Guten Abend allerseits!
Vorab: Man möge sich bitte nicht am merkwürdigen Titel
stören -- das Projekt IST merkwürdig.
Dann: Trotz aller Bedenken und Zweifel ("...halb zog sie
ihn, halb sank er hin...") suche ich tatsächlich Mit-
streiter, auch wenn die Chancen vermutlich nicht besonders
hoch sind, welche zu finden, und ich noch keine genaue
Vorstellung habe, wie die Zusammenarbeit aussehen könnte.
Historischer/biographischer Hintergrund des Projekts: Ich
habe, wie sicherlich der eine oder andere hier auch, immer
mal wieder Datenblätter von Bauteilen zusammengetragen, die
mir interessant schienen. Das ist zwar eine etwas einfältige,
aber doch auch anregende Tätigkeit, weil man einen Überblick
bekommt, was die üblichen Transistoren, Dioden, OPVs, ... so
können.
Der Haken bei der Sache war, dass ich mit dem lokalen Datei-
archiv nie zufrieden war. Alle Versuche, ein einfaches und
nützliches Ordnungsprinzip zu finden, sind früher oder später
im Sande verlaufen. Nicht die Arbeit des EINORDNENS war
furchtbar, sondern die Unbequemlichkeit beim WIEDERFINDEN.
Nun ist es so, dass ich immer mal wieder "etwas intensivere"
Berührung mit dem Debian-Paketarchiv habe, welches ja eine
verteilte Datenbank (in Form der Steuerdateien in den
Paketen) enthält. (Wilde Spielwiese für angewandte Graphen-
theorie.)
Dazu kommt, dass ich seit längerem das Gefühl hatte, mich
mal grundlegend mit relationalen Datenbanken, Normalformen
und SQL befassen zu sollen. Daher hatte ich der Übung halber
an einer SQL-Datenbank gebastelt, die parametrische Suche
in Transistordaten ermöglichen sollte.
Das war also das zündfähige Gemisch. Der Funke kam in
Gestalt diverser in diesen heiligen Hallen geführter
Diskussionen über EDA-Systeme, Arbeitsabläufe, Dateiformate
und Datenflüsse.
Reaktionsprodukt: Ein System, das aus drei wesentlichen
Teilen besteht:
1. einem Regelsystem für die Benennung und Speicherung der
Dateien,
2. einer Client-Software für die Suche und den Datenabruf
sowie
3. Ideen für eine Software für Wartung und Bestandspflege.
Kernpunkte:
1. Alle Dateien bleiben einfache Dateien im Dateisystem,
werden also speziell NICHT als BLOBs in einer Datenbank
gespeichert.
2. Gewisse (elementare) Eigenschaften einer relationalen
Datenbank werden mit Mitteln des Filesystems implementiert.
Das betrifft z.B.:
- Dateinamen werden wie zusammengesetzte Schlüssel gebaut,
d.h. bestehen aus mehreren für die Software unterscheid-
baren Feldern. Ich verwenden Typ, Hersteller und
Herausgabejahr für meine Datenblätter, also z.B.
"2N2904_#FAIR-2009.pdf".
- Wiederholungsgruppen (--> 1. Normalform) werden durch
Aliasnamne (Hardlinks) abgedeckt.
Beispiel: Wenn BC547 bis BC550 von NXP im selben
Datenblatt aus dem Jahre 2011 behandelt werden, dann
existieren die Hardlinks
BC546_#NXP-2011.pdf
BC547_#NXP-2011.pdf
BC548_#NXP-2011.pdf
BC549_#NXP-2011.pdf
BC550_#NXP-2011.pdf
für diese Datei.
3. Die Client-Software realisiert eine reine Typsuche, sucht
also NUR im Typfeld der Dateinamen. (Erweiterung ist in
Planung.)
Filterung und Suche stehen parallel zu Verfügung.
4. Die Client-Software zur Suche hat eine "Teilbaum-Eigen-
schaft": Sie kennt natürlich das Wurzelverzeichnis des
Datenblatt-Archives, ignoriert aber jegliche Verzeichnis-
struktur. Alle Dateinamen im Teilbaum werden zu EINER
Liste zusammengefasst. Wenn der gesuchte Typ IRGENDWO
im Archiv auftaucht, wird er gefunden.
5. Die Client-Software behandelt auch Dateien, deren Namen
NICHT den genannten Bauregeln entsprechen, nur stehen
manche Komfortfunktionen dann nicht zur Verfügung.
6. Die Client-Software hat eine "Datensatz-Eigenschaft": Wenn
es (im selben Unterverzeichnis oder in verschiedenen, das
ist egal) mehrere Dateien ("Aliasnamen", Hardlinks) gibt,
die im Typfeld den String "BC547" tragen, dann wird dieser
Typstring EINMAL in der Suchmaske angezeigt. Bei Auswahl
dieses Typs stehen aber ALLE passenden Dateien separat in
der Datei-Listbox, so dass ich leicht aussuchen kann, ob
ich das Datenblatt von Fairchild, ONSEMI oder CDIL sehen
will.
7. Die Funktion, zusätzliche Eigenschaften durch ein
Kategoriensystem ("Rubriken") zu codieren, ist in Arbeit.
Diese Idee setzt Punkt 3 teilweise außer Kraft; die
definierten Rubriken werden natürlich mit Mitteln des
Filesystems (nämlich Unterverzeichnissen) implementiert.
Im Moment existiert ein (äußerst rudimentärer) Client (erstellt
in Tcl/Tk) und ein Datenbestand, der ungefähr 3000 Datensätze
(vorwiegend Transistoren, auch OPVs, Dioden, Mikrocontroller)
kennt.
Es ist praktisch nachgewiesen, dass das System funktioniert.
Der Zugriff auf die Datenblätter ist RASEND schnell; die
Pflege des Bestandes mit "ln" und "mv" ist natürlich mühevoll,
aber ich hatte bisher noch keinen Bedarf nach einem speziali-
sierten Werkzeug :)
Das System ist eine bunte Mischung aus Eigenschafen einer
Dateisuche, eines Filemanagers, einer Datenbank und einer
Dokumentenverwaltung, was meine Schwierigkeiten erklärt, einen
allgemeinverständlichen Namen zu finden.
Das treffendste Bild scheint mir noch der Vergleich mit dem
Schlagwortkatalog einer Bibliothek, deshalb ist der offizielle
Arbeitstitel auch "SubCat". Wenngleich das Bild einer "submarine
cat" die Phantasie anregt, ist doch die Deutung als "subject
catalog" die sachlich richtige.
Mir ist klar, dass keine Einzeleigenschaft grundsätzlich neu
oder innovativ ist; allerdings ist mir keine Software bekannt,
die die Kombination der genannten Eigenschaften liefert. Am
nächsten kommen dem vielleicht Dokumentenmanagementsysteme,
aber da kann ich nicht mitreden, da ich keins kenne.
Über die oben genannten Punkte hinaus gibt es Vorüberlegungen
zum Einsatz in (Klein-)Unternehmen; das betrifft z.B. Netzwerk-
fähigkeit, Backup, Verfügbarkeit, Zusammenarbeit.
Größte Vorzüge des Systems sind:
* Alle Dateien sind zu jedem Zeitpunkt auch OHNE Verwendung
des Systems zugänglich (--> keine Exklusivität).
* Es ist robust gegen Unordnung.
* Es erfordert nur ein Minimum an Vorausplanung und kann im
laufenden Betrieb stufenweise geändert und angepasst werden.
So.
Nach dieser Werbeverkaufsfahrt der Katzenjammer: Das Projekt
wächst mir über den Kopf.
Mein ursprüngliches Problem (Datenblattverwaltung) scheint mir
weitgehend gelöst, aber ich glaube daran, dass die Kernidee
noch wesentlich weiter trägt. Schließlich wollen auch
Gehäusezeichnungen, Footprints, Schaltplansymbole und SPICE-
Modelle verwaltet werden... (Im Familienkreis wurde schon die
Verwaltung von Photos mit diesem System diskutiert...)
Ich würde mich sehr freuen, wenn es mir gelänge, der FOSS-
gemeinde etwas zurückzugeben, und dabei mitzuhelfen, die
freie EDA-Software zu verbessern und interoperabler zu
machen.
