Es gibt einen freien C Compiler der retargetable ist: LCC Mit dem Ding habe ich mich vor Jahren intensivst auseinandergesetzt. Jemand hat eine CPU in VHDL designed, den X32 Softcore: http://manualzz.com/doc/23529703/x32-programmers-manual---x32-32-bit-softcore-home-page Es ist ein 32 Bit Core, von denen gibt es ja einige ... Das Besondere am X32 ist aber, dass er den Bytestream des LCC direkt verarbeiten kann!! Mit anderen Worten, der LCC Compiler erzeugt einen Zwischencode. Der Code ist Maschinen unabhängig und Stack basiert. Die Backends machen daraus Assemblercode für das Zielsystem. Der X32 exisitiert und ist voll funktionabel. Es gibt eine komplette Toolchain samt C-Libs. Es gibt den LCC, einen X32 Assembler und einen X32 Linker. Der X32 läuft auf einem Spartan 3 (XC3S250) Zudem gibt es auch noch einen Simulator für den PC. Der ist quasi eine VM, die auch direkt den X32 Bytecode interpretiert. ======================= Ich träume davon den X32 auf einen Spartan 6 zu portieren. Oder Alternativ auf einen Artix 7. Das Problem ist, ich bin ein totaler Anfänger. Der VHDL Code ist für einen XC3S250 gemacht. Ich frage mich, ob der Spartan 6 lx9 ausreicht? Der Artix 7 sollte in jedem Fall gehen. ---------------------- Ehrlich gesagt, habe ich keine Ahnung wie das Teil funktioniert. Der VHDL Code des X32 überfordert mich einfach. In meiner naiver Denkweise stelle ich mir vor, dass es so gehen könnte: - IO anpassen auf das Ziel Board - SDRAM Code anpassen auf das SDRAM des Zielboard - die UART Schnittstelle austauschen Allerding ist mir nicht klar, wie ich die Einzelnen Module testen kann. ----------------------- Ist das (für mich) irgendwie machbar? Oder wäre es gescheiter sich ein passendes Spartan 3 Board anzulachen?
Was in einen XC3S250 passt, könnte mit viel Geschick auch in einen Spartan 6 oder Artix reinzufummeln sein :-) Im Ernst, die Frage ist weniger, ob das überhaupt geht, sondern mehr, ob es Sinn macht und unter welchen Umständen: FPGAs sollten hauptsächlich etwas anderes tun, als SoftCores zu hosten, daher machen diese an der Chipfläche in der Regel nicht viel aus, wodurch die ineffiziente Nutzung derselben nicht ins Gewicht fällt. Ich würde die am Ehesten als add für einen Artix sehen, denn der ist gross, modern und kosteneffktiv - der Spartan 6 läuft ja aus. Allerdings gibt es im Artix-Bereich ja den Zynq, der gleich richtig Performance hat und für sehr einfache Aufgaben, die man in einem FPGA mal nebenbei CPU-mässig (kompakter Code und langsam) erledigt, braucht man keinen 32-Bit-Prozessor. Spartan 7 wäre gfs ein Thema. Generell: Was man bei den Anwendungen, die Ich im Markt so sehe, ab und an brauchen könnte wäre ein guter, effektiver DSP-Core, den man gerade so reinwerfen könnte und der schon allemöglichen Filterungen parametrisierbar intus hätte und bei dem man sich die Funktion kurz in C drauf programmiert - aber für den Bereich gibt es auch externe Chips in Massen, zu unerreichbar geringen Kosten. Die bringen dann sogar oft schon Funktionen mit, die man ad hoc im FPGA gemacht hätte. Wir hatten da ja vor Kurzem den Fall zum Thema Audio-DSP und S/PDIF-Transceiver. Will heißen: Softcores im FPGA haben nur wenige Anwendungensbereiche. Was möchtest Du denn damit bauen?
Jürgen S. schrieb: > Im Ernst, die Frage ist weniger, ob das überhaupt geht, sondern mehr, ob > es Sinn macht und unter welchen Umständen: Naja Sinn ... Mir ist vollkommen klar dass es keinen Sinn macht. Wie die allermeisten Elktronik Basteleien die ich so mache ... > Ich würde die am Ehesten als add für einen Artix sehen, denn der ist > gross, modern und kosteneffktiv - der Spartan 6 läuft ja aus. Allerdings > gibt es im Artix-Bereich ja den Zynq, der gleich richtig Performance hat > und für sehr einfache Aufgaben, die man in einem FPGA mal nebenbei > CPU-mässig (kompakter Code und langsam) erledigt, braucht man keinen > 32-Bit-Prozessor. Spartan 7 wäre gfs ein Thema. Ja der Zync, den finde ich genial. Bei Controller vermisse ich sehr oft Logik am Ausgang. Deshalb verwende ich manchmal AVR mit CPLD. Aber ein FPGA ist natürlich ganz was anderes! Wo man gleich ganze UART, SPI, I2C abbilden kann! > parametrisierbar intus hätte und bei dem man sich die Funktion kurz in C > drauf programmiert - aber für den Bereich gibt es auch externe Chips in > Massen, zu unerreichbar geringen Kosten. Die bringen dann sogar oft > schon Funktionen mit, die man ad hoc im FPGA gemacht hätte. Der Clou ist, der Bytecode braucht keine große Toolchain. Ein X32 Controller könnte sich den selbst kompilieren. Dh. man könnte quasi C Sourcetext ausführen, der aus einem File, einer Datenbank oder aus dem Web kommt. > Will heißen: Softcores im FPGA haben nur wenige Anwendungensbereiche. Richtig, aber manchmal wäre ein Softcore schöner als eine state machine ... Und viel mächtiger. > Was möchtest Du denn damit bauen? Nichts bestimmtes. Ist wohl mehr so eine Art Nostalgie Anfall. Ich habe immer schon von einer Bytecode CPU geträumt. Und als ich das Projekt im Internet fand, da sind wohl die Gäule mit mir durchgegangen. Aber immerhin hat es mich inspiriert mich mit FPGA zu beschäftigen. ====== Interessantes Detail am Rande für die Spieler unter uns ... Derselbe Bytecode den der X32 ausführt, wird in Quake 3 Arena verwendet. Da laufen zig VM die Bytecode ausführen um das Spiel zu animieren.
Thomas W. schrieb: > Es ist ein 32 Bit Core, von denen gibt es ja einige ... > Das Besondere am X32 ist aber, dass er den Bytestream des LCC direkt > verarbeiten kann!! Den LCC hab ich mir für eine andere Stackmaschinen-Arch mal angesehen, aber beim Versuch, damit produktiv zu werden, gabs so'n paar Hindernisse. Auch der X32 sah vor ein paar Jahren recht nach verlassener Hütte aus.. Aber falls du viel Lust&Zeit zum Spielen hast: In der ZPU-Community geht ein bisschen was. Falls du es hinkriegst, den LCC-Bytecode in ZPU-kompatible Opcodes zu mappen (gerne auch mit Emulations-Tricks), wäre dir einige Aufmerksamkeit sicher. Wie sieht's denn beim X32 mit den FPGA-Resourcen aus? Thomas W. schrieb: > Allerding ist mir nicht klar, wie ich die Einzelnen Module testen kann. Simulieren... Ich könnte dir einen Docker-Container zur Verfügung stellen, die eine virtuelle Umgebung für den Papilio mit besagtem XC3S250 beinhaltet, da könntest du die X32 einbauen (virtueller UART ist z.B. vorhanden). Müsstest dich nur auf non-commercial/opensource einlassen. Der Port auf Spartan6/Artix hat dann zwar einige Tücken beim RAM, aber da kriegste hier sicher Hilfe.
