Ich versuche gerade eine Ein-Register-CPU in VHDL zu erstellen. Ich
möchte gerne in einem Takt-Zyklus Daten aus dem Akkumulator im RAM
platzieren.
Bei steigender Flanke wird die Instruktion, auf die der Program Counter
zeigt, auf die Leitung gelegt.
Ebenfalls bei steigender Flanke liest der Decoder die aktuell anliegende
Instruktion ein, verarbeitet sie und setzt entsprechende Steuersignale.
Dabei wird dem Akkumulator mitgeteilt, dass er den Inhalt auf die
Leitung zum RAM legen muss. Ebenso wird das "Write-Enable" für den RAM
gesetzt.
Bei fallender Flanke liest der RAM die Steuersignale ein und speichert
ggf. den anliegenden Wert. Ebenso wird zuletzt der Program Counter
hochgezählt.
Allerdings passiert das ja im FPGA mehr oder weniger gleichzeitig,
obwohl es in dieser Reihenfolge passieren muss. Gibt es eine
Möglichkeit, den Takt für die verschiedenen Komponenten zu verzögern?
Macht das überhaupt Sinn?
Falls nein - wie würde man das sonst lösen?
Such doch mal nach "MIPS pipelining", da findest du eine Menge
Unterrichtsmaterial. Vom MIPS-Konzept kann man im allgemeinen nicht
allzuweit abweichen, was FPGA-CPUs angeht, die üblichen
Implementierungen sind deswegen mehr oder weniger alle MIPS-ähnlich.
Grad mal selber gegoogelt, da gibts recht witzige Interpretationen:
https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/pipelining/
Aber mindestens zwei Register werden's dann schon, zum Akku brauchst du
ja noch einen Adress-Zeiger.
Strubi schrieb:> Such doch mal nach "MIPS pipelining", da findest du eine Menge> Unterrichtsmaterial.
Also komplett ohne Pipeline kommt man in VHDL nicht aus (auch wenn es in
echter Hardware ohne Pipeline funktoniert)?
Strubi schrieb:> zum Akku brauchst du> ja noch einen Adress-Zeiger.
Meinst du damit den Program-Counter?
Max M. schrieb:> Also komplett ohne Pipeline kommt man in VHDL nicht aus (auch wenn es in> echter Hardware ohne Pipeline funktoniert)?
Mit VHDL beschreibst du "echte Hardware"...
Wenn du "in echter Hardware" mit steigenden und fallenden Flanken eines
Taktes arbeitest, dann verdoppelst du lediglich die Taktfrequenz.
Wenn du mit phasenverschobenen Takten arbeitest, dann vervielfachst du
die Taktfrequenz auf den Kehrwert der kürzesten Phasenverschiebung.
Echte synthetisierbare und portierbare CPUs arbeiten heute deshalb
intern einfach gleich mit ein und dem selben vervielfachen Takt.
Und natürlich wird in echter Hardware heutzutage Pipelining zur
Beschleunigung genommen. Denn dann arbeitet der Prozessor gleichzeitig
mit relativ niedriger Taktfrequenz (z.B. 100MHz) an z.B. 5 Befehlen und
ist damit so schnell wie deine CPU mit 500MHz.
Lothar M. schrieb:> Und natürlich wird in echter Hardware heutzutage Pipelining zur> Beschleunigung genommen.
Das ist aber nicht eigentlich das, was wir im FPGA mit pipeling
bezeichnen. Das ist eher ein Verschachteltes Arbeiten wie ein
DDR-Controller und aus Sicht der Datenzeit paralleles Arbeiten, weil in
einem äussere Takt mehr als eine Aktion geschieht. Es braucht dazu auch
parallele Hardware.
Pipelining passiert nicht auf paralleler Hardware sondern auf
sequenzieller.
> Also komplett ohne Pipeline kommt man in VHDL nicht aus (auch wenn es in> echter Hardware ohne Pipeline funktoniert)?
Doch, kommst du schon, wenn du oben erwähnte State-Machine
implementierst. Dann liegt aber unter Umständen recht viel Logik brach.
