Moin Moin liebe Sportsfreunde, es treffen sich bei bestem
Fußballwetter...
Zu meinem Anliegen:
>Ist es möglich und erlaubt, in C++ ein Template Interface zu definieren?>> Hintergrund:
Ich habe mir auf Basis eines Inetrfaces (also pure virtual class) ein
Grundgerüst gebaut, mit dessen Implementierung sich ein Graph aufbauen
und durchwandern lässt - nennen wir den Datentyp Graph_Element_I (siehe
ganz unten).
Zu dem Interface gehören dann z.B. Implementierungen wie Graph_Common,
Graph_Node und Graph_Leaf, wobei Node und Leaf von Common erben.
Nur in dem Zustand kann der Datentyp nichts anderes als eben aufgebaut
zu werden und durchwandert zu werden. Außer existieren kann er also noch
nichts.
>> Ansatz 1
Für mein Projekt habe ich einfach mein definiertes Interface um Methoden
erweitert, die ich für die eigentliche Applikation brauche.
Was mich daran stört ist, dass Graph_Element_I dann schon auf eine
Anwendung spezialisiert ist und nicht elegant für eine andere Anwendung
hergenommen werden kann ohne Altlasten mit zu schleppen.
>> Ansatz 2
Angenommen, der Interfacetyp würde über ein Template definiert, würde
man sich ein Interface definieren, welches alle für den nackten Graphen
nötigen Methoden enthält PLUS solche, die für die konkrete Anwendung
nötig sind.
Dann könnte man die konkreten Implementierungen Common, Node und Leaf
auf die eigenen vererben UND sie wären bereits vom Typ der finalen
Implementierungen was interessant ist, wenn man z.B. an sowas wie
"GetChild(int loc)" denkt. mit einem bloßem GraphInterface Typ würde ich
auch nur den bekommen und käme ohne Cast (was ich als unsicher und
unelegant sehe) nicht an meine "App Methoden".
Ich hatte auch die Idee, das Interface mit den Applikationsmethoden auf
das Graph Interface zu vererben, aber dann müsste ich das ja auch in der
Klassendefinition vom Graph_Elemen_I angeben. Das widerspricht der Idee,
dass man eine Art Graph Bibliothek hat, die nach debuggen tief im
Repository verschwindet und nie wieder angefasst wird.
>>> Appendix
class Graph_Element_I
{
public:
virtual int16_t Enter(Graph_Element_I** ittsCurNode, uint16_t destLoc) =
0;
virtual int16_t Esc(Graph_Element_I **ittsCurNode) = 0;
virtual void SetEntry(Graph_Element_I* ent) = 0;
virtual Graph_Element_I* GetEntry() = 0;
virtual uint16_t AmtOfChilds() = 0;
virtual uint8_t* GetName() = 0;
virtual List<Graph_Element_I*>* GetChildList() = 0;
virtual int16_t FindLoop(Graph_Element_I* candi) = 0;
};
>> ODER
class Graph_App_I // siehe AppMethod_1/2
{
public:
virtual int16_t Enter(Graph_Element_I** ittsCurNode, uint16_t destLoc) =
0;
virtual int16_t Esc(Graph_Element_I **ittsCurNode) = 0;
virtual void SetEntry(Graph_Element_I* ent) = 0;
virtual Graph_Element_I* GetEntry() = 0;
virtual uint16_t AmtOfChilds() = 0;
virtual uint8_t* GetName() = 0;
virtual List<Graph_Element_I*>* GetChildList() = 0;
virtual int16_t FindLoop(Graph_Element_I* candi) = 0;
virtual AppMethod_1() =0;
virtual AppMethod_2() =0;
};
template <typename T> class Graph_Element_I
{
public:
virtual int16_t Enter(Graph_Element_I** ittsCurNode, uint16_t destLoc) =
0;
virtual int16_t Esc(Graph_Element_I **ittsCurNode) = 0;
virtual void SetEntry(Graph_Element_I* ent) = 0;
virtual Graph_Element_I* GetEntry() = 0;
virtual uint16_t AmtOfChilds() = 0;
virtual uint8_t* GetName() = 0;
virtual List<Graph_Element_I*>* GetChildList() = 0;
virtual int16_t FindLoop(Graph_Element_I* candi) = 0;
};
Zoukrates schrieb:> Ist es möglich und erlaubt, in C++ ein Template Interface zu definieren?
In C++ gibt's keine Interfaces, nur abstrakte Klassen. Klassen dürften
Templates sein, auch abstrakte Klassen. Also ja. Sowas kann man übrigens
auch durch schlichtes Ausprobieren beantworten.
Wolltest du noch was anderes wissen...?
PS: Doppelpointer in C++? Muss das sein? Nicht lieber ne Referenz auf
Pointer?
Moin,
Zoukrates schrieb:> Was mich daran stört ist, dass Graph_Element_I dann schon auf eine> Anwendung spezialisiert ist und nicht elegant für eine andere Anwendung> hergenommen werden kann ohne Altlasten mit zu schleppen.
Ehrlich gesagt, kann ich Deinen Ausführungen nicht ganz folgen. Aber:
Wenn Du einen überschaubaren Satz an Datentypen hast und die Applikation
tendentiel eher in Richtung zu immer mehr Funktionen auf diesen Daten
wächst, dann bietet sich das observer-pattern an.
Dabei haben die Datenstrukturen im wesentlichen die Funktion, von einem
observer iteriert werden zu können. Für jede Funktion definiert man dann
einen observer, der dann gezielt die gewünschte Funktion auf den
bestimmten Typen anwendet.
