Hi Leutz!
Ich habe einen CIC Filter in VHDL implementiert, der an sich auch ganz
gut funktioniert. Nur habe ich mir die Frage gestellt, ob die
Implementierung richtig ist oder ich einen Denkfehler im Ablauf der
Addition habe.
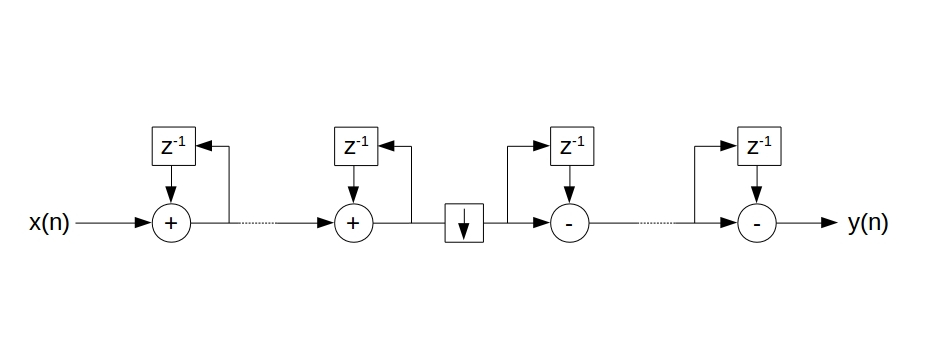
In der angehängten Zeichnung sieht man die Additionsknoten und die
Register / Verzögerer. Momentan habe ich es so implementiert, dass ich
die Additionen in einem Takt gemeinsam abarbeite, womit mir das aktuelle
Ergebnis des vorherigen Knotens also nicht für die Berechnung des
nachfolgenden Knotens zur Verfügung steht.
1
Integrator:process(nReset,iClk)
2
begin
3
if(nReset='0')then
4
nCICTemp<=(others=>'0');
5
nCICExpand<=(others=>'0');
6
nIntegration<=(others=>(others=>'0'));
7
nNewValue<='0';
8
nCount<=x"000000";
9
nNewValue<='0';
10
nDecTrigger<='0';
11
stateInt<=idle;
12
elsif(iClk='1'andiClk'event)then
13
nNewValue<=iNewValue;
14
casestateIntis
15
whenidle=>
16
nDecTrigger<='0';
17
ifnNewValue/=iNewValueandiNewValue='0'then--trigger on the falling edge of iNewValue
Alternativ wäre es aber auch denkbar, die Berechnung der Additionsknoten
in je einem Takt zu bearbeiten und somit das Ergebnis dem nachfolgenden
Additionsknoten zur Verfügung zu stellen, dieser muss dann nicht aufs
nächste Sample warten um den neuen Wert zu verrechnen:
1
Integrator:process(nReset,iClk)
2
begin
3
if(nReset='0')then
4
nCICTemp<=(others=>'0');
5
nCICExpand<=(others=>'0');
6
nIntegration<=(others=>(others=>'0'));
7
nNewValue<='0';
8
nCount<=x"000000";
9
nNewValue<='0';
10
nDecTrigger<='0';
11
stateInt<=idle;
12
elsif(iClk='1'andiClk'event)then
13
nNewValue<=iNewValue;
14
casestateIntis
15
whenidle=>
16
nDecTrigger<='0';
17
ifnNewValue/=iNewValueandiNewValue='0'then--trigger on the falling edge of iNewValue
Marcel D. schrieb:> Nun ist jedoch die Frage, welche Herangehensweise richtig ist.> Oder macht das keinen Unterschied?
Die zweite Lösung ist halt generell langsamer, weil ja jeder Schritt
nacheinander gemacht wird.
Im Resourcenverbrauch wirst du durch die zusätzliche FSM im zweiten Fall
auch ein wenig schlechter, denn du brauchst ja trotzdem alle einzelnen
Addierer. Nur tun die eben die meiste Zeit nichts...
> Nun ist jedoch die Frage, welche Herangehensweise richtig ist.
Mach die Nummer 1. Und wenn die zu langsam ist, dann denk über Pipelinig
nach. Das funktioniert aber nicht wie die Lösung 2, sondern eher wie die
Lösung 1 mit zwischengeschalteten Puffern.
Wenn man das CIC-Filter so implementiert, wie in Deinem Bild des ersten
Posts gezeigt, liegen (was die Signalverzögerung angeht) alle Addierer
in Reihe. Wenn Du die Addierer 32 Bit breit machst und M=3 stufig
arbeitest sind das 32*6=192 Bits, und alle Additionen müssen in einem
Takt des CIC Filters erledigt sein. Das kann schnell problematisch
werden.
