hi ich suche eine quelle für infos/codefetzen zu einem de-reverb algo hat vieleicht jemand eine quelle wo man vieleicht weitere infos bekommt? wäre sehr nett danke im vorraus grüße
235456456455623563235235635 schrieb: > hi > > ich suche eine quelle für infos/codefetzen zu einem de-reverb algo > > hat vieleicht jemand eine quelle wo man vieleicht weitere infos bekommt? > > wäre sehr nett > > danke im vorraus > > grüße 1. Deine Shift-Taste ist defekt 2. Deine Komma-Taste auch 3. wäre es nett, wenn du erläutern würdest, was du unter "de-reverb algo" verstehst.
Hi Sorry. Ich schreibe oft einfach so vor mich hin. Ich suche einen "De-Reverb" Algorithmus um ein Audiosignal( Sprache , mono 100-8000Hz , 16Khz Samplerate ) von Reverbeffekten( kurze Raumreflexionen ) zu bereinigen. Problem: Mikrofon steht im Raum, der Sprecher steht etwas entfernt. Man hört das durch den leichten Nachhall. Ich möchte nun den Sprecher soweit vom Rest isolieren das man diesen deutlicher verstehen kann. Aktuell schaue ich im speexcodec nach.
235456456455623563235235635 schrieb: > Aktuell schaue ich im speexcodec nach. In der aktuellen Version wurde dieser Teil scheinbar rausgenommen. Schade.
hi hat vieleicht jemand eine Idee wie man soetwas realisieren könnte?
235456456455623563235235635 schrieb: > hat vieleicht jemand eine Idee wie man soetwas realisieren könnte? Die hatten schon viele: https://scholar.google.de/scholar?hl=de&as_sdt=0%2C5&q=dereverberation&btnG= Mit einem "Codefetzen" ist es aber nicht getan. Wenn du MATLAB zur Verfügung hast wäre das hier interessant: http://www.kecl.ntt.co.jp/icl/signal/wpe/ Ansonsten gibt es meines Wissens nur diverse kommerzielle Plugins.
Moin, ist das kommerziell oder zu Lernzwecken? Wenn du nur experimentieren willst: Nimm mal die Impulsantwort deiner Lieblingskapelle (also die Gebäudevariante, ne) mit einem vernünftigen Mikrofon auf und suche zum Stichwort "Deconvolution". Anekdote meinerseits: Der Pfarrer erlaubte damals zu Zwecken der Forschung, dass ein sog. "Frauenfurz" (klassischer Silvester-Knallkörper) im Gotteshaus gezündet werden durfte :-)
Martin S. schrieb: > Der Pfarrer erlaubte damals zu Zwecken der > Forschung, dass ein sog. "Frauenfurz" (klassischer > Silvester-Knallkörper) im Gotteshaus gezündet werden durfte :-) Für den gleichen Zweck üblicher ist heute eher langsames Furzen mit ansteigender Frequenz (Sweep)... ;-)
Vielen Dank erstmal Einerseits zur Selbstforschung... Andererseits soll das ganze irgendwann als Sprachverbesserung für VoIP in diversen Produkten dienen. Eine 100%ige Bereinigung wäre auch nicht notwendig. Solange es um sich eine Reduzierung handelt wäre ich schon zufrieden. Ich vergaß zu erwähnen das es auf einem Cortex M läuft. Daher kann ich nicht die gängigen Tools/Plugins verwenden. Deswegen die Frage nach codefetzen oder Quellen wie man solche Dinge realisieren könnte. Für kurze Impulse ( Drums ..) soll sich ein Compressor mit dem Phasenverdrehten Signal eignen. https://riddlermike.wordpress.com/2013/08/25/deverb-for-free-removing-reverb-using-free-plugins/ Leider funktioniert das nur für kurze, starke Signale.