Martin S. schrieb: > Aber falls du viel Lust&Zeit zum Spielen hast: In der ZPU-Community geht > ein bisschen was. Falls du es hinkriegst, den LCC-Bytecode in > ZPU-kompatible Opcodes zu mappen (gerne auch mit Emulations-Tricks), > wäre dir einige Aufmerksamkeit sicher. Ah, ZPU kannte ich bisher nicht. LCC kann man sehr einfach an jede CPU anpassen. Darum schreiben die auch was von "retargetable C Compiler". Ich denke das wäre keine große Sache. Die Frage ist mehr, ob es dann noch effektiv und flink ist. Der X32 kann fast alle Bytecode Kommandos in einem Takt ausführen. Wenn noch der Speicher 32 Bit breit wäre, und die Refresh Bremse durch caching ausgetrickst ... > > Wie sieht's denn beim X32 mit den FPGA-Resourcen aus? > Der Autor schreibt, der XC3S250 ist "leicht ausreichend". Was immer das in Prozent bedeuten mag ... > Thomas W. schrieb: >> Allerding ist mir nicht klar, wie ich die Einzelnen Module testen kann. > > Simulieren... > Ich könnte dir einen Docker-Container zur Verfügung stellen, die eine > virtuelle Umgebung für den Papilio mit besagtem XC3S250 beinhaltet, da > könntest du die X32 einbauen (virtueller UART ist z.B. vorhanden). > Müsstest dich nur auf non-commercial/opensource einlassen. Der Port auf > Spartan6/Artix hat dann zwar einige Tücken beim RAM, aber da kriegste > hier sicher Hilfe. Klingt cool! Ich bin Fan von non-commercial/opensource ... Mal davon abgesehen kann ich mir kaum vorstellen, dass dies den Kommerz interessiert. Man müsste mal prüfen ob es mit der X32 Lizenz vereinbar ist. Damit habe ich mich noch gar nicht beschäftigt.
chris schrieb: >>Ich bin Fan von non-commercial/opensource ... > Als Contributor oder als Nutzer? In jedem Fall. Warum sollte man das Rad immer wieder neu erfinden
Thomas W. schrieb: > Ich denke das wäre keine große Sache. > > Die Frage ist mehr, ob es dann noch effektiv und flink ist. > Der X32 kann fast alle Bytecode Kommandos in einem Takt ausführen. > Wenn noch der Speicher 32 Bit breit wäre, und die Refresh Bremse durch > caching ausgetrickst ... Müsste mir das Opcode-Set auch nochma anschauen und mit den ZPU-Primitiven vergleichen (rund 15 opcodes/Klassen). Der Witz an der ZPU ist, dass man viel mit Emulation erschlagen kann, d.h. es gibt eine Klasse Opcodes, die intern Mikrocode ausführen. Damit kann man mit wenig Aufwand Emulations-Layer basteln, z.B. auch für gewisse DSP-Befehle (wo das Thema schon aufkam). Eventuell reicht es so, nur einen Assembler für das Bytecode-Set zu machen. Das interne RAM wäre hier 2x16 bit, nur aligned-Zugriff. Fraglich obs für die meisten einfachen Apps überhaupt Cache braucht, die ZPU-Codedichte wird bisher vom msp430 geschlagen, X32 wäre mal interessant. Thomas W. schrieb: > Mal davon abgesehen kann ich mir kaum vorstellen, dass dies den Kommerz > interessiert. Den Kommerz interessiert es leider insofern, dass sie sich des öfteren munter bedienen, aber sich nicht an die Opensource-Lizenzen halten (müssen). Die (L)GPL ist leider bei Hardware nicht wasserdicht, und kollidiert mit vielen anderen Lizenzen. Aber das ist ein anderes Thema.
bastler schrieb: > Strubi wirbt schon wieder für ZPU und Papilio ... Naja, die ZPU ist auch ziemlich genial. Mir gefällt sie sehr: - Stack based - sehr flink - simpel - genügsamer Umgang mit FPGA Rossourcen - GCC toolchain vorhanden Da ja eine GCC Toolchain existiert, gibt es wohl keinen Bedarf für den LCC. ===== Der Papilio hat mir auch sehr gefallen. Allerdings finde ich da den Mimas 2 besser vom Preis Leistungsverhältnis.
>Strubi wirbt schon wieder für ZPU und Papilio ...
Macht nix. Ich finde beides gut. Wobei der Papillo ein wenig sein Ziel
verfehlt:
Es soll Arduino-artig sein, das klappt aber nicht wirklich, weil die
Xilinx-IDE, die man trotzdem braucht, einfach zu kompliziert bleibt.

bastler schrieb: > Strubi wirbt schon wieder für ZPU und Papilio ... Wäre viel schlimmer, wenn ich für die bo8h 'werben' würde... P.S. Es ist keine Werbung, sondern nur ein Hinweis auf eine populäre Platform
Thomas W. schrieb: > Da ja eine GCC Toolchain existiert, gibt es wohl keinen Bedarf für den > LCC. Naja, der GCC-Port ist recht alt (2.95), und es gibt einige Nervigkeiten, die man ändern könnte, aber bei dem GCC Moloch nicht unbedingt tun will.. Der LCC wäre da schon interessant, und wenn das mit der X32 gut läuft, warum sollte es das nicht mit der ZPU. Ausserdem wird bald Winter und die Abende werden lang..
Angehängte Dateien:

chris schrieb: > Mimas 2 hat ein Audio-Jack ... interessant ... Das ALINX AX-309 hat sogar einen kleinen Lautsprecher mit drauf.
Angehängte Dateien:
-

ALINX_AX309_-_Audio.jpg
31 KB

Na gut, ok, sie schreiben "Buzzer", Leo sagt das bedeutet Summer/Hupe/Schnarre ... Ist wohl kein Lautsprecher. Aber es gibt eine Audio Zusatzkarte ...
Thomas W. schrieb: > Ist wohl kein Lautsprecher. Nö, aber 'Beethoven' hat bereits vor ~25J gezeigt, das da auch verständlicher und lauter Text raus kommen kann.:) Is und bleibt aber ne Quarktröte.
Thomas W. schrieb: > Ah, ZPU kannte ich bisher nicht. Thomas W. schrieb: > Naja, die ZPU ist auch ziemlich genial. > > Mir gefällt sie sehr: > - Stack based > - sehr flink > - simpel > - genügsamer Umgang mit FPGA Rossourcen > - GCC toolchain vorhanden Passt irgendwie nicht zusammen. Merkwürdig.
bastler schrieb: > Thomas W. schrieb: >> Ah, ZPU kannte ich bisher nicht. > > Thomas W. schrieb: >> Naja, die ZPU ist auch ziemlich genial. >> >> Mir gefällt sie sehr: >> - Stack based >> - sehr flink >> - simpel >> - genügsamer Umgang mit FPGA Rossourcen >> - GCC toolchain vorhanden > > Passt irgendwie nicht zusammen. Merkwürdig. Doch passt schon. vorher kannte ich sie nicht. Jetzt habe ich mich inzwischen informiert.
