Hallo, ich habe hier ein Board mit einem MC9S12DG128 Mikrocontroller drauf. Der hat eine HCS12 CPU drin. Ich habe auch die Software die auf dem Chip drauf ist in Form einer 80kb großen Binärdatei (Flash-Abbild). Aber keinen Quellcode. Den würde ich gern mittels disassemblen wieder herstellen. Ich weiss nicht in welcher Sprache die Software mal geschrieben wurde. Grundsätzlich müsste es doch möglich sein über den Befehlsschatz der CPU einen Assemblercode aus dem Binärbild zu erzeugen?! Wenn der Disassembler sogar den uC kennt, könnte er gar wissen was Programm und was Daten sind und die I/O Ports entsprechend bezeichnen. Habe im Netz sogar davon gelesen das es Disassembler geben soll die aufgrund von Bytesignaturen im Code erkennen ob und welche Libraries darin eingebettet sind, und daraus die Ursprungssprache ermitteln und sogar teilweise wieder decompilieren können. Leider habe ich auf dem Gebiet überhaupt keinen Überblick und hoffe das ich hier Tipps und Hinweise bekomme wie ich das angehe. Welche Tools könnte ich nutzen? Also schonmal vielen Dank im Voraus für die Hilfe!
Olli Z. schrieb: > Habe im Netz > sogar davon gelesen das es Disassembler geben soll die aufgrund von > Bytesignaturen im Code erkennen ob und welche Libraries darin > eingebettet sind Für so einen Exot? Ich wünsche dir viel Spass beim Suchen... 80kB sind grob gerechnet mindestens 100-150 Seiten engbedrucktes DINA4 als Assembler Listing - das kann schon ein paar Monate dauern.
Ich gehe davon aus das der ursprüngliche Quellcode in C geschrieben wurde. Zumindest sagt das Datenblatt des Chips was von "C optimized architecture produces extremely compact code" was dies sehr wahrscheinlich macht. Achja, da steht auch das die CPU mit den Typen 68HC11 und 68HC12 kompatibel ist. Vielleicht sind diese nicht ganz so "exotisch"? Aber sind uC nicht alle Exoten?;-)
einfach GOOGLE fragen (unglaublich daß sich das immer noch nicht rumgesprochen hat): disassembler for hcs12 core http://hc12web.de/dis12/ Ob das allerdings funktioniert kann ich nicht sagen. 80k ohh-ohh, da biste xx Wochen drüber. Da dürfe es fast schneller gehen die Sache (welche?) neu zu erstellen. Gruss
Google? Was ist das denn? Bestimmt wieder son neumodisches Zeug... wie dieses, dieses Internet was jetzt alle baben müssen. Tztz. Ne, den dis12 hab ich in der Tat auch schon gefunden. Der ist aber leider nicht für Windows gedacht. Und in den 80k sind bestimmt die Hälfte nur Daten. Ich will auch nicht alles verstehen, nur eine bestimmte Routine im Verhalten ändern. Meine Hoffnung ist, das man den Disassembleten Code später auch wieder assemblen kann.
Mit deinen Kenntnissen wird das nichts. Schon bei 2K ist das eine Herausforderung. Selbst wenn es Tools nach deinen Vorstellungen gibt, haben die einen dir nicht angenehmen Preis.
Eigentlich würde ich ja dieses empfehlen: https://packages.debian.org/search?keywords=m68hc1x&searchon=names&suite=all§ion=all aber vielleicht geht das auch: https://www.gnu.org/software/m68hc11/m68hc11_pkg_zip.html Bei den binutils ist ein Programm dabei mit 'objdump' im Namen, das macht das. Man muss ein wenig mit den vielen Kommandozeilenschaltern spielen...
Olli Z. schrieb: > Ne, den dis12 hab ich in der Tat auch schon gefunden. Der ist aber > leider nicht für Windows gedacht. Das ist Quelltext. Den wirst Du Deinem Compiler vor, dann läuft der auch unter Windows. Könnte es sein, daß Du Dir da vielleicht einen etwas zu großen Brocken vorgenommen hast?
Olli Z. schrieb: > Ich gehe davon aus das der ursprüngliche Quellcode in C geschrieben > wurde. Zumindest sagt das Datenblatt des Chips was von "C optimized > architecture produces extremely compact code" was dies sehr > wahrscheinlich macht. Quatsch. Auch Atmel sagt z.B. über die AVR8, dass die Architektur für C optimiert wäre und deshalb blablabla... Das ist aber natürlich keinerlei Hinweis darauf, dass für eine konkrete Applikation auch tatsächlich C verwendet wurde. Man schaue sich allein den ganzen Programmiersprachenzoo an, mit dem man die AVR8 programmieren kann...
