Hallo alle zusammen.
Ich habe eine Platine welche mit einem STM32F429BIT bestückt ist.
Diese Platine steuert ein Display mittels emWin an.
Außerdem habe ich weitere Peripherien wie eine LAN Schnittstelle (lwip).
Bei der Lan Schnittstelle habe ich momentan nur das TCP ECHO Client
Beispiel aus den Cube Beispielen übernommen.
Alles funktionierte tadellos.
Allerdings musste ich aus mehreren Gründen die Platine überarbeiten und
auf den Pingleichen STM32F767BIT wechseln.
Dies ist mein erstes Projekt mit einem F7.
Um etwaige Fehler bei der überarbeiteten Platine besser eingrenzen zu
können habe ich 2 Stück meiner Prototypen mit meinem ursprünglichem
STM32F429 bestückt.
Ansonsten ist die Hardware die selbe.
Wenn ich die Software mit dem STM32F429 überspiele funktioniert alles.
Anschließend habe ich ein neues Cube Projekt für den F7 erstellt. Die
Software ist im Prinzip die selbe. Auch der Clock Tree wurde gleich
konfiguriert.
Allerdings habe ich jetzt mit Problemen zu kämpfen.
Mein Ethernet ist sehr langsam. Bei meinem Terminal Programm dauert es
manchmal ganze 2 Sekunden bis ich eine Antwort zurück bekomme.
Mir ist aufgefallen, dass dieses Problem nicht auftritt wenn ich STemWin
nicht einbinde.
Wissen muss man hierbei dass die Verwaltung der Ethernet Libary (lwip)
in der Main über ein Unterprogramm geschieht welches hier durchgehen
aufgerufen wird.
Nun bin ich davon ausgegangen dass hier etwas falsch initialisiert
wurde.
Allerdings finde ich keinen Initialisierungsfehler.
Um zu testen ob emWin mich ausbremst habe ich eine Variable erstellt
welche bei jedem Durchgang der main schleife erhöht wird.
Dabei kam ich zu folgendem Ergebniss:
F4 komplette Software: ~110.000 Durchgänge pro Sekunde
F7 komplette Software : ~nur 37.000 Durchgänge pro Sekunde
F7 ohne GUI_Exec in der Main: ~110.000 Durchgänge pro Sekunde.
Allerdings ist das Ethernet seltsamerweiße immer noch so langsam.
F7 komplett ohne STemWin: ~470.000 Durchgänge pro Sekunde. Lan läuft
flüssig.
Fällt hierbei jemanden ein an was das liegen könnte?
Ich denke dass möglicherweiße irgendwas bei der Initialisierung des F7
falsch gemacht. Etwas das es vielleicht beim F4 noch nicht gab.
Zumindest könnte ich es mir nur so erklären.
Also es gibt ja jetzt seit dem F7 einen D- und einen I-Cache.
So wirklich hab ich den Sinn dahinter noch nicht verstanden.
Wenn ich beide allerdings initialisiere finde ich die Platine allerdings
gar nicht mehr im Netzwerk.
Außerdem fällt dann gelegentlich das Bild für circa eine halbe Sekunde
aus.
In den Beispielen sind allerdings beide Caches stehts initialisiert.
Gibt es hier etwas einzustellen?
Laut Cube nicht.
Am DMA und den Speicherbereichen habe ich nichts verändert.
Wenn ich die Cube Beispiele von F4 und F7 vergleiche sind hier auch
keine Unterschiede zu finden.
Takfrequenzen sind wie gesagt bei beiden Controllern gleich gewählt
worden.
Waitstates?
Hallo,
ich habe nur mit dem SAME70 von Atmel/Microchip Erfahrungen,
welcher auch ein M7 ist.
Wenn der D(aten)-Cache und DMA zusammen in Betrieb sind, bekommt der
Cache die über DMA gelesenen Daten nicht mit.
