Hallo, ich nutze einen Arm Cortex M4 und möchte Fixed point Multiplikation machen. Ich nutze Fix 15.16, also in einer 32Bit variable. Für die Multiplikation habe ich mir ein Define geschrieben: #define MUL_FIX15_16 (x,y) (((int64_t)(x) * (int64_t)(y))>>16) Das setzt der compiler aber nicht korrekt um. Normalweise würde ich folgenden ASM erwarten: SMULL r0, r1, r2, r3 LSL r1, r1, #16 ORR r1, r0, LSR #16 Daher erst eine Long signed multiplikation, dann um 16 geshifted zusammenfügen. Allerdings kommt nur eine SMULWB orperation raus (16-bit by 32-bit signed multiply returning 32-most-significant-bits, bottom), damit fehlt das obere word des ersten Operanden. Ich habe mir jetzt beholfen, eine inline ASM funktion zu schreiben, damit funktioniert es auch, aber gibt es die möglichkeit, das define anzupassen, damit es trotzdem korrekt umgesetzt wird? Gruß, Martin
Martin schrieb: > #define MUL_FIX15_16 (x,y) (((int64_t)(x) * (int64_t)(y))>>16) > ____________________^ Da ist ein Leerzeichen zu viel.
Welchen Compiler benutzt du? Bei mir sieht das so aus: test.c:
1 | #include <stdint.h> |
2 | |
3 | #define MUL_FIX15_16(x,y) (((int64_t)(x) * (int64_t)(y))>>16)
|
4 | |
5 | int32_t mul_fix15_16(int32_t x, int32_t y) { |
6 | return MUL_FIX15_16(x, y); |
7 | }
|
Compileraufruf:
1 | arm-none-eabi-gcc-7.2.0 -mcpu=cortex-m4 -O2 -S test.c |
test.s (Ausschnitt):
1 | mul_fix15_16: |
2 | smull r2, r3, r0, r1 |
3 | lsrs r0, r2, #16 |
4 | orr r0, r0, r3, lsl #16 |
5 | bx lr |
Das entspricht doch deinen Erwartungen, oder?
Bekomm ich auch mit GCC 8:
1 | typedef __INT32_TYPE__ int32_t; |
2 | typedef __INT64_TYPE__ int64_t; |
3 | |
4 | #define MUL_FIX15_16(x,y) (((int64_t)(x) * (int64_t)(y)) >> 16)
|
5 | |
6 | int32_t mul_fix15_16 (int32_t x, int32_t y) |
7 | {
|
8 | return MUL_FIX15_16 (x, y); |
9 | }
|
10 | |
11 | typedef signed _Accum fix16_15_t; |
12 | |
13 | fix16_15_t mul_fix16_15 (fix16_15_t x, fix16_15_t y) |
14 | {
|
15 | return x * y; |
16 | }
|
17 | /*
|
18 | $ echo | arm-eabi-gcc -xc - -E -dM |sort | grep -i __ACC
|
19 | #define __ACCUM_EPSILON__ 0x1P-15K
|
20 | #define __ACCUM_FBIT__ 15
|
21 | #define __ACCUM_IBIT__ 16
|
22 | #define __ACCUM_MAX__ 0X7FFFFFFFP-15K
|
23 | #define __ACCUM_MIN__ (-0X1P15K-0X1P15K)
|
24 | */
|
1 | .cpu arm7tdmi |
2 | mul_fix15_16: |
3 | smull r2, r3, r0, r1 |
4 | lsr r0, r2, #16 |
5 | orr r0, r0, r3, lsl #16 |
6 | bx lr |
7 | |
8 | mul_fix16_15: |
9 | smull r2, r3, r0, r1 |
10 | mov r0, r2 |
11 | lsl r3, r3, #17 |
12 | orr r0, r3, r0, lsr #15 |
13 | bx lr |
14 | |
15 | .ident "GCC: (GNU) 8.0.0 20170817 (experimental)" |
Falls die Fixed-Point Typen von Embedded-C verwendet werden wie in mul_fix16_15, darf natürlich kein Shift und kein Cast stehen. Wie an den internen Makros ersichtlich hat accum Q-Format s16.15, nicht s15.16.
Hast Du schon geschrieben, in welchem Kontext der Compiler das macht? Also zumindest noch zu zeigen: - Die Anweisung mit MUL_FIX15_16 - Die (Basis)Typen aller beteiligten Operanden und dem LValue - den Wertebereich, den der Compiler dafür annehmen kann vielleicht ist x ja in jedem Fall 0..255, wozu sollte er dann die obersten 3 Byte berücksichtigen? Es ist ja gerade keine Funktion.
