Ich nehme mal an, dass der Aufruf von Zufallszahl_holen nochmal in einer
Schleife ist?!
Wozu die nachfolgende Scheife zum hochzählen?
Statt for, if, anzahl[i-untere]++
reicht doch EIN
anzahlen[temptest-untere]++;
Hast du dir mal die Zufallszahlen selbst angesehen? Ist wirklich nur die
Verteilung "ungerecht" ;o), oder wackelt der Zufall ein paar mal hin und
her und spuckt dann nur noch die untere Zahl aus?
Hast du mal die Verteilung der unveränderten Funktion geprüft?
Natürlich, der Aufruf erfolgt in der Hauptschleife.
Ich hatte nur dieses Stück rauskopiert, um mit den restlichen hunderten
von Zeilen nicht die Übersichtlichkeit zu sprengen...
Mit der Schleife hast du natürlich auch recht, ist geändert.
Die Verteilung ist wirklich ungerecht :)
Ich habe nicht alle 10000 Werte durchgesehen, aber die ersten paar
tausend hüpfen schön hin und her.
Die Verteilung der Originalfunktion (hier mal zusammengefasst)
1
temptest=(temptest*17+37);
ist wie erwartet normal und "gerecht", aber ich finde einfach den Fehler
in meinem Code nicht... :(
Mach doch mal ein Histogramm als Bild.
Intuitiv wirkt diese Schleife so auf mich als ob sie kleinere Zahlen
bevorzugt. Vielleicht findest du das auch intuitiv wenn du als
Multiplier mal 1.1 einsetzt und als Constant 1 oder so.
Ordentlich gleichverteilte Zufallszahlen erzeugen ist nicht trivial und
es gibt Algorithmen wie MT
(https://de.wikipedia.org/wiki/Mersenne-Twister) nicht umsonst... ;)
Mir ist vollkommen bewusst, dass es hier keine "echten" Zufallszahlen
hat.
Das brauche ich aber auch nicht.
Ich hab den Controller grad nicht mehr hier, aber aus dem Kopf heraus
sah die Verteilung etwa so aus (10000 Aufrufe, Bereich 5...105):
Zahl Häufigkeit
5 149
6 99
7 98
8 99
9 100
10 99
11 98
....
Und so weiter, alle Werte (ausser halt die untere Grenze) schwanken
zwischen 98 und 100, also für mich ausreichend gleich verteilt. Bloß
halt die erst Zahl etwa 1,5mal häufiger.
Wie gesagt, die Verteilung im oroginalen Code sieht sehr gleichmäßig
aus.
Der Fehler kommt also durch meinen Zusatz für die Bereichseingrenzung.
Aber auch nach ein paar Stunden finde ich den Fehler nicht...
johann schrieb:> Der Fehler kommt also durch meinen Zusatz für die Bereichseingrenzung.> Aber auch nach ein paar Stunden finde ich den Fehler nicht...
Schuss ins Baue: Die Werte, die jetzt jenseits Deiner
Bereichseinschränkung liegen, werden jetzt irgendwie auf die Grenze
gesetzt. Darum gibt es jetzt dort mehr davon.
Klopf den Code mal auf so einen Effekt hin ab. Schau Dir an, was Du mit
Werten machst, die jenseits der Grenze liegen würden.
Wenn es doppelt so oft wäre, wäre das für mich irgendwie plausibel mit
einer falschen Zuordung der Grenzen etc... im Code.
Jedoch 1,5mal so häufig macht in meinen Augen auch mathematisch kaum
Sinn...
Werte die größer als das größte Vielfache kleiner als 255 sind, werden
verworfen und es wird neu "gewürfelt".
Danach wird durch den Modulo auf den passenden Bereich runtergerechnet
und die untere Grenze hinzuaddiert.
C++ troll...
Mach mal ein Histogramm dann kann man was sagen.
Deine zufallsfunktion macht irgendwas aber nix sinnvolles. Wo hast du
das her?
Nimm doch wenigstens ein lfsr oder sowas.
Ach ja zu deinem problem: Modulo ist böse. Zerstört dir die
gleichverteilung. In deiner letzten Zeile. Das ist mist.
Meckerziege schrieb:> C++ troll...
Was ist falsch an C++? Es wurde nach keiner bestimmten Sprache gefragt.
Meckerziege schrieb:> Deine zufallsfunktion macht irgendwas aber nix sinnvolles. Wo hast du> das her?
Aus der Standard-Library-Doku.
Meckerziege schrieb:> Nimm doch wenigstens ein lfsr oder sowas.
Besser, das ist der Mersenne-Twister.
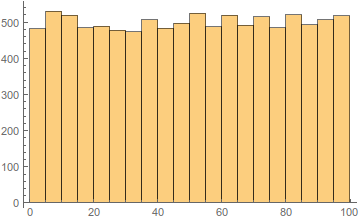
Meckerziege schrieb:> Mach mal ein Histogramm dann kann man was sagen.
Siehe Anhang, für 10000 Werte von 0-99. Passt, würde ich sagen.