Damit die CPU die eingelesenen Daten sehen kann, muss der Cache
invalidiert werden, er füllt sich dann aus dem RAM erneut auf. Ich habe
es mir einfacher gemacht und die vom Netzwerk-Stack benutzten Bereiche
als nicht cachebar eingestellt (in der Cortex M7 MPU).
Wie sieht es denn mit der Taktfrequenz aus ?
Zuerst läuft die CPU nur mit der Grundfrequenz (12 MHz ?), bis die PLL
zur Taktvervielfachung initialisiert wurde.
Gruß,
Martin C.
Vielen dank schon einmal für deine Hilfe!!
Ich denke so langsam komme ich der Sache näher.
Ich habe mir die Beispiele von STM noch einmal genauer angesehen.
Hier wird vor dem Enablen von D- und I-Cache einige MPU Funktionen
aufgerufen.
Anfangs dachte ich das dieses MPU nur dient um in irgendeiner weiße den
Speicher zu schützen.
Ich habe nun die entsprechenden Applikation Notea für caches und MPU
überflogen.
Hier gibt es tatsächlich einen Eintrag über Probleme mit dem DMA in
Kombination mit dem Datencache.
Ab Seite 8:
http://www.st.com/content/ccc/resource/technical/document/application_note/group0/08/dd/25/9c/4d/83/43/12/DM00272913/files/DM00272913.pdf/jcr:content/translations/en.DM00272913.pdf
Hier werden außerdem einige Lösungen genannt. Unter anderem den Bereich
nicht Cachebar zu machen, so wie du sagtest.
Die MPU Beispiele von STM sehen wie folgt aus:
(STM32F756BI)
1
/**
2
* @brief Configure the MPU attributes as Write Through for SRAM1/2.
3
* @note The Base Address is 0x20010000 since this memory interface is the AXI.
4
* The Region Size is 256KB, it is related to SRAM1 and SRAM2 memory size.
Seit dem ich diesen Teil im Code übernommen habe kann ich gleichzeitig
das Lan und StemWin verwenden.
Das Lan ist jetzt trotz eingebunden D- und i-Cache erreichbar.
Allerdings habe ich jetzt wieder die kurzen Bildaussetzer, welche ich
bereits in meinem vorherigen Post erwähnt habe.
Außerdem kommt es gelegentlich vor, dass einzelne Nachrichten vom Lan
wieder einen kurzen Augenblick dauern.
Insgesamt ist es jetzt zwar viel schneller aber durch die gelegentlichen
Aussetzer für meine spätere Applikation nicht hinnehmbar.
Ich werde mich wohl in die Caches, ihre Bedeutung und den MPU noch
genauer einlesen müssen. Vielleicht habe ich hier noch etwas übersehen.
Oder erkennt jemand eine Abweichung / Fehler in meinem Code?
wichtiges thema ist auch aligning
ich habe den LAN buffer in den extra 16K SRAM gelegt
dazu auch passend die MPU setzen ...
im Linkerfile habe ich alles auf ALIGN(8) gesetzt
hae festgestellt das größere Projekte irgendwann diese bremseffekte
zeigen
wenn man jedoch aligning beachtet gehts ...
ich habe immer auf O2 optimiert
dann läuft auch der LWIP gut
LwIP hat einen eigenen Heap und nutzt für die TCBs die eignenen malloc
funtionen .. nicht die blockvariante
ich schaue morgen mal nach und zeig mal meine config..( lwip, ethernet ,
mpu PLL )
nutzt du das original Linker file?
das war ei mir damals auch prolematisch weil er a 0x200000
durchaddressiert.
obwohl da 3 bereiche liegen
problem ist dann der DMA der nicht überall sauber abeitet
Könntest du mir noch sagen, wie du im Cube die Cortex_M7_Configuration
gewählt hast?
Auf was steht
-Flash Interface?
-Art Accelerator?
-Instruction Prefetch?
-CPU ICache?
-CPU DCache?
