Hallo,
leider wurde der Anfangs-Thread hierzu geschlossen.
Die Anfänge und die Gründe dafür, kann man dort nachlesen. Da es beim
genannten Thread keinen Verweis zu diesem gibt, entsteht, wenn man den
genannten Thread zuerst aufruft, der Eindruck, daß es sich mehr oder
weniger um eine Datenleiche handelt. Deshalb wäre es gut, wenn einer der
Moderatoren am Ende des geschlossenen Threads einen Link hier her machen
könnte.
Es geht um den Mikrocontrollertechnik-Kursus Modul A von Guy Weiler.
http://www.weigu.lu/tutorials/avr_assembler/pdf/MICEL_MODUL_A.pdfhttp://www.weigu.lu/tutorials/avr_assembler/index.html
Ich bin nun auf der Seite 82 bei der Aufgabe A405. Das Programm habe ich
mit den bis dahin vorgestellen Befehlen geschrieben und möchte nun mal
ein Programm sehen, das die Aufgabe Geschwindigkeitsoptimiert erledigen
würde.
Diese Version benötigt 4644 Zyklen für die 778 Daten bzw. 'B'.
Bernd S. schrieb:> Diese Version benötigt 4644 Zyklen für die 778 Daten bzw. 'B'.
Es sind ganz sicher deutlich weniger.
Hab' keine Lust genau nachzurechnen, aber schon ein grober Überschlag
sagt: du bist bei der Beherrschung von Assembler immer noch keinen
Schritt weiter. Du kannst immer noch nicht einmal den
Rechenzeitverbrauch einer gegebenen Routine korrekt ermitteln...
Damit du wenigstens kapierst, wie man sowas überschlägig ermittelt:
Die innere (immer ausgeführte) Schleife braucht 5 Takte, 778 mal
durchlaufen=3890.
Durchlaufen auch der äußeren Schleife erfordert einen Mehraufwand von 2
Takten, wird aber hier allerhöchstens 4 mal passieren->kann man in den
Skat drücken, genauso wie den "statischen" Teil ausserhalb der
Schleifen. Zusammen macht das maximal 12 Takte.
Überschlägig also insgesamt ca. 4000 Takte. Das ist ein ordentliches
Stück von dem weg, was du (wie auch immer) "ermittelt" hast...
> Ich bin nun auf der Seite 82 bei der Aufgabe A405. Das Programm habe ich> mit den bis dahin vorgestellen Befehlen geschrieben und möchte nun mal> ein Programm sehen, das die Aufgabe Geschwindigkeitsoptimiert erledigen> würde.
Du kannst nicht erwarten, dass ein Programm optimiert ist, wenn die
Aufgabe direkt vorgibt, suboptimal zu sein (weil hier der Plan nicht
war, ein optimales Programm zu schreiben, sondern dem Lehrling die
Verwendung einer bestimmten Adressierungsart zu vermitteln).
Für optimalen Code gibt es viele Strategien.
Bei sehr engen Schleifen ist natürlich "loop unrolling" immer eine sehr
attraktive Strategie. Die Idee dahinter ist, den Verwaltungsaufwand für
die Schleifensteuerung im Verhältnis zum Nutzcode im Schleifenrumpf zu
reduzieren. Im konkreten Fall benötigt der Nutzcode der inneren Schleife
2 Takte, die Schleifensteuerung aber 3. Das ist ein sehr schlechtes
Verhältnis, nur in 2/5 der Zeit macht der Code, was eigentlich sein
Job ist. Da kann man ganz sicher einiges dran verbessern...
Richtig Assembler programmieren können bedeutet: selber herausfinden,
was genau (ohne Beschränkung durch eine lehrhafte Aufgabenstellung) und
dies dann auch fehlerfrei umzusetzen. Dabei hilft dir kein Tutorial,
sondern nur eigenes Denken. Das Tutorial soll nur dazu dienen, dir die
nötigen Grundlagen zu vermitteln, also die vollständige Beherrschung des
Befehlssatzes.
Denn nur, wenn du weisst, was geht, kannst du aus dem, was geht, das
wählen, was sinnvoll ist,um die konkrete Aufgabe bezüglich der konkreten
Anforderungen optimal umzusetzen. Für die konkrete Aufgabe würde ein
richtiger Assemblerprogrammierer z.B. mit an Sicherheit grenzender
Wahrscheinlichkeit eher nicht "indirect with postincrement" als
Adressierungsart wählen, sondern "indirect with predecrement". Aber wie
schon gesagt: es handelt sich um eine Lehraufgabe für Dummies...
Du musst vor allem auch Lernen, dass Optimierung nahezu immer ein
Kompromiss zwischen Codegröße und Rechenzeit ist. Doofe Compiler können
nur immer in eine Richtung optimieren. Richtige Assemblerprogrammierer
hingegen kennen das Gesamtproblem und können von Fall zu Fall
entscheiden, wie stark an welcher Stelle des Codes in welche Richtung zu
optimieren ist. Vor allem deswegen sind sie cleverer als Compiler und
können besseren Code erzeugen als diese.
Das "loop unrolling" ist übrigens ein recht einfach überschaubares
Beispiel, um sich diese Sachverhalte grundlegend klar zu machen.
Interessant ist da auch der Vergleich mit einem echten Compiler im
Kontext eines realen Programmes. Nur sehr selten finden diese
unsäglichen Dinger die optimale Größe für das Unrolling. Nur zu deutlich
sieht man, dass nach 50 Jahren im Wesentlichen immer noch nur ziemlich
dumme Macros den Übersetzer-Job machen, die nach wie vor keinerlei
Ahnung vom Gesamtproblem haben...
c-hater schrieb:> Interessant ist da auch der Vergleich mit einem echten Compiler im> Kontext eines realen Programmes. Nur sehr selten finden diese> unsäglichen Dinger die optimale Größe für das Unrolling.
Bei den 8-bittern spielt eher die Integer-Promotion eine Rolle, die oft
überflüssige Instruktionen einfügt.
Für größeres Loop Unrolling hat ein AVR üblicherweise zuwenig Flash.
Dafür kann aber der Compiler nix. Bei AVR-GCC kann man das mit "-O3" mal
versuchen.
Moderne C-Compiler sind oftmals schneller und effizienter als
manueller Assembler, insbesondere bei 32-bittigen Plattformen.
Man sollte Effizenz auch nicht überbewerten. Wenn ich den Code bis auf
die letzte Assembler Instruktion optimieren muss habe ich in der Auswahl
der Hardware was falsch gemacht. Für zeitkritische Sachen haben moderne
µC normalerweise dedizierte Peripherie eingebaut.
$400-$60 = 928
928*5 -1 +5 = 4644 (ohne das nop)
So viel zur "Beherrschung von Assembler".
Im Übrigen sehe ich keine große Einsparmöglichkeit, solange die
Fragestellung so allgemein ist; von den erwähnten zwei Zeilen mal
abgesehen, aber das sind ja nur 2 Takte.
