hallo das Crowdorakel von uC.net,
mir liegt ein interessantes PDF vor, von dem ich eigentlich simpel den
Text extrahieren moechte... geht aber nicht.
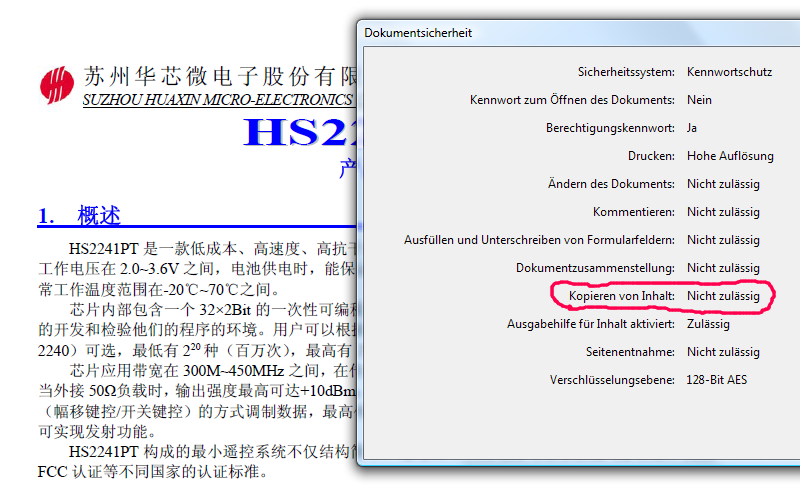
Nein: das PDF ist NICHT verschluesselt.
Ja: beim angucken am Bildschirm (z.B. in Firefox, Evince, XPdf) ist es
lesbar dargestellt.
Ja: es ist druckbar.
Nein: es enthaelt keine Bilder.
Nein: es ligt nicht am Tabellarischen layout. Haette ich zumindest den
Text braechte ich mit ScriptFu bestimmt was hin...
Was bisher scheiterte (alle produzieren nur Zeichensalat):
- pdftotext "pdftotext workcopy-11.pdf"
- ghostscript "gs -sDEVICE=txtwrite -o text.txt workcopy-11.pdf"
- abiword "abiword --to=txt workcopy-11.pdf"
- ebook-convert "ebook-convert workcopy-11.pdf text.txt"
LOWriter scheitert am "Insert".."Document" mit Fehlerdialog
"Libr...1.6.2 Read-Error. Error reading file."
(das Fenster laesst sich leider nicht vergroessern um den ganzen Titel
zu lesen!)
Im Anhang wie das Zeichensalatergebnis ausschaut.
Warum kein Anhang des Originals?
Weil es Telefonverbindungsdaten enthaelt. Zwar kein Staatsgeheimnis,
aber trotzdem.
Wer mich per PN kontaktiert um sich daran zu versuchen bekommt
natuerlich das Oginool.
Meine Bitte also: liest hier ein PDF-Guru mit, der sich daran
versuchen moechte? Er moege sich per PN zu erkennen geben - Danke.
Ich bekomme regelmäßig PDF Angebote die ich früher von Hand abtippen
musste um sie in unser SAP einzugeben (will der Einkauf so...). Bis ich
Evince als PDF-Reader entdeckt habe, der sich nicht um die
Adobe-PDF-Standards kümmert, in denen Copy&Paste bei meinen Dateien
verboten ist.
Wenn es also nicht Bilder sind, bei denen OCR die Lösung wäre, probier
das doch mal.
https://de.wikipedia.org/wiki/Evince
> probiere mal freeOCR! Holt text aus Grafik.> PDF to Word Converter
Danke aber sorry: kein Windows hier.
FreeOCR ist wohl nur free beer und Word nicht mal das... :-(
An den Weg via OCR habe ich zwar schon gedacht, aber muss das sein?
(wie ich bereits schrieb: es sind ohnehin keine Bilder im PDF
eingebettet. Ja, ich weiss: PDF malt halt die Buchstaben hin...)
Leo K. P. schrieb:>> Im Anhang wie das Zeichensalatergebnis ausschaut.>
pdftotext -enc encoding-name xy
Sets the encoding to use for text output. The encoding-name must be
defined with the unicodeMap command (see xpdfrc(5)). The encoding
name is case-sensitiv. This defaults to "Latin1" (which is a
built-in encoding). [config file: textEn-coding]
Leo K. P. schrieb:> An den Weg via OCR habe ich zwar schon gedacht, aber muss das sein?
Es ist dein Problem, du musst also entscheiden ob das sein muss.
Leo K. P. schrieb:> Ja, ich weiss: PDF malt halt die Buchstaben hin...
Eben drum, entweder du findest eine einfache Lösung oder du probierst es
via OCR.
Oder du tippst es ab ;)
Bei OCR könnten sich einige Erkennungsfehler einschleichen. Daher sollte
einen andere Lösung zuverlässiger sein. Falls der ganze Text sichtbar
ist: erst mal CTRL-A, dann CTRL-C und später mit CTRL-V wieder in ein
irgendwas.txt einfügen ging nicht? Mit Libreoffice ging auch nicht?
Sonst mal Originaldatei mit Editor ansehen was am Anfang steht. Evtl.
ist da ein hilfreicher Hinweis zu finden?
