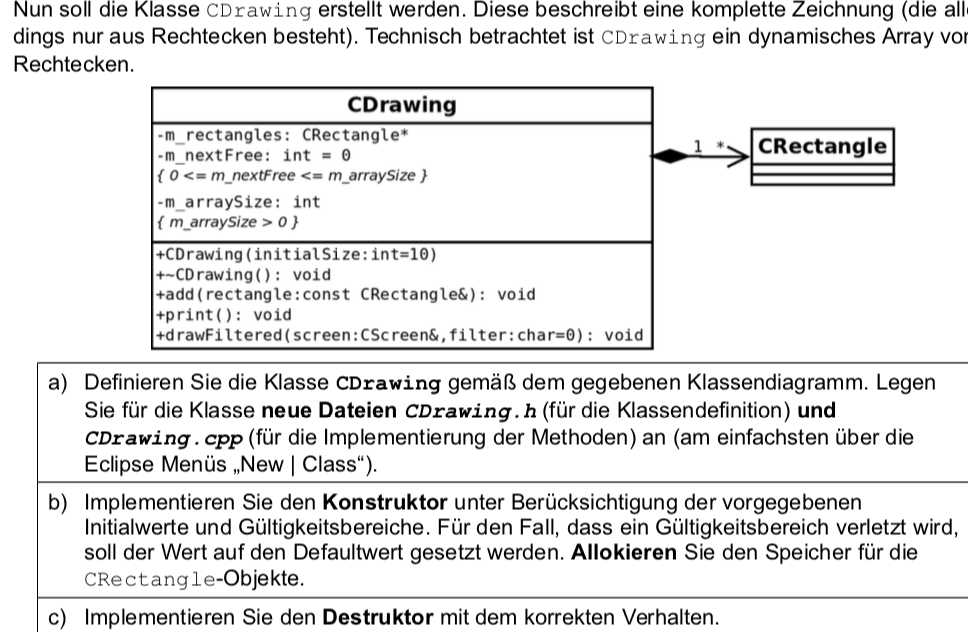
Bert3 schrieb:> else im ctor wäre unpassend wenn du immer allokieren möchtest - was> passiert z.B. bei CDrawing(-1)
Ich habe das Gefühl er meinte sowas:
1
CDrawing::CDrawing(intinitialSize){
2
3
if(initialSize>10||initialSize<0){
4
initialSize=10;
5
}
6
7
m_arraySize=initialSize;
8
m_rectangles=newCRectangle[m_arraySize];
9
}
wobei CDrawing(0) immer noch Ärger machen würde. Meine Empfehlung:
den Teil
1
m_arraySize=initialSize;
2
m_rectangles=newCRectangle[m_arraySize];
noch in eine private Funktion packen und dort noch entsprechend eine
Fallunterscheidung für kleiner gleich 0 machen.
#include<iostream>
using namespace std;
#include"CDrawing.h"
CDrawing::CDrawing(int initialSize ){
if(initialSize >10 || initialSize < 0){
initialSize = 10;
}
m_rectangles = new CRectangle [m_arraySize];
}
CDrawing::~CDrawing(){
delete [] m_rectangles;
}
Ich habe die else bedingung erst mal weg gemacht ,da der Speicher wohl
einfach ausserhalb der Bedingung gesetzt wird.
Aber was wollen die hier bei der Zusicherung ?
Im Klassen Diagramm ist ja bei der Zusicherung
arraySize > o gegeben usw
"int" als Array-Größe zu nehmen ist eh eine schlechte Idee. Man
verschenkt immer die Hälfte der möglichen Größe (Array-Größen können nie
negativ werden, aber je nach Architektur durchaus die volle Größe eines
vorzeichenlosen Typs annehmen).
Was passiert auf AMD64-Systemen? Hier ist "int" meistens ein
32-bit-Integer, geht also bis 2^31-1, während Arrays aber tatsächlich
bis 2^64 Elemente haben können.
