$ arm-none-eabi-gcc --version
arm-none-eabi-gcc (GNU Tools for Arm Embedded Processors
7-2017-q4-major) 7.2.1 20170904 (release) [ARM/embedded-7-branch
revision 255204]
Copyright (C) 2017 Free Software Foundation, Inc.
Ich hab in meinem Linkerscript sowas stehen:
1
SECTIONS
2
{
3
.isr_vector :
4
{
5
__vector_table = .;
6
KEEP(*(.vector_table))
7
*(.text.Reset_Handler)
8
*(.text.Default_Handler)
9
*(.text.System_Init)
10
*(.text.SystemCoreClockUpdate)
11
. = ALIGN(4);
12
} > VECTORS
13
14
.flash_protect :
15
{
16
KEEP(*(.kinetis_flash_config_field))
17
. = ALIGN(4);
18
} > FLASH_PROTECTION
19
20
.text :
21
{
22
*(.text*)
23
24
und so weiter
Insbesondere gehts mir hier um .vector_table und
.kinetis_flash_config_field
Seit Jahren funktioniert das problemlos mit -Os und -flto. Heute hab ich
mal einen neuen Rechner aufgesetzt und den aktuellen arm gcc aus dem
offiziellen repository installiert (siehe oben) und plötzlich schmeißt
mir der Linker alle KEEP() Sections ersatzlos raus.
Gibts irgend nen Trick wie ich um dieses überraschende neue Verhalten
(Bug?) herum arbeiten könnte um die betroffenen sektionen zu behalten
ohne auf LTO verzichten zu müssen?
Hab den Fehler gefunden.
Der Name der Konstante die bei mir rausoptimiert wurde entsprach
zufällig genau dem Namen eines Symbols das im Linkerscript definiert
war.
Konkret hieß das const struct für meine Tabelle in meinem Quelltext
zufällig __vector_table und wie es der Zufall will definiert mein oben
gepostetes Linkerscript ebenfalls ein (vollkommen unnötiges) Symbol des
selben Namens. Dieses Relikt habe ich nun aus meinem Linkerscript
entfernt und jetzt verhält sich wieder alles wie es soll.
Mal wieder typischer Fall von selbst in den eigenen Fuß geschossen (die
Kugel war über 1 Jahr lang unterwegs) und nach erfolgtem Treffer
reflexartig die Toolchain beschuldigt.
Bernd K. schrieb:> Der Name der Konstante die bei mir rausoptimiert wurde entsprach> zufällig genau dem Namen eines Symbols das im Linkerscript definiert> war.>> Konkret hieß das const struct für meine Tabelle in meinem Quelltext> zufällig __vector_table
"Zufällig" sollte man niemals reservierte Namen verwenden, also bei
allem, das mit "__" oder mit "_<Großbuchstabe>" beginnt genau wissen was
man tut.
Oft scheit ja die naming convention zu sein:
_xxx // irgendwas systemnahes
__xxx // irgendwas noch viiiiel systemnäheres oder etwas, wo man sich
unsicher ist
___xxx // etwas, das super-duper systemnah ist oder etwas das man nicht
wirklich blickt
...
Im speziellen Fall sollte also die Anwendung wohl keinen reservierten
Identifier verwenden, ansonsten stehst du nächsten monat hier mit "woher
kommt das "undefined reference to __vector_table" und wo muss ich das
definieren :-/
Gefahr erkannt, Gefahr gebannt.
Aber jetzt gehts weiter: Eben nen noch älteren Quelltext rausgekramt,
basierend auf dem Startupcode dieser Sammlung:
https://github.com/0xc0170/kinetis_klxx_gcc/
Insbesondere in meinem Beispiel diesen Startup-Code hier:
https://github.com/0xc0170/kinetis_klxx_gcc/blob/master/cmsis/MKL05Z4/startup_MKL05Z4.s
mit -Os -flto werden jetzt alle meine Interruptvektoren wegoptimiert, es
bleiben die eigentlich als weak deklarierten leeren Schleifen aus dem
default-handler Makro stehen.
Wahrscheinlich ist mit diesem Startup code auch irgendwas faul und gcc
hat recht aber ich sehe es nicht.