Rene Z. schrieb:> Bei mir ist A405 auf Seite 72.> cpi yl,$00> brne _NEXT>> kannst du dir sparen. Wenn YH das erste mal 0x04 wird muss YL = 0 sein.>
Danke, gleich der erste Beitrag, der wirklich auf die Fragestellung
eingeht. Sind zwar nur 2 Takte, wobei wir nun bei insgesamt 4642 sind,
aber das war ja das Ziel für mich, so wenig Takte wie möglich für diese
Aufgabe zu benötigen.
Du hast schon recht, aber wenn mann in dem Acrobat Reader die 82 angibt,
kommt man zu der Seite, die ich in diesem Dokument meine.
Zu diesen Zeitpunkt hatte ich gar nicht weiter überlegt, weil ich die
Aufgabe mit diesen Pre-Dekrement und Post-Inkrement nicht so richtig
wahrgenommen hatte und dadruch erst zwei Varianten mit Pre-Dekrement
durchgespielt habe, wo auf die " Nullabfrage " nicht verzichtet werden
kann.
1
ldi r16,'B'
2
ldi yh,$04
3
ldi yl,$00
4
_NEXT:
5
st -y,r16
6
cpi yl,$60
7
brne _NEXT
8
cpi yh,$00
9
brne _NEXT
10
nop
11
12
.EXIT
4650 Zyklen bzw. Takte
1
ldi r16,'B'
2
ldi yh,$04
3
ldi yl,$00
4
_NEXT:
5
st -y,r16
6
cpi yh,$00
7
brne _NEXT
8
cpi yl,$60
9
brne _NEXT
10
nop
11
12
.EXIT
4962 Takte
Hatte irgendwie noch aus alten C64-Zeiten im Sinn, das es von Vorteil
ist Schleifen Abwärts auf Null hin laufen zu lassen, wegen der einfachen
Auswertung des Zero-Flags.
Schon interessant wie man durch vorher richtiges Überlegen, mal eben für
die gleiche Aufgabe bis zu 320 Takte einsparen kann.
c-hater schrieb:> ...->kann man in den> Skat drücken,....>> Bei sehr engen Schleifen ist natürlich "loop unrolling" immer eine sehr> attraktive Strategie...>
Erst einmal danke für deinen ausführlichen Beitrag. Jedoch bitte ich
dich zu bedenken, das ich mir das ASM-Programmieren selber beibringe und
daher so eingefleischte Profiausdrücke ( Skat; loop unrolling ) gar
nicht interpretieren kann.
>> Für die konkrete Aufgabe würde ein> richtiger Assemblerprogrammierer z.B. mit an Sicherheit grenzender> Wahrscheinlichkeit eher nicht "indirect with postincrement" als> Adressierungsart wählen, sondern "indirect with predecrement".>
In diesem Fall, den ich ich genaustens vorgebe hast du allerdings
unrecht.
S. Landolt schrieb:> $400-$60 = 928> 928*5 -1 +5 = 4644 (ohne das nop)>
Ich habe mich bei der Taktangabe einfach auf den Simulator verlassen,
aber natürlich einen groben Fehler gemacht $03A0 ist eben nicht 3x256 +
10, sondern 3x256 + 10x16 = 928. Schön, das du zwischendurch auch mal
C-hater von seinem hohen Ross geholt hast ;-)
Bernd_Stein
Habe die Aufgabe A406 auf der Seite 83 so umgesetzt. Es kommen ja 168 x
8 = 1344 Daten vor ( 1344 = 7 Tage x 24 Stunden x Datensatz (8) ).
An Adresse $0100 wird der Mittelwert von Sensor 1 abgelegt usw.,
so daß der letzte Sensorwert ( Sensor 8 ) der Woche in Adresse $063F
abgelegt wurde. Der ATmega8 hat hierfür zu wenig internen SRAM, so daß
der ATmega32 im Simulator zu verwenden ist.
Nun dachte ich mir bei solchen Konstrukten ( adiw y,8 ) ist es
vielleicht besser, bei der Lowbyte-Adresse nicht genau die Endadresse zu
überprüfen, sondern lieber auf größer oder gleich, falls man sich mal
beim ausrechnen der Endadresse vertut.
Die " Arbeitsregisterverschwendung " dient des bessern Überblicks beim
Simulatordurchlauf.
Was haltet ihr davon ?
1
ser r16 ;Alle Pins von...
2
out DDRD,r16 ;...PortD als Ausgang konfigurieren
3
ldi yh,$01 ;Zeiger fuer die indirekte und...
4
ldi yl,$00 ;...indirekte Adresssierung mit Offset konfigurieren
5
_NEXT:
6
ldd r3,y+2 ;Sensor 3 Wert einlesen
7
ld r1,y ;Sensor 1 Wert einlesen
8
ldd r5,y+4 ;Sensor 5 Wert einlesen
9
out PORTD,r3 ;Sensor 3 Wert ausgeben
10
out PORTD,r1 ;Sensor 1 Wert ausgeben
11
out PORTD,r5 ;Sensor 5 Wert ausgeben
12
adiw y,8 ;Zeiger auf den naechsten Datensatz setzen
Mich wundert das sich niemand an meinem Text zum BRLO-Befehl stört.
Ich meine aus einem anderen Blickwinkel passt es ja schon, aber zu BRLO
-> Branch if Lower = If Rd < Rr bzw. C=1 ( BRCS -> Branch if Carry-Flag
ist Set ), geht ja eigentlich hervor, das so oft gesprungen werden
soll, so lange Rd kleiner ist als K. Ja, das ist schon alles ziemlich
verwirrend mit den Sprungbefehlen.
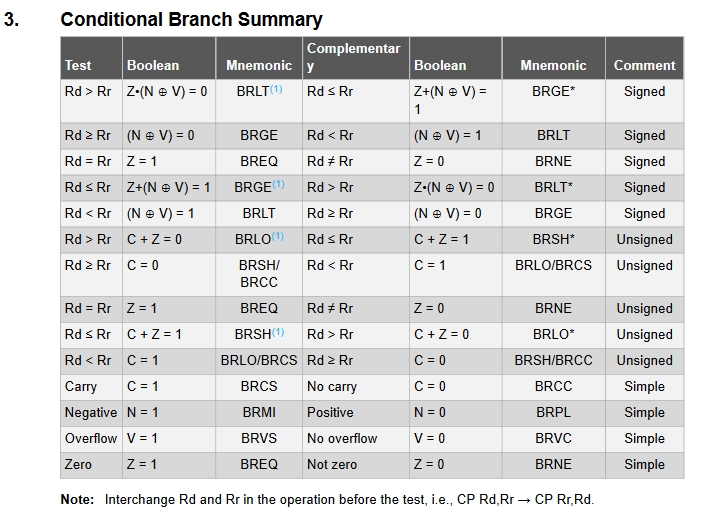
Seht den Anhang. Was wollen die mir mit NOTE : sagen ?
Meinen die nun Sternchen oder (1) ?
