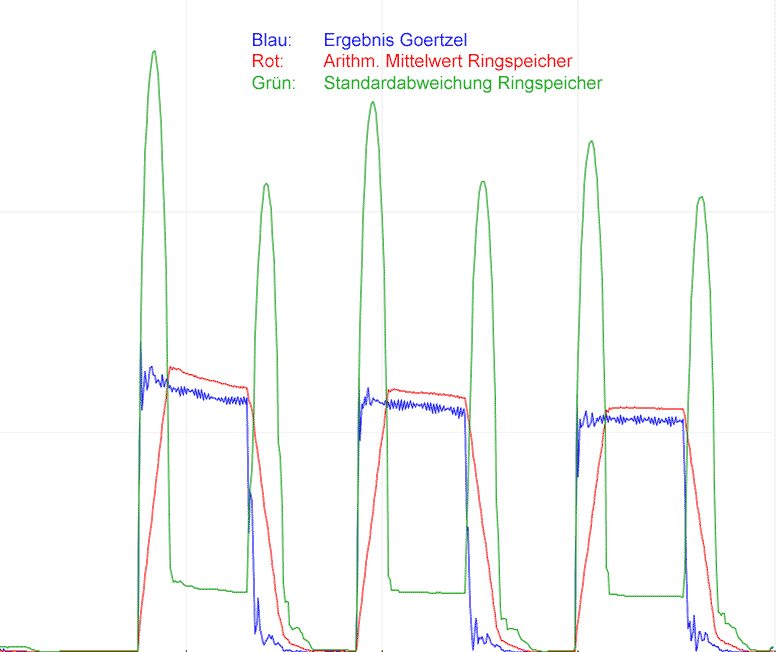
Hallo liebe DSPler,
habe am letzten und vorletztem langen Wochenende wohl ein paar graue
Haare mehr bekommen. Eines vorweg: Ich bin überhaupt nicht der
DSP-Spezi, also bitte nicht steinigen wenn mein Anliegen zu primitiv
etc. ist.
Ich möchte einen ca. z.B. 250 ms langen Ton (Länge bekannt, kann auch
deutlich länger sein) mit einer ebenso bekannten Frequenz (z.B. 4 KHz)
mit einem Mikrofon aus unbekannter akustischer Umgebung möglichst sicher
erkennen. Mit sampeln und der Erkennung mit dem Goertzel – Algorithmus
funktioniert das wunderbar, d.h. ich bekomme eine deutliche
Amplitudenänderung bei Detektion des Signals über die Zeitachse. Nur
leider kenne ich die Amplitude (= Ergebnis Goertzel) vorher nicht, so
dass ich keinen einfachen Schwellwert zur Auswertung einstellen könnte.
Dieser würde ggf. auch überschritten werden, wenn’s mal laut in der
Umgebung ohne Piepton wird bzw. nie erreicht werden, wenn der erkannte
Ton leiser ist.
Nun habe ich folgendes gemacht: Ich schreibe in einen Ring-Speicher (20
Werte / 50ms) die Goertzel-Ergebnisse, bilde den Mittelwert und
anschließend den Koeffizienten (entspricht Variationskoeffizient;
relative Standardabweichung) zw. letztem Messergebnis und eben diesem
Mittelwert. Liegt der zwischen 0.9 und 0.99, dann ist der Ton wohl
erkannt. Dieses Ergebnis wiederum zähle ich und wenn es häufig genug
hintereinander aufgetreten ist, dann ist der Ton erkannt. (siehe
Diagramm, absichtlich ohne Bemaßungsangabe)
Es funktioniert zwar, aber irgendwie ist mir das zu abenteuerlich
("unwissenschaftlich"). Gibt es hier einen besseren, prof. Ansatz (den
man auch verstehen kann)?
Beste Grüße
Angehängte Dateien:
-

Diagramm_www.png
20 KB
Es wird Dir gar nichts anderes über bleiben, als einen Schwellenwert zu nehmen, weil ab einer gewissen Distanz der Ton so oder so im Rauschen unter geht.
Analog OPA schrieb: > Es wird Dir gar nichts anderes über bleiben, als einen Schwellenwert zu > nehmen, weil ab einer gewissen Distanz der Ton so oder so im Rauschen > unter geht. Danke für die schnelle Antwort: Aber das ist ja das Problem, ich kenne den Schwellenwert nicht absolut. Beim Erkennen des Tons gibt es aber einen deutlich höheren Wert, der über dem (derzeitigem) Rauschen liegt. Klar, wenn's im Rauschen untergeht, dann geht es halt nicht. Und das ist eben mein Problem, diesen "Pegelsprung" zuverlässig zu detektieren, ohne die absoluten Werte zu kennen.