Du hast doch gerade an dem Symbol __vector_table herumgebastelt - könnte
da ein Zusammenhang bestehen? Die Vektortabelle sorgt ja meistens dafür,
dass die richtigen Interrupt-Vektoren in der richtigen Reihenfolge an
der richtigen Stelle stehen...
MfG, Arno
Und wenn ich die Reihenfolge im Linkeraufruf so ändere daß der
Startupcode zuerst genannt wird dann funktioniert der weak-Mechanismus
wieder.
Also:
Ohne LTO: überschreiben von WEAK geht immer, egal in welcher Reihenfolge
die Module beim Linken angegeben werden und egal ob C oder Assembler
oder gemischt.
Mit LTO: Assembler-Module mit WEAK müssen vor den Modulen die sie
überschreiben auf der Kommandozeile auftauchen. C-Module mit WEAK
anscheinend nicht, muss ich aber nochmal testen.
Wenn das kein Bug ist dann bedeutet das daß Module mit WEAK
grundsätzlich immer weiter links stehen müssen und daß es bisher (oder
ohne LTO auch heute noch) auch mit beliebiger Reihenfolge funktioniert
hat war ein reiner Zufall. Ich geh jetzt mal nach der Doku suchen.
Arno schrieb:> Du hast doch gerade an dem Symbol __vector_table herumgebastelt
Nein, jetzt hab ich ein noch älteres Projekt unter der Fuchtel mit ganz
anderem Startup code. Das aus Post #1 funktioniert wieder nachdem ich
den ein Jahr lang unbemerkt gebliebenen Namenskonflikt beseitigt habe.
Allerdings hab ich plötzlich kein gutes Gefühl mit der LTO mehr jetzt
nachdem mir bei dem anderen Projekt plötzlich das Verhalten von WEAK um
die Ohren fliegt (eigentlich ein komplett anders Problem, hätte
vielleicht nen neuen Thread aufmachen sollen, aber Problem 1 war ja
gelöst)
Bernd K. schrieb:> Allerdings hab ich plötzlich kein gutes Gefühl mit der LTO mehr
Evtl. fehlen Attribute an den C-Deklarationen, was sich erst bei
(globaler) Optimierung bemerkbar macht; insbesondere "used" und
"externally_visible".
Wenn du LTO im Verdacht hast, dann schau ins vom Compiler beim LTO-Lauf
generierten Assembler-Code in *.ltrans*.s. Dieser Code steht nicht in
modul.s bzw. der dortige asm-Code ist Makulatur.
Damit hast du schon mal eine Abgrenzung ob's auf Binutils /
Linker-Skrip-Ebene hakt oder C-seitig.
Johann L. schrieb:> Wenn du LTO im Verdacht hast, dann schau ins vom Compiler beim LTO-Lauf> generierten Assembler-Code in *.ltrans*.s.
Wie schalt ich die Generierung derselben ein?
Bernd K. schrieb:> Johann L. schrieb:>> Wenn du LTO im Verdacht hast, dann schau ins vom Compiler beim LTO-Lauf>> generierten Assembler-Code in *.ltrans*.s.>> Wie schalt ich die Generierung derselben ein?
Bei
Hi,
I've found this topic trying to resolve my issues with -flto that
occured in GCC 7.2.1.
I don't understand everything you've written[google translator still has
a lot to do with translating technical language]. I assume you have some
problems with link time optimization, which removes your sections from
output binary.
Here is what I've observed in my example:
Looks like LTO flag used in GCC 7.2.1 removes IRQ_Handlers and replaces
them with weak definitions from assembler statup file. What's more weird
is that this issue depends on order of object files in linking. If
startup file is placed first on object list, then LTO works fine. When I
change file order, every IRQ_Handler that is placed before statup file
on a linking list will be removed and replaced with weak definition from
statup. I've tried to use additional attributes(keep) and GCC flags but
it didn't help.
I am not sure if we are observing the same issue. Please let me know
what you think about that.
I would be grateful if you could respond in english.
Best Regards
RMszal schrieb:> What's more weird> is that this issue depends on order of object files in linking. If> startup file is placed first on object list, then LTO works fine. When I> change file order, every IRQ_Handler that is placed before statup file> on a linking list will be removed and replaced with weak definition from> statup.
