Guten Abend Ich habe zwei Datensätze, einen mit 4 Werten pro Minute der Andere hat halbstündliche Werte. Jetzt würde ich die halbstündlichen Werte gerne in den ersten Datensatz "hineininterpolieren". Leider verstehe ich das Beispiel unter pandas.Series.interpolate nicht so, dass ich die beiden Datensätze zusammen bekomme. Kann mir da jemand helfen? Gerne mit Erklärung, da ich es ja verstehen möchte :-) Danke und Gruß Kolja P.S. Ich kann auch kurze Beispieldaten zur Verfügung stellen, wenn nötig. edit: jaja, in dem Beispiel sind die Zeiträume nicht gleich. Ist aber nur ein Fehler in dem Beispiel für den Screenshot.
Angehängte Dateien:
-

Python_interpolieren.jpg
370 KB
Ohne, dass Du in der Tabelle was beschreibst, anzeichnest und erklärts, wird da keiner durchblicken. Generell musst Du den halbstundenwert mit mindestens einen Nachbarn zusammen in einer Formel bringen und einen Punkt auf der Gerade bilden. Gfs muss Du auch 3 oder 4 werte filtern und eine Formel bilden. Dann suchst du für jeden Punkt auf dieser halbstunden-Kurve, der Dich interessiert, die umliegenden 2,3,4 Punkte der anderen Kurve, die man ähnlich behandeln muss.
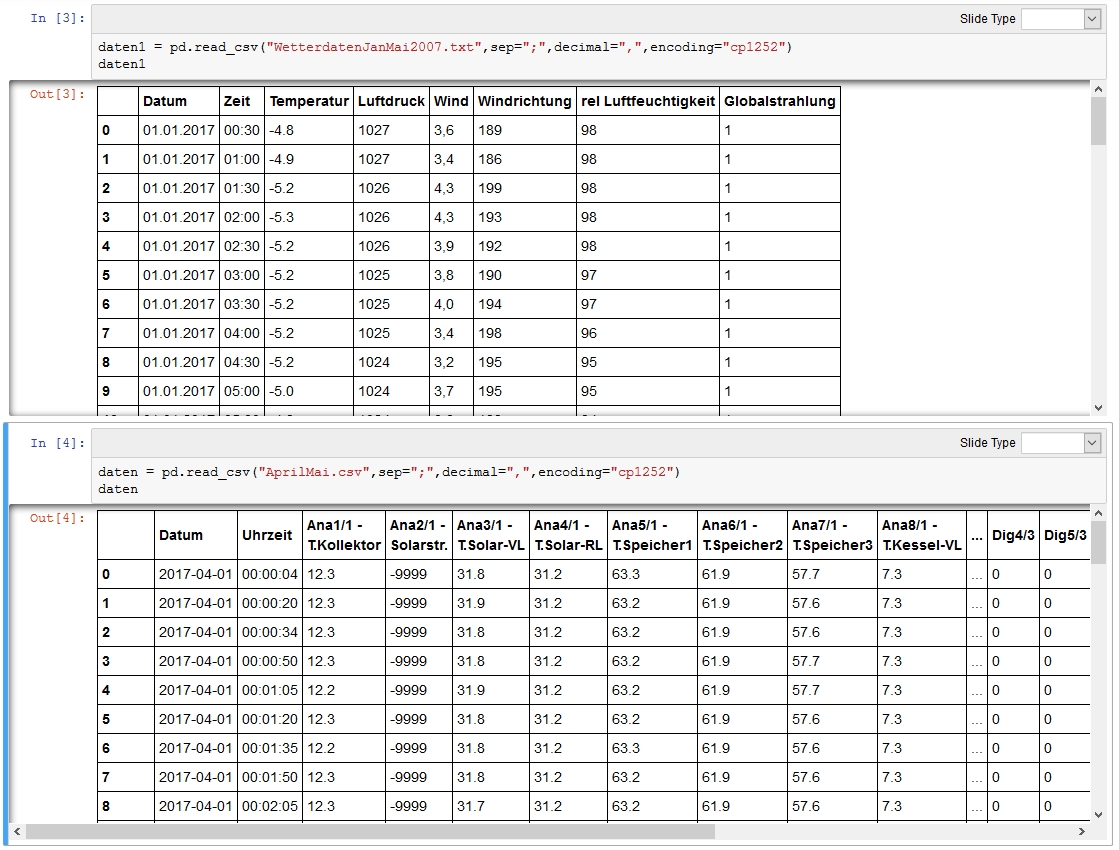
Interpreter Nummer 7 schrieb: > Ohne, dass Du in der Tabelle was beschreibst, anzeichnest und erklärts, > wird da keiner durchblicken. Danke für den Hinweis! Ok, ich versuche es mal mit den echten Daten: Halbstündlich:
1 | Datum Zeit Temperatur Luftdruck Wind Windrichtung rel Luftfeuchtigkeit Globalstrahlung |