Was ist daran "unwissenschaftlich"? Soweit ich verstanden habe, misst du wie "stark" deine Signalform in der Aufzeichnung vertreten ist und falls sich dieser Anteil sprunghaft erhöht, gilt dein Signal als erkannt. Ist meiner Meinung nach ein fundierter Ansatz. Zu Prüfen wäre, ob und wie wahrscheinlich false positives sind und wie man diese gegebenenfalls (z.B. durch Codierung) los wird.
>>> dass ich keinen einfachen Schwellwert zur Auswertung einstellen könnte.
Standard SNR Ding: Du nimmst das Verhältnis der Energie des Tons aus dem
Goertzel ( = Quadrat der Amplitude ) zur Gesamtenergie der samples ( =
Summe aller samplequadrate). Dann machst Du auf den Quotienten einen
Schwellwert, z.B. 10 Prozent aller Energie im Ton.
Cheers
Detlef
Du koenntest einen zweiten Goertzel 500 Hz tiefer laufen lassen. Breitbandige Umgebungsgeraeusche wuerden dann beide ausloesen. Dein zu erkennender Ton nur einen. Den zweiten Kanal koennte eventuell auch gut als Schwellwertgeber dienen.
Ganz richtig wäre das mit nicht nur einem Ton, sondern eben dem vollständigen Restspektrum (eben das, was nicht "Ton" ist) unter Veranschlagung dessen Spektralverlaufes und Amplitudengrenzen. Das läuft dann auch einen sich in der Amplitude anpassenden Filter hinaus. Die Alternative ist das Prozessieren indirekt in der Frequenzebene, um sich von der Amplitude unabhängig zu machen. Das ist dann so etwas wie ein "Multifrequenz-Görtzel" mit autoadaptiven Frequenzen.
Im Prinzip hast Du das selbe Problem, wie ich mit meinem Morsedekoder. Du brauchst einen langfristigen Mittelwert als Vergleichswert. Und dieser Wert sollte über einen deutlich längeren Zeitraum ermittelt werden, als der zu erwartende Impuls. Ich mache das, indem ich einen gleitenden Mittelwert über das "Grungderäusch" ermittle. Alles was eine gewisse Zeit darüber liegt, wird als mögliches Signal betrachtet.
Herzlichen Dank für die schnellen und vor allem qualifizierten Antworten!!! Besonders interessant finde ich die Anwort von Detlef_a, das werde ich alsbald (WE?) mal ausprobieren. Lieber Jürgen Schuhmacher, Deinen Text habe ich ganz oft gelesen und immer ein bisschen mehr verstanden, aber nicht alles. Geht der Ansatz dahin, über (bspw. eine FFT) das gesamte Spektrum zu erfassen um zu sehen, was da amplitudenmäßig überhaupt los ist und dann mit dem Goertzel auf der Zielfrequenz zu vergleichen? Manfred: Wie ermittelst du den langfristigen Mittelwert? Den Morseton erkennst du über Goertzel oder nur am Amplitudenanstieg des Gesamtsignals?
Den langfristigen Mittelwert erhalte ich dadurch, dass ich das Ausgangssignal des Goertzel's parallel zur übrigen Auswertung in einen gleitenden Mittelwert laufen lasse. Das ist dann mein Vergleichswert. Für die eigentliche Signalauswertung wird das Ausgangssignal aber auch noch einmal gemittelt (über 1 bis 6 Samples - einstellbar) damit nicht jeder Knacks als Ton erkannt wird. Allerdings verwende ich in der aktuellen Version keinen Goertzel mehr. Bei längerer Auswertezeit ist der einfach zu schmalbandig, was bei schnell wechselnden Frequenzen zu unpraktisch ist. Zum Vergleich: ich arbeite mit einer Abtastrate von 8kHz, die gesuchte Frequenz ist 800Hz und der Ringpuffer fasst 40 Samples. Daraus ergibt sich eine Auswertezeit von 5ms. Die geschätzte Bandbreite liegt dann bei etwa 200Hz, der Durchlassbereich ist aber nicht flach.