This is exactly the issue I am observing too.
Actually in this thread the first post was a different error, I had a
duplicate symbol in my linker script and in my startup, this made LTO
discard the entire output of that variable (the old one did not do this,
so I never noticed my error). This problem is resolved because it was my
own fault.
--
The remaining problem I am now facing is the exact same what you are
describing, I now have to put the object file with the weak symbols
earlier on the command line than the ones containing the strong symbol.
This behavior is new.
I have another project with startup code written in C, the weak default
handlers are normal c functions with __attribute((weak)) and these can
be linked in any position and the weak/strong overriding mechanism still
works here even with the new gcc. I am observing the problematic
behavior only with startup code written in assembly! So something
about the treatment of objects generated from assembly seems different
from those generated from c sources during the LTO pass.
When I disable LTO everything works as expected again.
Currently I am fixing my makefiles to make sure the startup code object
files are always mentioned in the first position during linking. I have
made another thread in this forum where I asked for help finding
detailed documentation about the usage of weak with regard to the
linkage order, whether gcc makes any guarantees or assumptions, I
suspect it is a bug but before I report it I need to know what the
documentation actually has to say about this topic but I have not yet
found it.
Good to hear that we have same problem.
I am also preparing to report this bug, here is the simplest example
that is not linked correctly:
1
volatileintflag;
2
3
voidRTC1_IRQHandler(void)
4
{
5
flag=0;
6
}
7
8
intmain(void)
9
{
10
while(1)
11
{
12
flag++;
13
}
14
}
I am making sure if this can not be resolved by adding some compiler
flags/attributes to the weak declaration inside startup, but I haven't
found any clue so far. I'll try to compare weak declarations inside C
compiled objects.
I've also found your second thread. Please let me know if you find any
solution[better than reordering files].
Best Regards
I have made a minimal self contained project that demonstrates the bug.
Extract the attached archive KL05_demo_gcc_weak_strong_bug.tar.gz. You
will find a minimal makefile project, versioned in a git repository with
only two commits on two branches, one shows the bug and the other
doesn't.
$ git checkout bad
$ make clean
$ make all
look at the generated .lst file in the build folder and note that the
Systick handler looks like this, it is the weak default implementation
from the startup assembly:
1
000004f4 <SysTick_Handler>:
2
4f4: e7fe b.n 4f4 <SysTick_Handler>
now checkout the good version
$ git checkout good
$ make clean
$ make all
The systick handler will look like this which is the strong C
implementation:
Da ich grad nicht viel zu tun hab, habe ich dein Beispiel mal durch den
7.2.0 vom bleeding-edge gehauen und kann jetzt nichts ungewöhnliches
finden.
arm-none-eabi-gcc (bleeding-edge-toolchain) 7.2.0
Copyright (C) 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is
NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR
PURPOSE.
Ah Mist. Richtig lesen... 7.2.1 ist das Thema.
Ich bin wohl gestern in die Falle mit dem 7.3.0 getappt. Andauernd bin
ich in einen nicht implementierten Interrupt gesprungen. Hat dann drei
Stunden gedauert bis ich Mal den alten 6er genommen habe. Und dann viel
mir auch der Thread wieder ein.
Ja, hab auch heute morgen nach langer Zeit auch grad wieder ein altes
Makefile passend ändern müssen nachdem ich mich erstmal 10 Minuten am
Kopf kratzen mußte warum das aus heiterem Himmel plötzlich nicht mehr
funktioniert, zum Glück kam die Erinnerung an diesen Sachverhalt dann
doch recht schnell zurück.
Ich hoffe das dauert nicht mehr allzulange oder gar noch ein paar Jahre
bis das endlich gefixt ist und man das final abhaken und zu den Akten
legen kann.
ich bin jetzt auch auf diesen bug gestoßen.
Leider ist Makefile anpassen keine Option wenn man STM32Cube benutzt, da
dieses automatisch generiert wird. Hier bleibt nur die Option die
benutzen Interrupts im Startupfile rauszuschmeißen.
