Hallo zusammen, vor kurzer Zeit stellte ich im EmBitz-Forum die Frage, wie man den normalen GDB für die Systemplattform (in meinem Fall Windows) in EmBitz einbindet. Die Antwort des Entwicklers war sinngemäß: "Warum sollte man EmBitz benutzen, wenn man für Windows entwickelt?". Sprich: einen Mikrocontroller-Quelltext erst einmal auf dem Entwicklungs-Betriebssystem laufen zu lassen und debuggen zu können, schien als ungewöhnliches Anliegen angesehen zu werden. Allerdings habe ich auch noch nie den Arbeitsplatz eines fortgeschrittenen Embedded-Entwicklers unter die Lupe genommen. Deshalb die Frage in die Runde: Wie sieht eigentlich eure Entwicklungsumgebung aus? Als Beispiel, welche Teile mich interessieren, stelle ich mal meine Entwicklungsumgebung vor: Ich entwickle für ARM Cortex M3/M4 und ein paar AVR-Altlasten. Als IDE nutze ich momentan EmBitz und Atmel Studio. Als Build-Prozeß nutze ich den, der in der IDE eingebaut ist. In der IDE habe ich normalerweise vier Targets eingerichtet: Zwei für die Zielplattform, davon eines als Debug-Build. Ein Target ist für die Entwicklungsplattform (hier Windows) und lässt automatisierte Modultests durchlaufen. Das vierte Target baut ein virtuelles Mock-Up des Systems aus LCD-und Bedienelemente-Emulation, um das grafische Layout und die Benutzerführung schneller testen zu können. Alle vier Targets werden mit einem GCC bedient. Die Zielplattform-Builds mit dem ARM-GCC, die Windows-Plattform mit MinGW64. Als Lookup-Tabellen-Füller dient Matlab. Das ist meist eine händische Copy-Paste-Sache (die Tabellenelemente werden richtig formatiert in der Konsole ausgegeben, aber von Hand in den Quelltext eingefügt). Mit Lookup-Tabellen meine ich errechnete mathematische Funktionswerte, aber auch Konvertierungsaufgaben (z.B. Bitmaps oder Schriftarten in Quelltext). Außerdem dient mir Matlab noch als schnelle Test-Umgebung, wenn ich kleine mathematische Methoden ausprobieren und das Ergebnis plotten will. Für die statische Codeanalyse nutze ich Clang/LLVM auf einer virtuellen Debian-Maschine. Da der Build-Prozeß in der obengenannten IDE kein Makefile exportieren kann oder will, erzeuge ich mein Makefile mit einem kruden (Matlab-) Skript aus der Konfigurationsdatei der IDE. Weil ich hier erst eine virtuelle Maschine starten muß, nutze ich diese Möglichkeit allerdings recht selten. Man sieht: In meinem Entwicklungsprozess steht Matlab an meheren Stellen, was einfach daran liegt, dass ich darin besser als in Python bin, aber vom Prozess ist das ja austauschbar. Die Dokumentation wird vom Quelltext völlig separat geführt. Sie befindet sich natürlich mit dem Quelltext im gleichen Versionsverwaltungssystem, aber es findet keine automatische Doku-Generierung à la Doxygen statt. Wie sieht eure Entwicklungsumgebung aus? Und welches wertvolle Werkzeug ist mir bislang entgangen? Viele Grüße W.T.
MikroE C mit mercurial Auf PIC, PIC32 und ARM (AVR geht auch kenne ich aber nicht) die gleiche IDE. Debugger kann simulieren oder auf der Zielplattform tracen. Gibt es auch mit Pascal und Basic compiler. Ziemlich schnörkellos und out of the box. Für mich (Hardwareentwickler der Software schreiben muss) super. Kostet aber einmalig Geld.
X4U schrieb: > Für mich (Hardwareentwickler > der Software schreiben muss) super. Hallo X4U, kannst Du das noch etwas ausführen? - Womit befüllst Du lookup Tables? - Nutzt Du den eingebauten Simulator und wenn ja: Wozu? - Erzeugst Du auch Builds für die Entwicklungsplattform, oder erschlägst Du das mit dem Simulator? - Der Hersteller bewirbt die Einbindung statischer Codeanalysewerkzeuge (cppcheck). Nutzt Du es und wie geht das in Deinen Workflow? - Nutzt Du die Doxygen-Fähigkeiten Deiner IDE? Viele Grüße W.T.
Walter T. schrieb: > Sprich: einen > Mikrocontroller-Quelltext erst einmal auf dem > Entwicklungs-Betriebssystem laufen zu lassen und debuggen zu können, > schien als ungewöhnliches Anliegen angesehen zu werden. Das liegt daran das im µC fast immer spezifische Sachen gemacht werden die es auf dem PC in der Form nicht gibt, Stichwort Interrupt oder Peripherie. Dazu kommen subtile Unterschiede im C-Compiler. Als Ergebnis findet man die "interessanten" Fehler nur wenn man das Programm auf dem Ziel-µC laufen lässt.
Jim M. schrieb: > Als Ergebnis findet man > die "interessanten" Fehler nur wenn man das Programm auf dem Ziel-µC > laufen lässt. Stimmt. Aber wenn ich die langweiligen Fehler schon vorher finde, spart mir das unterm Strich immer noch viel Zeit. Nebenbei geht es beim Build für den PC mehr um die Benutzerschnittstelle. Ich kann so Test-Versionen der Benutzerschnittstelle an Bekannte schicken und nach Meinungen und Verbesserungsvorschlägen fragen.
Sehr merkwürdig. In den Holz-, Metall- und Kunststoffverarbeitungsforen lieben es die Teilnehmer, ihren liebevoll gestalteten Arbeitsplatz und ihre teils selbst angefertigten oder verbesserten Werkzeuge vorzustellen.
Hallo Walter, meine Entwicklungsumgebung deckt die meisten Dinge die du schon gelöst hast nicht ab. Aber seit ca. 1 Jahr stelle ich alles auf CMake & Clion um. Damit will ich die gleichen Dinge erreichen, die du angesprochen hast. Den Vorteil von CMAKE sehe ich darin, alle möglichen Tools integrieren zu können. Das generieren von „einfachen“ Dateien ist z.B. direkt in CMake integriert. Mit Clion habe ich eine komfortable Entwicklungsumgebung die zum einen die CMake Dateien versteht und dann aber auch hervorragende Unterstützung für die eigentliche C/C++ Firmware Entwicklung. In einem Projekt habe ich auch den Google Test benutzt welches ebenfalls hervorragend von CLion unterstützt wird (Test - Runner). Die Tests hab ich dort allerdings nicht auf dem Target sondern auf dem PC ausgeführt.