@bitbeisser: Der Goertzel implementiert ein ungedämpftes System mit der auszuwertenden Frequenz als Resonanzfrequenz. In dieses System fütterst du die samples ein. Das ist sehr schmalbandig, an der Resonanzstelle wird die Verstärkung unendlich hoch, das System ist nicht stabil und die Ausgangsamplitude des Goertzel wird immer größer je mehr samples reinlaufen. Man kann die Bandbreite aber auch größer machen, indem man ein System nimmt das ein wenig gedämpft und damit stabil ist (Mehr Dämfung ist grössere Bandbreite). Wenn man einen Ton sucht aber die Frequenz nicht weiss geht das anders. Dazu habe ich mich hier mal ausführlichst geäußert: Beitrag "Frequenz, Amplitude und Phase eines Sinussignals bestimmen" Cheers Detlef
Das der Goertzel sehr schmalbandig sein kann, kann ich bestätigen. Wenn ich auf 80 Samples erhöhe, ist das für den Kurzwellenempfang nicht mehr handhabbar. Aber wenn sich die Frequenzen nicht ändern, wie z.B. bei den Wahltönen beim Telefon, kann das ja gewünscht sein. Aber das der nicht stabil sein soll, kann ich nicht nachvollziehen. Ich bin bisher immer von folgender Überlegung ausgegangen: Wenn ich einen Sinus der gesuchten Frequenz mit maximaler Amplitude habe, kann am Ausgang nicht mehr raus kommen als die Summe aller Beträge über die gegebene Anzahl von Taps. Das würde dann auch der Sichtweise entsprechen, wo der Goertzel als Spezialfall der Fourier Transformation betrachtet wird. Aber vielleicht sprichst Du von einer Variante, die mir unbekannt ist. > Man kann die Bandbreite aber auch größer machen, indem man > ein System nimmt das ein wenig gedämpft und damit stabil ist... Ich habe mal versucht die Eingangsdaten zu fenstern, so wie man es bei der FFT auch manchmal macht (wodurch der eigentliche Vorteil natürlich verloren geht). Das Funktioniert. Dabei verbessert sich auch die Dämpfung der Nebenzipfel, aber so breit und mit einem Durchlassbereich so rund wie eine Sinus Halbwelle, will man das Ding bestimmt nicht haben. > Wenn man einen Ton sucht aber die Frequenz nicht weiss geht das anders. Also ich mache das jetzt so, dass ich nebenbei eine FFT mitlaufen lasse und mir aus der Darstellung mittels Mausklick die Frequenz bestimme. Andere Programme suchen da innerhalb festgelegter Grenzen einfach nach dem stärksten Signal (und benötigen dann keine Grafik Ausgabe). Aber wenn die gesuchte Frequenz ausreichend genau bekannt und konstant ist, kann man diesen Aufwand sparen.
@Detlef_a:
> Standard SNR Ding: Du nimmst das Verhältnis der Energie des Tons aus ...
Genau das war's!!! Habe es am WE getestet und klappt GAAAAAANZ Prima!
Vielen Dank!!!!!!
So erledigt Generation Facebook also heute seine tägliche Arbeit: Anmelden im Netz, Wissen abgreifen und dann wieder abmelden, weil der account nicht mehr benötigt wird, denn man möchte sich ja nicht mehr im Forum beteiligen und gfs womöglich selber mal Wissen weitergeben und anderen helfen. So ist das heute.
Manfred M. schrieb: >> Wenn man einen Ton sucht aber die Frequenz nicht weiss geht das anders. > Also ich mache das jetzt so, dass ich nebenbei eine FFT mitlaufen lasse > und mir aus der Darstellung mittels Mausklick die Frequenz bestimme. Man kann aus zwei benachbarten Amplituden im Spektrum die richtige Frequenz ermitteln.
Rolf S. schrieb: > Manfred M. schrieb: >>> Wenn man einen Ton sucht aber die Frequenz nicht weiss geht das anders. >> Also ich mache das jetzt so, dass ich nebenbei eine FFT mitlaufen lasse >> und mir aus der Darstellung mittels Mausklick die Frequenz bestimme. > > Man kann aus zwei benachbarten Amplituden im Spektrum die richtige > Frequenz ermitteln. Kannst du das näher erläutern? Zwei benachbarte Amplituden können ja auch zwei Frequenzen sein.
Dieser Typ hat mal ne ganze Serie von Artikeln zur genauen Frequenzbestimmung aus FFTs geschrieben: https://www.dsprelated.com/showarticle/1127.php Das Problem sind da die Fensterfunktionen, die mache dir das ungenau afair. Wie gesagt, Frequenzbestimmung geht anders. Cheers Detlef
Detlef _. schrieb: > Das Problem sind da die Fensterfunktionen, die mache dir das ungenau > afair. Deshalb arbeitet mit unterschiedlichen Fensterfunktionen, bzw FFTs, die parallel und unterschiedlich arbeiten (und eben auch ganz ohne Fenster wuseln).
