Hallo Zusammen,
ich stehe hier vor einem kleinem RegEx Problem.
Aufgabenstellung:
Wir führen eine Migration von Lotus-Notes nach SharePoint durch. Da in
Lotus-Notes alles mögliche in ein Textfeld gepastet werden kann, stehen
wir vor dem Problem, die Urls die sich in den Textbody befinden zu
analysieren und entsprechend unserer Logik anzupassen.
Beim Export werden alle Dokumente die in so einem Textbody erwähnt
werden als Attachment an den Datensatz angehangen. Diese Attachments
werden von mir durch iteriert und ich versuche die Entsprechungen im
Textbody zu finden und anzupassen.
Folgendes Problem tritt auf:
In einigen Namen tauchen spezielle Sonderzeichen auf, die ich in meinem
RegEx mit "\S" berücksichtigen muss.
Jetzt tritt das Problem auf, dass der RegEx die Matches nicht immer
eindeutig identifizieren kann und Treffer die einzeln stehen sollen zu
einem Treffer zusammengezogen werden.
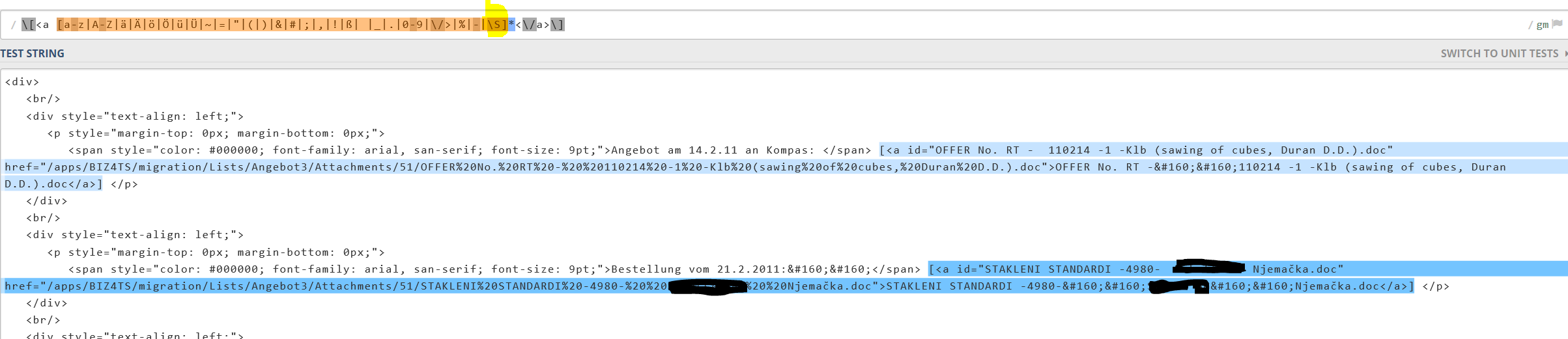
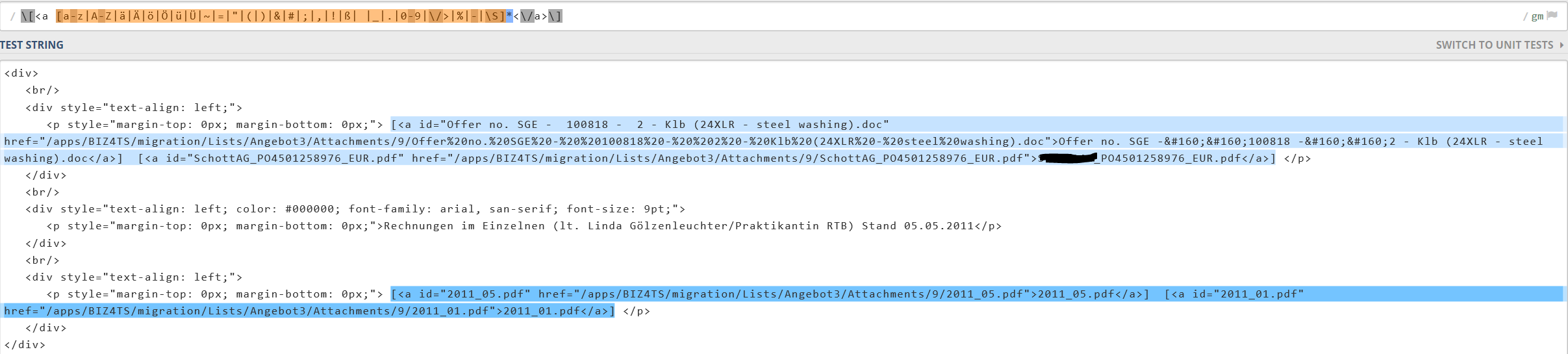
Ich habe versucht das Ganze an zwei Bilder zu verdeutlichen.
Bild1 zeigt das gewünschte Verhalten, es werden zwei Matches gefunden.
Bild2 zeigt das fehlerhafte Verhalten, es erden zwei Matches an Stelle
von drei Matches gefunden.
Hier das von mir verwendete RegEx.
1 | \[<a [a-z|A-Z|ä|Ä|ö|Ö|ü|Ü|~|=|"|(|)|&|#|;|,|!|ß| |_|.|0-9|\/>|%|-|\S]*<\/a>\]
|
Die zu ermittelnden Ausdrücke müßt Ihr aus den Bilder entnehmen, da ich
diese hier nicht posten kann wegen Spam Meldung.
Wahrscheinlich kann man den Ausdruck noch kürzer formulieren, im Monent
geht es mir nur darum den Fehler aus Bild2 zu eleminieren.
Gruß und Danke
Frank