Rufus Τ. F. schrieb: > Olli Z. schrieb: >> Ne, den dis12 hab ich in der Tat auch schon gefunden. Der ist aber >> leider nicht für Windows gedacht. > Das ist Quelltext. Den wirst Du Deinem Compiler vor, dann läuft der auch > unter Windows. Das ist mir schon klar. Leider compiliert das Teil unter Windows mit dem TDM-GCC nicht. Es hagelt nur Fehlermeldungen. Habe das Makefile mit "make" durchführen lassen. Fängt an mit Type errors (u_char, u_int,...), was ich über typedefs in der .h Datei noch gefixet bekam. Geht aber dann ins Uferlose mit hundert anderen Fehlern. > Könnte es sein, daß Du Dir da vielleicht einen etwas zu großen Brocken > vorgenommen hast? Da hast Du vermutlich recht. Aber ich wollte ja auch klein anfangen und was dabei lernen!
Olli Z. schrieb: > Fängt an mit Type errors Die fehlen unter Windows diese beiden Files: #include <sys/types.h> #include <sys/stat.h>
anstelle da mit windows rumzuwürgen ... wäre es nicht einfacher, eine Linux boot-cd zu nehmen, und den Disassembler dann unter Linux anzustossen und dein Binärfile zum Futter zu geben?
Ja, nicht falsch verstehen, eigentlich bin im Herzen einen Kommandozeilenjunkie. Manche Dinge gehen mit Windows aber einfach etwas flotter von der Hand (beim handling). Auch sind häufig die Windows-Tools in der Überzahl. Ich werde das aber trotzdem versuchen. Habe noch einen Laptop mit Ubuntu drauf, damit sollte das ja gehen.
Olli Z. schrieb: > Ja, nicht falsch verstehen, eigentlich bin im Herzen einen > Kommandozeilenjunkie. Manche Dinge gehen mit Windows aber einfach etwas > flotter von der Hand (beim handling). Auch sind häufig die Windows-Tools > in der Überzahl. Ich werde das aber trotzdem versuchen. Habe noch einen > Laptop mit Ubuntu drauf, damit sollte das ja gehen. Ohh das schwingt aber die Angst mit. Bloß nicht Windows zu sehr loben, die Tuxer hier im Forum könnten ja einen Klicki-Bunti Post schreiben? Du sagst es wie es ist. Mit Windows installiert man sich mal schnell ein Tool und es funktioniert halt. Mit Linux kompilierst du dir voher nen Affen, auf Anhieb klappt das nie und wirst dann noch bei Fragen angespuckt, warum du nicht googeln oder die man page lesen kannst.
Ich wollte auch nicht darüber diskutieren was besser ist. Beides hat seine Berechtigung. Es ist halt so, das ich "nur" disassemblen will und nicht erst Betriebssysteme installieren. Unter Linux compiliert das Tool zwar auf Anhieb, spuckt aber dennoch etliche Warnings raus. Egal, es läuft da. Jetzt bin ich wieder ein kleines Schrittchen weiter. Jetzt muss ich die Einsprungadresse finden und schauen was der dis12 so taugt. Vermutlich liegt da noch ein laaanger Weg vor mir...
Olli Z. schrieb: > Habe noch einen > Laptop mit Ubuntu drauf, damit sollte das ja gehen. Dann kannst Du ja vielleicht mit dem angehängten Archiv was anfangen. Das Programm compiliert(e) auch unter Linux nur mit dutzenden von Warnungen, weil Standard-Header nicht eingebunden wurden und Prototypen fehlten. Die Änderungen waren schnell gemacht, aber für Testen und Fehler suchen habe ich keine Zeit. Mit -Wall gibt es weitere Warnungen, die man teilweise durchaus ernst nehmen sollte. Nachtrag: Sehe gerade, Daß Du es inzwischen selber compiliert hast. Aber trotzdem...