Bernd_Stein
Hi
Ich programmiere seit mitte der 80er in Assembler. Und in dieser Zeit
bin ich zu >95% der Fälle mit Sprüngen in Abhängigkeit von Z oder C
ausgekommen. Deine permanente Krümelkackerei hilft dir also auch nicht
wesentlich weiter.
>Meinen die nun Sternchen oder (1) ?
Das Sternchen steht in der gleichen Zeile wie (1). Du kannst es dir also
aussuchen.
MfG spess
Bernd S. schrieb:> geht ja eigentlich hervor, das so oft gesprungen werden> soll, so lange Rd kleiner ist als K.
Nein, aus brlo geht nur hervor daß solange gesprungen wird solange C=1.
Welche Ursache C=1 nun hat ist eine ganz andere Frage. Das kann z.B.
eine Vergleichsoperation sein. Dabei wird der 2.Registerwert schlicht
vom ersten abgezogen (insofern gilt es also auf die richtige Reihenfolge
zu achten). Wird das Ergebnis dabei negativ ist C gesetzt und brlo
springt. Fertig und aus.
> Ja, das ist schon alles ziemlich> verwirrend mit den Sprungbefehlen.
Eigentlich nicht. Zu jedem Sprungbefehl ist doch klar definiert welches
Flag den Sprung auslöst.
spess53 schrieb:> Das Sternchen steht in der gleichen Zeile wie (1). Du kannst es dir also> aussuchen.>
Aha, das ist also so etwas wie eine ungeschriebene Regel oder was ?
>> Deine permanente Krümelkackerei hilft dir also auch nicht> wesentlich weiter.>
Die kommt nicht von mir sondern von ATMEL ;-)
Also ich will nochmal genauer erklären, was mich verwirrt.
In der gezeigten Tabelle steht bei Unsigned BRLO => Rd > Rr ; C+Z=0.
Oh, erkenne gerade meinen ersten Denkfehler + bedeutet nicht UND sondern
ODER.
Ok, die andere Sache ist, dass bei der Befehlsbeschreibung aber
If Rd < Rr ( C=1 ) steht und man dann erkennen muss, das dies das Selbe
bedeutet. Hinzu kommt bei mir, das man beim CPI-Befehl Rd und K nicht
tauschen kann.
Außerdem impliziert in der Tablle Branch if lower, das Rr bzw. K kleiner
sein müsste als Rd, was in der Befehlsbeschreibung aber genau umgekehrt,
aber " richtiger " ( Rd < Rr ) ist.
Zum anderen ist BRLO, genau dass Selbe wie BRCS, weshalb du auch ganz
gut zu 95% der Fälle mit dem Z oder C-Flag zurechtkommst !
Wen das alles als Anfänger nicht verwirrt, der ist für mich wirklich ein
Naturtalent.
Aber nun zur ursprünglichen Frage - würdest du die abschließende Prüfung
in meinem Programmbeispiel nun mit BRCS oder BRNE machen und warum ?
E.Ehrhart schrieb:> Nein, aus brlo geht nur hervor daß solange gesprungen wird solange C=1.>> Zu jedem Sprungbefehl ist doch klar definiert welches> Flag den Sprung auslöst.>
Nein, aus dieser Scheißtabelle eben nicht siehe C+Z=0. Klar ist dies nur
in der Befehlsbeschreibung und die habe ich ja gar nicht hier hoch
geladen.
Vielleicht, sollte ich versuchen diese Tabelle aus meinem Kopf zu
streichen, genauso wie die Befehle BRLO und BRSH.
Bernd_Stein.
Kommen wir zur Aufgabe A407. Hier geht es um Cut&Paste. Also der
SRAM-Bereich $0060 bis $01FF soll gelesen und in den SRAM-Bereich $0300
bis $049F kopiert werden. Anschließend wird der erste Bereich $0060 -
$01FF mit dem Nullbyte ( $7F ) überschrieben.
Geht das schneller als mit 5315 Takten ?
1
ldi xh,$00 ;X-Zeiger...
2
ldi xl,$60 ;...einrichten
3
ldi yh,$03 ;Y-Zeiger...
4
ldi yl,$00 ;...einrichten
5
_NEXT:
6
ld r16,x+ ;Erst Wert laden, dann X = X+1
7
st y+,r16 ;Erst Wert schreiben
8
cpi xh,$02 ;Adressbereich $0060 - $01FF bzw....
9
brne _NEXT ;...$0300 - $041F abgearbeitet ?
10
ldi r16,$7F ;Ja, Nullbyte laden und in den Bereich...
Bernd S. schrieb:> Zum anderen ist BRLO, genau dass Selbe wie BRCS, weshalb du auch ganz> gut zu 95% der Fälle mit dem Z oder C-Flag zurechtkommst !
Was hat das eine mit dem anderen zu tun? Für ein und dieselbe
MC-Sprunginstruktion (hier: zur Prüfung aufs C-Flag) kann man in
AVR-Assembler halt verschiedene Schreibweisen verwenden.
> Wen das alles als Anfänger nicht verwirrt, der ist für mich wirklich ein> Naturtalent.
Du solltest als Anfänger
> versuchen diese Tabelle aus meinem Kopf zu> streichen
und Dir statt dessen die einfachen Befehlsbeschreibungen zu Gemüte
führen. Das ist wirklich kein Hexenwerk, es werden immer nur einzelne
Flags abgefragt die irgendwelche Instruktionen zuvor verändert haben.
> genauso wie die Befehle BRLO und BRSH
die ja eigentlich nur und ganz unschuldig die Vergleichsoperation
hervorheben sollen.
> Hinzu kommt bei mir, das man beim CPI-Befehl Rd und K nicht tauschen kann.
Weil Vergleiche eben eine Subtraktion Wert2-Wert1 sind und die
Reihenfolge hier nicht egal ist!
> Aber nun zur ursprünglichen Frage - würdest du die abschließende Prüfung> in meinem Programmbeispiel nun mit BRCS oder BRNE machen und warum ?
Das kann man mit beiden. Wie immer führen bei Asm viele Wege zum Ziel!
Die Schreibweise
1
cpi yh,$06 ;Pruefen, ob der Datenbereich...
2
brne _NEXT ;...$0100 bis...
3
cpi yl,$40 ;...$063F...
4
brlo _NEXT ;...abgearbeitet ist
ist aber insofern schlauer als daß brlo hier definitiv alle Fälle
unter Low-Adr. $40 erfasst (nach Erreichen von HighAdr 06 natürlich) und
nicht nur einen bestimmten wie es mit der Prüfung aufs Z-Flag der Fall
wäre = dem Erreichen von Punkt $40, was vielleicht infolge des
Additions-Intervalls (und zuviel Denkfäulnis :) nie geschieht. Eine
andere, übersichtlichere Variante des Tests auf Erreichen von $640 wäre
z.B. der 16bittige Vergleich
1
ldi xl,$06
2
cpi yl,$40
3
cpc yh,xl
4
brlo next
mit dem Nachteil, daß hier noch ein weiteres Register zum Vergleichen
eingespannt werden müsste. Zuweilen bietet es sich an, den Pointer mit
sbiw über den Bereich rückwärts wandern zu lassen, damit erschlägst Du
nämlich zwei Fliegen: Der Pointer bewegt sich und Du kannst gleich das
sbiw C-Flag-Ergebnis für den Vergleich bemühen...