Dir ist auch sicher klar, dass Fetch, Decode, Execute und Write-Back
nicht in einem Taktzyklus funktionieren kann (was die genau bedeuten,
findest du typischerweise in der Literatur).
Du kannst natürlich schon Logik bauen, die gleich ein angelegtes Datum
mit einem Wert irgendwie verwurstet, und im nächsten Takt ausgibt, dann
handelst du dir aber massiv komplexe Logik und einen Flaschenhals ein,
der dir den Systemtakt nach unten zwingt. Sowohl im FPGA als auch in
realer HW.
>> Strubi schrieb:>> zum Akku brauchst du>> ja noch einen Adress-Zeiger.>> Meinst du damit den Program-Counter?
Nee, der ist ja nur beim Fetch relevant. Du willst ja irgendwo anders
Daten holen/speichern, dafür brauchste den Zeiger. Dafür kannst du
natürlich ein (virtuelles) "top of stack" register (der Inhalt der
Adresse, die im Stack-Pointer steht) verwenden. Dann hast du eine
Stack-Machine, was in der Implementation fast auf dasselbe rausläuft wie
eine Ein-Register-CPU.
Lothar M. schrieb:> Denn dann arbeitet der Prozessor gleichzeitig> mit relativ niedriger Taktfrequenz (z.B. 100MHz) an z.B. 5 Befehlen und> ist damit so schnell wie deine CPU mit 500MHz.
Das könnte sich missverstehen lassen, d.h. beisst sich mit echt
paralleler Ausführung, also als solcher definierter Opcodes (wie bei
manchen DSPs), oder der 'superscalaren' Variante, die unter Umständen
mehrere sequenzielle Opcodes gleichzeitig abarbeiten kann.
Die Pipeline definiert ja eigentlich im einfachsten Fall nur eine
Verkettung der atomaren Funktionen Fetch/Decode, Execute, usw. Sobald
was parallel verarbeitet wird, gabelt sich ne Pipe oder es gibt mehrere
vernetzte Instanzen davon, das wär etwas kompliziert fürn Anfang..
Das Ding mit der dreckigen Wäsche aus dem obigen Link beschreibt's
eigentlich recht nett. Oder die Heinzelmännchen, die den Eimer
weiterreichen..
Strubi schrieb:> Doch, kommst du schon, wenn du oben erwähnte State-Machine> implementierst.
Im Studium haben wir das Signal mit UND und ODER Gattern verzögert, ich
weiß nicht, in wiefern das mit VHDL möglich ist? Die CPU, die ich
versuche zu bauen, gibt es tatsächlich schon
(http://pdf.eepw.com.
cn/420090717/0c6b3d3419f57d26d6057c8fac26482f.pdf).
Da sehe ich keinen Hinweis auf Pipeline nur "Full CMOS static design".
Strubi schrieb:> Du willst ja irgendwo anders> Daten holen/speichern
Das sind in dem Fall tatsächlich 30 General Purpose Registers, die als
RAM verwendet werden. Die 512 Words an Flash bilde ich in einem Array
ab:
Max M. schrieb:> Im Studium haben wir das Signal mit UND und ODER Gattern verzögert
Ja, das ist die lange Schreibweise für "Murks".
> ich weiß nicht, in wiefern das mit VHDL möglich ist?
Es ist möglich. Aber du bekommst das nicht reproduzierbar in ein FPGA.
Und darum geht es letztendlich doch?
> Da sehe ich keinen Hinweis auf Pipeline nur "Full CMOS static design".
Ein vollstatisches Design darf aber keine solchen hingebastelten Timings
enthalten. Und der von dir verlinkte Prozessor hat, soweit ich das sehe,
sowas auch nicht drin.
Das ist ein vollkommen simples alltägliches synchrones Design.
Als Denkanstoß: letztendlich ist dieser Prozessor nur eine FSM, die vom
ROM gesteuert wird.
Lothar M. schrieb:> Und darum geht es letztendlich doch?
Jop
Lothar M. schrieb:> Ein vollstatisches Design darf aber keine solchen hingebastelten Timings> enthalten.