Thomas W. schrieb: > Jetzt habe ich mich inzwischen informiert. Das ging aber schnell. Weniger als eine Stunde, um zu so einem Urteil zu kommen.
>Mimas 2 hat ein Audio-Jack ... interessant ...
Wobei die beiden Kanäle des Audio-Anschlusses direkt mit den Digitalpins
über zwei Widerstände verbunden sind. Das gibt "Punktabzug". Nicht mal
Entkoppelkondensatoren und ein einfacher RC-TP sind vorhanden.
Martin S. schrieb: > Das interne RAM wäre hier 2x16 bit, nur aligned-Zugriff. Fraglich obs > für die meisten einfachen Apps überhaupt Cache braucht, die > ZPU-Codedichte wird bisher vom msp430 geschlagen, X32 wäre mal Ich habe früher öfters mit NIOS gearbeitet und auch mal meinen VA-Synth probehalber implementiert. http://www.96khz.org/doc/concept%20sound%20synthesizer%20NIOS.htm Man sieht, dass man im Vergleich zum Original-DSP trotz damals aktueller FPGA-Power nicht so sehr viel weiter kommt - von wegen "Hardwarebeschleunigung" und so. Die ursprüngliche Version stammt von einem TMS320 aus 1996 und das NIOS ist wiederum von 2006. Heute sind wir nochmals 10 Jahre weiter, aber geändert hat sich an der gesamten Geschichte eigentlich nichts: Die FPGAs sind schneller, größer und billiger, aber die DSPs werden genauso schneller und billiger, d.h. die FPGAs werden nicht so viel schneller billiger und effektiver, als dass sie denen viel abgraben könnten. Wenn schon FPGA dann müssen da ganz andere Strukturen rein und die spezifischen Vorteile der parallelen Elemente und pipelines genutzt werden. Der dicke fette Punkt bei all diesen Signalprozessoren in FPGAs - sei es Audio, Video oder Radar (=virtuelles Audio/Video) - ist der, dass aus mehreren Ebenen die Werte der Samples aus Kanälen, Zeilen und Zeiten bis zu einem gewissen Grad gleichzeitig sichtbar sind und ohne irgendwelche Speicherzugriffe bearbeitet werden können. Das ist der entscheidende Aspekt. Damit kriegt man den Datentakt auf den Systemtakt und die gesamte Bandbreite hängt an den parallelen Speicher- und Rechenaktionen. Ich denke z.B. dass man diese Applikation in einen FPGA packen könnte: Beitrag "EV-Board mit Texas Instruments DSP für Abschlussarbeit"
Jürgen S. schrieb: > Man sieht, dass man im Vergleich zum Original-DSP trotz damals aktueller > FPGA-Power nicht so sehr viel weiter kommt - von wegen > "Hardwarebeschleunigung" und so Der NIOS ist auch nicht wirklich eine DSP-Architektur... Wir sind auch beim X32, das ist ne ganz andere Geschichte. Wenn man mit den Stackmaschinen DSP machen will, muss man sie mit einer Co-DSP-Pipe aufbohren. Da kommt natürlich ein anderer Befehlssatz ins Spiel. Ich wollte nur oben damit sagen: Es ist gerade mit den Stack-Maschinen sehr elegant und kompakt aufzulösen und viel weniger Gefuddel als die ARM oder MIPS-DSP ASE-Hacks. Beim DSP muss man für die optimale Ausnutzung der parallelisierenden Pipes nach wie vor Assembler schreiben und die Pipeline recht gut kennen, im FPGA ist das eher an den Zweck anpassbar. Es geht mir vor allem um die Anwenderfreundlichkeit, da ist es nett, wenn der Grossteil des Codes von einem brauchbaren C-Compiler abgedeckt wird. Wenn das auf dem FPGA auch geht, und noch komplett simulierbar, ist man in manchen Anwendungen inzwischen schneller bei einer robusten Lösung als mit einem klassischen DSP.
Martin S. schrieb: > Naja, der GCC-Port ist recht alt (2.95), und es gibt einige > Nervigkeiten, die man ändern könnte, aber bei dem GCC Moloch nicht > unbedingt tun will.. Nu mach's mal nicht älter, als es Not tut :-)
1 | $ zpu-elf-gcc --version |
2 | zpu-elf-gcc (GCC) 3.4.2 |
3 | Copyright (C) 2004 Free Software Foundation, Inc. |
4 | This is free software; see the source for copying conditions. There is NO |
5 | warranty; not even for ... |
Aber ja, einen frischen Compiler dürfte es schon mal geben. Leider ist Compilerbau so gar nicht mein Thema... Duke
Duke Scarring schrieb: > Nu mach's mal nicht älter, als es Not tut :-) Woops, stimmt. Da hab ich wohl was verwechselt.. Duke Scarring schrieb: > Aber ja, einen frischen Compiler dürfte es schon mal geben. Leider ist > Compilerbau so gar nicht mein Thema... Ehrlich gesagt würde ich lieber auf LLVM umsteigen. Aber auch der handelt Stackmaschinen suboptimal, deswegen wäre ich schon auf ein LCC-Beispiel gespannt. Thomas, hast du zum LCC ein paar Statistiken, was Code-Generierung/Optimierungen angeht?
Martin S. schrieb: > Ehrlich gesagt würde ich lieber auf LLVM umsteigen. Aber auch der > handelt Stackmaschinen suboptimal, deswegen wäre ich schon auf ein > LCC-Beispiel gespannt. Thomas, hast du zum LCC ein paar Statistiken, was > Code-Generierung/Optimierungen angeht? Macht euch da keine großen Hoffnungen. Der LCC ist quasi ein Uni Projekt. Ein Zwerg gegen den Riesen GCC. Optimierungen gibt es aber nur sehr rudimentär. Die Stärken des LCC sind woanders. - er kompiliert rasend schnell - er ist extrem klein - sehr einfach portierbar - die Struktur ist sehr einfach und verständlich Die Einfachheit des LCC macht es mir möglich, ihn zu vollständig zu verstehen. Damit kann ich damit herum spielen. Beim GCC wäre ich dazu nicht in der Lage. ----------- Der Vorteil am X32 wäre nur die Kompaktheit des Code. Man teilt ihm EINEN Speicherblock zu, und hat eine geschlossene VM. Der Speicherblock ist sehr einfach zu kontrollieren. Der Code liegt immer ganz unten, die Daten darauf, der Stack wächst von oben nach unten. Es ist simpel und sicher. Daher kann man auch zig VM simulieren. ----------- Ich verwende den X32 Simulator gerne in Apps um Usercode auszuführen. Benutzer geben C Code ein. Der wird instant kompiliert und dann bei Bedarf ausgeführt. Je nach Umgebung gibt es eine angepasste VM. Mit speziellen "System Funktionen" für den User. ----------- Für den X32 FPGA Core sehe ich keine spezielle Anwendung. Da gibt es einfach schon mehrere bessere Lösungen. Aber es ist für mich das ideale Hobby Projekt, mich mit der FPGA Welt auseinanderzustzen.