Wie könnte der zugehörige Code ausschauen?
Hi
Bernd S. schrieb:> Geht das schneller als mit 5315 Takten ?Bernd S. schrieb:> _NULLBYTE:> st -x,r16 ;...$01FF - $0060 schreiben> cpi xh,$00 ;Bereich...> brne _NULLBYTE ;...> cpi xl,$60 ;...abgearbeitet ?> brne _NULLBYTE ;Nein, dann weiter machen> nop ;Marke fuer den Breakpoint im Simulator
Denke, Du kommst außer in zwei Fällen mit EINER Prüfung aus.
XH ist im letzten Durchgang immer 00, somit brauchst Du in Deinem Code
immer die Prüfung auf XL.
Wenn Du als Erstes auf XL prüfst, hast Du pro XH nur einen Fall, wo XL
'passt' und XH als zweite Prüfung hinzu genommen werden muß.
Also so:
E.Ehrhart schrieb:> Eine> andere, übersichtlichere Variante des Tests auf Erreichen von $640 wäre> z.B. der 16bittige Vergleich> ldi xl,$06> cpi yl,$40> cpc yh,xl> brlo next>
Mir ist bei der Assemblerprogrammierung die Geschwindigkeit am
wichtigsten, bei anderen Sprachen ist dies sicherlich auch die
Übersichtlichkeit, deshalb kommt diese Variante in Assembler für mich
nicht in Frage.
Bernd_Stein
Patrick J. schrieb:> Also so: _NULLBYTE:> st -x,r16 ;...$01FF - $0060 schreiben> cpi xl,$60 ;Bereich...> brne _NULLBYTE ;...> cpi xh,$00 ;...abgearbeitet ?> brne _NULLBYTE ;Nein, dann weiter machen> nop ;Marke fuer den Breakpoint im Simulator> ... ungetestet ...>
Danke, besonders für den zusätzlich erleuternden Text. Spart mal eben
316 Takte, also insgesamt nur noch 4999 und ehemals 5315.
S. Landolt schrieb:> Warum schreibt man nicht gleich in der ersten Schleife dieses> "Nullbyte", also: .> .> ldi r17,$7F> _NEXT:> ld r16,x ;Erst Wert laden, dann X = X+1> st x+,r17>
Weil die ursprünglichen Daten in diesem Bereich zuerst in einem anderen
Bereich verschoben, kopiert, gesichert, oder wie auch immer, werden
sollen. Und dann erst soll dieser Bereich mit dem Nullbyte überschrieben
werden.
Außerdem kommt man so auch nur mit einem Arbeitsregister (r16) aus und
braucht kein weiteres.
Du hast das Plus geklaut, aber den Text nicht geändert ;-)
Bernd_Stein
Bevor man sich unnütz Zeit für Optimieren ans Bein bindet, sollte man
erstmal prüfen, wieviel % CPU-Last die Routine in der gesamten
Applikation wirklich kostet.
4644 Zyklen bei 16MHz sind nichtmal 0,3ms. Dagegen ist ein Wimpernschlag
schon eine Ewigkeit.
Ich verwende für analoge Steuerungen und Regelungen schon länger nur
noch float, kostet ja nichts. Es macht aber die Programmierung deutlich
komfortabler, übersichtlicher und weniger fehleranfällig.
Und für den Benutzer ist kein zeitlicher Unterschied gegenüber int
bemerkbar.
Deshalb mein einleitendes Zitat - am Ende sieht man keinen Unterschied.
Und was das zusätzliche Register betrifft, nun, wenn das tatsächlich
nicht frei sein sollte, dann macht man eben am Beginn/Ende ein push/pop,
die 4 Takte bekommt man vielfach zurück.
an Peter Dannegger
Ich bezog mich auf Bernd Stein, pardon, ich hätte zitieren sollen. Im
übrigen handelt es sich ja um reine Theorie, Sandkastenspiele, oder
besser Fingerübungen - es hört sich ja auch kein Mensch mit Vergnügen
Tonleitern auf dem Klavier an.
Peter D. schrieb:> Bevor man sich unnütz Zeit für Optimieren ans Bein bindet, sollte man> erstmal prüfen, wieviel % CPU-Last die Routine in der gesamten> Applikation wirklich kostet.>
Ja schon, aber das ist nun mal ein Tick von mir. Seit dem ersten
Programm auf dem C64 in Assembler, bin ich halt von der Geschwindigkeit
dieser Sprache fasziniert und sehe auch da den einzigartigen Vorteil
dieser Programmiersprache. Natürlich ist das alles heute nicht mehr so
extrem wie zu Commodore C64-Basic-Zeiten.
Also, lass mir meinen Fetisch und stör dich nicht weiter drann ;-)
Bernd_Stein
Bernd S. schrieb:> Mir ist bei der Assemblerprogrammierung die Geschwindigkeit am> wichtigsten, bei anderen Sprachen ist dies sicherlich auch die> Übersichtlichkeit, deshalb kommt diese Variante in Assembler für mich> nicht in Frage.
Dann hast Du vermutlich noch kein größeres Projekt in Asm erstellt und
beschränkst Dich hier wirklich nur auf einen Speed-
Bernd S. schrieb:> Fetisch
Besonders Asm ist bei der Kleinteiligkeit seiner Bausteine, gerade bei
größeren Projekten, auf eine ausreichende Übersichtlichkeit angewiesen,
die sich durchaus auch herstellen lässt. Der eigentliche konträre
Gegenpart zur Geschwindigkeit heißt aber sehr oft: Codegröße! Für viele
Projekte ist die erzielte Geschwindigkeit mehr als genug, es hilft dann
aber alles nichts wenn der tolle hochperformante Code nicht mehr in den
niedlichen AVR-Speicher passt. Was in der Praxis wirklich von
Bedeutung ist hat Peter D. auf den Punkt gebracht. Dem tragen letztlich
auch die vorhandenen Hochsprachen Rechnung.