Bekommt jedes Register dann seinen separaten Time-Slot? Ist der
grundlegende Ansatz mit Instruktions-Register, Decoder + Flags setzen,
Akkumulator einstellen und RAM lesen / schreiben richtig?
Lothar M. schrieb:> letztendlich ist dieser Prozessor nur eine FSM, die vom> ROM gesteuert wird.
Ist FSM = Stack Machine? Meinst du so etwas z.B. für 5+10*3?
1
PUSH 10
2
PUSH 3
3
MUL
4
PUSH 5
5
ADD
Auf den ersten Blick erkenne ich da keine Analogien zu dem Befehlssatz
der CPU, die ich nachbauen möchte.
FSM = Finite State Machine
Hab mir jetzt deine Wunsch-CPU nicht angesehen, aber wenn Du mehr als
ein Register hast, ist es keine Stack-Maschine.
Ich gehe schwer davon aus, dass diese CPU irgend eine Art Pipelining
implementiert. Das ist heute eine Selbstverständlichkeit, die kaum im
Datenblatt erwähnt wird. Wie gesagt, du lässt sonst Logik u.U. zeitweise
brachliegen oder es wird irgendwas gemultiplext (wegen potentieller
Logik-Verstopfung eine ungeliebter Effekt). Siehe z.B. Zealot/ZPU. Dafür
ist es einfach zu implementieren, da kaum Konflikte (siehe "MIPS
Hazards") auftreten können.
Fang doch einfach mal an die 'Stages' (Befehls-Verarbeitungsstufen?)
gemäss deinem Ansatz als einfache FSM zu implementieren. Nächste Übung:
Implementiere eine Pipeline, identifiziere Konflikte, wie Klassiker:
Gerade (im vorherigen Zyklus) geschriebenen Wert zurücklesen.
Strubi schrieb:> Dafür> ist es einfach zu implementieren, da kaum Konflikte (siehe "MIPS> Hazards") auftreten können.
Das ist erstmal mein Ziel: Die CPU so einfach wie möglich implementiert
bekommen, ohne Pipelining-Mechanismen.
Ich hab gerade ein paar seltsame Effekte während der Simulation.
Ich hab dem Ablauf nun in Zustände aufgeteilt, der aktuelle Zustand wird
in einem separaten Register verwaltet.
Zustand *0*: Der Program Counter passt seinen Wert an
Zustand *1*: Der passende Befehl wird geladen
Zustand *2*: Befehl wird decodiert und Steuersignale werden gesetzt
Zustand *3*: Daten werden ggf. aus dem RAM geladen
Zustand *4*: Der Akkumulator (bzw. die ALU) führt Berechnungen durch
Zustand *5*: Daten werden ggf. ins RAM zurückgeschrieben (vom Akku aus)
Zustand *5*: Der Stack speichert ggf. die Rücksprungadresse, falls ein
JUMP vorliegt
Mein Program Counter:
1
libraryIEEE;
2
useIEEE.STD_LOGIC_1164.ALL;
3
USEIEEE.numeric_std.all;
4
5
entityProgram_Counteris
6
7
port(
8
9
c0:instd_logic;
10
pc:outunsigned(8downto0);
11
is_jump:instd_logic;
12
jump_addr:inunsigned(8downto0);
13
is_ret:instd_logic;
14
ret_addr:inunsigned(8downto0);
15
state:inunsigned(2downto0)
16
17
);
18
19
endProgram_Counter;
20
21
architectureBehavioralofProgram_Counteris
22
23
signalpc_int:unsigned(8downto0):="000000000";
24
25
begin
26
process(c0,state)
27
begin
28
29
if(falling_edge(c0)andstate="000")then
30
if(is_jump='1')then
31
pc_int<=jump_addr;
32
elsif(is_ret='1')then
33
pc_int<=ret_addr;
34
else
35
pc_int<=pc_int+1;
36
endif;
37
pc<=pc_int;
38
endif;
39
40
endprocess;
41
42
endBehavioral;
Die Leitung pc ist mit der Top-Level-Entity verbunden.