Thomas W. schrieb: > Für den X32 FPGA Core sehe ich keine spezielle Anwendung. > Da gibt es einfach schon mehrere bessere Lösungen. Naja, eine Anwendung hast du ja schon implizit genannt, diese Art Stack-Maschinen performen sehr gut in Safety-Anwendungen, wo es auf Geschwindigkeit weniger ankommt als auf robuste Ausführung. Das ist auf dem FPGA als 'gehärtete Umgebung' besonders interessant. Als ich damals den LCC angeschaut habe, war die Codedichte ganz ok, nur am Backend bin ich gescheitert. Es gibt ein echt gutes Paper ("A compiler for stack machines" von Mark Shannon), nur habe ich das dort erwähnte 'lcc-s' Backend nie in freier Wildbahn gesehen.
Martin S. schrieb: > Es gibt ein echt gutes Paper ("A compiler > for stack machines" von Mark Shannon), nur habe ich das dort erwähnte > 'lcc-s' Backend nie in freier Wildbahn gesehen. "A compiler for stack machines" sieht interessnt aus, danke für den Hinweis. Werde mir das heute Abend durchlesen ...
Martin S. schrieb: > Es gibt ein echt gutes Paper ("A compiler > for stack machines" von Mark Shannon), nur habe ich das dort erwähnte > 'lcc-s' Backend nie in freier Wildbahn gesehen. So genial, das Script schaut aus wie eine frühe Arbeit für den X32. Sogar die Namen für die Assembler memnonics sind ident! Das beschriebene LCC Backend existiert. Samt Assmebler, Linker und Simulator. Es ist quasi die X32 Toolchain. Für mich sieht es so aus, wie wenn dies die Überlegungen sind, die später zur Entwicklung des X32 Core geführt haben. Gefällt mir, sehr spannend.
Im ersten Schritt möchte ich den X32 implementieren.
Aber mir geht es auch um Optimierungen des LCC Backend für den X32.
Bei meiner VM, die ja den X32 simuliert, habe ich schon einige
Schwachpunkte erkannt und verbessert.
- durch zusätzliche Befehle für Sequenzen die sehr häufig generiert
werden
- durch Optimierung des Stack selbst, quasi ein Mini Cache Konzept
-----
Zusätzliche Befehle:
zb. die Zuweisung erfolgt bei der LCC stack machine immer so
y = {}
INDIR Y
...
ASSGN
Der Befehl ASSGN speichert den Top-Stack-Wert in die Adresse die als
nächster am Stack liegt. Da bietet sich ein Befehl an, der direkt den
Wert am Stack speichert: STORE
Genauso beim laden von Werten aus lokalen und parameter Variable: LOAD
Man spart nicht nur Instruktionen sondern auch teure Stack Opeartionen.
Und vorallem betrifft dies die Masse des Code.
------
Optimierung des Stack:
Das einlagern und auslagern des Stack im externen Speicher ist "teuer"
Und rechnen kann ich sowieso nur innerhalb von register die für die ALU
erreichbar sind.
Die Top Stack Werte sind X, Y, Z
Diese Werte gibt es auch als virtuelle Register mit einem "dirty flag".
Es werden, wenn möglich die register dem Stack vorgezogen.
Also dann, wenn die Werte ident sind.
Auf den wirklichen Stack wird erst zugegriffen, wenn es notwendig wird.
Das spart enorm an Stack Operationen.
Beim FPGA würde ich sogar noch weiter gehen.
Durch die parallele Verarbeitung bietet sich an, dass ein Modul das
transparent macht.
Also wenn der SDRAM gerade nichts zu tun hat, werden X, Y und Z
automatisch ein bzw. ausgelagert
Also Quasi ein Mini Cache.
Die hier kennst du dann wohl schon: http://wwwtmp.st.ewi.tudelft.nl/gemund/Publications/sijmen_ra.pdf Thomas W. schrieb: > Optimierung des Stack: > > Das einlagern und auslagern des Stack im externen Speicher ist "teuer" > Und rechnen kann ich sowieso nur innerhalb von register die für die ALU > erreichbar sind. > > Die Top Stack Werte sind X, Y, Z > > Diese Werte gibt es auch als virtuelle Register mit einem "dirty flag". > Es werden, wenn möglich die register dem Stack vorgezogen. > Also dann, wenn die Werte ident sind. Witzig, das ist in etwa das Thema, was beim GCC/LLVM eklig wurde und bei der ZPU mit eher als unsauberer Hack (memregs) implementiert ist. Die ist auch keine reine 'Forth'-Stil Stackmaschine, da Direktzugriff innerhalb eines Fensters auf den Stack möglich ist. Wenn man da ein Zwischending zwischen SPARC und ZPU ansetzt, liegt einiges an Optimierung drin - wenn der Compiler es denn so "intus" hätte. Thomas W. schrieb: > Also wenn der SDRAM gerade nichts zu tun hat, werden X, Y und Z > automatisch ein bzw. ausgelagert Diese Register sind bei meinem 'Experiment' einfach Teil des Stacks, aber im Distributed memory für den schnellen Direktzugriff (bypass), der eigentliche Stack ist im BRAM. Das prinzipiell nervige ist halt, dass sich dieses Fenster immer verschiebt, sobald eine Funktion den SP für lokale Variablen verändert, müssen die Shadow-Register ins RAM geflusht werden, das geht zwar mit parallel laufender Cache-Logik, aber bringt ein paar andere Probleme mit sich. Wenn ich die Features des LCC und des Peephole-Optimizers verstanden habe, steckt da bzgl. Stack-Maschinen deutlich mehr drin als im klassischen Registeransatz des GCC. Das X32-Backend gibt ja relativ direkt den insn-tree in die Bytecode-Mnemonics aus. Für das Aufbohren auf den hybriden Ansatz (Register/Stack-Mischmasch) würde mich allerdings schon so ein oder anderes *.md-File interessieren, wie für die im Paper zitierten UFO oder UTSA, aber ich hatte da damals nix im Netz gefunden (müsste man ev. bei den Unis nachbohren). Es war dann schlussendlich fürs Testen und Verifizieren einfacher, einfach ein ZPU-kompatibles Frontend in der HW als Instruction-Decoder zu implementieren.
Martin S. schrieb: > Das X32-Backend gibt ja relativ direkt den insn-tree in die > Bytecode-Mnemonics aus. Für das Aufbohren auf den hybriden Ansatz > (Register/Stack-Mischmasch) würde mich allerdings schon so ein oder > anderes *.md-File interessieren, wie für die im Paper zitierten UFO oder > UTSA, aber ich hatte da damals nix im Netz gefunden (müsste man ev. bei > den Unis nachbohren). Es war dann schlussendlich fürs Testen und > Verifizieren einfacher, einfach ein ZPU-kompatibles Frontend in der HW > als Instruction-Decoder zu implementieren. Der X32 Backend verwendet kein .MD File und daher auch keinen LBURG. Der LCC wird ja mit einem BYTECODE backend geliefert. Der gibt den tree quasi 1:1 aus als Textfile. Und das ist genau der Assembler befehlssatz des X32. Das ist ja der Clou, es braucht kein Backend, deswegen ist jede neue LCC version direkt einsetzbar. In Wahrheit wurde jedoch das Bytecode Backend leicht modifiziert. Weil der Compiler keinen Unterschied macht, ob return Werte einer Funktion verwendet werden oder nicht. Und das hat den Stack verschmutzt, da der return Wert am Stack abgelegt wird und quasi bereinigt werden sollte. ==== Der LBURG ist ja ein simples tool. Es ist sinnvoll um varianten von Registerbefehle auf C Source Ebene aufzublasen. Das sieht man sehr gut an dem X86 Backend ...