> Evince als PDF-Reader entdeckt habe, der sich nicht um die
uups, sorry nochmals. Evince ging in der Liste vergessen.
Evince ist auch mein standard PDF-Betrachter und ich kann darin zwar per
Maus Text selektieren, bekomee beim Pasten im Editor aber ganz
aehnlichen Zeichensalat wie bei den versagenden Konvertierprogramme.
Als Notnagel wuerde ich Maus/Copy/Paste nehmen weil solchein Dokument
1x/Monat eintrudelt. Eine CLI-basierte Loesung ziehe ich aber definitiv
vor.
> pdftotext -enc encoding-name xy
Danke fuer den Hinweis, hilft aber auch nicht.
oszi40 schrieb:> Sonst mal Originaldatei mit Editor ansehen was am Anfang steht. Evtl.> ist da ein hilfreicher Hinweis zu finden?
Die Textdaten sind sehr wahrscheinlich komprimiert. Sieht man am letzten
Beitrag.
Und dann scheint jeder Buchstabe oder mindestens jedes Wort direkt
grafisch positioniert zu sein. Ohne eine genaue Analyse ist das also
nicht einfach mit copy&paste übertragbar.
Da müsste man sich schon ein Programm schreiben.
Ich habe vor vielen Jahren mal einen Generator geschrieben, das interne
PDF Format ist echt kein Spass.
oszi40 schrieb:> ist: erst mal CTRL-A, dann CTRL-C und später mit CTRL-V wieder in ein> irgendwas.txt einfügen ging nicht? Mit Libreoffice ging auch nicht?>> Sonst mal Originaldatei mit Editor ansehen was am Anfang steht. Evtl.> ist da ein hilfreicher Hinweis zu finden?
Remove the password and restrictions of PDF files online:
https://crackmypdf.com/https://www.pdfunlock.online/
Das wird wahrscheinlich alles nicht sonderlich viel bringen, da der Text
vermutlich mit einem "Embedded Subset" des Fonts abgespeichert wird.
Zur Verdeutlichung des Prinzips:
Hallo -> ASCII -> 72 97 108 108 111
Dafür müssen jetzt natürlich alle Zeichen bis 255 vorliegen. Also baut
sich der PDF-Generator seinen eigenen Font:
1 -> H, 2 -> a, 3 -> l, 4 -> o
Hallo --> 1 2 3 3 4
Und im nächsten Abdatz steht "Hallo du" und weil das mit dem
Komprimieren so toll funktioniert, wird das auch noch Abschnittsweise
gemacht:
1 -> " ", 2 -> H, 3 -> a, 4 -> d, 5 -> l, 6 -> o, 7 -> u
Hallo du --> 2 3 5 5 6 1 5 7
Für den dekodierenden pdf-Viewer ist das alles kein Problem, da ja das
korrekte Zeichen für den im jeweiligen Abschnitt gültigen Code
hinterlegt ist.
Kopier man allerdings daraus, hat man (ASCII 0 bis 7) unsichtbare
Steuerzeichen bis totalen Zeiochenmüll. Und das meist auch nicht
durchgehen gleich, sonst könnte einfach bspe. 65 addiert werden.
Das ist ein Problem, das mir auch schon das eine oder andere Mal
Kopfschmerzen beschert hat und wenn jemand eine Lösung hat: Her damit!
Entweder liegts an der Schrift, oder der "unterliegende Text" ist
verschlüsselt.
Die Lösung ist ein OCR-Tool zu verwenden, z.Bsp. tesseract (frei).
Ich würde mich auch um eine Zusendung freuen.
Bei Tesseract musst du nur vorher die Seiten teilen (pdftk), in ein Bild
(png) wandeln (gs / imagemagick), dann tesseract -l deu XXX.png XXX.pdf,
und schließlich wieder zusammenfügen.
Ich hab dafür ein Online-Tool gebaut dessen URL ich auf PM mitteilen
kann.
> Remove the password and restrictions of PDF files online:> Entweder liegts an der Schrift, oder der "unterliegende Text" ist> verschlüsselt.
wie ich bereits im ET schrieb: das PDF is NICHT verschluesselt.
1
$ pdfcrack -o workcopy-11.pdf
2
Error: Encryption not detected (is the document password protected?)
3
$
-|- -|-
Mittlerweile habe ich auch mit Inkscape rumgemacht.
Plumpes oeffnen ergibt "nix" ausser 4 Dekolinien, jedoch definitiv kein
Text.
So man beim Importdialog die Option "use Poppler" anwaehlt, bekommt man
ein Rendering des PDFs in das Inkscape Dokument. Hierbei handelt es
sich aber um eine Pixelwueste, also ein PNG-Abbild des Textes.
Also dasselbe wie
> Bei Tesseract musst du nur...
ein erster, plumper Versuch mit tesseract verlief seehhr ernuechternd
:-/
Das Ergebnis im Anhang: weder Tel.Nummern noch Datum noch Zeiten wurden
erkannt. Der Rest des Textes besteht eigentlich aus einem sehr sehr
eingeschraenkten Vokabular (im Schnellueberflug zaehle ich gerade mal
nur 24 einzigartige Woerter).
1
$ convert workcopy-11.pdf abbild-11.png
2
$ tesseract -l deu abbild-11.png tesseract-11.txt
3
$
Harter Einsieg in OCR...