Ich hab' mir diese Sourcen jetzt mal genauer angesehen. Ja, das ist ziemlich grindiges Zeug, aber mit etwas Handarbeit bekommt man das auch mit VC2010 (das ist der C/C++-Compiler, mit dem ich hier gerade arbeite) übersetzt. Wenn man das Biest aufruft, spuckt es das hier aus:
1 | C:\prj\dis12>dis12.exe |
2 | Usage: dis12.exe [options] file |
3 | -a file address classification file |
4 | -b [+-]hhhh set the behavior of the disassembler |
5 | 'hhhh' is a bit mask composed of: |
6 | 0x0001 force 8 bit immed in 32..126 to char |
7 | 0x0002 force long immediate to symbol |
8 | 0x0004 force 9 bit pc indexed to symbol |
9 | 0x0008 force other 9 bit indexed to symbol |
10 | 0x0010 force 16 bit pc indexed to symbol |
11 | 0x0020 force other 16 bit indexed to symbol |
12 | 0x0040 force 16 bit pc indirect indexed to symbol |
13 | 0x0080 force other 16 bit indirect indexed to symbol |
14 | a '-' prefix removes a bit and |
15 | a '+' prefix adds a bit and |
16 | no prefix sets the mask to the value |
17 | the default is 0x0077 |
18 | -d turn debug on |
19 | -D hhhh set debug to 'hhhh', where |
20 | 1 show pass 1 disassembly |
21 | 2 dump memtype struct |
22 | 4 show find_type() |
23 | 8 show addlabel() |
24 | 10 show get_byte() |
25 | 20 show load_file() |
26 | 40 |
27 | -l file write listing to 'file' |
28 | -o hhhh set org to 'hhhh' |
29 | -s file symbol mapping file |
Das VS2010-Projekt habe ich mal angehängt. Es gibt zwar noch jede Menge Warnungen, aber die liegen in erster Linie am grindigen Code (getopt.c beispielsweise ist noch im steinalten K&R-Dialekt geschrieben). Zwei Typdefinitionen sind nötig, die habe ich in dis12_types.h untergebracht; getopt.c braucht noch eine eigene Headerdatei (getopt.h), und die muss mit "" statt mit <> eingebunden werden. Die index-Funktion habe ich einer neueren getopt-Variante (https://gnunet.org/svn/flightrecorder/src/flightrecorderd/getopt.c) entnommen. Das war es aber auch schon, alles in allem vielleicht 10 Minuten Arbeit.
Hat vielleicht jemand ein fertiges kleines Assemblerprogramm und Binärcode dazu um den Disassembler zu testen? Bevor ich an mein Image gehe würde ich gern wissen ob der tut.
Olli Z. schrieb: > Grundsätzlich müsste es doch möglich sein über den Befehlsschatz der CPU > einen Assemblercode aus dem Binärbild zu erzeugen?! Klar, IDA Pro kann das, letze Freewareversion 5.0. Olli Z. schrieb: > Habe im Netz > sogar davon gelesen das es Disassembler geben soll die aufgrund von > Bytesignaturen im Code erkennen ob und welche Libraries darin > eingebettet sind, und daraus die Ursprungssprache ermitteln und sogar > teilweise wieder decompilieren können. Kaum bei dem Exoten.
Das habe ich --in Ermangelung von HC12-Code-- natürlich nicht anstellen können, mein "Test" bestand nur im Aufrufen der Windows-Exe.
Fliegt auf die Fresse. Der Code ist wohl wirklich sehr grindig. In dis12.c in der Funktion disasm muss die Variable "mem_type" initialisiert werden (vermutlich mit 'c'). Wenn man dann noch den Rückgabewert der Funktion "get_byte()" mit 0xFF maskiert, dann kommt tatsächlich was 'raus. Ob das nun sinnvoll ist ...
Angehängte Dateien:
-

device_memorymap.PNG
52 KB -

memory_map.PNG
37 KB
Rufus Τ. F. schrieb: > Das habe ich --in Ermangelung von HC12-Code-- natürlich nicht anstellen > können, mein "Test" bestand nur im Aufrufen der Windows-Exe. Ja, natürlich. Dafür auch schonmal ein wirklich herzliches Dankeschön von mir! Ich lade mir gerade Visual Studio Community herunter um das nachzuspielen. Ich hatte bislang nur den WinGW drauf, aber der hat halt nur einen gcc für Windows. Ich hoffe das das MS-Zeugs besser klappt.