Hallo Sub-Sub, Sub-Sub schrieb: > meine Entwicklungsumgebung deckt die meisten Dinge die du schon gelöst > hast nicht ab. Macht ja nichts. Ich suche ja keine Problemlösung. Mich interessiert nur, wie andere Sachen machen. (Zum Vergleich: Ich habe mal vor ein paar Wochen mit einem Schreiner in seiner Werkstatt gestanden und gequatscht. Er schien Zeit zu haben, und ich hatte es auch. In der Dreiviertelstunde habe ich mehr über Holzbearbeitung dazugelernt, als in einem ganzen Jahr im Bastelkeller. Und der Kaffee war auch gut.) Sub-Sub schrieb: > [...] CMake & Clion [...] Google Test [...] > Das sieht nach einer ordentlichen Investition aus, die man nicht zum Spaß macht (nicht wahnsinnig teuer, aber jenseits des üblichen Hobby-Budgets). Also nehme ich mal an, daß Du Profi bist. Sub-Sub schrieb: > Den Vorteil > von CMAKE sehe ich darin, alle möglichen Tools integrieren zu können. > Das generieren von „einfachen“ Dateien ist z.B. direkt in CMake > integriert. Sehe ich das Richtig, daß der Vorteil von CMake darin besteht, dass man ihm ein Verzeichnis mit Quelltext zum Fraß vorwerfen kann, ohne erst mühevoll jede zu kompilierende Datei in den Build einbauen zu müssen? Und was ist mit "einfachen" Dateien gemeint? Geht das Richtung Lookuptable, oder eher Richtung Build-Skripte? Viele Grüße W.T.
Hi
Wir arbeiten hier mit make als Basis für unsere Builds.
Generiert werden diese Makefiles mit Hilfe eines Perlscripts das dazu
noch folgende Aufgaben übernimmt:
- Steuern des Buildvorgangs
* Was soll gebaut werden (welches Subsystem)
* Auswahl der Architektur (wir bauen hier ca. 10 verschiedene)
* Debug, Release
- Tools laufen lassen
* Doxygen
* gtest
* cppcheck
- Reports erzeugen
* Excelsheets mit Testergebnissen
* Codecoverage (HTML, per lcov)
Wird alles von der Kommandozeile aufgerufen. Man hat also typischerweise
einen Editor (VS, VSCode, Eclipse, ...) offen und daneben ein Terminal
in dem man dann den Build startet.
Matthias
Walter T. schrieb: > Sehe ich das Richtig, daß der Vorteil von CMake darin besteht, dass man > ihm ein Verzeichnis mit Quelltext zum Fraß vorwerfen kann, ohne erst > mühevoll jede zu kompilierende Datei in den Build einbauen zu müssen? Kann man machen. Mach ich aber nicht. Ich addiere jede Quelltextdatei zu einer Liste. Manche open Source Komponenten bringen schon CMakeLists Dateien mit, die man dann wiederum in seine CMake Datei inkludieren kann. FreeRtos und StmLib sind zum Beispiel zwei CMake Listen, die ich selber befüllt habe. So kann ich diese immer wieder verwenden. Ähnlich teile ich dann auch Code auf, welcher für verschiedene Projekte benutzt wird oder die Plattform spezifisch (MCU, Layout) sind. Was ich sagen will ist das man mit CMake alles sehr gut strukturieren kann und zwar so dass man es auch wiederverwenden kann. Μαtthias W. schrieb: > Generiert werden diese Makefiles mit Hilfe eines Perlscripts das dazu > noch folgende Aufgaben übernimmt: Dies kann man mit CMake auch lösen. CMake ist ein Build Generator. Man kann damit für verschiedene IDE’s oder make Tools die Projekt Dateien generieren. Mit einfache Dateien meine ich die Dateien in denen man üblicherweise irgendwelche Konfigurationseinstellungen macht (z.B: Versionsnummer) die sich aber von Projekt zu Projekt geringfügig unterscheiden (die gleichen Settings aber unterschiedlich Werte) Bei Lookup Tables würde ich eher versuchen diese mit constexpr und einem aktuellen C++ Compiler zu generieren.
Μαtthias W. schrieb: > Man hat also typischerweise > einen Editor (VS, VSCode, Eclipse, ...) offen und daneben ein Terminal > in dem man dann den Build startet. Definitiv ein Klassiker, der niemals alt wird. Danke für Deinen Einblick! Insbesondere für mich interessant: Μαtthias W. schrieb: > Generiert werden diese Makefiles mit Hilfe eines Perlscripts das dazu > noch folgende Aufgaben übernimmt: > [...] > * Doxygen > * gtest > * cppcheck > - Reports erzeugen > * Excelsheets mit Testergebnissen > * Codecoverage (HTML, per lcov)
Walter T. schrieb: > erzeuge ich mein Makefile mit einem > kruden (Matlab-) Skript aus der Konfigurationsdatei der IDE. Ich schreib (schrieb) mein Makefile von Hand (Grundgerüst einmal geschrieben, danach für neue Projekte nur noch leicht modifiziert oder erweitert) und in der IDE (momentan noch Eclipse) sage ich einfach: "Das ist ein Makefile-Projekt, nutze das existierende Makefile, schau Dir an was es macht und konfiguriere Deine Code-Assistenz dementsprechend automatisch". Das ist unter dem Strich sehr wartungsfreundlich, sehr flexibel, sehr einfach zu durchschauen und 100% deterministisch.
Bernd K. schrieb: > Ich schreib (schrieb) mein Makefile von Hand Auch eine Lösung, die immer noch ihre Vorteile hat. Wie erzeugst Du Look-Up-Tables? Baust Du Deinen Quelltext nur für die 7-Bit-Zielplattform, oder hat Dein Makefile auch für die Entwicklungsplattform ein Target?