2 | 0 01.01.2017 00:30 -4,8 1027 3,6 189 98 1 |
3 | 1 01.01.2017 01:00 -4,9 1027 3,4 186 98 1 |
4 | 2 01.01.2017 01:30 -5,2 1026 4,3 199 98 1 |
Viertelminütlich:
1 | Datum Uhrzeit Ana1/1 - T.Kollektor Ana2/1 - Solarstr. Ana3/1 - T.Solar-VL |
2 | 0 2017-01-01 00:00:04 -3.9 -9999 26.0 |
3 | 1 2017-01-01 00:00:18 -3.9 -9999 26.0 |
4 | 2 2017-01-01 00:00:33 -3.9 -9999 25.9 |
5 | 3 2017-01-01 00:00:48 -3.9 -9999 26.0 |
6 | 4 2017-01-01 00:01:04 -3.9 -9999 26.0 |
7 | 5 2017-01-01 00:01:18 -3.9 -9999 25.9 |
Die halbstündlichen Daten sollen linear interpoliert werden. Dann gibt es ja zu jedem Zeitpunkt einen eindeutigen Wert. Die Zeitpunkte werden durch die Messpunkte der viertelminütlichen Werte vorgegeben und sollen in deren Datensatz eingefügt werden. Jetzt verständlicher?
Hi, ich würde erst ein Upsampling auf den halbstündlichen Daten auf dein Intervall von den anderen Zeitstempeln machen und dann die NaN-Werte mittels Interpolation füllen. Anschließend kann man die DataFrames über die Zeitstempel joinen (ggf. auf den richtigen Zeitstempel zurechtrücken, auf die Sekunde genau kommt es doch nicht an?).
Ne, auf eine sekundengenaue Zusammenführung kommt es nicht an.
Angehängte Dateien:
-

Python_interpolieren1.jpg
420 KB
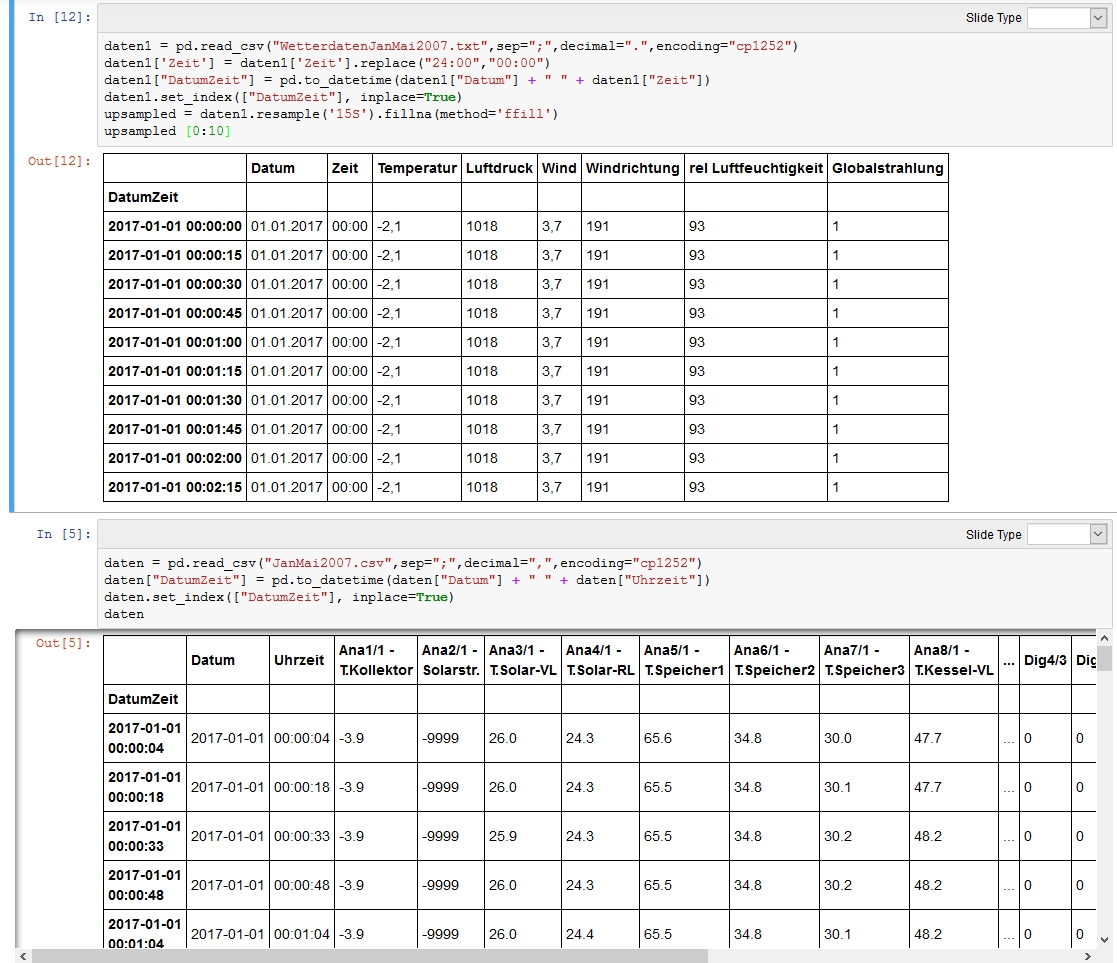
