Hallo,
kann mir jemand sagen bzw Code zur Vefügung stellen, wie man einen Array
per Bitbanding anspricht?
Ich habe eine Art FAT in einem EEPROM, lese diese ein in
uint8_t ee_fat[1024];
wobei jedes Bit einen benutzten Sektor abbildet. 8 Bit sind also 8
"Sektoren". Die Adresse der Daten berechne ich dann aus der Bitposition.
Wäre nur schön, wenn man den ganzen Array oben als ein Bitfeld hätte.
Ich habe leider nur Makros, für 32 Bit Variablen und die sind nicht ganz
so trivial.
Was fehlt wäre sowas wie testbit(ee_fat,1234)
Oder gibt es sowas wie:
struct {
unsigned int data:8760; // 8760 Bits
}
vermutlich eher weniger, meine Bitfelder sind auf elementare Typen
begrenzt.
Gruss,
Christian
Was spricht gegen einfache Bit-Operationen:
1 | #include <limits.h> |
2 | #include <stdbool.h> |
3 | #include <stddef.h> |
4 | |
5 | bool getBit (size_t index) { |
6 | const size_t entrySize = sizeof(ee_fat[0]) * CHAR_BIT; |
7 | return ee_fat [index / entrySize] & (1 << (index % entrySize)); |
8 | }
|
9 | void setBit (size_t index, bool value) { |
10 | const size_t entrySize = sizeof(ee_fat[0]) * CHAR_BIT; |
11 | const size_t bit = index % entrySize; |
12 | ee_fat [index / entrySize] = (ee_fat [index / entrySize] & ~(1 << bit)) | (value << bit); |
13 | }
|
Ist dann sogar portabel und hängt nicht vom Bit-Banding einer spezifischen Hardware ab. Wenn du C++ nutzt, kannst du auch einfach std::bitset nehmen.
Spricht nichts gegen..... sieht gut aus, probiere ich mal aus! ee_fat [index / entrySize] = (ee_fat [index / entrySize] & ~(1 << bit)) | (value << bit); Nicht ganz einfach zu verstehen... erst Bit löschen mit & ~(.. , dann das neue mit ODER danach einmaskieren? Geht das hier auch noch eleganter?
1 | /* Bit setzen */
|
2 | LED_BitStream |= (uint64_t)(1ull << pos ); |
3 | /* 1 Bit evtl. blinken lassen */
|
4 | if (blink) |
5 | /* Setze korrespondierende Position im Blink Stream */
|
6 | LED_BitStatus |= (uint64_t)(1ull << pos ); |
7 | else
|
8 | LED_BitStatus &= ~(uint64_t)(1ull << pos ); |
Christian J. schrieb: > Nicht ganz einfach zu verstehen... erst Bit löschen mit & ~(.. , dann > das neue mit ODER danach einmaskieren? Ja genau. > Geht das hier auch noch eleganter? Geht auch, aber je nach Hardware kann es sein dass if-else-Konstrukte langsamer sind (wg. Pipeline & Branch-Prediction) als eine scheinbar kompliziertere Arithmetik. Kannst du ja einfach ausprobieren.
Christian J. schrieb: > Spricht nichts gegen..... sieht gut aus, probiere ich mal aus! > > ee_fat [index / entrySize] = (ee_fat [index / entrySize] & ~(1 << bit)) > | (value << bit); > > Nicht ganz einfach zu verstehen... erst Bit löschen mit & ~(.. , dann > das neue mit ODER danach einmaskieren? Naja, der grosse Vorteil vom Bit Banding IST ja eben, dass die Operation auf dem Bit "atomisch" ist, d.h. wenn Du ein Bit über seinen Alias manipulierst, bleiben die anderen Bits im selben 32 Bit Wert unberührt. Du musst Dich also nicht mit Maskenoperationen herumschlagen. Allerdings kannst Du durch funktionale Abstraktion die Maskenoperationen in den "traditionellen" Implementationen von Bitfeldern so einkapseln, dass Du sie genau an einer Stelle machen musst. Dann sind die Bitfelder so ziemlich gleichwertig... ausser... es gibt nebenläufigen Zugriff auf die Bitfelder (in dem Fall hilft Dir die Ununterbrechbarkeit der Operation beim Bit Banding, Nebenläufigkeitsprobleme zu umschiffen).
