Hallo,
hat jemand Ahnung von vServern? Bei mir läuft ständig /var/log/kern.log
voll mit Dingen, die ich zum ersten Mal sehe. Alle paar Minuten kommen
neue kryptische Zeilen dazu. Wie gehe ich systematisch vor, um das
Problem zu finden?
1
Dec 30 13:40:59 myserver kernel: [4193690.744629] do_page_fault+0x22/0x30
Oliver V. schrieb:> vmstat sagt
Nix wesentliches, aber Du hast verdammt viel I/O (Lesen von Disk, bi).
Ein Buff von 0 sehe ich eigentlich nur in Out-of-memory Situationen,
weil da der Kernel alle Puffer frei gibt.
Der Webserver kann eventuell zuviele MySQL Verbindungen aufreissen, aber
da müsste man deutlich mehr über Deine Config wissen.
Jim M. schrieb:> Ein Buff von 0 sehe ich eigentlich nur in Out-of-memory Situationen,> weil da der Kernel alle Puffer frei gibt.
Genau das passiert hier ja auch. Der Kernel wirft Prozesse ab, weil
Speicher knapp. Da wär eine Prozessliste mit Speicherbelegung nützlich.
Das mit den bi ist mir auch schon aufgefallen. Das geht aber auch dann
nicht weg, auch wenn ich apache2, mysqld, spamassassin, dovecot, postfix
und amavis beende (das ist eigentlich auch alles, wofür ich den Server
brauche).
TestX schrieb:> ist das zufällig ein billigteil das nur 1gb MAX hat und wesentlich> weniger "garantierten" speicher und shared kernel ?
Sieht schwer danach aus. Zu wenig Server für zu viel Aufgaben.
Mir fällt auf, das du deutlich weniger swap space als Hauptspeicher
hast, was sehr ungünstig ist:
Oliver V. schrieb:> SwapTotal: 524288 kB> SwapFree: 510536 kB
swapTotal sollte mindestens die Grösse des installierten RAM erreichen.
Als Abhilfe würde ich mehr RAM und mehr swap space vorschlagen.
Ausserdem macht sich dovecot (und php-cgi) doch recht breit, es wäre
eine Überlegung wert, das mal ein wenig runterzustutzen.
Matthias S. schrieb:> Mir fällt auf, das du deutlich weniger swap space als Hauptspeicher> hast, was sehr ungünstig ist:
Hab ich bei Servern(!) eigentlich immer so. Die sollen arbeiten, nicht
swappen. Wenn ein Server bös auf den Swapspace geht, dann hat man zu
wenig RAM oder die Services gehen zu grosszügig damit um.
Stark swappende Services ergeben eigentlich nur Sinn, wenn sich das über
den Tag verschiebt. Also sowas wie Services A+B tagsüber und C+D nachts.
Hier gibts zu viel Services mit zu viel davon genutztem oder nutzbarem
Speicher. Beispielweise einen spamd mit maximal 5 Prozessen. Die
verabschieden sich zwar nach einer Weile - aber Gnade der Kiste, wenn
mal alle 5 zusammen kommen. Wenn nicht grad ein mittleres Unternehmen
mit versorgt wird, dann reicht eigentlich einer.
PS: Mein Heimserverlein mit 3GB RAM läuft völlig ohne Swapspace.
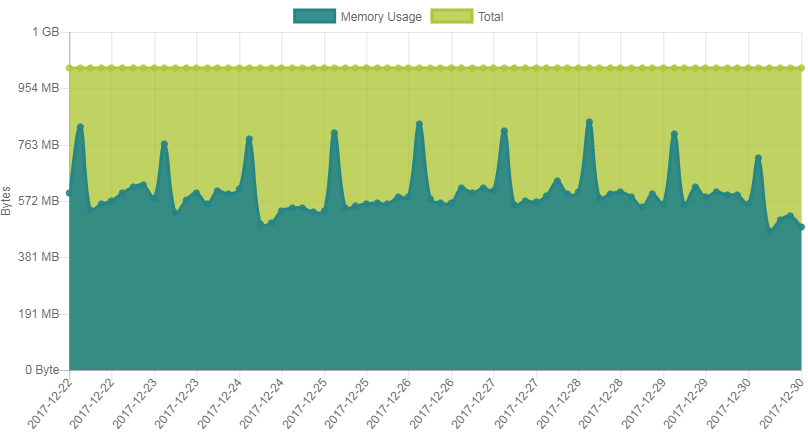
Das ist die RAM-Nutzung laut Verwaltungspanel meines Anbieters.