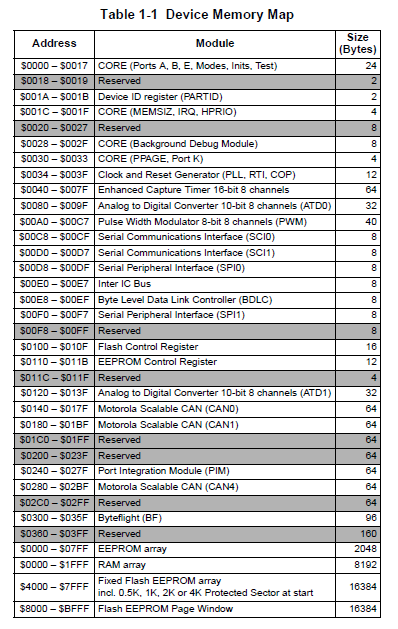
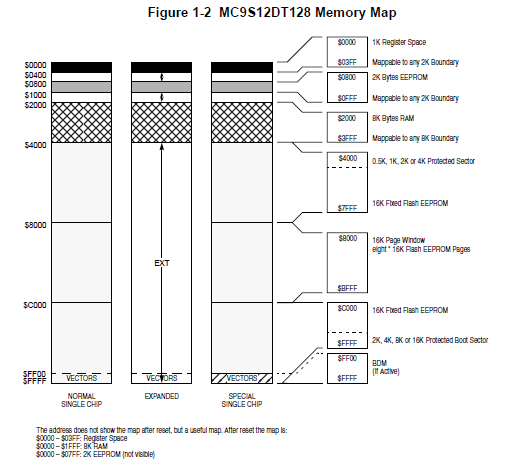
Ich meine mich zu erinnern, dass der Flash ab Adresse 0x4000 anfängt. Darunter sind Peripherals, ISV, RAM, NVM, usw gemappt. Ist aber schon wieder > 2 Jahre her dass ich was mit dem S12 zu tun hatte. Gibt's keine Datenblätter zum Downloaden? EDIT: Ah, zu spät; Olli hat jetzt hier obeb schon den Mem Map gepostet
Michael B. schrieb: > Olli Z. schrieb: >> Grundsätzlich müsste es doch möglich sein über den Befehlsschatz der CPU >> einen Assemblercode aus dem Binärbild zu erzeugen?! > > Klar, IDA Pro kann das, letze Freewareversion 5.0. IDA kann leider sogar bei der aktuellen 6.x kein HCS12 disassemblen. Die Freeware kann ohnehin nur 80x88 Code.
Hier wäre der von mir besagte Bootloader. Tatsäclich konnte das von mir unter Linux compilierte dis12 (bislang ohne irgendwelche Korrekturen um Source!) das Abbild ohne Fehlermeldung decompilieren. Die Startadresse wird mit 0x06BE angegeben. Ob das stimmt... keine Ahnung.
Eric B. schrieb: > Ich meine mich zu erinnern, dass der Flash ab Adresse 0x4000 > anfängt. > Darunter sind Peripherals, ISV, RAM, NVM, usw gemappt. Ist aber schon > wieder > 2 Jahre her dass ich was mit dem S12 zu tun hatte. > Gibt's keine Datenblätter zum Downloaden? Ja, genau so ist es. Wie bei vielen anderen uCs auch liegen die ganzen I/O-Ports auf Adressen im RAM. Dieses liegt eigentlich bei $0000-$1FFF (8k). Ist also das was am Beginn des Bootloaders steht einstellungen für die Ports? Jedenfalls müsste das Programm ja im Adressbereich $0140 bis $017F (CAN0) oder $0180 bis $01BF (CAN1) irgendwas tun.
SORRY! Ich hatte in meinem Bootloader ein paar Bytes zuviel am Anfang drin. Hier nochmal die korrekten Dateien.
Bei der geposteten Datei "lab9.sx.bin" ist die Größe von genau 16000 Bytes sehr merkwürdig; wenn das ein ROM-Abzug ist, wäre die Startadresse tatsächlich interessant. Lässt man das mit -o 4000 laufen (um das Disassemblat bei 0x4000 beginnen zu lassen), endet das mit der Adresse 0x7e7f, was irgendwie nicht mit den Interruptvektoren zusammenpassen will. Um auf 0xFFFF als Endadresse zu gelangen, müsste der Code bei 0xc180 beginnen. Dann jedenfalls sieht die Vektortabelle ab 0xFF80 irgendwie sinnvoller aus. Andererseits wäre dann genau ein Vektor überhaupt gesetzt, und das wäre der "Real Time Interrupt CRGINT (RTIE)". Ob das wirklich sinnvoll ist?