Der Akkumulator:
1
libraryIEEE;
2
useIEEE.STD_LOGIC_1164.ALL;
3
USEieee.numeric_std.ALL;
4
5
entityW_Regis
6
7
port(
8
9
c0:instd_logic;
10
read_w:instd_logic;
11
write_w:instd_logic;
12
place_immediate:instd_logic;
13
14
is_add:instd_logic;
15
16
reg_write_data:outunsigned(3downto0);
17
reg_read_data:inunsigned(3downto0);
18
19
immediate:inunsigned(3downto0);
20
w_reg_top:outunsigned(3downto0);
21
state:inunsigned(2downto0)
22
);
23
24
25
endW_Reg;
26
27
architectureBehavioralofW_Regis
28
29
signalw_content:unsigned(3downto0):="0000";
30
31
begin
32
process(c0,state)
33
begin
34
35
if(falling_edge(c0)andstate="100")then
36
if(read_w='1')then
37
reg_write_data<=w_content;
38
elsif(write_w='1')then
39
if(place_immediate='1')then
40
w_content<=immediate;
41
elsif(is_add='1')then
42
w_content<=w_content+reg_read_data;
43
else
44
w_content<=reg_read_data;
45
endif;
46
endif;
47
48
w_reg_top<=w_content;
49
50
endif;
51
52
endprocess;
53
54
endBehavioral;
Auch hier ist die Leitung w_reg_top mit der Top-Leve-Entity verbunden.
Der in der angehängten Simulation durchgeführte Befehl lädt den Wert
"0x1" in den Akkumulator.
Nun das seltsame Verhalten: Der Wert des Program Counters wird
flankengenau geupdated, der Inhalt vom W-Register allerdings nicht,
sonder erst zum nächsten Befehl (wenn dieser den entsprechenden Zustand
erreicht hat). Ich würde also erwarten, dass w_reg_top in der
Simulation den Wert 1 hat.
Warum ist das so?
Max M. schrieb:> Nun das seltsame Verhalten: Der Wert des Program Counters wird> flankengenau geupdated, der Inhalt vom W-Register allerdings nicht,> sonder erst zum nächsten Befehl (wenn dieser den entsprechenden Zustand> erreicht hat)
ohne deinen Code vollständig durchgegangen zu sein: in einem Taktzyklus
weißt du w_content einen neuen Inhalt zu. Diese Zuweisung wird aber erst
zum Ende des Prozesses wirksam.
Deine zusätzliche Zuweisung
w_reg_top <= w_content
bringt w_reg_top auf den Wert, den w_content zu Beginn des Prozesses
hatte (nicht auf den Wert, der während des Prozesses zugewiesen wurde).
Der neue Wert von w_content macht sich erst im folgenden Taktzyklus
bemerkbar.
Max M. schrieb:> Der Akkumulator:
...ist normalerweise nicht getaktet, sondern pure und reinste
Kombinatorik. Durch deine Takterei hast du zusätzlich eine Stufe
Flipflops eingefügt und das gefunden, was man Latency nennt: deine
Ergebnisse werden um 1 Takt "verschoben".
Lothar M. schrieb:> deine> Ergebnisse werden um 1 Takt "verschoben".
Achso, beim Program-Counter ist das deswegen nicht, da ich eins
hochzähle und mit 0 beginne.
Achim S. schrieb:> bringt w_reg_top auf den Wert, den w_content zu Beginn des Prozesses> hatte (nicht auf den Wert, der während des Prozesses zugewiesen wurde).> Der neue Wert von w_content macht sich erst im folgenden Taktzyklus> bemerkbar.
Danke dir, das erklärt auch, warum mein Jump nicht funktioniert :(
Wie löst man das?
Lothar M. schrieb:> ist normalerweise nicht getaktet, sondern pure und reinste> Kombinatorik.
Wie funktioniert das denn, wenn ich noch Daten aus dem RAM holen muss?
Im Diagramm der CPU, die ich nachbauen möchte, sind Akkumulator und ALU
quasi eine Einheit (sind in einem Block zusammen gefasst)
Max M. schrieb:> Danke dir, das erklärt auch, warum mein Jump nicht funktioniert :(> Wie löst man das?