Obacht: Bei Bitbanding sollte "ee_fat" als "volatile" deklariert werden, da der Compiler nicht weiss, dass die Bitbanding-Operationen darauf Einfluss haben. Sollte ungefähr so mit Bitbanding funktionieren, ungetestet.
1 | #define RAM_BASE_BYTES 0x12345678 // Basisadresse bitadressierbares RAM
|
2 | #define RAM_BASE_BITS 0x87654321 // Spiegeladresse für Bitadressierung
|
3 | |
4 | #define bb_ram ((volatile uint32_t *)RAM_BASE_BITS)
|
5 | #define bb_offs(array) ((unsigned)(array) - RAM_BASE_BYTES)
|
6 | #define bb_bit(array,bit) bb_ram[bb_offs(array) * 8 + (bit)]
|
7 | |
8 | bb_bit(ee_fat,123) = ... |
9 | if (bb_bit(ee_fat,123)) ... |
Jo, danke! Ich probiers heute abend dann mal aus am uC. Geht auch mehr um den Spass an der Sache als einen echten Nutzwert da stündliche Wettermessdaten abzuspeichern. Kann man auch aus Datenbanken abfragen wie die Werte wann wo waren.
ist es so was was du meinst?
1 | #define BitBandMemAddr(addr, bitnum) ((volatile uint32_t*)(0x22000000 + (((uint32_t)(addr) & 0xFFFFF) << 5) + ((bitnum) << 2)))
|
2 | |
3 | volatile uint8_t bitarray[10]; |
4 | |
5 | int main(void) |
6 | {
|
7 | volatile uint32_t *ba=BitBandMemAddr(&bitarray,0); |
8 | ba[0]=1; |
9 | ba[1]=1; |
10 | ba[2]=1; |
11 | ba[3]=1; |
12 | ba[4]=1; |
13 | ba[5]=1; |
14 | ....
|
15 | |
16 | ba[79]=1; |
17 | |
18 | if (ba[12]) |
19 | {
|
20 | |
21 | ...
|
22 | ...
|
temp schrieb: > ist es so was was du meinst? Genau so geht das beim STM32, der hat extra Bitbanding Adressen um auf dem RAM einzelne Bits lesen/schreiben zu können. Da braucht man nichts ausmaskieren/rechnen/zuweisen, das geht direkt.