Christoph schrieb: > ich würde erst ein Upsampling auf den halbstündlichen Daten auf dein > Intervall von den anderen Zeitstempeln machen und dann die NaN-Werte > mittels Interpolation füllen. Es dauerte eine Stunde, aber dann hat es funktioniert :-) Danke für die "Anleitung". Das Ergebnis ist im angehängten Bild zu sehen. Christoph schrieb: > Anschließend kann man die DataFrames über > die Zeitstempel joinen Das sollte ja kein Problem sein und sogar ziemlich gut passen, da die beiden Zeitstempel sich meist nur um 5 Sekunden unterscheiden. Nur habe ich leider gar keinen Ansatzpunkt wie das in Pandas zu realisieren ist. Vielleicht noch eine Hilfestellung? Danke und Gruß Kolja P.S. Warum hat der Index in der unteren Tabelle einen Zeilenumbruch? Ist nur kosmentisch, aber stört mich trotzdem.
Bei joinen gibt es ja hier das Problem, dass die Zeitstempel unterschiedlich sind und nur ungefähr zueinander passen. Entweder du ziehst bei einem Datensatz einen konstanten Offset von ein paar Sekunden ab und hoffst, dass es immer passt oder du schaust dir Merging AsOf auf https://pandas.pydata.org/pandas-docs/stable/merging.html an. Ich glaube, das ist eine elegantere Lösung...
Hallo Christoph
merge_asof() sieht gut aus, aber ich verstehe nicht,
warum ich diesen Fehler bekomme:
In: df=pd.merge_asof(daten, daten1,
on='DatumZeit',tolerance=pd.Timedelta('10s') )
Out: KeyError: 'DatumZeit'
"on" soll doch die Spalte sein, nach der zusammengeführt wird,
also der Index der beiden Tabellen.
Naja, er findet den Key DatumZeit in dem DataFrame nicht...ich vermute, dass set_index nicht nötig ist (die Leerzeilen sind irgendwie verdächtig)- was passiert wenn du das weglässt?