> template <typename T> class Graph_Element_I> {> public:>> virtual int16_t Enter(Graph_Element_I** ittsCurNode, uint16_t destLoc) => 0;
Ja, dass ist gültiges C++. Allerdings sind die Typen Graph_Element_I<
int > und z.b. Graph_Element_I< char > Basisklassen für zwei
unterschiedliche Hierarchien (wahrscheinlich nicht dass, was Du suchst)
und stehen in keiner "is a" Relation.
mfg Torsten
> Das mit dem Interface in C++ ist mir klar - ich benutzt das im Ausdruck nur so,
weil es im Sprachgebrauch und beim Schreiben flüssiger ist.
> Graph_Element_I<int > und z.b. Graph_Element_I< char >
habe ich in der Art nicht vor.
Es wird eher ein Interface geben, dass Typ für alle Klassen sein soll,
die in der Anwendung genutzt werden und das geht als Typdefinition an
das "Templateinterface" á la
MyAppMethods_I
{
/*
pure virtuelle Graph_Methoden...
*/
/*
pure virtuelle App_Methoden...
*/
}
Graph_Element_I <MyAppMethods_I>
{
/*
pure virtuelle Graph_Methoden...
*/
}
Wenn der Compiler clever ist, merkt er, daß Graph_Element_I gar nicht
von T abhängt.
Ja, ich geb zu, Zweifel an der Cleverness sind angebracht.
Es bleibt allerdings der Einwand, daß "template<typename T> nur dann
Sinn macht, wenn T irgendwo danach benutzt wird.
Carl D. schrieb:> Es bleibt allerdings der Einwand, daß "template<typename T> nur dann> Sinn macht, wenn T irgendwo danach benutzt wird.
Wir haben das mal in einer String-Klasse eingesetzt, die im wesentlichen
die max. Länge als Parameter hatte. Damit bei Strings gleicher Länge,
aber unterschiedlichem Domain-Typen keine Zuweisung etc. möglich waren,
gab es dann noch einen zweiten Parameter (Tag-Type).
Torsten R. schrieb:> Carl D. schrieb:>>> Es bleibt allerdings der Einwand, daß "template<typename T> nur dann>> Sinn macht, wenn T irgendwo danach benutzt wird.>> Wir haben das mal in einer String-Klasse eingesetzt, die im wesentlichen> die max. Länge als Parameter hatte. Damit bei Strings gleicher Länge,> aber unterschiedlichem Domain-Typen keine Zuweisung etc. möglich waren,> gab es dann noch einen zweiten Parameter (Tag-Type).
Wir sind uns aber einig, daß der TO kein ausgebuffter C++-Programmierer
ist und diesen Anwendungsfall nicht mal ahnt, oder?
Carl D. schrieb:> Wir sind uns aber einig, daß der TO kein ausgebuffter C++-Programmierer> ist und diesen Anwendungsfall nicht mal ahnt, oder?
Ja, da sind wir uns einig. Mir ist auch nicht ganz klar, welches Problem
der TO lösen möchte. :-) Von daher ist Dein Einwand auf jeden Fall
richtig (vielleicht nur nicht mit der Absolutheit).
>Welches Problem will ich lösen?
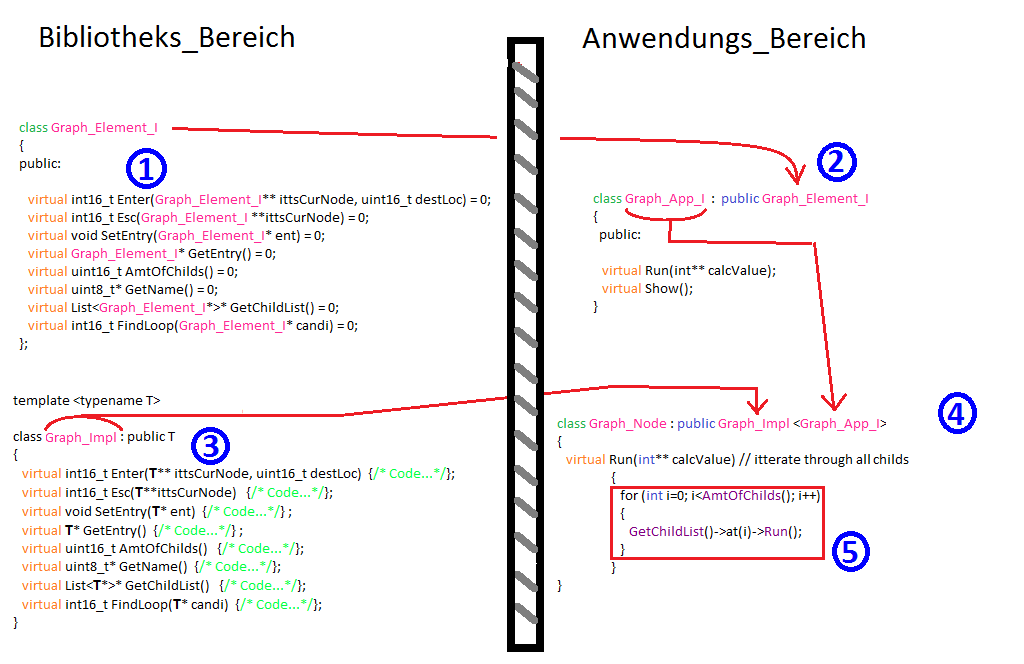
Oft sagen Bilder mehr als tausend Worte, daher hab ich eine Art Skizze
angehängt, was ich mir vorstelle, auch wenn ich es jetzt nicht im ISO
UML gemacht habe...