Sobald ich dies weiß werde ich deine Änderungen einfach mal in mein
Projekt übernehmmen und ausprobieren.
was reicht nicht aus vom LAN her?
ich habe
SIP,
RTP,
MJPEG stream empfangen,
TLS websocket verbindung
Sylog spam
und das alles parallel
inkl software audio verarbeitung ( echo usw ) und JPEG softwaredecoder
32zuterrtzkutehte schrieb:> achso ..>> caches sind alle AN> prefetch an> MPU auch an
Ich habe dein Beispiel jetzt übernommen und getestet.
Das mit dem System_Init und dem Linker File hab ich weggelassen, weil
mir das zu heikel war dort etwas zu verstellen.
Resultat:
Die Main Schleife wird jetzt noch langsamer durchlaufen....
Nur noch 20.000 Durchgänge pro Sekunde.
Aber: Das Lan funktioniert jetzt!!!
Ich verstehe den Zusammenhang nicht :-/
Könntest du es mir möglicherweise ein wenig erklären, was die geänderten
Zeilen bewirken?
Aufgrund der langsamen Main bin ich mir trotz allem noch nicht sicher ob
ich es so lassen kann :-/
hast du dein linker file auch angepasst was die section "eth"
beinhaltet?
Problem sind die Speicherbereiche die zwar zusammenhängend ab adresse
0x2000000 sind ...
aber!!!
DTCM hat 64bit anbindung glaube und ist daher schneller
SRAM1 240kb hat nur 32bit anbindung und damit langsamer
SRAM2 16kb auch nur 32bit aber über anderen Bus angebunden und damit für
ETH/USB besser
das ganze teil ist eine wissenschaft für sich.
ich habe jetzt im linker alles auf 8byte aligned und verschenke damit
ein paar byte ...
aber ich brauch nicht mehr so super genau aufpassen wo welches byte
landet.
da ich ein RTOS nutze was mit heap_5 betrieben wird und den rest vom
DTCM , SRAM1 als dynamischen heap nutzt...
probleme hat der M7 immer dann wenn er nicht richtig aligned ist...
dann wird ein teil der SW zum bremsklotz
witzig ist dann zB auch wenn 1-2 Tasks ( von 10 ) langsamer laufen ..
der rest aber weiterhin schnell agiert
man sucht sich dann blöd
Matthias F. schrieb:> enn ich von deinem Code nur das hier übernehme:> ethernetif.c:> __ALIGN_BEGIN ETH_DMADescTypeDef> __attribute__((__section__(".eth"),used)) DMARxDscrTab[ETH_RXBUFNB]> __attribute__((aligned(8)));/* Ethernet Rx MA Descriptor */> __ALIGN_BEGIN ETH_DMADescTypeDef> __attribute__((__section__(".eth"),used)) DMATxDscrTab[ETH_TXBUFNB]> __attribute__((aligned(8)));/* Ethernet Tx DMA Descriptor */> __ALIGN_BEGIN uint8_t __attribute__((__section__(".eth"),used))> Rx_Buff[ETH_RXBUFNB][ETH_RX_BUF_SIZE] __attribute__((aligned(8))); /*> Ethernet Receive Buffer */> __ALIGN_BEGIN uint8_t __attribute__((__section__(".eth"),used))> Tx_Buff[ETH_TXBUFNB][ETH_TX_BUF_SIZE] __attribute__((aligned(8))); /*> Ethernet Transmit Buffer */>> geht das Lan wie es soll. Allerdings wird die Main nur 40.000 in der> Sekunde durchlaufen.