Bei den Wetterdaten (die ersten, interpolierten) gibt es folgenden Fehler: TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'RangeIndex' Bei den Solardaten nicht.
Ah, der muss ja nach dem set_index genaus damit die Interpolation durchführen. Der kann also nicht weg.
Hm, die Leerzeile (zweite Zeile) sieht aber trotzdem merkwürdig aus.
Letzte Idee:
> df = df.set_index(pd.DatetimeIndex(df['b']))
So in der Art (inplace geht natürlich auch).
Angehängte Dateien:
-

Python_interpolieren2.jpg
230 KB
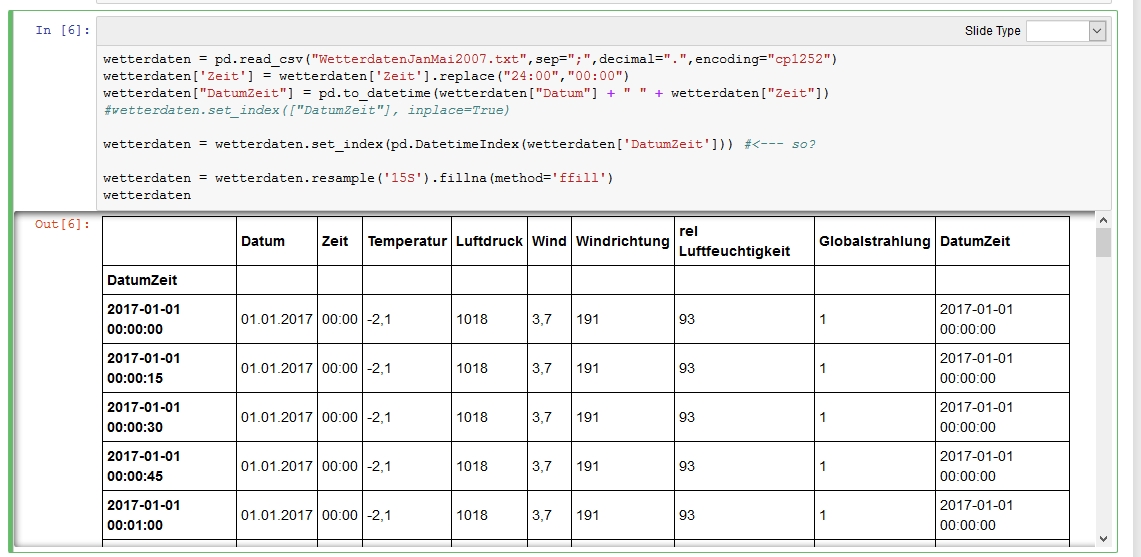
Verstehe nicht so ganz was du mit der Zeile bezwecken willst, habe es mal wie im Bild zu sehen interpretiert. Jetzt gibt es aber keine Zeit mehr, außer im Index
OK, mach mal schrittweise weiter. Die zweite Zeile sieht immer noch merkwürdig aus (=>löschen?) Ich würde mit dem Upsamplen anfangen. Es kann sein, dass mal der Index der Zeitstempel sein muss, dann mal wieder nicht. Den Zeitstempel kannst du mit df["time"] = df.index wieder als "normale" Spalte definieren. Dann ist das Joinen etwas tricky, weil wir den Key der Zeitstempel sein soll, gleichzeitig für die Toleranz nutzen wollen- ob das so klappt, weiß ich nicht.