235456456455623563235235635 schrieb: > Ich vergaß zu erwähnen das es auf einem Cortex M läuft. Klingt bisschen mager.. Lange FIR kannst du damit nicht rechnen, das wird dann schnell mal was mit NEON-Assembler-Hacks. Das ist so oder so auch nur begrenzt sinnvoll, von einem Nachhall in der Beispiel-Kirche kommt mit so einigen Sekunden was zusammen, da musst man gehörig tricksen. Wenn du im VoIP-Bereich was reissen willst: Da sind die Claims schon recht gut abgesteckt, heisst: kaum Chancen auf erfolgreiche Marktpenetration :-)
Echtzeit-Enthallung macht man eher nicht indem man versucht die Impulsantwort zu entfalten, sondern dadurch dass man das Betragsspektrum der Nachhallkomponente im STFT-Bereich schätzt und mit mit spektraler Modifikation unterdrückt (z.B. https://www.vocal.com/dereverberation/spectral-subtraction/). Das schafft ein ARM Cortex locker. Allerdings ist es schwierig, dadurch für normal hörende Menschen eine wirkliche Verbesserung der Sprachverständlichkeit zu erreichen, da das menschliche Gehör das selbst schon ziemlich gut hinkriegt.
hi Strubi schrieb: > Klingt bisschen mager.. > Lange FIR kannst du damit nicht rechnen, das wird dann schnell mal was > mit NEON-Assembler-Hacks. Das ist so oder so auch nur begrenzt sinnvoll, > von einem Nachhall in der Beispiel-Kirche kommt mit so einigen Sekunden > was zusammen, da musst man gehörig tricksen. > Wenn du im VoIP-Bereich was reissen willst: Da sind die Claims schon > recht gut abgesteckt, heisst: kaum Chancen auf erfolgreiche > Marktpenetration :-) Im VoIP Bereich gibt es sicher einiges an fertigen Lösungen. Wir haben jedoch unsere eigenen :-) Und da aktuell noch einige Ressourcen überig sind, können wir diese sicher noch in Verbesserungen stecken. Das ganze läuft bisher in einem STM F7 + Audio Codec. Viel mehr ist dann aber auch nicht dran. Es geht hier auch nicht um den Nachhall in einer Kathedrale. Eher um den Reverbeffekt in einem max 5x5m Raum bei einem erhöhtem Abstand vom Sprecher zum Mikrofon. Hier ist der Reverbanteil eher sehr kurz im ms Bereich. Andreas S. schrieb: > Echtzeit-Enthallung macht man eher nicht indem man versucht die > Impulsantwort zu entfalten, sondern dadurch dass man das Betragsspektrum > der Nachhallkomponente im STFT-Bereich schätzt und mit mit spektraler > Modifikation unterdrückt (z.B. > https://www.vocal.com/dereverberation/spectral-subtraction/). Das > schafft ein ARM Cortex locker. Allerdings ist es schwierig, dadurch für > normal hörende Menschen eine wirkliche Verbesserung der > Sprachverständlichkeit zu erreichen, da das menschliche Gehör das selbst > schon ziemlich gut hinkriegt. Danke für den neuen Ansatz. werde mir das mal durchlesen. Ja, es geht hierbei um eine gewisse "Hilfe" für den Hörer. Wenn es nicht 100% perfekt rausgefiltert wird, OK auch gut. Auf der Hardwareseite kann man das Signal schon bereinigen in dem man mehrere Mikrofone verbaut. Man kann hierbei auch filtern woher der Sprecher kommt(Beamforming) und die anderen Mikrofone zur Korrektur nutzen. Ich habe leider nur 1 Mikro verbaut.
Du möchtest jetzt einen kompletten Code in C für echo cancelling? Ich habe sowas mal gemacht, früher auch in C: http://www.96khz.org/oldpages/echocancelling2.htm muss Dir aber sagen, dass die Möglichkeiten begrenzt sind, auch wenn mit modernen DSPs sicher mehr geht, als zu meiner Zeit. Richtig gut geht es dann, wenn man den Raum kennt und einfache deutliche Echos herausfiltern kann.