Jürgen S. schrieb: > Detlef _. schrieb: >> Das Problem sind da die Fensterfunktionen, die mache dir das ungenau >> afair. > > Deshalb arbeitet mit unterschiedlichen Fensterfunktionen, bzw FFTs, die > parallel und unterschiedlich arbeiten (und eben auch ganz ohne Fenster > wuseln). Ja, das geht mehr oder weniger gut mit FFTs. Als ichs' noch nicht besser wußte hab ichs auch so gemacht und propagiert, z.B. hier Beitrag "Genaue Frequenzbestimmung nach FFT" Es geht aber besser. Dargestellt hier: Beitrag "Frequenz, Amplitude und Phase eines Sinussignals bestimmen" Das funktioniert auch mit gedämpften Schwingungen, siehe hier: https://www.dsprelated.com/showarticle/795.php Besser geht das nicht. Punkt. Math rulez. Cheers Detlef
@Detlef: Ich bezog mich bei meiner Antwort nicht zwingend auf das Sonderproblem der Frequenzerkennung, sondern mehr auf die Frage das TE, nach der Tonerkennung überhaupt. Je nachdem, welchen Aspekt des Signals man fokussiert, sind unterschiedliche Fenster unterschiedlich gut dafür geeignet. Daher arbeitet man mitunter auch ohne Fenster, wenn es weiterverarbeitet werden soll und einer parallelen, um ein Signal zu vermessen und Informationen darüber zu gewinnen. Dynamische Frequenzkorrektursysteme a la Autotune arbeiten z.B. so. Die Frequenzbestimmung eines unbekannten Tones ist nochmal eine andere Frage, die aber hier nicht relevant ist, da die Frequenz dem TE ja bekannt zu sein scheint.
Ich kenne jetzt den Goertzel nicht im Detail, aber ist das Aufzeichnen mit nur EINEM Mikrofon Pflicht? Wie wäre es mit 2 Mirkos, eines das in Richtung Tonquelle zeigt und eines in eine andere Richtung (um nur die Umgebung zu erfassen). Das machen heutige Smartphone-Bauer ja auch so... Anschliessend würde ich beide Signale/Spektren/PSD von einander abziehen und schon ist der SNR wesentlich besser und eine Detektion einfacher. Klappte bei meiner Diplomarbeit und breitbandigen HF-Signalen sehr gut.
Naja, ein Mic hört nach hinten, eines nach vorn zur gewünschten Schallquelle. Dann hast du zwischen dem Störschall 'von hinten' und dem 'von vorn' zweimal die Schalllaufzeit zwischen mic und gewünschter Schallquelle. Keine Ahnung, ob sowas mit Schall gut geht. Cheers Detlef
Detlef _. schrieb: > aja, ein Mic hört nach hinten, eines nach vorn zur gewünschten > Schallquelle. Dann hast du zwischen dem Störschall 'von hinten' und dem > 'von vorn' zweimal die Schalllaufzeit zwischen mic und gewünschter > Schallquelle. Keine Ahnung, ob sowas mit Schall gut geht. Warum sollte das nicht gut gehen? Braucht nur einen Differenzverstärker. Ich fürchte nur, dass es so einfach nicht wird. Störschall kommt auch von vorne, woher das Nutzsignal kommt und von der Seite. Außerdem kann man ein Mikro auch durch Abschirmungsmassnahmen gegen Schall von hinten schützen.
>>Warum sollte das nicht gut gehen?
Weil das zeitverzögert ist, darum geht das nicht.
Cheers
Detlef
Detlef _. schrieb: > Weil das zeitverzögert ist, darum geht das nicht. Naja, bei bekanntem Frequenzbereich und bekanntem Mikrophon-Abstand sollte die (+-)Korrektur kein Problem sein.
Nee, ist es nicht. Viel Spass, sachma wenn geht. Cheer Detlef
Die Idee ist ja nicht schlecht, wird daber schon gemacht. In praktisch jedem Mikrofon gibt es Laufzeitglieder, die sich dieser Phasenüberlagerung bedienen, um Schallrichtungen zu fakussieren. Mit einem Array wiederum kann man auch DOA-Analyse betreiben. Es ist aber so, dass der Abstand vom Rauschen zum Signal odt nicht ausreicht, um mit mehreren überlagerten Mikrofonen einen nennenswerte Rauschunterdrückung zu gewinnnen.
Was spricht denn dagegen, den einfallenden Ton einfach mit dem Sollton zu korrelieren?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.