Angehängte Dateien:
-

Python_interpolieren3.jpg
470 KB
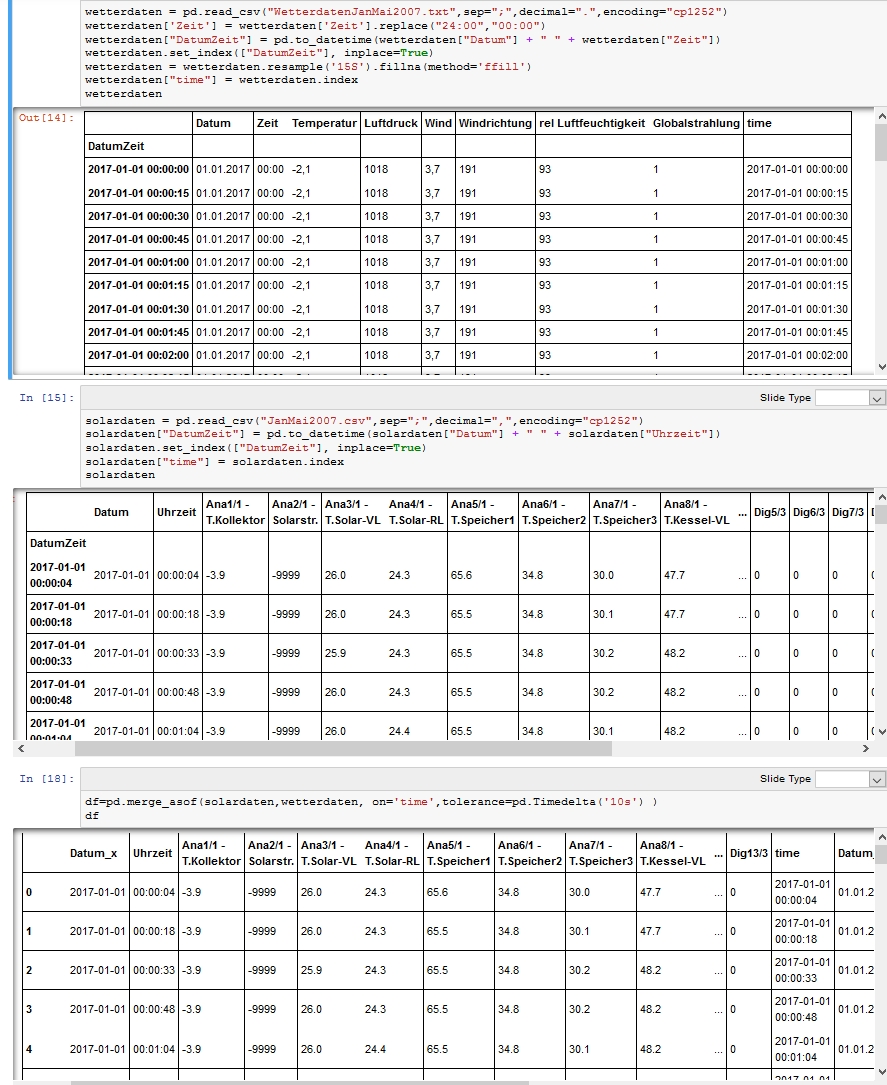
Meinst du mit der zweiten Zeile die mit .replace()? Ist notwendig, da Stunden nur zwischen 0 und 23 akzeptiert werden. Aber die Idee mit dem Index verschieben hat etwas gebracht, ich hab nur noch nicht ganz verstanden was. Erstmal essen :-) Im Bild noch der Zwischenstand. Auf jeden Fall vielen Dank bis jetzt!
1 | wetterdaten = pd.read_csv("WetterdatenJanMai2007.txt",sep=";",decimal=".",encoding="cp1252") |
2 | wetterdaten['Zeit'] = wetterdaten['Zeit'].replace("24:00","00:00") |
3 | wetterdaten["DatumZeit"] = pd.to_datetime(wetterdaten["Datum"] + " " + wetterdaten["Zeit"]) |
4 | wetterdaten.set_index(["DatumZeit"], inplace=True) |
5 | wetterdaten = wetterdaten.resample('15S').fillna(method='ffill') |
6 | wetterdaten["time"] = wetterdaten.index |
7 | wetterdaten
|
8 | |
9 | solardaten = pd.read_csv("JanMai2007.csv",sep=";",decimal=",",encoding="cp1252") |
10 | solardaten["DatumZeit"] = pd.to_datetime(solardaten["Datum"] + " " + solardaten["Uhrzeit"]) |
11 | solardaten.set_index(["DatumZeit"], inplace=True) |
12 | solardaten["time"] = solardaten.index |
13 | solardaten
|
14 | |
15 | df=pd.merge_asof(solardaten,wetterdaten, on='time',tolerance=pd.Timedelta('10s') ) |
16 | df
|
Nochmal der Code, weil im Bild so klein
Nein, ich meinte die zweite Zeile in beiden DataFrames wo in der ersten Spalte DatumZeit steht aber sonst nix weiter. Hat der merge denn geklappt, d.h. stehen in df die Daten richtig drin? Ggf. mal die doppelten Spalten droppen...
