Hallo,
welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,
die auch mit wenig ram&rom (4kB/32kB) auskommt?
Die allgegenwärtigen libs (in C geschrieben!) sollte man aber noch
weiter verwenden können.
(Ich habe über die Jahre eine leichte C-Allergie entwickelt, die auch
bei C++ und ähnlichen auftritt)
Arduino F. schrieb:> Ich würde dir eine Desensibilisierung empfehlen...
Entweder das oder gleich Assembler schreiben. Bei nur 4kB RAM kennt man
noch jedes Byte mit Namen.
ARM Cortex-M an sich ist aber für C-Compiler optimiert.
Es ist auch in Assembler nicht übermäßig schwierig C-Libraries zu
benutzen, aber die müssten erstmal in das enge RAM und Flash Korsett
passen...
Selbst wenn es eine andere Programmiersprache gäbe, dann fehlen meist
noch die Registerbeschreibungen, Bitkonstanten u.ä. wie man sie
üblicherweise in den C-Include-Dateien der Hersteller findet.
Aber vielleicht ist das ja ganz interessant:
http://blog.japaric.io/quickstart/
Oliver
Programierer schrieb:> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Free Pascal, weil C-Allergiker oftmals Pascal mögen.
Programierer schrieb:> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Das hängt nur sehr wenig von der Programmiersprache ab, sondern im
wesentlichen von der Qualität des Compilers. 32K Flash und 2K RAM
reichen auch in C für sehr viele Dinge aus.
> Die allgegenwärtigen libs (in C geschrieben!) sollte man aber noch> weiter verwenden können.
Dann wäre ein C-Compiler die kanonische Wahl. Obwohl natürlich auch
viele andere Sprachen mit C-Linkage umgehen können. Notfalls sogar
Assembler, obwohl das eher Masochismus ist als alles andere.
Aber deiner Intention, Speicher zu sparen, entspricht das nicht. Denn
das, was ein C-Programm typischerweise fett macht, sind eben die
verwendeten Libraries.
> (Ich habe über die Jahre eine leichte C-Allergie entwickelt, die auch> bei C++ und ähnlichen auftritt)
Dann wünsche ich baldige Genesung. Gesund ist das nämlich nicht.
Programierer schrieb:> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Hier würde ich die GCC einsetzen mit wahrscheinlich stark
eingeschränktem C++.
... manchmal im Leben gibt es einfach keine sinnvollen Alternativen ;)
Grüße Oliver
Rainer S. schrieb:> https://www.mikroe.com/mikropascal/#arm
Finger weg...
Das Drumherum von Mikroelektronika (Boards, Bibliotheken, IDE usw.) ist
wirklich hübsch eingerichtet und es macht echt Spaß, damit zu basteln.
Die Compiler würde ich mir aber genau angucken, bevor ich damit
professionell loslege. Zumindest die AVR-Compiler sind/waren unter aller
Sau(*), inklusive lächerlichem Optimierer und extrem subtilen Bugs(**).
In die mitgelieferten Bibliotheken kann man halt größtenteils nicht
reingucken.
(*) Der optimiert meistens garnix, aber wenn, dann auch mal
versehentlich großzügig Teile des Programms weg...
(**) Konkret hat der C-Compiler an verschiedenen Stellen ein
char-Argument nicht zu int promoted, wie es im Standard gefordert ist.
Markus F. schrieb:> wie wär's mit Ada?>> https://www.adacore.com/download
Interessant.
Ich hab hier viele libXYZ.a und dazu passende XYZ.h
Wie kann ich die weiterhin verwenden?
Ein "use XYZ.h;" (oder so ähnlich) geht wohl nicht..
Die *.h Dateien, wirst du wohl in ADA Packages umschreiben dürfen.
Dann sollte es auch mit deinen *.a klappen.
-- Ungetestet (bin nicht so der ADA Spezi)
Jedes gute ADA Buch sollte einen Abschitt "Interfacing to Other
Languages", o.ä. beinhalten.
Arduino F. schrieb:> Die *.h Dateien, wirst du wohl in ADA Packages umschreiben dürfen.
Das ist nur die halbe Miete.
> Dann sollte es auch mit deinen *.a klappen.
Das ist nicht gesagt. Dazu muß der ADA-Compiler entweder das gleiche ABI
(Aufrufkonvention, Typcodierung) benutzen wie der C-Compiler oder es
zumindest als Variante unterstützen.
u8g2 schrieb:> Selbst wenn es eine andere Programmiersprache gäbe, dann fehlen meist> noch die Registerbeschreibungen, Bitkonstanten u.ä. wie man sie> üblicherweise in den C-Include-Dateien der Hersteller findet.
Ja. Jemand der nicht zur Fraktion "Dumm, faul und gefräßig" zählt würde
womöglich auch über den Einsatz von Nim nachdenken. Einige Leute hatten
damit im Embeded-Bereich ja schon experimentiert. Aber
>wenig ram&rom (4kB/32kB)
ist schon extrem wenig.
Ich hatte damals als Schüler das Programmieren in Pascal gelernt.
Die Windows API war in C geschrieben, jedoch hatte Borland sie
weitgehend in Pascal Libraries gekapselt.
Der Haken war, dass die Dokumentation dieser Kapselungen stets veraltet
und oft unvollständig war. Dazu kam, dass ich gelegentlich Windows
Features nutzen wollte, die Pascal nicht gekapselt hatte.
Zum Beispiel wollte ich damals den Status eines Fensterlosen Programmes
(IR Empfänger) mit einem Taskleisten-Icon in der rechten unteren Ecke
anzeigen.
So wurde ich gezwungen, ziemlich oft in die API Dokumentation von
Microsoft zu schauen. Dort fand ich oft auch oft hilfreiche
Programmbeispiele, aber eben immer nur in C (manhcmal auch C++).
So musste ich gezwungenermaßen auch wenigstens ein bisschen C und C++
lernen. Und als ich so weit war, fragte ich mich "Warum programmiere ich
eigentlich in Pascal"?
Mir fielen nur wenige starke Argumente für Pascal ein. Deswegen
wechselte ich nach C/C++ obowhl das technisch gesehen ein Rückschritt
war und die Sprache definitiv hässlicher ist. Trotzdem bin ich bis heute
dabei geblieben und hatte nie das Gefühl, dabei auf dem Holzweg zu sein.
Nun programmiere ich nur noch selten Windows/Linux Programme, dafür mehr
Mikrocontroller. Dass man die auch in C/C++ programmieren kann, erwies
sich für mich als äußerst praktisch. Nach wie vor sind diese Sprachen
mit hässlichen Details durchsetzt, aber das ist für mich noch lange kein
Grund, sie nicht zu benutzen.
Egal welche andere Sprache zu benutzt, du wirst dich trotzdem auch mit C
auseinander setzen müssen. Alleine schon wegen der Libraries.
Stefan U. schrieb:> Egal welche andere Sprache zu benutzt, du wirst dich trotzdem auch mit C> auseinander setzen müssen. Alleine schon wegen der Libraries.
Genauso ist das. Man muss C nicht lieben, aber man muss es trotzdem
beherrschen, wenn man in dieser Welt programmiermässig mit dem Arsch an
die Wand kommen will.
Und natürlich: Es läßt sich auch viel besser über Sachen lästern, die
man kennt und gerade deswegen hasst, weil man sie kennt. ;o)
c-hater schrieb:> Man muss C nicht lieben, aber man muss es trotzdem> beherrschen, wenn man in dieser Welt programmiermässig mit dem Arsch an> die Wand kommen will.
In der Systemprogrammierung vielleicht. Bei normaler
PC/Server-Anwendungs- oder Web-Entwicklung kann man gut ohne auskommen.
Stefan U. schrieb:> Deswegen> wechselte ich nach C/C++ obowhl das technisch gesehen ein Rückschritt> war und die Sprache definitiv hässlicher ist.
C und C++ so über einen Kamm zu scheren ist etwas gemein, schließlich
ist C++ vielfach mächtiger. C++ hat einen Gutteil seiner Hässlichkeit
aus C geerbt und der bezieht sich hauptsächlich auf die Syntax, und die
ist weiter hinten auf der Lernkurve eh nicht mehr so wichtig. Dafür kann
C++ auch mehr als Pascal...
Ich habe früher in PL/M programmiert, das ist irgendwo zwischen C und
Assembler. Bin aber froh das ich das nicht mehr brauche, ein bisschen
Luxus möchte man beim Programmieren ja schon haben.
Und das ist doch eher der Punkt, man benutzt C oder C++ um einen höheren
Abstraktionslebel zu haben und besser lesbare, wartbare und erweiterbare
Software zu bekommen. C/C++ sind schon sehr effizient mit den modernen
Compilern, ein Register = 0x1234 wird auch zu wenigen Bytes
Maschinencode.
Dann hängt die Programmgrösse weniger von der Sprache ab als vielmehr
von den
Bibliotheken die ich dazupacke. Wenn ich den Komfort eines printf(),
vielleicht sogar noch mit float Unterstüzung haben möchte, dann kostet
das halt ein paar kB mehr. Das Schöne bei den Cortex-M ist doch gerade
das die in ihren Familien viele Geschwister haben und man mit wenig
Aufwand einen Controller mit mehr Dampf auswählen kann. 256 kB Flash
bekommt man auch für 2€, warum da alles abspecken und dem
Performancegott opfern?
Dr. Sommer schrieb:> [...] schließlich ist C++ vielfach mächtiger [als C].
Papperlapapp, C++ ist nicht mächtiger als C oder Assembler: sind alle
"nur" Turing-vollständig. *wegduck*
Johann L. schrieb:> Papperlapapp, C++ ist nicht mächtiger als C oder Assembler: sind alle> "nur" Turing-vollständig. *wegduck*
Mit dem Argument kannst du auch gleich in Brainfuck programmieren...
Programierer schrieb:> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Leider gar keine.
Es hat sich C mittlerweile zu einer Monokultur entwickelt und
Alternativen sind nicht in Sicht.
Es haben die Leute von Mikroe mal versucht, mit Basic und Pascal zu
landen, aber sie haben es falsch angestellt, nämlich so, daß ihr Produkt
eben nicht vom Anwender auf einen µC eingerichtet werden kann, der nicht
bereits in der Liste der unterstützten Chips steht.
Hätten sie lediglich zwischen den Architekturen (M0...M4F..M7)
unterschieden und all die Registeranpassungen einfach in einen
Hardwareunit (für C-Leute: sowas wie "LPC408x.h") gepackt, dann hätten
diese Compiler eine Anwender-Basis bekommen können. Die Sprache gibt's
ja her:
1
wasinCsolautet:
2
#define NVIC_ISPR (*((volatile unsigned long *) (0xE000E200)))
3
4
wäreinPascaletwaso:
5
NVIC_ISPR:dwordabsolute$E000E200;
easy, gelle? aber leider eben nicht zu kriegen.
W.S.
Axel S. schrieb:> Arduino F. schrieb:>> Die *.h Dateien, wirst du wohl in ADA Packages umschreiben dürfen.>> Das ist nur die halbe Miete.>>> Dann sollte es auch mit deinen *.a klappen.>> Das ist nicht gesagt. Dazu muß der ADA-Compiler entweder das gleiche ABI> (Aufrufkonvention, Typcodierung) benutzen wie der C-Compiler oder es> zumindest als Variante unterstützen.
Der Ada gnat-Compiler ist Teil der GCC. gcc und gnat stammen also aus
demselben Stall und kennen sich. Wie man C-Funktionen von Ada aus
aufruft (und umgekehrt) steht hier:
https://gcc.gnu.org/onlinedocs/gcc-5.4.0/gnat_ugn/Interfacing-to-C.html
Fertig ist man damit allerdings längst nicht. Die gnat runtime gibt es
fertig nur für bestimmte ausgesuchte Boards. Andere benötigen wenigstens
eine rudimentäre Portierung ->
http://blog.adacore.com/porting-the-ada-runtime-to-a-new-arm-board. Das
dürfte für so ein "kleines" Board relativ simpel sein - viel Runtime
passt da ja gar nicht drauf.
Programierer schrieb:> (Ich habe über die Jahre eine leichte C-Allergie entwickelt, die auch> bei C++ und ähnlichen auftritt)
Ich würde Dir empfehlen, alles was Du bisher über C++ weißt, weg zu
werfen und statt dessen modernes C++ mit viel moderner TMP neu(!) zu
erlernen. Um C als common-ground kommst Du leider nicht herum ...
Programierer schrieb:> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Wenn Dein Programm zu groß wird, dann nimm doch einfach einen größeren
Cortex-M. Da gibt es nun wirklich genug Auswahl für jeden Geschmack.
Deine Anfrage ist sehr unspezifisch. Ein "Blinky" Programm passt immer
in 4kB/32kB, oder meinst Du, dass der Compiler/Linker mit 4kB/32kB
auskommen muss?
Die gcc-Monokultur hat auch Vorteile:
Ein '-fdump-ada-spec' macht aus .h .ads
Ein schwer lesbares .h wird dardurch nicht lesbarer - aber ich
'with/use' es ja nur?
Oliver schrieb:
>http://blog.japaric.io/quickstart/
Danke! Die Rust Leute haben das gleiche Problem:
keine Registerbeschreibungen, keine Bitkonstanten..
Programierer schrieb:> keine Registerbeschreibungen, keine Bitkonstanten..
..und wenn man die Seite nicht nur überfliegt, kann man lernen dass es
für sehr viele MCUs *.svd files gibt und mit "svd2$SPRACHE" diese
übersetzen kann:)
Programierer schrieb:> (Ich habe über die Jahre eine leichte C-Allergie entwickelt, die auch> bei C++ und ähnlichen auftritt)
was stört Dich den an C, was Du hoffst, in anderen Sprachen zu finden?
Wie sieht es mit Ada und Rust aus?
es gäbe auch noch forth, das kommt wirklich mit wenig RAM/ROM aus.
https://github.com/jeelabs/mecrisp-stellaris läuft anscheinend schon mit
16kb flash und 1kb ram.
Terminalprogramm für eine serielle Schnittstelle ist üblicherweise alles
was man braucht, compiler und entwicklungsumgebung ist in den 16k
inkludiert.
Torsten R. schrieb:> was stört Dich den an C, was Du hoffst, in anderen Sprachen zu finden?
Unschön ist die Unmenge an undefined behaviour, besonders weil der
Compiler dann halt "irgendwas" macht, aber garantiert nichts Nützliches.
Das wird obendrein schlimmer, weil wegen angeblicher Performancegewinne
solche UBs auf einmal beim Optimieren genutzt werden, was früher nicht
der Fall war. Nicht, daß man dadurch wirklich schnelleren Code hätte,
aber haufenweise reifgetestete Codebasen zeigen sich auf einmal doch
buggy.
Klar kann man sagen, der Programmierer muß wissen, was er macht, aber
"design for safety" ist ein grundlegendes Engineering-Prinzip, das
zumindest für Debug-Builds automatisch möglich sein sollte.
Dann die z.T. unsinnige Operatoren-Rangfolge (z.B. ist & niedriger als
==), die Integer-Promotion ist auch immer wieder ein Quell der Freude,
und Arrays zerfallen bei Aufruf an Funktionen zu Pointern, so daß
automatische Längenchecks nicht optional eincompilierbar sein können.
Dann sind da noch die haarsträubenden Library-Funktionen besonders rund
ums Stringhandling, die auch mit den n-Versionen (strncpy) immer noch
Händchenhalten brauchen, weil der resultierende String u.U. nicht
nullterminiert ist.