Martin S. schrieb: > Die hier kennst du dann wohl schon: > > http://wwwtmp.st.ewi.tudelft.nl/gemund/Publications/sijmen_ra.pdf Ja genau, dieses PDF hat mich animiert mich mit FPGA zu beschäftigen.
Obwohl, nee, dieses Dokument kannte ich noch nicht. Da ist mit keinem Wort der X32 erwähnt! Mir scheint, da hatte das Kind noch keinen namen ...
Moin, > Das ist ja der Clou, es braucht kein Backend, deswegen ist jede neue LCC > version direkt einsetzbar. > Das ist schon klar, das meinte ich mit "direkter Ausgabe". > In Wahrheit wurde jedoch das Bytecode Backend leicht modifiziert. > Weil der Compiler keinen Unterschied macht, ob return Werte einer > Funktion verwendet werden oder nicht. > Und das hat den Stack verschmutzt, da der return Wert am Stack abgelegt > wird und quasi bereinigt werden sollte. > Falls du den "bug" meinst:
1 | int gna(x) { ... }
|
2 | |
3 | while(1) gna(random()) |
wo der Stack nicht korrigiert wurde (sowas sollte eigentlich im Compiler gepatcht werden, nicht im backend). > Der LBURG ist ja ein simples tool. > Es ist sinnvoll um varianten von Registerbefehle auf C Source Ebene > aufzublasen. > Das sieht man sehr gut an dem X86 Backend ... Es wäre vermutlich für Stack-Reordering recht brauchbar, um besagte Registerfenster (auch andersorten "sliding register windows") zu optimieren. Aber so weit kam ich nicht. Der LCC flog eigentlich damals in die Ecke wegen ganz pragmatischer Gründe: - Offenbar kein Support für was wie __attribute__((packed)) struct { .. } - Anonyme Unions gingen nicht - Designierte Initializer (struct s {int gna; ..} g = { .gna = ... }) auch nicht Weisst du, ob sich da was geändert hat?
Martin S. schrieb: > Weisst du, ob sich da was geändert hat? Es gab immer wieder Änderungen im GIT des LCC. Aber seit drei Jahren keine mehr. https://github.com/drh/lcc Was ja andererseits auch ein gutes Zeichen ist. Der LCC scheint nahezu frei von Bugs zu sein ...
Hi Thomas, wie ist der momentane Stand? Wollte mich mal wieder damit beschäftigen. Auf die Schnelle habe ich das x32 Backend nicht mehr gefunden, insbes. die erwähnten x32-tools, die originale Webseite scheint nicht mehr vorhanden. Gibt's da ein git Repo o.ä.? Hast du den X32 inzwischen mal in die Simulation gesteckt?
Martin S. schrieb: > Hi Thomas, > > wie ist der momentane Stand? Wollte mich mal wieder damit beschäftigen. > Auf die Schnelle habe ich das x32 Backend nicht mehr gefunden, insbes. > die erwähnten x32-tools, die originale Webseite scheint nicht mehr > vorhanden. Gibt's da ein git Repo o.ä.? > Hast du den X32 inzwischen mal in die Simulation gesteckt? Oh mei, ich stecke noch in den Basics. Beschäftige mich mit SDRAM, DDR, FSM und ganz simple CPU Kerne. Inzwischen habe ich mich relativ intensiv mit Verilog beschäftigt. Aber ich fange jetzt an mit VHDL. Der X32 ist ja in VHDL implementiert. ======= Und ich habe jetzt weitere Hardware angeschafft. Ein Spartan 3 Board von Waveshare, und ein Artix 7 von Digilent. Das Spartan 3 Board hat 500K logiccells und ist mein erster Kandidat. ======= Ja die ursprüngliche Seite ist weg. Schon sehr lange... Interessanterweise gibt es aber einen Port der sogar ein GIT hat. Der Port läuft auf einem moderneren Board, aber auch ein Spartan 3. Die haben den X32 eingesetzt für eine Quadrocopter Steuerung, wenn ich das richtig verstehe ... https://github.com/erwinvaneyk/quadcopter
Meine anfängliche FPGA Euphorie hat sich etwas gedämpft. Ich muss zugeben, dass ich mich da sehr sehr schwer tue. Es ist so, dass meine Denkweise sehr stark geprägt ist durch Software Programmierung. Immer wieder wundere ich mich, dass Dinge im FPGA funktionieren bzw. nicht funktionieren. Da muss ich sehr viel aufholen und da braucht leider immens Zeit. So viele Dinge, für die ich bisher noch nie einen Gedanken verschwendet habe, sind plötzlich ein Problem. Für euch bestimmt nur ein Lacher, aber für mich hunderte kleine Lernaufgaben, die ich bewältgen und verinnerlichen muss. Schliesslich möchte ich es nicht nur zum laufen bringen. In erster linie will ich es verstehen.
Der neuere Port vom X32 ist vom April 2010. Es läuft auf einem Trenz TE300 Board. Man hat sich insbesondere Gedanken gemacht um die Speicherverwaltung. Das scheint eines der größten Nadelöhre des X32 zu sein. link auf das PDF: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.719.5194&rep=rep1&type=pdf Ich hänge es auch hier dran. Wer weiß wie lange diese Quellen noch existieren ...
Den VHDL Sourcecode des X32 für das Trenz board TE300 findest du hier: http://www.st.ewi.tudelft.nl/~koen/quad-rotor/2015/Resources/ Direkter Link auf die Software: http://www.st.ewi.tudelft.nl/~koen/quad-rotor/2015/Resources/in4073TE300.tar.gz
Hi Thomas, Thomas W. schrieb: > Ich muss zugeben, dass ich mich da sehr sehr schwer tue. > Es ist so, dass meine Denkweise sehr stark geprägt ist durch Software > Programmierung. > Auch wenn's hier öfters anders breitgetreten wird: muss kein Nachteil sein. > > So viele Dinge, für die ich bisher noch nie einen Gedanken verschwendet > habe, sind plötzlich ein Problem. > > Für euch bestimmt nur ein Lacher, aber für mich hunderte kleine > Lernaufgaben, die ich bewältgen und verinnerlichen muss. Da müssen so ziemlich alle durch. Du kannst allerdings bisschen nachhelfen. Falls noch nicht auf einen Simulator festgelegt wärst: Mit GHDL erfährt man grosse Lerneffekte, ich nutze das Dingen auch öfters zum 'Reverse-Engineering' von Fremd-HDL. Da GHDL recht streng und korrekt (!) die VHDL Standards umsetzt, gilt quasi: Was in GHDL sauber läuft, tut auch fast immer in der Synthese. Damit vermeidest du schon mal viel Aerger. Wenn du dich nur auf die Funktion der 'black box' fokussieren willst, kannst du auch einfach Komponenten zusammenstecken und mit GHDL gucken, was passiert. Ansonsten: Danke für die Links, vielleicht steck ich das Ding mal über die Feiertage in den "Container".