Markus M. schrieb: > Genau so geht das beim STM32, der hat extra Bitbanding Adressen um auf > dem RAM einzelne Bits lesen/schreiben zu können. Das weiss ich :-) Es geht ja auch granuliert manuell aber damit geht es eben programmiertechnisch einfacher. Diesen Trümmer habe ich gesucht: #define BitBandMemAddr(addr, bitnum) ((volatile uint32_t*)(0x22000000 + (((uint32_t)(addr) & 0xFFFFF) << 5) + ((bitnum) << 2)))
Markus M. schrieb: > Da braucht man nichts ausmaskieren/rechnen/zuweisen, das geht direkt. Umrechnen muss der Prozessor schon, nämlich die normale Byteadresse des Arrays in die Bitadresse des Spiegeladressraums. Aber man kann sich aussuchen wann man das tut. So sieht es jedenfalls eleganter aus:
1 | #define RAM_BASE_BYTES 0x12345678 // Basisadresse bitadressierbares RAM
|
2 | #define RAM_BASE_BITS 0x87654321 // Spiegeladresse für Bitadressierung
|
3 | |
4 | #define bb_ram ((volatile uint32_t *)RAM_BASE_BITS)
|
5 | #define bb_array(array) (bb_ram + ((unsigned)(array) - RAM_BASE_BYTES) * 8)
|
6 | |
7 | volatile uint32_t *ee_fat_bb = bb_array(ee_fat); |
8 | |
9 | ee_fat_bb[1234] = ... |
10 | if (ee_fat_bb[1234]) ... |
temp schrieb: > ist es so was was du meinst? > #define BitBandMemAddr(addr, bitnum) ((volatile uint32_t*)(0x22000000 + > (((uint32_t)(addr) & 0xFFFFF) << 5) + ((bitnum) << 2))) > > volatile uint8_t bitarray[10]; Selbst ohne Optimierung ist das extrem schmal aber leider nicht debugbar Und leider funktioniert es auch nicht. ba[0] = 1; ba[1] = 1; ba[2] = 0; ba[3] = 1; v1 = ba[0]; v2 = ba[1]; v3 = ba[2]; v4 = ba[3]; v1 = 1; V2 bis v4 = 0; 0x22003080 <error: Cannot access memory at address 0x22003080> volatile uint8_t *ba = (uint8_t*)BitBandMemAddr(&ee_fat,0); 0800266A ldr r3, [pc, #376] ; (0x80027e4 <main+476>) 0800266C lsls r3, r3, #5 0800266E bic.w r3, r3, #4261412864 ; 0xfe000000 08002672 bic.w r3, r3, #31 08002676 add.w r3, r3, #570425344 ; 0x22000000 0800267A str r3, [r7, #20] (115) ba[0] = 1; 0800267C ldr r3, [r7, #20] 0800267E movs r2, #1 08002680 strb r2, [r3, #0] (116) ba[1] = 1; 08002682 ldr r3, [r7, #20] 08002684 adds r3, #1 08002686 movs r2, #1 08002688 strb r2, [r3, #0]
Dr. Sommer schrieb: > bool getBit (size_t index) { > const size_t entrySize = sizeof(ee_fat[0]) * CHAR_BIT; > return ee_fat [index / entrySize] & (1 << (index % entrySize)); > } > void setBit (size_t index, bool value) { > const size_t entrySize = sizeof(ee_fat[0]) * CHAR_BIT; > const size_t bit = index % entrySize; > ee_fat [index / entrySize] = (ee_fat [index / entrySize] & ~(1 << > bit)) | (value << bit); > } Ich hoffe mal, dass ich das richtig umgeschrieben habe, da ich mit Zeigern und castings auf Kriegsfuss stehe. Brauchte das Feld nämliuch als Parameter, ist ne lokale Variable.
1 | bool getBit (uint8_t* p, size_t index) { |
2 | const size_t entrySize = sizeof(p[0]) * CHAR_BIT; |
3 | return p[index / entrySize] & (1 << (index % entrySize)); |
4 | }
|
5 | void setBit (uint8_t* p, size_t index, bool value) { |
6 | const size_t entrySize = sizeof(p[0]) * CHAR_BIT; |
7 | const size_t bit = index % entrySize; |
8 | p[index / entrySize] = (p[index / entrySize] & ~(1 << bit)) | (value << bit); |
9 | }
|
Dr. Sommer schrieb: > Ja sieht doch gut aus. Funktioniert's nicht? In 5 MInuten kann ich Dir das sagen.....
Beitrag #5127693 wurde von einem Moderator gelöscht.
Korrigiere mich, es funktioniert! War nur etwas dumm dargestellt im Watch. Nach umschalten auf Binärdarstellung ist die 1 da wo sie hingehört.