>>Der springende Punkt ist Punkt 5.
In meiner Anwendung gibt es eine Methode Run(), welche rekursiv auf den
Nodes arbeitet. Wenn ich nur das einfache Graph_Interface von Punkt 1
nei der Implementierung bei Punkt 3 verwende, erreiche ich über
GetChildList->at(index)
die Run() Methode nicht. Jedenfalls nicht ohne Cast, was ich wie gesagt
nicht elegant finde und auch die Sicherheit anzweifle (mit Recht?).
Daher die Idee, im Bibliothekbereich ein Interface bereit zu stellen
(Punkt 1), welches im Anwendungsbereich vererbt wird (Punkt 2) und bei
Punkt 3 mit einer template-basierten Implementierung (Punkt 4)
zusammengeführt wird.
Ganz verstehe ich es noch nicht recht: Wieso ist es Aufgabe des
Applikationsteils, alle Knoten des Graphen durchzulaufen? Sollte das
nicht eher eine Funktion von Graph_Impl sein?
Oder möchtest du, dass verschiedene Durchlauffunktionen existieren, die
dann pro Knoten verschiedene Sachen machen?
>Oder möchtest du, dass verschiedene Durchlauffunktionen existieren
Zum einen das - es wird am Ende Nodes und Leafs geben, die Run()
unterschiedlich implementieren
> und zum anderen>Wieso ist es Aufgabe des>Applikationsteils, alle Knoten des Graphen durchzulaufen
Ich stell mir das so vor, dass der die Graph Files im Bibliotheksbereich
nur eine Grundimplementierung bieten, mit denen sich ein Graph aufbauen
und durchlaufen lässt.
Das was konkret in der Applikation gemacht werden soll, seh ich als
sinnvoll auch dort implementiert zu haben.
Dann lassen sich die Basisimplementierungen von Graph auch für andere
zwecke hernehmen ohne Fremdmethoden dabei zu haben.
Zoukrates schrieb:>>Welches Problem will ich lösen?>> Oft sagen Bilder mehr als tausend Worte, daher hab ich eine Art Skizze> angehängt, was ich mir vorstelle, auch wenn ich es jetzt nicht im ISO> UML gemacht habe...
Ja, aber in dem Fall ist auf dem Bild ja auch nur Code.
> In meiner Anwendung gibt es eine Methode Run(), welche rekursiv auf den> Nodes arbeitet.
Du möchtest einen generischen Graphen, den Du traversieren kannst? Wenn
ja, warum schreibst Du das nicht. Wenn dem so ist, da gäbe es was von
Boost (http://www.boost.org/doc/libs/1_66_0/libs/graph/doc/index.html).
> Wenn ich nur das einfache Graph_Interface von Punkt 1> nei der Implementierung bei Punkt 3 verwende, erreiche ich über> GetChildList->at(index)> die Run() Methode nicht. Jedenfalls nicht ohne Cast, was ich wie gesagt> nicht elegant finde und auch die Sicherheit anzweifle (mit Recht?).
Das scheint ein Teil-Problem, Deiner Lösung zu Deinem Problem zu sein.
Schwer etwas dazu zu sagen, wenn Du uns verschweigst, welches Problem Du
lösen möchtest.
Duck Mc Scrooge schrieb:>>Wieso ist es Aufgabe des>>Applikationsteils, alle Knoten des Graphen durchzulaufen> Ich stell mir das so vor, dass der die Graph Files im Bibliotheksbereich> nur eine Grundimplementierung bieten, mit denen sich ein Graph aufbauen> und durchlaufen lässt.> Das was konkret in der Applikation gemacht werden soll, seh ich als> sinnvoll auch dort implementiert zu haben.> Dann lassen sich die Basisimplementierungen von Graph auch für andere> zwecke hernehmen ohne Fremdmethoden dabei zu haben.
Dann ist die Implementierung von Run() im Applikationsteil falsch
platziert; das gehört in den Bibliotheks-Teil.
Ich würde in Graph_impl<T> die nicht-virtuelle Funktion Run()
implementieren mit folgender Schnittstelle:
1
template<typenameOP>
2
voidRun(OP&&op);
die dann im Applikationsteil so verwendet wird:
1
intcalcValue=0;
2
that_graph.Run([&](Graph_App_I&element){
3
calcValue+=element.wasauchimmer;
4
element.Show();
5
});
Ich nehme dabei an, dass Graph_App_I die anwendungsspezifischen Daten
eines Knotens enthält.
Die Klasse Graph_Node in deiner Abbildung müsste m.E. im
Bibliotheks-Teil liegen.
Im übrigen denke ich, dass es möglich ist, vollkommen ohne virtuelle
Funktionen auszukommen.
Wie Robitzki richtig ahnt, gibt es ein übergeordnetes Ziel. Das habe ich
zu Anfang nicht komplett ausgebreitet, weil ich nur eine Frage zu einem
Teilaspekt hatte.
Insgesamt soll es ein generischer Graph sein (danke für die Vokabeln),
dessen Funktionalität von außen erweitert werden kann.
Dazu kommen zwei wichtige Details:
1)
die Member der Liste, welche über GetChildList() erreicht werden,
können sowohl Nodes, wie auch Leafs sein.
2)
In der Anwendung kann es verschiedene Implementierungen von Nodes und
Leafs geben.
Aus den beiden Punkten ergibt sich meiner Meinung nach, dass es schon
nötig istInterfaces einzusetzten und zum anderen Sinn macht, auf Grund
verschiedener (in diesem Fall) Run() Implementierungen diese in
abgeleiteten Klassen im Anwendungsbereich zu machen.