Angehängte Dateien:
-

x32.png
29 KB
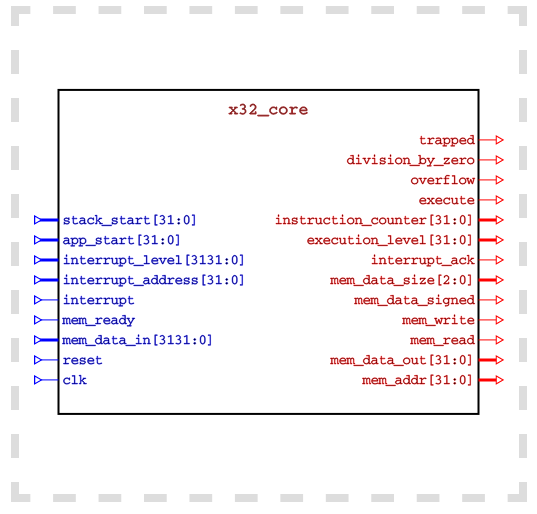
Moin, habe mal probehalber den X32-Source in die Mühle gesteckt, und es geht schon los, der grosse Showstopper ist die Verwendung von std_logic_arith und Konsorten für den ALU-Teil. Das schreit nach Problemen beim Portieren auf andere Architekturen. Mäh. Ansonsten sind keine grossbösen Konstrukte drin, der 'DRC' geht durch, liesse sich also auf numeric_std umschreiben, aber: den Regresstest dafür müsste man wohl selber stricken, da fand ich nix zu. Das ist mE die grösste Arbeit... Was nicht so erfreute, war die riesige State machine im 'controller'-Modul, scheint's hat der X32 keine Pipeline und spendiert eine Menge Zyklen. Habe dann noch probeweise mit dem LCC etwas Testcode versucht zu kompilieren, das klappt auch soweit bis auf die beschriebenen C99-Konstrukte oben. Was mir nicht klar beim LCC ist, wie man im GCC Code gezielt plaziert (linker script), das müsste man vermutlich auch ein eigenes Linker-Backend machen. Code-Dichte: Verglichen mit der ZPU scheint knapp etwa Faktor 2 rauszuschauen. Ist aber auch weiter nicht verwunderlich (16 bit opcodes bei X32 vs 8 bei ZPU). Das ROM-Binary sieht recht gut kompressibel aus (erster Test bei unter 50%) Soll dich jetzt aber nicht bremsen, weiterzumachen. Der X32 ist nach wie vor ein pfiffiges proof-of-concept und insbes. die LCC-Seite ist immer noch hochinteressant, der GCC ist einfach zu schwerfällig zu handhaben.
Martin S. schrieb: > C99-Konstrukte oben. Was mir nicht klar beim LCC ist, wie man im GCC > Code gezielt plaziert (linker script), das müsste man vermutlich auch > ein eigenes Linker-Backend machen. Das gibt es bereits fix fertig Ursprünglich wurde der Bytecode aus dem LCC übersetzt in X32 Assembler (minimale Änderungen). Der Assembler erzeugt Object Dateien. Der Linker macht aus Object entweder Libs oder Bin Code. Der X32 und auch die VM können direkt das BIN File verarbeiten == Ich habe die VM schon länger im Einsatz. Der Zwischenschritt vom Bytecode zu X32 Assembler habe ich integriert in ein eigenes LCC Backend. Und ich habe einige neue Assembler Befehle eingeführt, die das ganze sehr optimieren in Bezug auf Code Größe UND Ausführunggeschwindigkeit. Diese neuen befehle müsste ich im X32 Core nachführen, oder eben den LCC zurück bauen. > > Code-Dichte: Verglichen mit der ZPU scheint knapp etwa Faktor 2 > rauszuschauen. Ist aber auch weiter nicht verwunderlich (16 bit opcodes > bei X32 vs 8 bei ZPU). Das ROM-Binary sieht recht gut kompressibel aus > (erster Test bei unter 50%) Ah gut zu wissen. Das größte Problem ist wohl, dass Instruktionen IMMER 32 bit breit sind. Das kostet natürlich für einfache Dinge ... > > Soll dich jetzt aber nicht bremsen, weiterzumachen. Der X32 ist nach wie > vor ein pfiffiges proof-of-concept und insbes. die LCC-Seite ist immer > noch hochinteressant, der GCC ist einfach zu schwerfällig zu handhaben. Ich mache auf jeden Fall weiter. Es ist mein Lern Objekt um bei den FPGA ein bisschen rein zu schnuppern. Als Lösung für Projekte sehe ich eher den Weg in Richtung Zynq. Eine Kombi aus ARM und Xilinx ist einfach klasse, finde ich.
Die neuen X32 Assembler Befehle ergaben sich aus Analysen von der Übersetzung gängiger C Programme in X32 Assembler. bestimmte Kombis von X32 Instruktionen kommen besoonders häufig vor. Zb. - laden von Integer aus lokalen oder register Variable. - Zuweisung von Integer in lokalen oder register Variable. - Inkrement/Dekrement in Zeiger Ziel - Laden von kleinen Konstanten Es lohnt sich einfach, aus mehreren X32 Instruktionen eine neue zu machen. - weniger Stackbewegung - weniger Instruktionen - optimierte Ausführung
Hi Thomas, > > Das gibt es bereits fix fertig Wo? In den x32-tools finde ich nix, was ein LD-Script liest.. >> >> Code-Dichte: Verglichen mit der ZPU scheint knapp etwa Faktor 2 >> rauszuschauen. Ist aber auch weiter nicht verwunderlich (16 bit opcodes >> bei X32 vs 8 bei ZPU). Das ROM-Binary sieht recht gut kompressibel aus >> (erster Test bei unter 50%) > > Ah gut zu wissen. > > Das größte Problem ist wohl, dass Instruktionen IMMER 32 bit breit sind. > Das kostet natürlich für einfache Dinge ... Ich lese hier INSTR_SIZE := 16... (decoder.vhd) > Als Lösung für Projekte sehe ich eher den Weg in Richtung Zynq. > Eine Kombi aus ARM und Xilinx ist einfach klasse, finde ich. Mit fertigem und funktionierendem (!) Linux BSP, wenn man's braucht, full ack. Ansonsten ist das Ding leider für viele Applikationen zu dick und verbraucht Unmengen Strom. Es gibt schon eine Menge Anwendungen, wo ein Softcore in der Form unabdingbar ist und ein ARM schon als 'verboten' gilt.