Arbeitet hier jemand am GCC Projekt mit oder kennt jemanden?
Das ist doch scheiße, dass dieser bug schon über 2 Jahre alt ist und
laut den Kommentaren auch in der neuesten 9.3 Version immer noch
enthalten ist.
LTO sollte man für embedded ohnehin nicht benutzen, da der Stackbedarf
damit nicht mehr statisch analysierbar ist und durch verschärftes
Inlining unkontrolliert wächst.
Wieso erhöht inlining den Stackbedarf?
Und wieso ist der Stackbedarf dann nicht mehr statisch analysierbar?
Das klingt nach einem GCC Problem.
LTO schalte ich ein um z.B. Bitbanging ohne Overhead für
Funktionsaufrufe nutzen zu können.
ARM M4 (stm32) schrieb im Beitrag #6462780:
> Wieso erhöht inlining den Stackbedarf?
Weil Callees in the Caller wandern und dort gleichzeitig existieren
statt nacheinander wie im call tree.
> Und wieso ist der Stackbedarf dann nicht mehr statisch analysierbar?
Weil der Binärcode heftig und vor allem auch über translation units
hinweg verändert wird, so daß er mit dem Source nicht mehr viel zu tun
hat.
> Das klingt nach einem GCC Problem.
GCC verweigert die Analyse schlichtweg und wirft leere .su-Files aus.
> LTO schalte ich ein um z.B. Bitbanging ohne Overhead für> Funktionsaufrufe nutzen zu können.
Das geht auch mit Macros (oder in C++ mit Templates), oder mit static
inline Funktionen in der Treiberschicht. Wenn Du aus jeder Ecke der
Applikation direkt auf die HW zugreifst, stimmt ohnehin etwas mit der
Architektur nicht.
Nop schrieb:> ARM M4 (stm32) schrieb im Beitrag #6462780:>> Wieso erhöht inlining den Stackbedarf?>> Weil Callees in the Caller wandern und dort gleichzeitig existieren> statt nacheinander wie im call tree.>
Hmm ich vermute mal in einfachen Fällen (s. Beispiel unten) wird der
Stack perfekt wiederverwendet. In welchen Fällen wäre dies nicht
möglich?
Klar ist die minimal benötigte Stackgröße durch die größte Funktion
vorgegeben.
>> Und wieso ist der Stackbedarf dann nicht mehr statisch analysierbar?>> Weil der Binärcode heftig und vor allem auch über translation units> hinweg verändert wird, so daß er mit dem Source nicht mehr viel zu tun> hat.>>> Das klingt nach einem GCC Problem.>> GCC verweigert die Analyse schlichtweg und wirft leere .su-Files aus.>
Ist mir auch mal aufgefallen, klingt wieder nach einem GCC bug.
Dass gcc keine vernünftige "whole program" Optimierung kann ist doch ein
Relikt von anno damals™. Ob ich alles in ein File kloppe oder modular
programmiere und LTO benutze macht aus logischer Sicht keinen
Unterschied.
>> LTO schalte ich ein um z.B. Bitbanging ohne Overhead für>> Funktionsaufrufe nutzen zu können.>> Das geht auch mit Macros (oder in C++ mit Templates), oder mit static> inline Funktionen in der Treiberschicht.
Joa oder man hofft auf einen guten Optimizer.
Wenn man aus ISR heraus andere Handler funktionen aufruft werden die
ohne LTO leider auch nicht geinlined.
ARM M4 (stm32) schrieb im Beitrag #6463873:
> Hmm ich vermute mal in einfachen Fällen (s. Beispiel unten) wird der> Stack perfekt wiederverwendet.
In einfachen Fällen schon, aber nicht in komplexeren. So richtig übel
wird es, falls man Rekursion benutzt, weil eine aufgerufene Funktion mit
ihrem Stackbedarf dann Teil der rekursiven Funktion wird und auf jedem
Rekursionslevel Stack verbraucht. Das kriegt man ohne LTO in den Griff,
indem man Inlining per Funktions-Attribut verbietet, aber LTO versaut
das wieder.
> Ist mir auch mal aufgefallen, klingt wieder nach einem GCC bug.