Ich kann jetzt keine Knappheit erkennen, wenn ich ehrlich bin. Ich
dachte auch immer, dass ein RAM-knappes Linux zuerst den Cache
verkleinert, swappt und erst dann meckert.
Die Peaks kommen vom täglichen Backup.
spamd habe ich jetzt mal auf 1 child limitiert. Danke für den Tipp. Bin
für mehr Tipps dankbar.
Die reale Speicherbelegung ist schon mit einem physischen Server
schwierig genug zu bewerten. Statistiken aus "ps" und dem Management
geben nur grobe Hinweise, erst recht bei grober Zeitauflösung.
Hier kommt hinzu, dass es sich hier um einen virtuellen Server handelt.
Manche Virtualisierungstechnik simuliert dabei eine formal streng
getrennte Maschine, andere hingegen nutzen einen gemeinsamen Kernel
(z.B. Virtuozzo). Das verkompliziert Speicheranalysen u.U. beträchtlich,
weil man sich da eigentlich wie in Platos Höhle vorkommt.
Aber das sind natürlich alles nur Ratespiele. Wenn das Problem auch
auftritt, wenn so circa überhaupt nichts läuft ...
Oliver V. schrieb:> auch wenn ich apache2, mysqld, spamassassin, dovecot, postfix> und amavis beende
... dann wirds komplizierter und vielleicht weiss der Anbieter des
Servers dazu beizutragen.
Such mal in den Logs die Zeilen der Art
Memory cgroup out of memory: Kill process ... (...)
raus. Also was immer wieder abgeschossen wird, ob sich ein Muster
zeigt. Das obige "node /usr/share" sagt mir nichts.
A. K. schrieb:> Die sollen arbeiten, nicht> swappen. Wenn ein Server bös auf den Swapspace geht, dann hat man zu> wenig RAM oder die Services gehen zu grosszügig damit um.
Der Meinung bin ich prinzipiell natürlich auch - nichts geht über
physischen RAM, wobei meine Linuxbox auch mit 1GB gut klarkommt, sie
aber auch nicht so viel zu tun hat (Apache, Samba, netatalk, CUPS, ein
wenig postgresql und irgendwelche anderen Dinge, die mir gerade
entfallen sind :-P). Aber wenns so knapp wird, sorgt swapspace
wenigstens dafür, das da nicht dauernd Kernel Exceptions kommen - die
sollten die grosse Ausnahme sein.
Oliver V. schrieb:> Das ist die RAM-Nutzung laut Verwaltungspanel meines Anbieters
Das ist natürlich gemittelt und in den Peaks könnten schon mal 100% drin
sein, die wir nicht sehen. Dein syslog sagt jedenfalls, das da immer
wieder zu wenig Speicher ist.
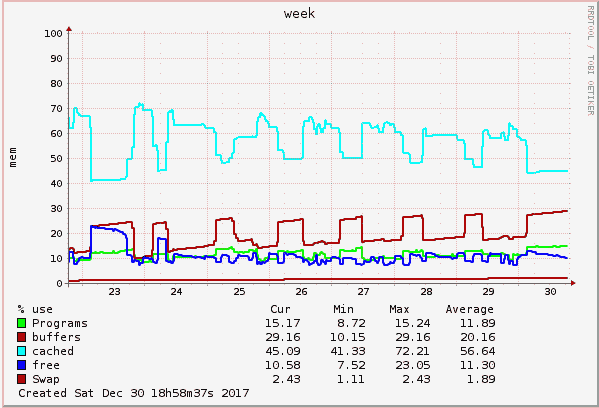
Anbei mal die Speichersituation meiner Box über die letzte Woche.