Bei mir ja auch :-) Nur schade, dass das mit dem Bitbanding nicht klappte. Ist ganz schön viel:
1 | 12 ldr r3, [r7, #8] |
2 | 08000314 ldr r2, [r7, #20] |
3 | 08000316 udiv r2, r3, r2 |
4 | 0800031A ldr r1, [r7, #20] |
5 | 0800031C mul.w r2, r1, r2 |
6 | 08000320 subs r3, r3, r2 |
7 | 08000322 str r3, [r7, #16] |
8 | (77) p[index / entrySize] = (p[index / entrySize] & ~(1 << bit)) | (value << bit); |
9 | 08000324 ldr r2, [r7, #8] |
10 | 08000326 ldr r3, [r7, #20] |
11 | 08000328 udiv r3, r2, r3 |
12 | 0800032C ldr r2, [r7, #12] |
13 | 0800032E add r3, r2 |
14 | 08000330 ldr r1, [r7, #8] |
15 | 08000332 ldr r2, [r7, #20] |
16 | 08000334 udiv r2, r1, r2 |
17 | 08000338 ldr r1, [r7, #12] |
18 | 0800033A add r2, r1 |
19 | 0800033C ldrb r2, [r2, #0] |
20 | 0800033E sxtb r1, r2 |
21 | 08000340 movs r0, #1 |
22 | 08000342 ldr r2, [r7, #16] |
23 | 08000344 lsl.w r2, r0, r2 |
24 | 08000348 sxtb r2, r2 |
25 | 0800034A mvns r2, r2 |
26 | 0800034C sxtb r2, r2 |
27 | 0800034E ands r2, r1 |
28 | 08000350 sxtb r1, r2 |
29 | 08000352 ldrb r0, [r7, #7] |
30 | 08000354 ldr r2, [r7, #16] |
31 | 08000356 lsl.w r2, r0, r2 |
32 | 0800035A sxtb r2, r2 |
33 | 0800035C orrs r2, r1 |
34 | 0800035E sxtb r2, r2 |
35 | 08000360 uxtb r2, r2 |
36 | 08000362 strb r2, [r3, #0] |
37 | (78) } |
Optimierungen eingeschaltet?! Die Division sollte eigentlich wegoptimiert werden.
Dr. Sommer schrieb: > Optimierungen eingeschaltet?! Die Division sollte eigentlich > wegoptimiert werden. Dann kann ich nicht mehr debuggen, weil der Source Code nicht mit dem Bin File übereinstimmt. Man kann keine BPs mehr setzen und der Codefluss ist chaotisch.
Christian J. schrieb: > volatile uint8_t *ba = (uint8_t*)BitBandMemAddr(&ee_fat,0); Mach volatile uint32_t *ba = (uint32_t*)BitBandMemAddr(&ee_fat,0); draus und die Sache wird besser aussehen. Der Bitbanding-Bereich bildet Bits auf Worte ab, nicht auf Bytes. Weshalb zwar > (115) ba[0] = 1; > 0800267C ldr r3, [r7, #20] > 0800267E movs r2, #1 > 08002680 strb r2, [r3, #0] noch funktioniert, nicht aber > (116) ba[1] = 1; > 08002682 ldr r3, [r7, #20] > 08002684 adds r3, #1 > 08002686 movs r2, #1 > 08002688 strb r2, [r3, #0]
Christian J. schrieb: > Selbst ohne Optimierung ist das extrem schmal aber leider nicht debugbar > Und leider funktioniert es auch nicht. Mein Code bezieht sich auf einen STM32F103C8 und da funtioniert das. Hab das eben nochmal in Debugger betrachtet. Leider hast du uns nicht verraten was du für einen Chip hast. Ob der Bitbang Bereich bei deiner CPU auch an 0x22000000 losgeht kann ich nicht in der Glaskugel lesen. Das der Code kurz wird ist ja genau das was damit erreicht werden soll. Aber die Doku dazu sollte man sich schon reinziehen.
Genau den gleiche Schips.... Blaue Pille Board. Wenn Du es im Debugger hast, dann schieb es doch mal rüber...
Nochmal gegoogelt. Alle M3 und M4 sollten das auf dieser Adress haben. M0 hat es überhaupt nicht.