Martin S. schrieb: > Ich lese hier INSTR_SIZE := 16... (decoder.vhd) Hmmm, den VHDL Code habe ich mir nie genau angesehen. Weil ich das eh noch nicht wirklich vollinhaltlich verstehen kann. Aber Simulator, der die Basis ist für die VM, der fetched immer 32 bit. Vermutlich weil das Argument der Instruction quasi fast immer dabei ist. > >> Als Lösung für Projekte sehe ich eher den Weg in Richtung Zynq. >> Eine Kombi aus ARM und Xilinx ist einfach klasse, finde ich. > > Mit fertigem und funktionierendem (!) Linux BSP, wenn man's braucht, > full ack. > Ansonsten ist das Ding leider für viele Applikationen zu dick und > verbraucht Unmengen Strom. > Es gibt schon eine Menge Anwendungen, wo ein Softcore in der Form > unabdingbar ist und ein ARM schon als 'verboten' gilt. Stromverbrauch?? Ich hatte bisher nur mit STM32 zu tun. Einfache ARM Kerne wie der F407. Die sind absolut spitze im Stromverbrauch. Vorallem die Typen die speziell dafür ausgelegt sind. Der ARM kann sich so schlafen legen, dass er fast nichts mehr braucht. Es gibt da Boards die jahrelang mit einer Knopfzelle auskommen. Ich denke das ist wohl nur eine Frage des Software Design. Aber ja, prinzipiell sehe ich schon den Vorteil eines X32 Softcore. Den könnte man ja auch schlafen legen. Den gröten Vorteil sehe ich beim X32, dass der Code dynamisch geladen werden kann. Weil es einfach nur ein simples File ist. Der "Loader" ist eine simple Byte-Kopier-Maschine. Ja man kann den Code sogar dynamisch generieren. Aus C Source oder X32 Source code ...
Thomas W. schrieb: > Aber Simulator, der die Basis ist für die VM, der fetched immer 32 bit. > Vermutlich weil das Argument der Instruction quasi fast immer dabei ist. Das wird's erklären. Ich hab nur nach "imm*" ge-grept und fand nix passendes. Thomas W. schrieb: > Die sind absolut spitze im Stromverbrauch. > Vorallem die Typen die speziell dafür ausgelegt sind. Schon. Aber das ist bei Xilinx ganz anderes Silizium :-) Die neueren Cortexe sind schon recht gut, aber wer MSP430 gewohnt ist... Thomas W. schrieb: > Aber ja, prinzipiell sehe ich schon den Vorteil eines X32 Softcore. > Den könnte man ja auch schlafen legen. Auf dem FPGA holst du nicht so viel raus. Du kannst bei einigen Architekturen die Clocks manipulieren/deaktivieren, aber die Aufweck-Logik ist nicht so ganz trivial. Thomas W. schrieb: > Den gröten Vorteil sehe ich beim X32, dass der Code dynamisch geladen > werden kann. Das geht doch genauso mit allen anderen CPUs.. Oder meinst du, dass der X32 native compiliert? Den Hintergedanken hatte ich nämlich, obwohl möglicherweise sinnfrei, aber hochnerdy: Auf dem 'Systemprozessor' den Code für den Coprozessor compilieren. D.h. C-Snippet ans System schicken und binnen 20 Sekunden eine Coroutine haben. Aber dafür bräuchte es Support für gezielte Allozierung gewisser Codesegmente.
Martin S. schrieb: > Das geht doch genauso mit allen anderen CPUs.. > Oder meinst du, dass der X32 native compiliert? > Den Hintergedanken hatte ich nämlich, obwohl möglicherweise sinnfrei, > aber hochnerdy: Auf dem 'Systemprozessor' den Code für den Coprozessor > compilieren. D.h. C-Snippet ans System schicken und binnen 20 Sekunden > eine Coroutine haben. Aber dafür bräuchte es Support für gezielte > Allozierung gewisser Codesegmente. Ja voll nerdy. Der LCC übersetzt sich sogar selbst. Ich habe den LCC als X32 code. Du kannst tatsächlich C Source Text in die VM laden (oder eingeben, oder von der SD Karte lesen, oder aus dem Internet, oder per UART ...), er übersetzt es und führt es aus. Quasi ein C Interpreter ... Martin S. schrieb: > Aber dafür bräuchte es Support für gezielte > Allozierung gewisser Codesegmente. Oder eben ganz einfach gehalten. Der X32 hat ja nur wenige Register. So kann man mehrere Threads in getrennte Adressräume laden und zügig umschalten. Theoretisch könnte man auch im FPGA mehrere banks an Register führen, die man einfach umschaltet. Dh. der Core arbeitet an verschiedenen Tasks und das umschalten kostet keine Zeit. Dasselbe gilt für Interrupts. Einfach eine eigene Register Bank pro Interrupt. Davon können andere CPU's nur träumen ...
> > Der LCC übersetzt sich sogar selbst. > Ich habe den LCC als X32 code. > > Du kannst tatsächlich C Source Text in die VM laden (oder eingeben, oder > von der SD Karte lesen, oder aus dem Internet, oder per UART ...), er > übersetzt es und führt es aus. > > Quasi ein C Interpreter ... > Jetzt wird's ja richtig interessant :-) Mit wieviel RAM (insbesondere .data und .bss) wäre man da dabei, kannst Du dazu was sagen? Code (.text) ist nicht so das Thema, da man den gut auslagern kann. > > Der X32 hat ja nur wenige Register. > > So kann man mehrere Threads in getrennte Adressräume laden und zügig > umschalten. > > Theoretisch könnte man auch im FPGA mehrere banks an Register führen, > die man einfach umschaltet. Dh. der Core arbeitet an verschiedenen Tasks > und das umschalten kostet keine Zeit. Das geht bereits bei der ZPU sehr elegant, sofern man sich nicht mit dem 'memreg'-Hack ins Knie schiesst (das ist so ein Wermutstropfen an der GCC-ABI). > > Dasselbe gilt für Interrupts. > Einfach eine eigene Register Bank pro Interrupt. > Davon können andere CPU's nur träumen ... Naja. Schon mal (neben der ZPU) die SPARC angesehen? Neu ist das nicht, aber in der Tat ist wohl so, dass sich viele Entwickler mit dem Stackmaschinen-Konzept schwer tun (man hat's auch oft einfach so gelernt). Im hybriden Ansatz mit Direktzugriff auf TOS+n steckt aber schon ne Menge drin. Und richtig cool wird's dann, wenn du die Befehlssätze mit "inline"-Schmankerln aufbohrst. Da kann man trotz einer gewissen Schwäche bzgl. der 'wandernden Register' die klassischen Architekturen wie MIPS/RISC-V usw. alt aussehen lassen, zumindest für spezielle Zwecke. Bisschen was dazu wurde hier schon verraten: Beitrag ""Neue" CPU-Architektur-Aspekte (FPGA softcores)" So schalte ich z.B. einfach zwischen 'DSP'-opcodes und ZPU-Opcodes über ein Adressbit um, d.h. der DSP-Mikrocode liegt irgendwo ab 0x80000, bspw. Genau da wäre der LCC interessant, um die DSP-Applets zu generieren, aber deswegen muss der Code gezielt alloziert werden können, d.h. es gibt ein ".text"-Segment mit nativem Code, und sowas wie ".text.dsp" mit dem erweiterten Kram. Könntest du konkret zu dem Fall einen Hinweis liefern, wie das mit dem LCC "fix&fertig" funktioniert? Ich bin nicht fündig geworden..