Bis hin zu völlig überflüssigen Späßen wie daß das Ergebnis von
malloc(0) implementationsabhängig ist, was zur Fehlerbehandlung blöd
werden kann. Überhaupt, wieso kriegt free() nicht einen Pointer auf
einen Pointer, um den automatisch zu nullen? Dann hätte man bei "use
after free" automatisch zu einem Crash, was leicht zu entdecken wäre.
Also ich mag C, mehr als Pascal jedenfalls, aber C hat schon seine
unschönen Seiten.
Lothar schrieb:> BASIC
Hm .. die IDE wirkt wie ein mal schnell so zur Übung zusammengeklickter
Dialog aus VC. Wenig vertrauenserweckend.
Die Mathe-Funktionen der Runtime Library sind wohl ebenfalls
"überschaubar".
Kann es sein, dass das Produkt noch nicht ganz ausgereift ist?
;-)
W.S. schrieb:> was in C so lautet:> #define NVIC_ISPR (*((volatile unsigned long *) (0xE000E200)))>> wäre in Pascal etwa so:> NVIC_ISPR : dword absolute $E000E200;
Und wo ist da das Pascal-Pendant zu "volatile"?
Nase schrieb:> Rainer S. schrieb:>> https://www.mikroe.com/mikropascal/#arm> Das Drumherum von Mikroelektronika (Boards, Bibliotheken, IDE usw.) ist> wirklich hübsch eingerichtet und es macht echt Spaß, damit zu basteln.
Na, das ist doch schon mal was. Wenn man die IDE mit der von der oben
erwähnten BASIC Variante vergleicht, tun sich da doch Welten auf.
> Die Compiler würde ich mir aber genau angucken, bevor ich damit> professionell loslege. Zumindest die AVR-Compiler sind/waren unter aller> Sau(*), inklusive lächerlichem Optimierer und extrem subtilen Bugs(**).
Ist dein Wissen dazu überhaupt noch aktuell? Oder sind die Bugs
vielleicht schon längst fehlerbereinigt ..
> In die mitgelieferten Bibliotheken kann man halt größtenteils nicht> reingucken.
Wollen doch viele Anwender vielleicht auch gar nicht. Sie wollen die
Libs einfach nur benutzen und damit schnell Ergebnisse erzielen.
> (*) Der optimiert meistens garnix,
Muss wirklich JEDES Codeschnipsel immer "hoch optimiert" sein? Sind wir
nicht längst aus dem Zeitalter der "ich muss noch ein paar Bytes mehr
rausquetschen" Analogie herausgewachsen?
> aber wenn, dann auch mal> versehentlich großzügig Teile des Programms weg...
Wäre nicht schön. Aber ist das wirklich noch so? Die verkaufen doch ihre
Lizenzen nicht erst seit gestern.
> (**) Konkret hat der C-Compiler an verschiedenen Stellen ein> char-Argument nicht zu int promoted, wie es im Standard gefordert ist.
Bugs eben. Wie viele Bugs haben Compiler noch mal (generell und quasi
immer)? Ein paar Dutzend, ein paar hundert, ein paar Tausend?
Thomas E. schrieb:> Und wo ist da das Pascal-Pendant zu "volatile"?
Pascal hat kein volatile.
> In FPC, every statement is basically considered to be a compiler-level> memory barrier for accesses to global variables. So within a single> statement multiple accesses can be optimised, but that cannot happen not> across statements. It's not perfect since it inhibits some optimisation,> but on the flip side it's very simple and easy to reason about.
Quelle:
http://lists.freepascal.org/pipermail/fpc-pascal/2015-December/046057.html
> Unschön ist die Unmenge an undefined behaviour
In C ist alles nötige sehr genau definiert. "undefined behaviour"
provoziert man nur, indem man etwas macht, was nicht vorgesehen ist. Und
dann bekommt man vom Compiler eine deutliche Warnung.
> auf einmal beim Optimieren genutzt werden
Es steht Dir frei, den Optimierungs-Grad selbst einzustellen. Neue
Optimierungen kommen immer nur in die höchste Stufe oder in eine neue
Stufe. Du kannst die Optimierung auch ganz deaktivieren und ggf. manuell
optimieren, wenn Dir das eher zusagt.
Das alles sind aber nicht C spezifische Probleme. Das kann Dir in jeder
beliebigen Programmiersprache ebenso passieren. Ich meine z.B. Java, da
hast du obendrein noch viel weniger Einflussmöglichkeiten.
> "design for safety"
Das ist nicht das primäre Ziel der Sprache C. Allerdings kannst du den
Optimizer deaktivieren und alle Warnungen aktivieren, dann bist du ganz
nahe an der Anforderung dran.
> die z.T. unsinnige Operatoren-Rangfolge
Hm die ist bei fast allen Programmiersprachen ebenso. Und ich finde sie
durchaus sinnvoll.
Deine weiteren Kritikpunkte wurden längst durch C++ und zahlreiche
andere Programmiersprachen ausgemerzt. Aber diesen Luxus bezahlt man mit
geringerer Performance und mehr Speicherbedarf.
Offensichtlich gibt es aber noch genug Fälle, wo man eben diese "Kosten"
nicht toleriert, sonst wäre C schon lange tot.
Was die Library angeht: Du musst sie nicht benutzen. Schreibe Dir eine
eigene!
> die ... immer noch Händchenhalten brauchen
Du musst die alten Funktionen/Libraries ja nicht benutzen.
Wenn ich heute mit einem Trabbi über die Autobahn knattere, kann ich
mich auch nicht darüber beklagen, dass manche Auto immer noch so lahm
und laut sind.
> Bis hin zu völlig überflüssigen Späßen wie daß das Ergebnis> von malloc(0) implementationsabhängig ist
Du wirfst da zu viel ein eine Topf. Malloc holt sich Speicher vom OS.
Also hängt das Verhalten von Malloc direkt von OS ab. Wenn du das nicht
willst, musst du eine eigene Speicherverwaltung nehmen, so wie Java es
tut. Gibt es übrigens auch für C.
Nur wundere Dich dann nicht, dass jedes kleine Popel-Programm per
default erstmal etwa die Hälfte des RAM zu belegen versucht.
Glücklicherweise vergibt Windows inzwischen nur noch virtuellen
Speicher, so dass das kaum noch auffällt. Aber ich weiß noch, wie das
unter Windows 3.11 und 95 lief.
> Also ich mag C ... aber C hat schon seine unschönen Seiten.
Da stimme ich Dir allerdings zu. Das trifft sicher auf jede Sprache zu.
Ich arbeite beruflich viel mit Java, der Sprache, die angeblich alles
besser machen sollte. Pustekuchen! Java hat genau so viele Fallstricke.
> Beim GCC sind derzeit mehr als 10000 bekannt
Wobei das vermutlich größtenteils nur mutmaßliche Bugs sind, die noch
untersucht und bestätigt oder abgewiesen werden müssen.
Stefan U. schrieb:> In C ist alles nötige sehr genau definiert. "undefined behaviour"> provoziert man nur, indem man etwas macht, was nicht vorgesehen ist. Und> dann bekommt man vom Compiler eine deutliche Warnung.
Nein, die bekommt man nicht. Oder nur manchmal. Wie beispielsweise
möchtest Du bei undefiniertem Verhalten den Compiler warnen lassen, wenn
man eine Variable um eine andere Variable shiftet, deren Wert aber erst
zur Laufzeit bekannt wird?
Um DAS rauszufinden, brauchst Du sehr, sehr aufwendige und damit auch
teure Tools.
> Es steht Dir frei, den Optimierungs-Grad selbst einzustellen.
C ohne Optimierungen ist ja ziemlich witzlos, weil dann das zentrale
C-Argument mit der Geschwindigkeit nicht mehr vorhanden ist.
> Das alles sind aber nicht C spezifische Probleme.
Doch, das ist es, weil der Compiler sich beim Optimieren zwar darauf
verläßt, daß kein undefiniertes Verhalten da ist, aber meistens nicht
warnt. C enthält schlichtweg zuviel undefiniertes Verhalten, darunter
auch solches, was man genausogut implementationsabhängig hätte machen
können.
> Das ist nicht das primäre Ziel der Sprache C.
Genau das ist ja einer der unschönen Punkte an C. Besonders, weil man
das nichtmal per Debugbuild optional haben kann.
> Hm die ist bei fast allen Programmiersprachen ebenso. Und ich finde sie> durchaus sinnvoll.
Ich finde sie unsinnig. if (x & MASK == MASK) geht nicht, sondern es muß
wegen der unsinnigen Priorität if ((x & MASK) == MASK) heißen. Unsinnig
ist das, weil es so gut wie keinen Fall gibt, in dem man wirklich die
erstere Variante würde haben wollen.
Daß man beim switch ein break setzen muß, wenn man enden will, anstatt
ein continue, wenn man in den nächsten case reinlaufen will, ist auch so
ein Mangel.
> Du musst die alten Funktionen/Libraries ja nicht benutzen.
Das ist keine Widerlegung meines Argumentes, sondern eine Bestätigung.
> Du wirfst da zu viel ein eine Topf. Malloc holt sich Speicher vom OS.> Also hängt das Verhalten von Malloc direkt von OS ab.
Das ist eben der Kritikpunkt.
Stefan U. schrieb:> Was die Library angeht: Du musst sie nicht benutzen. Schreibe Dir eine> eigene!
Achja, übrigens ist schon die dahinterliegende implizite Grundannahme
vollkommen verkehrt. Man schreibt sich in aller Regel nämlich die
Codebasis, an der man arbeitet, nicht als Einzelner im stillen
Kämmerlein from scratch selber.
> C ohne Optimierungen ist ja ziemlich witzlos, weil dann das zentrale> C-Argument mit der Geschwindigkeit nicht mehr vorhanden ist.
Sage das nicht. Ich habe das mal bei meinen eigenen Programmen
ausprobiert und war erstaunt, dass der Code nur wenig größer und
langsamer wurde, als mit Optimierung.
Ich hatte da ein Verhältnis von 1:5 erwartet, aber es war am Ende
weniger als 1:2.
> if (x & MASK == MASK) geht nicht
Das ist ein schönes Beispiel, um zu erklären, warum du die Rangfolge
nicht magst. Jetzt verstehe ich dich besser.
>> Du musst die alten Funktionen/Libraries ja nicht benutzen.> Das ist keine Widerlegung meines Argumentes, sondern eine Bestätigung.
Ok
Stefan U. schrieb:> Was die Library angeht: Du musst sie nicht benutzen.> Schreibe Dir eine eigene!
Den Mangel, dass Arrays bei Übergabe zu Pointern ohne Längeninformation
zerfallen, kann man damit aber auch nicht lösen. Oder ein paar andere
Dinge, die im Kern der Sprache verankert sind.
Nop schrieb:> Torsten R. schrieb:>>> was stört Dich den an C, was Du hoffst, in anderen Sprachen zu finden?>> Unschön ist die Unmenge an undefined behaviour, besonders weil der> Compiler dann halt "irgendwas" macht, aber garantiert nichts Nützliches.
Ja, wenn das Dein Hauptkriterium an einer Sprache ist, hast Du
eingentlich nur 2 Möglichkeiten:
1) (fast) keine Abstraktionen: das wäre dann z.B. Assembler
2) In allen Abstraktionen, definiertes Verhalten:
Du must Dich ja nicht alleine auf die Garantien stützen, die Dir die
Sprache gibt. Wenn Du andere Garantien haben möchtest oder brauchst,
dann gibt evtl. einen C-Compiler / Plattform, die das bieten. Undefined
behaviour verbietet ja nicht, dass es Tools gibt, die Verhalten an der
Stelle definieren. Der Code wäre dann halt nicht mehr protabel. Unter
Umständen ist das dann aber das kleinere Übel.
C ist aber halt eine multi-purpose language. Und genau zu definieren,
wie sich strcpy( 0, 0 ) verhält bedingt halt z.T. teure Prüfungen, der
derjenige, der das nicht braucht, nicht haben möchte.
Man kann aber Arrays und String durch Objekte ersetzen. Dann sind wir
allerdings schon bei C++.
Obwohl: Objekt-Orientiert kann man auch in C programmieren. Nur gewinnt
man damit ebenfalls keinen Schönheitswettbewerb.
Nop schrieb:> Wie beispielsweise möchtest Du bei undefiniertem Verhalten den> Compiler warnen lassen, wenn man eine Variable um eine andere> Variable shiftet, deren Wert aber erst zur Laufzeit bekannt wird?>> Um DAS rauszufinden, brauchst Du sehr, sehr aufwendige und damit auch> teure Tools.
3.11 Program Instrumentation Options
GCC supports a number of command-line options that control adding
run-time instrumentation to the code it normally generates. [...]
Another class of program instrumentation is adding run-time checking to
detect programming errors like invalid pointer dereferences or
out-of-bounds array accesses, as well as deliberately hostile attacks
such as stack smashing or C++ vtable hijacking. There is also a general
hook which can be used to implement other forms of tracing or
function-level instrumentation for debug or program analysis purposes.
1
-fsanitize=address
2
-fsanitize=kernel-address
3
-fsanitize=thread
4
-fsanitize=leak
5
-fsanitize=undefined
6
-fsanitize=shift
7
-fsanitize=shift-exponent
8
-fsanitize=shift-base
9
-fsanitize=integer-divide-by-zero
10
-fsanitize=unreachable
11
-fsanitize=vla-bound
12
-fsanitize=null
13
-fsanitize=return
14
-fsanitize=signed-integer-overflow
15
-fsanitize=bounds
16
-fsanitize=bounds-strict
17
-fsanitize=alignment
18
-fsanitize=object-size
19
-fsanitize=float-divide-by-zero
20
-fsanitize=float-cast-overflow
21
-fsanitize=nonnull-attribute
22
-fsanitize=returns-nonnull-attribute
23
-fsanitize=bool
24
-fsanitize=enum
25
-fsanitize=vptr
26
-fsanitize=pointer-overflow
27
-fsanitize=builtin
28
-fasan-shadow-offset=number
29
-fsanitize-sections=...
30
-fsanitize-recover=
31
-fsanitize-address-use-after-scope
32
-fsanitize-undefined-trap-on-error
33
-fsanitize-coverage=trace-pc
34
-fsanitize-coverage=trace-cmp
35
-fbounds-check
36
-fcheck-pointer-bounds
37
-fchkp-check-incomplete-type
38
-fchkp-narrow-bounds
39
-fchkp-first-field-has-own-bounds
40
-fchkp-flexible-struct-trailing-arrays
41
-fchkp-narrow-to-innermost-array
42
-fchkp-optimize
43
-fchkp-use-fast-string-functions
44
-fchkp-use-nochk-string-functions
45
-fchkp-use-static-bounds
46
-fchkp-use-static-const-bounds
47
-fchkp-treat-zero-dynamic-size-as-infinite
48
-fchkp-check-read
49
-fchkp-check-write
50
-fchkp-store-bounds
51
-fchkp-instrument-calls
52
-fchkp-instrument-marked-only
53
-fchkp-use-wrappers
54
-fcf-protection=
55
-fstack-protector
56
-fstack-protector-all
57
-fstack-protector-strong
58
-fstack-protector-explicit
59
-fstack-check
60
-fstack-clash-protection
61
-fstack-limit-register=reg
62
-fstack-limit-symbol=sym
63
-fstack-limit
64
-fsplit-stack
65
-fvtable-verify=
Immerhin ein Anfang, auch wenn die Warning / Analyse nicht vom Compiler
kommt sondern qua Instrumentierung zur Laufzeit.