Zoukrates schrieb:> 1)> die Member der Liste, welche über GetChildList() erreicht werden,> können sowohl Nodes, wie auch Leafs sein.
Warum willst Du das machen? Du hast einen Graphen. Wenn Du die Anwendung
hast, mit alles Knoten im Graphen etwas zu machen, dann sag dem Graphen
doch, was Du mit den Knoten machen möchtest:
1
constgraphall=...;
2
all.for_each([](constnode&n){n....;});
list< T* > ist (fast) immer falsch. Die Performance von so etwas ist
unterirdisch.
> 2)> In der Anwendung kann es verschiedene Implementierungen von Nodes und> Leafs geben.
Du möchtest einen Baum? Welche Eigenschaften haben den die Nodes, ausser
dass sie leafes enhalten?
> Aus den beiden Punkten ergibt sich meiner Meinung nach, dass es schon> nötig istInterfaces einzusetzten und zum anderen Sinn macht, auf Grund> verschiedener (in diesem Fall) Run() Implementierungen diese in> abgeleiteten Klassen im Anwendungsbereich zu machen.
Wenn den Eigenschaften deiner Datenstruktur zur Compile-Zeit bekannt
sind, solltest Du ohne Polymorphie auskommen.
Erstmal danke, für die kritischen Fragen Robitzki - ich denke in diesem
Fall lerne ich am meisten, Dinge zu hinterfragen.
Ich gebe zu, ich hatte schon mal den Eindruck, dass ich Interfaces zu
inflationär einsetzte.
> const graph all = ...;> all.for_each( []( const node& n ) { n....; } );
Das kann ich leider nicht lesen - da fehlt mir wohl das Plugin zum
passenden C++ Standard.
Dazu vll. als Hintergrund: Ich baue an einem Entwurf, der auch auf
embedded läuft und für mein Zielsystem unterstützt der Compiler bis C++
2003.
>list< T* > ist (fast) immer falsch. Die Performance von so etwas ist>unterirdisch.
Welche stelle in der Skizze meinst du? Vll. hab ich was übersehen.
GetChilList() liefert List<T*>* , also einen Zeiger auf eine Zeigerliste
- einen Zeiger zurückgeben müsste doch mit das schnellste sein, dass man
machen kann?
>Welche Eigenschaften haben den die Nodes, ausser>dass sie leafes enhalten?
Die Nodes und Leafs können sich graphisch darstellen. Das habe ich über
ein Visitor Pattern gelöst. Es wird von verschiedenen Arten von
Nodes/Leafs auch verschiedene GUIs geben.
Auch den Aspekt hatte ich eingangs weggelassen, weil es mir hier um
einen Teilaspekt ging und ich nicht nach einer Gesamtlösung fragen
wollte.
Erstens wäre es für mich langweilig^^ und zum anderen röche das arg nach
"Ich hab da ne Idee - macht mal für mich"
Bei den angedeuteten Leaf Varianten 1 und 2 z.B. kann über die GUI der
Wert zum addieren/multiplizieren verändert werden.
Zoukrates schrieb:> Das kann ich leider nicht lesen - da fehlt mir wohl das Plugin zum> passenden C++ Standard.
Das ist ein Lambda (eine lokale Funktion), die gibt es jetzt schon seit
2011. Gerade mit C++11 kamen sehr viele Neuerungen, die für Embedded
sehr wertvoll sind. Vielleicht solltest Du Deinen Compiler mal
aktualisieren.
> Dazu vll. als Hintergrund: Ich baue an einem Entwurf, der auch auf> embedded läuft und für mein Zielsystem unterstützt der Compiler bis C++> 2003.
C++03 sind ja nur ein paar kleine Fixes, der da hinter stehende Standard
ist von 1998. Das sind 20 Jahre! :-)
> Welche stelle in der Skizze meinst du? Vll. hab ich was übersehen.> GetChilList() liefert List<T*>* , also einen Zeiger auf eine Zeigerliste> - einen Zeiger zurückgeben müsste doch mit das schnellste sein, dass man> machen kann?
Ups, habe ich übersehen. So wird es ja noch schlimmer. Dann musst Du ja
noch zusätzlich die std::list dynamisch anlegen. Selbst ältere C++
Compiler können in der Regel RVO (Return Value Optimization) und gerade
bei Zeigern als Elemente, ergibt eine std::list<> überhaupt keinen Sinn.
(Wenn dann warscheinlich std::vector< const T* >).
Aber warum um alles in der Welt willst Du so eine Funktion überhaupt
haben, wenn Du mit einem Visitor über alle Elemente Deines Baums
iterieren kannst?
>>Welche Eigenschaften haben den die Nodes, ausser>>dass sie leafes enhalten?> Die Nodes und Leafs können sich graphisch darstellen.
Also Unterscheiden sich Nodes und Leaves nicht?
> Das habe ich über> ein Visitor Pattern gelöst.
Das klingt vernünftig. Nur wie passt das mit dem obigen Ansatz zusammen?
Wenn ich einen generischen Graphen / Baum hätte, den ich mit einem
Visitor besuchen könnte, sähe die Verwendung in etwa so aus (C++98):
1
structleave{};
2
structnode{};
3
4
tree<leave,node>all_nodes=...;
5
6
struct:tree<leave,node>::visitor
7
{
8
virtualvisit(constleave&l)
9
{
10
print(l);
11
}
12
13
virtualvisit(constnode&n)
14
{
15
print(n);
16
}
17
}printer;
18
19
all_nodes.visit(printer);
> Auch den Aspekt hatte ich eingangs weggelassen, weil es mir hier um> einen Teilaspekt ging und ich nicht nach einer Gesamtlösung fragen> wollte.