Walter T. schrieb: > Wie sieht eigentlich eure Entwicklungsumgebung aus? Meine: Emacs für alles :) (aber damit bin ich natürlich auch der Einzige hier), also egal, ob ich auf dem Host mal was machen muss, auf einem AVR oder einem ARM (letzteres ist unsere Hauptarbeit). GDB-Einbindung dort ist mittlerweile zu einer ausgewachsenen IDE gediehen, auch wenn ich deren Funktionalität nur selten in größerem Umfang brauche. Ich benutze den GDB schon so lange, dass ich die wesentlichen Funktionen direkt im GDB erledigen kann. Parallele Tests auf dem Host gehen hier, bedingt durch die Peripherie am Controller, praktisch nicht. Mathematische Algorithmen werden in Python oder in letzter Zeit (kundengetrieben) auch in Matlab auf dem Host entwickelt und dann ggf. in den Controller umgesetzt (manuell in C neu geschrieben). Host ist bei mir Linux (Windows dann nur in VMware, vorrangig für den Office-Krams, aber auch die HP Logicanalyzer-Software oder Altium), bei anderen Windows, spielt nicht so die große Rolle. Wir sind oft so weit an der Hardware am Controller dran, dass vieles an Debugging ohne Logic Analyzer nicht praktikabel machbar ist.
Jörg W. schrieb: > Emacs für alles :) (aber damit bin ich natürlich auch der > Einzige hier), > [...] > Host ist bei mir Linux > [...] > Wir sind oft so weit > an der Hardware am Controller dran, dass vieles an Debugging ohne > Logic Analyzer nicht praktikabel machbar ist. Hallo Jörg, Danke für Deine Beschreibung. Ich finde es sehr interessant zu erfahren, daß auch noch solche Arbeitsplätze offensichtlich sehr produktiv eingesetzt werden. Klar - hier liegt der Schwerpunkt ja wahrscheinlich in der Zusammenarbeit zwischen der Software- und der Messplatz-Entwicklungsumgebung. Da Du mir damals die erste Starthilfe mit LLVM gegeben hast interessiert mich noch: Nutzt Du dieses Werkzeug auch produktiv? Viele Grüße W.T.
Linux System mit - Eclipse - GNU ARM Plugin (bzw. GNU MCU mittlerweile) - GCC + Clang (hauptsächlich für Sanatizers) - Python (scipy, numpy, pyqt) - Matlab - gtest/gmock Lookup-Table Füller oder ähnliches brauch ich nicht, da C++. ;)
Walter T. schrieb: > Da Du mir damals die erste Starthilfe mit LLVM gegeben hast interessiert > mich noch: Nutzt Du dieses Werkzeug auch produktiv? Höchstens indirekt, als Compiler (Clang). Aber nicht für embedded.
Ich nutze: * Sublime als Editor * CMake/Make für builds * GCC als C++ compiler für embedded * Clang als C++ compiler auf der Entwicklungsplattform * Ruby oder CoffeeScript für Skripting-Tasks * Doxygen zur Dokumentation * Boost.Test für Unit-Tests auf der Entwicklungsplattform * Ansonsten alles aus Boost, was einsetzbar ist * command line GDB (ich debugge relativ selten) mfg Torsten
Bei mir ist es: * IDE: QtCreator, Emacs * Builder: meistens make, gelegentlich cmake, qbs * µC: GCC * non-µC: Clang/GCC * Skript: bash, awk, sed, ... (Unix-Werkzeugkasten) * Doku: Asciidoctor * Test: Google-Test * Debugger: GDB
Vincent H. schrieb: > Linux System mit Torsten R. schrieb: > Ich nutze: Wilhelm M. schrieb: > Bei mir ist es: Danke für eure Beschreibungen! Genau so stelle ich mir das vor. Da waren schon wieder etliche Werkzeuge dabei, von denen ich noch nie gehört habe (Asciidoctor, Sublime, CoffeeScript, Boost) oder die ich nie im Leben mit µC-Entwicklung in Verbindung gebracht hätte (pyqt, gmock).
Walter T. schrieb: > Wie erzeugst Du Look-Up-Tables? Mit Python. Und auch alles was mit C-Makros nur sehr umständlich oder nur mit unwartbarer schwarzer Magie machbar wäre - wenn überhaupt - lass ich lieber von sauberen übersichtlichen Python-Scripten generieren (z.B. USB-Deskriptoren oder dergleichen), und da ich ja mein eigenes Makefile verwende kann ich das auch problemlos in den Buildprozess einbauen.
Jörg W. schrieb: > Walter T. schrieb: >> Wie sieht eigentlich eure Entwicklungsumgebung aus? > > Meine: Emacs für alles :) (aber damit bin ich natürlich auch der > Einzige hier), Nein, bist Du nicht. ;-) Meine "Entwicklungumgebung" ist keine, jedenfalls keine IDE im klassischen Sinn: meine wichtigsten Werkzeuge sind der GNU Emacs als Editor (ob der schon als IDE durchgeht, sei dahingestellt), die Bash als Kommandozeile und GNU Make zur Integration und Steuerung von eigentlich allem: Build, Tests, Simulation, Flashing, und so weiter. Hinzu kommen (je nach Kollegen) noch eine Versionsverwaltung wie Git, Mercurial oder Subversion (ich selbst bin da vornehmlich Git zugeneigt), und zudem Python- oder Bash-Skripte für verschiedene weitere Aufgaben. Und, ach ja, Doxygen für die Dokumentation sowie weitere Werkzeuge wie Valgrind, Sonarcube und ansonsten den guten alten UNIX-Werkzeugkasten. Mit diesem Werkzeugkasten mache ich alles, von einfachen Sachen wie HTML, CSS und JavaScript über verschiedene Skriptsprachen bis hin zu großen und umfangreichen Projekten in C++ und Java für Linux, Windows und AIX, aber auch AVRs. Als Hauptvorteil sehe ich, daß ich dieselben Werkzeuge für alles benutzen kann und mich nicht an mehrere verschiedene IDEs gewöhnen muß. Außerdem kann ich alles mit der Tastatur machen. ;-)
Bernd K. schrieb: > Walter T. schrieb: >> Wie erzeugst Du Look-Up-Tables? Also die Zeit, dass ich LU-Tables mit externen Tools erzeuge, ist vorbei: ich nehme nur noch constexpr-f().
... und git / svn habe ich vergessen (hatte ich nicht als Werkzeuge im engeren Sinn betrachtet, da denkt man ja kaum noch drüber nach ...) Und ja: valgrind/helgrind für non-µC, wenn es irgendwie hatnäckig klemmt. Wobei ich sagen muss, dass die immer seltener zum Zuge kommen - und das ist wohl auch gut so. Und das hat m.E. weniger mit mehr Erfahrung als mit einer aufpolierten Sprache zu tun ...
i3wm und teilweise auch tmux, Sublime Text, vim, bash, Make und Templates für alles mögliche, git. In i3 und vim bin ich noch etwas wackelig, aber ich zieh das durch.