Naturgemäß ist sowas für Cross-Entwicklung schlechter zu nutzen und auch
schlechter unterstützt als für Host-Entwicklung, aber die Behauptung,
dass ohne teure [tm] Tools nix ginge, ist wohl etwas grobschlächtig.
Dann sind da noch Tools wie Valgrind oder Mudflap, oder Tools zur
statischen Analyse.
Gegeben den Fall, dass man Embedded-Entwicklung ernsthaft betreibt, wird
man den Code sauber in Hardware-Abhängiges und in Hardware-Unabhängiges
wie Algorithmen und Verwaltungskrempel etc. aufgeteilt haben und
entsprechend betesten. Der HW-unabhängige Teil läuft also auch auf
einem Host mit voller Verfügbarkeit o.g. Instrumenter — wobei die
Übertragbarkeit der Ergebnisse umso mehr eingeschränkt ist, je weiter
die Plattformen voneinander abweichen (z.B. sind Ergebnisse für int=32
gröber als für int=16, und weil int-Promotion nicht portiert werden
kann).
Torsten R. schrieb:> 2) In allen Abstraktionen, definiertes Verhalten:
Daß das Performance kostet, ist schon klar. Deswegen würde ich das ja
auch nur für Debug-Builds haben wollen. Quasi eine Art Pascal-Modus für
den C-Compiler.
Stefan U. schrieb:> Obwohl: Objekt-Orientiert kann man auch in C programmieren. Nur gewinnt> man damit ebenfalls keinen Schönheitswettbewerb.
Zumal die grundlegenden Probleme sich damit auch nicht erledigen.
Deswegen verwendet man in C++ ja tunlichst keine rohen C-Pointer.
Johann L. schrieb:> Immerhin ein Anfang, auch wenn die Warning / Analyse nicht vom Compiler> kommt sondern qua Instrumentierung zur Laufzeit.
Geht aber auch nur unter Linux und hilft nicht besonders weiter, wenn
man damit Mikrocontroller programmieren will.
Nop schrieb:> Torsten R. schrieb:>> Daß das Performance kostet, ist schon klar. Deswegen würde ich das ja> auch nur für Debug-Builds haben wollen. Quasi eine Art Pascal-Modus für> den C-Compiler.
Wie wäre es mit --just-like-java ? ;-)
Nop schrieb:> Johann L. schrieb:>>> Immerhin ein Anfang, auch wenn die Warning / Analyse nicht vom Compiler>> kommt sondern qua Instrumentierung zur Laufzeit.>> Geht aber auch nur unter Linux und hilft nicht besonders weiter, wenn> man damit Mikrocontroller programmieren will.
Lies meinen Post einfach zu Ende :-/
Programierer schrieb:> Hallo,>> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?>> Die allgegenwärtigen libs (in C geschrieben!) sollte man aber noch> weiter verwenden können.>> (Ich habe über die Jahre eine leichte C-Allergie entwickelt, die auch> bei C++ und ähnlichen auftritt)
Konfuzius sagt: Wenn Du Dich einer Vergewaltigung nicht entziehen kannst
dann lehne Dich zurück und genieße sie.
Du wirst nicht um C herumkommen. Also mach das beste draus.
Stefan U. schrieb:>> Deswegen würde ich das ja auch nur für Debug-Builds haben> wollen.>> Kannst du doch: Die Option dazu heisst -O0
Und damit zerfallen dann z.B. Arrays nicht mehr zu Pointern unter
Verlust der Längeninformation?
Johann L. schrieb:> Lies meinen Post einfach zu Ende :-/
Habe ich. Ist in der Praxis aber nur begrenzt nützlich. Wenn auch noch
ein µC-spezifisches OS zum Einsatz kommt, wird der Aufbau eines Mockups
so richtig spaßig. Die dafür nötige zusätzliche Entwicklungszeit fällt
übrigens auch nicht kostenlos vom Himmel.
Es bleibt dabei, daß es diese Möglichkeit "gratis" nur dann gibt, wenn
man sowieso Applikationen für Linux erstellt, was die Sache relativ
nutzlos macht.
Brille schrieb:> Ist dein Wissen dazu überhaupt noch aktuell? Oder sind die Bugs> vielleicht schon längst fehlerbereinigt ..
Ebendas gab ich zu bedenken. Mein Wissen datiert etwa auf Anfang 2017.
Brille schrieb:> Muss wirklich JEDES Codeschnipsel immer "hoch optimiert" sein? Sind wir> nicht längst aus dem Zeitalter der "ich muss noch ein paar Bytes mehr> rausquetschen" Analogie herausgewachsen?
Natürlich.
Nur erzeugt z.B. der GCC selbst auf langweiligster Optimierungsstufe
etwa um Faktor 5 weniger Code. Bei Mikroe fehl(ten damals) ja selbst
simpelste Sachen wie Speicherzugriffe zusammenzuziehen.
Ich erinnere mich düster an elendige Wüsten im Assembly aus "lds lds ..
sts sts" (AVR), nur um ein paar Bits in einer lokalen Variable zu setzen
(nee...ohne volatile natürlich).
Joachim D. schrieb:> Noch einer: 1 Seite Pascal ~ 1 Zeile C.> Pascal ist so elend viel Tipparbeit ;)
So extrem ist das nicht. Das meiste macht doch die IDE automatisch auf
Knopfdruck (Methoden und Interfaces implementieren, etc.) und begin geht
mir auf ner deutschen Tastatur schneller von der Hand als die unsägliche
geschweifte Klammer. Unterm Strich beibt da auch nicht viel mehr zu
schreiben als bei den meisten anderen statisch getypten Syntaxen aus
dieser Familie auch (C++, Java, C#, etc.).
Und wenn man (wie ich) auch unter Pascal den 1TBS/Kernel-"Klammer"-stil
pflegt (begin ans Ende der Zeile) kommt auch verkleichbar kompakter Code
raus.
#define NVIC_ISPR (*((volatile unsigned long *) (0xE000E200)))
>>wäre in Pascal etwa so:>NVIC_ISPR : dword absolute $E000E200;
naja... ist auch ein bisschen vom C Compiler abhängig.
Bei IAR dürfte das gehen - und dann sind wir sogar noch etwas
übersichtlicher als Pascal.
>> if (x & MASK == MASK) geht nicht> ist doch if(x & MASK), da interessiert doch die> Rangfolge zu == überhaupt nicht.
Doch, denn beabsichtigt war ja das Verhalten von
if ((x & MASK) == MASK)
dummschwaetzer schrieb:> Stefan U. schrieb:>>> if (x & MASK == MASK) geht nicht>> ist doch if(x & MASK), da interessiert doch die Rangfolge zu ==> überhaupt nicht.
Nein, das ist nicht das selbe.
dummschwaetzer schrieb:> if ((x & MASK) == MASK)> ist für mich gleich> if(x & MASK)> oder wo ist der Unterschied?
Annahme MASK == 0x0F
Oben: Alle Bits müssen gesetzt sein.
Unten: Mindestens ein Bit muss gesetzt sein.
dummschwaetzer schrieb:> if ((x & MASK) == MASK)> ist für mich gleich> if(x & MASK)> oder wo ist der Unterschied?
Laß MASK mal mehr als ein Bit gesetzt haben, dann wäre (x & MASK) gleich
TRUE, auch wenn in x nur ein Tuil der Bits von MASK gesetzt sind.
Außerdem ist (x & MASK == MASK) soviel wie (x & 1), unabhängig vom
Inhalt von MASK.
> if ((x & MASK) == MASK)> ist für mich gleich> if(x & MASK)> oder wo ist der Unterschied?
Setzen wir konkrete Werte ein:
x=17
MASK=16
((17 & 16) == 16) ist wahr
(17 & 16) ist >0 also auch wahr
Setzen wir andere Werte ein:
x=0
MASK=16
((0 & 16) == 0) ist wahr
(0 & 16) ist 0, also falsch
Jetzt verstanden?
Hallo,
((x&MASK)==MASK),
dein Beispiel
(((0 & 16) == 0)
wird also zu
(0 & 16) == 16)
und falsch.klappt alo.
gut, es wahren die mehr als ein Bit, ich verwende dieses Konstrukt nur
zum Testen eines Bits.
Nase schrieb:> Die Compiler würde ich mir aber genau angucken, bevor ich damit> professionell loslege. Zumindest die AVR-Compiler sind/waren unter aller> Sau(*), inklusive lächerlichem Optimierer und extrem subtilen Bugs(**).
Funktioniert hier hervorragend im produktiven Einsatz seit mehreren
Jahren.
In der Tat habe ich einen Bug gefunden, der selten auftritt. Der ist
mittlerweile behoben und ich werde bei den Credits bei der Compilerinfo
genannt.
Ben W. schrieb:> ich schätze mal Rust wurde schon genannt,> dort gibt es mittlerweile alle Register namen dank der svd2rust tools.
Das Tool ist auch super, nur bringts leider nix wenn die SVD schlichtweg
unbrauchbar sind. Und zumindest bei ST sind sie das...
Vincent H. schrieb:> Das Tool ist auch super, nur bringts leider nix wenn die SVD schlichtweg> unbrauchbar sind. Und zumindest bei ST sind sie das...
Was genau ist denn unbrauchbar?
AFAIK, werden die .svd Dateien auch von den Debuggern benutzt.
> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,> die auch mit wenig ram&rom (4kB/32kB) auskommt?
Forth. Damit hast du dann auch ein Alleinstellungmerkmal.
Olaf
>Forth. Damit hast du dann auch ein Alleinstellungmerkmal.
Aber nur wenn Du die mindestens 20 verschiedenen Forthsystem ignorierst,
die es für ARM-Controller gibt ;-)
Ich kann die PAscal wärmstens!! empfehlen.
Von Mikroe.
Wenn man sich dann in Pascal gut zurecht findet, schreibst Du Programme
auf dem PC gleich auch in PAscal.
Mit Lazarus Freepascal hast Du dann was, wo Du in kürzester Zeit super
Sachen machen kannst.
Das einzige was da dran komme wäre Visual C++ von MS nur unendlich
komplexer.
Daher meine dringende Empfehlung Pascal.
Lass Dir keinen Unsinn einreden das PAscal nicht für Bitzugriffe taugt,
Leute die das behaubten, haben nicht verstanden.
Die vergleichen Pascal aus den 7=/80er Jahren mit dem C von
heute..sinnvoller wäre es aber Pascal von heute mit C von heute zu
vergleichen..
Dann würde viele eher Pascal verwenden als in C zu frickeln
dazu muss man sagen, mikroe unterstützt so ziemlich alle gängigen STM32
Chips und noch einige andere.
Auch das Pascal eignet sich mittlerweile für den produktiven Einsatz.
Viel Kritik die ich hier lese, galt noch vor einigen Jahren..aber die
Welt dreht sich weiter
Nop schrieb:> Programierer schrieb:>>> welche andere Programmiersprachen könnt ihr für ARM cortex M empfehlen,>> die auch mit wenig ram&rom (4kB/32kB) auskommt?>> Free Pascal, weil C-Allergiker oftmals Pascal mögen.
Ich mag C
Hat jemand Erfahrung mit micropython?
https://github.com/micropython/micropython
Hab ich jetzt gerade auf der oben verlinkten Wiki Seite entdeckt und
scheint recht aktiv zu sein.
zu Mikroe..weshalb Thread nicht gelesen.
Hatte gesehen das es bereits erwähnt wurde, aber ganz offensichltich
nocha uf ganz frühe Versionen bezogen.
Mittlerweile läuft das ganz brauchbar und wir auch im Kommerziellen
Bereich eingesetzt, wie Lazarus Free Pascal übrigens auch
W.S. schrieb:> was in C so lautet:> #define NVIC_ISPR (*((volatile unsigned long *) (0xE000E200)))>> wäre in Pascal etwa so:> NVIC_ISPR : dword absolute $E000E200;> easy, gelle? aber leider eben nicht zu kriegen.>> W.S.
Du vergleichst Äppel Mit Kohlrouladen.
Gruß,
Holm
Nop schrieb:> Thomas E. schrieb:>>> Und wo ist da das Pascal-Pendant zu "volatile"?>> Pascal hat kein volatile.>>> In FPC, every statement is basically considered to be a compiler-level>> memory barrier for accesses to global variables. So within a single>> statement multiple accesses can be optimised, but that cannot happen not>> across statements. It's not perfect since it inhibits some optimisation,>> but on the flip side it's very simple and easy to reason about.>> Quelle:> http://lists.freepascal.org/pipermail/fpc-pascal/2015-December/046057.html
Ist aber sowieso Wurscht da die obere Zeile nur ein Präprozessor Symbol
definiert, ohne jede Funktionalität dahinter.Das ist nichts weiter als
#define lehmann 5
..jedes Auftreten von lehmann im folgenden Text wird durch 5 ersetzt.
Das vergleicht W.W. mit einer Variablendefinition.
Die ganze Sache wird in Pascal ohne volatile recht lustig wenn die
Variable ohne Wissen des Compilers ihren Wert ändert (memory mapped
register)..
Gruß,
Holm
Tina schrieb:
[..]
> Dann würde viele eher Pascal verwenden als in C zu frickeln
Aha. Pascal verwendet man, in C frickelt man.
Kompetente Auskunft.
Gruß,
Holm
Holm T. schrieb:> Die ganze Sache wird in Pascal ohne volatile recht lustig wenn die> Variable ohne Wissen des Compilers ihren Wert ändert (memory mapped> register)..
Eben nicht, weil zumindest Free Pascal das von sich aus als volatile
handhabt, wenn ich die genannte Quelle richtig verstehe. Dafür geht die
Optimierung bei non-volatile halt nicht.
Andere Pascal-Compiler könnten das natürlich anders machen, weil reales
Pascal mangels brauchbarer Standard-Grundlage schon immer balkanisiert
war.
Tina schrieb:> Ich kann die PAscal wärmstens!! empfehlen.> Von Mikroe.
Der TE hat nach eigener Aussage eine C-Allergie. Da mikroPascal eher ein
mutiertes C als ein echtes Pascal ist (was man durchaus auch positiv
sehen kann), wird er vermutlich auch darauf allergisch reagieren.
Nop schrieb:> Eben nicht, weil zumindest Free Pascal das von sich aus als volatile> handhabt, wenn ich die genannte Quelle richtig verstehe. Dafür geht die> Optimierung bei non-volatile halt nicht.>> Andere Pascal-Compiler könnten das natürlich anders machen, weil reales> Pascal mangels brauchbarer Standard-Grundlage schon immer balkanisiert> war.
Das volatile-Qualifier ist einer der Punkte, wo mikroPascal etwas
Sinnvolles von C geerbt hat.
BCPL schrieb:> Vincent H. schrieb:>>> Das Tool ist auch super, nur bringts leider nix wenn die SVD schlichtweg>> unbrauchbar sind. Und zumindest bei ST sind sie das...>> Was genau ist denn unbrauchbar?>> AFAIK, werden die .svd Dateien auch von den Debuggern benutzt.
Teilweise fehlende/falsche Bits, teilweise selbst zwischen 2 sehr nah
verwandten Derivaten komplett unterschiedliche Namensgebung (z.b.
ADC_Common vs. ADC123_Common, etc.), von anderen Familien braucht man da
gar nicht erst reden.
Teilweise weit hinterher mit der Verfügbarkeit, zumindest verglichen zu
den echten Headern, die wohl intern bei ST auch mit irgendeinem Tool
erzeugt werden...
usw. usf.