Jegliche konstruktive Mitwirkung wird dankbar angenommen,
sei es in Form von hartnäckigen Nachfragen, Vorschlägen
oder sachlicher Kritik. Bei nachhaltigem Interesse kann ich
auch gern die Quelltexte zur Erprobung des Systems zur
Verfügung stellen -- für mentale Beeinträchtigungen aufgrund
der Codequalität kann allerdings keine Reparationsleistung
erbracht werden...
Feuer frei.
Korrektur: Possetitjel schrieb: > 7. Die Funktion, zusätzliche Eigenschaften durch ein > Kategoriensystem ("Rubriken") zu codieren, ist in Arbeit. > Diese Idee setzt Punkt 3 teilweise außer Kraft; die "... setzt Punkt 4 teilweise außer Kraft" > definierten Rubriken werden natürlich mit Mitteln des > Filesystems (nämlich Unterverzeichnissen) implementiert.
Also Google-Desktop-Suche mit Verschlagwortung so strukturiert wie Dein Post?
Possetitjel schrieb: > Am nächsten kommen dem vielleicht Dokumentenmanagementsysteme, aber da > kann ich nicht mitreden, da ich keins kenne. Hm, nicht vielleicht mal recherchieren ob es nicht genau das schon gibt? Was du bauen willst ist eine Dokumentenverwaltung. Die Bastelei mit den Dateinamen würd ich lassen. Lieber die Dateinamen original lassen oder einfach durchnummerieren, und die Suche komplett über eine Datenbank machen. Das ist letztendlich flexibler und erspart einem die Einschränkungen die Dateinamen haben (Länge, Sonderzeichen). Heutzutage ist alles web basiert - daher würd ich das hier auch überlegen. Dann würde es nämlich auch für Organisationen interessant - es muss nicht jeder einen Client installieren, Browser & PDF Reader reicht.
Kann jemand für mich zusammenfassen, was die Frage vom TO war?
Achim S. schrieb: > Also Google-Desktop-Suche mit Verschlagwortung Gute Frage -- nächste Frage. Google-Desktop-Suche kenne ich nicht, weil Google sowieso der Erzfeind ist. -- Trotzdem gutes Stichwort, danke. Müsste ich mal testen, nur um den Vergleich zu haben. > so strukturiert wie Dein Post? ???
Juliuß schrieb: > Kann jemand für mich zusammenfassen, was die Frage vom TO war? Aufnahmetest für ein SW-Projekt.
Achim S. schrieb: > Juliuß schrieb: >> Kann jemand für mich zusammenfassen, was die Frage >> vom TO war? > > Aufnahmetest für ein SW-Projekt. ... und Juliuß ist durchgefallen? Du sprichst in Rätseln (und ich bin übermüdet.)
Dr. Sommer schrieb: > Possetitjel schrieb: >> Am nächsten kommen dem vielleicht Dokumentenmanagementsysteme, >> aber da kann ich nicht mitreden, da ich keins kenne. > > Hm, nicht vielleicht mal recherchieren ob es nicht genau das > schon gibt? Hatte ich schon mal in Angriff genommen, aber mir fehlen die passenden Buzzwords -- eben weil ich mich auf dem Sektor nicht auskenne. Ich dachte, wenn jemandem das, was ich will, bekannt vorkommt, würde er hier bescheidsagen... :) > Was du bauen willst ist eine Dokumentenverwaltung. Ja -- aber eben mit ein paar speziellen Eigenschaften. Am wichtigstens sind mir die niedrige Einstiegsschwelle und die volle Zugänglichkeit der Dateien über das Filesystem. Meine Zielgruppe sind ggf. Privatleute und Klitschen, die zu klein sind, um einen Vollzeit-Administrator zu haben. Deswegen will ich, wenn's geht, auch keine Datenbank. [...] > Heutzutage ist alles web basiert - daher würd ich das > hier auch überlegen. Dann würde es nämlich auch für > Organisationen interessant - es muss nicht jeder einen > Client installieren, Browser & PDF Reader reicht. Den Gedanken hatte ich auch schon -- das Problem ist hier wieder die Einstiegsschwelle, aber diesmal für mich: Webkrempel ist nicht mein Ding. Bissl im Filesystem rummachen bekomme ich dagegen noch hin...
Projekte & Code: Hier könnt ihr eure Projekte, Schaltungen oder Codeschnipsel vorstellen und diskutieren. Bitte hier keine Fragen posten!
Beitrag #5505050 wurde von einem Moderator gelöscht.
Juliuß schrieb: > Kann jemand für mich zusammenfassen, was die Frage > vom TO war? Was an "Biete Chimäre -- suche Mitstreiter" verstehst Du nicht?
Mehmet K. schrieb: > Projekte & Code: > Hier könnt ihr eure Projekte, Schaltungen oder Codeschnipsel > vorstellen und diskutieren. Bitte hier keine Fragen posten! Weiter so. Keinesfalls die Zitatfunktion benutzen -- jeder intelligente Mensch weiss, auf welchen Artikel Du Dich beziehst! Und da ich intelligent bin und ganz sicher weiss, dass Du Dich auf meinen Ursprungsartikel beziehst: Ich habe keine Frage gestellt ! Ich habe eine Bitte formuliert ! Nachtrag: Wie soll man Projekte diskutieren, ohne Fragen zu stellen?
Wenn es nicht nur darum geht, Bauteile auf Leiterplatten zu identifizieren, kommt man um eine parametrische Suche eigentlich nicht herum. Wie oben auch schon vorgeschlagen, würde ich das als Web-Anwendung (via PHP und xyzSQL) realisieren. - Man braucht nur einen Browser als Client (+ggf. PDF-Reader) - Einfügen oder Editieren von Bauelementan kann über Formulare im Browser erfolgen - Link zur Distributor-Seite, ohne das Programm zu wechseln - Distributor-Bestände und Preise können via Crawler abgefragt werden - Lagerverwaltung kann mit integriert werden - Verlinkung mit weiteren Dokumenten (z.B. Family spec, Refman oder Footprint) ist einfach möglich Bei der ganzen Sache sollte man sich auch überlegen, wie die meistens bereits vorhandenen Datenblätter in das System eingepflegt werden können, ohne dass sich jemand hinsetzt und alles von Hand einträgt. Also: Verzeichnis mit PDFs angeben und nach einer gewissen Zeit sind mindstens 80% der Bauelemente mitsamt ihrer wichtigsten Parameter automatisch in die Datenbank aufgenommen worden. Das wäre dann wohl ein Alleistellungsmerkmal. Ansonsten könnte man auch einfach die parametrische Suche der Distributoren benutzen, die haben meist auch Datenblätter dabei...
Joerg W. schrieb: > Ansonsten könnte man auch einfach die parametrische Suche der > Distributoren benutzen, die haben meist auch Datenblätter dabei... Das ist ja schön und gut, und ich mache das auch häufig so. Die Erfahrung hat aber gezeigt, dass Herstellerlinks auf das web durchaus auch verschwinden, wenn es dem Anbieter nicht mehr gefällt. Von daher bin ich auch dazu über gegangen, eine private lokale Datensammlung zu pflegen. Dateibasiert und mit denselben Problemen der Wiederauffindung, die Possetitjel beschreibt.
Possetitjel schrieb: >> Also Google-Desktop-Suche mit Verschlagwortung > > Gute Frage -- nächste Frage. dann goolge nach Desktop-Suche und Verschlagwortung. Da gibt es genügend Programme und auch wissenschaftliche Beiträge >> so strukturiert wie Dein Post? > > ??? Dein Post ist unstrukturiert, eine Bleiwüste. Dein Projekt kann strukturierter sein, deshalb die Frage. Meine Antwort war ja vielleicht noch knapp und provokannt. Aber wie Due hier reagierst, wo jemand die Brettbeschreibung postet, ist nicht mehr schön. Possetitjel schrieb: > Mehmet K. schrieb: > >> Projekte & Code: >> Hier könnt ihr eure Projekte, Schaltungen oder Codeschnipsel >> vorstellen und diskutieren. Bitte hier keine Fragen posten! > > Weiter so. > > Keinesfalls die Zitatfunktion benutzen -- jeder intelligente > Mensch weiss, auf welchen Artikel Du Dich beziehst! > > > Und da ich intelligent bin und ganz sicher weiss, dass Du > Dich auf meinen Ursprungsartikel beziehst: *Ich habe keine* > Frage gestellt ! Ich habe eine Bitte formuliert ! > > > Nachtrag: Wie soll man Projekte diskutieren, ohne Fragen > zu stellen? Wenn Du ein Tolles Programm hast, dass Einmachgläser verwaltet und Etiketten dafür druckt, ... dann wäre dies das Brett, um das Programm vorzustellen. So ist es nun im offtopic gelandet, und Mehmets Post ist zusammenhanglos...