Die korrekte Lösung (welche auch alle Standard-Container wie std::vector
nutzen) ist es, std::size_t aus dem Header <cstdint> zu verwenden. Da
"int" vorgegeben ist, kannst du ja dazuschreiben warum das so besser
ist. Unter Java nutzt man zwar "int" für alles und jedes, aber C++ ist
nicht Java.
Ja aber wir machen nur die Grundlagen von C++.
Von uns will er immer nur Zusicherungen im Konstruktor und das wars .
Was würdest du sagen wäre hier die korrekte Zusicherung?
Lara C. schrieb:> Ja aber wir machen nur die Grundlagen von C++.
Auch die kann man korrekt machen. "int" ist halt einfach falsch.
Lara C. schrieb:> Von uns will er immer nur Zusicherungen im Konstruktor und das wars .
Und dann darf man alles andere irgendwie machen? Willst du unbedingt
etwas falsches lernen und angewöhnen, um es dann später wieder
umzulernen?
Lara C. schrieb:> Was würdest du sagen wäre hier die korrekte Zusicherung?
Einfach nur dass die Array-Größe > 0 ist. m.M.n wäre zwar Größe 0 auch
sinnvoll, aber das scheint nicht so gewollt zu sein. Kleiner 0 kann
std::size_t ohnehin nicht werden - wenn man also versehentlich versucht
etwas negatives zu übergeben, gibt es einen Compiler-Fehler und man
sieht sofort was falsch ist - es handelt sich somit also um ein
sichereres API.
Lara C. schrieb:> Ja aber wir machen nur die Grundlagen von C++.>> Von uns will er immer nur Zusicherungen im Konstruktor und das wars .> Was würdest du sagen wäre hier die korrekte Zusicherung?
Welchen Wert kann denn bei deiner Implementierung m_arraysize annehmen?
Wurde das so irgendwo gefordert?
Oder ist das eher die Randbedingung für nextFree?!
InitialSize ist ein Default-Wert für den Fall, daß man nichts anderes
angegeben hat. Wenn man aber z.B. eine Zeichnung aus 1000 Objekten
anlegen will, dann kann man sich 100 mal 10 Eintäge mehr Speicher holen
und umkopieren ersparen, in dem man einfach gleich genug Platz
anfordert.
Natürlich nur, wenn der Konstruktor nicht auf 0..10 Objekte beschränkt
ist.
Die add-Methode muß sich dann um die Frage kümmern, ob noch Platz ist
und ggf. m_arraysize (und das Array, auf das m_rectangles zeigt)
vergrößern.
Bei der Aufgabe geht es also um die (Minimal-)Implementierung eines
dynamischen Containers für CRectangle Objekte.
Wohl eher "< 1". Es ist aber ziemlich dämlich, im Falle eines
Programmierfehlers einfach irgendeinen Default anzunehmen. Wenn man
schon eine negative Array-Größe übergibt, kann man keine Annahmen über
zukünftige Zugriffs-Indices machen, und dann passiert irgendwas. Wenn
schon sollte man eine Exception werfen oder ein "assert()" nutzen, oder
natürlich negative Größen einfach vermeiden indem man std::size_t nutzt,
was man sowieso auf jeden Fall tun sollte.
Lara C. schrieb:> Ich glaube ,dass der Prof wahrscheinlich das möchte bei dieser Klausur:
.
> ...> if(m_arraySize < 0){>> initialSize = 10;> m_arraySize = initialSize;>>> }> else{>> m_rectangles = new CRectangle [m_arraySize];> }> ...>>> Ohne Gewähr
aber sicher will er nicht, daß der Pointer m_rectangles Initial bleibt,
oder?
initialSize = 10;
> m_arraySize = initialSize;
Hier schmeisse ich doch da sZeug von initial in Array ?
Und dann später speicher anlegen ?
Oder in else auch m_arraySize = initialSize; und dann Speicher anlegen ?