Angehängte Dateien:
-

fix.png
44 KB
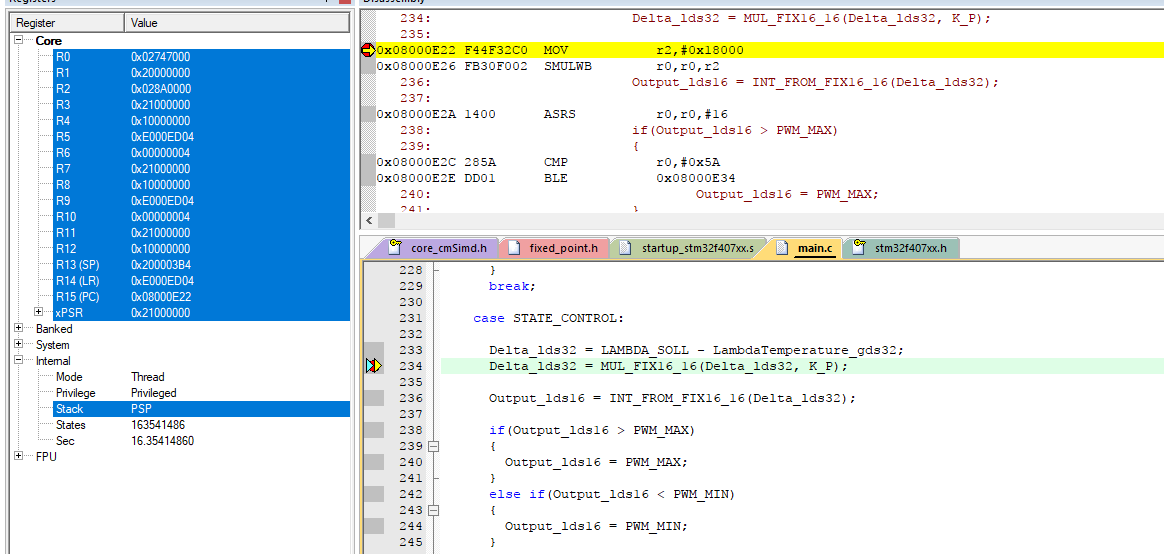
Hallo, ich nutze den Keil ARM compiler. Im Bild kann man sehen, dass in R2 0x18000 geladen wird, das ist K_P, also 1,5. Delta_lds32 hat den Wert 0x2747000, also 628,xxx Bei mir müsste dann irgendwas mit 900 rauskommen, aber das Ergebnis ist bei mir negativ, 0xFECD0000 Das haut irgendwie nicht hin oder ich übersehe was.
Ich habe das Problem gefunden: Wenn ich auf uint64_t caste, funktioniert es. Daher ist mein Macro nun: #define MUL_FIX16_16(x,y) ((int32_t)((uint64_t)((int64_t)(x) * (int64_t)(y)) >> 16)) Nicht schön, die vielen Casts, aber es funktioniert.
das ist ein Function like Macro, die frage ist nur warum nicht gleich eine Funktion draus machen. mit dem Attribute "inline" versehen sollte es den gleiche code genereien. ich denke der KEIL fürn ARM ist eigentlich ein GNU dann gehts nach diesem muster im HEader
1 | static inline __attribute__((always_inline)) int fn(const char *s) |
2 | {
|
3 | return (!s || (*s == '\0')); |
4 | }
|
Martin schrieb: > Ich habe das Problem gefunden: Wenn ich auf uint64_t caste, > funktioniert > es. Logisch... Das recht-shiften von "signed" Typen ist von C(++) nicht definiert, da kann irgendwas raus kommen. Root schrieb: > das ist ein Function like Macro, die frage ist nur warum nicht > gleich > eine Funktion draus machen. Ist doch viel lustiger, wenn man sowas wie "x++" an ein Makro übergibt ;-) Man könnte sich natürlich auch (in C++) seine eigene "FixedPoint" Klasse definieren, und die arithmetischen Operatoren entsprechend überladen, dann muss man gar nicht mehr mit Makros und expliziten Funktionsaufrufen rumhantieren, sondern kann seine Formeln so hinschreiben wie sie sind.