Stichwort Desktopsuche: Mit "Ava Find" haben Verwandte und ich selbst gute Erfahrungen gemacht.
Juliuß schrieb: > Kann jemand für mich zusammenfassen, was die Frage vom TO war? Ich finde die Lösung des TE super, aber vielleicht könnte mir jemand noch mal schnell das zugehörige Problem schildern? Ich meine Dokumentenverwaltungssysteme (und dann auch mit Versionierung, die ich beim TE gar nicht sehe) sind schon eine Weile erfunden. Was ist denn jetzt der Casus Cnackus, das Alleinstellungsmerkmal oder überhaupt mal die Grundidee? Bei einem 3 Minuten Elevator-Pitch hättest du so keine Chance. Zu viel Gelaber statt auf den Punkt zu kommen. Die Details kann man dann nachreichen sobald der Gegenüber verstanden hat worum es eigentlich geht.
Mehmet K. schrieb: > Codeschnipsel falls es um den Begriff geht: ich könnte mir selbst Einzeiler vorstellen, die mit großem Nutzen jeder direkt und sofort nutzen kann und die es Wert wären, in Proj.&Code vorgestellt zu werden. Irgendwer hat ja z.B. mal statische asserts erfunden (vor vielen Jahren). Nur so als Beispiel, also sowas:
1 | #define STATIC_ASSERT(COND,MSG) typedef char static_assertion_##MSG[(COND)?1:-1]
|
Ja, die Grenze zum "ich habe ein int initialisiert" ist fließend ;-)
Achim S. schrieb: > Possetitjel schrieb: >>> Also Google-Desktop-Suche mit Verschlagwortung >> >> Gute Frage -- nächste Frage. > > dann goolge nach Desktop-Suche und Verschlagwortung. Nee, sicher nicht. Was Verschlagwortung ist, weiss ich. Unter einer Desktop- Suche kann ich mir immerhin etwas vorstellen. Mein Punkt war: Ich habe ein äußerstes Misstrauen gegen alle Datenkraken-Dienste, z.B. von Google. Ich kann daher nicht aus eigener Anschauung beurteilen, ob die Google-Desktop-Suche das leistet, was mir vorschwebt, weil ich die Google-Desktop-Suche gar nicht kenne. Wenn Dich das, was mir vorschwebt, an die Google-Desktop-Suche erinnert, kann ich ja nicht GANZ falsch liegen. Das ist eine interessante Rückmeldung. Danke. > Dein Post ist unstrukturiert, eine Bleiwüste. Na klar. Ich vermute, Du gehörst auch zu den Managertypen, die die Gebrüder Wright ankacken, weil sie nicht das Antikollisionsradar und die Mini-Drinks erfunden haben? ((c) Tom DeMarco) > Dein Projekt kann strukturierter sein, deshalb die Frage. Ach, das will ich nicht beurteilen. Wer das, was ich schreibe, komplett bescheuert findet, ist völlig frei, das zu tun. Das ist in Ordnung. Er mag sich nur nicht beschweren, dass ich mir keine Mühe gebe, ihn vom Gegenteil zu überzeugen. Ich muss nichts verkaufen.
"regain" bietet eine sehr gute offline Desktop-Suche mit Datenbank-Schnittstellen, basierend auf dem Paket Lucene. http://regain.sourceforge.net/ https://en.wikipedia.org/wiki/Lucene Interessant waere auch eine Anbindung an einen Komponententester, der die Bauteile vermisst und die Werte sowie den Lagerort in einer Datenbank speichert. So kann man seine Bauteile vermessen, archivieren, lagern und bei Bedarf leicht wieder auffinden. Finde die Idee toll.
Den Hype um Webanwendungen kann ich zwar teilweise nachvollziehen, da sich der clientseitige Pflegeaufwand nur noch auf die Auswahl eines geeigneten Webbrowsers bezieht. Allerdings setzt das voraus, dass jederzeit ein Zugriff auf den entsprechenden Webserver möglich ist. Ein dateibasiertes System finde ich daher für meine eigenen Zwecke besser, allerdings nur dann, wenn die Verzeichnisstruktur sinnvoll auf ein Versionskontrollsystem (z.B. Subversion oder Git) abzubilden ist. Wenn ich z.B. mit einem Notebook zu einem Kunden fahren will, müssen sämtliche aktiven Projekte mit Hilfe eines einzigen Synchronisationskommandos (z.B. svn update oder git fetch/pull) aktualisiert werden können. Besonders schick wäre es, wenn man mit dem Datenblattverwaltungssystem auch mehrere Ansichten verwalten könnte, z.B. für verschiedene Projekte. Und wenn es dann auch noch möglich wäre, solche Projektansichten als svn:externals zu exportieren, wäre das ganze für meinen Anwendungszweck nahezu perfekt. Nachtrag: Für die (für meine derzeitigen Zwecke) perfekte Lösung fehlt natürlich noch eine Verknüpfung mit Altium Designer, d.h. entsprechenden Bauteilebibliotheken. Mittlerweile sind ja etliche Halbleiterhersteller dazu übergegangen, die Bauelemente-Datenblätter von den Gehäuse-Datenblättern zu trennen und nur noch auf letztere zu verweisen. Dies sollte auch in einer Bauelementedatenbank berücksichtigt werden. Dort sollte es auch die Möglichkeit geben, Verknüpfungen zwischen identischen oder hinreichend ähnlichen Bauformen verschiedener Hersteller zu hinterlegen.
Possetitjel schrieb: > Jegliche konstruktive Mitwirkung wird dankbar angenommen OK, dann bin ich außen vor. Du willst doch tatsächlich dir ein weiteres Ordnungs-System schaffen - in der Hoffnung, dann was Relevantes leichter wiederzufinden. meine Ansicht: gib's auf, bevor du anfängst. Ich hab sowas schon durch und weiß, daß man damit scheitert. Der Grund dafür ist, daß man quasi das tatsächliche Leben eben nicht in einen Formalismus pressen kann. Das, was du heut als ausreichendes Kriterien-System betrachtest, wird mit Sicherheit in der Zukunft nicht mehr zutreffen. W.S.
calibre könnte für Datenblatt-Verwaltung geeignet sein, irgendwie komm ich aber mit dem Programm nicht zurecht. Mayan EDMS ist ein webservice, kann man aber ohne Probleme lokal installieren oder per Docker laufen lassen. Verdaut PDFs aus einem watch-folder oder auch direkt vom Scanner. Kann Dokumente verschlagworten, automatisch analysieren und in eine Hierarchie einordner, die man per FUSE auch als Datei-System wieder exportieren kann. Natürlich gibts auch Volltextsuche. Für Datenblätter und ähnliches habe ich allerdings einfach nur ein Verzeichnis welches "grob" organisiert ist, und regelmässig von recoll gescannt wird, gefunden wird dann mit Volltext-Suche, das ist schneller als jede Hierarchie (die sich bei Datenblättern und Appnotes ja oft nicht direkt aufzwingt, also nicht eindeutig ist und dann sucht man in 5 Ebenen tiefen Hierarchien herum).