Dr. Sommer schrieb:> Lara C. schrieb:>> Ja aber wir machen nur die Grundlagen von C++.>> Auch die kann man korrekt machen. "int" ist halt einfach falsch.
int ist nicht falsch, es ist nur nicht die beste Wahl.
> Kleiner 0 kann std::size_t ohnehin nicht werden - wenn man also> versehentlich versucht etwas negatives zu übergeben, gibt es einen> Compiler-Fehler und man sieht sofort was falsch ist - es handelt sich> somit also um ein sichereres API.
Nein. Wenn ich size_t als Parameter habe, bringt der Compiler keinen
Fehler beim Übergeben einer negativen Zahl. Vielmehr wird eine sehr
große positive Zahl daraus.
Mich würden ja mal wieder zwei andere Sachen interessieren, denn diese
Art des Aufgabenblattes hatten wir schon mehrfach:
1) Welche HS/FH/BA/Uni und Studiengang ist das?
2) Warum werden nicht die Kommilitonen/Assis/Profs gefragt?
Im Sinne einer Prüfungsoptimierung sollte/muss man wohl so antworten,
wie der Dozent das gerne hätte (und das kann hier keiner wissen). Das
ist aber leider oft nicht state-of-the-art.
Rolf M. schrieb:> Nein. Wenn ich size_t als Parameter habe, bringt der Compiler keinen> Fehler beim Übergeben einer negativen Zahl.
Achja, der Fehler kommt nur wenn man per {} initialisiert; macht hier
natürlich keiner. Dennoch finde ich es suboptimal einen Datentyp zu
verwenden, der ungültige Werte zulässt, obwohl es eine bessere Wahl
gibt.
Rolf M. schrieb:> int ist nicht falsch,
Es schränkt die Funktionalität unnötig ein; das fällt für mich unter
"falsch". Genau solche Probleme behindern z.B. die Portierung von x86
auf x86_64...
Wilhelm M. schrieb:> 1) Welche HS/FH/BA/Uni und Studiengang ist das?
Diese Aufgabenblätter sehen überall gleich aus... Und sind überall
gleich falsch :-)
Wilhelm M. schrieb:> 2) Warum werden nicht die Kommilitonen/Assis/Profs gefragt?
Die wissen es doch auch nicht.
Vorausgesetzt der TO möchte C++ für die Praxis lernen und nicht nur
diese Prüfungsaufgabe lösen.
Dies wären meine Tipps als C++ Entwickler:
1) Im Konstruktor sollten alle Member initialisert werden. Entweder über
die Initialisierungsliste oder (wie zum Teil schon passiert) in der
Deklaration. m_rectangles sollte ein nullptr sein, sonst ist es bei
einem Fehler im Konstruktor undefiniert und das kann zu vielen Fehlern
führen (auch in anderen Modulen), die man dann nicht einfach wieder
reproduzieren kann (z.B. Access Violation (gut zu finden), Heap
Corruption (sehr sehr hässlich).
2) Wenn print oder drawFiltered das Objekt nicht verändern, dann würde
ich diese Methoden als const markieren. Sonst kann man diese später über
eine const CDrawing& nicht verwenden.
3) Den Kostruktor mit einem Parameter als explicit markieren, damit der
Kompiler diesen nicht als konvertierenden Konstruktor verwenden kann.
Sonst dürfte der Compiler damit einen int in ein CDrawing umwandeln.
4) m_rectangles, m_nextFree, m_arraySize machen ja nichts anderes, als
der std::vector schon macht. Sogar eine initialSize
(std::vector::reserve) hat dieser schon. Damit fällt die ganze händische
Programmierung weg, vorallem wenn man das Array vergrößern muss.
Außerdem sollte der std::vector auch schon so programmiert sein, dass
der Speicher auch bei einer Exception wieder freigegeben wird. Hantiert
man selbst mit new/delete, dann kann eine unerwartete Exception schnell
zu einem Leak führen.