Soll der Wert von w_content immer in w_reg_top geschrieben werden? Dann
mach diese Zuweisung w_reg_top <= w_content einfach außerhalb des
(getakteten) Prozesses. Damit gibt es dann keinen unerwünschten
Taktzyklus Latenz.
Max M. schrieb:> Akkumulator und ALU quasi eine Einheit
Der Akku ist lediglich ein getaktetes Register mit einigen Bits Breite.
Er ist der Lieferant eines Operators und "zugleich" der Speicher des
Ergebnisses. "Zugleich" in Anführungszeichen, weil dazwischen eine
Taktflanke kommt.
Du solltest dir mal aufzeichnen, welche Teile in diesem Prozessor
speichern müssen und welche Teile nur rechnen oder kombinatorische
Funktionen abhandeln. Dann siehst du, dass die ALU keinen Takt braucht,
der Akku aber schon. Und der Programmcounter natürlich auch.
Wie gesagt: VHDL ist eine Beschreibungssprache und wenn du etwas
beschreiben willst, dann musst du dir vorher ein Bild davon machen
(können).
Achim S. schrieb:> Damit gibt es dann keinen unerwünschten> Taktzyklus Latenz.
Wie löse ich das mit dem Jump? Der tritt auch um einen Takt verzögert
auf:
1
libraryIEEE;
2
useIEEE.STD_LOGIC_1164.ALL;
3
USEIEEE.numeric_std.all;
4
5
entityProgram_Counteris
6
7
port(
8
9
c0:instd_logic;
10
pc:outunsigned(8downto0);
11
is_jump:instd_logic;
12
jump_addr:inunsigned(8downto0);
13
is_ret:instd_logic;
14
ret_addr:inunsigned(8downto0);
15
state:inunsigned(2downto0)
16
17
);
18
19
endProgram_Counter;
20
21
architectureBehavioralofProgram_Counteris
22
23
signalpc_int:unsigned(8downto0):="000000000";
24
25
begin
26
process(c0,state)
27
begin
28
29
if(falling_edge(c0)andstate="000")then
30
if(is_jump='1')then
31
pc_int<=jump_addr;
32
elsif(is_ret='1')then
33
pc_int<=ret_addr;
34
else
35
pc_int<=pc_int+1;
36
endif;
37
pc<=pc_int;
38
endif;
39
40
endprocess;
41
42
endBehavioral;
Achim S. schrieb:> Damit gibt es dann keinen unerwünschten> Taktzyklus Latenz.
Danke, das hat geholfen!
Lothar M. schrieb:> Dann siehst du, dass die ALU keinen Takt braucht,> der Akku aber schon.
Wie würde ich denn hier den add-Befehl aus dem Prozess raus bekommen? Es
scheint, als könnte man ein if nur innerhalb eines Prozesses
verwenden:
Max M. schrieb:> Wie löse ich das mit dem Jump? Der tritt auch um einen Takt verzögert> auf:
Na komm, die Transferleistung ist jetzt nicht so gewaltig: du musst halt
auch das
pc <= pc_int;
aus dem getakteten Prozess herausziehen um einen Takt weniger Latenz zu
bekommen.
Max M. schrieb:> Es> scheint, als könnte man ein if nur innerhalb eines Prozesses> verwenden:
vielleicht hilft dir "when"
http://www.ics.uci.edu/~jmoorkan/vhdlref/cond_s_a.html
Achim S. schrieb:> Na komm, die Transferleistung ist jetzt nicht so gewaltig: du musst halt> auch das> pc <= pc_int;> aus dem getakteten Prozess herausziehen um einen Takt weniger Latenz zu> bekommen.
Da hätte ich tatsächlich auch selbe drauf kommen können, danke dir.
In der Simulation hängt es allerdings nun davon ab, ob die erste Flanke
fallend oder steigend ist. Handelt es sich um eine fallende Flanke wird
der PC direkt auf 1 gesetzt und somit ein Befehl übersprungen.