Prinzipiell wären SVDs eine tolle Sache, aber nicht wenn man sie nicht
ordnungsgemäß pflegt. :(
Yalu X. schrieb:> Das volatile-Qualifier ist einer der Punkte, wo mikroPascal etwas> Sinnvolles von C geerbt hat.
Ist aber auch wieder typische Pascal-Balkanisierung: je nach Compiler
sind ungekennzeichnete globale Variablen mal volatile und mal nicht. Das
passiert halt, wenn's keinen praxistauglichen Standard gibt.
Holm T. schrieb:> Ist aber sowieso Wurscht da die obere Zeile nur ein Präprozessor Symbol> definiert, ohne jede Funktionalität dahinter.
Sobald man das Prärozessorsymbol mit seinem darin enthaltenen volatile
in seinen Code einbaut wird es genauso wirksam als hätte man es direkt
selbst dort hingeschrieben.
> Das ist nichts weiter als> #define lehmann 5
weder "lehmann" noch "5" kann ich im verlinkten Post finden.
> Die ganze Sache wird in Pascal ohne volatile recht lustig
Nein, denn wenn Du das von Dir zitierte Post auch gelesen hättest dann
hättest Du gesehen daß in FPC jeder Strichpunkt eine Speicherbarriere
ist, bzw der Compiler enthält schlichtweg keine Optimierungen die über
solche Grenzen hinweg optimieren. Also ist praktisch von Haus aus alles
immer volatile. Solange das so bleibt braucht man sich auch keine
Gedanken um diesen gesamten Themenkomplex machen. Der Preis den man
zahlt sind massiv schlechtere Compileroptimierungen.
Das wird wahrscheinlich erst wieder interessant wenn irgendwann mal FPC
wie seit Jahren geplant auf LLVM als Backend umsteigt, selbiges könnte
wahrscheinlich potentiell bedeutend besser optimieren als der bisherige
FPC und Nutzen aus nicht-volatilen Variablen ziehen, vielleicht wird es
dann eingeführt.
Yalu X. schrieb:> Der TE hat nach eigener Aussage eine C-Allergie. Da mikroPascal eher ein> mutiertes C als ein echtes Pascal ist (was man durchaus auch positiv> sehen kann), wird er vermutlich auch darauf allergisch reagieren.
Zumindest besteht eine deutliche Chance einer solchen Kreuzallergie.
Bernd K. schrieb:> Holm T. schrieb:>> Ist aber sowieso Wurscht da die obere Zeile nur ein Präprozessor Symbol>> definiert, ohne jede Funktionalität dahinter.>> Sobald man das Prärozessorsymbol mit seinem darin enthaltenen volatile> in seinen Code einbaut wird es genauso wirksam als hätte man es direkt> selbst dort hingeschrieben.>
Loriot: Ach!?
Du definierst also Interrupt Service Routinen immer im cpp und nicht im
Compiler oder Assembler?
>> Das ist nichts weiter als>> #define lehmann 5>> weder "lehmann" noch "5" kann ich im verlinkten Post finden.
Wirklich nicht? Tatsache! Bernd K. aber auch nicht.
>>> Die ganze Sache wird in Pascal ohne volatile recht lustig>> Nein, denn wenn Du das von Dir zitierte Post auch gelesen hättest dann> hättest Du gesehen daß in FPC jeder Strichpunkt eine Speicherbarriere> ist, bzw der Compiler enthält schlichtweg keine Optimierungen die über> solche Grenzen hinweg optimieren. Also ist praktisch von Haus aus alles> immer volatile. Solange das so bleibt braucht man sich auch keine> Gedanken um diesen gesamten Themenkomplex machen. Der Preis den man> zahlt sind massiv schlechtere Compileroptimierungen.>
Nein! Doch! Oh..
> Das wird wahrscheinlich erst wieder interessant wenn irgendwann mal FPC> wie seit Jahren geplant auf LLVM als Backend umsteigt, selbiges könnte> wahrscheinlich potentiell bedeutend besser optimieren als der bisherige> FPC und Nutzen aus nicht-volatilen Variablen ziehen, vielleicht wird es> dann eingeführt.
Du bekommst von mir einen grünen Gummipunkt zum Sammeln. Hast Du Dir
echt verdient.
Gruß,
Holm
Bernd K. schrieb:> Nein, denn wenn Du das von Dir zitierte Post auch gelesen hättest dann> hättest Du gesehen daß in FPC jeder Strichpunkt eine Speicherbarriere> ist, bzw der Compiler enthält schlichtweg keine Optimierungen die über> solche Grenzen hinweg optimieren. Also ist praktisch von Haus aus alles> immer volatile. Solange das so bleibt braucht man sich auch keine> Gedanken um diesen gesamten Themenkomplex machen. Der Preis den man> zahlt sind massiv schlechtere Compileroptimierungen.
Vorsicht bei derartigen Schlußfolgerungen, wenn man so C-orientiert
argumentiert wie du grad eben.
Normalerweise gilt bei Pascal das "immer volatile" nur für Variablen,
die eine Prozedur oder Funktion nicht unter ihrer vollständigen
Kontrolle hat.
Das ist aber ne subtile Sache.
Erstens sind lokale Variablen einer Prozedur oder Funktion nicht
volatile, es sei denn, sie werden von lokalen Prozeduren/Funktionen
verwendet. (ja, dieses Konzept gibt es in Pascal).
Zweitens sind unit-interne globale Variablen nur dann volatile, wenn sie
entweder im Interface veröffentlicht sind oder innerhalb des Units von
mehreren Instanzen verwendet werden, so daß eine Instanz eben nicht
davon ausgehen kann, daß sie den alleinigen Zugriff darauf hat.
Und ein wirklich auf µC als Zielplattform portiertes Pascal müßte das
"absolute" automatisch als volatile behandeln, das ist ja wohl klar.
Nun ja, kommen wir noch kurz zu Mikroe und deren Pascal: Da ist nach wie
vor nur eine beschränkte Auswahl an Zielplattformen möglich - und als
Anwender kann man diese nicht erweitern. Genau das ist ein
Disqualifizierungsmerkmal gegenüber den üblichen C-Compilern jenseitsvon
Mikroe. Ich hab grad mal geschaut: einige Freescale MK22xx, dazu viele
STM32, Texas/Stellaris - aber ansonsten weder LPC noch Nuvotons usw.
W.S.
wowzu auch...das ist eben genau das Problem von diesem Opensource
Gedanken..alles muss frei und toll und für alles sein.Schlussendlich ist
alles ein wildes Gebastel.
Wir sehen alle wie toll das bei linux klappt...
Bei Mirko e.
Download.
Starten..
Hellow World tippen, übertragen ..läuft!
Hallo world über Uart tippen..übetragen ..läuft..
Das gleiche bei Freepascal..download..Tippen..läuft....
In C geht das höchstens mit MS Visual C++
Mehr will ich damit nicht sagen.
Und Sowohl Freepascal als auch mikroe werden in kommerziellen Produkten
eingesetzt.
Und diese Gejammer dieses und jenes ginge nicht..so ein Quatsch..im
Alltag spielt das für 99,9% überhaupt keine Rolle
Und sicher ginge auch Python..hier kenne ich mich aber nicht gut genug
mit aus, als das ich das jetzt vergleichen könnte..was da mehr doer
weniger Vorteile hätte im Vergleich zu Pascal.
Lange Rede kein Sinn...teste das doch einfach mal, schau die einfache
Beispiele an und entscheide selbst.
Ich fände es aber super, wenn Du das Ergebnis hier schreiben würdest,
egal wie es ausgefallen ist.
W.S. schrieb:> Zweitens sind unit-interne globale Variablen nur dann volatile, wenn sie> entweder im Interface veröffentlicht sind oder innerhalb des Units von> mehreren Instanzen verwendet werden, so daß eine Instanz eben nicht> davon ausgehen kann, daß sie den alleinigen Zugriff darauf hat.
Es gibt nicht nur I/O-Ports.
Wie stellt sich das bei Interrupt-Handlern dar? Ohne das Wissen eines
Compilers, welche der nur innerhalb der Unit oder Instanz verwendeten
Variablen auch von Handlern genutzt werden, wird es dann doch etwas
schwierig, oder? Ebenso Multithreading als Erweiterung dieses Prinzips.
Das ist doch im Grunde genau das gleiche Problem. Auch in C wird
"volatile" nur dort erforderlich, wo der Compiler nicht selber weiss
worum es geht. Wenn ein non-C Compiler Unit- oder Instanz-lokale
Variablen nicht optimieren darf, weil mehr dahinter ist als die für ihn
sichtbare Reihenfolge der Codeausführung, dann muss man ihm das sagen.
Man kann sich dann nur darüber streiten, in welcher Form man das macht.
Weiss ein Compiler, dass eine Funktion ein Handler ist, und gibt es
keine Pointer, dann geht es ohne "volatile", weil er es aus dem Code
ableiten kann. Andernfalls sind wieder alle Wetten offen.
Mit der erwähnten Beschränkung auf Optimierung nur innerhalb eines
Statements ist man natürlich auf der sicheren Seite. Aber wenn man
darüber hinaus will, muss man sich schon Gedanken um Interrupts und
Multithreading machen. Das Ergebnis muss nicht dem "volatile" in C
entsprechen, das geht auch anders. Aber irgendwas wird nötig.
Tina schrieb:> Mehr will ich damit nicht sagen.
Ist auch besser so, ehrlich. Das vermeidet, dass du dich hier weiter
mit ausgesprochener „Sachkenntnis“ blamierst.
Die C Compiler der 70er und frühen 80er arbeiten ungefähr nach dem
erwähnten Muster, Optimierungen mit Folgen für Zugriffe auf Variablen
allenfalls innerhalb von Statements durchzuführen.
Die Mainframes waren schon wesentlich weiter, aber die hatten auch die
Kapazitäten dazu (dortige Erfahrungen führten zur RISC Philosophie). Ein
Compiler, der ohne allzu viele Overlays in den 64KB grossen logischen
Adressraums einer PDP-11 passen und dafür keine 12 Passes verbraten
soll, der ist halt begrenzt.
Es war der Druck neuer ernsthaft optimierender C Compiler auf 32-Bit
Maschinen, der "volatile" überhaupt erst erforderlich machte.
> wie seit Jahren geplant auf LLVM als Backend umsteigt, selbiges könnte> wahrscheinlich potentiell bedeutend besser optimieren als der bisherige> FPC
Eine rigide Beschränkung der Optimierung kann Sinn ergeben. Es gibt
Umgebungen, in denen Code grundsätzlich nur unoptimiert genutzt wird,
weils sonst einfach zu gefährlich ist. Lieber mehr Bums in Hardware als
ein Bums gegen den Baum. Mit der Vorgabe keiner Statement-übergreifender
Optimierung landet man ähnlich. Was man nicht falsch machen kann, das
macht man auch nicht falsch.
Ob es dann allerdings überhaupt Sinn ergibt, hochkomplexe Compiler wie
GCC oder LLVM als Grundlage zu nehmen, möchte ich in Frage stellen. Wenn
Zuverlässigkeit höchste Priorität hat, dürfte es besser sein, kleine
übersichtliche Compiler zu verwenden, die Statements ziemlich direkt in
Code umsetzen. Statt sich mit zigmal grösseren Compilern abzukämpfen, in
denen ein grosser Teil des Quellcodes überhaupt nicht genutzt wird. Denn
mit jeder geänderten Zeile im Compiler geht das Test- und
Zertifizierung-Gedöns erneut los, selbst wenn diese Zeile überhaupt
nicht zum tragen kommt.
Jörg W. schrieb:> Ist auch besser so, ehrlich.
Nee, laß mal. Für das, was die Leute von Mikroe vorgesehen haben,
funktioniert es wohl. Aber das ist eben auch zugleich die Beschränkung.
Wenn sich jeder seine Entsprechung zu "meinchip.h" selber schreiben
könnte (Konjunktiv, kein MUSS), dann wäre das der Verbreitung extrem
nützlich gewesen. Ist aber nicht, wohl aus Firmenpolitik, also war's
das.
W.S.
A. K. schrieb:> mit jeder geänderten Zeile im Compiler geht das Test- und> Zertifizierung-Gedöns erneut los, selbst wenn diese Zeile überhaupt> nicht zum tragen kommt.
Ich hatte schon ein solches GCC-Update, bei dem der Test dann sehr
schnell ging - das erzeugt Hexfile war nämlich dasselbe wie vorher.
A. K. schrieb:> Es gibt nicht nur I/O-Ports.>> Wie stellt sich das bei Interrupt-Handlern dar?A. K. schrieb:> Ebenso Multithreading als Erweiterung dieses Prinzips.
Hast du es denn nicht gelesen, was ich geschrieben habe? Bei
Interrupthandlern sieht das ganz genauso aus wie bei Threadfunktionen am
PC.
Meine Delphi-Programme benutzen schon seit ewig Threads und das
funktioniert auch seit ewig, ohne daß dafür dedizierte Pendants zu
"volatile" erforderlich wären. Die Regeln dazu hab ich doch umrissen.
Bei C ist das erklärlicherweise schwieriger, weil es dort vieles nicht
gibt und deshalb in erheblichem Maße mit Zeigern und Casts gearbeitet
werden muß.
Und mal ganz abgesehen davon..
..schau dir bloß mal an, wie all die STM32-Jünger heutzutage ihre
Controller programmieren: Da werden XYZ_InitStruct's bis zum Bersten
gefüllt und ein Stück Libfunktion aufgerufen, wo doch ein simples
Beschreiben der HW-Register es um Längen effizienter getan hätte.
Glaubst du wirklich, daß bei solchem Programmierstil ein noch so hoch
optimierender C-Compiler irgendwas ausrichten kann? Ich nicht.
W.S.
"Ist auch besser so, ehrlich. Das vermeidet, dass du dich hier weiter
mit ausgesprochener „Sachkenntnis“ blamierst."#
Na versucht da wieder ein Moderator Unruhe zu stiften?....
Sorry, aber solch Kommentare sollte man sich als Mod klemmen
Nop schrieb:> Ich hatte schon ein solches GCC-Update, bei dem der Test dann sehr> schnell ging - das erzeugt Hexfile war nämlich dasselbe wie vorher.
Das hilft dir nicht wirklich. Denn das besagt nicht, dass es bei einer
Änderung in deinem Programm immer noch neutral bleibt.
Wenn dann auch noch die verwendete Version des Compiler selbst Teil
einer restriktiven Vorgabe ist, man also nicht einfach den Update der
IDE ziehen und mal eben das Projekt neu übersetzen darf, dann dürften
bekannte Bugs des Compilers, um die man herum programmiert, typischer
sein als neue Versionen des Compilers mit Ausicht auf neue unbekannte
Bugs.
W.S. schrieb:> ..schau dir bloß mal an, wie all die STM32-Jünger heutzutage ihre> Controller programmieren: Da werden XYZ_InitStruct's bis zum Bersten> gefüllt und ein Stück Libfunktion aufgerufen, wo doch ein simples> Beschreiben der HW-Register es um Längen effizienter getan hätte.
Hast denn nicht gelesen, was ich schon vor langer Zeit geschrieben habe?
Meine Rede seit Jahren. ;-)
Effizienz ist aber weniger der Punkt, meistens jedenfalls, wenns dadurch
immerhin einfacher und übersichtlicher würde. Was es schon aufgrund der
umständlichen struct-Technik nicht ist. Unschön finde ich auch, dass
dabei eine gut dokumentierte Hardware durch eine mässig bis schlecht
dokumentierte Library ersetzt wird. Und man sich spätestens beim
Debugging sowieso mit der Auswirkung auf die Hardware befassen muss,
also um dessen Doku sowieso nicht herum kommt.