Dr. Sommer schrieb: > Logisch... Das recht-shiften von "signed" Typen ist von C(++) nicht > definiert, da kann irgendwas raus kommen. Der Rechts-Shift ist immer dann eindeutig definiert, wenn der linke Operand nichtnegativ ist (und der rechte innerhalb erlaubter Grenzen liegt). Im Martins Beispiel sind beide Faktoren positiv. Da die Multiplikation keinen Überlauf ergibt, ist auch das Ergebnis positiv. Damit sollte auch die Verschiebung um 16 Bit nach rechts das erwartete Ergebnis liefern. Dass das nicht der Fall ist, deutet für mich auf einen Compiler-Bug hin. Ist das Produkt negativ, ist das Ergebnis implementation-defined (nicht undefined). Im Compiler-Handbuch sollte spezifiziert sein, wie das Ergebnis in diesem Fall aussieht. In der Praxis gibt es dafür eigentlich nur zwei Alternativen: 1. Der Shift erfolgt arithmetisch, d.h. das Vorzeichen bleibt erhalten. 2. Der Shift erfolgt logisch, d.h. freiwerdenden höherwertigen Bitpositionen werden mit Nullen aufgefüllt. Bei einem Rechts-Shift um 16 Bits macht sich der Unterschied zwischen diesen beiden Alternativen nur in den höchstwertigen 16 der 64 Bits bemerkbar. Diese werden aber bei der Zuweisung an eine 32-Bit-Variable abgeschnitten, so dass das Ergebnis auch bei einem negativen Produkt stimmen sollte. Zwar ist auch die Umwandung von int64_t nach int32_t implementation-defined, aber auch hier wird man bei der üblichen Zweierkomplementdarstellung der meisten Prozessoren (inkl. ARM) keine Überraschungen erleben. Ich würde ein abgespecktes Beispiel mit Bitte um Stellungnahme an Keil schicken.
Martin schrieb: > Im Bild kann man sehen, dass in R2 0x18000 geladen wird, das ist K_P, > also 1,5. > > Delta_lds32 hat den Wert 0x2747000, also 628,xxx > > Bei mir müsste dann irgendwas mit 900 rauskommen, aber das Ergebnis ist > bei mir negativ, 0xFECD0000 Dass das Ergebnis mit SMULWB falsch wird, ist klar. Trotzdem würde ich auch mit SMULWB nicht 0xFECD0000, sondern 0xFEC5C800 (Bits 47-16 von 0x2747000*(-0x8000)) als Ergebnis erwarten.
Yalu X. schrieb: > Dass das nicht der Fall ist, deutet für mich auf einen > Compiler-Bug hin. Hat denn der TO irgendwo ein Beispiel im relevanten Kontext gezeigt? Solange kein Codebeispiel da ist, vermute ich einfach falschen Code.
Achim S. schrieb: > Yalu X. schrieb: >> Dass das nicht der Fall ist, deutet für mich auf einen >> Compiler-Bug hin. > > Hat denn der TO irgendwo ein Beispiel im relevanten Kontext gezeigt? > Solange kein Codebeispiel da ist, vermute ich einfach falschen Code. Du hast recht, so ganz sicher ist das nicht. Allerdings geht aus Martins Screenshot Martin schrieb: > Bild schon einiges hervor, so z.B., dass das Makro mit einem variablen (0x02747000) und einem konstanten (0x00018000) Argument aufgerufen wird. Letzteres wird zwar vollständig in ein Register (r2) geladen, das nachfolgende SMULWB ignoriert aber dessen höherwertige Hälfte. Damit wird das variable Argument mit -0x8000 statt mit 0x18000 multipliziert. Dieser Fehler löst sich auch nicht dadurch auf, dass das Produkt anschließend mit ASRS um 16 Bits nach rechts geshiftet wird. Was mich etwas stutzig macht, ist der Makroname: Im Eröffnungsbeitrag heißt das Makro MUL_FIX15_16, im Screenshot und dem nachfolgenden Beitrag MUL_FIX16_16. Ist das nur ein Vertipper, oder sind das tatsächlich zwei unterschiedliche Makros, von denen wir das tatsächlich verwendete noch gar nicht zu Gesicht bekommen haben?
Yalu X. schrieb: > Ist das nur ein Vertipper, wobei mir sowas aus Erfahrung immer Suspekt ist. Wenn jemand ausführlich einen defizilen Fehler beschreibt, ... und dazu Codezeilen abtippt(!). OK, manchmal läufen Code und Browser auf verschiedenen Rechnern. Aber hier scheint mir der TO noch immer zu glauben, dass der Compiler ein Makro in Assemblercode umsetzt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.