Dr. Sommer schrieb:> Rolf M. schrieb:>> int ist nicht falsch,> Es schränkt die Funktionalität unnötig ein; das fällt für mich unter> "falsch". Genau solche Probleme behindern z.B. die Portierung von x86> auf x86_64...
Aus performance Sicht können bspw. intel prozessoren (von denen weiß ich
von einer intel Veranstaltung) ints in for loops besser optimiert
werden.
Wenn man sich sicher ist (oder checkt), dass size() nicht größer ist als
numeric_limits<int>::max() (oder INT_MAX oder whatever) ist es
sicherlich nicht falsch und ggf. eine bessere Wahl als size_t.
Lks schrieb:> Wenn man sich sicher ist (oder checkt), dass size() nicht größer ist als> numeric_limits<int>::max() (oder INT_MAX oder whatever) ist es> sicherlich nicht falsch und ggf. eine bessere Wahl als size_t.
Das Argument ist aber ein ganz anderes als "ich nehm immer int weil...
ich das schon immer so gemacht hab... und weil das in Java auch so
geht... und weil der Prof das auch so macht" :)
Da muss man dann aber auch erst prüfen ob es ein Intel-Prozessor ist.
Und auch hier würd ich dann eher unsigned int, oder noch besser
uint32_t, nehmen. Solche CPU-abhängigen Mikro-Optimierungen dürften aber
i.A. ziemlich selten nötig/sinnvoll sein. Da gibt's in den meisten
Programmen noch ganz andere Dinge...
Lks schrieb:> Aus performance Sicht können bspw. intel prozessoren (von denen weiß ich> von einer intel Veranstaltung) ints in for loops besser optimiert> werden.
Kannst du das genauer erklären? Bei unsigned int verglichen mit int (32
Bit Werte auf 64 Bit Systemen) kann ich das verstehen (ausnutzen von
signed-int-overflow-undefined-behavior), aber bei size_t mit 64 Bit?
@Dr. Sommer
Signed Typen in for loops werden bei intel (und wahrscheinlich auch bei
anderen Prozessoren) schneller verarbeitet (for loops) als unsigned
typen. Da geht es (je nach Problematik) nicht um mikrooptimierung
sondern um zwei- bis dreistellige Prozentzuwächse.
Ich wollte eigentlich nur sagen, dass ints in for loops (auch über stl
container) nicht generell "falsch" sind ;)
Lks schrieb:> Da geht es (je nach Problematik) nicht um mikrooptimierung> sondern um zwei- bis dreistellige Prozentzuwächse.
Um wie viele Tausend Takte wird das denn langsamer? Die meisten
Programme bestehen ja eher nicht zu 90% aus Schleifenzähler
inkrementieren.
Und worin besteht überhaupt der Unterschied zwischen signed und unsigned
Addition? Das sind ja nichtmal verschiedene Instruktionen.
Dr. Sommer schrieb:> Lks schrieb:>> Da geht es (je nach Problematik) nicht um mikrooptimierung>> sondern um zwei- bis dreistellige Prozentzuwächse.>> Um wie viele Tausend Takte wird das denn langsamer? Die meisten> Programme bestehen ja eher nicht zu 90% aus Schleifenzähler> inkrementieren.> Und worin besteht überhaupt der Unterschied zwischen signed und unsigned> Addition? Das sind ja nichtmal verschiedene Instruktionen.
Da geht es eher nicht nur um das eigentliche Inkementieren (das auch,
hier werden Überläufe anders gehandelt -> es muss ein Überlauf flag
gesetzt werden) sondern auch um das Optimieren auf compiler Ebene
(Vektorisieren, das Beispiel mit dem Performance Sprung war auf einer
AVX-512 CPU - fairer Weise Intel Compiler auf Intel CPU :P). Kontex war
Signalverarbeitung + Neuronale Netze auf Intel CPUs.
Aber ich glaube wir schweifen etwas ab.