> Hast du es denn nicht gelesen, was ich geschrieben habe?
Wenn es in dem betreffenden Beitrag stand, dann habe ich es darin nicht
gefunden. Und im Rest vom Thread auch nicht. Ich bin konkret weder mit
Delphi noch sonst einem halbwegs aktuellen Pascal näher vertraut,
weshalb ich deren Konzepte zur Kennzeichnung oder Vermeidung
nebenläufigen Zugriffs nicht kenne. Genau die würden mich ja
interessieren.
A. K. schrieb:> Wenn es in dem betreffenden Beitrag stand, dann habe ich es darin nicht> gefunden. Und im Rest vom Thread auch nicht.
Mein Verstaendnis von der Sache: Nur lokale Variablen werden optimiert,
globale Variablen sind implizit volatil (allerdings nur im Rahmen eines
Statements). Welche Variablen genau unter lokal und global einsortiert
werden, weiss ich aber auch nicht.
Ein Interrupt greift auf Hardwareregister zu, diese sind global (=
volatile). Werte werden in Puffervariablen geschrieben, diese sind
global (=volatile).
W.S. schrieb:> Glaubst du wirklich, daß bei solchem Programmierstil ein noch so hoch> optimierender C-Compiler irgendwas ausrichten kann? Ich nicht.
Das hat nix mit Glauben zu tun, das ist gar kein Problem. Gute Compiler
wie der GCC können noch ganz andere Sachen optimieren, mit mehreren
verschachtelten temporären Objekten, per templates generierten
Algorithmen usw. Im konkreten Falle der ST HAL müsste man dazu aber die
Optimierung erstmal erlauben, indem die Funktionen als "inline"
markiert, was ST natürlich nicht getan hat. Schlau wäre es zudem, wo
möglich die structs zu initialisieren und als constexpr zu markieren
anstelle von nachträglichen Zuweisungen, sodass sie im Flash landen.
Wird die entsprechende HAL-Funktion mehrfach genutzt, spart man so
durchaus Flash gegenüber direkten Register-Zugriffen.
Tina schrieb:> Hellow World tippen, übertragen ..läuft!> Hallo world über Uart tippen..übetragen ..läuft..
Schön, ein System was die schnelle Implementierung von Hello World
ermöglicht! Das kann Arduino (C++) auch. Möchte man mehr Freiheiten für
komplexere Aufgaben, freut man sich über flexiblere Systeme, die dann
natürlich schwieriger zu handhaben sind.
A. K. schrieb:> Aber wenn man> darüber hinaus will, muss man sich schon Gedanken um Interrupts und> Multithreading machen. Das Ergebnis muss nicht dem "volatile" in C> entsprechen, das geht auch anders. Aber irgendwas wird nöti
Bei Multithreading ist aber volatile auch ungeeignet, schon alleine weil
nicht-wegoptimierte Zugriffe noch lange kein "konsistentes" Verhalten
bei Multiprozessor-Systemen garantieren. Dort nutzt man atomics, Mutexe
usw.
Beispiel:
1
volatileinta=0,b=0;
2
voidthread1(void){
3
a=1;
4
b=2;
5
}
6
voidthread2(void){
7
printf("%d,",b);
8
printf("%d\n",a);
9
}
Die Ausgabe kann z.B. "2, 0" sein, trotz volatile. Hier brauchts nicht
nur Optimierungs-Barrieren, sondern auch Speicher-Barrieren, wie sie von
atomics geboten werden. Vielleicht kann jemand was dazu sagen, wie
Pascal das handhabt?
Dr. Sommer schrieb:> Das hat nix mit Glauben zu tun, das ist gar kein Problem.
In diesem Falle habe ich da schon meine Zweifel. Da werden Bits in
IO-Register gesetzt (die sind "volatile"), die da schon so drin stehen,
weil man ja diese structs immer komplett befüllen muss als Nutzer, und
die Bibliotheksfunktion sie dann auch komplett in die Hardware
reinwirft.
Hat allerdings nichts mit C oder Alternativen dazu zu tun. :-)
W.S. schrieb:> Bei C ist das erklärlicherweise schwieriger, weil es dort vieles nicht> gibt und deshalb in erheblichem Maße mit Zeigern und Casts gearbeitet> werden muß.
Das ist falsch, denn in C hat volatile weder mit Zeigern noch mit Casts
etwas zu tun. Es ist in C drin, weil C als Sprache zur
Systemprogrammierung konzipiert und dann auch eingesetzt worden ist.
Sobald man den ersten RX/TX-Interrupt hat, wird offensichtlich, daß man
das braucht.
Pascal hat das nicht, weil es als nutzlose Spielzeugsprache aus dem
Elfenbeinturm ISO-standardisiert worden ist. In der Folge hat jeder
Compiler-Hersteller sein eigenes Süppchen kochen müssen, um daraus etwas
praktisch Brauchbares zu machen.
Feldstecher schrieb:> Mein Verstaendnis von der Sache: Nur lokale Variablen werden optimiert,> globale Variablen sind implizit volatil (allerdings nur im Rahmen eines> Statements).
So gehts natürlich ohne Kennzeichnung, wie ich schon schrieb. Ist aber
eben auch recht restriktiv hinsichtlich Optimierung. Im Kontext von
Controllern kann das ein akzeptabler Kompromiss sein.
Interessant sind Variablen, die nur innerhalb des Moduls (oder Unit, wie
immer das heisst) bekannt sind, aber ausserhalb der
Funktionen/Prozeduren. Wenn du diese in deinen Begriff "global"
einschliesst, dann gibts keine Probleme.
Nop schrieb:> Pascal hat das nicht, weil es als nutzlose Spielzeugsprache aus dem> Elfenbeinturm ISO-standardisiert worden ist. In der Folge hat jeder> Compiler-Hersteller sein eigenes Süppchen kochen müssen, um daraus etwas> praktisch Brauchbares zu machen.
Dass es hier nicht um das Wirth'sche Pascal der 70er geht ist
offensichtlich. Wenn man plattformübergreifend programmiert ist das
natürlich ein Kriterium, man ist mit Pascal-Deriviaten etwas festgelegt.
Aber das muss im Controller-Umfeld nicht unbedingt ein grosses Problem
sein.
Dr. Sommer schrieb:> Im konkreten Falle der ST HAL müsste man dazu aber die> Optimierung erstmal erlauben, indem die Funktionen als "inline"> markiert
Nein. "inline" ist lediglich ein unverbindlicher Vorschlag an den
Compiler, der aber gemäß der as-if-Philosophie mit und ohne inline
inlinen kann oder auch nicht.
> was ST natürlich nicht getan hat. Schlau wäre es zudem, wo> möglich die structs zu initialisieren und als constexpr zu markieren
In C?!
> Die Ausgabe kann z.B. "2, 0" sein, trotz volatile. Hier brauchts nicht> nur Optimierungs-Barrieren, sondern auch Speicher-Barrieren
Die sind natürlich hardware-spezifisch, aber volatile ist die halbe
Miete.
Nop schrieb:> Nein. "inline" ist lediglich ein unverbindlicher Vorschlag an den> Compiler, der aber gemäß der as-if-Philosophie mit und ohne inline> inlinen kann oder auch nicht.
Korrekt. Aber beim inlinen hat der Compiler viel mehr Möglichkeiten zur
Optimierung. Optimieren ist ja auch nicht vom Standard vorgeschrieben.
Nop schrieb:> In C?!
Das ist natürlich C++. "static const" hilft aber auch in C.
Nop schrieb:> Die sind natürlich hardware-spezifisch, aber volatile ist die halbe> Miete.
Was bringt die halbe Miete, wenn sie nicht funktioniert? Man nutzt
einfach atomics wie sie vom Standard vorgeschrieben sind und kein
volatile, und es funktioniert. volatile braucht man bei normalen
Programmen mit klassischem Multithreading nie, das ist nur für
Low-Level-Programmierung mit Interrupts und IO-Registern.
A. K. schrieb:> Es gibt nicht nur I/O-Ports.
In C ist volatile nur für I/O Zugriffe relevant, oder? Volatile
verhindert kein reordering, synchronisiert nicht und garantiert keine
atomaren Zugriffe.
Wie sieht das bei Free Pascal aus? Gibt es da so etwas wie _Atomic(Type)
(C) und atomic<Type> (C++), oder werden alle Zugriffe auf "globale"
Objekte automatisch voll synchronisiert (barrier,release/acquire, ...),
oder muss man alles selbst synchronisieren?
Nop schrieb:> Sobald man den ersten RX/TX-Interrupt hat, wird offensichtlich, daß man> das braucht.
In C ja. Aber es sind auch andere Konzepte vorstellbar.
Denk dir eine Sprache, mit ein paar Eigenschaften:
- Es gibt zumindest in Handlern keine Pointer.
- Ein Handler nutzt nur Variablen aus dem Modul, in dem er definiert
ist.
- Ein Handler wird entsprechend gekennzeichnet.
Dann hat der Compiler den vollen Überblick darüber, welche Variablen auf
welche Weise nebenläufig sind, ohne dass man die extra kennzeichnen
müsste. Nämlich nur die in Handlern. Und er könnte dann sogar besser
optimieren als C, beispielsweise weil er mit einer Variable, die im
Hauptkontext geschrieben und im Handler gelesen wird, anders umgehen
kann als umgekehrt.
Multithreading wäre dann ein eigenes Thema.
A. K. schrieb:> Dass es hier nicht um das Wirth'sche Pascal der 70er geht ist> offensichtlich.
Schon, aber dieser Unsinn ist standardisiert worden. Eine Konsequenz
ist, daß eventuelle Änderungen stets abwärtskompatibel sein müssen, weil
man nicht einfach wie in C sagen kann, nach welchem Standard man denn
compilieren will. Gibt ja keinen brauchbaren.
> Wenn man plattformübergreifend programmiert ist das> natürlich ein Kriterium, man ist mit Pascal-Derivaten etwas festgelegt.
Vor allem wird es lästig, wenn man z.B. Mockups erstellen will. Dann ist
man direkt auf Compiler begrenzt, die auf PC und dem Controller
verfügbar sind. Effektiv also auf FPC. Für Hobby OK, aber keine Firma
würde sich auf etwas einlassen, wo man im Ernstfall mit Glück in
irgendeinem Forum nachhaken kann.
> Aber das muss im Controller-Umfeld nicht unbedingt ein grosses Problem> sein.
Ist es aber. Da es keine Standards gibt, sondern nur proprietäres
Gefrickel (und das schon weit vor Turbo-Pascal), finden
Sprachdiskussionen nicht herstellerübergreifend statt wie bei C. Die
Folge ist, daß jeder irgendwie erweitert und man überhaupt keine
referenzierbare Baseline bekommt. Den Vendor-Lockin gibt's natürlich
gratis dazu.
Mit C muß ich mir keine Gedanken machen, was für einen Compiler und
Hersteller ich da gerade habe, denn da das standardisiert ist, verhält
es sich überall gleich. Stellenweise gleich krank, aber immerhin.
Dennoch sehe ich Pascal als Lehrsprache im Vorteil gegenüber C, schon
weil das strikte Typensystem den Anfänger von vornherein sensibilisiert.
Zwei/Drei-Sterneprogrammierung braucht ein Anfänger eh nicht.
mh schrieb:> In C ist volatile nur für I/O Zugriffe relevant, oder?
Jein. Man nimmt das auch, wenn Interrupts einem Sachen in einen Buffer
schaufeln, den man aus der Applikation lesen will - und umgedreht. Also
nicht nur direkt für die IO-Register-Zugriffe.
Jörg W. schrieb:> In diesem Falle habe ich da schon meine Zweifel.
Sie sind aber unangebracht. Ich verstehe nicht ganz was du meinst, habe
es aber ausprobiert:
Die angehängte Datei ist eine Zusammenstellung der Funktion und
Definitionen zur Initialisierung eines GPIO-Pins in der HAL. Die
Funktion ist mit always_inline markiert. Das sieht dann ziemlich schlimm
aus und die Funktion ist sehr lang, aber der GCC macht daraus bei -O3:
1
00000000<test>:
2
0:4a03ldrr2,[pc,#12];(10<test+0x10>)
3
2:6813ldrr3,[r2,#0]
4
4:f023030fbic.wr3,r3,#15
5
8:f0430303orr.wr3,r3,#3
6
c:6013strr3,[r2,#0]
7
e:4770bxlr
8
10:40010800.word0x40010800
Besser geht's m.W. nicht. Ob Pascal-Compiler, oder proprietäre Compiler
wie der ARMCC so gut sind, bliebe noch zu erforschen...
Dr. Sommer schrieb:> Was bringt die halbe Miete, wenn sie nicht funktioniert? Man nutzt> einfach atomics wie sie vom Standard vorgeschrieben sind
Atomics in C? Nach welchem Standard?
Ansonsten kann man ohne weiteres volatile kombinieren mit einem Macro,
das einem einen hardwaremäßigen Memsync gibt, und schon hat man, was man
braucht. Ich hab sowas auch schon gemacht, weil das zwar in gewisser
Weise ein dirty hack ist, dafür aber portabel unter allen
Betriebssystemen funktioniert. Sollte man halt nicht gerade so einbauen,
daß es einem die Performance ruiniert.
Nop schrieb:> Atomics in C? Nach welchem Standard?
C11.
Nop schrieb:> Ansonsten kann man ohne weiteres volatile kombinieren mit einem Macro,> das einem einen hardwaremäßigen Memsync gibt, und schon hat man, was man> braucht.
Über fiese Hacks und Inline-Assembler brauchen wir wohl nicht zu
diskutieren...
> Die Ausgabe kann z.B. "2, 0" sein, trotz volatile.
Das ist leider so nicht ganz richtig. Die schreibenden Zugriffe auf a
und b in thread1 dürfen nicht vertauscht werden weil a und b volatile
sind.
mh schrieb:> In C ist volatile nur für I/O Zugriffe relevant, oder?
Nein, es ist auch für Interrupts und Multithreading relevant. Atomarer
Zugriff ist zwar ein eigenes Thema, aber wenn aufgrund entsprechender
Massnahmen gesichert ist, dass kein nicht-atomarer Zugriff unterbrochen
wird, muss trotzdem sichergestellt werden, dass ein Zugriff überhaupt
stattfindet.
Der Klassiker hierfür ist:
1
bool flag;
2
3
void handler(void)
4
{
5
flag = true;
6
}
7
8
void run(void)
9
{
10
.. egal was, aber lass "flag" in Ruhe ..
11
}
12
13
void f(void)
14
{
15
for (;;) {
16
if (flag) {
17
run();
18
flag = false;
19
}
20
}
21
}
Ohne "volatile" bei "flag" wird ein optimierender Compiler in f() nicht
jedesmal in der Schleife auf "flag" zugreifen, sondern genau 1x am
Anfang und von der Änderung nichts mitkriegen.
mh schrieb:> Die schreibenden Zugriffe auf a> und b in thread1 dürfen nicht vertauscht werden weil a und b volatile> sind.
Vom Compiler nicht. Der Prozessor weiß davon nix und kann die anordnen
wie er lustig ist.
Hier noch eine Quelle dazu:
https://stackoverflow.com/a/4558031
"Short & quick answer: volatile is (nearly) useless for
platform-agnostic, multithreaded application programming. It does not
provide any synchronization, it does not create memory fences, nor does
it ensure the order of execution of operations. It does not make
operations atomic. It does not make your code magically thread safe.
volatile may be the single-most misunderstood facility in all of C++."