Dr. Sommer schrieb:> Meckerziege schrieb:>> Mach mal ein Histogramm dann kann man was sagen.> Siehe Anhang, für 10000 Werte von 0-99. Passt, würde ich sagen.
Seufz, nicht du. Dass der MT aus der C++-Standardbibliothek funktioniert
ist nun wirklich nicht die Bildschirmfläche wert, auf die dieser Post
angezeigt wird.
@johann: nicht-deterministische Zufallszahlen und ordentlich verteilte
Zufallszahlen sind zwei verschiedene Ansprüche. Klar kriegst du keinen
"echten" Zufall, du solltest aber trotzdem näherungsweise eine
Gleichverteilung erzeugen. Und das erreichst du auf diese Art nicht. MT
erzeugt auch keine "echten" Zufallszahlen, aber sehr gut
gleichverteilten Pseodozufall.
johann schrieb:> hoechstGrenze = ((uint8_t)(255/count))*count; //wie oft passt count> in 255? größtes Vielfaches<=255
Count 96, hoechstGrenze 192.
johann schrieb:> wo liegt denn mein Denkfehler?
Es gibt also Werte zwischen 0 und 192 zurück. 0 ist bei 0, 96 und 192,
also 1,5 mal so viel wie die anderen.
johann schrieb:> Werte die größer als das größte Vielfache kleiner als 255 sind, werden> verworfen und es wird neu "gewürfelt".
das ist schon mal Quatsch, damit machst du die mögliche Gleichverteilung
der originalen Funktion kaputt weil du einen Teil der Werte nicht
verwendest.
> Danach wird durch den Modulo auf den passenden Bereich runtergerechnet> und die untere Grenze hinzuaddiert.
du musst den 8-bit-Wert nehmen und auf deinen Wertebereich umrechnen!
Ergebnis = Min + RND(8Bit) * (Max - Min) / 256
Dafür brauchst du noch nicht mal Gleitkommaberechnungen da du Anstelle
der Division einfach die oberen 8Bit des Ergebnisses der Multiplikation
verwenden kannst.
Sascha
Sascha W. schrieb:> johann schrieb:>> Werte die größer als das größte Vielfache kleiner als 255 sind, werden>> verworfen und es wird neu "gewürfelt".> das ist schon mal Quatsch, damit machst du die mögliche Gleichverteilung> der originalen Funktion kaputt weil du einen Teil der Werte nicht> verwendest.
Nein, das ist kein Quatsch (nachdem man den kleinen Fehler korrigiert
hat, s.o.). Erst durch diese Maßnahme sind überhaupt gleichverteilte
Zahlen in einem beliebigen Subintervall des Zufallszahlenwertebereichs
möglich.
> du musst den 8-bit-Wert nehmen und auf deinen Wertebereich umrechnen!> Ergebnis = Min + RND(8Bit) * (Max - Min) / 256Das ist Quatsch, denn genau damit machst du die Gleichverteilung
tatsächlich kaputt.
Mal abgesehen davon, dass es wohl
Ergebnis = Min + RND(8Bit) * (Max - Min + 1) / 256
heißen müsste.
Wenn die Spanne < der max Pseudo-Zufallszahl ist,
versuch mal den folgenden Ansatz:
Multipliziere das ganz normale RANDOM() Ergebnis mit der
gewünschten SPANNE (= 1 + MAX - MIN) und teile das Ergebnis
durch das maximale Ergebnis von RANDOM() + 1. Anschließend
addierst du den gewünschten MIN-Wert.
Ergebnis: Pseudo-Zufallszahlen von MIN...MAX,
dabei haben alle Ausgabewerte des Pseudo-Zufallszahlen-
generators ein Mitspracherecht...
So, also den Grund haben Helmut H. und Yalu X. ja bereits gezeigt.
Jetzt noch ein paar Sachen zum programmieren:
1. Single Responsibility Principle
Eine Funktion soll nur für eine Sache zuständig sein. In deinem Fall
erzeugt sie eine Zufallszahl UND bildet sie auf den gewünschten
Wertebereich ab.
Also solltest du das aufteilen in eine Funktion Zufallszahl_holen() und
eine Funktion Zufallszahl_Bereich(...), die ihrerseits die erste
Funktion aufruft.
Ich weiß dass dieser Ratschlag ungefragt kommt, aber bedenke die
Vorteile:
* du sparst Code-Aufdoppelungen. Statt 2 mal die Formel im Code zu haben
kannst du einfach die gleiche Funktion aufrufen.
* Wenn du irgendwann den MYRAND_MODULO einführen willst musst du nur
eine Stelle im Code ändern. Dito falls du mal eine ganz andere Formel
verwenden willst. (Probier mal den Blum-Blum-Shub Generator.)
* Es hilft bei der Fehlersuche. Du hättest die Verteilung deines
Zufallsgenerator und die Logik mit dem Bereich getrennt prüfen können.
Um dann festzustellen, dass das Ergebnis des Zufallszahlengenerators
noch ok ist. Oder alternativ in der Bereichslogig einen anderen
"Zufallszahlengenerator" aufrufen, der die garantiert gleichverteilte
Folge 1,2,3,4,... liefert.