OK: die Bilddatei abbild-11.png ist vllt. etwas klein geraten und schaut
aus wie ein Fax (ausgefranste Zeichen) - ich mach nochmal 'ne Runde...
Leo K. P. schrieb:> ein erster, plumper Versuch mit tesseract verlief seehhr ernuechternd
Hi, ich hatte dir per Mail mein (sehr brauchbares) Ergebnis mit
Tesseract geschickt. Evtl. ist es im Spam gelandet (anderer
Absenderadresse).
Leo K. P. schrieb:
> Ja: es ist druckbar.
Zum 2. und letzten Mal: Dann druck es halt als Text-Datei.
Falls Du nicht weisst, wie so etwas geht - suche mal nach
"Generic"-Druckern.
Soeren K. schrieb:> Hi, ich hatte dir per Mail mein (sehr brauchbares) Ergebnis mit> Tesseract geschickt.
hi Soeren,
Besten Dank, das ist angekommen (nix spam) und insofern perfekt
gelungen das nun pdftotext korrekten Text extrahiert.
(die diversen Spalten sind nun untereinander, ich muss also die Zeilen
wieder rekonstruieren. Das soll nun aber nicht mehr Dein Problem sein
und auch nicht Diskussionsgegenstand in diesem Thread)
Du schreibst Du hast das mit tesseract erzielt. Also sollte ich das
doch offline bei mir auch erreichen... (ich mag online-Dienste nicht
und Du nicht monatlich Post von mir :-)
Ist Dir Font-mässig irgendwas aufgefallen? Wie ich weiter oben
schrieb, ist bei mir die Anzeige am Bildschirm so "Fax-Mässig"; dies
scheint ebenfals auf die Bildzwischenstufe welche ich per convert
produziere zuzutreffen.
Ich kann jedoch nicht eruieren welchen Font ich ggfs. nachinstallieren
soll...
Gruss,
Leo
Teste bitte mal:
--> png erstellen mit imagemagick und 200dpi
convert -density 200 -flatten pdfdatei.pdf pngdatei.png
tesseract -l deu pngdatei.png pdfdatei-neu pdf
Ich habe das unter Ubuntu schon mit
pdftoppm xxxxxxx.pdf pdfimg -png
und anschließendem gimagereader versucht. Da kommt leider nur reiner
Text und einige Lesefehler, aber besser als nichts.
pdftotext -listenc
List the available encodings
Evtl. gibt die Ausgabe von "pdffonts" Hinweise ob das loesbar ist.
The pdffonts tool, also part of Xpdf, will list all of the fonts used by
a PDF file, along with their types, whether the fonts are embedded or
not, and whether the fonts have ToUnicode mappings or not
aus https://www.glyphandcog.com/textext.html
Wenn ich das jetzt richig verstanden habe, sind die im pdf
mitgelieferten Fonts das Problem. Diese einfach gegen z.B. Arial
auszutauschen wird oft schief gehen, wenn die Zeichen andere Breite
haben. Dann stimmt keine Tabelle und kein Rand.
Wahrscheinlich ist wie oben genannt der "Druck in eine Datei" die
einfachste Variante zur späteren Bearbeitung?
> Abhilfe gibt es über den Umweg PDF->PS->PDF:pdf2ps vorher.pdf - | ps2pdf> - nachher.pdf>> Aus dem erzeugten PDF sollte nun der Text extrahiert werden können.
sehr interessant, klapp jedoch hier leider auch nicht.
Das Ergebnis ist (selbst auf der Systemkonsole!) als waere es in
Zapfdingbats o.ae. Symbolschrift geschrieben (Sterne, Schere, Dreieck,
Kreis, usw.) :-/
-|- -|-
Fontextraktion:
> Hier gibts Vorschläge wie man dem evtl. beikommen könnte:>
<https://stackoverflow.com/questions/3488042/how-can-i-extract-embedded-fonts-from-a-pdf-as-valid-font-files>;
Volgende Versuche sind GESCHEITERT:
- gs mit extractFonts.ps
- fontforge (core dump!)
Bei pdf2ps bin ich zu wenig fluessig in PS um das gemaess Angabe von
Hand im Editor rauzudroeseln. Zu sehen sind 160 Zeilen mit
1
%%BeginResource: file (PDF CharProc obj_32)
zu finden, wobei die "Zahl" bei obj_xx mit wenigen luecken von 10..167
geht. Das duerften die Zeichendefinitionen des irgendwie eingebetteten
und namenlosen Fonts sein.
Den weg mit *pdf-parser.py* braucht etwas mehr Zeit und Einarbeitung...
OT:
Leo K. P. schrieb:> Den weg mit *pdf-parser.py* braucht etwas mehr Zeit und Einarbeitung...
haha: geiles Markup-Rendering hier ;-) Weiss das der Chef?
oszi40 schrieb:> Wahrscheinlich ist wie oben genannt der "Druck in eine Datei" die> einfachste Variante zur späteren Bearbeitung?
Ich weiss genau was Dieter Quackenbusch meint; unter Windows.
Ich habe jedoch kein Windows hier (Zum 2. und letzten Mal)
Ich bekomme zwar ein "Generic Printer" (Text-only) eingerichtet, jedoch
NUR im zusammenhang mit einer echten SCHNITTSTELLE.