Wilhelm M. schrieb: > Bernd K. schrieb: >> Walter T. schrieb: >>> Wie erzeugst Du Look-Up-Tables? > > Also die Zeit, dass ich LU-Tables mit externen Tools erzeuge, ist > vorbei: ich nehme nur noch constexpr-f().
1 | // 0° - 90° Sinus Wave
|
2 | struct sinus_wave2 : wave_base< sinus_wave2 > |
3 | {
|
4 | static constexpr const char* pattern() |
5 | {
|
6 | return
|
7 | " ********** "
|
8 | " ** ** "
|
9 | " ** ** "
|
10 | " * * "
|
11 | " ** ** "
|
12 | " * * "
|
13 | " * * "
|
14 | " * * "
|
15 | " * * "
|
16 | " * * "
|
17 | " "
|
18 | " * * "
|
19 | " * * "
|
20 | " * * "
|
21 | " * * "
|
22 | " "
|
23 | " * * "
|
24 | " * * "
|
25 | " * * "
|
26 | " "
|
27 | " * * "
|
28 | " * * "
|
29 | " "
|
30 | " * * "
|
31 | " * * "
|
32 | " "
|
33 | " * * "
|
34 | " * * "
|
35 | " "
|
36 | " * * "
|
37 | " "
|
38 | "* *"; |
39 | }
|
40 | };
|
Ich gestehe aber, dass ich den C++ Code mit Ruby erzeugt habe ;-)
Walter T. schrieb: > Da waren schon wieder etliche Werkzeuge dabei, von denen ich noch nie > gehört habe... > Boost Das meinst du aber nicht ernst, oder? Oliver
Jörg W. schrieb: > Meine: Emacs für alles :) (aber damit bin ich natürlich auch der > Einzige hier) Nö ;) Gibt zwar seltene Ausnahmen (und immer mit Gefluche, weil da alles immer anders geht) und manchmal ist es auch jmacs statt emacs. Aber anders kann ich bei meinem Zoo (uC, FPGA, Webkram, C, C++) nicht den Überblick bewahren. Der Rest ist Standardkram (svn, make, gdb, doxygen, meistens perl für Tabellenkram). Auf hippe&trendige Tools oder Sprachen verzichte ich...
Nach all diesen Berichten bin ich jetzt ganz zerknirscht und liege am Boden zerstört... Heute oute ich mich: Meine bisherigen Entwicklungsumgebungen bestanden immer nur aus Klicki-Bunti IDEs wie Keil uVision, IAR, Atollic. Make kenne ich nur noch von früher her als ich noch mit MSDOS oder LINUX gearbeitet hatte. OK, Und auch etwas Commandline mit CCS PIC Compiler. So finde ich mich also als einer dieser ach, so verachteten Lehnstuhlprogrammierer:-( Zu meiner Ehrenrettung kann ich aber sagen, daß ich mich vor Jahren immerhin an den Linker Script und Startup Files gewagt habe um notwendige Memory Anpassungen für Spezialanwendungen (Bootloader für STM32) zu ermöglichen. Was mich jetzt aber interessieren würde: Welche entwicklungstechnische Gründe gab es für Euch auf IDEs ganz zu verzichten? Bis jetzt boten uns IDEs immer genug Einstellungs- und Anpassungsmöglichkeiten um direkte Make und andere Scripte nicht notwendig zu machen. Embedded Linux Projekte machten wir immer mit PuTTY, SSH Client und andere Windows Werkzeuge auf einer fernen Linux Maschine übers Netzwerk. Keiner von uns hat einen Linux Desktop. Natürlich war auf der Linux Ebene über PuTTY alles Command line. Macht ihr wirklich alle so komplizierte und exotische Sachen die mit Standard Werkzeugen nur schwer oder nicht machbar wären? Jedenfalls ist es interessant zu hören was andere machen.
> Was mich jetzt aber interessieren würde: Welche entwicklungstechnische > Gründe gab es für Euch auf IDEs ganz zu verzichten? Bis jetzt boten uns > IDEs immer genug Einstellungs- und Anpassungsmöglichkeiten um direkte > Make und andere Scripte nicht notwendig zu machen. Nimm mal an einer kommt zu dir (z.B im Rahmen eines Atex oder Sil Audit) und sagt dir du sollst mal eben eine 3-5Jahre alte Softwareversion auschecken und neu erzeugen. Und zwar so das dabei das identische Binaerfile rauskommt wie du es damals verwendet hast. (Ich koennte mir vorstellen das soetwas in letzte Zeit oefter im Automobilbereich passiert ist. :-) ) Dann ist es viel einfacher du installierst den alten Compiler neu, checkst aus und rufst einmal make auf. Bei Eclipse ist es ja schon fast unmoeglich eine identische Version auf zwei unterschiedlichen Rechnern im Abstand von einer Stunde zu installieren. Olaf
Olaf schrieb: > und sagt dir du sollst mal eben eine 3-5Jahre alte Softwareversion > auschecken und neu erzeugen. Dann sage ich das es nicht nötig ist auszuchecken und stupse den Job auf dem Buildserver an ;)
Gerhard O. schrieb: > Macht ihr wirklich alle so komplizierte und exotische Sachen die mit > Standard Werkzeugen nur schwer oder nicht machbar wären? Make, gcc, gdb etc. SIND die Standardwerkzeuge.
Gerhard O. schrieb: > Macht ihr wirklich alle so komplizierte und exotische Sachen die mit > Standard Werkzeugen nur schwer oder nicht machbar wären? Dazu kommt noch das sich mit scriptgesteuerten Prozessen einfach mehr und einfacher automatisieren lässt. Wenn wir hier alles einmal durchbauen und Testen wollen (inkl. Flashen diverser Geräte usw.) dann ist das ein einfacher Aufruf eines Scripts in einem Verzeichnis und anschließender sehr ausgedehnter Kaffeepause :-) Matthias
Gerhard O. schrieb: > Nach all diesen Berichten bin ich jetzt ganz zerknirscht und liege am > Boden zerstört... > > Heute oute ich mich: Meine bisherigen Entwicklungsumgebungen bestanden > immer nur aus Klicki-Bunti IDEs wie Keil uVision, IAR, Atollic. Es gibt unterschiedliche Anwendungen, unterschiedliche Ziele, unterschiedliche Randbedingungen und unterschiedliche Vorgeschichte. Deswegen sind die Lösungen auch unterschiedlich. Gerhard O. schrieb: > Macht ihr wirklich alle so komplizierte und exotische Sachen die mit > Standard Werkzeugen nur schwer oder nicht machbar wären? Emacs und Co sind Standardwerkzeuge. Nur nicht für jeden Nutzer das Optimum.