hier werden die buffer für die LAN schnittstelle
also descriptoren und TX/RX Buffer
auf 8byte aligned in die extra 16kb SRAM 2 gelegt
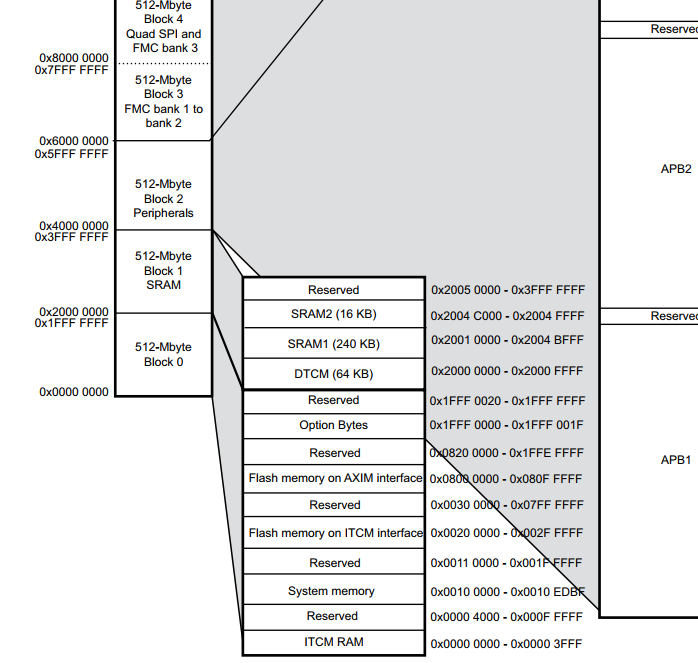
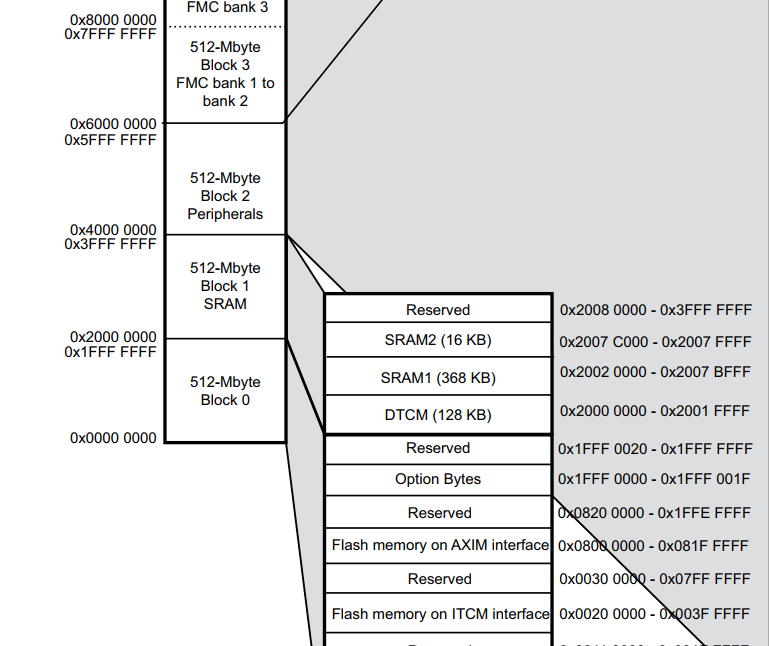
0x20000000...........0x20010000..............................0x2004C000.
...
_____DTCM RAM_______|______240kb SRAM_______________________|__16kb SRAM
..
der DTCM ist aber an einem anderen BUS angebunden
Daher auch probleme mit DMA und daten die im DTCM RAM liegen.
ich würde von anfang an aufpassen wo welche daten liegen.
es ist dem µC nicht egal welcher RAM bereich das ist .
zB musst du mal schauen wo der STACK in deinem Linkerfile liegt.
wenn du nur eine RAM region hast udn der STACK liegt am ende ...
ist er momentan in den letzten 16kb
STACK sollte im indealfall im DTCM liegen
also den ersten 64kb
bei mir am ende des DTCM RAM
wenn man den ganzen quatsch mal umgebogen hat , gehts
wenn dir das zu langsam ist ..
lege die funktion in den ITCM RAM
hier ist quasi auch 0Waitstates für befehle und damit voller MCU takt
der JPEG decoder von elm chan läuft dann auf ca 260% gegenüber normalen
funktionen aus dem Flash
Soory, ich war die letzen Tage geschäftlich unterwegs.