Christoph schrieb: > Hat der merge denn geklappt, d.h. stehen in df die Daten richtig drin? Weiß ich noch nicht, etwas unübersichtlich das alles... Christoph schrieb: > Ggf. mal die doppelten Spalten droppen... Wie kann ich den generell nur ausgewählte Spalten anzeigen? Das geht leider nicht: daten["Datum_x","Uhrzeit"] Christoph schrieb: > Nein, ich meinte die zweite Zeile in beiden DataFrames wo in der ersten > Spalte DatumZeit steht aber sonst nix weiter. Wundert mich auch warum die da ist, stört aber nicht.
Kolja L. schrieb: > Weiß ich noch nicht, etwas unübersichtlich das alles... Ein df.shape gibt schonmal einen Anhaltspunkt über die Größe- vergleiche das mal mit den ursprünglichen Daten, ob das hinkommen kann. Kolja L. schrieb: > Das geht leider nicht: daten["Datum_x","Uhrzeit"] Das sollte gehen: > daten.loc["Datum_x","Uhrzeit"]
Christoph schrieb: > Das sollte gehen: >> daten.loc["Datum_x","Uhrzeit"] Doch nicht ganz, nu aber: >> daten.loc[["Datum_x","Uhrzeit"]]
Christoph schrieb: > Ein df.shape gibt schonmal einen Anhaltspunkt über die Größe- vergleiche > das mal mit den ursprünglichen Daten, ob das hinkommen kann. Mhh, das passt dann noch nicht :-( wetterdaten.shape 1952521 rows × 9 columns solardaten.shape 865866 rows × 92 columns merge_asof daten.shape 865866 rows × 100 columns Und .loc funktioniert irgendwie gar nicht: daten.loc["Uhrzeit"] ergibt: KeyError: 'the label [Uhrzeit] is not in the [index]'
Kolja L. schrieb: > Und .loc funktioniert irgendwie gar nicht: Aber ist .loc nicht nur für Series und nicht für DataFrames? edit, so gehts: daten[['Datum_x','Uhrzeit','time','Datum_y','Zeit','Temperatur']]
Hm, sind auch genügend solardaten vorhanden bzw. geht die Messreihe so lang wie beim Wetter? Der merge geht nur für Daten, die in beiden Datensätzen vorhanden sind. Prinzipiell sieht das aber doch gut aus- es sind 8 Spalten aus dem Wetterdatensatz zum Solardatensatz hinzugekommen (time ist jetzt vermutlich nur noch einmal vorhanden, da der join darüber erfolgt ist). .loc geht auch für einen Datenframe. Wenn man eine Spaltenauswahl trifft, sind zwei eckige Klammern nötig: df.loc[["a", "c"]].
Christoph schrieb: > Hm, sind auch genügend solardaten vorhanden bzw. geht die Messreihe so > lang wie beim Wetter? Ne, zweimillionen vs. achthundertausend Kolja L. schrieb: > wetterdaten.shape > 1952521 rows × 9 columns > > solardaten.shape > 865866 rows × 92 columns > > merge_asof > > daten.shape > 865866 rows × 100 columns Aber es sollten ja...
Deine Messzeit muss für beide Reihen gleich sein => du musst die gleiche Anzahl an Datenpunkten in den beiden Messreihen haben. Anderenfalls bleibt bei einem Join über den Zeitstempel das Minimum an Einträgen übrig.
Ja, jetzt ist nur noch die Frage, warum die noicht gleich lang sind. Ich reduziere mal die Anzal der Zeilen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.