Martin S. schrieb: > So schalte ich z.B. einfach zwischen 'DSP'-opcodes und ZPU-Opcodes über > ein Adressbit um, d.h. der DSP-Mikrocode liegt irgendwo ab 0x80000, > bspw. Mehrere CPU's, - umschalten, faszinierend. :-) Martin S. schrieb: > Genau da wäre der LCC interessant, um die DSP-Applets zu generieren, > aber deswegen muss der Code gezielt alloziert werden können, d.h. es > gibt ein ".text"-Segment mit nativem Code, und sowas wie ".text.dsp" mit > dem erweiterten Kram. Könntest du konkret zu dem Fall einen Hinweis > liefern, wie das mit dem LCC "fix&fertig" funktioniert? Ich bin nicht > fündig geworden.. Die Toolchain ist simpel. Es gibt eigentlich keine Segmente wie man es sonst kennt. Aber natürlich gibt es im objekt file noch Code, initialisierte Vars, nicht intialisierte Vars, der "Rest" ist stack. Die aktuelle Toolchain unterstützt keine Zieladress Management. Im executable file gibt es nur noch einen Block, der zwingend bei Adresse 0 beginnt. Der Block enthält code und initialisierte Vars. Die C Tolchain unterstützt auch eine schmale Variante von printf() und eine einfache Speicherverwaltung. Dabei muss natürlich die Zeichenausgabe als Systemcall zur verfügung stehen. Der FPGA könnte Register simulieren und die Ausgabe auf einen Soft-UART machen. Ich habe aber in der VM einfach eine System Funktion, die Parameter an nimmt. In der Systemfunktion implementiere ich spezifische Dinge der Zielhardware. ==== Der Loader in der VM bekommt als Parameter nur das execFile und die Speichergröße. - Das execFile wird ab Adresse null in den Speicher geladen. - Die Ausführung des Code beginnt an Adresse 0 - Adressen sind immer 32 bit breit (wie auch die integer) - Adressen sind immer gültig außer sie sind größer als die Speichergröße Variante 1: Wenn man den X32 Softcore im FPGA so designed, dass die Adressverwaltung einen Offset erlaubt, dann könnte man zig Instanzen von Code laufen lassen in einem gängigen SDRAM. Um Usercode zu starten, würde ich also einfach einen Systembefehl implementieren, der als Loader funktioniert. Dazu ein bisschen Code was das Threading steuert. Variante 2: Man modifiziert den Linker so, dass man den code für eine bestimmte Adresse hin übersetzt. Dann könnte man den in einem dafür angelegten Teil des Speicher laufen lassen. Mir gefällt variante 1 viel besser, weil der Code dann in einem separaten, geschützten Speicher läuft. Die Apps laufen dann alle voneinander unabhängig und können sich nicht gegenseitig stören.
Thomas W. schrieb: > > Mehrere CPU's, - umschalten, faszinierend. :-) > Vereinfacht ist es nur eine CPU mit einer Befehlssatzerweiterung, sprich 9. Bit. > > Die Toolchain ist simpel. > Es gibt eigentlich keine Segmente wie man es sonst kennt. Offenbar gibt es nur fix definierte CODE, DATA, usw. Ich fürchte, ich muss doch noch ne Weile bei ELF-Hacks bleiben. > > Mir gefällt variante 1 viel besser, weil der Code dann in einem > separaten, geschützten Speicher läuft. Die Apps laufen dann alle > voneinander unabhängig und können sich nicht gegenseitig stören. Dann bräuchtest du aber konsequenterweise 'hart' getrennte Stacks, das ist etwas verschwenderisch. Ausserdem sollen/müssen SW-Threads ja miteinander kommunizieren. Würde das in der HW nicht zu kompliziert machen. Wenn du wirklich eine harte Trennung brauchst, ganz pragmatisch: Neue CPU instanzieren. Wenn der Core kompakt ist, kostet dich 2x Core weniger als 1x Threading-Wollmilchsau. Die "von-Neumann"-Kompatibilität ist dann allerdings dahin, wenn sich die CPUs den Code teilen müssen. Damit wären wir wieder bei den Segmenten... Wenn du trotzdem eine gewisse Safety brauchst, kannst du immer noch pro Context einen einfachen Wächter (TLB und Stackfenster) konfigurieren, der ne Exception wirft, wenn wer was verbotenes macht.
Martin S. schrieb: > Dann bräuchtest du aber konsequenterweise 'hart' getrennte Stacks, das > ist etwas verschwenderisch. Ausserdem sollen/müssen SW-Threads ja > miteinander kommunizieren. Würde das in der HW nicht zu kompliziert > machen. Ja klar, jede App hat ihren separaten Adressraum. Verschwenderisch? Die meisten Apps kommen mit 128K locker durch. Und die kleinen SDRAM haben 128MB ... Und es ist ja dynamisch, nur die Apps die wirklich gerade laufen brauchen auch wirklich Speicher.
Thomas W. schrieb: > Verschwenderisch? Jeder separate Stack frisst dir im FPGA mindestens eine RAM-Primitive mit fixer Grösse auf, plus Logik. Das externe Code-Memory ist nicht so das Thema, das wirst du ja typischerweise vom SDRAM her schon mal cachen. Und den Stack/Register-Fenster willst du nicht im SDRAM haben...
Martin S. schrieb: > Thomas W. schrieb: >> Verschwenderisch? > > Jeder separate Stack frisst dir im FPGA mindestens eine RAM-Primitive > mit fixer Grösse auf, plus Logik. > > Das externe Code-Memory ist nicht so das Thema, das wirst du ja > typischerweise vom SDRAM her schon mal cachen. Und den > Stack/Register-Fenster willst du nicht im SDRAM haben... Du denkst da vermutlich schon etliche ebenen weiter wie ich ... Aber es wäre auch mit nur EINEM Stack kein Problem. Der Stack könnte sogar einen eigenen geschützten Bereich haben. Ich habe sogar mal angedacht, für den Stack ein 8MBit statisches RAM zu verwenden ... Das liegt sogar schon bei mir zuhause ... https://de.aliexpress.com/item/IS62WV51216BLL-SRAM-Board-Memory-Storage-Module-A-Development-Solution-for-SRAM-with-16-bit-Parallel-Interface/488753123.html?spm=a2g0s.9042311.0.0.D9cDkn
Wobei, wenn ich es mir richtig überlege, ... ... den statischen RAM blendet man einfach irgendwo im 32 Bit Adressraum ein!
Den Stack willst du auf jeden Fall im Block-RAM haben, eventuell mit impliziten Shadow-Registern im Distributed RAM, sonst geht dir Performance flöten. Es geht auf jeden Fall elegant mit einem Stack, Virtualisierungstricks bremsen nur aus. Du kannst einfach dafür sorgen, dass per Task nur der Zugriff auf ein gewisses Fenster erlaubt ist. Mal n Beispiel:
1 | .stackA 0x000087ff-0x00008600 : ... |
2 | .stackB 0x000085ff-0x00008400 : |
3 | .stackC 0x000083ff-0x00008200 : |
Von deinem Stackpointer maskierst du dann einfach die untersten 9 bit (0x1ff) und die oberen kommen aus einem KOntext-Register, an dem der 'user space' nicht drehen darf. Ist halt sehr billig und unflexibel, da fixe Fenstergrösse für jeden Task. Den SP kannst du aber auch separat überwachen, was eh Sinn macht, wenn dein Programm irgendwas rekursiv aufruft (potentieller Ueberlauf..) Thomas W. schrieb: > ... den statischen RAM blendet man einfach irgendwo im 32 Bit Adressraum > ein! So einfach wird es dann auch nicht, wenn ich nicht falsch liege, musst du ein asynchrones Bus-Interface stricken und allenfalls mit Wartezyklen arbeiten, beim X32 ev. wegen fehlender Pipeline nicht nötig. Hätte aber erst mal externes RAM aussen vor gelassen. Keep it simple...
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.