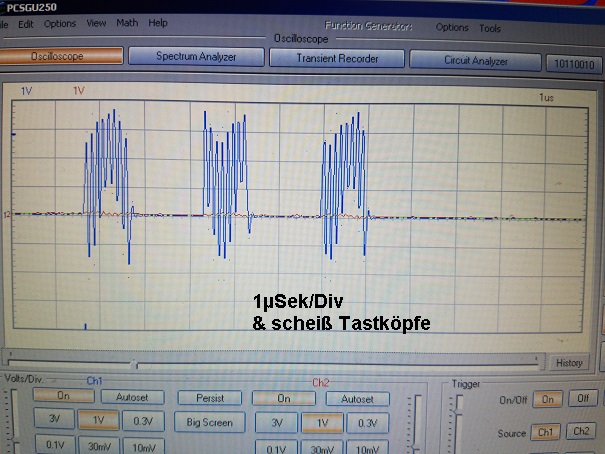
Moin,
hab zwei XMega 8e5, die über SPI kommunizieren.
Jetzt versuche ich die Geschwindigkeit bis zum Maximum hochzudrehen.
Dazu habe ich den Modus mit Pufferung aktiviert (SPI_PORT.CTRLB =
0b11000000).
Optimierung ist auf -O1. SPI-IRs haben höchste Priorität.
Die Datenübertragung ist sauber, die Werte kommen an. Auf dem Oszi sehe
ich jetzt, dass zwischen den Bytes immer eine riesige Lücke ist. Also
1µSek erstes Byte, dann 1,5µSek Loch, dann 1µSek zweites Byte, dann
1,5µSek Loch und so weiter. Ich komme damit auf 400 kB pro Sekunde
Maximum. Ist hier Ende Gelände? Im Datenblatt find ich nichts zur
maximalen Geschwindigkeit.
Danke!
Christoph
Für alle, die es intressiert, hier der Code des Masters, der des Slave
ist ähnlich:
1
ISR(SPIC_INT_vect)// SPI-Interrupt
2
{if(SPI_PORT.STATUS&0b10000000)// empfangenes Byte bereit zum Auslesen?
SPI_PORT.INTCTRL&=~0b00100000;// deaktiviere Interrupts bei bereitem Sendepuffer
18
}
19
}
20
}
21
22
23
voidinitialisiere_SPI_Master(void)// SPI an PORTC einstellen
24
{cli();// Interrupts deaktivieren
25
SPI_PORT.CTRL=0b01010000;// SPI master, clock idle low, data setup on trailing edge, data sampled on leading edge, Geschw 32MHZ/4
26
SPI_PORT.CTRLB=0b11000000;// gepuffert Modus 1, sofort laden
27
SPI_PORT.INTCTRL=0b10000010;// 00: aus, 01: niedrige, 10: mittelere, 11: hohe Priorität => mittlere, denn Master darf zwischendurch anhalten, Slave muss reagieren
Nur mit der ISR und dem Init wir dir hier kaum einer helfen können.
1,5 us sind bei 32 MHz 48 Takte. Schau einfach im dissambly was der
xMega von Start vom senden bis zum nächsten Byte macht.
Gruß JackFrost
Wenn du jedes Byte per Interrupt holst wird das so langsam sein.
Die ISR verschlingt ja einiges an Zeit/Overhead.
Meine XMega128A1 konnten / können auch SPI mit Double Speed,
d.h. bei 32 MHz Taktfrequenz läuft das SPI mit maximal 16MHz
und nicht mit Clock/4.
Frickelfritze schrieb:> Wenn du jedes Byte per Interrupt holst wird das so langsam sein.
Sehe ich genauso. Interrupt bei SPI hat höchstens dann Sinn, wenn
man mit sehr niedriger SPI-Taktrate arbeitet. Wenn man versucht, da
maximal Geschwindigkeit rauszuholen, geht das nur mit Polling. Sind
ja eh nur ein paar CPU-Takte, die man damit verwartet.
Alternativ sollte Burst-SPI beim Xmega ja auch per DMA machbar sein,
sofern das mit dem Client auch passt.
Jörg W. schrieb:> Sehe ich genauso. Interrupt bei SPI hat höchstens dann Sinn, wenn> man mit sehr niedriger SPI-Taktrate arbeitet. Wenn man versucht, da> maximal Geschwindigkeit rauszuholen, geht das nur mit Polling. Sind> ja eh nur ein paar CPU-Takte, die man damit verwartet.
Das ist Unsinn. Wenn man SPI wirklich so ausnutzt, sind Interrupts
tatsächlich nicht zielführend, dann braucht man aber auch kein Polling,
sondern nur optimale (taktzyklengenaue) Ansteuerung, erst dann ergibt so
ein Burst-Betrieb irgendeinen Sinn.
Ja, das geht nicht mit C, but who cares... In C geht es immerhin, wenn
man DMA dafür benutzen kann. Aber am Ende jeder DMA-Sequenz steht dann
doch wieder eine ISR...
Und wie wenig effizient in C implementierte ISRs sind, brauche ich ja
wohl kaum noch zu erwähnen. Höchstens auf ausdrücklichen Wunsch...
c-hater schrieb:> Aber am Ende jeder DMA-Sequenz steht dann> doch wieder eine ISR...
Kann es sein, dass man ab und an auch Daten "verarbeiten" will? Nur mal
so gefragt ...
Dieter F. schrieb:> Kann es sein, dass man ab und an auch Daten "verarbeiten" will? Nur mal> so gefragt ...
Natürlich, das ist sogar der absolute Normalfall.
Das geht am am Einfachsten, wenn man möglichst linear Code vor sich
hinrödeln lassen kann. Das ist, wofür z.B. C-Compiler optimieren. Das
können sie (inzwischen) sogar sehr gut.
Nur ist die böse Realität halt nie so gnädig, die Eingabe genau in dem
Moment bereit zu stellen, wo der Code sie braucht und nur sehr selten
ist sie so gnädig, das Ergebnis der Berechnungen instantan im vollen
Umfang genau in dem Moment weiterleiten zu können, wenn sie vorliegen.
Kurz: die bösen IO-Erfordernisse sind oft der Knackpunkt, nicht die
eigentliche Rechenaufgabe...
Frickelfritze schrieb:> Wenn du jedes Byte per Interrupt holst wird das so langsam sein.> Die ISR verschlingt ja einiges an Zeit/Overhead.
Ok, ihr meint also die ISR ist zu lahm... da ich mit den
SPI-Hardware-Puffern arbeite, und die ISR während der Übertragung
bereits nachlädt, hätte ich jetzt nicht darauf getippt.
Werde mal ausprobieren, die Daten in einer stupiden while-Schleife in
die Hardware zu ballern, nur mal um zu gucken, ob es dann schneller
wird.
VG
Mit Overhead werden es wahrscheinlich um die 500 kBps. Muss wohl mal
EDMA ausprobieren... Das sieht zwar kompliziert aus, aber wohl die
einzige Lösung mit wenig CPU-Last und viel Geschwindigkeit!?
Danke noch mal! :)
Christoph M. schrieb:> Es ist tatsächlich die ISR, die alles ausbremst.
Interruptannahme, Registersicherung etc. verplempert einfach viel
Zeit.
> Muss wohl mal EDMA ausprobieren... Das sieht zwar kompliziert aus, aber> wohl die einzige Lösung mit wenig CPU-Last und viel Geschwindigkeit!?
Wenn man längere Sequenzen am Stück senden möchte, ist das die
sinnvollste Variante.