Kann man irgendwie rauskriegen, welcher Prozess da so viel Speicher
anfordert? Das müssen ja mit einem Schlag mehr als 300 MB sein, denn so
viel ist zur Zeit frei und das Log wird voller und voller. Alle paar
Minuten oder Sekunden ein Eintrag. Das Komische ist: Alles
funktioniert.....
Dec 30 17:25:25 myserver kernel: [4207155.917035] Memory cgroup out of memory: Kill process 5117 (node /usr/share) score 69 or sacrifice child
2
Dec 30 17:51:44 myserver kernel: [4208734.790055] Memory cgroup out of memory: Kill process 27331 (node /usr/share) score 50 or sacrifice child
3
Dec 30 17:51:46 myserver kernel: [4208737.021524] Memory cgroup out of memory: Kill process 31868 (mysqld) score 80 or sacrifice child
4
Dec 30 17:59:14 myserver kernel: [4209184.828698] Memory cgroup out of memory: Kill process 31878 (node /usr/share) score 45 or sacrifice child
5
Dec 30 17:59:17 myserver kernel: [4209188.700699] Memory cgroup out of memory: Kill process 13189 (mysqld) score 80 or sacrifice child
6
Dec 30 18:46:51 myserver kernel: [4212042.228739] Memory cgroup out of memory: Kill process 6715 (node /usr/share) score 66 or sacrifice child
7
Dec 30 18:51:55 myserver kernel: [4212346.525603] Memory cgroup out of memory: Kill process 20449 (node /usr/share) score 66 or sacrifice child
8
Dec 30 19:04:51 myserver kernel: [4213122.474568] Memory cgroup out of memory: Kill process 12130 (node /usr/share) score 67 or sacrifice child
9
Dec 30 19:23:32 myserver kernel: [4214243.424181] Memory cgroup out of memory: Kill process 11577 (node /usr/share) score 67 or sacrifice child
10
Dec 30 19:26:38 myserver kernel: [4214429.486930] Memory cgroup out of memory: Kill process 23878 (mysqld) score 79 or sacrifice child
11
Dec 30 19:32:02 myserver kernel: [4214753.218824] Memory cgroup out of memory: Kill process 23918 (node /usr/share) score 67 or sacrifice child
Also entweder mysqld oder /usr/share.
MySQL ist schon ziemlich eingedampft und mit dem MySQLTuner bearbeitet
worden. So viel braucht der nicht mehr.
Was /usr/share ist, keine Ahnung.
Derjenige der abgeschossen wird, muss nicht derjenige sein, der den
meisten Speicher hat oder will. Mir sind die Regeln dafür aber nicht
bekannt.
Beim MySQL sollte man es aber merken. Wer nutzt den? PHP? Dann könnte
dessen Log was dazu vermelden.
MySQL wird von PHP genutzt, ja, aber eher selten. Da läuft kein Forum
oder Shop oder sowas. Der Mailkram benutzt es, glaube ich, auch.
In den anderen Logs finde ich keine Probleme. Nicht einmal in dem von
MySQL!?
Was mich aber auch stutzig macht, ist der konstant hohe "load average"
von fast 10 auf dem Server. Manchmal sogar mehr.
Die Prozesse werden willkürlich raus geschossen, es muß nicht unbedingt
an Mysqld liegen, ich hatte mal beim VServer das Problem das der kmem zu
klein war gibt in etwa die gleichen Fehler wen der Server nicht komplett
abschmiert.
Schau mal mit:
cat /proc/user_beancounters
Gibt es eine Möglichkeit, herauszufinden, welcher Prozess diese hohen
io/bi-Werte verursacht, die vmstat anzeigt?
Ich glaube, dass diese beiden Symptome zusammen hängen.