Wenn ich dich richtig verstanden habe: Das Programm soll Dateien verwalten und datenbankmäßig bestimmte Eigenschaften vorhalten. Die Eigenschaften werden aber getrennt von den eigentlichen Datein (Z.B. Datenblättern) vorgehalten. Das Programm soll insbesondere zur Suche nach den Dateien und Inhalten helfen. Possetitjel schrieb: > Alle Dateien bleiben einfache Dateien im Dateisystem, > werden also speziell NICHT als BLOBs in einer Datenbank > gespeichert. Wenn die "Nutz"-Dateien im Dateisystem organisiert werden sollen, ist es sicher sinnvoll das auch für die zugefügten Eigenschaften durchzuführen. Man könnte sich also für Ordner einen Unterordner mit Namen "SubCat" vorstellen, in dem für jede Nutzdatei eine Eigenschaftendatei mit gleichem Namen aber anderer Endung liegt. Für die Nutzdatei "LM358.pdf" dann z.B. eine Eigenschaftendatei LM358_pdf.cat. In Subcat kann dann der Nutzer angeben, dass ein Orner mit allen Unterordnern subcat-verwaltet werden soll. Subcat scannt dann die Verzeichnisse durch und muss vermutlich einen Dateibrowser bereitstellen, damit man den Dateien Eigenschaften zuweisen kann. Die Eigenschaften werden in bestimmte Felder kategorisiert, bei Widerständen sind das andere wie bei Transistoren. Ein Problem dabei ist der unkontrollierte Zugriff auf die Dateien über einen Dateibrowser. Pfade stimmen dann nicht mehr, es gibt verwaiste Eigenschaftendateien, überschriebene Dateien, d.h. mit gleichem Name aber geöndertem Inhalt und ähnliches. Da muss man sich gut Gedanken machen, wie man das robust bekommt. > (Im Familienkreis wurde schon die > Verwaltung von Photos mit diesem System diskutiert...) Das heißt es muss sich um eine generische, konfigurierbare Lösung handlen. Das wird insbesondere für die Datensatzverwaltung komplizierter. Im Programm kann man dann einen "Datentyp" anlegen, z.B. Transistor, für den man bestimmte Eigenschaftfelder vorsieht. Einer neuen Datei weist man dann zunächst den "Datentyp" zu und kann anschließend die typspezifischen Eigenschaftenfelder ausfüllen. Bei der Suche wirds dann interessant, verschiedene Typen könnten gemeinsame Felder haben, oder man möchte den gleichen Wert in verschiedenen Feldern suchen. Auch Unterkategorien sind wohl erwünscht. So könnte man nach Transistoren mit einem bestimmten Collector- bzw. Drainstrom suchen wollen. Sind Collectorstrom und Drainstrom verschiedene Eigenschaften wegen unterschiedlichen Typen "Bipolartransistor" und "FET", dann kann man in der Suche mit einer oderverknüpften Suche für beide (getrennte) Felder einen Wert angeben. Eine andere Vorgehensweise könnte sein, dass man von übergeordneten Eigenschaften ableitet. Typ "Transistor" hat dann das Feld "Collector-/DrainStrom", der Typ Bipolartransistor als abgeleiteter Typ überschreibt das Feld zu Collectorstrom... In der Suche kann man dann für den Typ Transistor über Bipolare und Fets suchen oder eben gezielter. Wird sicher schnell aufwendig. -- Ob sowas schon gibt? Keine Ahnung.
Angehängte Dateien:
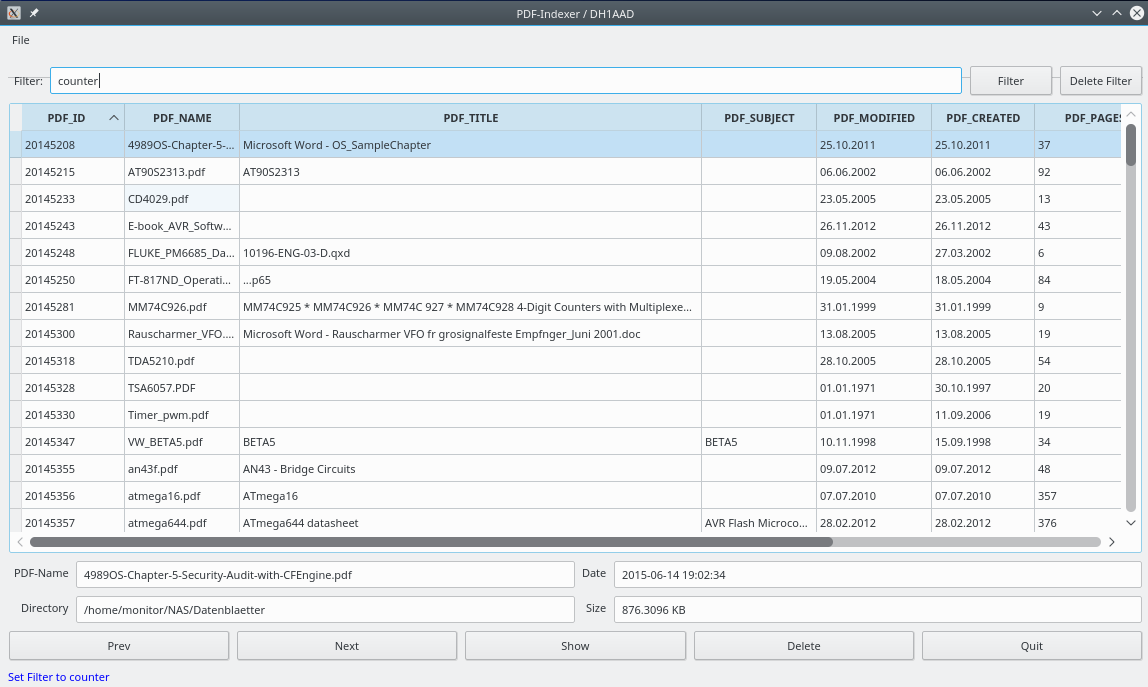
Hi, ich habe mir vor einiger Zeit ein kleines Tool (PyQt) erstellt, um meine PDF-Datenblätter besser wieder zu finden. Man kann damit eine einzelne Datei, Dateiliste oder ganze Verzeichnisse importieren. In der DB werden nur die PDF-Metadaten gespeichert sowie der Pfad zum eigentlichen PDF. Auch wird versucht das PDF zu extrahieren um eine Volltextsuche zu ermöglichen. Für meine Zwecke reicht mir das so aus. Gruß Ingo, DH1AAD
Possetitjel schrieb: > Kernpunkte 1, 2, 3, 4, 5, 6: Das macht jede Desktopsuche bereits jetzt. Egal ob es die in Windows (Windows Search) oder die in Gnome (Tracker) oder KDE (Baloo) eingebaute/mitinstallierte ist. > 7. Die Funktion, zusätzliche Eigenschaften durch ein > Kategoriensystem ("Rubriken") zu codieren, ist in Arbeit. > Diese Idee setzt Punkt 3 teilweise außer Kraft; die > definierten Rubriken werden natürlich mit Mitteln des > Filesystems (nämlich Unterverzeichnissen) implementiert. Siehe oben, wenn die PDFs in passende Unterverzeichnisse einsortiert sind (hier bspw. RCL, Connectors, Displays etc. und div. für die ganzen Hersteller) > Im Moment existiert ein (äußerst rudimentärer) Client (erstellt > in Tcl/Tk) und ein Datenbestand, der ungefähr 3000 Datensätze > (vorwiegend Transistoren, auch OPVs, Dioden, Mikrocontroller) > kennt. Hier sind's ~3300 Datenblätter, ANs, PCNs, Errata etc. überwiegend keine Transistoren ;) > Es ist praktisch nachgewiesen, dass das System funktioniert. > Der Zugriff auf die Datenblätter ist RASEND schnell; die > Pflege des Bestandes mit "ln" und "mv" ist natürlich mühevoll, > aber ich hatte bisher noch keinen Bedarf nach einem speziali- > sierten Werkzeug :) Aufwand hier: Einmal beim Download in das passende Verzeichnis ablegen. Was mir eher fehlt: Eine vernünftige Suche über alle Parameter insb. bspw. bei OpAmps, aber auch bei Dioden (die Suche bei div. Distributoren ist z.T. unterirdisch, die der Hersteller z.T. unvollständig). So was wäre eher was für eine Webseite (JSON-/XML-Schemata für den automatischen Upload, überprüfte Datensätze etc. pp) und wenn man schon dabei ist, könnten auch gleich passende Bibliotheken mit dazu gepackt werden.