In den zugehörigen Druckdialoge ist dann nichts von "umleitung in Date"
o.Ä. zu finden.
Natuerlich finde ich einen voreingerichteten virtuellen Drucker: diese
ist aber NICHT "text-only" sondern erzeugt PDFs. Ich starte ja bereits
mit PDF!!!
Moment mal: nach dem Hinweis zur Deutschen Bank muss ich nun was
probieren gehen...
Leo K. P. schrieb:> Natuerlich finde ich einen voreingerichteten virtuellen Drucker: diese> ist aber NICHT "text-only" sondern erzeugt PDFs. Ich starte ja bereits> mit PDF!!!
Das PDF durch den PDF-Drucker zu jagen wäre aber auch mal einen Versuch
wert.
Leo K. P. schrieb:> Moment mal: nach dem Hinweis zur Deutschen Bank muss ich nun was> probieren gehen...
Nein: das original-PDF via virtuellen PDF-Drucker gedruckt und dann
durch pdftotext ergibt genauso Buchstabensalat.
Sinnloses probieren mit den auf diesem Weg selektierbaren Varianten
-->PS oder -->SVG bleibt wohl ...sinnloses probieren.
oszi40 schrieb:> Ganz dumm gefragt: Kann der Erzeuger kein besseres Format liefern?
Die Antwort lautet soweit:
"Wegen 1 Kunde stellen wir nicht den ganzen Prozess um."
Bedenke: das sind die Telefonverbindungsdetails; diese werden sicher
nicht durch Mausschubser fuer jeden Kunden einzeln angefertigt sondern
werden aus dem "Telefonnetz" automatisch generiert.
Das Dokument scheint (zumindest mir als nicht in der Druckbranche
heimischen) mit dem gleichen Font gesetzt zu sein wie andere
Korrespondenz der Firma, nichtmal ein firmenspezifischer Briefkopf ist
da drin.
Bis letzthin wurde dies auf Papier per Brief zugestellt - neu muss ich
als Kunde dies selber als PDF abholen.
Ich freute mich dass ich nun dank el.Format (eben PDF) eigene
Auswertungen skripten kann - leider Fehlanzeige solange ich nicht
irgendwie an den Text gelange.
Ausser ich mache dies per OCR, was sich jedoch ABSURD anfuehlt da im PDF
eben gar kein BILD drin steckt...
So langsam glaube ich an "EDV == Ende" Der Vernunft.
Soeren K. schrieb:> Teste bitte mal:>> --> png erstellen mit imagemagick und 200dpi>> convert -density 200 -flatten pdfdatei.pdf pngdatei.png> tesseract -l deu pngdatei.png pdfdatei-neu pdf
SEHR GUT :-)
ich habe eine kleine Versuchsreihe gemacht:
tesseract -l deu stdin convert__dens${DENS}-11.txt
5
done
6
$
7
$ wc -l convert__dens*txt
8
79 convert__dens100-11.txt
9
82 convert__dens150-11.txt
10
74 convert__dens200-11.txt
11
76 convert__dens220-11.txt
12
72 convert__dens250-11.txt
13
345 convert__dens280-11.txt
14
354 convert__dens330-11.txt
15
347 convert__dens400-11.txt
16
1429 total
17
$
hierbei unterscheiden sich die Ergebnisse mit 200/220/250 dpi
untereinander nur in ein paar LEERZEILEN :-) der erkannte Text ist in
diesen 3 Dateien IDENTISCH, korrekt (Stichprobe) UND die Datenzeilen
bleiben erhalten (kein um-zu-ordnen der Spalten noetig).
Hoehere Zahl an dpi bringt nur wieder die Spalten untereinander, was
ich separat wieder umordnen muesste.
An dieser Stelle ein grosses Dankeschön an alle welche konstruktiv
in diesem Thread an meinem Problem mitgemacht haben, insbesondere an
Soeren: von ihm kam entscheidende Unterstuetzung zu meinen ersten
Gehversuche in OCR.
-|- -|-
Natuerlich empfinde ich es als aergerlich ein elektronisches Dokument
(PDF) geliefert zu bekommen welches Text (keine Bilder) enthaelt, dieser
Text sich aber nur ab Bildschirm/Papierdruck abgelesen weiterverwenden
laesst.
Dass nun OCR abhilfe bringt ist zwar ein Zeugnis der Leistungsstärke
heutiger Algorithmen, in diesem Einsatz jedoch bleibt mir der schale
Nachgeschmack von "mit Kanonen auf Spatzen geschossen" zu haben.
Der Umweg über die OCR ist eine Notlösung: Analogisierung und dann
wieder Digitalisierung.
Das digitale Dokument wird vom PDF-Reader richtig dargestellt, also muss
das Dokument die Codierungsinformation enthalten, also muss es möglich
sein, das Dokument digital bearbeiten zu können.
Oder irre ich mich?
Georg: Das digitale PDF wird analog vom PDF reader gerendert
(analogisiert sozusagen), dem ist es ziemlich egal was der Mensch da
sieht.
Wenn da ein Customfont in dem PDF steckt, dann kann jedes Teichen
sonstwas sein.. Ein Smiley, ein Buchstabe, eine Ziffer. Aber eben nicht
was z.b. Unicode vorgibt. Oder gleich Codepunkte im Unicode die dafür
reserviert sind. Ohne OCR: Keine Chance.