Jürgen S. schrieb: > Du möchtest jetzt einen kompletten Code in C für echo cancelling? > > Ich habe sowas mal gemacht, früher auch in C: > http://www.96khz.org/oldpages/echocancelling2.htm > > muss Dir aber sagen, dass die Möglichkeiten begrenzt sind, auch wenn mit > modernen DSPs sicher mehr geht, als zu meiner Zeit. Richtig gut geht es > dann, wenn man den Raum kennt und einfache deutliche Echos herausfiltern > kann. Hi Nein keine Echocancellation. Diese läuft bereits und funktioniert wie sie soll. Sie filtert ja die rückgekoppelten Lautsprechersignale raus. Ich meine den effekt eines Mikros in einem Raum. Sprecher nah -> Verständlichkeit sehr gut, kaum Nachhall Sprecher weit -> Verständlichkeit lässt nach, nachhall ist im verhältnis zum Signal lauter
235456456455623563235235635 schrieb: > Nein keine Echocancellation. > Diese läuft bereits und funktioniert wie sie soll. > Sie filtert ja die rückgekoppelten Lautsprechersignale raus. Ich muss dazu glaube noch etwas sagen ... Das Gerät ist ein Wechselsprecher.
Jürgen S. schrieb: > Ich habe sowas mal gemacht, früher auch in C: > http://www.96khz.org/oldpages/echocancelling2.htm Aber das beschriebene dort trifft es quasi genau.
235456456455623563235235635 schrieb: > Ich meine den effekt eines Mikros in einem Raum. > > Sprecher nah -> Verständlichkeit sehr gut, kaum Nachhall Häh? Der viele Hall ist doch die Summe von Echos.
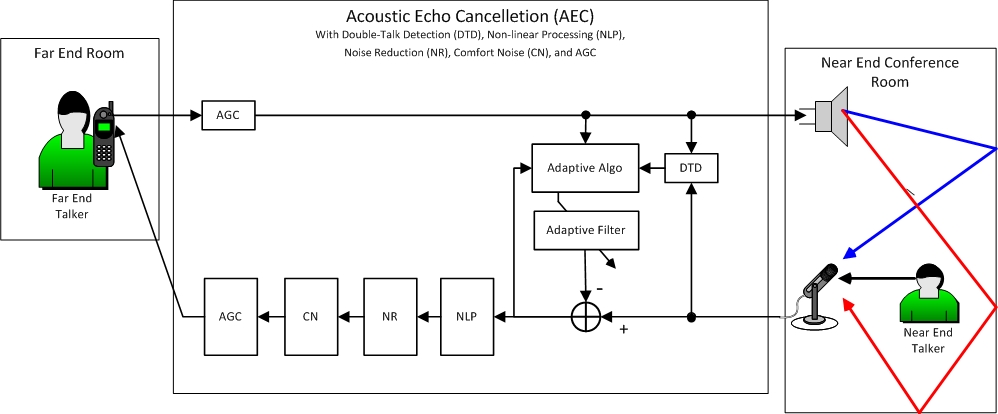
12345678981653184683154 schrieb: > Häh? Der viele Hall ist doch die Summe von Echos. Hmm .. So hatte ich das noch nicht gesehen, ist aber richtig. die aktuelle AEC ist eher so aufgebaut: http://q-syshelp.qschome.com/Content/Resources/Images/AEC_block_diagram_full.png Theoretisch sollte sie die Reflexionen auch rausrechnen können, tut dies aber scheinbar nicht ausreichend. Leider ist diese AEC eine lib die ich nicht einsehen darf/kann.
{kind=link}
Beitrag #5294084 wurde von einem Moderator gelöscht.