Angehängte Dateien:
-

Unbenannt.JPG
77 KB
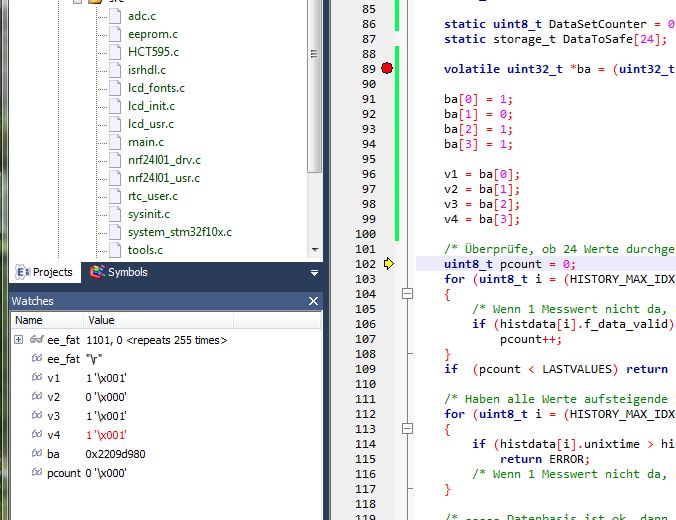
A. K. schrieb: > Mach > volatile uint32_t *ba = (uint32_t*)BitBandMemAddr(&ee_fat,0); > draus Passt! Stimmt! Läuft! :-) Kotmäßig erheblich kürzer als das maskieren, nur 4 Befehle pro Bitsetzen, ohne Optimierung.
temp schrieb: > Nochmal gegoogelt. Alle M3 und M4 sollten das auf dieser Adress haben. > M0 hat es überhaupt nicht. Klappt auch ja jetzt, hatte falsch gecastet. Jungs, ihr seit spitze! :-)
Christian J. schrieb: > Dann kann ich nicht mehr debuggen, weil der Source Code nicht mit dem > Bin File übereinstimmt. Man kann keine BPs mehr setzen und der Codefluss > ist chaotisch. Geht schon, ist etwas fummeliger. Wenn du die Optimierungen nicht nutzt, beschwer dich nicht dass der Code ineffizient ist. Aus der Division sollte ein Bitshift werden, aus dem Modulo ein "and". Wenn das unoptimierte Programm nicht in den Flash passt, nimmt man einen größeren Chip für das Debuggen und einen kleineren (in den das optimierte Programm passt) für die Serie. Falls man keine Serie produziert, braucht man auch nicht am Flash zu sparen.
Christian J. schrieb: > Der A.K. .... wenn wir ihn nicht hätten :-) Dass du sogar Fehler beim Kopieren machst habe ich auch nicht gleich gesehen...
Dr. Sommer schrieb: > Geht schon, ist etwas fummeliger. Wenn du die Optimierungen nicht nutzt, > beschwer dich nicht dass der Code ineffizient ist. In der Release Version ist natürliuch alles eingeschaltet, die ist auch 20kb kürzer als die Debug Version. Nein, man kann nicht debuggen, Embitz schmiert sogar komplett ab, wenn man es versucht. Wenn der Code nicht zeile für zeile dem Kompilat entspricht ist Ende. Und ist ja nur Hobby, habe ja jetzt 128kb mit dem OCD Debugger und dem patch aus dem C103RB heraus geholt. Die haben ja alle 128kb statt 64. Schalte ich LTO ab und noch so eine Option bläst der Code auf 110kb auf und der geht noch rein.
Christian J. schrieb: > Nein, man kann nicht debuggen, Embitz > schmiert sogar komplett ab, wenn man es versucht. Wenn der Code nicht > zeile für zeile dem Kompilat entspricht ist Ende. Oy. Eclipse und GDB können das. Versuch mal -Og, das ist ein Kompromiss zwischen Debugbarkeit und Optimierung. Für Hobby kann man auch einfach einen F4 nehmen, die haben z.B. 1 MB, da braucht man sich gar keine Sorgen um Programmspeicher machen. Kostet ein paar Euro mehr und spart ein paar graue Haare.