Ich denke eher, daß die Beziehung zwischen Quelltext und Binärcode dann
nicht mehr so gegeben ist, daß die funktionsbezogene Auskunft überhaupt
noch Sinn ergäbe.
> Ob ich alles in ein File kloppe oder modular> programmiere und LTO benutze macht aus logischer Sicht keinen> Unterschied.
Wenn man alle c-files per #include einbindet (hat man früher vor LTO
echt gemacht), hat man zwar denselben Effekt, aber bereits nach dem
Übersetzungsschritt der dann einzigen translation unit.
Das bietet aber andere Stolpersteine, beispielsweise in bezug auf
pointer aliasing, was nur innerhalb von translation units ausgewertet
wird und nicht darüber hinaus.
> Wenn man aus ISR heraus andere Handler funktionen aufruft werden die> ohne LTO leider auch nicht geinlined.
Außer wenn sie als static inline markiert oder als Macros implementiert
sind.
Nop schrieb:> ARM M4 (stm32) schrieb im Beitrag #6463873:>>> Hmm ich vermute mal in einfachen Fällen (s. Beispiel unten) wird der>> Stack perfekt wiederverwendet.>> In einfachen Fällen schon, aber nicht in komplexeren. So richtig übel> wird es, falls man Rekursion benutzt, weil eine aufgerufene Funktion mit> ihrem Stackbedarf dann Teil der rekursiven Funktion wird und auf jedem> Rekursionslevel Stack verbraucht. Das kriegt man ohne LTO in den Griff,> indem man Inlining per Funktions-Attribut verbietet, aber LTO versaut> das wieder.>
Rekursion auf embedded? Come on, man!
Ohne Rekursion funktioniert "noinline" + LTO wie erwartet.
Tja, wenn dir und mir kein Beispiel einfällt...
In meiner Theorie sollte es immer funktionieren, den Stackbedarf der
größten geinlinten Funktion direkt von Beginn an zu benutzen und fertig.
Die Frage ist halt was kann der GCC wirklich.
>> Ist mir auch mal aufgefallen, klingt wieder nach einem GCC bug.>> Ich denke eher, daß die Beziehung zwischen Quelltext und Binärcode dann> nicht mehr so gegeben ist, daß die funktionsbezogene Auskunft überhaupt> noch Sinn ergäbe.>
Der Optimizer weiß doch welche Funktionen er geinlined hat. Ein Mensch
könnte das problemlos aufaddieren. Der Stackbedarf einer geinlined
Funktion könnte tatsächlich keinen Sinn mehr ergeben (weil sie in dem
Sinne nicht mehr existiert), aber wen interessiert das wirklich?
Relevant ist doch nur der maximale Stackbedarf und der startet immer bei
main.
-> Eigentlich müsste man doch mit dem .elf + .map file auch völlig ohne
GCC den Gesamtstackbedarf analysieren können? Reset_Handler ausfindig
machen und von da an alles aufaddieren -> fertig (naive Version).
Achnee, gibt es schon zu kaufen:
https://www.absint.com/stackanalyzer/gallery.htm# (Setup Tab). Der
arbeitet mit .elf files.
>> Ob ich alles in ein File kloppe oder modular>> programmiere und LTO benutze macht aus logischer Sicht keinen>> Unterschied.>> Wenn man alle c-files per #include einbindet (hat man früher vor LTO> echt gemacht), hat man zwar denselben Effekt, aber bereits nach dem> Übersetzungsschritt der dann einzigen translation unit.>> Das bietet aber andere Stolpersteine, beispielsweise in bezug auf> pointer aliasing, was nur innerhalb von translation units ausgewertet> wird und nicht darüber hinaus.>
Das wäre dann Code der auf UB basiert. Strict aliasing abschalten oder
alias Regeln einhalten wäre besser.
>> Wenn man aus ISR heraus andere Handler funktionen aufruft werden die>> ohne LTO leider auch nicht geinlined.>> Außer wenn sie als static inline markiert oder als Macros implementiert> sind.