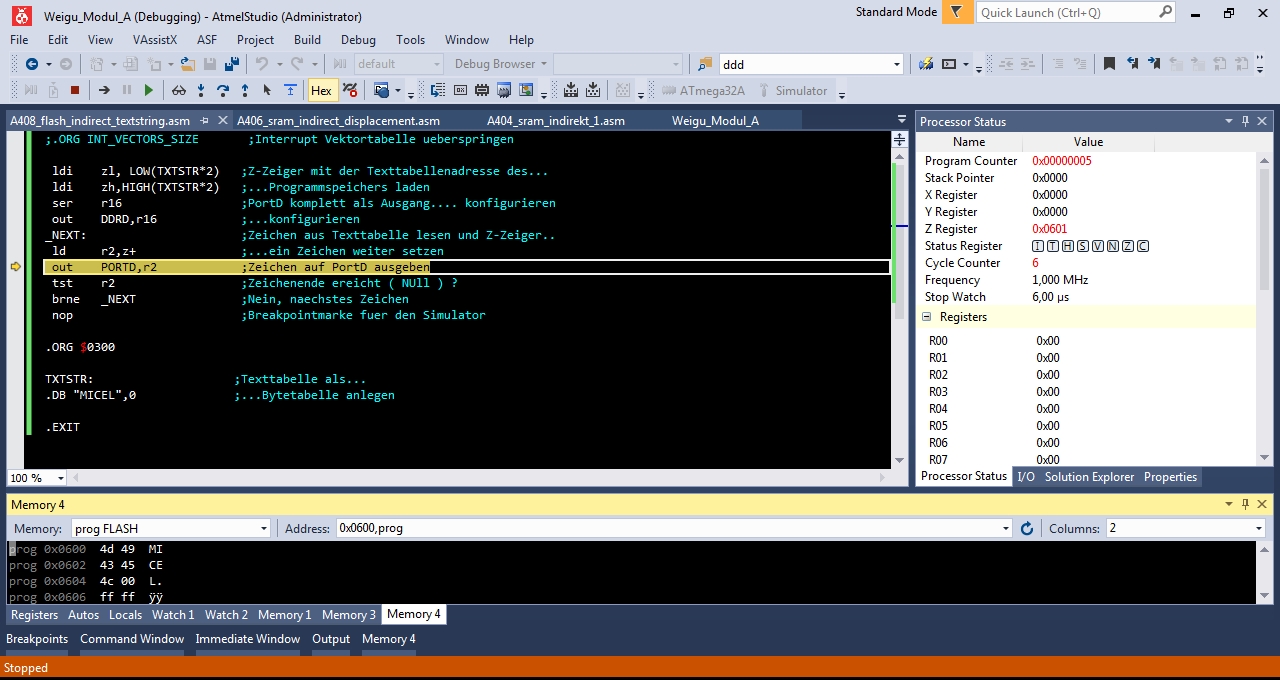
Bernd S. schrieb:> Kann mir jemand schreiben, warum in R02 der Wert $4D für 'M' nicht> auftaucht ?
Klassischer Anfängerfehler.
Überlege nochmal, wie man Daten aus dem Flash ausliest!
ldi zl, LOW(TXTSTR*2) ;Z-Zeiger mit der Texttabellenadresse des...
4
ldi zh,HIGH(TXTSTR*2) ;...Programmspeichers laden
5
ser r16 ;PortD komplett als Ausgang.... konfigurieren
6
out DDRD,r16 ;...konfigurieren
7
_NEXT: ;Zeichen aus Texttabelle lesen und Z-Zeiger..
8
lpm r2,z+ ;...ein Zeichen weiter setzen
9
out PORTD,r2 ;Zeichen auf PortD ausgeben
10
tst r2 ;Zeichenende ereicht ( NUll ) ?
11
brne _NEXT ;Nein, naechstes Zeichen
12
nop ;Breakpointmarke fuer den Simulator
13
14
.ORG $0033
15
16
TXTSTR: ;Texttabelle als...
17
.DB "MICEL",0 ;...Bytetabelle anlegen
18
19
.EXIT
Jetzt hab ich noch zwei andere Verständnisprobleme. Ich wollte halt
sehen, ab welcher Adresse das Programm endet und ich die Tabelle
einfügen kann.
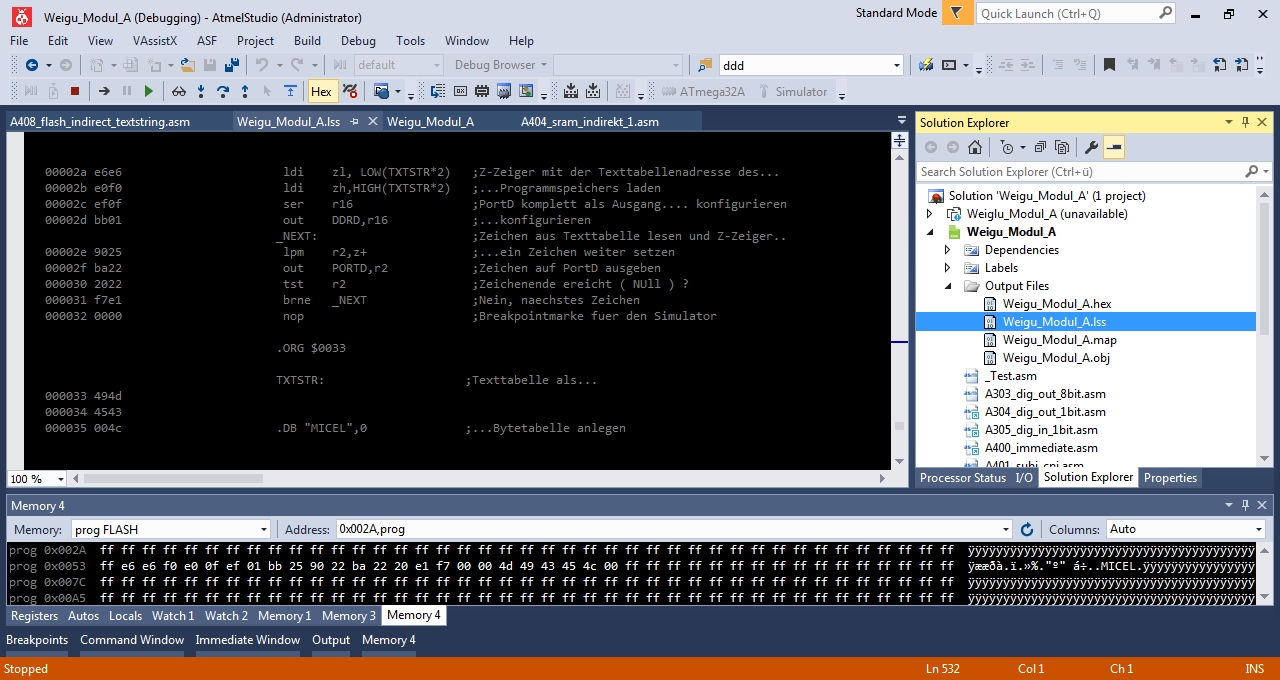
Dies kann man ja schön in der .lss Datei sehen.
1. Warum ist im Programmspeicher der erste Befehl an Adresse $0054,
aber im Listingfile (.lss) richtigerweise an $002A ?