Wenn der Font immer konstant ist (könnte ja für jedes PDF neu
verschwurbelt werden), dann könnte man theoretisch einmal mühselig das
Mapping herausfinden (kann man gaaaaanz theoretisch mittels OCR
automatisieren, bloß wieso?) und dann einfach über eine Mappingtabelle
zurückmappen. Aber dann kommt jemand auf die Idee gleich nur noch
Glyphen als Grafikbefehle in das PDF zu klatschen, dann ist aber ganz
vorbei.
Das passt schon so mit dem OCR, besonders weil es ja kein Scan sondern
ein digitial gerendertes Bild ist, wenn man den OCR Reader da auf den
Font trainiert, dann kann das am Ende perfekt klappen.
Leo K. P. schrieb:> An dieser Stelle ein grosses Dankeschön
Gern.
Ansonsten: So wie ich den Header/ die strings (bash: strings XXX.pdf)
der Datei gedeutet habe wird die mit hornalter (2005) Sofware erstellt,
leider fehlt mir da der Hintergrund was da genau passiert, ich vermute
aber auch einen Zusammenhang mit der Schriftart. Sicher kann man da über
Umwege und der Font wieder zurückkommen - doch warum wenn es so
funktioniert. Nur für den Ehrgeiz? Da bin ich leider raus, verfolge das
Thema aber gerne lesend weiter.
PS: Wenn du sowas oder andere "Konvertierungen" professionell brauchst,
mit API und SLA --> PM ;-)
Leo K. P. schrieb:> Bedenke: das sind die Telefonverbindungsdetails;
Ich weiß zwar nicht, ob ich dein Problem richtig verstanden habe.
Du hast also nur Text, keine Bilder.
Dann öffne es doch mal im FF PDF-Reader.
Dort markierst du mit der Maus den Text, kopieren, Wordpad oder besser
Excel öffnen, einfügen.
Die Formatierung ist natürlich weg.
michael_ schrieb:> Dort markierst du mit der Maus den Text, kopieren
Ähnlicher Vorschlag stand schon ganz oben.
Risikobetrachtung: Was ich zu OCR noch ergänzen wollte: eine 99%ige
Erkennung heißt, daß die hundertste Zahl falsch sein könnTe! OCR
erreicht teilweise erst durch Wörterbücher eine gute Erkennungsrate. Ob
aber in einer Statistik 456 oder 567 Bockwürste verkauft wurden steht in
keinem Wörterbuch.
oszi40 schrieb:> Bei OCR könnten sich einige Erkennungsfehler einschleichen. Daher sollte> einen andere Lösung zuverlässiger sein. Falls der ganze Text sichtbar> ist: erst mal CTRL-A, dann CTRL-C und später mit CTRL-V wieder in ein> irgendwas.txt einfügen ging nicht? Mit Libreoffice ging auch nicht?
Meinst du das?
Die Tastaturkürzel hab ich überlesen. Ich bin ein Mausmensch.
Mit der Maus kann man aber unbeliebte Inhalte umgehen.
Libreoffice und FF PDF-Reader sind sicher verwandt.
Sollte aber gehen.
Georg M. schrieb:> michael_ schrieb:>> Sollte aber gehen.>> An diesem PDF-File kann man üben:
pdffonts BRAK_2015_01.pdf
name type emb sub uni
object ID
AdvPS_ZD-Identity-H CID Type 0C yes no no
1989 0
AdvPS4C993D-Identity-H CID Type 0C yes no no
1992 0
AdvPS4C9939-Identity-H CID Type 0C yes no no
1995 0
AdvPS4C96C8-Identity-H .....
... 94 weitere! ...
Was ueben, scannen :)
https://en.wikipedia.org/wiki/PostScript_fonts#CID
"CID-keyed fonts may be made without reference to a character collection
by using an "identity" encoding, such as Identity-H (for horizontal
writing) or Identity-V (for vertical). Such fonts may each have a unique
character set, and in such cases the CID number of a glyph is not
informative;"
wenn es keine Uebereinstimmung mit verbreiten Zeichensaetzen gibt, bspw.
das nicht ascii-basiert ist da gibt es ja eine Schnittmenge mit z.B.
windows1255, UTF-8, UTF-16 usw. was die Zahlen und das Alphabet
anlangt, dann kommt doch idR. nichts interpretierbares beim copy und
paste raus.
> An diesem PDF-File kann man üben:> http://www.brak-mitteilungen.de/media/BRAK_2015_01.pdf
Was machen eigentlich screenreader mit solchen verklausulierten PDFs?
Sind solche PDFs überhaupt noch barrierefrei und für Sehbehinderte
zugänglich? Nur via OCR mit Restrisiko von Fehldeutungen?
ich hab versucht mit iText den text aus dem PDF zu extrahieren, hab aber
auch nur schrott raus bekommen.
im nächsten versuch habe ich versucht ein PDF1.4 aus dem inhalt des
originals zu erzeugen, und daraus den text zu extrahieren - selbes
ergebnis.
ich vermute jetzt mal ins blaue hinein, dass der inhalt der
originaldatei kein text ist, sondern in irgendeiner art bilder mit
positionierungsverweisen.
c.m. schrieb:> auch nur schrott raus bekommen.