> Dec 30 19:32:02 myserver kernel: [4214753.218824] Memory cgroup out of
2
> memory: Kill process 23918 (node /usr/share) score 67 or sacrifice
3
> child
>> Also entweder mysqld oder /usr/share.> MySQL ist schon ziemlich eingedampft und mit dem MySQLTuner bearbeitet> worden. So viel braucht der nicht mehr.> Was /usr/share ist, keine Ahnung.
"/usr/share" ist ein Verzeichnis auf Deinem Linux-System. Mit "node" ist
möglicherweise ein Programm aus dem Amateurfunkbereich gemeint, das
früher im Paket "node" und heute in dem Paket "ax25-node" enthalten sein
soll. Du als Admin dieses Systems solltest wissen, was da installiert
ist, was dort läuft, warum es läuft, wer das benötigt und wie es
gestartet wird. ;-)
Und bevor diese Diskussion "Out of memory" -- "Nein" -- "Doch" -- "Das
kann aber nicht sein" -- "Ooooh" noch weiter geführt wird: doch, das ist
so, und es steht ganz eindeutig in den Kernellogs. Ganz offensichtlich
gibt es eine Control Group, und das für diese Control Group
konfigurierte Speicherlimit ist nun einmal erschöpft, und darum tut der
OOM-Killer seinen Job.
Da es sich um eine Control Group handelt -- also: ein Feature von
modernen Linux-Kernels, mit dem unter anderem die Ressourcen und die
Priorisierung einzelner Prozesse oder Prozessgruppen limitiert werden
können (ähnlich wie einst mit ulimits, nur viel weiter gehend) -- ist es
wenig zielführend, das mit Werkzeugen zu betrachten, die den
Ressourcenverbrauch des Gesamtsystems und seiner Prozesse anzeigen.
Zielführender ist es, zunächst festzustellen, welcher Control Group die
betreffenden Prozesse zugeordnet, und wie deren Ressourcenlimits
konfiguriert sind. Die dazu nötigen Informationen findest Du unter
/sys/fs/cgroup, unter /proc/<pid>/cgroup, und mit den Programmen des
Pakets "cgroup-tools". HTH, YMMV.
K. J. schrieb:> Die Prozesse werden willkürlich raus geschossen,
Nein, das war früher mal so. Darüber haben sich die FreeBSD-Jungs dann
so lange lustig gemacht, bis unter Linux der OOM-Killer eingeführt
wurde, der nach nicht ganz trivialen, aber durchaus sinnvollen Kriterien
herauszufinden versucht, welchen Prozeß das System am ehesten
verschmerzen kann -- hat IIRC mit Benutzung, Priorität und so weiter zu
tun -- und diesen erschießt.
Oliver V. schrieb:> Gibt es eine Möglichkeit, herauszufinden, welcher Prozess diese hohen> io/bi-Werte verursacht, die vmstat anzeigt?
Das Programm iotop(8) aus dem Paket "iotop".
Oliver V. schrieb:> Ok, also /sys/fs/cgroup ist schon einmal ein leeres Verzeichnis.
Was genau ist denn das für ein Debian, und wie wird es virtualisiert?
Sheeva P. schrieb:> Mit "node" ist> möglicherweise ein Programm aus dem Amateurfunkbereich gemeint, das> früher im Paket "node" und heute in dem Paket "ax25-node" enthalten sein> soll.
Ne, das ist schon Node.js, zumal im obigen log auch npm (node package
manager) und PM2 (Advanced Node.js process manager) auftauchen.
Du brauchst einfach mehr Ressourcen, ganz einfach. Wenn du dir das nicht
leisten kannst, musst du halt weniger drauf laufen lassen. Die
LogMeldungen sind doch eindeutig.
Das mit den knappen Ressourcen glaube ich nicht. Mittlerweile ist der
Cache auf über 650 MB angewachsen. Das wäre nicht der Fall, wenn der
Platz tatsächlich gebraucht werden würde.
Es sei denn, natürlich, ein Prozess fordert auf ein Mal eine irrsinnige
Menge (1-2 GB) an. Da gebe ich euch Recht. Aber so etwas habe ich bisher
nicht gefunden.