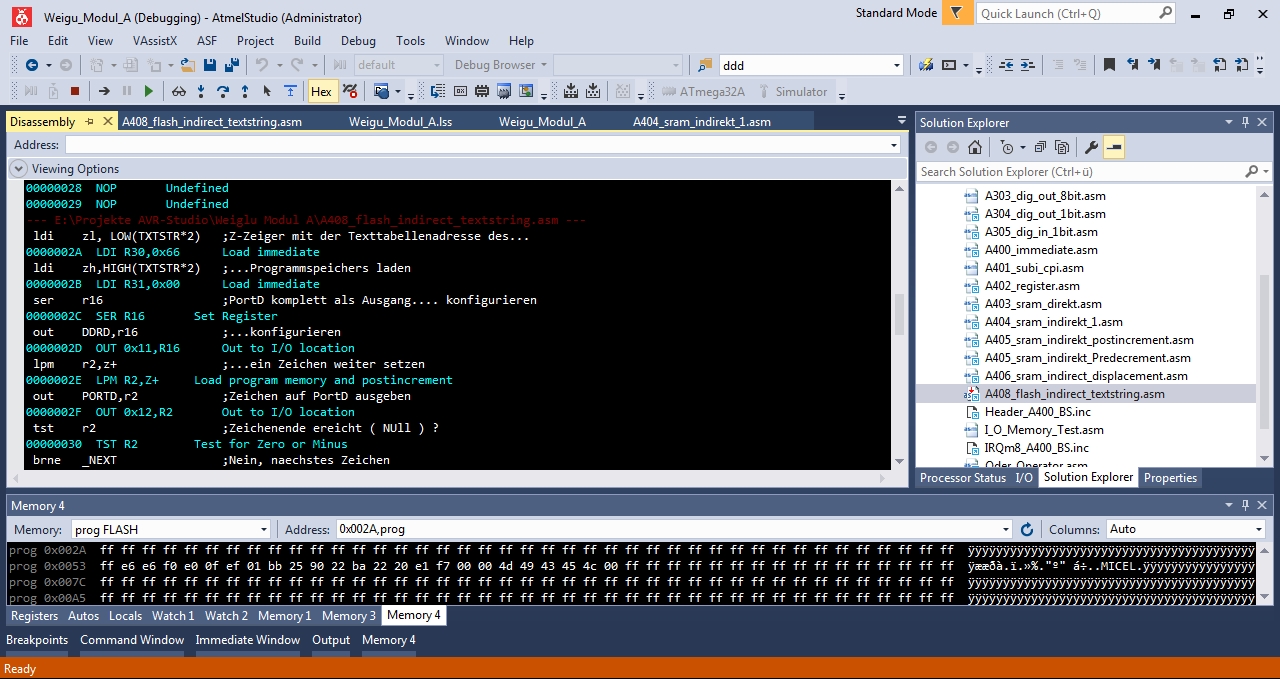
2. Wieso bekomme ich auf einmal beim simulieren, solch eine Ansicht,
wenn ich die Zeile mit .ORG INT_VECTORS_SIZE einfüge ?
Bernd_Stein
Bernd S. schrieb:> 1. Warum ist im Programmspeicher der erste Befehl an Adresse $0054,> aber im Listingfile (.lss) richtigerweise an $002A ?>
Da bin ich gerade selbst drauf gekommen. Weil er nicht in der
Word-Ansicht dargestellt wird sondern in der Byte-Ansicht ( Adresse*2 ).
Bernd_Stein
Bernd S. schrieb:> Ich wollte halt> sehen, ab welcher Adresse das Programm endet und ich die Tabelle> einfügen kann
Da gibts nix notwendigerweise zu "sehen". Mach Dein .DB Statement an
beliebiger Code-Stelle (aber hinter der Resetmarke) und gut ist. Die
Datenbyteanzahl sollte wegen der Flash-Wortlänge allerdings geradzahlig
sein (notfalls noch eine unnütze Null dran).
Rudi schrieb:> Die> Datenbyteanzahl sollte wegen der Flash-Wortlänge allerdings geradzahlig> sein (notfalls noch eine unnütze Null dran).>.
Sowas macht glücklicherweise der Assembler. Schade das niemand Punkt 2
erklären konnte.
Bei der Aufgabe A500:
b) Wieso werden beim Sprungbefehl wohl zwei Werte angegeben?
Weil gesprungen wird und einmal nicht. Jetzt Frage ich mich jedoch,
warum gibt es da Taktmäßig eine Unterscheidung ? Befehlsholphase und
Befehlsausführungsphase werden doch zu diesem Zeitpunkt in einem Takt
erledigt und es ist ein Ein-Word-Befehl.
1
.CSEG ;was ab hier folgt kommt in den FLASH-Speicher
2
.ORG $0000 ;Programm beginnt an der FLASH-Adresse 0x0000.CSEG
3
4
ldi r16,0
5
_LOOP:
6
dec r16
7
brne _LOOP
8
9
_endlos:
10
rjmp _endlos
This instruction branches relatively to PC in either
direction (PC - 63 ≤ destination ≤ PC + 64). Parameter k is the offset
from PC and is represented in two’s
complement form. (Equivalent to instruction BRBC 1,k.)
Operation:
(i) If Rd ≠ Rr (Z = 0) then PC ← PC + k + 1, else PC ← PC + 1
Dachte erst es liegt daran das einmal PC+1 ( 1Takt ) und beim Sprung
PC+k+1 zu bearbeiten ist. Dann habe ich mir den RJMP-Befehl angesehen
und da gibt es ja nur in die Rückwärtssprungrichtung +1, aber trotzdem
braucht er jedesmal 2 Takte.
Relative jump to an address within PC - 2K +1 and PC + 2K (words).
Bernd_Stein
Desweiteren habe ich noch ein Problem mit der Formelumstellung Seite 94:
d) Stelle die Formel nach G1 um.
Ich habe für t = 3tT + ( G1-1 )*3. Ldi (1T); dec (1*1T); Schleife
(255-1)*3; brne (1T weil jetzt nicht mehr gesprungen wird )
herausbekommen.
G1 = ?
1
.CSEG ;was ab hier folgt kommt in den FLASH-Speicher
2
.ORG $0000 ;Programm beginnt an der FLASH-Adresse 0x0000.CSEG
Bernd S. schrieb:> Rudi schrieb:>> Die>> Datenbyteanzahl sollte wegen der Flash-Wortlänge allerdings geradzahlig>> sein (notfalls noch eine unnütze Null dran).>>.> Sowas macht glücklicherweise der Assembler. Schade das niemand Punkt 2> erklären konnte.
Ja da hast Du Recht. Passieren tut nix. Es ist aber immer gut schon im
Programmtext zu sehen was nun wirklich im Speicher Sache ist. Von den
unschönen Assemblerwarnungen ganz abgesehen.
> Jetzt Frage ich mich jedoch, warum gibt es da Taktmäßig eine Unterscheidung ?> Dachte erst es liegt daran das einmal PC+1 ( 1Takt ) und beim Sprung> PC+k+1 zu bearbeiten ist. Dann habe ich mir den RJMP-Befehl angesehen> und da gibt es ja nur in die Rückwärtssprungrichtung +1, aber trotzdem> braucht er jedesmal 2 Takte.
Es wird wohl daran liegen daß relative Sprünge generell 2 Takte
benötigen.