Das Problem ist, dass wenn ein Anfänger mit seiner Lösung kommt, uns
aber das Problem nicht verrät, dann wird es extrem schwierig zu
verstehen, was Du überhaupt erreichen möchtest. Es kann Dir auch keiner
einen Tipp geben, dass es evtl. eine viel bessere Lösung für Dein
Problem gibt.
> Bei den angedeuteten Leaf Varianten 1 und 2 z.B. kann über die GUI der> Wert zum addieren/multiplizieren verändert werden.
"Der Wert zum addieren/multiplizieren" kommt jetzt zum ersten mal in
Deiner Beschreibung vor. Wie sollen wir Dich so verstehen?
Da sind einige Punkte, wo ich mir mit mehr Ruhe Gedanken machen muss.
Ich picke jetzt mal nur die Sache mit dem
List<T*>* GetChildList();
heraus.
Wieso muss ich die Liste dann dynamisch anlegen? Bzw. meinst du damit
jedes Mal wenn die Methode aufgerufen wird oder nur eben wenn die Liste
aufgebaut wird? Hinter der versteckt sich jedenfalls kein new List<T*>,
nur die Adressrückgabe einer bestehenden Liste.
Naja, an dieser Stelle kann ich mir trotz µC embedded den Luxus leisten
für die Liste dynamisch zu allozieren. Das System wird nicht 24/7/365
laufen.
Ich kann es mir vom Design her leisten gelegentlich einen Reset aus zu
führen, um den Heap frei zu kriegen.
Ich meine wenn ich mir dann einen Interfacetypen Graph_App_I denke, den
Graph aus diesem Typ aufbaue und eine Zeigervariable habe á la
List<Graph_App_I*>* childListPtr;
childListPtr = GetChildList();
dann muss doch nichts dynamisch angelegt werden?
Zoukrates schrieb:> Ich meine wenn ich mir dann einen Interfacetypen Graph_App_I denke, den> Graph aus diesem Typ aufbaue und eine Zeigervariable habe á la>> List<Graph_App_I*>* childListPtr;> childListPtr = GetChildList();>> dann muss doch nichts dynamisch angelegt werden?
Wenn Du nicht vor hast, das Ergebnis dynamsich zu alloziieren, warum um
alles in der Welt gibst Du dann einen Zeiger zurück? Und nicht einfach
eine Referenz? Und warum std::list? Die "übliche" Wahl in dem Fall,
wäre: std::vector< const Graph_App_I* >& oder ein Paar von Iteratoren.
Torsten R. schrieb:> struct leave {};
leaf! (To) leave ist ein Verb und heisst verlassen oder (weg) gehen.
Ansonsten: weiter so! :-) Ist eine interessante Konversation hier!
Torsten R. schrieb:> Die "übliche" Wahl in dem Fall,> wäre: std::vector< const Graph_App_I* >& oder ein Paar von Iteratoren.
Ich hätte gedacht, die übliche Wahl wäre, das Objekt gleich iterierbar
zu machen.
Rolf M. schrieb:> Torsten R. schrieb:>> Die "übliche" Wahl in dem Fall,>> wäre: std::vector< const Graph_App_I* >& oder ein Paar von Iteratoren.>> Ich hätte gedacht, die übliche Wahl wäre, das Objekt gleich iterierbar> zu machen.
Zoukrates wollte auf dieses Detail eingehen. Meiner Meinung nach sollte
es diese Funktion (GetChildList()) nicht geben.
Wenn ich einen generische Graphen / Baum habe, dann muss ich mir auch
überlegen, wie ich den Nutzer auf die einzelnden Knoten / Blätter
zugreifen lassen möchte. Das kann je nach Anwendungsfall deutlich
unterschiedlich sein (depeth first/breadth first, gefilter/ ungefilter,
usw.).
Egal wie ich mich entscheide, eine Funktion die eine Liste aller Knoten
im Graphen zurück liefert, müsste da redundant sein.
Das letze "übliche Wahl" bezieht sich somit einfach auf die
Implementierung einer Funktion, die eine Liste von Referenzen auf
Objekte zurück gibt.
Es wäre schon hilfreich etwas mehr über den ominösen Graphen zu
erfahren:
* Ist er wirklich einen generischen Graphen, oder ist er vielleicht doch
- gerichtet
- azyklisch
- oder sogar ein Baum?
* Gibt es wirklich einen Unterschied zwischen den Blättern (Leaf /
Leaves) und den restlichen Knoten?
Ich musste die Begrifflichkeiten erstmal googlen...
Gerichtet - eher nein, Kannten können in beiden Richtungen bewandert
werden
Azyklish - letztendlich ja, Run() rekursiv implementiert ist
ein Baum? - nein
Unterschied Blättern/Knoten - ja, Run() tut nur in den Leafs tatsächlich
etwas, in den Knoten wird eine Berechnung ausgeführt. Außerdem haben die
Leafs keine children, d.h. GetChilList kann statisch NULL zurückgeben,
Enter() ist anders implementiert und FindLoop() auch.
FindLoop() testet vor dem Einfügen eines Kandidaten, ob ein Zyklus
entstehen würde. Da bei mir der Graph zur Laufzeit aufgebaut wird, bin
ich zum Glück nicht in der Situation, einen bestehenden Graphen auf die
Existenz von Zyklen prüfen zu müssen.