Nop schrieb:> mh schrieb:>>> In C ist volatile nur für I/O Zugriffe relevant, oder?>> Jein. Man nimmt das auch, wenn Interrupts einem Sachen in einen Buffer> schaufeln, den man aus der Applikation lesen will - und umgedreht. Also> nicht nur direkt für die IO-Register-Zugriffe.
In dem Fall muss der Zugriff aber auch atomar sein. Die Zugriffe dürfen
also nicht unterbrechbar sein und dürfen nicht umgeordnet werden.
Dr. Sommer schrieb:> Nop schrieb:>> Atomics in C? Nach welchem Standard?> C11.
Ah, gut zu wissen, danke.
> Über fiese Hacks und Inline-Assembler brauchen wir wohl nicht zu> diskutieren...
Nix inline-Assembler, das geht mit "__sync_synchronize" sowohl mit GCC
als auch mit LLVM. Sinnigerweise kapselt man das mit einem eigenen
Macro, falls man auf einen Compiler stößt, bei dem man es anders machen
müßte.
Nop schrieb:> Nix inline-Assembler, das geht mit "__sync_synchronize" sowohl mit GCC> als auch mit LLVM.
Ah, weil compilerspezifische nichstandardisierte Builtins gleich viel
besser sind als Assembler ;-) Vor C11 und C++11 haben die beiden
Sprachen rein technisch gar kein Multithreading unterstützt, das wurde
nur durch Spracherweiterungen möglich. C++11 hat dann Atomics
eingeführt, und C hat sie abgekupfert - seitdem kann man
plattformunabhängig und standardkonform mit Multithreading arbeiten, und
das ganz ohne volatile. Atomics können einem aber leicht einen Knoten
ins Hirn machen...
Nop schrieb:>> Aber das muss im Controller-Umfeld nicht unbedingt ein grosses Problem>> sein.>> Ist es aber. Da es keine Standards gibt, sondern nur proprietäres> Gefrickel
Wenn sich jemand bei einer bestimmten Lösung für eine bestimmtes
Werkzeug entscheidet, dann kann das auch sinnvoll sein. Auch dann, wenn
er sich mit diesem Werkzeug festlegt. Das ist seine Entscheidung.
Ich würde auch empfehlen, den Begriff "Gefrickel" nicht
überzustrapazieren. Es sei denn man ist ohnehin auf Kravall aus. Nicht
jede spezielle Lösung ist schon deshalb Gefrickel, weil sie speziell
ist.
Apropos Wirth: In diesem Sinn war Wirth ein Frickler erster Güte ;-).
Seine Philosophie war nämlich, sich für jedes Problem, das er nicht mit
einem seiner bestehendene Werkzeug sauber abdecken konnte, ein neues
Werkzeug zu schaffen. Standards, Multiplattformfähigkeit und
Vendor-Lockin hat ihn wenig interessiert (als Prof konnte ihm das auch
egal sein).
mh schrieb:> In dem Fall muss der Zugriff aber auch atomar sein.
Nein, muß er nicht. Immerhin hat man ja drei Variablen: Lese-Index,
Schreib-Index und Buffer. Man muß das halt in der richtigen Reihenfolge
machen und sich ggf. lokale Kopien der Indices anlegen, auf denen man
arbeitet. Das ist eigentlich ziemlich straight-forward.
Dr. Sommer schrieb:> Ah, weil compilerspezifische nichstandardisierte Builtins gleich viel> besser sind als Assembler ;-)
Wieso, wenn man, wie ich sagte, mit einem eigenen Macro kapselt, dann
ist sowas nicht weiter wild.
A. K. schrieb:> Ohne "volatile" bei "flag" wird ein optimierender Compiler in f() nicht> jedesmal in der Schleife auf "flag" zugreifen, sondern genau 1x am> Anfang und von der Änderung nichts mitkriegen.
Ja, in deinem Beispiel stimmt das. Aber der Compiler darf alles
(natürlich nicht wirklich alles ;-) ) was nicht volatile ist um die
volatile Zugriffe anders anordnen.
Wenn der Inhalt deiner for-Schleife so aussieht:
1
intfoo=0;
2
if(flag){
3
foo=f();
4
flag=false;
5
}
6
// mache was mit foo
Und f sieht so aus:
1
intf(){
2
// ... berechne Wert ...
3
returnWert;
4
}
dann kann der Compiler daraus
1
intfoo=f();
2
if(flag){
3
flag=false;
4
}
5
else{
6
f=0;
7
}
8
// mache was mit foo
machen, solange er sehen kann das f keine Nebeneffekte hat. Das in
diesem Fall nicht sinnvoll und nicht wirklich schädlich, kann aber
schnell ein Problem werden wenn das Flag andere Daten schützt, die im
Handler gesetzt werden.
A. K. schrieb:> Nicht> jede spezielle Lösung ist schon deshalb Gefrickel, weil sie speziell> ist.
Ich hab seinerzeit genug Frust mit der Balkanisierung von Pascal gehabt,
weil im Unterricht Turbo-Pascal eingesetzt wurde, ich aber einen Atari
ST hatte und mir somit ST-Pascal verfügbar gewesen wäre.
Selbstverständlich inkompatibel. Mit C wäre das alles kein Problem
gewesen, aber mit Pascal gab's dann abenteuerliche Klimmzüge, die allein
dem Pascal-Sprachgefrickel geschuldet waren.
Dr. Sommer schrieb:> mh schrieb:>> Die schreibenden Zugriffe auf a>> und b in thread1 dürfen nicht vertauscht werden weil a und b volatile>> sind.> Vom Compiler nicht. Der Prozessor weiß davon nix und kann die anordnen> wie er lustig ist.
Ist das so? Der Standard sagt soweit ich weiß, dass die Zugriffe nicht
vertauscht werden dürfen und unterscheidet nicht zwischen Compiler und
CPU. Also muss der Compiler dafür sorgen, dass die CPU nichts vertauscht
(? oder .)
mh schrieb:> Ist das so?
Lies doch meinen Link. Der Standard würde wohl kaum explizit
vorschreiben, dass Atomics eine Reihenfolge definieren, wenn volatile
Variablen es auch täten. Wie gesagt, alte C Standards können eigentlich
kein Multithreading, und das dort enthaltene volatile ist nicht dafür
gedacht oder geeignet.
37: 8b 3d 00 00 00 00 mov 0x0(%rip),%edi # 3d <thread2+0x15>
20
3d: 58 pop %rax
21
3e: eb c0 jmp 0 <print>
(printf ausgelagert um Code zu verkürzen). Ich seh da nix mit Memory
Barriers oder Synchronisierung. Der Compiler weiß an der Stelle nicht,
ob die beiden Funktionen nacheinander oder von verschiedenen Threads
aufgerufen werden, kann hier also auch nichts optimieren.
Nop schrieb:> gewesen, aber mit Pascal gab's dann abenteuerliche Klimmzüge, die allein> dem Pascal-Sprachgefrickel geschuldet waren.
Ich will hier nicht speziell auf irgendein bestimmten Pascal raus. Oder
auf irgendeine bestimmte Sprache. Sondern auf Entscheidungsprozesse
allgemein.
Denk dir folgende Situation: Eine Firma A bringt eine neue Technik raus,
neue geniale Hardware, eine neuen Sprache mit neuen Eigenschaften, egal.
Eine andere Firma B sieht im Gegensatz zur konservativen Konkurrenz
frühzeitig das Potential und bringt auf dieser Basis ein Produkt, das
halb so teuer oder doppelt so schnell ist wie die Konkurrenz. Eben weil
sie als einzige oder zumindest erste auf etwas setzt, das neu ist und
speziell.
Wenn das Zeug von Firma A rechtzeitig funktioniert, hat B gewonnen und
die Konkurrenz hat ein grosses Problem. Wenn nicht, hat B ein Problem.
Beides hat es in der Vergangenheit schon öfter gegeben. Das macht diese
Entscheidung zu einer wesentlichen unternehmerischen Entscheidung. Aber
Begriffe wie "Gefrickel" sind in hier Schwachsinn (auch wenn die im
Gefolge eines Fehlschlags garantiert aufkommen ;-).
Deshalb: Nicht jede spezielle Lösung ist unangebracht. Es kann im
Einzelfall mehr Kritierien geben als nur Standards. Oft sind es
sinnvoll, der Herde zu folgen, aber nicht immer. Wenn eine neue Sprache,
ob sie was mit Pascal zu tun hat oder nicht, besondere Mechanismen
enthält, die ein neues Produkt wesentlich erleichtern, kann auch eine
Einschränkung auf diese proprietäre oder exotische Sprache einen Sinn
ergeben.
Dr. Sommer schrieb:> Der Standard würde wohl kaum explizit> vorschreiben, dass Atomics eine Reihenfolge definieren, wenn volatile> Variablen es auch täten.
Volatile verhindert das Umordnen der Zugriffe innerhalb eines Threads,
verhindert aber nicht, dass sie mit Zugriffe in einem anderen Thread
vertauscht werden. Atomics garantieren die Ordnung (und mehr) der
Zugriffe in mehreren Threads.
mh schrieb:> Volatile verhindert das Umordnen der Zugriffe innerhalb eines Threads
Jein. Das Gemeine ist, daß die nicht-volatile-Zugriffe sehr wohl über
die volatile-Zugriffe hinweg umgeordnet werden dürfen.
mh schrieb:> Volatile verhindert das Umordnen der Zugriffe innerhalb eines Threads,> verhindert aber nicht, dass sie mit Zugriffe in einem anderen Thread> vertauscht werden.
Sag ich doch. Um die Synchronisierung zwischen mehreren Threads ging es
ja die ganze Zeit. Schön dass du mir es jetzt glaubst...
A. K. schrieb:> Ich will hier nicht speziell auf irgendein bestimmten Pascal raus. Oder> auf irgendeine bestimmte Sprache. Sondern auf Entscheidungsprozesse> allgemein.
Nur sind die in Bezug auf Sprachen eben doch etwas anders gelagert. Wenn
da jeder abseits des Standards frickelt, weil es keinen brauchbaren
Standard gibt und geben wird, dann ist das Ergebnis einfach nur
Balkanisierung und Vendor-Lockin. Und, wie am Beispiel Pascal zu sehen,
die Erosion der ganzen Sprache in die weitgehende Bedeutungslosigkeit.
Und das obwohl Pascal sehr wohl Vorzüge hat, mit die es gegen C antreten
hätte können - wenn es standardisiert gewesen wäre.
Der Grund ist fehlender Wettbewerb, weil es zwischen inkompatiblen
Compilern keinen Wettbewerb gibt. Die Nutzer haben nämlich so hohe
Opportunitätskosten beim Wechsel, daß er ohnehin kaum machbar ist.
Das ist eben anders, wenn alle Wettbewerber denselben Standard
implementieren, weil die Entwicklung Standard-getrieben und nicht als
Frickelei erfolgt. Dann ist die Frage nämlich nicht, wer coolere
proprietäre Features frickelt, die die Nutzer binden, sondern wer den
Standard besser implementiert.
Auch in der Frage atomarer Zugriffe kann ich mir vorstellen, dass man
Sprachen schaffen kann, in denen es der Compiler selbst herausfinden
kann, welche Zugriffe wie abgesichert werden müssen. Oder das Ausmass an
Zugriffskonflikten durch andere Programmier-Paradigmata erheblich
reduziert wird. Und der Programmierer nicht fast in Assembler-Manier
jeden Kleinscheiss explizit modellieren muss, wie in C11.
Diese Sprache wird sicherlich nicht annähernd wie C aussehen, auch nicht
wie ein bestehendes Pascal. Und es wird Fälle geben, in denen man mit
den Freiheiten von C schneller ist als mit eher generischen Lösungen
dieser Sprache. Aber umgekehrt könnte diese Sprache das Programmieren
mit vielen Threads wesentlich erleichtern. Nicht immer ist das Tempo des
Programms der wichtigste Faktor. Oft ist das Tempo des Programmierers
wichtiger, oder die Zuverlässigkeit der Lösung.
Das fände ich interessanter als eine Neuauflage von der alten Frage, ob
man das Ei am dicken oder dünnen Ende aufschlägt, bzw. ob Pascal oder C.
A. K. schrieb:> Und der Programmierer nicht fast in Assembler-Manier> jeden Kleinscheiss explizit modellieren muss, wie in C11.
Aber dafür ist C doch gedacht, als portabler Makro-Assembler zur
Systemprogrammierung.
Nop schrieb:> Dann ist die Frage nämlich nicht, wer coolere> proprietäre Features frickelt, die die Nutzer binden, sondern wer den> Standard besser implementiert.
Schön wärs, wie oft passiert das in der Realität? Wer interessiert sich
dafür, wie gut Windows den POSIX-Standard oder den OpenGL-Standard
implementiert, wenn Windows das leistungsfähigere DirectX und Games
bietet im Gegensatz zu z.B. Linux? Wer fragt danach wie gut der
Microsoft C++ Compiler den C++ Standard implementiert (lange Zeit
ziemlich schlecht), wenn Visual Studio die benutzerfreundlichste IDE auf
der Plattform ist? Sinngemäß sieht man das doch ständig im Forum, wo
über Keil, IAR & Konsorten geschwärmt wird, die noch teilweise nicht
einmal versuchen aktuelle Sprachstandards zu implementieren, aber soo
tolle IDE's bieten. Weiter geht's mit FTDI-IC's die ein proprietäres
Protokoll statt USB-CDC nutzen, Office Suites die proprietäre Formate
nutzen, die Liste lässt sich endlos fortsetzen.
A. K. schrieb:> Auch in der Frage atomarer Zugriffe kann ich mir vorstellen, dass> man> Sprachen schaffen kann, in denen es der Compiler selbst herausfinden> kann, welche Zugriffe wie abgesichert werden müssen.
Richtig, gibts schon länger als C, nämlich rein funktionale Sprachen.
Nop schrieb:> Aber dafür ist C doch gedacht, als portabler Makro-Assembler zur> Systemprogrammierung.
Aber vielleicht sind zwei falsche Lösungen nicht richtiger als eine.
Also wenn man grad nicht dabei ist, ein Betriebssystem zu programmieren.
Dr. Sommer schrieb:> mh schrieb:>> Ist das so?> Kann man übrigens auch einfach ausprobieren:
Das ist x86? Dann ist das nicht sehr aussagekräftig, da x86 ein sehr
striktes (mir ist keine besseres Wort eingefallen) Memory Model hat und
Writes nur unter speziellen Bedingungen umordnet. Nen Arm mit OoO wäre
da interessanter.
Nop schrieb:> mh schrieb:>>> Volatile verhindert das Umordnen der Zugriffe innerhalb eines Threads>> Jein. Das Gemeine ist, daß die nicht-volatile-Zugriffe sehr wohl über> die volatile-Zugriffe hinweg umgeordnet werden dürfen.
Ich wollte auch nicht das Gegenteil behaupten, mein Beispiel mit foo =
f() und flag beruht ja genau darauf.
Dr. Sommer schrieb:> Sag ich doch. Um die Synchronisierung zwischen mehreren Threads ging es> ja die ganze Zeit. Schön dass du mir es jetzt glaubst...
Ok, vllt. haben wir dann etwas aneinander vorbei geschrieben. Ich
bestreite nicht, dass in deinem Beispiel die Ausgabe 2, 0 möglich ist.