Lks schrieb:> Da geht es eher nicht nur um das eigentliche Inkementieren (das auch,> hier werden Überläufe anders gehandelt -> es muss ein Überlauf flag> gesetzt werden) sondern auch um das Optimieren auf compiler Ebene> (Vektorisieren, das Beispiel mit dem Performance Sprung war auf einer> AVX-512 CPU - fairer Weise Intel Compiler auf Intel CPU :P). Kontex war> Signalverarbeitung + Neuronale Netze auf Intel CPUs.
Hast du ein konkretes Beispiel?
Dr. Sommer schrieb:> Und auch hier würd ich dann eher unsigned int, oder noch besser> uint32_t, nehmen.
Das ist jetzt aber schon sehr akademisch:
32Bit vorausgesetzt und in der Annahme das ein CRectangle 4 Int-Werte
enthält würde das Array bei der Anzahl INT_MAX an Elementen schon eine
stattliche Größe von 32+ GB aufweisen.
In der Praxis sollte nichts anderes verwendet werden als ein
STL-Container, IMHO ;)
mh schrieb:> Lks schrieb:>> Aus performance Sicht können bspw. intel prozessoren (von denen weiß ich>> von einer intel Veranstaltung) ints in for loops besser optimiert>> werden.>> Kannst du das genauer erklären? Bei unsigned int verglichen mit int (32> Bit Werte auf 64 Bit Systemen) kann ich das verstehen (ausnutzen von> signed-int-overflow-undefined-behavior), aber bei size_t mit 64 Bit?
:)
Gut beobachtet. Ich musste grad schmunzeln weil ich EXAKT dieses Problem
vor kurzem in einem Talk von Chandler Carruth gesehn hab. Hier der Link
zu besagter Stelle:
https://youtu.be/yG1OZ69H_-o?t=2358
Na, da sagt er ja sogar dass size_t (64bit) auch effizient wäre. Braucht
halt nur mehr Speicher. Solange man aber nicht sicher ist dass 32bit
reichen braucht man das eh...
M.K. B. schrieb:> Dies wären meine Tipps als C++ Entwickler:
...
5) Rule of three/five/zero berücksichtigen
6) Niemals `using namespace ...` in headern oder vor dem #include
anderer header.
7) überlegen, ob sich default Funktionsparameter mit Überladungen
vermeiden lassen.
8) forward declaraction verweden, wenn nur ein incomplete type in der
declaration eines Typens ausreicht.
9) Nach dem Studium alles gelernte sofort vergessen und mit ein paar
guten Bücher von Vorne anfangen ;-)
mfg Torsten
mh schrieb:> Lks schrieb:>> Da geht es eher nicht nur um das eigentliche Inkementieren (das auch,>> hier werden Überläufe anders gehandelt -> es muss ein Überlauf flag>> gesetzt werden) sondern auch um das Optimieren auf compiler Ebene>> (Vektorisieren, das Beispiel mit dem Performance Sprung war auf einer>> AVX-512 CPU - fairer Weise Intel Compiler auf Intel CPU :P). Kontex war>> Signalverarbeitung + Neuronale Netze auf Intel CPUs.>> Hast du ein konkretes Beispiel?
Im Beispiel ging es um ein k-means clustering. In einer "size_t for
loop" spuckt das Intel Performance Tool (Intel Advisor war das glaube
ich) "Scalar loop. Not vectorized: unsigned types for induction variable
and/or for lower/upper iteration bounds make loop uncountable Loop with
unsigned induction variable" aus. Überschrift der Folie lautet
"Compilers don't like unsigned integers".
Auf den nächsten Folien wird die Struktur der Loop geändert und die
loops auf std::ptrdiff_t umgestellt. Das bringt am Ende ein speedup von
ca. Faktor 3 (AVX-2). Dann wird nicht mehr über ein array of structures
(RGB pixel als structure und dann einen Array davon) sondern über eine
Structure of arrays iteriert -> caching optimiert + effizienter
vektorisiert -> bringt erneut einen speedup von Faktor 2, insgesamt
Faktor ~6. Danach wird noch etwas weiter optimiert (ptrdiff_t durch int
ersetzt, wenn ich das richtig sehe), sodass der compiler AVX 512
verwenden kann (erneut Faktor ~2 an speedup).