Gerhard O. schrieb: > Nach all diesen Berichten bin ich jetzt ganz zerknirscht und liege am > Boden zerstört... > > Heute oute ich mich: Meine bisherigen Entwicklungsumgebungen bestanden > immer nur aus Klicki-Bunti IDEs wie Keil uVision, IAR, Atollic. Make > kenne ich nur noch von früher her als ich noch mit MSDOS oder LINUX > gearbeitet hatte. OK, Und auch etwas Commandline mit CCS PIC Compiler. > So finde ich mich also als einer dieser ach, so verachteten > Lehnstuhlprogrammierer:-( Erfahrungsgemäß gibt es bei "Hardcore" Vim/Emacs/etc. Nutzern immer 2 Typen. Die einen, die die Features mit einer "full blown" IDE abgewogen haben und für die sich die IDE einfach nicht auszahlt oder gar unkomfortabler ist. Und dann gibts die, die sich drauf einen abwedln weils halt so h4x00r-1337 is. Und ja, es gibt legitime Beweggründe. Etwa wenn man einen Sprachenmix verwendet, der sich mit einer IDE nicht abdecken läst. Oder wenn sich Eclipse mal wieder mit einem Java.Stackoverflow abschießt... dann greif ich mir auch oft aufs Hirn und frag mich wieso ich mir das antu. Dann gibts aber wieder Momente, da muss ich im GDB einen conditional breakpoint setzen, der erst beim 3. Schleifendurchlauf auftritt wenn das 2x dimensionale Array an Stelle [9][1] den Wert 42 hat...
Gerhard O. schrieb: > Welche entwicklungstechnische > Gründe gab es für Euch auf IDEs ganz zu verzichten? Wir verzichten nicht grundsätzlich auf IDEs (ich zumindest nicht), genausowenig verzichten wir auf graphische Oberflächen und Mäuse. Wir weisen ihnen lediglich einen anderen Platz in der Hierarchie der Abhängigkeiten zu, einen an dem sie weniger Probleme im Projekt verursachen und besser ihre eigentliche® Aufgabe wahrnehmen können: Das Editieren von Code. Wir wollen so gut es geht vermeiden daß das Projekt vom Klickibunti und der IDE der Tagesmode abhängig wird, deshalb bauen wir die Projekte mit etablierten Standardwerkzeugen auf etablierten robusten Fundamenten auf (GNU-Tools, bash, make, gcc) und die IDE oder Emacs oder andere Spezialtools und das Klickibunti kommt eine Schicht höher, es ist das optionale Sahnehäubchen oben drauf wenn man mal Lust auf Autovervollständigung, durchklickbare Aufruf-/Aufruferbäume oder Makro-Expansion bei Mouse-Over hat.
Ich nutze den mcedit vom Midnight-Commander als Editor. Da ich meist
gemischt C und ASM programmiere,und das auf mehreren Controllerfamilien,
haben die ASM-Files meist verschiedene Endungen (z.B. .thumbasm oder
.vleasm) mit denen ich das Highlighting einfach anpassen kann. Dazu
angepasste Makefiles, die aber alle auf demselben Template basieren.
Dazu kommt noch eine riesige Bibliothek ("unilib"), die eine Art HAL
darstellt und für jeden genutzten Controllertyp einzeln erstellt wird,
genauso wie der Startup-Code, Include-Files, Makefiles und
Linkerscripts. Mittlerweile habe ich auch alle wichtigen Funktionen der
stdlib integriert, so dass ich meine Applikationen via -nostartfiles
-nostdlib compilieren kann. Außerdem sind jede Menge Low- und Highlevel
I/O enthalten, wobei es oft schwierig war, den kleinsten gemeinsamen
Nenner zu finden. Beispiel:
set_clock(CLOCK_8_16);
setzt den Clock auf 16 MHz bei einem Quarz von 8MHz. Ob das jetzt ein
HCS08, ein S12X, ein STM32xx, ein SPX56xx oder ein Renesas R8C ist,
spielt keine Rolle. Bei einem AVR würde der Compiler meckern, dass
CLOCK_8_16 nicht definiert ist. Hier müsste man dann CLOCK_16_16 nehmen
und einen 16MHz Quarz.
Ich hatte schon mal angefangen, das zu dokumentieren um es zu
veröffentlichen, aber leider wächst es schneller als ich mit dem
Dokumentieren hinterherkomme ;-)
Debugger benutze ich praktisch überhaupt nicht, mir reichen ein paar LED
und ggf. eine serielle Verbindung. Und bei externer Hardware ein
Logic-Analyzer.
Bei meinem aktuellen Projekt (wieder mal eine Emulationsgeschichte) gibt
es z.B 6 verschieden Makefiles für verschieden Plattformen (PC/Console,
PC/SDL und verschiedene Controllerboards), aber nur einen Source-Block.
Die Hauptentwicklung passiert mit der SDL-Variante, weil ich hier die
Debug-Ausgaben "scrollbar" im Consolenfenster habe und die auch ggf. in
eine Datei umlenken kann.
Die Umschaltung mache ich im Makefile mittels -DMCU=nn, was ich in einem
Headerfile auswerte und entsprechende Defines setze. So kann ich bei
Bedarf leicht eine neue Plattform hinzufügen. Oder "klonen", weil ich
z.B. zeitkritische Funktionen durch ASM-Code ersetzen will.
In die Makefiles habe ich auch immer die passenden Aufrufe von meinem
Universalprogrammmer integriert, so dass ein "make start" das Projekt
komplett neu compiliert, auf den Controller überträgt und diesen
anschließend neu startet. Inzwischen wechsle ich die virtuelle Console
und warte in Minicom auf den Prompt vom Controller...