Zoukrates schrieb:> Ich musste die Begrifflichkeiten erstmal googlen...>> Gerichtet - eher nein, Kannten können in beiden Richtungen bewandert> werden
Dann passt der Begriff "Child(ren)" nicht, oder du brauchst zu jedem
Knoten und Blatt auch eine Funktion getParent() oder sogar getParents().
Wie kannst du sonst "rückwärts" laufen?
> Azyklish - letztendlich ja, Run() rekursiv implementiert ist> ein Baum? - nein
Wenn deine Datenstruktur kein Baum ist und die Kanten können in beide
Richtungen bewandert werden, dann ist es aber ein zyklischer Graph.
> Unterschied Blättern/Knoten - ja, Run() tut nur in den Leafs tatsächlich> etwas, in den Knoten wird eine Berechnung ausgeführt.
Ok, das klingt dann doch wieder nach einem Baum oder wenigstens nach
einem DAG (directed acyclic Graph). Wenn deine Struktur ein DAG
entspricht musst du aber aufpassen, dass beim rekursiven durchwandern
nicht bestimmte Teile von deinem Graphen doppelt durchlaufen werden:
1
,->- B ->-.
2
A D <-- D wird u.U. doppelt "ausgeführt"!
3
`->- C ->-´
A ruft rekursiv B und C auf. B ruft dann rekursiv D auf, C aber auch, da
C nicht weiss, dass/ob D schon von B aufgerufen wurde.
> Außerdem haben die> Leafs keine children, d.h. GetChilList kann statisch NULL zurückgeben,
Das ist ja das was ein Leaf zu einem Leaf macht :-)
mhhh... ok, vielleicht hab ich mir die Bedeutungen falsch
zusammengegoogelt.
Erstmal ganz fundamental:
So wie ich den Unterschied zwischen Baum und Graph verstanden habe,
definiert sich ein Baum (jedenfalls ein binärer) darüber, das ein Knoten
genau zwei Nachfolger hat und genau einen Vorgänger.
In dem was ich habe, kann der selbe Knoten ggf. aus verschiedenen
anderen Knoten erreicht werden; d.h. die Adresse eines Knoten kann in
der Childliste mehrerer anderer Knoten vorkommen. Das ist der
Hintergrund von Set/GetEntry(); bevor ein Knoten betreten wird, wird die
Adresse der Herkunft hinterlegt - ähnlich, wie wenn man in einem
Labyrinth Schnippsel an Kreuzungen ablegt.
Ich versuch´s mal in Ottonormalverbrauchersparache:
>Verbindungen zwischen Elementen können in beiden Richtungen bewandert werden.
(ungerichtet?)
>Es soll wegen der rekursiven Implementierung von Run() keine Möglichkeit/Gefahr
bestehen, dass "Kreise" entstehen (Zyklen?).
Zoukrates schrieb:> mhhh... ok, vielleicht hab ich mir die Bedeutungen falsch> zusammengegoogelt.>> Erstmal ganz fundamental:> So wie ich den Unterschied zwischen Baum und Graph verstanden habe,> definiert sich ein Baum (jedenfalls ein binärer) darüber, das ein Knoten> genau zwei Nachfolger hat und genau einen Vorgänger.
Nein.
Ein Graph ist eine Struktur, die eine Menge von Objekten (Knoten/Nodes)
zusammen mit den zwischen diesen Objekten bestehenden Verbindungen
(Kanten/Edges) repräsentiert.
Ein Baum ist ein spezieller Typ von Graph, der zusammenhängend ist und
keine geschlossenen Pfade enthält. Ein binärer Baum ist nur eine Sorte
aus vielen.
https://de.wikipedia.org/wiki/Graph_(Graphentheorie)https://de.wikipedia.org/wiki/Baum_(Graphentheorie)> In dem was ich habe, kann der selbe Knoten ggf. aus verschiedenen> anderen Knoten erreicht werden d.h. die Adresse eines Knoten kann in> der Childliste mehrerer anderer Knoten vorkommen.
Ok, damit ist dein Graph sicherlich kein Baum.
> Hintergrund von Set/GetEntry(); bevor ein Knoten betreten wird, wird die> Adresse der Herkunft hinterlegt - ähnlich, wie wenn man in einem> Labyrinth Schnippsel an Kreuzungen ablegt.
Dann aber nicht vergessen nach dem Run() die Schnipsel wieder
aufzuräumen . Nicht dass die bei einem nächsten Run() alles blockieren
:-)
>>Verbindungen zwischen Elementen können in beiden Richtungen bewandert werden.> (ungerichtet?)
Das wäre ungerichtet, ja. Ich sehe in deiner PNG oben aber keine
Funktionen die dir vom Child zum Parent führen. Ohne die kannst du die
Verbindungen also nicht in beiden Richtungen bewandern.
>Ich sehe in deiner PNG oben aber keine Funktionen die dir vom Child zum Parent
führen
Da hab ich die Zusammenhänge nicht deutlich genug differenziert - Run()
macht keine Verwendung von den "Schnippseln" mit den Eintrittsadressen -
bei der in den Nodes rekursiven Implementierung ist das ja auch nicht
nötig - da "wandert" ja nichts.
Die Methoden die zum durchwandern benutzt werden sind sinngemäß
Enter(uint16_t childSel)
Esc()
SetEntry(T* entry)
T* GetEntry()
Vor dem Eintritt wird über SetEntry(T* entry) die Herkunft gespeichert
und bei ESC() kann die Herkunftsadresse wieder abgerufen werden.