Wenn es nichts ausmacht, dass das Signal 2M=6 Takte verzögert am Ausgang
rauskommt, kannst Du so arbeiten, wie von Dir vorgeschlagen, und die
jeweils nächste Stufe bekommt das Resultat der vorherigen Stufe einen
Takt später. Das entspricht dem Einbau von z^-1 Gliedern hinter jeder
Stufe.
Dein Bild zeigt übrigens nicht die übliche Form eines CIC Filters.
Normal erfolgt das Downsampling um R zwischen den Integrate und den Comb
Anteilen. Dann braucht man die Comb Filter auch nur seltener berechnen.
Ich blick durch Deine Implementation nicht wirklich durch, ich habe den
Eindruck, dass Du mit Hilfe von State-Maschinen Schritte in der
Reihenfolge festlegen willst.
Hier Meine Implementation mit N=2, D=1, R einstellbar.
Mir ging es eher um eine allgemeine Frage über die Berechnung und ob
diese zeitgleich an allen Knoten oder hintereinander durchgeführt werden
muss. In meiner Implementierung sind die nCombIn die Subtraktionsknoten,
die nCombDelay die vorwärts gerichteten Verzögerungselemente. Ich nutze
3 Prozesse um die Config, Integrator und Comb parallel ablaufen zu
lassen. Das ganze Teil soll ein 4 Stage CIC zur Dezimierung sein, den
kompletten Code packe ich mal als Anhang bei.
Die Grundüberlegung war die, dass die Ergebnisse der Berechnung bei
einzelnen SM-Stages ja weitaus schneller passieren, als sie eigentlich
angedacht sind. Beim FIR oder IIR werden ja ebenfalls alle
Multiplikationen und Additionen parallel ausgeführt, deswegen auch meine
beiden Implementierungen. Funktionieren tun sie beide, nur stellt sich
mir die Frage was richtig(er) ist :3
Ich gehe momentan davon aus, dass diese Implementierung (#2) die
richtige ist. Bei einem Dezimationsfaktor von 4 bekomme ich nach 4
Werten eine Änderung am Ausgang, in der anderen Variante erst nach 20.
Wozu brauchst Du hier eine State Machine?
Ein CIC hat seinen Vorteil einzig in der resourcenschonenden
Implementierung. Addieren, Differenzieren. Alle Verrenkungen drum herum
gehören da raus und blähen nur auf.
Marcel D. schrieb:> Also alles in einzelne Prozesse auslagern wie Ossi es gemacht hat?
Ganz sicher nicht. Wozu? Ist Dir klar, was Prozesse sind und wie sie
wirken? Das Verlagern von Code in unterschiedliche Prozesse hat
ergebnistechnisch in der Regel gar keine Wirkung und wenn, dann keine
gute.
Bläht nur den Code auf.
Wir sind aber an einer anderen Stelle, nämlich dem Aufblähen der
Funktion!
Daher nochmals meine Frage: Wozu eine state machine und ein stückweises
Berechnen mit den calc stages?
Der Code zeigt mir wieder mal, dass hier nicht parallel gedacht wird
sondern eine Implementierung eines sequenziellen Ablaufs wie man ihn in
C laufen lassen müsste, übersetzt wurde.
Softwareentwickler sollten sich von FPGAs fernhalten.
Weltbester FPGA-Pongo schrieb im Beitrag #5325604:
> Daher nochmals meine Frage: Wozu eine state machine und ein stückweises> Berechnen mit den calc stages?
Um sicherzustellen, dass die Berechnung des vorherigen Knotens
abgeschlossen ist und ich das Ergebnis der nachfolgenden Einheit zur
Verfügung stellen kann, das ganze in einer getakteten Umgebung weil ich
asynchrones Verhalten vermeiden will? Ich habe 10 Takte für die
Berechnung bis ein neuer Wert kommt und mit dem as fast as possible
Ansatz bin ich beim fitten leider schon auf die Schnauze gefallen.
Weltbester FPGA-Pongo schrieb im Beitrag #5325604:
> Der Code zeigt mir wieder mal, dass hier nicht parallel gedacht wird> sondern eine Implementierung eines sequenziellen Ablaufs wie man ihn in> C laufen lassen müsste, übersetzt wurde.
Für mich sieht der Aufbau eines CICs ziemlich seriell aus, könntest es
mir ja erklären.
Weltbester FPGA-Pongo schrieb im Beitrag #5325604:
> Softwareentwickler sollten sich von FPGAs fernhalten.
Danke für diese Offenbarung, werde sofort meinen Job kündigen und alle
Leute in meiner Umgebung warnen, niemals mit FPGAs anzufangen wenn sie
schon mal eine Programmiersprache abseits von VHDL oder Verilog
nutzten...