Gerhard O. schrieb: > Macht ihr wirklich alle so komplizierte und exotische Sachen die mit > Standard Werkzeugen nur schwer oder nicht machbar wären? Eigentlich bei jedem trivialen Projekt, habe ich mindestens zwei Zielplattformen: Ein Controller und meine Entwicklungsrechner. Alleine schon deswegen, weil ich Unit Tests mache und diese dann halt nicht auf dem Controller laufen, habe ich mehrere Zielplattformen. Aber auch mehrere µController in einem Projekt, ist mittlerweile keine Seltenheit mehr. Im Endeeffekt hat jede IDE etwas Make-Ähnliches im Bauch. Statt nun den Build strukturiert, lesbar im Quellcode abzubilden, liegen die Regeln in irgend welchen XML-Dateien. Änderungen an diesen XML-Dateien sind meist kaum nachzuvollziehen. CMake/Make basierte Builds lassen sich auch gut automatisieren. Ich habe ein make target um Software zu bauen und auf einer Zielhardware zu installieren. Das kann ich gut für Automatisierungen nutzen. Versuch das mal mit einer IDE. Das Argument von Olaf, durch die Nutzung von Standard Werkzeugen, auch in der Zukunft Projekte ohne viel Aufwand weiter bearbeiten zu können, hat bei mir schon einige Kunden überzeugt. Ich denke, dass es auch sehr typisch für den Embedded Bereich ist, dass Projekte mal für Jahre eingemottet werden und dann doch noch mal ein Update fällig wird. Da ist es dann hilfreich, wenn man nicht plötzlich noch mal irgendwo Windows XP installieren muss, um die alte IDE wieder zu laufen zu bekommen. mfg Torsten
Angehängte Dateien:
-

emacs-ide.png
280 KB
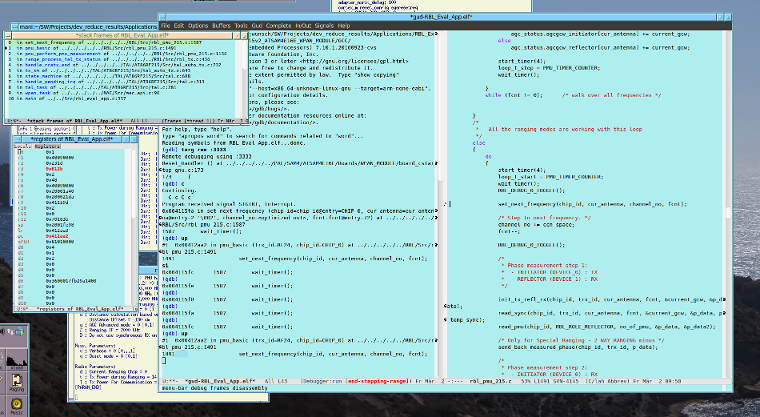
Gerhard O. schrieb: > Was mich jetzt aber interessieren würde: Welche entwicklungstechnische > Gründe gab es für Euch auf IDEs ganz zu verzichten? Ich benutze gelegentlich Qt Creator – immer dann, wenn ich mal was mit Qt mache. Das passiert selten genug, als dass mir die darin eingebauten Hilfen hinsichtlich Qt die Arbeit tatsächlich vereinfachen. Ansonsten hat man mit diesen IDEs immer zwei Probleme: erstens ein Vendor-Lock-In (*), zweitens ist bei jeder IDE immer alles ganz anders als bei jeder anderen. (*) Versuch' doch mal, mit den offiziellen IDEs ein Atmel-ICE zum Debuggen eines STM32 oder ein ST-Link zum Debuggen eines Atmel ARM zu benutzen. ;-) Mit OpenOCD ist das gar kein Problem. Ich muss daher zur Arbeit mit einer anderen (embedded) Hardware nicht nur nicht die Oberfläche (IDE) wechseln, sondern nicht einmal den Debug-Dongle. Du darfst dir sowas aber nicht so feature-arm vorstellen, wie das auf den ersten Blick klingen mag. Anbei mal ein Screenshot, wie der Emacs im aktuellen GDB-Modus so ungefähr aussieht. (Ich habe das absichtlich so weit verkleinert, dass man es nicht richtig lesen kann, ist schließlich unser proprietärer Quellcode. Soll ja nur grob das look&feel demonstrieren.)
Joerg W. schrieb: > Die Hauptentwicklung passiert mit der SDL-Variante, Das finde ich interessant. Vor Jahren habe ich nach einer Lösung für eine PC-basierte Emulation für Taster-Eingaben, Display-Ausgaben etc. gesucht, aber keine ähnliche Anwendung gefunden. Ich habe dann meinen Kram auch auf SDL aufgebaut in der Annahme, mit meinen Anforderungen allein dazustehen, zumal ich in Jahren Forenbesuch nie etwas ähnliches gelesen habe.
Jörg W. schrieb: > Anbei mal ein Screenshot, wie der Emacs > im aktuellen GDB-Modus so ungefähr aussieht. Danke für den Screenshot. Ich habe keinerlei Vorstellung davon gehabt, wie der Emacs heute aussieht. Meine letzte Erfahrung damit war Micro-Emacs auf dem Amiga 1200.
Angehängte Dateien:
-

Emacs1.png
150 KB
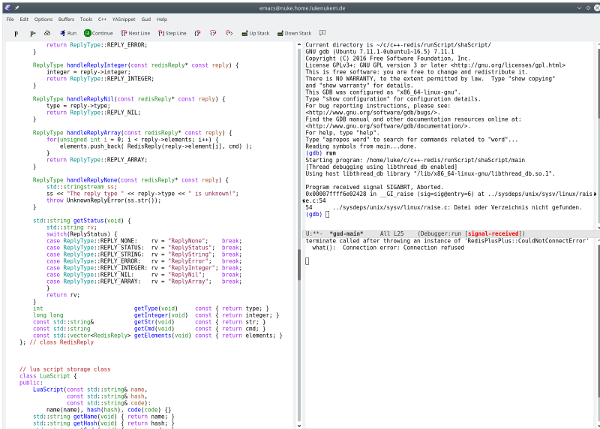
Walter T. schrieb: > Jörg W. schrieb: >> Anbei mal ein Screenshot, wie der Emacs >> im aktuellen GDB-Modus so ungefähr aussieht. > > Danke für den Screenshot. Ich habe keinerlei Vorstellung davon gehabt, > wie der Emacs heute aussieht. Meine letzte Erfahrung damit war > Micro-Emacs auf dem Amiga 1200. So kann der Emacs heute aussehen, muß er aber nicht. Emacs ist (nicht nur hinsichtlich des Aussehens) äußerst flexibel konfigurierbar. Bei mir unter KDE sieht der Emacs ohne viel Konfiguration ganz anders aus, siehe Anhang.
