Hallo,
ich programmiere gerade ein simples digitales Filter auf einem ARM
Cortex M0+ (SAMD11). Der Compiler ist gcc. Dabei muss des öfteren durch
65536 dividiert werden, um den Zahlenbereich zu begrenzen. Korrekt würde
es also so lauten:
1
int32_tx;
2
...
3
x/=65536;
Allerdings ist die Division eine aufwändige Operation, da der ARM sie
iterativ berechnen muss, denn es gibt keinen Maschinen-Divisionsbefehl.
Theoretisch würde es genügen, die beiden oberen Bytes von x in die
beiden niederwertigsten Bytes zu verschieben:
1
int32_tx;
2
...
3
x>>=16;
Doch ist garantiert, dass bei negativem x von links Einsen eingeschoben
werden, so dass das Ergebnis negativ bleibt? Die ANSI-C-Dokumentationen
schweigen sich darüber aus. Mit gcc scheint es zu funktionieren, aber
wie sieht es bei anderen Compilern aus? Gibt es eine saubere
Möglichkeit, einen arithmetischen Shift erzwingen?
Mike schrieb:> Die ANSI-C-Dokumentationen> schweigen sich darüber aus.
Ausprobieren ist dir zu umständlich?
Hier Hobbyprogrammierer belästigen und eine unzuverlässige Info ist ja
viiiieeel wertvoller.
Hast du kontrolliert, ob "x /= 65536" eine aufwendige Division macht?
Normalerweise kennt der GCC-Optimizer mehr Tricks, als bei einem
Programmiere aus den Mathe Vorlesungen hängen geblieben ist.
Mike schrieb:> Doch ist garantiert, dass bei negativem x von links Einsen eingeschoben> werden, so dass das Ergebnis negativ bleibt?
Nein. Offiziell nicht. Ich kenne aber keine Plattform, bei der es anders
ist.
Allerdings ist das Ergebnis bei negativem Nenner auch bei
reingeschobenem Vorzeichen verschieden, wenn der Rest der Division nicht
0 ist.
A. K. schrieb:> Allerdings ist das Ergebnis bei negativem Nenner auch bei> reingeschobenem Vorzeichen verschieden, wenn der Rest der Division nicht> 0 ist.
Allerdings ist das Ergebnis bei negativem Zähler auch bei
reingeschobenem Vorzeichen verschieden, wenn der Rest der Division nicht
0 ist.
Mike schrieb:> Allerdings ist die Division eine aufwändige Operation, da der ARM sie> iterativ berechnen muss, denn es gibt keinen Maschinen-Divisionsbefehl.
Eigentlich sollte jeder halbwegs moderne Compiler eine
Division/Multiplikation auf Basis einer Zweipotenz erkennen und in eine
Schiebeoperation umwandeln.
M. K. schrieb:> Eigentlich sollte jeder halbwegs moderne Compiler eine> Division/Multiplikation auf Basis einer Zweipotenz erkennen und in eine> Schiebeoperation umwandeln.
Yep. Nur ist sdiv kürzer als die Ersatzsequenz.
Cortex M3, gcc 4.8.1, -Os:
mov r3, #65536
sdiv r0, r0, r3
und bei -O1:
add r3, r0, #65280
adds r3, r3, #255
bics r0, r0, r0, asr #32
it cs
movcs r0, r3
asrs r0, r0, #16
Detlev T. schrieb:> Ich habe es einmal kurz getestet. Selbst ohne Optimierung (-O0) macht> der gcc ... einen Shift-Befehl, der das Vorzeichen erhält.
Das ist prinzipiell falsch, weil in die falsche Richtung "gerundet"
wird.
Siehe http://codepad.org/s9bcOmkk oder http://codepad.org/8NMZ194I
Kurioserweise ist der gcc 6.3.1 Code für den Cortex M0
asr r3, r0, #31
lsr r3, r3, #16
add r0, r3, r0
asr r0, r0, #16
besser als der zeitoptimierte Code für den Cortex M3
add r3, r0, #65280
adds r3, r3, #255
bics r0, r0, r0, asr #32
it cs
movcs r0, r3
asrs r0, r0, #16
obwohl der M3 ein Superset des M0 ist.
Ich habe es mal mit meinem Compiler für die unterschiedlichen
Optimierungsstufen ausprobiert. Was das Hin-und Hergeschiebe bei -O(1)
macht, überschaue ich im Moment nicht, da ich mich mit Cortex-Assembler
nicht gut auskenne. Ab -O(2) wird immer arithmetisch geschoben.
Das Rundungsverhalten ist anscheinend nicht gleich. Arithmetisch ">>"
rundet ja immer zur nächstkleineren Zahl. "/" scheint dagegen zur Null
hinzurunden, wenn ich mich richtig erinnere. Der Compiler scheint sich
wohl nicht darum zu scheren.
-O(0)
Mike schrieb:> Was das Hin-und Hergeschiebe bei -O(1)> macht, überschaue ich im Moment nicht,
Der Compiler aber schon ...
> Der Compiler scheint sich wohl nicht darum zu scheren.
... weshalb diese Aussage etwas "mutig" ist. Denn das "Hin-und
Hergeschiebe" dient eben dazu, die Rundung richtig durchzuführen.
Prinzip für x / (1<<N):
if (x < 0)
x += (1<<N)-1;
x >>= N;
Genau das macht er in der nicht optimierten Version.
Die optimierte Version für den Cortex M0 erzeugt einen zu addierenden
Wert 0 oder (1<<N)-1 auf recht clevere Art.