2. Die Zeile "if (g_nLastRandom>hoechstGrenze)" kann weg weil das vom
while mit erledigt wird.
Grüße, Tilo
@Jakob
So ganz hast du noch nicht verstanden, wofür die count Variable ist. Es
geht darum, dass man von dem Zufallszahlen-Bereich nur ein ganzzahliges
Vielfaches der SPANNE, wie du es nennst, benutzt wird.
Warum?
Weil sonst die Gleichverteilung flöten geht. Bei deinem Vorschlag
entstehen durch die Division Nachkommastellen, die Abstände von
benachbarten Zahlen im Zahlenbereich beträgt aber 1.
Mit anderen Worten ... Bei einem ganzzahligen Vielfachen kann man die
Verteilung gleichmäßig auf den gewünschten Zahlenbereich verteilen. Die
Verteilung der übrigen Zahlen kann man nicht mehr gleichmäßig verteilen.
Yalu X. schrieb:> [...]> Das ist Quatsch, denn genau damit machst du die Gleichverteilung> tatsächlich kaputt.>> [...]
Yalu hat durchaus recht.
Es wäre vielleicht aber doch sinnvoll, einmal zu erklären, warum diese
Umrechnung die Verteilung beeinflusst.
Es sei vorausgesetzt, dass die Funktion diskrete Zufallszahlen, also
Integers, in dem Intervall [a,b] erzeugt. Weiter sollen wiederum
diskrete Zufallszahlen in dem Intervall [c,d] erzeugt werden. Es sei b >
a bzw. c > d.
Hilfsweise ist die Anzahl der Elemente m in dem Intervall [a,b] m = b -
a + 1; ebenso die Anzahl der Elemente n in dem Intervall [c,d] n = d - c
+ 1.
Dann ergeben sich zwei Fälle (abgesehen von dem Fall gleich grosser
Intervalle m = n):
1. Der neue Bereich [c,d] ist kleiner als der Bereich [a,b]; also m > n.
In diesem Fall ergeben sich durch Rundung bei der Umrechnung in das neue
Intervall, je nach Wahl der Grenzen etc. mindestens zwei Zahlen aus dem
Intervall [a,b] die der selben Zahl aus dem Intervall [c,d] zugeordnet
werden.
D.h., die Häufigkeit dieser zweiten Zahl aus dem Intervall [c,d] ist
mindestens doppelt so hoch, wie die der Ursprungszahlen.
2. Der neue Bereich [c,d] ist grösser als der Bereich [a,b]; also n > m.
In diesem Fall ergeben sich [...] mindestens zwei Zahlen aus dem
Intervall [c,d] die der selben Zahl aus dem Intervall [a,b] zugeordnet
werden können. D.h., die Häufigkeit dieser zweiten Zahlen ist halb so
gross wie die der Ursprungszahlen.
Die Verteilung bleibt nur dann erhalten, wenn beide Intervalle, das
ursprüngliche der Zufallszahlenerzeugung und das neue der Umrechnung
reelle Zahlen sind. Auf dem Computer ergibt sich aber das zusätzliche
Problem, dass aufgrund der begrenzten Bitanzahl nicht alle bei der
Berechnung sich ergebenden reellen Zahlen darstellbar sind. Die nötige
Bitzahl lässt sich aus dem Verhältnis der Elemente in den Intervallen
ermitteln.
Da aber in diesem Fall ohnehin diskrete Werte, d.h. Integerzahlen,
erzeugt werden sollen, liesse sich die Routine so ändern, dass der
ursprünglich verwendete Modulo-Wert (der in dem Code des TOs implizit
durch Modulo-Operation auf 2^8 ersetzt wurde) wieder ausdrücklich
verwendet wird und zu k (d.h. die Anzahl der Elemente in dem Intervall)
gesetzt wird. Ein evtl. von Null verschiedene Grenze kann dann
nachträglich addiert werden; das beeinflusst die Verteilung nicht, wie
sich erschliesst, wenn man obige Überlegung für diesen Fall
nachvollzieht.
Auf diese Weise ist die Erzeugung der Zufallszahl eine Operation (nicht
eine Wiederholung bis das Ergebnis im gewünschten Intervall liegt).
Es muss aber auch bemerkt werden, dass dieses Verfahren zwar recht gut
gleich verteilte Werte erzeugt, aber doch keine Gleichverteilung im
strengen Sinn. (Entsprechende Diskussionen lassen sich im Internet
leicht finden. Chi-Quadrat-Test wäre ein Stichwort).
Ich hoffe das hilft weiter.
Tilo R. schrieb:> Jetzt noch ein paar Sachen zum programmieren:>> 1. ...>> 2. ...
3. Die Semikola nach den Blockklammern kannst du weglassen (an zwei
Stellen hast du das schon getan). Hier stellen sie zwar keinen Fehler
dar, in einem anderen Fall tun sie das aber schon:
Hallo Zusammen,
und vielen Dank an Helmut und Yalu für die Hinweise.
Das war der Fehler, nun sieht die Verteilung schick aus und einen Schutz
vor Div0 habe ich auch noch eingebaut.
Danke Leute :)