Das liegt aber nicht daran, dass die Zugriffe von a = 1; b = 2; anders
angeordnet werden dürfen (dürfen sie nicht soweit ich weiß, weder
Compiler noch CPU), sondern daran, dass ein anderer Thread diese
Zugriffe nicht zwingen in der gleichen Reihenfolge sehen muss.
A. K. schrieb:> Aber vielleicht sind zwei falsche Lösungen nicht richtiger als eine.> Also wenn man grad nicht dabei ist, ein Betriebssystem zu programmieren.
Naja aber es ist doch relativ sinnfrei, sich darüber zu beklagen, daß C
eben vorrangig darin gut ist, wofür es gedacht ist - wenn man eben was
anderes will. Genauso ist Pascal als Lehrsprache durchaus gut, weil es
Anfänger dazu zwingt, sich von vornherein über Datentypen Gedanken zu
machen.
Dr. Sommer schrieb:> Schön wärs, wie oft passiert das in der Realität?
Ziemlich oft, weswegen C und C++ weiterhin sehr wichtige Sprachen sind.
Windows ist keine Sprache und kein Compiler, also andere Baustelle.
> Sinngemäß sieht man das doch ständig im Forum, wo> über Keil, IAR & Konsorten geschwärmt wird, die noch teilweise nicht> einmal versuchen aktuelle Sprachstandards zu implementieren
Irrelevant, denn sie implementieren überhaupt mal Standards, und
deswegen kann man zwischen ihnen wechseln, wenn man will. Es ist nicht
so, daß die bestehende Codebasis einen auf einen Hersteller festnageln
würde, das ist der Punkt.
Es ist doch in der Realität weitgehend egal, wie sexy man einen Compiler
findet, um ein neues Projekt zu starten. Der Knackpunkt ist doch,
wieviel Aufwand es wäre, die bestehende Codebasis zu migrieren.
Schließlich macht man weitaus mehr Bestandspflege als Neustart auf der
grünen Wiese.
Allein schon die Drohung, daß man seinen Compiler wechseln KÖNNTE,
bewirkt Wettbewerb - aber eben auch nur, wenn die Drohung mit einer
bestehenden Codebasis realistisch ist.
mh schrieb:> Das ist x86?
Ja.
mh schrieb:> Nen Arm mit OoO wäre da interessanter.
Hab ich grad keinen Compiler für, kannst du ja mal ausprobieren.
mh schrieb:> sondern daran, dass ein anderer Thread diese> Zugriffe nicht zwingen in der gleichen Reihenfolge sehen muss.
Das ist die abstrakte Sichtweise. Dass ein anderer Thread eine andere
Reihenfolge beobachtet, kann (muss aber nicht) daran liegen, dass die
tatsächlichen schreibenden Speicherzugriffe in anderer Reihenfolge
passieren (z.B. die Reihenfolge in der Cache-Pages rausgeschrieben
werden). Oder es liegt daran, dass der CPU des beobachtenden Threads die
Pages in anderer Reihenfolge liest.
Nop schrieb:> Irrelevant, denn sie implementieren überhaupt mal Standards, und> deswegen kann man zwischen ihnen wechseln, wenn man will. Es ist nicht> so, daß die bestehende Codebasis einen auf einen Hersteller festnageln> würde, das ist der Punkt.
Tja, kompilier bspw. mal den LPC USB Stack mit dem GCC und freu dich
über zufällige Hardfaults, weil der GCC undefiniertes Verhalten anders
umsetzt als z.B. der Keil, mit welchem das wohl entwickelt wurde... ST
versucht wenigstens, den GCC auch zu unterstützen.
Nop schrieb:> aber eben auch nur, wenn die Drohung mit einer> bestehenden Codebasis realistisch ist.
Genau, daher weichen schlaue Compilerhersteller auf subtile Art vom
Standard ab, sodass man eben nicht mehr so leicht abhauen kann. Das ist
doch Microsofts alte und bewährte Strategie...
Ich bin zwar auch sehr für einheitliche Standards, aber die Realität ist
dann doch nicht ganz so rosig. Am Ende gewinnt doch der mit dem besseren
Marketing...
A. K. schrieb:> Auch in der Frage atomarer Zugriffe kann ich mir vorstellen, dass man> Sprachen schaffen kann, in denen es der Compiler selbst herausfinden> kann, welche Zugriffe wie abgesichert werden müssen. Oder das Ausmass an> Zugriffskonflikten durch andere Programmier-Paradigmata erheblich> reduziert wird. Und der Programmierer nicht fast in Assembler-Manier> jeden Kleinscheiss explizit modellieren muss, wie in C11.>> Diese Sprache wird sicherlich nicht annähernd wie C aussehen, auch nicht> wie ein bestehendes Pascal. Und es wird Fälle geben, in denen man mit> den Freiheiten von C schneller ist als mit eher generischen Lösungen> dieser Sprache. Aber umgekehrt könnte diese Sprache das Programmieren> mit vielen Threads wesentlich erleichtern. Nicht immer ist das Tempo des> Programms der wichtigste Faktor. Oft ist das Tempo des Programmierers> wichtiger, oder die Zuverlässigkeit der Lösung.>> Das fände ich interessanter als eine Neuauflage von der alten Frage, ob> man das Ei am dicken oder dünnen Ende aufschlägt, bzw. ob Pascal oder C.
Die Sprache von der du redest heisst GO!
Diese wurde mit den Bedürfnissen von Multithreading (in relativ großem
Stil) im Fokus entwickelt.
Dr. Sommer schrieb:> weil der GCC undefiniertes Verhalten anders umsetzt
Undefiniertes Verhalten (gemäß Standard) ist exakt das. Wer sich auf ein
bestimmtes undefiniertes Verhalten verläßt, dem ist eh nicht mehr zu
helfen.
Nop schrieb:> Wer sich auf ein bestimmtes undefiniertes Verhalten verläßt, dem ist eh> nicht mehr zu helfen.
Jo. Sag das NXP. Auch im ST Code grassieren Dinge wie verbotene
Bezeichner. Hier im Forum werden oft kategorisch die korrekten Lösungen
abgelehnt und stattdessen undefinierte Frickelei bevorzugt, wie bspw.
Pointer umcasten und unions zum Daten konvertieren zu nutzen, um sich
dann über unerwartetes Verhalten zu wundern.
Dr. Sommer schrieb:> IAR & Konsorten geschwärmt wird, die noch teilweise nicht einmal> versuchen aktuelle Sprachstandards zu implementieren
Kennst du IAR wirklich? Meiner Meinung nach tust du ihnen damit
grob unrecht. Die hatten bspw. eine C99-Standard-Bibliothek, als
man im GCC-Umfeld davon nur träumen konnte.
Deren IDE habe ich nicht benutzt, aber der Compiler ist wirklich gut.
Eine einzige Sache habe ich in Erinnerung, bei der sie ziemlich dünn
sind: inline asm constraining. Das macht inline asm praktisch nutzlos,
denn das Einzige, auf was man sich darin verlassen kann, sind globale
Variable (aber dann könnte ich auch gleich die komplette Funktion in
Assembler schreiben). Das inline asm constraining des GCC versteht
man zwar wohl nur dann völlig, wenn man den Compiler versteht :), aber
es gibt einem System(bibliotheks)programmierer ein mächtiges Werkzeug,
welches man gerade im Embedded-Bereich gut benötigen kann.
Jörg W. schrieb:> Das inline asm constraining des GCC versteht> man zwar wohl nur dann völlig, wenn man den Compiler versteht :), aber> es gibt einem System(bibliotheks)programmierer ein mächtiges Werkzeug,> welches man gerade im Embedded-Bereich gut benötigen kann.
Das Inline-ASM vom GCC ist enorm mächtig, gerade weil es sich nicht nur
dazu eignet, ASM Funktionen zu schreiben, sondern sich recht weitgehend
in die Optimierung des Compilers integriert und man oft nur sehr wenig
ASM braucht, da der Compiler den Rest von sich aus erledigt. Aber wie
viele mächtigen Werkzeuge eignet es sich auch vorzüglich dazu, sich in
den Fuss zu schiessen.
A. K. schrieb:> Aber wie viele mächtigen Werkzeuge eignet es sich auch vorzüglich dazu,> sich in den Fuss zu schiessen.
Uneingeschränkte Zustimmung. :) Ist mir aber trotzdem viel lieber
als das impotente inline asm des IAR. Da schreiben die Leute nämlich
dann inline asm statements, die sich auf implizite Annahmen (wie
lokale Variablen in Registern) verlassen, die sie per trial&error
ermittelt haben und die bereits in der nächsten Compilerversion
hinfällig sein können. Da weiß man dann gar nicht mehr, warum der
Fuß plötzlich weh tut. :-))
Dr. Sommer schrieb:> Jo. Sag das NXP. Auch im ST Code grassieren Dinge wie verbotene> Bezeichner.
Daß Software von Hardwarefirmen nicht unbedingt der Hit ist, kann ja nun
keinen verwundern.
> Pointer umcasten und unions zum Daten konvertieren zu nutzen
Type punning über unions ist seit C99 einer der beiden korrekten Wege,
das zu tun.
Pointercasting ist abgesehen von wenigen Ausnahmen (char * darf alles
aliasen) undefiniertes Verhalten. Da, wo es im Code nicht zu vermeiden
ist, muß man striktes Aliasing im Build abschalten. Du nutzt direkt oder
indirekt übrigens jeden Tag Code, bei dem das so ist - alles, was mit
Linux gebaut wurde nämlich.
Nop schrieb:> Type punning über unions ist seit C99 einer der beiden korrekten Wege,> das zu tun.
Der ist zwar erlaubt, aber das Ergebnis ist dennoch undefiniert (hängt
bspw. von der Byte-Reihenfolge der Plattform ab). Und in C++ ists immer
noch verboten.
Nop schrieb:> Daß Software von Hardwarefirmen nicht unbedingt der Hit ist, kann ja nun> keinen verwundern.
Dass sich Weltkonzerne wie ST keine kompetenten Informatiker leisten
können wundert mich doch etwas.
Nop schrieb:> Da, wo es im Code nicht zu vermeiden> ist, muß man striktes Aliasing im Build abschalten.
An welchen Stellen ist es denn wirklich unvermeidbar? Mir fällt keine
ein außer Register-Zugriffen, und das fällt glaube ich nicht unter
Strict Aliasing...
Nop schrieb:> Du nutzt direkt oder> indirekt übrigens jeden Tag Code, bei dem das so ist - alles, was mit> Linux gebaut wurde nämlich.
Die Code-Qualität des Linux Kernels ist ohnehin... kaum in Worte zu
fassen?
Jörg W. schrieb:> Kennst du IAR wirklich?
Ok, mit IAR war nur einfach ein proprietärer geraten. Hier bspw.
http://en.cppreference.com/w/cpp/compiler_support sieht man bei den
proprietären ganz viel rot...
Dr. Sommer schrieb:> Jörg W. schrieb:>> Kennst du IAR wirklich?> Ok, mit IAR war nur einfach ein proprietärer geraten. Hier bspw.> http://en.cppreference.com/w/cpp/compiler_support sieht man bei den> proprietären ganz viel rot...
Da ist IAR nicht dabei.
Allerdings kann ich zu neueren C++-Standards da auch nicht mehr viel
sagen; ist zu lange her, dass ich ihn mal in den Fingern hatte.
Dr. Sommer schrieb:> Der ist zwar erlaubt, aber das Ergebnis ist dennoch undefiniert
Nein, ist es nicht.
> (hängt bspw. von der Byte-Reihenfolge der Plattform ab).
Das ist implementation defined, nicht undefined. Undefined hieße
beispielsweise, daß der Compiler das komplett wegoptimieren könnte -
inklusive dem ganzen Rest des Programms.
Ich hab schon type punning benutzt, wenn ich structs hatte, die aus 4
Bytes bestanden, die man aber mit einer Union auf uint32_t alle zusammen
nicht nur nullen kann, sondern auch kopieren und vergleichen. Wo
innerhalb des uint32_t welches Byte landet, ist dafür egal.
> Und in C++ ists immer noch verboten.
Das schon.
> Dass sich Weltkonzerne wie ST keine kompetenten Informatiker leisten> können wundert mich doch etwas.
Dürfte mit der Firmenkultur zu tun haben. Wenn man sich als
Hardwarefirma versteht, dann gilt Software eher so als Dreingabe. Daß
man wesentlich mehr Hardware verkaufen kann, wenn man sie den
potentiellen Kunden mundgerecht vorlegt, ist eine Erkenntnis, die den
Firmen immer noch neu ist.
> An welchen Stellen ist es denn wirklich unvermeidbar? Mir fällt keine> ein außer Register-Zugriffen, und das fällt glaube ich nicht unter> Strict Aliasing...
Beispielsweise, wenn man in C etwas memcpy-artiges programmieren will,
was schneller als byteweises Kopieren geht.
Bei Pascal ist es eine der Kritiken, daß zwar Funktionen mit variabler
Argumentzahl vorkommen, man selber aber keine definieren kann. Dieselbe
Kritik muß sich dann C an dieser Stelle auch gefallen lassen.
> Die Code-Qualität des Linux Kernels ist ohnehin... kaum in Worte zu> fassen?
Der Linuxkernel ist einfach nur sehr systemnah. Mal so vermutet, wo ich
das plausibel fände:
Wenn man beispielsweise einen Datenblob von einem Treiber bekommt, den
man interpretieren oder auch modifizieren will, dann möchte man kein
memcpy machen. Dann würde die Sache nämlich drastisch langsamer, falls
der Compiler gerade mal nicht fähig ist, das memcpy wegzupotimieren.
Etwa im Beispiel des Netzwerkstacks hängt ja das Format bestimmter
Pakete überhaupt erst von einem Paket-Identifier ab. Da ein struct
drüberzucasten und ggf. die relevanten Felder endianess-mäßig mit den
host/network-Macros zu behandeln, ist da wohl der Weg der Wahl.
Nop schrieb:> Dr. Sommer schrieb:>>> Der ist zwar erlaubt, aber das Ergebnis ist dennoch undefiniert>> Nein, ist es nicht.>>> (hängt bspw. von der Byte-Reihenfolge der Plattform ab).>> Das ist implementation defined, nicht undefined. Undefined hieße> beispielsweise, daß der Compiler das komplett wegoptimieren könnte -> inklusive dem ganzen Rest des Programms.>> Ich hab schon type punning benutzt, wenn ich structs hatte, die aus 4> Bytes bestanden, die man aber mit einer Union auf uint32_t alle zusammen> nicht nur nullen kann, sondern auch kopieren und vergleichen. Wo> innerhalb des uint32_t welches Byte landet, ist dafür egal.
Das UB entsteht durch das Lesen des nicht-aktiven members der union.
Das IB entsteht durch die endianness.
Beides lässt sich aber lösen.
Nop schrieb:> Das ist implementation defined, nicht undefined.
Achja, richtig. Was ich eigentlich sagen wollte ist, dass man sich hier
oft gewundert wird, warum so etwas nicht immer tut was man will:
1
voidtest(void){
2
uint32_ta=0xAABBCCDD;
3
charb=((char*)a)[2];
4
assert(b==0xBB);
5
}
Der cast nach "char*" und Dereferenzierung ist ja sogar erlaubt, aber
das Ergebnis ist dennoch nicht was man haben wollte, weil keiner sich
die Mühe macht dem Standard zu folgen.
Nop schrieb:> Beispielsweise, wenn man in C etwas memcpy-artiges programmieren will,> was schneller als byteweises Kopieren geht.
memcpy sollte bei guten Compilern auch nicht Byteweise, sondern i.A.
effizient sein. Das ist dann aber Teil der Plattform (Compiler+C
Library) und kann in der Tat nicht korrekt in C implementiert werden
(außer man schaltet Strict Aliasing ab, was ja dann nicht
Standard-Konform ist).