Zu spät geboren um die Welt zu erkunden und zu früh geboren um einen
ordentlichen Compiler zu haben. :(
Nop schrieb:> In einfachen Fällen schon, aber nicht in komplexeren. So richtig übel> wird es, falls man Rekursion benutzt, weil eine aufgerufene Funktion mit> ihrem Stackbedarf dann Teil der rekursiven Funktion wird und auf jedem> Rekursionslevel Stack verbraucht.
Hast du ein Beispiel, wo der Compiler das nicht optimieren kann?
ARM M4 (stm32) schrieb im Beitrag #6464984:
> Rekursion auf embedded? Come on, man!
Gibt Fälle, wo das nützlich ist. Natürlich muß man dabei das
Rekursionslevel begrenzen.
> Ohne Rekursion funktioniert "noinline" + LTO wie erwartet.https://interrupt.memfault.com/blog/best-and-worst-gcc-clang-compiler-flags#-flto> In meiner Theorie sollte es immer funktionieren, den Stackbedarf der> größten geinlinten Funktion direkt von Beginn an zu benutzen und fertig.> Die Frage ist halt was kann der GCC wirklich.
Das bekommt man halt leider nicht direkt mit GCC raus.
> Das wäre dann Code der auf UB basiert.
Tut er nicht, weil der Compiler beim Aufruf einer Funktion in einer
anderen TU davon ausgehen muß, daß z.B. der übergebene void-Pointer in
der Funktion wieder in genau den Ursprungstyp zurückgewandelt wird.
Falls dem nicht so ist, kann er das nicht sehen, und deswegen ist es
auch kein UB.
mh schrieb:> Hast du ein Beispiel, wo der Compiler das nicht optimieren kann?
Das ist doch offensichtlich bei rekursiven Funktionen. Ein starker
temporärer Stackverbrauch wird in die externe Funktion ausgelagert, ist
aber wieder zuende, wenn man in die aufrufende rekursive Funktion
zurückgeht. Das klappt natürlich nicht mit Inlining.
Eine Alternative wäre natürlich, die temporären Variablen in der
rekursiven Funktion als static zu nehmen, was allerdings etwas hacky
wäre.
Nop schrieb:> mh schrieb:>>> Hast du ein Beispiel, wo der Compiler das nicht optimieren kann?>> Das ist doch offensichtlich bei rekursiven Funktionen.
Nein es ist nicht offensichtlich. Deswegen habe ich nach einem Beispiel
gefragt. Also ein minimales lauffähiges Beispiel das der Compiler nicht
optimieren kann.
mh schrieb:> Nein es ist nicht offensichtlich.
Dann denk ein wenig drüber nach. Ich bau Dir jetzt keinen Code zurecht,
nur um Dir das Nachdenken zu sparen.
Nop schrieb:> mh schrieb:>>> Nein es ist nicht offensichtlich.>> Dann denk ein wenig drüber nach. Ich bau Dir jetzt keinen Code zurecht,> nur um Dir das Nachdenken zu sparen.
Dann gehe ich davon aus, dass du dir das aus den Fingern gesaugt hast,
ich sehe keinen Grund, warum der Compiler das nicht hinbekommen sollte.
mh schrieb:> Dann gehe ich davon aus, dass du dir das aus den Fingern gesaugt hast
Weil Du das Problem nicht verstanden hast und Dir nicht klar ist, wie
der Stackframe einer rekursiven Funktion aussieht.
Könnt ihr euch nicht per DM anzicken? Wieder ein ganz interessanter
thread, dessen Beobachtung man aufgeben muss, weil sich 2 "Experten" mit
"Nein", "Doch", "Nein", "Doch" austauschen und einem das Mail-Postfach
zumüllen.
Nop schrieb:> mh schrieb:>>> Dann gehe ich davon aus, dass du dir das aus den Fingern gesaugt hast>> Weil Du das Problem nicht verstanden hast und Dir nicht klar ist, wie> der Stackframe einer rekursiven Funktion aussieht.
Dann hast du vielleicht versagt, das Problem zu beschreiben. Bei dem was
du beschrieben hast, sehe ich keinen Grund, warum der Compiler das nicht
optimieren kann. Ich sage nicht, dass er es immer macht. Aber solange du
oder jemand anderes keinen guten Grund oder ein Beispiel gibt, gehe ich
davon aus, dass es kein Problem gibt.