Bei mir führen Set/GetEntry allerdings keine Stacks, wo
Herkunftsadressen bei mehrfachen Eintritten gespeichert werden - ist für
meine Anwendung aber auch nicht nötig.
Wobei, wenn ein Graph azyklisch ist, ist das wahrscheinlich ohnehin
nicht nötig.(?)
Zoukrates schrieb:> Da hab ich die Zusammenhänge nicht deutlich genug differenziert - Run()> macht keine Verwendung von den "Schnippseln" mit den Eintrittsadressen -> bei der in den Nodes rekursiven Implementierung ist das ja auch nicht> nötig - da "wandert" ja nichts.
Das verstehe ich jetzt nicht. "Wandern" ist doch nichts anderes als
rekursiv den Graphen durchlaufen? Du schreibst ja weiter oben:
Zoukrates schrieb:> In meiner Anwendung gibt es eine Methode Run(), welche rekursiv auf den> Nodes arbeitet.
Da man über mehrere Wegen zu einem Knoten (oder Blatt) kommen kann,
musst du irgendwie merken welche Knoten schon bewandert wurden um
mehrfaches Ausführen vom Run() vorzubeugen -- es sei denn, das ist nicht
wichtig oder sogar gewollt. Siehe mein Minimalbeispiel weiter oben:
Eric B. schrieb:
>Das verstehe ich jetzt nicht. "Wandern" ist doch nichts anderes als>rekursiv den Graphen durchlaufen?
Unter wandern verstehe ich, wenn "etwas" das nicht Teil einer Struktur
ist Möglichkeiten bekommt, verschiedene Punkte der Struktur zu besuchen.
Also einen Zeiger vom Typ der Knoten der Struktur hat (T* currentNode;)
und z.B. vereinfacht sowas machen kann
currentNode = currentNode->GetChildAt(2);//Enter
bzw.
currentNode = currentNode->GetEntry();//Esc
Aber Rekursion verschachtelt sich in Funktions/Methoden Aufrufen.
(da sollte ich vll. nochmal über die Auslastung des Stack nachdenken)
Zoukrates schrieb:>>Das verstehe ich jetzt nicht. "Wandern" ist doch nichts anderes als>>rekursiv den Graphen durchlaufen?>> Unter wandern verstehe ich, wenn "etwas" das nicht Teil einer Struktur> ist Möglichkeiten bekommt, verschiedene Punkte der Struktur zu besuchen.
Warum würde dieses "etwas" das wollen? Und woher sollte der wissen
welche Punkte der Struktur er besuchen will?
Zur Inspiration ein bisschen Python (altmodisches 2.7, sorry) im Anhang.
Output ist:
Wenn du den Unterschied zwischen Knoten und Blätter auflöst und ein
Blatt einfach daran erkennst, dass die Liste der Kindern leer ist, wird
es noch einfacher.
Schwieriger wird es wenn alle Knoten nur einmal besucht werden sollen...
Eric B. schrieb:> Schwieriger wird es wenn alle Knoten nur einmal besucht werden sollen...
Aber auch nicht so viel schwieriger wenn man ein bisschen darüber
nachdenkt :-)
Naja, wir sind ja schon ein ganzes Stück vom Thema meines Eingangsposts
weg - da hatte ich nur eine Detailfrage während wir inzwischen schon bei
dem Grund für die ganze Architektur sind.
Mal sehen, ob ich es nachvollziehbar in Worte gefasst bekomme:
Zunächst mal haben die Möglichkeit über die Struktur zu itterieren und
die Run() Methoden nur gemeinsam, dass sie sich die selbe Struktur zu
Nutze machen. Das Itterieren und Run() brauchen einander jedoch nicht,
da sie unterschiedlichen Zwecken dienen.
In den Leafs wird bei Run() eine konkrete Rechnung ausgeführt.
In den Nodes werden Rekursiv die Run() Methoden der Member aus der
Childlist aufgerufen.
Das Itterieren wird für die graphische Darstellung genutzt. Wird ein
Member betreten, wird über das Visitor Pattern die passende
Visualisierung aufgerufen. Bei den Leafs lassen sich die Parameter
verändern, mit denen die Berechnungen der jeweiligen Instanz ausgeführt
werden.
D.h. das Itterieren bildet eine Menuestruktur ab.
Nodes fassen Leafs und andere Nodes zu funktional ähnlichen Gruppen
zusammen.
>Beispiel:
Ich brauche zwei "Ausgänge" die gemeinsam haben, dass sie auf einen Feed
eine Multiplikation von 5 ausführen, dann 2 addieren und noch eine
Tiefpassfunktion anwenden und dann aber jeweils noch eine
Unterschiedliche letzte Skalierung.
Dann erzeuge ich erstmal einen Node "A", der eben Leafs hat die
*5
+2
Tiefpass
machen
Dann erzeuge ich einen Node B_1 der in die Childliste die Referenz von A
bekommt und einen Leaf mit
*0,5
und erzeuge einen Node B_2 der in die Childliste die Referenz von A
bekommt und einen Leaf mit
*0,75 bekommt.
Zoukrates schrieb:> In den Leafs wird bei Run() eine konkrete Rechnung ausgeführt.> In den Nodes werden Rekursiv die Run() Methoden der Member aus der> Childlist aufgerufen.
Genau dieses rekursive Aufrufen ist iterieren!
> Das Itterieren wird für die graphische Darstellung genutzt.
Aber grundlegend macht es doch kein Unterschied ob ich in den Run()
Funktionen irgendwas berechne oder eine graphische Darstellung
generiere?