Nop schrieb:> Dieselbe> Kritik muß sich dann C an dieser Stelle auch gefallen lassen.
C++ kann's!
Nop schrieb:> Dann würde die Sache nämlich drastisch langsamer, falls> der Compiler gerade mal nicht fähig ist, das memcpy wegzupotimieren.
Dafür muss man dann aber das strict Aliasing abschalten, was wiederum
eine Menge Optimierungen verhindert. Man könnte in solchen Fällen auch
korrekt mit Bit-Operationen arbeiten, aber das ist, insb. in C, viel
Tipparbeit.
Wilhelm M. schrieb:> Das UB entsteht durch das Lesen des nicht-aktiven members der union.
In C99 nicht. Natürlich geht das nur, wenn wir hier von gleichen Größen
reden. Etwa einen 4-Byte-float schreiben und einen drüberliegenden
uint32_t lesen geht.
Aber wenn man einen uint8_t schreibt und dann den uint32_t liest, steht
logischerweise nicht fest, was denn in den anderen drei Bytes des
uint32_t ist.
Dr. Sommer schrieb:> uint32_t a = 0xAABBCCDD;> char b = ((char*) a) [2];
Meintest Du "&a"?
> das Ergebnis ist dennoch nicht was man haben wollte
Kommt drauf an, vielleicht wollte man ja einen Endianess-Test schreiben.
Nop schrieb:> Meintest Du "&a"?
Äh ja, natürlich.
Nop schrieb:> Kommt drauf an, vielleicht wollte man ja einen Endianess-Test schreiben.
... den man in korrektem C grundsätzlich nicht braucht, denn wenn man
Daten-Konvertierungen nur über Bitoperationen durchführt, wird das vom
Compiler automatisch korrekt gemacht! Aber wenn man schon bei
Nicht-Standard-Code ist, kann man auch _BYTE_ORDER_ o.ä. nutzen...
Nop schrieb:> Wilhelm M. schrieb:>>> Das UB entsteht durch das Lesen des nicht-aktiven members der union.>> In C99 nicht. Natürlich geht das nur, wenn wir hier von gleichen Größen> reden. Etwa einen 4-Byte-float schreiben und einen drüberliegenden> uint32_t lesen geht.
Es bezog sich ja auf C++.
Ab C99 ist das explizit erlaubt.
In C++ (schon immer) explizit verboten wegen UB (Ctor/dtor-Prolematik).
Dr. Sommer schrieb:> Nop schrieb:>> Meintest Du "&a"?> Äh ja, natürlich.>> Nop schrieb:>> Kommt drauf an, vielleicht wollte man ja einen Endianess-Test schreiben.> ... den man in korrektem C grundsätzlich nicht braucht, denn wenn man> Daten-Konvertierungen nur über Bitoperationen durchführt, wird das vom> Compiler automatisch korrekt gemacht! Aber wenn man schon bei> Nicht-Standard-Code ist, kann man auch _BYTE_ORDER_ o.ä. nutzen...
Oder std::endian
Dr. Sommer schrieb:> Dafür muss man dann aber das strict Aliasing abschalten, was wiederum> eine Menge Optimierungen verhindert.
Ja sicher, genau das tut man beim Build des Kernels ja auch. Jedenfalls
seit strict aliasing auf einmal Default des GCC wurde, ich glaube bei
4.9 oder so. Ich entsinne mich, daß Torvalds sich über diese
Default-Änderung ziemlich aufgeregt hat.
Andererseits muß man auch konkret nachmessen, ob strict aliasing
überhaupt Vorteile bringt. Bei dem Code, den ich bisher hatte, war da
gar nichts meßbar. Deswegen schalte ich es jedenfalls zum Release
einfach ab. Selbst in Benchmarks geht's da um kaum mehr als 1-2% oder so
(IIRC).
Selbst bei heftig numerischem Code bringt es wenig, weil das Aliasing
kompatibler Datentypen (z.B. die ganzen doubles in Matrizen und
Vektoren) immer noch da ist, und das kriegt man dann mit "restrict" in
den Griff - welches aber auch bei abgeschaltetem strict aliasing geht.
Dr. Sommer schrieb:>> Kommt drauf an, vielleicht wollte man ja einen Endianess-Test schreiben.> ... den man in korrektem C grundsätzlich nicht braucht
Datentausch mit anderen Systemen?
> Daten-Konvertierungen nur über Bitoperationen durchführt
Um das zu machen, muß man aber vorher schon die eigene Endianess wissen?
Nop schrieb:> Datentausch mit anderen Systemen?Nop schrieb:> Um das zu machen, muß man aber vorher schon die eigene Endianess wissen?
Eben nicht, das ist ja der Witz. Angenommen, wir wollen einen Little
Endian 4-Byte vorzeichenlosen Integer aus einer Datei einlesen:
1
uint32_tconvert(FILE*f){
2
unsignedchardata[4];
3
if(fread(data,1,4,f)!=4)return0;
4
return((uint32_t)data[0])
5
|(((uint32_t)data[1])<<8)
6
|(((uint32_t)data[2])<<16)
7
|(((uint32_t)data[3])<<24);
8
}
Dann wird hier der Integer in der Reihenfolge der Host-Plattform
zurückgegeben - automatisch korrekt BE/LE/Whatever. Für diesen Code muss
man die eigene Reihenfolge überhaupt nicht wissen. Der Compiler weiß
schon, ob "<<" im Speicher nach "oben" oder "unten" shiftet (d.h. ob
höherwertige Bits "oben" oder "unten" gespeichert werden). Dieser Code
wird von Compilern natürlich auch optimiert, also wenn kein
Byte-Tauschen nötig ist weil die Reihenfolge passt, wird da auch nix
gemacht. Und das alles ohne undefiniertes/implementation defined
Behaviour oder Abschalten von Strict Aliasing usw.
Dr. Sommer schrieb:> Dann wird hier der Integer in der Reihenfolge der Host-Plattform> zurückgegeben - automatisch korrekt BE/LE/Whatever.
Ooops. Mir fällt gerade auf, daß ich das EXAKT so auch schon
implementiert habe. Bei der Ausgabe auf der anderen Seite
dementsprechend auch, so daß das Format der gespeicherten Daten auch da
nicht von der Endianess der speichernden Partei abhing. :-)
> Und das alles ohne undefiniertes/implementation defined> Behaviour oder Abschalten von Strict Aliasing usw.
Wird halt nochmal anders, wenn Du IP-Pakete hast, die je nach
Format-Byte im Header einen ganz unterschiedlichen folgenden Aufbau
haben können. Daß man da mit Pointercasting arbeitet, kann ich
nachvollziehen. Ansonsten (also mit memcpy) würde man riskieren, daß bei
sonstigen Code-Änderungen oder Compiler-Updates als Seiteneffekt das
Wegoptimieren nicht mehr klappt. Was entsprechend ätzend zu debuggen
wäre.
Nop schrieb:> Wird halt nochmal anders, wenn Du IP-Pakete hast, die je nach> Format-Byte im Header einen ganz unterschiedlichen folgenden Aufbau> haben können.
Hm, warum? Man baut ein paar Fallunterscheidungen ein - je nach
Format-Byte konvertiert man den Payload halt anders und speichert das
Ergebnis in ein jeweils anderes struct. Die kann man sogar per union
"übereinander" speichern um Speicher zu sparen (nicht zum
Konvertieren!).
Nop schrieb:> Daß man da mit Pointercasting arbeitet, kann ich> nachvollziehen.
Der einzige wirkliche Grund dafür ist, dass Konvertieren über Bitshifts
viel Tipparbeit ist.
Nop schrieb:> Ansonsten (also mit memcpy) würde man riskieren, daß bei> sonstigen Code-Änderungen oder Compiler-Updates als Seiteneffekt das> Wegoptimieren nicht mehr klappt. Was entsprechend ätzend zu debuggen> wäre.
Aber memcpy ist doch eh nicht zum konvertieren geeignet
(Byte-Reihenfolge usw.). Und ich debugge lieber ein Performance-Problem
als kurioses Fehlverhalten bei Compiler-Update...
Dr. Sommer schrieb:> Format-Byte konvertiert man den Payload halt anders und speichert das> Ergebnis in ein jeweils anderes struct.
Eben letzteres wäre Kopieren, und das will man ja vermeiden.
> Und ich debugge lieber ein Performance-Problem> als kurioses Fehlverhalten bei Compiler-Update...
Wenn man strict-aliasing abschaltet, hat man bei einem Compiler-Update
kein Fehlverhalten. Nur als das per Default eingeführt wurde, wird man
das sicherlich gehabt haben - wenn man dann auch noch die Releasenotes
nicht gelesen hat.
Nop schrieb:> Eben letzteres wäre Kopieren, und das will man ja vermeiden.
Ich verstehe dein Problem nicht. Ob man jetzt per Fallunterscheidung auf
unterschiedliche Member einer union die sich in einem umgecasteten
struct befindet zugreift, oder per Fallunterscheidung die Bytes
unterschiedlich konvertiert, macht jetzt keinen großen Unterschied.
Nop schrieb:> Wenn man strict-aliasing abschaltet, hat man bei einem Compiler-Update> kein Fehlverhalten.
Es sei denn das Verhalten des Compilers ändert sich nochmal irgendwie,
worauf man sich ja nicht verlassen kann, weil Code ohne strict aliasing
vom Standard nicht abgedeckt ist.
schön, das solche C Konversationen grundsätzlich kontrovers sind..der
Themenstarter ist dadurch nicht ein Stück weiter....
Also
Pascal
Python
Java
welche Alternativen gibt es noch?
Der Quatsch mit den Standard von Pascal kann man sich auch sparen.+Der
Standard ist Delphi/Freepascal
Und ja, es gibt kleinste Unterschiede zu Mikroe oder AVRco Pascal,
genauso wie es bei C verschiedende Varianten gibt als auch bei
Python..als spart man sich den Zirkus an Diskussion und sollte
vielleicht mal wieder zum Thema Zurück
Jemand der in Cöfter arbeitet hat mit den kleinen Unterschieden der
Versionen genauso wenig Probleme wie jemand der in PAscal oder Python
schreibt.
Schlussendlich Programmiert man ja nur mit z.B: Freepascal und Mikroe
Pascal.
Das ist dann kein Drama..genauso wie andere in C mit gcc und VC arbeiten
und da auch mit Unterschiefen leben müssen.
Schlussendlich kommt man mit allen Sprachen ans Ziel, weshalb solceh
Diskussionen müßig sind
Tina schrieb:> Schlussendlich kommt man mit allen Sprachen ans Ziel, weshalb solceh> Diskussionen müßig sind
Na dann ist ja gut, wenn die Sprachauswahl derart irrelevant ist.
Komisch, dass es trotzdem so viele verschiedene gibt.
A. K. schrieb:> Ich bin konkret weder mit> Delphi noch sonst einem halbwegs aktuellen Pascal näher vertraut
Ja, das merkt man deutlich.
Ich will da aber nicht weiter drauf herumreiten, weil sonst alle, die
nur C und sonst nix kennen, mir "Missionieren" vorwerfen. Vorsorglich
verweise ich dazu auf Adenauer.
Ansonsten scheinen wir beim Thema "StLib des Grauens" und einschlägiger
anderer Hersteller-Libs und -IDe's etc. ähnlicher nsicht zu sein. Meine
kennst du ja: Texteditor, Totalcommander als IDE, Batchdatei als Make
all" und die eigentliche Toolchain, bei ARM eben Keil. Hab mich einmal
bei der Lernbetty mit dem Gcc herumgeärgert, geht zwar, aber wenn ich
nicht muß, nehme ich den Gcc auch nicht.
W.S.
owe....und genau an diesem Punkt merkt man was für Leute hier ihre
Argumente vortragen..viel Spaß noch....
Nur Kindergarten hier..er hat kaka gesagt...lol
Ich glaub das ist ein neure Weltrekord!
led_flasher läßt 2 LEDs blinken und fragt einen Taster ab.
Mit nur 60 kByte Flash und 34 kByte SRAM eine super Leistung ;->
Small Is Beautiful schrieb:> Mit nur 60 kByte Flash und 34 kByte SRAM eine super Leistung ;->
wenn Du schlanke Programme haben willst, musst Du mit dem zfp Profil
compilieren ...
W.S. schrieb:> Ich will da aber nicht weiter drauf herumreiten,
Schade. Denn von ihm werde ich sicherlich keine Antwort darauf erhalten:
A. K. schrieb:> weshalb ich deren Konzepte zur Kennzeichnung oder Vermeidung> nebenläufigen Zugriffs nicht kenne. Genau die würden mich ja> interessieren.
Markus F. schrieb:> wenn Du schlanke Programme haben willst, musst Du mit dem zfp Profil> compilieren ...
Wenn ich "zfp-stm32f4" verwende, bekomm ich:
"Ada.Interrupts" is not a predefined library unit"
Also entweder schlanke Programme oder Interrupts?
W.S. schrieb:> Hab mich einmal bei der Lernbetty mit dem Gcc herumgeärgert
Abgesehen davon, daß die Syntax des Inline-Assemblers eine Frage der
Gewohnheit ist, und daß das Aufsetzen des Linkerfiles nicht ganz trivial
ist, was für Probleme gab es da?

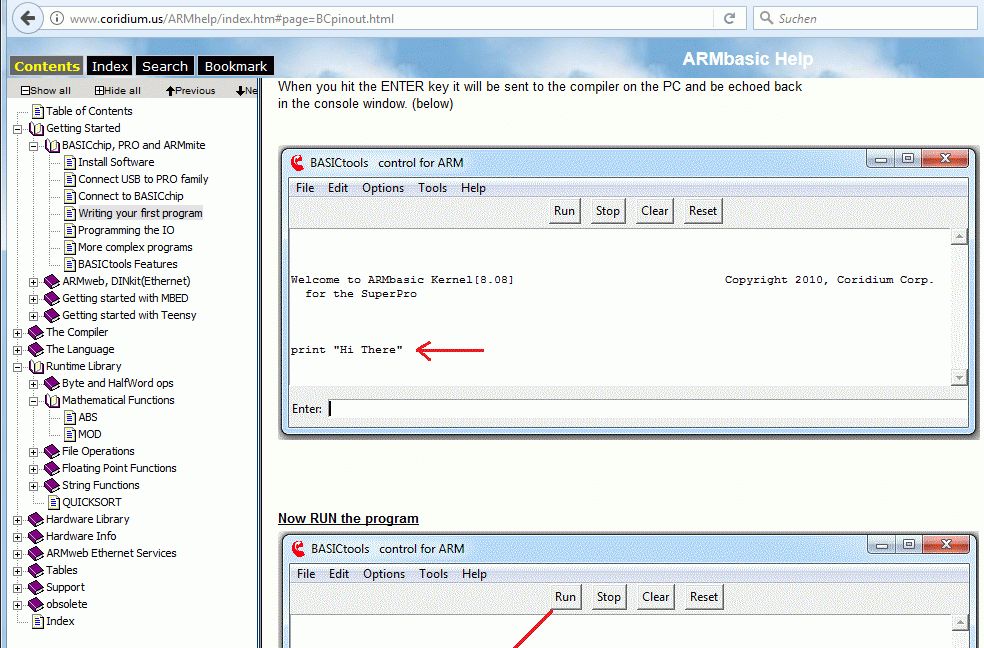
{kind=link}