Walter T. schrieb: > Sehr merkwürdig. In den Holz-, Metall- und Kunststoffverarbeitungsforen > lieben es die Teilnehmer, ihren liebevoll gestalteten Arbeitsplatz und > ihre teils selbst angefertigten oder verbesserten Werkzeuge > vorzustellen. Aber der Tischler z.B. lernt erstmal mit der Rauhbank und dem Hobel, bevor er das Holz durch die NC-gesteuerte Hobelmaschine jagt. Übertragen bedeutet dies: 1. kein Windows - und wenn ja, dann LinuxUmgebung Cygwin oä 2. keine IDE 3. keine toolchain zu fuss also zB. als OS Linux oder FreeBSD oder MacOS, vim als Editor, clang oder gcc oder was auch immer auf Shell-Ebene aufrufen, Linker ebenfalls ( Verständnis, dass Linker und Compiler zwei ganz verschiedene Dinge sind ), Make probieren, selbst anpassen usw. usw. - dann je nach Umgebung noch AVRDude ... wenn das alles in Fleisch und Blut übergegangen ist - was Jahre dauert (für vim braucht man schon sehr lange, will aber irgendwann nie mehr darauf verzichten) , dann würde ich mal schauen, was an Eclipse, Netbeans, Studio usw. so genial ist. und wenn ich dann immer noch glaube, dass ich irgendwelchen Windows-Müll brauche, dann höchstes in ner virtuellen Maschine
Walter K. schrieb: > Aber der Tischler z.B. lernt erstmal mit der Rauhbank und dem Hobel, > bevor er das Holz durch die NC-gesteuerte Hobelmaschine jagt. > > Übertragen bedeutet dies: Gerne. Mich interessiert auch, wie Dein Arbeitsplatz aussieht. Weniger interessiert es mich, wie mein Arbeitsplatz Deiner Meinung nach aussehen sollte. Aber wenn Du magst, kannst Du das gerne auch vorstellen.
Aus dem schönen Salzburg gibts seit kurzem ein Visualisierungs-Tool das viele IDEs imho ziemlich alt aussehn lässt. Das Ding heißt Sourcetrail (https://www.sourcetrail.com/) und eignet sich wunderbar um die eigene oder fremde Codebasen zu "browsen". Recht beeindruckend sind vor allem die nahtlosen Übergänge zwischen graphischer Darstellung und tatsächlichem Code. Sehr zu meinem Erstaunen funktioniert das sogar mit absurd komplexen C++ Template Orgien und tausenden von Klassen. Eines meiner Testbeispiele umfasste eine Factory-Funktion, die 5942(!) Abhängigkeiten hatte... und obwohl Sourcetrail vor dem Öffnen eine kurze Warnung anzeigte war der Graph binnen Sekunden geladen und flüssig browsbar. Hier auch noch der entsprechende C++Now Talk des Entwicklers Eberhard Gräther: https://www.youtube.com/watch?v=fnIFVYFspfc Das Erstellen eines Projekts funktioniert recht schmerzlos, entweder durch indirektes Einbinden einer Compilation Database (via cmake/make) oder direkt als Visual Studio oder etwa Code::Blocks Projekt.
Ja, das finde ich auch genial, benutze es schon seit längerem ( Beitrag "Re: Wie viele Codelines in C/C++ Datei noch sinnvoll?" )
Vincent H. schrieb: > Aus dem schönen Salzburg gibts seit kurzem ein Visualisierungs-Tool Eigenwerbung?
Jörg W. schrieb: > Vincent H. schrieb: >> Aus dem schönen Salzburg gibts seit kurzem ein Visualisierungs-Tool > > Eigenwerbung? Nein ich bin aus dem noch viel schöneren Wien... ;)
Hatte mich nur gewundert, warum dafür eine schon ein halbes Jahr schlummernde Threadleiche exhumiert worden ist. ;-)
Vincent H. schrieb: > Aus dem schönen Salzburg gibts seit kurzem ein Visualisierungs-Tool das > viele IDEs imho ziemlich alt aussehn lässt. Das Ding heißt Sourcetrail > (https://www.sourcetrail.com/) und eignet sich wunderbar um die eigene > oder fremde Codebasen zu "browsen". Inwieweit ist Codetrail in Deinen Workflow eingebunden? Magst Du Deinen Werkzeugkasten kurz vorstellen?
Walter T. schrieb: > Inwieweit ist Codetrail in Deinen Workflow eingebunden? Magst Du Deinen > Werkzeugkasten kurz vorstellen? Sourcetrail hat Doxygen bei mir als "goto tool" ersetzt um fremden Code zu verstehen. Ich persönlich bin ein visueller Lerntyp und hab auch früher schon so Dinge wie flow/call/etc. graphs gezeichnet um mir ein grobes Bild eines Ablaufs zu machen. Genau für sowas is Sourcetrail gedacht. Das ist jetzt perse weder besonders neu noch originell. Was Sourcetrail aber einfach gut macht ist die Art und Weise wie alles aufbereitet wird. Die Grafiken sind super, das GUI ist intuitiv, es gibt sinnvolle Such- und Filteroptionen, die Graphen werden übersichtlich dargestellt und lassen sich ordnen, Hierachien lassen sich sinnvoll ein- und ausblenden... da kommen einfach sehr viele Kleinigkeiten zusammen.
Kann man diese Übergangsanimationen deaktivieren? Wenn mich was tierisch nervt, dann sowas.