Ich sehe das Problem in der Verschlagwortung. Man kann nicht alle interessanten Attribute, in diesem Fall ein Satz technischer Daten, im Dateinamen unterbringen. Also wäre eine Möglichkeit dass jede Datei ihre Metadaten enthält. Das funktioniert ja bei MP-3-Dateien und den zugehörigen Playern bereits hinreicheind gut. Und schon dort erkenne ich, dass die Arbeit, sämtliche Metadaten korrekt einzupflegen rasch gigantische Ausmaße annimmt. Von daher brauche ich mir garnicht erst die Mühe machen, ein entsprechendes System zu installieren - in diesem Leben würde das niemals fertig werden.
> Vorab: Man möge sich bitte nicht am merkwürdigen Titel > stören -- das Projekt IST merkwürdig. leider ist mir unklar, was das genaue Ziel des Projekts ist. Man kann es anhand der bisherigen Posts nur erahnen: Eine Transitordatenbank mit verschiedenen Verlinkungen, um dann offline mittels Schlagwortsuche das entsprechende Datenblatt des Transitors zu finden? Wie Du richtig erkannt hast: das wird Dir allein über den Kopf wachsen (vor allen Dingen sprengt es den Zeitrahmen) und eben wegen Web-Verfügbarkeit und Schlagwortsuche per Google im Prinzip absolut nicht mehr notwendig - somit ist der kommerzielle Aspekt gleich Null. Wenn es ein abgeschottetes System sein soll, wird das die jeweilige Firma immer für sich selbst entwickeln und je nach Größe des Unternehmens macht das dann ein ganzes Team (unabhängig von der Spezifikation dieses Projekts, aber der Aufbau ist in den Modulen identisch). So als Übung zur Einarbeitung in SQL, C, C++ sicherlich ein nettes Projekt, um dann selbst fit zu werden .... dann bist Du wirklich fit.
Possetitjel schrieb: > Nun ist es so, dass ich immer mal wieder "etwas intensivere" > Berührung mit dem Debian-Paketarchiv habe, welches ja eine > verteilte Datenbank (in Form der Steuerdateien in den > Paketen) enthält. (Wilde Spielwiese für angewandte Graphen- > theorie.) Ja, nur leider auch deutliches Zeichen, dass diese Spielwiese nicht beherrscht wird. Deutliches Zeichen: die zunehmenden Updates des Updatesystems selber. Die sind fast immer nur für genau nur eins nötig: eine Endlos-Schleife beim Parsen des Graphen zu beheben... Allerdings: bei Windows erfolgt exakt dasselbe Spiel. Das liegt allerdings nicht wirklich daran, dass es grundsätzlich unmöglich wäre, einen universellen Parser für derartige Graphen zu schreiben. Nein, es liegt daran, dass bei der Konstruktion der Updatesysteme Frickler am Werk waren, die die zukünftige Komplexität nicht annähernd im Blick hatten und im Prinzip nur ein paar triviale Grundmuster in ihrem Parser implementiert haben. Und an dem Scheiss wird nun immer wieder aufwendig für jeden Einzelfall rumgepatched, um die Fälle zu fangen, die halt nicht in die Grundmuster passen, statt endlich mal was zu schaffen, was Hand und Fuß hat... Das musste mal raus. Auch wenn es garnicht zu deinem Thema passt. Dafür brauchst du nämlich so ein System garnicht. Das ist schlichte parametrische Suche in Datenbanken. Ein viel einfacheres Thema. Nicht trivial ist hingegen: eine gute parametrische DB zu konstruieren. > Dazu kommt, dass ich seit längerem das Gefühl hatte, mich > mal grundlegend mit relationalen Datenbanken, Normalformen > und SQL befassen zu sollen. Das solltest du wohl sehr dringend... Bevor das nicht passiert ist, wirst du nicht verstehen, was im Folgenden sagen werde... > 1. einem Regelsystem für die Benennung und Speicherung der > Dateien, Schon geloosed. Kein Mensch braucht irgendwelche Dateien, wenn er eine Datenbank benutzt. > 2. einer Client-Software für die Suche und den Datenabruf > sowie > 3. Ideen für eine Software für Wartung und Bestandspflege. Da fehlt das Wichtigste: das Konzept für die Parameter. Das ist komplizierter als man denkt. Es geht nämlich nicht nur darum, festzulegen, welche Parameter wie gespeichert werden, sondern vor allem darum, bei Abfragen festzustellen, welche der nicht explizit durch die Abfrage spezifizierten wichtig sind, um ein sinnvolles Suchergebnis zu liefern. Denn ja: es gibt oft semantische Beziehungen zwischen den Parametern. Diese Semantik in der Datenbank abzubilden, das wäre der eigentliche Trick. Für den normalen Scheiss genügt hingegen das, was auch die (Re-)Seller allerorten bereits als Suche anbieten... > Kernpunkte: > 1. Alle Dateien bleiben einfache Dateien im Dateisystem, > werden also speziell NICHT als BLOBs in einer Datenbank > gespeichert. Das ist (allenfalls) für die Original-Datenblätter u.ä. sinnvoll. > 2. Gewisse (elementare) Eigenschaften einer relationalen > Datenbank werden mit Mitteln des Filesystems implementiert. Das ist völliger Unsinn, absolut kontraproduktiv. > 3. Die Client-Software realisiert eine reine Typsuche, sucht > also NUR im Typfeld der Dateinamen. Damit wird es endgültig unnütz. Wenn ich schon weiß, was ich kaufen will, brauch' ich keine lokale hochintelligent spezialisierte DB eines Expertensystems zur Bauteilwahl mehr, sondern einfach nur noch die Suchfunktion bei meinem bevorzugten Dealer... > 4. Die Client-Software zur Suche hat eine "Teilbaum-Eigen- > schaft": Sie kennt natürlich das Wurzelverzeichnis des > Datenblatt-Archives, ignoriert aber jegliche Verzeichnis- > struktur. Alle Dateinamen im Teilbaum werden zu EINER > Liste zusammengefasst. Wenn der gesuchte Typ IRGENDWO > im Archiv auftaucht, wird er gefunden. > 5. Die Client-Software behandelt auch Dateien, deren Namen > NICHT den genannten Bauregeln entsprechen, nur stehen > manche Komfortfunktionen dann nicht zur Verfügung. > 6. Die Client-Software hat eine "Datensatz-Eigenschaft": Wenn > es (im selben Unterverzeichnis oder in verschiedenen, das > ist egal) mehrere Dateien ("Aliasnamen", Hardlinks) gibt, > die im Typfeld den String "BC547" tragen, dann wird dieser > Typstring EINMAL in der Suchmaske angezeigt. Bei Auswahl > dieses Typs stehen aber ALLE passenden Dateien separat in > der Datei-Listbox, so dass ich leicht aussuchen kann, ob > ich das Datenblatt von Fairchild, ONSEMI oder CDIL sehen > will. > 7. Die Funktion, zusätzliche Eigenschaften durch ein > Kategoriensystem ("Rubriken") zu codieren, ist in Arbeit. > Diese Idee setzt Punkt 3 teilweise außer Kraft; die > definierten Rubriken werden natürlich mit Mitteln des > Filesystems (nämlich Unterverzeichnissen) implementiert. Alles Bullshit. Viel Aufwand, um in einem Dateisystem was zu machen, was in einer relationalen DB um ein Vielfaches einfacher und besser und performanter abbildbar wäre.