Torsten R. schrieb:> Könnt ihr euch nicht per DM anzicken?
Gibt's für Gastnutzer nicht.
> und einem das Mail-Postfach zumüllen.
Ist doch Dein Problem, wenn Du Dich unbedingt registrieren wolltest und
Thread-Benachrichtigungen aktiviert hast.
mh schrieb:> Dann hast du vielleicht versagt, das Problem zu beschreiben. Bei dem was> du beschrieben hast, sehe ich keinen Grund, warum der Compiler das nicht> optimieren kann.
Weil er den Stackframe aufbaut?! Hier mal für ARM-GCC 8.2.1 mit -O2
mittels
https://godbolt.org/z/93KnYrhttps://godbolt.org/z/6oqzdW
Man beachte, an welcher Stelle im Calltree jeweils der Stackpointer um
4096 dekrementiert wird. Ohne Inlining ist das nur zwischendrin, aber
geht nicht in die Rekursion ein, aber mit Inlining geht der
Zwischenstackbedarf auf jedem Rekursionslevel ein. Das ist doch völlig
offensichtlich.
Nop schrieb:> Man beachte, an welcher Stelle im Calltree jeweils der Stackpointer um> 4096 dekrementiert wird.
Klar muss er die Daten hier alle auf den Stack packen, da
1
externvoidfoo2(int*)
hier unbekannt ist und den Pointer auf den Stack speichern kann.
Wie sieht es aber aus wenn er die Funktion foo2 kennt, z.B. dank LTO? Da
dreht sich deine Behauptung ja drum.
Könnt ihr bitte euren eigenen Thread aufmachen um das Für und Wider von
LTO zu diskutieren? Hier gehts um einem Bug im gcc der nichts mit eurer
Diskussion zu tun hat. Danke.
mh schrieb:> Klar muss er die Daten hier alle auf den Stack packen, da> extern void foo2(int*)> hier unbekannt ist
Die Funktion hat nur den Zweck, daß der Compiler in diesem
Trivialbeispiel nicht das ganze temporäre Array wegoptimiert. Mit einem
tatsächlich notwendigen Array wäre es derselbe Stackframe.
Nop schrieb:> mh schrieb:>>> Klar muss er die Daten hier alle auf den Stack packen, da>> extern void foo2(int*)>> hier unbekannt ist>> Die Funktion hat nur den Zweck, daß der Compiler in diesem> Trivialbeispiel nicht das ganze temporäre Array wegoptimiert. Mit einem> tatsächlich notwendigen Array wäre es derselbe Stackframe.
Nur verhinderst du mit dieser Funktion jede Optimierung des
Stackframes.
mh schrieb:> Nur verhinderst du mit dieser Funktion jede Optimierung des> Stackframes.
Irrelevant. Es kann auch eine Funktion sein, die letztlich in der Kette
von einem IO-Buffer abhängt. Ob die inlined wird oder nicht, spielt
keine Rolle.
Du sprichst außerdem die ganze Zeit diffus von irgendeiner
"Optimierung", ohne aber zu sagen, was genau der Compiler Deiner Meinung
nach in welcher Weise da optimieren soll. Also was genau denkst Du, daß
der Compiler da tun soll?