Wenn die CPU mal im FPGA läuft, kann ich mir ja nicht aussuchen, ob die
erste Flanke fallend oder steigend sein wird (oder?). Wie läuft das dann
ab?
Bei meinem Stack für die Rücksprungadressen lässt sich das Problem mit
der Verzögerung nicht so einfach lösen (glaub ich), da hier noch ein
Index-Wert drann hängt:
Max M. schrieb:> if(idx = "1") then> if(idx = "0") then
Du kannst diese beiden if-Abfragen einfach weglassen, denn in realer
Hardware kann idx nur '0' oder '1' sein. Denk mal kurz drüber nach, was
wäre, wenn im ersten Fall idx schon '0' wäre, oder im zweiten Fall schon
'1'. Richtig: dann würe idx im ersten Fall wieder '0' und im zweiten
Fall wieder '1'.
Langer Rede kurzer Sinn: der Synthesizer wird diese if-Abfragen eh'
umstandslos wegoptimieren... ;-)
Max M. schrieb:> signal idx : unsigned(0 downto 0);
Warum sooooo umständlich? Sieh mal nach, wie unsigned-Vektoren definiert
sind: ein unsigend-Vektor mit der Breite 1 Bit ist ein simpler
std_logic...
Siehe dort in der Zeile direkt nach dem Copyright:
https://standards.ieee.org/downloads/1076/1076.2-1996/numeric_std.vhdl
Wenn du damit aber die Wege für einen späteren idx bereithalten willst,
warum machst du den idx dann nicht gleich zum Integer? dann sparst du
dir das Herumkonvertieren beim Arrayzugriff.
Am leichtesten lässt sich VHDL Code schreiben und lesen, wenn man sich
vorneweg Gedanken zu den verendeten Datentypen macht...
Und dann die Sesitivliste: da ist viel zu viel drin. Das kommt auch von
der ungewöhnlichen Schreibweise für das Enable. Du verwendest den zwar
funktionierenden aber unüblichen zweiten Fall von dort:
http://www.lothar-miller.de/s9y/archives/1-Clock-Enable-in-einer-ISE-VHDL-Beschreibung.html
Mein Tipp: mach es wie der Rest der Welt. In die Sensitivliste eines
getakteten Prozesses kommt nur der Takt (und nötigenfalls bestens noch
der asynchrone Reset).
Mein Vorschlag zu deinem Code wäre dann sowas in diese Richtung:
Danke für deine hilfreichen Tipps, das ist mein erstes Projekt bzw.
meine ersten Gehversuche mit VHDL, von dem her ist jeder Hinweis gerne
gesehen.
Lothar M. schrieb:> Warum sooooo umständlich?
Ja, das frag ich mich nun auch
Lothar M. schrieb:> Mein Tipp: mach es wie der Rest der Welt. In die Sensitivliste eines> getakteten Prozesses kommt nur der Takt (und nötigenfalls bestens noch> der asynchrone Reset).
Okay, ich dachte, da muss alles rein, auf das im folgenden Prozess
lesend zugegriffen wird?
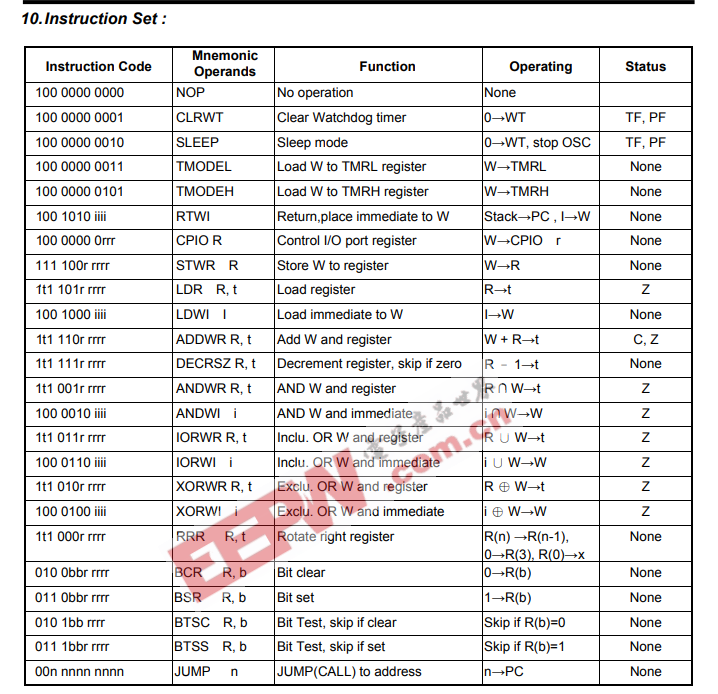
Ich hätte noch kurz zwei Fragen zum Instruction Set der CPU:
1. Der Befehl "LDR R, t" hat zwei Parameter. R steht einmal für das
General Register (also quasi das RAM) und t gibt an, ob der Inhalt von
R in das Working Register oder in ein General Register geschrieben
werden soll.