Possetitjel schrieb: > Vorab: Man möge sich bitte nicht am merkwürdigen Titel > stören -- das Projekt IST merkwürdig. Immerhin merkwürdig genug, daß auch schon andere -- zum Beispiel ich -- auf so eine Idee gekommen sind und ein paar Zeilen Code dazu geschrieben haben. Leider bin ich gerade beruflich ziemlich eingespannt, so daß das Projekt zur Zeit leider auf Eis liegen muß. ;-( > Der Haken bei der Sache war, dass ich mit dem lokalen Datei- > archiv nie zufrieden war. Alle Versuche, ein einfaches und > nützliches Ordnungsprinzip zu finden, sind früher oder später > im Sande verlaufen. Nicht die Arbeit des EINORDNENS war > furchtbar, sondern die Unbequemlichkeit beim WIEDERFINDEN. Gerade deswegen habe ich einen etwas anderen Ansatz gewählt, nämlich die Volltext-Suchmaschine Elasticsearch mit einem kleinen Python-Skript zum Import der Datenblätter und einer kleinen Webanwendung mit Python und Flask zum Suchen und Abrufen derselben. Nichts gegen SQL-Datenbanken, ich bin ein großer Fan von PostgreSQL. Aber für diesen Anwendungsfall ist Elasticsearch IMHO besser geeignet: das kann PDF-Daten direkt importieren, die Textinhalte daraus extrahieren und macht einen invertierten Index daraus, der sehr schnell durchsucht werden kann, und gleichzeitig kann es auch strukturierte Daten speichern. Natürlich hat das einen Preis: Elasticsearch ist ein Monster. Das initiale Setup und auch das Aufsetzen eines Clusters sind zwar ein Kinderspiel, aber die Abfragesprache (JSON) kann bei fortgeschrittenen Funktionen durchaus komplex werden -- obwohl: das kann man auch mit SQL haben, ich sag' nur Window Functions oder Common Table Expressions. ;-) Andererseits ist Elasticsearch bei der Suche unfaßbar schnell und obendrein dank seiner (extrem einfach aufzusetzenden) Clusterfähigkeit fast unendlich skalierbar, bietet extrem viele Suchmöglichkeiten, zum Beispiel unscharfe Suche mit Levenshtein-Distanz, phonetische Suche, und vieles mehr. Nicht ohne Grund sind Elasticsearch und Apache Solr die verbreitetsten Volltext-Suchmaschinen -- und ich kenne zum Beispiel eine große Versicherung in D, die etwa 600 GB Daten und Dokumente in einem Elasticsearch-Cluster nutzt. Eine mir bekannte Bank in den Niederlanden pumpt die gesamten Logdateien ihres Rancher-Containerclusters in einen Elasticsearch-Cluster, um sie mit dem Webfrontend Kibana zu analysieren und zu visualisieren. Auch wenn mein Ansatz ein anderer ist, finde ich Dein Projekt grundsätzlich prima und verstehe nicht, warum jetzt plötzlich Leute über Dich herfallen, die bisher hier noch nie durch konstruktive Beiträge aufgefallen sind. ;-) Insofern: viel Spaß und Erfolg!
Possetitjel schrieb: > Was Verschlagwortung ist, weiss ich. Unter einer Desktop- > Suche kann ich mir immerhin etwas vorstellen. Wenn ich Deinen Gebrauch von "ln" (warum eigentlich keine Symlinks?) und "mv" richtig verstanden habe, benutzt Du da ein UNIXoides System. Da gibt es ein paar moderne Desktops wie zum Beispiel KDE, die so etwas bereits eingebaut haben -- im Falle von KDE mit einer Software namens Baloo, die zu Akonadi gehört. Auf der CLI gibt es dazu den Befehl "baloosearch" für die Suche.
min schrieb: > "regain" bietet eine sehr gute offline Desktop-Suche mit > Datenbank-Schnittstellen, basierend auf dem Paket Lucene. > > http://regain.sourceforge.net/ Cool, danke, das kannte ich noch nicht. > https://en.wikipedia.org/wiki/Lucene Das ist übrigens die Library, die auch in den Volltext-Searchengines Apache Solr und Elasticsearch arbeitet.
> Auch wenn mein Ansatz ein anderer ist, finde ich Dein Projekt > grundsätzlich prima und verstehe nicht, warum jetzt plötzlich Leute über > Dich herfallen, die bisher hier noch nie durch konstruktive Beiträge > aufgefallen sind. ;-) Dankeschön! Ich könnte jetzt noch was zum obigen Projekt und zu Elasticsearch, etc. schreiben (Danke für den Link, Elasticsearch kannte ich noch gar nicht und hat ganz klare Vorteile). Aber wie immer im Leben gibt es noch eine zweite Seite der Medaille, die Du leider gar nicht mehr wahrnimmst, weil Du Sie aufgrund Deines Lebenslaufes gar nicht wahrnehmen kannst oder willst. Und andere natürlich auch nicht, es wird gar nicht mehr wahrgenommen ... es kommt einfach nichts und das Space Shuttle oder die Ariane Rakete stürtzt dann mal ab, obwohl doch alles richtig war ;-) Ich habe allerdings keine Lust mehr auf irgendeinen sinnlosen Disput, wo sich dann die ganzen watchdogs und andere toxic people wieder einschalten, lieber nicht. Ich gehe davon aus, daß ich ebenfalls zu den Leuten mit den weniger konstruktiven Beiträgen gehöre ;-) Damit kann ich gut leben. Eine Waschinenmaschinen-Reparatur der Firma xy oder aktuell die Konstruktion einer 1000Watt (warum nicht noch mehr?) LED-Leuchte, usw.,usw., in Subforum Analogtechnik oder auch anderswo gehören natürlich zu den brillianten konstruktiven Beiträgen ;-) Selbiges im Prinzip hier, werde ich aber nicht weiter erläutern! Na ja, blabla blabla, nochmals vielen Dank für Deinen Post und den goldrichten Einwand - ich schreib demnächst dann noch einen Abschiedspost im verhaßten Offtopic und das war's dann.
Joerg W. schrieb: > Wenn es nicht nur darum geht, Bauteile auf Leiterplatten > zu identifizieren, kommt man um eine parametrische Suche > eigentlich nicht herum. Im Prinzip stimmt das. Parametrische Suche war ja auch ursprünglich das Ziel; deshalb meine Versuche mit SQL. Das Problem ist: Wo sollen die Daten herkommen? Bei einer Parameterdatenbank kann man genau DIE Daten abrufen, die man vorher (von Hand oder sonstwie) eingepflegt hat. Die Reichweite der "Verschlagwortung", die ich im Moment verwende, ist nicht ganz so groß -- dafür ist das Aufwand- Nutzen-Verhältnis VIEL besser: Ich muss nur ein paar Schlagworte eingeben, gewinne aber den Zugriff auf das gesamte Datenblatt mit all seinen Angaben. > Wie oben auch schon vorgeschlagen, würde ich das als > Web-Anwendung (via PHP und xyzSQL) realisieren. Nichts dagegen. Allerdings bekomme ich das nicht als Einzelkämpfer hin; dazu fehlt mir das Wissen. Da sich aber die gesamte Datenhaltung im Filesystem abspielt, sehe ich keinen Grund, wieso man statt des lokalen Client, an dem ich im Moment bastele, nicht auch etwas webbasiertes verwenden können sollte. > Bei der ganzen Sache sollte man sich auch überlegen, > wie die meistens bereits vorhandenen Datenblätter in > das System eingepflegt werden können, ohne dass sich > jemand hinsetzt und alles von Hand einträgt. Die schlechte Nachricht: Das geht nicht anders. Die gute Nachricht: Das Einpflegen kann man in mehreren Stufen machen. Man kann die Dateien also im ersten Schritt einfach so, wie sie sind, in das Archiv hineinwerfen und findet sie dann genauso wieder, wie es auch mit jedem normalen Filemanager der Fall wäre. Noch kein Fortschritt, aber auch kein zusätzliches Problem. Die Datenblätter, die man öfter braucht, kann man Stück für Stück einpflegen, das ist eine relativ kleine Mühe. > Ansonsten könnte man auch einfach die parametrische > Suche der Distributoren benutzen, die haben meist auch > Datenblätter dabei... Klar -- das eignet sich als Quelle für die Datenblätter...
Mark S. schrieb: > Von daher bin ich auch dazu über gegangen, eine private > lokale Datensammlung zu pflegen. Dateibasiert und mit > denselben Problemen der Wiederauffindung, die Possetitjel > beschreibt. Magst Du dazu ein paar Worte mehr schreiben? Hast Du Lösungen für die Probleme gefunden?
Alex G. schrieb: > Stichwort Desktopsuche: Mit "Ava Find" haben Verwandte > und ich selbst gute Erfahrungen gemacht. min schrieb: > "regain" bietet eine sehr gute offline Desktop-Suche mit > Datenbank-Schnittstellen, basierend auf dem Paket Lucene. Es scheint sich ja abzuzeichnen, dass mein Projekt am ehesten mit einer Desktop-Suche vergleichbar ist. Ich werde mich in der Richtung mal kundig machen; danke für den Hinweis.