Man sollte sich in diesem Zusammenhang auch mal Gedanken darüber machen,
welche Rundung man bei Integer-Division überhaupt bevorzugt: zur 0 hin
(wie in C) oder Richtung -∞ (wie in Python). Die letztere ist für mich
die logischere und in den meisten Anwendungen auch die geeignetere.
Reguläre Integer-Divisionen mit negativen Operanden verwende ich
deswegen in C so gut wie nie. Für Skalierungszwecke wie bspw. bei der
Festkommaarithmetik (die ich aber nur selten vorzeichenbehaftet
benötige) verwende ich ausschließlich Shift-Operationen. Dass der
>>-Operator für negative linke Operanden implementation-defined ist,
stört mich dabei nicht so sehr, da diesbezüglich alle von mir bisher
eingesetzten Compiler dasselbe Verhalten zeigen.
Für die vorliegende Anwendung in einem digitalen Filter (die ich
allerdings nicht im Detail kenne) dürfte die Shift-Operation ebenfalls
die bessere Wahl sein.
Yalu X. schrieb:> Man sollte sich in diesem Zusammenhang auch mal Gedanken darüber machen,> welche Rundung man bei Integer-Division überhaupt bevorzugt: zur 0 hin> (wie in C) oder Richtung -∞ (wie in Python). Die letztere ist für mich> die logischere und in den meisten Anwendungen auch die geeignetere.
Wobei "Runden" im Fall hier der falsche Begriff ist: es geht eher um ein
korrektes "Abschneiden". Es ist ein wenig verwirrend und überraschend,
wenn das Ergebnis der "Division" 3/16 den Wert 0 ergibt, aber -3/16 den
Wert -1
http://codepad.org/fHApZAda
Lothar M. schrieb:> Es ist ein wenig verwirrend […]
für den Kaufmann: ja
für den Mathematiker: nein
für den Ingenieur oder Informatiker: kommt darauf an :)
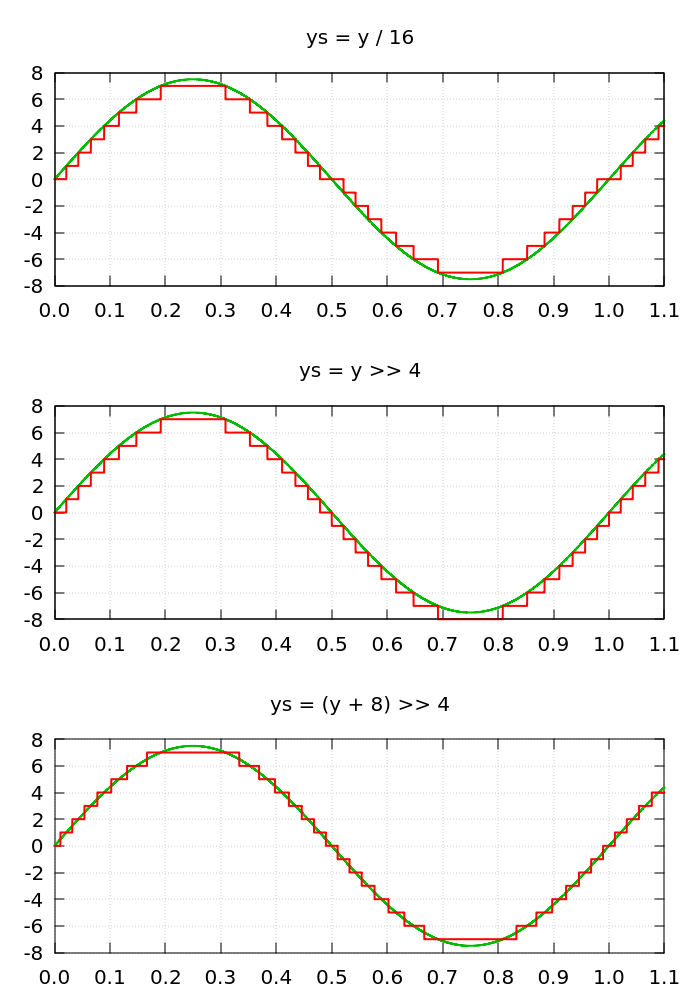
Im Anhang habe ich mal die verschiedenen Divisionsmöglichkeiten im
Hinblick auf die vorliegende Aufgabenstellung, nämlich die Skalierung
von Signalen, vergleichend dargestellt.
In allen drei Fällen wird von einem Sinussignal mit der Amplitude 120
ausgegangen. Damit die Werte in eine 8-Bit- Variable passen, soll das
Signal um den Faktor 16 herunterskaliert werden. In den drei Diagrammen
ist das ohne Diskretisierung skalierte Signal jeweils in grüner Farbe
eingezeichnet.
Im ersten Beispiel wird dazu die gewöhnliche Integer-Division genommen.
An den Nulldurchgängen entstehen leichte Unregelmäßigkeiten ähnlich den
Übernahmeverzerrungen eines schlechten Gegentaktendstufe. Außerdem ist
die Amplitude um 0,5 LSB zu klein.
Im zweiten Beispiel wird die Division durch eine Shift-Operation
realisiert. Die Nulldurchgangsverzerrungen sind verschwunden und auch
die Amplitude stimmt. Allerdings hat das Signal jetzt einen Offset von
-0,5 LSB, der bei Filteranwendungen aber über einen Koppelkondensator am
Ausgang eliminiert wird und deswegen meist akzeptabel ist.
Man kann diesen Offset aber auch auf digitaler Seite korrigieren, wie
das dritte Beispiel zeigt. Dazu wird vor dem Shift einfach der halbe
Skalierungfaktor zum Signal addiert.