Angehängte Dateien:
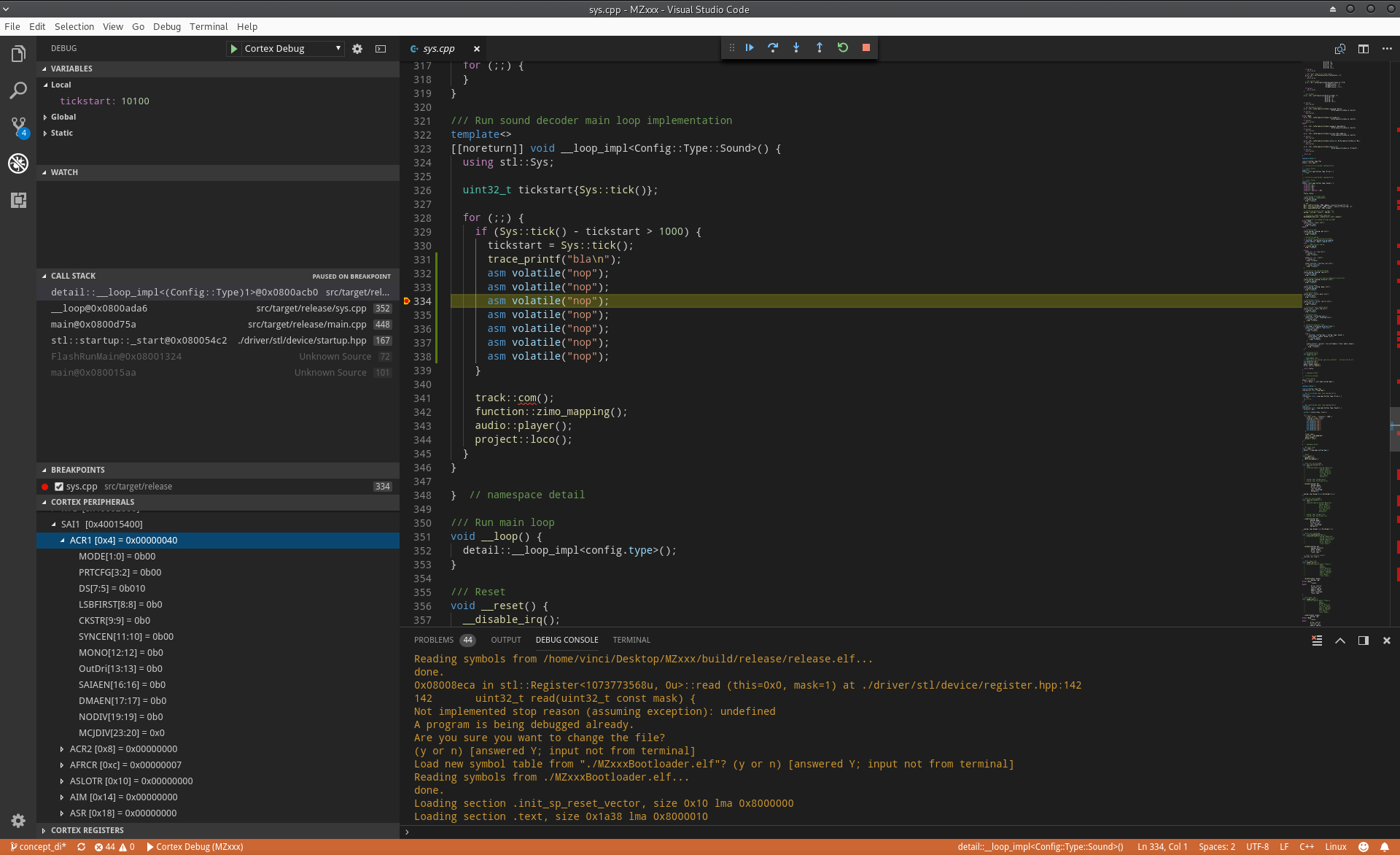
Bin nun bei Visual Studio Code und dem Cortex-Debug Plugin gelandet. Sehr zu meinem Erstauen hat sogar der Peripheral View out of the box funktioniert... Herrlich! Das einzige was dem Plugin aktuell abgeht ist semihosting, owa mei... des is sowieso viel zu lahm. :p
Walter K. schrieb: > Walter T. schrieb: >> Sehr merkwürdig. In den Holz-, Metall- und Kunststoffverarbeitungsforen >> lieben es die Teilnehmer, ihren liebevoll gestalteten Arbeitsplatz und >> ihre teils selbst angefertigten oder verbesserten Werkzeuge >> vorzustellen. > > Aber der Tischler z.B. lernt erstmal mit der Rauhbank und dem Hobel, > bevor er das Holz durch die NC-gesteuerte Hobelmaschine jagt. > > Übertragen bedeutet dies: > 1. kein Windows - und wenn ja, dann LinuxUmgebung Cygwin oä > 2. keine IDE > 3. keine toolchain zu fuss > > also zB. als OS Linux oder FreeBSD oder MacOS, vim als Editor, clang > oder gcc oder was auch immer auf Shell-Ebene aufrufen, Linker ebenfalls > ( Verständnis, dass Linker und Compiler zwei ganz verschiedene Dinge > sind ), Make probieren, selbst anpassen usw. usw. - dann je nach > Umgebung noch AVRDude ... > > wenn das alles in Fleisch und Blut übergegangen ist - was Jahre dauert > (für vim braucht man schon sehr lange, will aber irgendwann nie mehr > darauf verzichten) , dann > würde ich mal schauen, was an Eclipse, Netbeans, Studio usw. so genial > ist. > > und wenn ich dann immer noch glaube, dass ich irgendwelchen Windows-Müll > brauche, dann höchstes in ner virtuellen Maschine ..kann ich unterschreiben. Gruß, Holm
Holm T. schrieb: > ..kann ich unterschreiben. Du hast in diesem Jahrtausend eine Tischler-Ausbildung gemacht, bei der Du als Lehrling an keine moderne Maschine durftest? Und Du hieltest das für eine gute Idee?
Walter K. schrieb: > Verständnis, dass Linker und Compiler zwei ganz verschiedene Dinge > sind Das ist ja zum Beispiel sowieso erforderliches Wissen ohne das man C oder C++ überhaupt nicht verwenden kann. Es gehört zum Grundwissen von C oder wie soll man sonst verstehen was zum Beispiel das Schlüsselwort extern bedeutet, was es mit Headern auf sich hat, mit Deklaration vs Implementation. Und wie man Fehlermeldungen vom Linker zu deuten hat (dazu muß man wissen daß es den gibt und noch viel wichtiger was der macht und wann der das macht, womit der das macht und warum der das macht). Es ist absolut essentiell vollständig verstanden zu haben wie kompiliert und gelinkt wird und warum das zwei separate Schritte sind und welche Dateien da jeweils mit im Spiel sind wenn man mit C oder C++ arbeiten will. Anders gehts doch überhaupt nicht, nicht mal ansatzweise!
Um noch einmal das Thema klarzustellen: In diesem Thread ist jeder eingeladen, seine eigene Entwicklungsumgebung vorzustellen. Welche Werkzeuge er gern nutzt und warum. Es geht nicht darum, anderen zu erklären, warum sie keine Ahnung haben mögen.
Walter T. schrieb: > Holm T. schrieb: >> ..kann ich unterschreiben. > > Du hast in diesem Jahrtausend eine Tischler-Ausbildung gemacht, bei der > Du als Lehrling an keine moderne Maschine durftest? Und Du hieltest das > für eine gute Idee? Ich habe viele moderne Maschinen in den Fingern gehabt und habe dabei festgestellt das die modernen schön glänzen. Meine Ausbildung fand aber auch nicht in diesem Jahrtausend statt. Gruß, Holm
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.