Kongo Bongo schrieb im Beitrag #5294084: > Wenn Dir DAS nicht klar, ist dann hast Du wenig Chancen, dem Thema näher > zu kommen. Das ist wie gesagt ein "kleiner" Teil eines Projekts. Da der Rest aber läuft und ich schon gern die Audioqualität verbessern wollen würde. Da ist die AEC als lib ( eingekauft... ) Habe daher mit DSP und Audioverarbeitung noch nichts gemacht im Sinne von selbst programmiert. Bis auf das Anpassen von Pegeln der Audiodaten und passender E/A(mit SAI und externem Codec) ist noch nicht viel passiert.
"Echo" und "Nachhall" sind in der akustischen Signalverarbeitung zwei völlig verschiedene Themen. - "Echo" ist ein bekanntes (!) Signal das durch den Raum beeinflusst und wieder vom Mikrofon aufgenommen wird. Es lässt sich meistens recht einfach durch ein lineares adaptives Filter modellieren und vom Mikrofonsignal subtrahieren. - "Nachhall" sind die Reflexionen eines unbekannten (!) Signals, d.h. des aufzunehmenden Sprechers. Da es keine Referenz gibt muss man hier versuchen, "blind" zwischen erwünschten (Direktschall) und unerwünschten Signalanteilen (Nachhall) zu trennen, was sehr viel schwieriger ist.
hi Andreas S. schrieb: > - "Echo" ist ein bekanntes (!) Signal das durch den Raum beeinflusst und > wieder vom Mikrofon aufgenommen wird. Es lässt sich meistens recht > einfach durch ein lineares adaptives Filter modellieren und vom > Mikrofonsignal subtrahieren. JA, das funktioniert soweit Da das Signal zum LS ja bekannt ist, kann es vom Mikrofonsignal abgezogen werden.Das macht die AEC super. > - "Nachhall" sind die Reflexionen eines unbekannten (!) Signals, d.h. > des aufzunehmenden Sprechers. Da es keine Referenz gibt muss man hier > versuchen, "blind" zwischen erwünschten (Direktschall) und unerwünschten > Signalanteilen (Nachhall) zu trennen, was sehr viel schwieriger ist. Diesen effekt würde ich gern reduzieren. bzw keine cancellation... eine suppression würde genügen. hier finde ich oft nur "spectral subtraction" also ähnlich dem noise cancelling...
Jemand schrieb: > Ich meine den effekt eines Mikros in einem Raum. Doch, doch - genau das meine Ich. Man muss eben nach Identitäten suchen und genau deshalb wird es mit zu wenig DSP-Power schwierig bis unmöglich. Da muss sehr viel gefaltet und bewertet werden. Das Thema haben wir ja auch bei anderen Bereichen der Signalverarbeitung - nicht nur beim Audio, wobei Ich das auch beim Audio vorangestrieben habe:
Jürgen S. schrieb: > Doch, doch - genau das meine Ich. Man muss eben nach Identitäten suchen > und genau deshalb wird es mit zu wenig DSP-Power schwierig bis > unmöglich. Da muss sehr viel gefaltet und bewertet werden. Das Thema > haben wir ja auch bei anderen Bereichen der Signalverarbeitung - nicht > nur beim Audio, wobei Ich das auch beim Audio vorangestrieben habe: hi ist zwar nun schon älter... Aber ich versuche mich da erstmal einzulesen. Habe schon etwas experimentiert und auch grob herausgefunden wie man soetwas realisieren könnte. Leider habe ich momentan zu wenig zeit für DIESE Baustelle. Ich blaib aber mal am DSP und FIR/FFT thema dran. Das scheint ganz gut zu sein wenn man mal etwas mehr darüber bescheid weiß. Das ist mir momentan noch zu komplex.
Andreas S. schrieb: > - "Echo" ist ein bekanntes (!) Signal das durch den Raum beeinflusst und > wieder vom Mikrofon aufgenommen wird Das kann sich aber nur auf das beziehen, was aus dem Lautsprecher, also vom Gesprächsteilnehmer kommt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.