(Und iterieren hat nur einen T :-))
Eric B. schrieb:> Zoukrates schrieb:>>> In den Leafs wird bei Run() eine konkrete Rechnung ausgeführt.>> In den Nodes werden Rekursiv die Run() Methoden der Member aus der>> Childlist aufgerufen.>> Genau dieses rekursive Aufrufen ist iterieren!
Nein. Entweder ich mache es iterativ oder rekursiv. Iterieren heißt,
dass man eine Schleife und eben keine Rekursion verwendet.
Siehe https://de.wikipedia.org/wiki/Iterative_Programmierung
Zoukrates schrieb:> Naja, wir sind ja schon ein ganzes Stück vom Thema meines> Eingangsposts> weg - da hatte ich nur eine Detailfrage während wir inzwischen schon bei> dem Grund für die ganze Architektur sind.
Na ja, es sollte doch immer das Keep-It-Simple-Prinzip reichen. Ist doch
gar nicht so falsch, unnötige Polymorphie zu kicken - Vererbung ist doch
eine der stärksten Abhängigkeiten in einer Architektur. Und unnötige
Kopplung an saukomplizierte Schnittstellen bringt doch nix.
Ich finde, es würde eine Lösung über das Visitor-Pattern reichen,
zumindest für dein Additions/Multiplikations-Zeug. Ob du Dir nen
Gefallen tust, den Graph generischst möglich zu machen, wag ich zu
bezweifeln - wie teuer sollen denn die Iterationskosten im Graphen
bitteschön werden, wenn du dreimal rundherum traversierst?
> In den Leafs wird bei Run() eine konkrete Rechnung ausgeführt.> In den Nodes werden Rekursiv die Run() Methoden der Member aus der> Childlist aufgerufen.
Was braucht denn bitte ein Knoten im Graph eine Berechnung auszuführen?
Warum nicht einfach den Graph zur reinen Datenhaltung nehmen und einen
zu implementierenden Visitor die Operationen auf dem Graphen
implementieren lassen?
Performance ist selbst dann noch 'ne andere Sache, da muss man dann
sehen, ob man mit assoziativen Containern Kosten drücken kann.
> Das Itterieren wird für die graphische Darstellung genutzt. Wird ein> Member betreten, wird über das Visitor Pattern die passende> Visualisierung aufgerufen. Bei den Leafs lassen sich die Parameter> verändern, mit denen die Berechnungen der jeweiligen Instanz ausgeführt> werden.> D.h. das Itterieren bildet eine Menuestruktur ab.> Nodes fassen Leafs und andere Nodes zu funktional ähnlichen Gruppen> zusammen.
Verstehe aber, was du erreichen willst, hatte ich auch mal probiert -
für Menüstrukturen würde ich lieber 'nen MVC nehmen und keinen Graphen
bauen.
>>Beispiel:> Ich brauche zwei "Ausgänge" die gemeinsam haben, dass sie auf einen Feed> eine Multiplikation von 5 ausführen, dann 2 addieren und noch eine> Tiefpassfunktion anwenden und dann aber jeweils noch eine> Unterschiedliche letzte Skalierung.
Was willste machen, sowas hier?
http://www.boost.org/doc/libs/1_46_1/libs/spirit/example/qi/calc2_ast.cpp
Dann hättest du ja auf jeden Fall ne Baumstruktur und könnest deinen
Graphen entsprechend vereinfachen - einfach von der Wurzel beginnend die
Teilbäume durchtraversieren.
>wie teuer sollen denn die Iterationskosten im Graphen>bitteschön werden, wenn du dreimal rundherum traversierst?
Dem kann ich nicht ganz folgen - welche Kosten meinst du? (schon klar,
dass es keine monetären sind).
Das Traversieren wird von der Bedienungsoberfläche gemacht durch den
Nutzer also nicht mit zig Kilohertz.
So wie ich das sehe, belastet Traversieren nicht den Stack, also
jedenfalls nicht im Sinne von ineinander geschachtelten
Methodenaufrufen.
>Warum nicht einfach den Graph zur reinen Datenhaltung nehmen und einen>zu implementierenden Visitor die Operationen auf dem Graphen>implementieren lassen?
Kann ich aus dem Stand nicht beantworten, aber lass ich mir durch den
Kopf gehen!
Rolf M. schrieb:> Eric B. schrieb:>> Genau dieses rekursive Aufrufen ist iterieren!>> Nein. Entweder ich mache es iterativ oder rekursiv. Iterieren heißt,> dass man eine Schleife und eben keine Rekursion verwendet.
Ja gut. Wenn man es dann schon so genau nimmt, kann man gar nicht über
rekursive Strukturen wie Graphen oder Bäume iterieren.
Wenn dir aber wichitg ist, nicht rekursiv über die Knoten iterieren zu
können, dann trenn doch die Knoten von den Kanten. Alle Knoten landen in
einer Liste, über die du einfach iterieren kannst. In einer 2. Liste
legst du die Kanten als Referenzen anf den Knoten ab.
@db8fs
Ich würde den Einwurf von dir gerne noch mal aufgreifen:
>>wie teuer sollen denn die Iterationskosten im Graphen>>bitteschön werden, wenn du dreimal rundherum traversierst?>Dem kann ich nicht ganz folgen - welche Kosten meinst du? (schon klar,>dass es keine monetären sind).>Das Traversieren wird von der Bedienungsoberfläche gemacht durch den>Nutzer also nicht mit zig Kilohertz.>So wie ich das sehe, belastet Traversieren nicht den Stack, also>jedenfalls nicht im Sinne von ineinander geschachtelten>Methodenaufrufen.