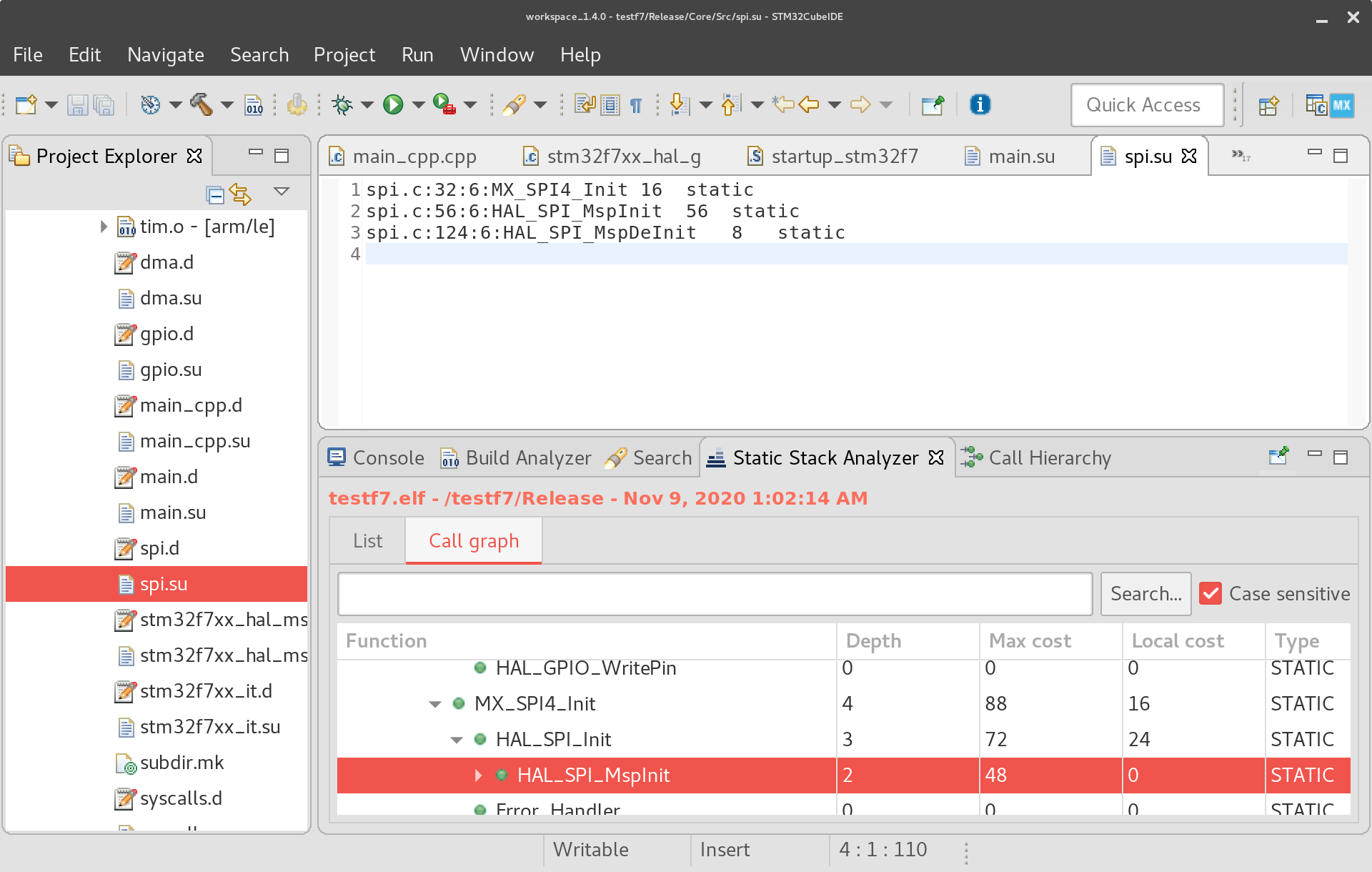
Welche Tools benutzt Ihr denn für statische Stackanalyse?
Ich kannte nur das "Static Stack Analyzer" Tool von ST und da ist mir
ein Problem aufgefallen.
Ich habe wie vorgeschlagen, ein Python Skript geschrieben dass aus GCC
.list Files die lokale und maximale Stackgrößen aller Funktionen
berechnet, sieht dann aus wie im Anhang. Passt eigentlich ganz gut mit
dem Output vom ST Tool überein, ABER...
-> Die GCC .su files enthalten nur die lokale Stackgröße, d.h. das ST
Tool muss das selber aufaddieren.
-> Mein Tool hat teilweise größere lokale Stackbedarfe berechnet als das
ST Tool
-> Im Screenshot sieht man, dass im .su File 56Byte für HAL_SPI_MspInit
stehen (das kommt bei mir auch raus, sieht man nicht im Bild da ich die
LTO Variante angehängt habe), im Call graph aber steht stattdessen 0!
Dadurch berechnt mein Tool 56Byte mehr für den gesamten Calltree. Ist
das ein Bug von ST? Oder die sind schlauer...