In den Dateien unter /proc/*/cgroup sind zumindest keine Zahlenwerte
eingetragen, die irgendwelche Limits suggerieren könnten. Ich habe daran
auch nie etwas verstellt. Ist alles mehr oder weniger Standard (bis eben
auf die kleinen Tweaks seitdem ich das Problem bemerkt habe).
Leider ist es ein Stochern im Nebel. Anfrage beim Anbieter läuft
parallel, aber wegen Wochenende und Feiertagen wird das etwas dauern.
Oliver V. schrieb:> Mit iotop habe ich kein Glück. :/
Ok, die Fehlermeldung unter Ubuntu 16.04 LTS ist da eindeutiger... Du
mußt das Programm als root ausführen ("sudo iotop").
Oliver V. schrieb:> Virtualisiert wird laut Anbieter mit "LXC".
Wow, das würde ich mich nicht trauen. Bei einem eigenen Server finde ich
LXC ja ganz praktisch, aber fremden auf container zugriff zu geben wäre
mir etwas zu riskant. Welcher Anbieter ist das?
Habe ich versucht. Gleiche Meldung.
Meine Vermutung ist momentan:
memory: usage 817004kB, limit 819200kB, failcnt 1777024222
memory+swap: usage 1228800kB, limit 1228800kB, failcnt 7939462527
Also Limits von 800MB und 1200MB. Ich habe aber mehr RAM (1GB) und
nochmal 500MB Swap, die der vServer auch zu belegen versucht.
Der Anbieter hat wahrscheinlich ein falsches Limit gesetzt bzw. einfach
vergessen, das korrekte Limit einzustellen. Nämlich auf den Wert des
bestellten RAMs und RAM+SWAP.
Mal schauen, was die sagen.
Proxmox VE ist eine leistungsstarke und leichtgewichtige Open Source Server-Virtualisierungssoftware, optimiert für Leistung und Benutzerfreundlichkeit. Für maximale Flexibilität haben wir zwei Virtualisierungstechnologien unter einer Managementoberfläche vereint: Kernel-based Virtual Machine (KVM) und Container-Virtualisierung mit Linux Container (LXC).
Oliver V. schrieb:> Virtualisiert wird laut Anbieter mit "LXC".
Spannend. ;-)
Was mir übrigens gerade beim neuen 'Drüberschauen noch auffällt: nach
der von Dir geposteten Ausgabe von "free -t" (im Post [1] ganz unten)
swappt die Büchse schon, und nach der von Dir in [2] geposteten Ausgabe
von "ps aux" sind in Summa schon 98,2 % des Arbeitsspeichers belegt.
Auch dieses "usage 817004kB, limit 819200kB" aus [3] weist deutlich
darauf hin, daß diese Kiste völlig am Ende ist.
In [3] erwähnst Du, daß Du für 1 GB RAM bezahlst, und natürlich solltest
Du dann auch erwarten können, 1 GB RAM zu bekommen. Aber selbst wenn die
Kiste den gebuchten Arbeitsspeicher hätte, wäre das Ganze immer noch
allzu Spitz auf Knopf genäht. Wenn Du mit Deinem Hoster redest, solltest
Du lieber ein komplettes Gigabyte dazu buchen, dann hast Du auch genug
Reserve, wenn Du größere E-Mails oder Deine Webseite mehr Aufmerksamkeit
bekommt.
Um temporär über die Feiertage wieder etwas Luft zu bekommen, würde ich
jetzt zunächst den größten Ressourcenfresser Amavis sowie eventuell auch
Spamassassin deaktivieren, oder die Anzahl der Apache- und PHP-Prozesse
beschränken. Oder schlimmstenfalls eine Swapdatei anlegen und einbinden,
damit die Maschine etwas mehr Swapspace hat -- das ist aber wirklich die
dreckigste aller dreckigen Lösungen. YMMV.