Die reine Condition-Prüfung (mit dem Ergebnis false = kein Sprung)
dagegen nur einen. Warum das so ist kann dem Programmierer doch egal
sein- er nimmt es als gegeben hin.
d) Stelle die Formel nach G1 um.
Ich habe für t = 3tT + ( G1-1 )*3. Ldi (1T); dec (1*1T); Schleife
(255-1)*3; brne (1T weil jetzt nicht mehr gesprungen wird )
herausbekommen.
G1 = ?
1
.CSEG ;was ab hier folgt kommt in den FLASH-Speicher
2
.ORG $0000 ;Programm beginnt an der FLASH-Adresse 0x0000.CSEG
3
4
ldi r16,255
5
_LOOP:
6
dec r16
7
brne _LOOP
8
9
_endlos:
10
rjmp _endlos
11
12
.EXIT ;Ende des Quelltextes
t = Verbrauchte Zeit ; tT = Zeitdauer für einen Takt ; G1 = Anfangswert
t = 3tT + ( G1-1 )*3 => Klammer auflösen
t = 3tT + G1*3 - 3tT => Hinsehen und überlegen
t = G1*3 => |:3
*G1=t/3*
Verbrauchte Zeit also 255*3 = 765 Takte. G1=0 ist als 256 anzusehen.
t=G1*3 finde ich ist eine gut zu merkende Grundlage für die
AVR-Assemblerprogrammierung, wenn es um 8-Bit-Zeitschleifen geht.
Das ist nicht aus meinen Überlegungen entstanden, sondern hierher :
http://www.avr-asm-tutorial.net/avr_de/zeitschleifen/delay8.html
Schade, fetthinterlegen mit ** geht leider nicht.
Bernd_Stein
Bernd S. schrieb:> wenn es um 8-Bit-Zeitschleifen geht
sollte man immer eine timerinterrupt-basierte Lösung bevorzugen. Nicht
nur, weil diese sich sehr weitläufig justieren lässt und keine
Taktorgien zu berechnen sind. Vor allem, weil sie nicht unnütz
Prozessorzeit verbrät und das geschmeidige Fließen des Hauptprogramms
ohne jede Not ins Stocken bringt.
Rudi_H schrieb:> Deine Klammer ist falsch aufgelöst...nicht -3tT, sondern -3.>
Vielleicht sollte ich dann die Formel lieber so aufstellen :
t = 3tT + ( G1-1tT )*3
Rudi schrieb:>> Bernd_Stein. schrieb:>> wenn es um 8-Bit-Zeitschleifen geht>> sollte man immer eine timerinterrupt-basierte Lösung bevorzugen.>
Da gebe ich dir Grundsätzlich schon recht, aber falls die
Interruptbasierte Zeitbasis mal zu groß sein sollte, kann man sich
sicherlich auch hiermit mal begnügen. Es kommt halt immer darauf an. Ich
selbst sehe das ja auch so, das solche Zeitschleifen oder auf Ereignisse
warten in Assembler Perlen vor die Säue schmeissen ist. Der Vorteil von
Assembler ist und bleibt nun mal seine einzigartige Schnelligkeit.
Bernd_Stein
t = Verbrauchte Zeit ; tT = Zeitdauer für einen Takt ; G1 = Anfangswert
t = 3tT + ( G1-1 )*3tT => Klammer auflösen
t = 3tT + G1*3tT - 3tT => Hinsehen und überlegen
t = G1*3tT => |:3tT
G1 = t/3tT
Habe die Formel nochmal durchdacht. Es ist sinnvoller sie so, für eine
8-Bit Zeitschleife aufzustellen, da die Schleife ja einmal weniger
durchlaufen wird ( -1*3tT ) als mit G1 angegeben wird.
Also in Worten :
Die verbrauchte Zeit entspricht dem Anfangswert der Zählschleife ( G1 )
mal drei für die Zeit, die ein Takt ( tT ) benötigt. Ganz schön
verwirrend nicht wahr.
Als Beispiel :
Der µC läuft mit einem Megahertz, dann braucht ein Takt eine
Mikrosekunde.
Wenn der Anfangswert des Schleifenzähler 255 beträgt, dauert das
ausführen dieser Sequenz 255*3*1µs, also 765µs. Es können also nur
Vielfache von drei Mikrosekunden als Zeiten entstehen.
1
.CSEG ;was ab hier folgt kommt in den FLASH-Speicher
2
.ORG $0000 ;Programm beginnt an der FLASH-Adresse 0x0000.CSEG
Bernd S. schrieb:> Da gebe ich dir Grundsätzlich schon recht, aber falls die> Interruptbasierte Zeitbasis mal zu groß sein sollte, kann man sich> sicherlich auch hiermit mal begnügen. Es kommt halt immer darauf an. Ich> selbst sehe das ja auch so, das solche Zeitschleifen oder auf Ereignisse> warten in Assembler Perlen vor die Säue schmeissen ist.
Betreibst Du das MC-Handwerk eigentlich als Hobby der grauen Theorie
oder schreibst Du auch tatsächlich (für Dich) nützliche und größere
ASM-Programme? Man gewinnt nämlich den Eindruck, es würde an Erfahrung
mit letzterem mangeln bzw. an den richtigen Prioritäten.
Bernd S. schrieb:> Bei der Aufgabe A500:> b) Wieso werden beim Sprungbefehl BRNE wohl zwei Werte angegeben?>> Weil gesprungen wird und einmal nicht. Jetzt Frage ich mich jedoch,> warum gibt es da Taktmäßig eine Unterscheidung ? Befehlsholphase und> Befehlsausführungsphase werden doch zu diesem Zeitpunkt in einem Takt> erledigt und es ist ein Ein-Word-Befehl.>
Ich erkläre mir dies so:" In einem Systemtakt holt sich die CPU zwei
Register in die ALU und führt mit ihnen entsprechend dem Befehl eine
ALU-Operation aus ".
Beim bedingtem Sprung ( BRNE ) wird also der PC ( 2 Byte -> entsprechend
2 Registern ) geholt und 1 hinzuaddiert ( 1 Takt ), wenn der Sprung
nicht erfolgt.
Wenn der Sprung erfolgt, kommt obiges Szenario zustande und nun wird zu
dem jetzt gebildeten PC noch k ( +-64 ) addiert, was ein weiteren Takt
braucht.