32zuterrtzkutehte schrieb:> hast du dein linker file auch angepasst was die section "eth"> beinhaltet?
Nein das Linker File war mir zu heikel um dort etwas zu verändern.
Aber so wie du es erklärst würde es womöglich schon Sinn machen dort
etwas zu verändern.
Die Sektion .eth gibt es bei mir nicht. Hast du diesen neu angelegt?
> probleme hat der M7 immer dann wenn er nicht richtig aligned ist...> dann wird ein teil der SW zum bremsklotz
Seltsam ist das dieses Problem beim M4 nicht hat. Zumindest ist es bei
mir noch nicht aufgetaucht.
> hier werden die buffer für die LAN schnittstelle> also descriptoren und TX/RX Buffer> auf 8byte aligned in die extra 16kb SRAM 2 gelegt
So ganz verstehe ich das noch nicht :-/
Du legst also den buffer gezielt in einen anderen Speicherbereich.
Was genau sagt hierbei das aligned aus?
> der DTCM ist aber an einem anderen BUS angebunden> Daher auch probleme mit DMA und daten die im DTCM RAM liegen.>> ich würde von anfang an aufpassen wo welche daten liegen.> es ist dem µC nicht egal welcher RAM bereich das ist .
Momentan sieht mein Linker File noch so aus:
1
MEMORY
2
{
3
RAM(xrw):ORIGIN=0x20000000,LENGTH=512K
4
FLASH(rx):ORIGIN=0x8000000,LENGTH=2048K
5
}
Der DTCM ist bei 0x2000 000 - 0x2001 FFFF.
Das heißt momentan wird erst der DTCM befüllt und anschließend der
normale Ram. Ich bestimmte aber momentan noch nicht wo welche Daten
liegen?
>> STACK sollte im indealfall im DTCM liegen> also den ersten 64kb> bei mir am ende des DTCM RAM
Ok das könnte ich mal testen
Nochmals vielen Dank für deine Hilfe.
Eine solche gute Antwort findet man eher seltener in diesem Forum.
Ich habe das Grundproblem jetzt dank deiner Hilfe verstanden.
Außerdem habe mir nochmals das Cube Beispiel vom Ethernet des F7
angesehen.
Tatsächlich wird hier der Speicher des Ethernet auch im Linkerscript
verschoben. Dies ist mir zu Beginn nicht aufgefallen.
Ich werde die Änderungen nun aus dem Cube Beispiel übernehmen.
Sollte ich in Zukunft weitere Geschwindigkeits-Probleme bekommen werde
ich auch deine anderen Änderungen übernehmen.
Matthias F. schrieb:> Eine solche gute Antwort findet man eher seltener in diesem Forum.
ich kann sowas auch nicht gut erklären ^^
ob ich damit richtig liege weiß ich leider selbst nicht 100%ig.
Ich habe aber viele anfängliche Probleme durch viel testen beseitigt
bekommen.
Ich hatte oft Probleme mit SW teilen die schon ewig funktioniert hatten
, dann plötzlich aber langsam wurden auch wenn nur minimal was geändert
wurde.
zB eine zusätzliche Variable in ein struct.
Ganze SW teile waren danach total langsam.
Durch das neue kompilieren inkl der neuordnung der Variablen war dann
die eine oder andere Variable nicht richtig aligned.
die zugriffe werden dann x mal hin und hergeschoben und das bremmst dann
massiv.
erst das 8byte aligning und die manuelle ordnung im RAM brachten das
gewünschte ergebnis.
Ich würde dennoch von anfang an den RAM richtig aufteilen.
Im Cube Script war auch mal der Fehler den STACK am ende des DTCM zu
legen.
OK , funktioniert.
Da das aber nur ein pointer ist und kein reservierter Bereich. kann man
ein großes Array anlegen und schreibt vom DTCM über den STACK in den
normalen RAM
witzig wirds erst dann wenn DMA dazukommt und seine Probleme mit dem
DTCM RAM hat.
Denn der DMA kann leider nicht überall hin schreiben/lesen