Diese Test-pdf-Datei bringt spezielle Fonts mit. Auch markieren ging in
die Hose. Hat schon mal einer den Text maschinell vorlesen lassen? Wäre
für Sehbehinderte sicher interessant.
> Mit der Maus kann man aber unbeliebte Inhalte umgehen.
nicht in meinem Fall: wie ich bereits im gestrigen Post von 12:23
beschrieben habe. Mausefalle = Mouse FAIL.
> Libreoffice und FF PDF-Reader sind sicher verwandt.
FALLS die Verwandtschaft zutreffen sollte, WÜRDEN beide auch unter den
selben Limitierungen leiden.
> Sollte aber gehen.
Haette, Taete und Sollte - 3 Brueder die gingen zusammen ...den Bach
runter.
> Wäre für Sehbehinderte sicher interessant.heisser Aspekt der Sache!
c.m. schrieb:> ich vermute jetzt mal ins blaue hinein, dass der inhalt der> originaldatei kein text ist, sondern in irgendeiner art bilder mit> positionierungsverweisen.
Falsche Vermutung.
Zumindest kann pdfimage zwar an die 270 Bilder extrahieren, nach
kurzer Schnellsichtung sind dies jedoch echte Bilder (Deko, Hintergrund,
Kunstvolle Überschriften, usw.) und haben nix mit dem Text an sich zu
tun.
1
$ pdfimages -list BRAK_2015_01.pdf
2
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size ratio
Da es sich um ein Dokument aus Anwaltsdunskreisen handelt, wuerde ich
mich nicht mal wundern wenn eine Weile nach Druck auf Papier sich auch
noch die Tinte verfluechtigt... nach e-Ink ist das dann der A-Ink ;-)
Zitat:
"Often this is done on purpose. I have seen documents that randomly
remap characters differently for each font in the dot. It is used as a
form of obfuscation and the only real way to extract text from these
PDF's is to resort to OCR. There are many financial reports that use
this type of trick to stop people from extracting their data.
Also, Identity-H is just a 1:1 character mapping for all characters from
0x0000 to 0xFFFF. ie. Identity is an identity mapping.
Your real problem is the missing /ToUnicode entry in this PDF. I suspect
there is also an embedded CMap in your PDF that explains why there could
be 3 bytes per character."
https://stackoverflow.com/questions/17193839/where-can-i-a-mapping-of-identity-h-encoded-characters-to-ascii-or-unicode-chara
nun, das Dokument scheint vor 15 Jahren mit Ghostscript unter Unix und
LaTex oä. erstellt worden zu sein.
Es hat keine Restriktionen, mit Schrifttyp 3.
Konnte nichts mit Copy und Paste erreichen. Einzig in Acrobat unter OCR
das hat funktioniert und als Docx Datei abgespeichert. Ein bischen
holprig, aber wenn man es 3 x gemacht hat dauert es keine 3 Min.
es sieht doch eher so aus als wäre der Text in Bitmap
(Raster Fonts)umgewandelt worden.
Da wird es mit dem extrahieren und copy and paste wohl nichts, eher nur
mit dem OCR Verfahren funktionieren.
Hab mir mal die Seite von Tom Rokicki und seiner Radical Eye Software
angeschaut. Interessant
https://en.wikipedia.org/wiki/Dvipshttp://tug.org/texinfohtml/dvips.htmlhttp://www.radicaleye.com/
When producing postscript files, dvips embeds fonts inside the file.
Most recent distributions will normally embed scalable fonts, also known
as Type 1 fonts. Files generated with older distributions, however, may
embed raster fonts. To substitute raster for scalable fonts in a
postscript file in a situation where the original dvi file is
unavailable use a utility called pkfix.
Leo K. P. schrieb:> Natuerlich empfinde ich es als aergerlich ein elektronisches Dokument> (PDF) geliefert zu bekommen welches Text (keine Bilder) enthaelt, dieser> Text sich aber nur ab Bildschirm/Papierdruck abgelesen weiterverwenden> laesst.Leo K. P. schrieb:> Falsche Vermutung.> Zumindest kann pdfimage zwar an die 270 Bilder extrahieren, nach> kurzer Schnellsichtung sind dies jedoch echte Bilder (Deko, Hintergrund,> Kunstvolle Überschriften, usw.) und haben nix mit dem Text an sich zu> tun.
Von was redest du nun?
Was ist dein .PDF?
Ich habe jetzt nochmal ein PDF im AR X aufgemacht.
Mit der Maus kann man nichts markieren. Aber alles.
Das habe ich nun in Wordpad und Libre Writer (3.4) eingefügt.
Die Bilder sind weg.
Aber die Formatierung, Schriftgröße, Fett usw ist alles noch da.
Und unter AR X kann man das PDF als Text speichern. Da sind dann
Formatierungen usw. alle weg.
Mehr kann man eigentlich nicht verlangen.
Im AR wird noch die Umwandlung in Word/Excel angeboten.
Allerdings nur Online.
Sicher nicht umsonst.
Wer noch mehr will, installiert eben den Adobe Acrobat.
Um die Monster PDF vom Georg geht es doch hier nicht.
Das ist nicht der Maßstab!
Ich hab zwei genommen, einmal ein Beschreibung von KiCad und noch eine.
Auf einem anderen Rechner.