Der unbedingte Sprung ( RJMP ) braucht immer 2 Takte, da er im ersten
Takt den PC-LOW und k-LOW holt und diese addiert, dann im zweiten Takt
PC-High und k-High holt und diese addiert. ( k = +- 2048 )
So nun zu meinen Lösungen zur Aufgabe A501.
a) 1Mhz = 765µs ; 16Mhz = 47,8125µs
b) 1/10 Sekunde = 100ms, also Nein
c) 256 durchläufe -> 768µs bzw. 48µs
Bernd_Stein
.CSEG ;was ab hier folgt kommt in den FLASH-Speicher
2
.ORG $0000 ;Programm beginnt an der FLASH-Adresse 0x0000.CSEG
3
4
ldi xl,LOW (65535)
5
ldi xh,HIGH(65535)
6
_LOOP:
7
sbiw xh:xl,1
8
brne _LOOP
9
10
_endlos:
11
rjmp _endlos
b) t = 1T + 4T * G1 ( T = Takt, G1 = X-Zeiger )
c) Ja, 1 Takt wenn mit 4T * G1 gerechnet wird.
d) Ja, wenn es auf den einen Takt nicht ankommt
e) G1 = t / 4T
f) 1Mhz = 262.140 bzw. 262.14µs ; 16Mhz = 16.383,7500 bzw. 16.383,8125µs
g) 100ms -> G1 = 100.000µS / 4µS --> 25.000 f. 1Mhz ; 16Mhz = 400.000,
also
nicht in 16Bit machbar.
Bernd_Stein
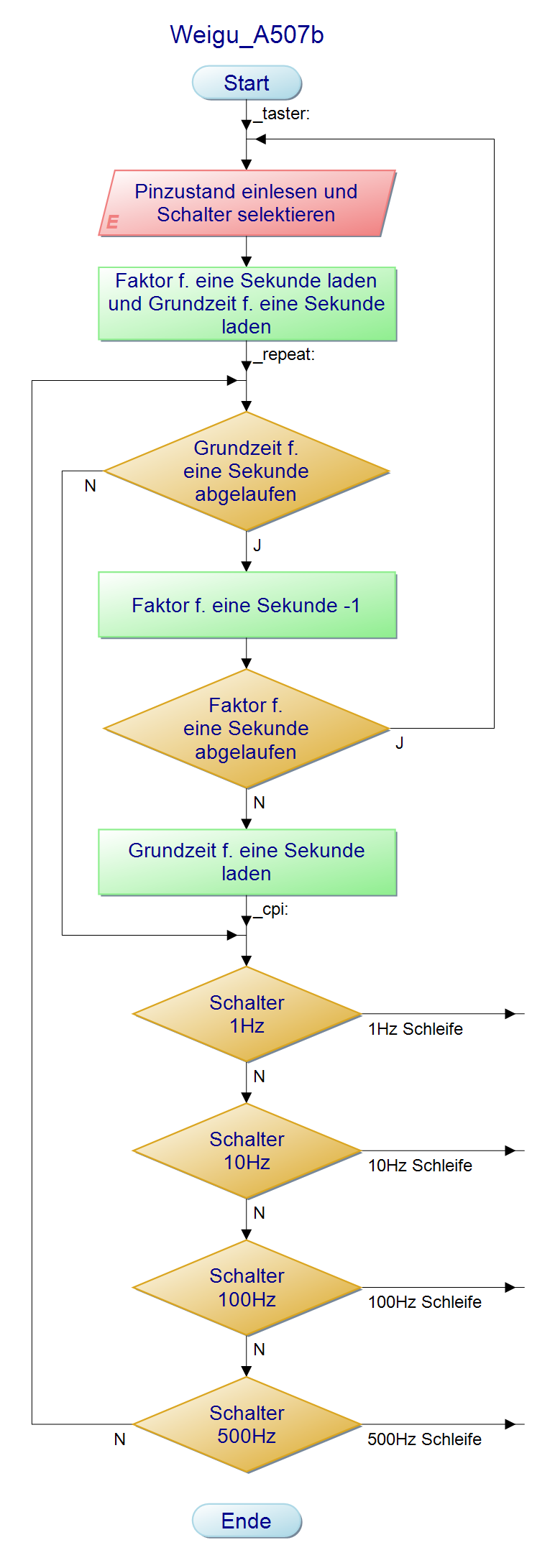
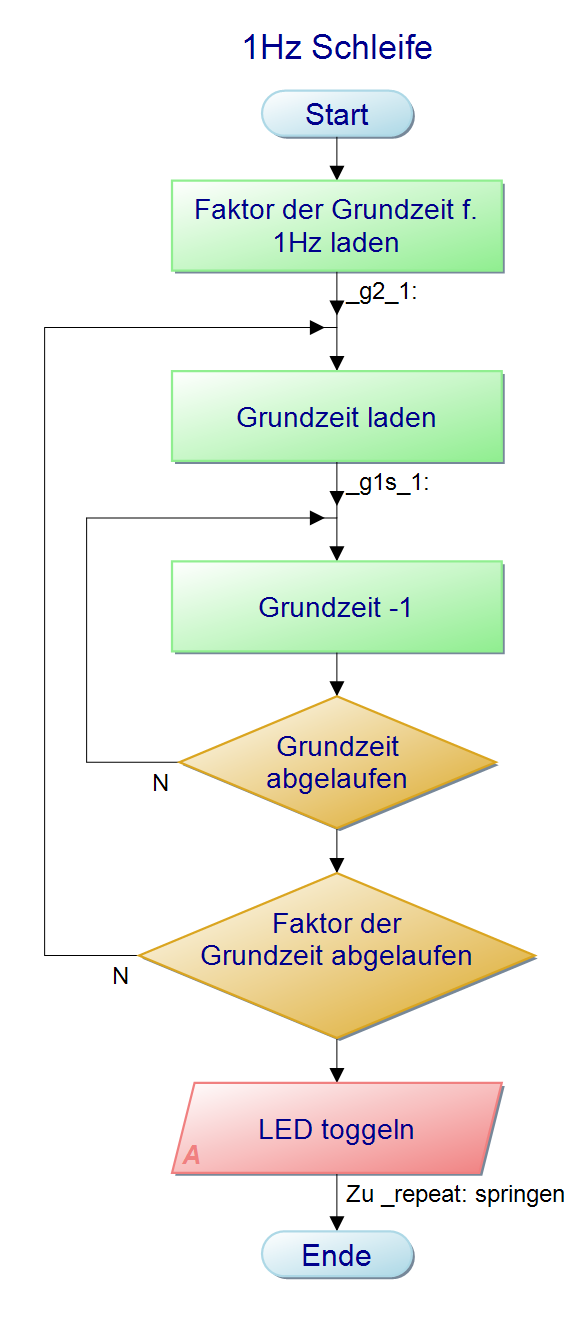
Bin jetzt bei A507b angekommen und habe ein Problem die
Schalterabfrage im Sekundenrythmus einzufügen.
Nach dem Umschalten bleibt die vorherige Frequenz bestehen.
b)Für Fleißige:
Bei hohen Frequenzen kann die zur Schalterabfrage benötigte Zeit die
Genauigkeit der Frequenz beeinflussen. Ändere das Programm so um, dass
die Schalter nur ein mal pro Sekunde abgefragt werden. Speicheredas
Programm als "A507_frequency_generator_3.asm".
Der PAP für 1Hz ist stellvertretend für die anderen Frequenzen, da sich
nur die Werte für den Faktor der Grundzeit ändert.
Bernd_Stein
{kind=link}
{kind=link}