Andreas S. schrieb: > Den Hype um Webanwendungen kann ich zwar teilweise > nachvollziehen, da sich der clientseitige Pflegeaufwand > nur noch auf die Auswahl eines geeigneten Webbrowsers > bezieht. Allerdings setzt das voraus, dass jederzeit > ein Zugriff auf den entsprechenden Webserver möglich > ist. Ja. Nach meiner Erfahrung haben kleinere Uni-Institute wie auch kleine Klitschen in der Wirtschaft das Problem, dass nur zeit- und fallweise Kapazität für die Pflege der eigenen IT vorhanden ist. Deswegen ist das Ziel, möglichst viele ohnehin vorhandene Mechanismen zu benutzen (und ein Filesystem IST heutzutage immer vorhanden) und sich möglichst wenig von zentral zu wartenden Ressourcen abhängig zu machen. > Ein dateibasiertes System finde ich daher für meine > eigenen Zwecke besser, allerdings nur dann, wenn die > Verzeichnisstruktur sinnvoll auf ein Versionskontroll- > system (z.B. Subversion oder Git) abzubilden ist. Hmm. Was bedeutet das im Kontext des Datenblatt-Kataloges? Datenblätter ändern sich nicht betriebsmäßig (keine "Verkehrsdaten", sondern "Stammdaten") -- es können lediglich neue Versionen hinzukommen. Das ist bereits berücksichtigt. Ansonsten gibt es EINEN Verzeichnisbaum, der den "Bestand" aufnimmt (jede Datei wird unter einem kryptografischen Hash-Namen gespeichert), und beliebig viele "Kataloge", die die Hardlinks (="Schlagworte") aufnehmen. Natürlich könnte man auch projektspezifische "Kataloge" anlegen, aber in diese Richtung habe ich noch nicht gedacht. Das war erstmal nicht im Fokus -- aber wenn jemand das brauchen kann, ist es natürlich interessant. > Wenn ich z.B. mit einem Notebook zu einem Kunden fahren > will, müssen sämtliche aktiven Projekte mit Hilfe eines > einzigen Synchronisationskommandos (z.B. svn update oder > git fetch/pull) aktualisiert werden können. Ich würde vermuten, dass das mit rsync oder so machbar ist, aber das ist geraten. Mir ist Dein Anwendungszenarium noch nicht ganz klar. > Besonders schick wäre es, wenn man mit dem > Datenblattverwaltungssystem auch mehrere Ansichten verwalten > könnte, z.B. für verschiedene Projekte. Und wenn es dann auch > noch möglich wäre, solche Projektansichten als svn:externals > zu exportieren, wäre das ganze für meinen Anwendungszweck > nahezu perfekt. Hmm. Vielleicht müsste man das mal gründlicher durchspielen. Ich hatte die Verwendung von Versionsverwaltungssystemen für meinen Zweck verworfen, weil Datenblätter ja keine Dokumente sind, die betriebsmäßig geändert werden und wo von "einem" Dokument eine Vielzahl von Versionen vorhanden ist -- das sind ja eher statische Daten. Es gibt zwar mehrere Ausgaben desselben Datenblattes, aber die sind eben so, wie sie sind, und ändern sich nicht mehr. Das schließt aber nicht aus, eine Schnittstelle zu VCS zu schaffen; ich hatte das nur bisher nicht auf dem Schirm.
Bei deiner Filesystem Lösung sehe ich schnell ein Ende der Möglichkeiten erreicht, die man ohne Hacks umsetzen kann. Ich habe pro Projekt einen Datenblatt-Ordner. Da lege ich die komplette Doku für einen Baustein ab, also: - Datenblatt - Reference Manual - Errata - Footprint - Relevante Appnotes - ggf. Tools, Firmware-Config Wie würde das sinnvoll strukturiert in dein System passen? Wie verwalte ich verschiedene Versionen? Z.B. hat ein Mikrocontroller xyz-B zu xyz-C Typ ein anderes Errata und evtl. neue Register. Wie kann ich festlegen welcher Datenbestand zu welchem Projekt gehört? Z.B. brauche ich zur Wartung eines alten Projekts alle Daten zum Hardware Stand von damals, neue Infos will ich dann nicht bekommen. Also so wie du es präsentiert hast, ein System zum horten diverser BC337 & Co Standard-Datenblätter, wäre es für mich bloß eine Fleissaufgabe ohne großen Nutzen.
Sheeva P. schrieb: > Possetitjel schrieb: >> Vorab: Man möge sich bitte nicht am merkwürdigen Titel >> stören -- das Projekt IST merkwürdig. > > Immerhin merkwürdig genug, daß auch schon andere -- zum > Beispiel ich -- auf so eine Idee gekommen sind und ein > paar Zeilen Code dazu geschrieben haben. :) Wir hatten das Thema ja auch schonmal gestreift, als es um horizon, Schaltplansymbole, Footprints usw. ging. > Leider bin ich gerade beruflich ziemlich eingespannt, so > daß das Projekt zur Zeit leider auf Eis liegen muß. ;-( Schade. > Gerade deswegen habe ich einen etwas anderen Ansatz > gewählt, nämlich die Volltext-Suchmaschine Elasticsearch > [...] > > Natürlich hat das einen Preis: Elasticsearch ist ein > Monster. Naja, ich denke, wir haben nicht nur technisch und methodisch komplementäre Ansätze, sondern auch verschiedene Zielgruppen. Mein Fokus liegt auf Leuten wie mir, die zwar ein computer- technisches Grundverständnis haben und ggf. auch die eine oder andere Kleinigkeit programmieren können, aber eben keine hauptberuflichen studierten Informatiker sind. Für z.B. eine kleine Klitsche, die spezielle elektronische Messgeräte entwickelt, produziert und vertreibt, ist die IT nur ein notwendiges Übel, das halt funktionieren muss. Zuverlässige Verfügbarkeit irgendwelcher hochentwickelter Serverdienste ist nach meiner Erfahrung höchst unwahrschein- lich. Ich habe daher versucht, das zu unterstützen und zu ver- bessern, was an Arbeitsschritten sowieso stattfindet. Ich lade ab und an ohnehin Datenblätter herunter, die ich bei Farnell, über Google oder direkt beim Hersteller finde. Dabei muss ich i.d.R. SOWIESO einen passenden Dateinamen angeben -- also fällt kein Zusatzaufwand an, wenn ich den Namen nach einem bestimmten System bilde und die Datei auf diese Weise in mein System einpflege. Und wenn ich das DaBla ohnehin schon im Viewer habe, kann ich auch leicht die Aliasnamen für die anderen Typen vergeben und alles in die richtige Kategorie einsortieren. Das ist eine relativ kleine Mühe, die man ja nur einmal hat -- und sowieso nur bei den Datenblättern, die schon irgendwie interessant sind. > Andererseits ist Elasticsearch bei der Suche unfaßbar > schnell und obendrein dank seiner (extrem einfach > aufzusetzenden) Clusterfähigkeit fast unendlich skalierbar, > bietet extrem viele Suchmöglichkeiten, zum Beispiel > unscharfe Suche mit Levenshtein-Distanz, phonetische Suche, > und vieles mehr. Naja, ich sehe die Gefahr eines gewissen Overengineerings. Die 15-Mann-Bude (Entwicklung & Fertigung), bei der ich zuletzt gearbeitet habe, hatte genau EINEN hauptberuflichen Programmierer. Der musste neben der Arbeit an den Kunden- projekten auch das Inhouse-Zeug machen. Es gab mit Ach und Krach eine Datenbank für Lagerverwaltung und Einkauf -- an Dokumentenmanagement oder Datenblattverwaltung war gar nicht zu denken. Das war NICHT die Schuld dieses armen Teufels... > Auch wenn mein Ansatz ein anderer ist, finde ich Dein > Projekt grundsätzlich prima und verstehe nicht, warum > jetzt plötzlich Leute über Dich herfallen, die bisher > hier noch nie durch konstruktive Beiträge aufgefallen > sind. ;-) "Wenn Du kritisiert wirst, dann musst Du irgend etwas richtig machen. Denn man greift nur denjenigen an, der den Ball hat." (Bruce Lee) > Insofern: viel Spaß und Erfolg! Danke.