[1] Beitrag "Re: vServer-Kernellog läuft ständig voll"
[2] Beitrag "Re: vServer-Kernellog läuft ständig voll"
[3] Beitrag "Re: vServer-Kernellog läuft ständig voll"
Bist du bei einem Anbieter mit Discounter im Namen? Da hatte ich die
letzten Tage die selben Probleme und bin mit der selben Konfiguration zu
einem anderen Anbieter gewechselt, der keine solchen Probleme macht.
Sheeva P. schrieb:> [Dinge]
Ach so, am Rande bemerkt: um den Ressourcenverbrauch von UNIX-Systemen
über längere Zeiträume zu überwachen, gibt es den altbekannten "System
Activity Reporter" (SAR) im Paket "sysstat". Eins der Programme liest in
regelmäßigen Intervallen die Performancecounter des Systems aus,
speichert die Zustände und setzt die Counter zurück. Die gespeicherten
Zustände können dann mit den anderen Programmen ausgelesen und in
verschiedenen Formaten -- tabellarisch, JSON, CSV, XML -- ausgegeben
werden. Nach einem konfigurierbaren Zeitraum, normalerweise sieben Tage,
werden die gespeicherten Daten gelöscht.
So hnlich arbeitet collectd, das kenne ich aber nur vom Hörensagen. SAR
hat dabei den Vorteil, daß ich ihn seit Ewigkeiten kenne und er auch für
andere UNIXe als Linux, etwa AIX, Solaris, HPUX und FreeBSD verfügbar
ist. So kann ich dasselbe Werkzeug und dieselben Skripte für den ganzen
Zoo nutzen. Der Nachteil von SAR ist allerdings, daß er eben nur Daten
sammelt und ausgibt, für die Visualisierung muß man sich entweder selbst
etwas schreiben oder auf etwas wie GNUplot, pyxplot, Flot oder jqPlot
ausweichen.
Für einen professionellen Betrieb geht natürlich nichts über ein
"richtiges" Monitoring, etwa mit Icinga, Zabbix, Shinken, Cacti, oder
für verclusterte und verteilte Umgebungen so etwas wie Ganglia. Solche
Systeme sind jedoch relativ aufwändig und vielleicht ein wenig
überdimensioniert, wenn man nur einen oder einige wenige kleine vServer
betreiben will.
Oliver V. schrieb:> Ich bin am Überlegen, ob ich das Caching deaktiviere... und wie.> Zumindest mal für ein Experiment. Mit jeder meiner Optimierungen wächst> der Cache.
Laß' es. Das ist sogar noch irrsinniger als eine Swapdatei anzulegen.
Das System benutzt den Dateisystemcache, um häufig genutzte Dateien zu
cachen, damit das System sie nicht bei jedem Zugriff von der Festplatte
laden muß. Eine Deaktivierung des Dateisystemcache erhöht daher die
I/O-Last auf der Festplatte MASSIV. Das kann das ganze System
unbenutzbar machen, zumal Du oben ja ohnehin schreibst, daß Du eine
enorme I/O-Last hast.
Linux benutzt für den Dateisystemcache aber eh nur freien
Arbeitsspeicher, und gibt Cache-Speicher wieder frei, sobald eine
Anwendung mehr Speicher anfordert als gerade frei ist. Außerdem wird der
Dateisystemcache für die Pufferung und Gruppierung von Schreibzugriffen
benutzt. Das bedeutet, daß Linux das tatsächlichen Schreibvorgänge so zu
gruppieren versucht, daß die zu beschreibenden Festplattensektoren
möglichst nahe bei einander liegen, um möglichst geringe Verfahrwege des
Schreibkopfes und möglichst wenige Drehungen der Diskplatter zu
erzielen. Derartige Positionierungen kosten nämlich bei klassischen
Platter-Festplatten (Rotierender Rost) sehr viel Zeit, I/O-Performance
und Zugriffslatenz.