Das Ganze fand in der Präsentation vorerst auf einen Kern statt. Und
skalierte dann noch mit Anzahl der Kerne bei Parallelisierung mittels
openmp.
Als Hinweise kam dann noch:
...
- Use small types to help vectorization
- Use contiguous memory access
...
Die Folien kommen von Georg Zitzlsberger
(https://software.intel.com/en-us/user/420234) und sind tw. mit
Quelltext versehen.
Lks schrieb:> Im Beispiel ging es um ein k-means clustering. In einer "size_t for> loop" spuckt das Intel Performance Tool (Intel Advisor war das glaube> ich) "Scalar loop. Not vectorized: unsigned types for induction variable> and/or for lower/upper iteration bounds make loop uncountable Loop with> unsigned induction variable" aus. Überschrift der Folie lautet> "Compilers don't like unsigned integers".
Die "hilfreiche" Warnung... hat in vielen Fällen nicht direkt etwas mit
size_t zu tun und ist ohne wirklich konkretes Beispiel nutzlos.
Der restliche Teil deines Beitrags lässt sich mit:
Lks schrieb:> - Use small types to help vectorization> - Use contiguous memory access
zusammenfassen.
Diese Hinweise sind schön und gut, aber für einen Großteil aller
Softwareprojekte irrelevant.
Es wird zuerst korrekte Software geschrieben und dann optimiert wo es
nötig ist. Nur in Software die zu langsam ist und in den <5% des
Programms, die relevant für die Performance sind, muss man zwischen
korrekt und schnell abwägen.
Zum Schreiben korrekter Software gehört allerdings das Wählen der
richtigen Datentypen. Ob unsinged der richtige Datentyp ist, ist dann
wieder eine andere Frage, mit vielen pro und contra Argumenten, die
jeder für sich selbst abwägen muss.
mh schrieb:> Diese Hinweise sind schön und gut, aber für einen Großteil aller> Softwareprojekte irrelevant.> Es wird zuerst korrekte Software geschrieben und dann optimiert wo es> nötig ist. Nur in Software die zu langsam ist und in den <5% des> Programms, die relevant für die Performance sind, muss man zwischen> korrekt und schnell abwägen.> Zum Schreiben korrekter Software gehört allerdings das Wählen der> richtigen Datentypen. Ob unsinged der richtige Datentyp ist, ist dann> wieder eine andere Frage, mit vielen pro und contra Argumenten, die> jeder für sich selbst abwägen muss.
Ich bin generell bei dir. Wie ich weiter oben schon schrieb:
Lks schrieb:> Ich wollte eigentlich nur sagen, dass ints in for loops (auch über stl> container) nicht generell "falsch" sind ;)mh schrieb:> Nur in Software die zu langsam ist und in den <5% des> Programms, die relevant für die Performance sind, muss man zwischen> korrekt und schnell abwägen.
An dieser Stelle möchte ich widersprechen. Korrekt und schnell wäre auch
eine Möglichkeit ;) Ein int bspw. kann korrekt und schnell sein, wenn
sichergestellt ist, dass der Container nicht zu groß ist.
Dr. Sommer schrieb:> Und worin besteht überhaupt der Unterschied zwischen signed und unsigned> Addition? Das sind ja nichtmal verschiedene Instruktionen.
Guck mal hier:
CppCon 2016: Chandler Carruth “Garbage In, Garbage Out: Arguing about
Undefined Behavior..."
https://youtu.be/yG1OZ69H_-o?t=39m13s
mh schrieb:> Nur in Software die zu langsam ist und in den <5% des> Programms, die relevant für die Performance sind, muss man zwischen> korrekt und schnell abwägen.
In der Regel wird man eher zwischen schön und schnell abwägen. Schneller
Code, der aber nicht das richtige Ergebnis bringt, ist ja nun eher
sinnlos.