Auf dem jetzigen PC:
Hier hat allein das abspeichern ca 4min. gedauert!
Leider habe ich hier kein Office
Die Zeichen sind nicht im Umfang von Wordpad drin.
Irgend ein spezieller Zeichensatz.
Klaus forrestjump, ich danke Dir auch fuer die Analyse.
> nun, das Dokument scheint vor 15 Jahren mit Ghostscript unter Unix und> LaTex oä. erstellt worden zu sein.
Ja, sowas erzaehlt pdfinfo.
> Es hat keine Restriktionen, mit Schrifttyp 3.> Konnte nichts mit Copy und Paste erreichen. Einzig in Acrobat unter OCR> das hat funktioniert und als Docx Datei abgespeichert. Ein bischen> holprig, aber wenn man es 3 x gemacht hat dauert es keine 3 Min.
Nochmals Danke fuer deine Zeit.
Dein OCR ist in der Tat etwas holprig: viele "0" wurden als "D"
uebernommen.
Dank Sören habe ich den Schuloeffel zu OCR mit tesseract gefunden
und da ist die Trefferquote hoeher. (s. o.)
Ich werde spaeter noch Versuche anstellen mit vorgegebenem Wörterbuch
weil in diesen Tabellendaten keine Prosa vorkommt.
Die beste Vorbereitung fuer OCR ist wohl der "Richtige[TM]" Satz an
parameter fuer convert ; ein dicker Brocken wenn man nicht aus der
Druck-/Bildbearbeitungsbranche kommt...
Klaus B. schrieb:> Hab mir mal die Seite von Tom Rokicki und seiner Radical Eye Software> angeschaut. Interessant
Interessant in der Tat: so kommen die Erklaerungen zusammen :-)
pkfix will ich auch noch probieren. Fuer 12kB "Perlscript"
installieren sich gerade 600MB an neue Pakete...
Die Hoffnung dass dies noch was bringt habe ich jedoch an einem
kleinen Ort.
michael_ schrieb:> Im AR wird noch die Umwandlung in Word/Excel angeboten.> Wer noch mehr will, installiert eben den Adobe Acrobat.Ganz sicher auf Linux.
Wer lesen kann ist klar im Vorteil.
michael_ schrieb:> Leo K. P. schrieb:>> Natuerlich empfinde ich es als aergerlich ein elektronisches Dokument>> (PDF) geliefert zu bekommen
:
> Von was redest du nun?> Was ist dein .PDF?meine Datei welche ich wegen Datenschutz nicht hier im Forum
beifuege.
> Leo K. P. schrieb:>> Falsche Vermutung.>> Zumindest kann pdfimage zwar an die 270 Bilder extrahieren, nach
:
> Von was redest du nun?> Was ist dein .PDF?
die verlinkte von BRAK.
Ich bitte um Entschuldigung fuer die Verwirrung.
Frei nach G.Orwell "alle PDF sind gleich, nur einige sind gleicher.".
Der Fokus dieses Threads ist wie man bei solchen "gleicheren" PDFs an
den Text gelangen kann.
michael_ schrieb:> Um die Monster PDF vom Georg geht es doch hier nicht.> Das ist nicht der Maßstab!
Natürlich ist das der Maßstab.
Es geht nicht darum, stinknormale Standard-PDF-Dateien zu verarbeiten.
Das funktioniert, das ist bestens bekannt, dafür gibt es zig Tools. Bei
stinknormalen Standard-PDF-Dateien steht der Nutztext als lesbarer Text
in der Datei drin.
Hier geht es aber um PDF-Dateien, bei denen der Nutztext eben nicht als
lesbarer Text drinsteht, und bei denen jedes Tool zur Textextraktion
versagt, das nicht OCR verwendet.
Wie solche PDF-Dateien funktionieren, ist auch klar: Der zur Anzeige
verwendete Font wird auf eine eigene Zeichenbelegung heruntergebrochen
(nämlich nur die Zeichen, die tatsächlich verwendet werden), die
Zeichencodes neu numeriert und der Text in diese neue, individuelle
Codierung übersetzt.
Beispiel:
Es werden ausschließlich die Ziffern von 0-9 und der Dezimalpunkt
dargestellt.
Der reduzierte Zeichensatz enthält also nur die Glyphen . und 0-9. Diese
elf Zeichen werden mit den Zeichencodes 0-10 neu belegt, und zwar so:
. = 0
0 = 1
1 = 2
2 = 3
...
9 = 10
Soll nun der Text "123.45" im Dokument codiert werden, steht dort nicht
die Zeichenfolge 0x31 0x32 0x33 0x2e 0x34 0x45, sondern die Zeichenfolge
0x02 0x03 0x04 0x00 0x05 0x06
Das entscheidende ist: Die Tabelle oben ist nirgends im Dokument
enthalten, sie geht bei der Dokumentenerstellung verloren und kann nur
durch Analyse der den Zeichencodes zugeordneten Bilder (Glyphen)
rekonstriuert werden.
Wird es klarer?
Rufus Τ. F. schrieb:> Das entscheidende ist: Die Tabelle oben ist nirgends im Dokument> enthalten, sie geht bei der Dokumentenerstellung verloren und kann nur> durch Analyse der den Zeichencodes zugeordneten Bilder (Glyphen)> rekonstriuert werden.