Letztlich ist es ein sehr gutes Zeichen, wenn der Cache mit jeder Deiner
Optimierungen wächst. Denn das zeigt zunächst nur, daß Deine
Optimierungen tatsächlich wirken und Arbeitsspeicher freimachen. Wenn
trotzdem weiterhin OOM-Fehler im Kernellog auftreten, zeigt das daher
nur, unter welch hohem Druck Dein System gestanden hat und noch steht.
Die Fehler sollten jetzt aber seltener auftreten, oder?
Wie auch immer: ein Server sollte im normalen Betrieb trotz vollem Cache
immer noch freien Arbeitsspeicher für die Applikationen übrig haben.
Oliver V. schrieb:> Ich habe mal alle Dienste, die ich oben genannt habe, beendet und den> Server so einige Zeit stehen lassen. Das ist jetzt noch an Prozessen> übrig:> [...]> Trotz jetzt ausreichend freien Speichers und nur wenigen Prozessen> häufen sich noch immer die Fehlermeldungen und noch immer ist io/bi sehr> hoch. :/
Sehr merkwürdig. Ok, da läuft immer noch ein PHP, ein saslauthd, ein
xinetd, ein gam_server und ein memcached, aber das sollte eigentlich
nicht der Punkt sein. Ist es möglich, daß Dein Cron-Daemon irgendwas
Riesiges aufruft, das uns entgangen ist? Ist es möglich, daß Du oder
Dein Hoster Euch irgendeine Sauerei wie ein Rootkit eingefangen habt,
das sich vor den handelsüblichen Diagnosewerkzeugen verbirgt? Und welche
Prozesse werden jetzt überhaupt gekillt?
Sheeva P. schrieb:> Sehr merkwürdig.
Mir kommt das schon eine Weile seltsam vor. Nachdem ich sah, dass er
anfangs schon schrieb, das Verhalten wäre von seinen Services
unabhängig.
> Ist es möglich, daß Dein Cron-Daemon irgendwas> Riesiges aufruft, das uns entgangen ist?
Das sollte dann aber im "ps" irgendwie sichtbar sein. Soviel I/O völlig
ohne CPU geht doch fast nicht und die akkumulierte CPU steht da drin.
Blieben noch extreme Respawns, aber auch die sollten doch irgendwie
auffallen.
> Dein Hoster Euch irgendeine Sauerei wie ein Rootkit eingefangen habt,> das sich vor den handelsüblichen Diagnosewerkzeugen verbirgt? Und welche> Prozesse werden jetzt überhaupt gekillt?
Oder manche Statistik-Werte sind mit etwas Vorsicht zu geniessen.
Vielleicht werden darin mehr Daten eingefangen, als nur jene, die zu
dieser VM gehören.
Die restlichen Dienste (cron, php, bind, saslauth, xinet, memcached,
...) habe ich jetzt auch noch abgeschossen und gewartet. Keine Änderung!
vmstat io/bi hoch
fehler im kernel.log
Was mich wundert: Ich bekomme immernoch Meldungen zu mysqld im
kernel.log, obwohl der schon längst nicht mehr läuft!?
Ich frage mich gerade, ob ich Meldungen von einem anderen Container
sehe..... und ob vmstat die Werte des Hostservers anzeigt.
Hm, egal, ich reboote jetzt und warte auf die Antwort des Anbieters.
Dieser Mist füllt über kurz oder lang die Platte. Als ich es gemerkt
habe, waren es schon 1 GB an Logs. Das landet ja nicht nur in
kernel.log, sondern auch in messages, syslog, dmesg... Dann wird der
Unsinn ja auch noch komprimiert und das anscheinend auf jedem Container.
So ein Quatsch kann doch nicht normal sein. Das ist ein fetter Bug.
Oliver V. schrieb:> Hm, egal, ich reboote jetzt und warte auf die Antwort des Anbieters.
Gute Idee, hoffentlich macht der Support jetzt den andern Kunden zur Sau
der seinen RAM nicht im Griff hat.
A. K. schrieb:> "dmesg shows host's log"
Vielleich fragt man mal höflich nach ob man nicht auf einen ruhigeren
Server gelegt werden kann...