Nun frage ich mich: Wie soll hier ein t=1 (= General Register)
funktionieren? Ich hab nur 5 Bits, und die geben bereits an, aus welchem
Register Daten geladen werden. Die einzige Möglichkeit, die mir
einfällt, ist das in das selbe Register wieder zurückgeschrieben wird
(was etwas sinnlos wäre)?
2. RTWI popt die oberste Adresse vom 2-level Stack, allerdings sehe
ich keinen Befehl, der einen push durchführt?
Der einzige unbedingte Sprung ist JUMP, da steht aber nix von Stack in
der Beschreibung.
Der kleinste PIC10F200 hat zwei Befehle für unbedingte Sprünge, einmal
goto und call. Die Verwendung von goto:
1
main: nop
2
goto main
während call eine Unterfunktion aufruft (also ein push quasi):
1
main: nop
2
call func
3
goto main
4
5
func: nop
6
retlw 0
Ein Befehl scheint da bei der MDT90P01 zu fehlen oder mir ist die
Funktionsweise nicht ganz klar.
Max M. schrieb:> Lothar M. schrieb:>> Mein Tipp: mach es wie der Rest der Welt. In die Sensitivliste eines>> getakteten Prozesses kommt nur der Takt (und nötigenfalls bestens noch>> der asynchrone Reset).>> Okay, ich dachte, da muss alles rein, auf das im folgenden Prozess> lesend zugegriffen wird?
Es muss alles rein, was eine Neuberechnung des Prozesses nötig macht,
weil sich durch die Änderung dieses Signals in der Simulation die
Resultate des Prozesses ändern würden. Und bei einem getakteten Prozess
können sich Resultate nur mit einer Taktänderung ergeben.
Dem Synthesizer ist die Sensitivliste vollkommen schnuppe! Er erweitert
fehlende Signale oder er ignoriert sie wie er es braucht. Und meldet
dann bestenfalls, dass die Simulation nicht mehr zur Realität passt.
Max M. schrieb:> Der einzige unbedingte Sprung ist JUMP, da steht aber nix von Stack in> der Beschreibung.
Etwas seltsame Lösung: Ein Flag im Status Register gibt an, ob es sich
um einen JUMP oder einen CALL handelt. Da war anscheinend die Wortbreite
zu kurz für einen weiteren Befehl.
Lothar M. schrieb:> Es muss alles rein, was eine Neuberechnung des Prozesses nötig macht,> weil sich durch die Änderung dieses Signals in der Simulation die> Resultate des Prozesses ändern würden. Und bei einem getakteten Prozess> können sich Resultate nur mit einer Taktänderung ergeben.
Alles klar, vielen Dank!
Hm, ich scheitere daran, dieses Design vernünftig in meinen Nachbau zu
implementieren.
Aktuell führt eine Leitung SCALL vom RAM zum Stack (der dann bestimmt,
ob die Adresse des JUMP-Befehls abgelegt wird oder nicht).
Wie schaffe ich es nun, dieses Bit im RAM beim nächsten JUMP-Befehl auf
0 zu setzen (so wie es die Beschreibung vorsieht)?
Prinzipiell erkennt der Program-Counter ob es sich beim aktuellen Befehl
um einen Jump handelt, aber der hat keine Verbindung zum RAM.