Angehängte Dateien:


Ja, hat der Master auch, den 429er aber bei dem hier muss ich etwas knausern mit dem Platz.... packe das aber jetzt auch wieder weg und widme mich er Reparatur echter Hardware zum Anfassen, die auch glimmt und glüht und vor allem sehr schwer ist :-) -Og klappt echt gut und ist sogar nur 4 kb größer als das Minimum. Code ist echt atomar:
1 | (87) static storage_t DataToSafe[24]; /* Datenspeicher für 24h Stunden */ |
2 | (88) |
3 | (89) volatile uint32_t *ba = (uint32_t*)BitBandMemAddr(&ee_fat,0); |
4 | 08003086 lsls r3, r4, #5 |
5 | 08003088 bic.w r3, r3, #4261412864 ; 0xfe000000 |
6 | 0800308C bic.w r3, r3, #255 ; 0xff |
7 | 08003090 add.w r3, r3, #570425344 ; 0x22000000 |
8 | (90) |
9 | (91) ba[0] = 1; |
10 | 08003094 movs r2, #1 |
11 | 08003096 str r2, [r3, #0] |
12 | (92) ba[1] = 0; |
13 | 08003098 movs r1, #0 |
14 | 0800309A str r1, [r3, #4] |
15 | (93) ba[2] = 1; |
16 | 0800309C str r2, [r3, #8] |
17 | (94) ba[3] = 1; |
18 | 0800309E str r2, [r3, #12] |
19 | (95) |
20 | (96) v1 = ba[0]; |
21 | 080030A0 ldr r2, [r3, #0] |
22 | (97) v2 = ba[1]; |
23 | 080030A2 ldr r2, [r3, #4] |
24 | (98) v3 = ba[2]; |
25 | 080030A4 ldr r2, [r3, #8] |
26 | (99) v4 = ba[3]; |
27 | 080030A6 ldr r3, [r3, #12] |
Platz? Diese F407 Board hier könnte noch auf Deine Platine passen: http://www.ebay.de/itm/STM32F407VET6-ARM-Mini-Version-Core-Board-Cortex-M4-STM32-Minimum-System-Board-/122444767496?hash=item1c8246e108
Dr. Sommer schrieb: > Oy. Eclipse und GDB können das. Versuch mal -Og, Könntest Du mir mal zeigen wie -Og definiert ist? In der offiziellen GNU Doku finde ich das nicht.
Markus schrieb: > Platz? > Diese F407 Board hier könnte noch auf Deine Platine passen: > Ebay-Artikel Nr. 122444767496 Kenne ich. Ich habe die Masterplatine mit dem 407 gemacht, einfach ein Disko Board drauf gesteckt, wo ich diverses vorher abgelötet habe, da ich es nicht brauche. Und etliches an Peripherie dran gebaut. Das wuchs immer mehr. Da nutze ich einiges mehr an SPIs und I2Cs, bzw auch die 180 kb Ram. Aber für die kleinen Dinge reichen die 103 aus. Schnell muss nichts sein und Platz genug ist auch da. Habe 4 Timer im Einsatz, 2 als PWM, beide SPIs, eine I2C und noch die CRC Einheit, sowie die RTC und die Backup Register.
Christian J. schrieb: > Könntest Du mir mal zeigen wie -Og definiert ist? In der offiziellen GNU > Doku finde ich das nicht. Ich schon: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html -Og Optimize debugging experience. -Og enables optimizations that do not interfere with debugging. It should be the optimization level of choice for the standard edit-compile-debug cycle, offering a reasonable level of optimization while maintaining fast compilation and a good debugging experience.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.