Im Prinzip ja. Offenbar kann man die Tabellen bei Verwendung bekannter
Fonts rekonstruieren. Ich vermute, dass das in meinem Fall
(Kontoauszüge, s.o) erfolgreich war.
Ich habe dieses BRAK PDF mal durch Tesseract (ältere Version) mit
deu+eng gejagt, gerendert wird das Ganze in Java mit PDFBox mit
Antialiasing an und automatischem Kontrast, der Extrakt ist sehr gut
(war zu erwarten, ist ja kein Scan).
Um Ärger mit Anwälten zu vermeiden als Zitat nur mal die Werbanzeige auf
Seite 5:
"www.volkswagen.de/selbststaendige
Steigern Sie Ihr Potenzial. Mit Professional Class. Volkswagen für
Selbstständige.
Ihr täglicher Antrieb sind maßgeschneiderte Lösungen, die Sie Ihren
Kunden garantieren. Und genau das bieten wir Ihnen auch — mit
Professional Class. Profitieren Sie von der attraktiven,
modellabhängigen Prämie und kommen Sie in den Genuss zahlreicher
Vorteile beim GeschäftsfahrzeugLeasing. Das Plus zu Ihrem Leasingvertrag
sind folgende
komfortable Mobilitätsmodule:
0 Wartung 8c Verschleiß-Aktion ° ReifenClever-Paket 0 KaskoSchutz °
Europa Tank 8c Service Karte Bonus 0 HattpflichtSchutz
Kraftstoffverbrauch des GolfVariant in 1/100 km: kombiniert 5,3-3,3,
COz-Emissionen in g/km: kombiniert 124-87.
Professional Class Volkswagen für Selbstständige Das Auto.
Wartung & Verschleiß-Aktion, KaskoSchutz‚ HaftpflichtSchutz (nur in
Verbindung mit KaskoSchutz‚ Leistungen gem. Bedingungen der Allianz
Versicherungs-AG), ReifenClever-Paket (verfügbar für ausgewählte
Modelle), Europa Tank & Service Karte Bonus jeweils nur in Verbindung
mit GeschäftsfahrzeugLeasing der Volkswagen Leasing GmbH, Gifhorner Str.
57, 38112 Braunschweig. Bonität vorausgesetzt. Prämie erhältlich bei
nahezu jeder Neuwagenbestellung. Professional Class ist einAngebot für
alle Selbstständigen. Einzelheiten zur jeweils erforderlichen
Legitimation erfahren Sie bei Ihrem teilnehmenden Volkswagen Partner.
Abbildung zeigt Sonderausstattung gegen Mehrpreis."
Das passt schon einigermaßen
Leo K. P. schrieb:> michael_ schrieb:>> Im AR wird noch die Umwandlung in Word/Excel angeboten.>> Wer noch mehr will, installiert eben den Adobe Acrobat.>> Ganz sicher auf Linux.> Wer lesen kann ist klar im Vorteil.
Erstens ist das dein Problem!
Und du meinst, dass du keine Word/Excel Dateien mit irgendeinen
LINUX-Programm aufmachen kannst?
Dann lerne es.
Leo K. P. schrieb:> meine Datei welche ich wegen Datenschutz nicht hier im Forum> beifuege.
Die will ich auch nicht sehen.
Du hast aber zwei Beispiele angeführt.
Wenn es der zuerst genannte Verbindungsnachweis ist, ist das Ziel
erreicht.
Wenn man die Schrift:
AdvPS4C9939-Identity-H
Mit 10,5, 7,5 usw.
hat, dann kann man auch das BRAK lesen.
Wegen der Bindestriche ist vermutlich das Anwalts-BS ein UNIX.
Rufus Τ. F. schrieb:> michael_ schrieb:>> Um die Monster PDF vom Georg geht es doch hier nicht.>> Das ist nicht der Maßstab!>> Natürlich ist das der Maßstab.>> Es geht nicht darum, stinknormale Standard-PDF-Dateien zu verarbeiten.
Doch.
Es ist ja wie zu oft hier, dass vom ursprünglichen Thema abgewichen wird
und ausufert zu Extrembeispielen.
Im Anhang noch das KiCad Beispiel.
michael_ schrieb:>> Wenn man die Schrift:>> AdvPS4C9939-Identity-H> Mit 10,5, 7,5 usw.>> hat, dann kann man auch das BRAK lesen.
Das stimmt doch aber gerade nicht. Zumal es garkeine AdvPS4C9939 gibt,
das ist ein dem Konstrukt zugewiesener Name.
how about man schrieb:> michael_ schrieb:>>> Im Anhang noch das KiCad Beispiel.>>> was soll das sagen?>> Das ist anders. 9 der 11 Schriften haben ein code-mapping.
Nicht code vermutlich wird cmapping character-mapping heissen, ist aber
egal.
Versuch mal zu verstehen was der hier per java macht:
https://stackoverflow.com/a/39644941
---
Muss sich aber schon um etwas besonderes handeln das immer wieder kehrt
als das man den Aufwand treibt. Z.B. die Kontoauszuege.
Aber das ist genau das was den Threadersteller eben beschaeftigt.
hallo zusammen,
kann man denn jetzt,zeilen oder nummern von einer telekom evn pdf
entfernen oder löschen?
oder geht das nicht?
für eure hilfe wäre ich dankbar!!!