Erich schrieb: > zu lab9.sx.bin > Ok, es ist ein mc9s12dp256 Vielleicht gibt uns Erich den Source dazu. Nur dann würde es Sinn machen. Wir wollen ja nicht seinen Code knacken, sondern prüfen ob der dis12 irgendwas sinnvolles ausspuckt. Ohne Startadresse finde ich das schwierig. Die Frage ist auch, ob dieser ASM-Code im RAM oder im FLASH ausgeführt werden sollte.
Diese AN liest sich interessant: http://www.nxp.com/assets/documents/data/en/application-notes/AN2546.pdf Dort ist zu lesen: "This bootloader implementation allows user software to be downloaded into the RAM of the MCU using the CAN or SCI serial interfaces. The bootloader polls the CAN and SCI ports for messages. When a message is received, the bootloader attempts to match the incoming communication baud rate against a number of selected baud rates based on common crystal frequencies. After the user software has been downloaded into RAM, execution is transferred to the code resident in RAM." Dies entspricht zu 100% meinen Vorstellungen wie es laufen müsste und hier scheine ich wohl goldrichtig zu liegen. Micht würde es sogar garnicht wundern, wenn der Bootloader den ich angefügt habe eben genau dieser ist der hier beschrieben wird!
Olli Z. schrieb: > Vielleicht gibt uns Erich den Source dazu. Ok, Für eine noch einfachere Variante lab9a. Programm läuft im Ram.
Na, dann ist -o C180 beim Disassemblieren gar nicht so falsch, denn dann stimmt die Interrupttabelle tatsächlich mit der in vectors.c überein.
Anbei noch der Bootloader (läuft rein im RAM) im S-REC Format. Die erste Zeile: S325000004F4100D0400110D5C003E0D8C00220DBC0027147A003615570037171F003113 AC00D1 Die letzte Zeile: S31A00001EF4E241A240B7C53D04460AB7C549B7C546560436F63D77 So wie es da steht, wird der Programmcode ab Adresse $04F4 bis $1EF4 ins RAM geladen, ist also in Wirklichheit nur $1A00 Bytes lang. So disassembliert (datei anbei) existiert auch die im Programmiertool angegebene Startadresse von $06BE. Und da geht es dann so los:
1 | jsr L0597 ;$06BE $16 $05 $97 |
2 | bsr L06CD ;$06C1 $07 $0A |
3 | ldd #$09C4 ;$06C3 $CC $09 $C4 |
4 | std L046C ;$06C6 $7C $04 $6C |
5 | jsr L05A7 ;$06C9 $16 $05 $A7 |
6 | rts ;$06CC $3D |
Das könnte die Main-Loop sein. Bestehend aus weiteren Subroutinen (jsr) und am Ende ein Return (rts) welches wohl zum aufrufenden Programm zurückkehrt. Im Modul selbst muss ja auch noch ein Code vorhanden sein, der diesen Bootloader über den Bus empfängt und ausführt.
Olli Z. schrieb: > So wie es da steht, wird der Programmcode ab Adresse $04F4 bis $1EF4 ins > RAM geladen, ist also in Wirklichheit nur $1A00 Bytes lang. Dann ist die *.bin-Datei irgendwie Unfug.
Es sind natürlich $1A05 Bytes, weil ich die letzten 5 Bytes veruntreut hatte. Somit stimmt alles. Der Code scheint auch irgendwie Sinn zu machen von der angegebenen Einsprungstelle. Zumindest ist das Ergebnis vom dis12 irgendwie brauchbar. So direkten Maschinencode in dieser Größenordnung versteht ja kein Mensch. Wie müsste ich weiter vorgehen? Mein Plan war im Code die Zugriffe auf die I/O-Adressen zu finden. Z.B. hätte ich geglaubt das irgendwo darin die CAN-Schnittstelle (und vielleicht sogar auch noch die SCI) initialisiert werden. CAN0 hat seine Register im Adressbereich ab $0140 gemapped, CAN1 ab $0180. Ich müsste ja irgendwo diesen Basisoffset finden, oder Zugriffe in diesem Bereich (jeweils 64 Bytes). Es wird Befehle geben um den Bytewert für ein Register zusammenzustellen und welche um diesen dann an die Adresse zu laden. Natürlich muss diese Adresse nicht hardkodiert im Code stehen, sondern kann auch aus einer Lookup-Tabelle im Speicher stammen. Am besten wäre natürlich eine Simulation, mit der man Schritt für Schritt den ASM-Code ausführen kann und der einem den Zustand der Register und der Peripherie anzeigt. So könnte man womöglich am schnellsten aus den Subroutinen schlau werden.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.