Possetitjel schrieb: > Mark S. schrieb: > >> Von daher bin ich auch dazu über gegangen, eine private >> lokale Datensammlung zu pflegen. Dateibasiert und mit >> denselben Problemen der Wiederauffindung, die Possetitjel >> beschreibt. > > Magst Du dazu ein paar Worte mehr schreiben? Hast Du > Lösungen für die Probleme gefunden? Mein Archiv ist einfach hierarchisch gegliedert. Die entscheidende Frage ist für mich hier die Wahl der Begriffe, d.h. die Namensvergabe der Unterverzeichnisse. Diese sollten so eindeutig und leicht merkbar wie irgend möglich sein. Es gibt zum Glück gewisse Namenskonventionen in der Elektronik an die ich mich versuche zu halten, die aber nun mal auch nicht überall konsequent durch gehalten werden. Genau hierin steckt mein Gehirnschmalz. Beispiel: hardwarearchiv/pub/components/active/ic/analogue/opa/semi_opa_ti_tle206x .pdf Wie man sieht, kommen hier schnell tiefe Verzeichnisbäume zu Stande. Der Dateiname ist in einer bestimmten Weise aufgebaut um technische Merkmale auszufiltern. Und schließt damit eine einfache alphabetische Suche nach der Typenbezeichnung aus - das mache ich dann lieber online. Und dann verwende ich eine Menge Zeit, die mich interessierenden Bereiche händisch möglichst konsequent um zu benennen. Eine Sysiphusarbeit - aber dieselbe müßte man auch bei der Pflege von Metadaten leisten. Ansonsten benutze ich die parametrische Suche von Mouser und Digikey und kippe die Datenblätter in die eingerichteten Verzeichnisse. Das funktioniert für mich nun seit etwa 15 Jahren so, dieses Archiv umfaßt derzeit 13,9GB.
Sheeva P. schrieb: > Possetitjel schrieb: >> Was Verschlagwortung ist, weiss ich. Unter einer Desktop- >> Suche kann ich mir immerhin etwas vorstellen. > > Wenn ich Deinen Gebrauch von "ln" (warum eigentlich keine > Symlinks?) und "mv" richtig verstanden habe, benutzt Du > da ein UNIXoides System. Ja. > Da gibt es ein paar moderne Desktops wie zum Beispiel KDE, > die so etwas "so etwas" == Desktop-Suche? > bereits eingebaut haben -- im Falle von KDE mit einer > Software namens Baloo, die zu Akonadi gehört. Auf der > CLI gibt es dazu den Befehl "baloosearch" für die Suche. Ich habe bisher um Gnome, KDE & Co. einen Bogen gemacht, weil ich keinen echten Bedarf dafür hatte und der Aufwand dem Nutzen nicht angemessen schien. Ich könnte meinen Standpunkt allerdings auch mal überdenken... :) Dein Anstoß ist insofern interessant, als das Ordnungssystem, die Suchsoftware und die (noch nicht existierende) Software zur Bestandspflege im Prinzip unabhängig sind. Ich bin nicht zwingend scharf darauf, alles selbst zu programmieren; im Prinzip besteht auch die Möglichkeit, nur die Software für die Verschlagwortung selbst zu machen und eine fertige Desktop-Suche für die Abfrage zu verwenden.
> Ich habe bisher um Gnome, KDE & Co. einen Bogen gemacht, > weil ich keinen echten Bedarf dafür hatte und der Aufwand > dem Nutzen nicht angemessen schien. Ich könnte meinen > Standpunkt allerdings auch mal überdenken... :) Du kannst Dich auch in Elasticsearch und JSON einarbeiten und ich kann Dir vorhersagen wie das enden wird. Was kannst Du denn schon mehr oder weniger gut? Der Thread lautet doch Biete Chimäre -- suche Mitstreiter .... oder willst Du jetzt doch alles allein machen? Dann einigt man sich z.B. auf eine gängige Programmiersprache, in diesem Fall Java wegen Plattformunabhängigkeit und jeder macht ein Modul fertig - das ist dann ein Guß ohne komplizierte Schnittstelleneinbindung, die sonst notwendig wäre. Alles was Du Dir so vorstellst wird sowieso nicht funktionieren - jedenfalls nicht in einem normalen Zeitrahmen. Daß das Ganze dann am Ende nicht perfekt sein wird ist auch klar; aber dann hat man wenigstens was zu Ende gebracht was halbwegs läuft anstatt sich komplett zu verzetteln .... und danach sieht's sowieso aus. Das war dann mal eine nette Übung; kommerziell gesehen ist das sowieso ein Rohrkrepierer - da würde ich gar nicht drüber nachdenken.
Beitrag #5507729 wurde von einem Moderator gelöscht.
Mark S. schrieb: > Mein Archiv ist einfach hierarchisch gegliedert. Okay. Das ist bei mir im Prinzip auch der Fall. > Die entscheidende Frage ist für mich hier die Wahl der > Begriffe, d.h. die Namensvergabe der Unterverzeichnisse. > Diese sollten so eindeutig und leicht merkbar wie irgend > möglich sein. Hmm. Hier scheinen mir zwei Unterschiede zu liegen. Zum einen: Eine Art "Unterverzeichnisse" (Rubriken) gibt es bei mir auch; die sind aber nur teilweise mit den tatsächlichen physischen Speicherorten identisch, da sind Freiheitsgrade und Konfigurationsmöglichkeiten geplant. Das scheint mir sinnvoll, weil das System auch funktionieren soll, wenn man gerade aufräumt und mehrere unterschiedlich sortierte Teilbestände hat. Zum anderen: Standardmäßig wird im Gesamtbestand gesucht; ich kann aber die Suche auch auf eine "Rubrik" beschränken (=in ein "virtuelles Unterverzeichnis" wechseln). Der Punkt ist: Ich KANN das tun, aber ich MUSS nicht. Wenn ich nicht wechsele, ist nur die Liste länger, in der ich herumscrollen und aus der ich auswählen kann. [...] > Beispiel: > hardwarearchiv/pub/components/active/ic/analogue/opa/ > semi_opa_ti_tle206x.pdf > Wie man sieht, kommen hier schnell tiefe Verzeichnisbäume > zu Stande. Ja, das kenne ich :) > Der Dateiname ist in einer bestimmten Weise aufgebaut um > technische Merkmale auszufiltern. Gut. Weitere Gemeinsamkeit. Das ist bei mir genauso. > Und schließt damit eine einfache alphabetische Suche > nach der Typenbezeichnung aus [...] Naja... das sehe ich nicht ganz so: Die Dateinamen werden bei mir nicht nur aus mehreren Feldern aufgebaut -- mein Finder KENNT diesen Aufbau und kann daher die Felder wieder trennen. Mein Finder WEISS also (anhand der Trennzeichenfolgen), welcher Teil des Filenamens die Typenbezeichnung, welcher der Hersteller und welches der Versionskenner ist. Im GUI ist das automatisch richtig zugeordnet. > Und dann verwende ich eine Menge Zeit, die mich > interessierenden Bereiche händisch möglichst konsequent > um zu benennen. Eine Sysiphusarbeit - Mein Testarchiv kennt ungefähr 3000 Typen. Ich würde schätzen, ich habe im Mittel vielleicht eine Minute je Typ investiert. Arbeit - ja, aber erträglich. Ich erhoffe mir noch eine Verbesserung, wenn es dafür vielleicht mal ein spezialisiertes Werkzeug gibt. > aber dieselbe müßte man auch bei der Pflege von Metadaten > leisten. Ja -- der Komfort meiner Lösung liegt nicht beim Erschließen (das muss man in beiden Fällen machen), sondern beim Wieder- finden. > Das funktioniert für mich nun seit etwa 15 Jahren so, > dieses Archiv umfaßt derzeit 13,9GB. Das ist ganz lustig; ich arbeite seit etwa einem Jahr an meinem System; das Testarchiv hat ca. 1.2GByte.
Mark S. schrieb: > Beispiel: > hardwarearchiv/pub/components/active/ic/analogue/opa/semi_opa_ti_tle206x .pdf Solch eine hirarchische Organisation ist nur bedingt sinnvoll, da sich viele Bauelemente an unterschiedlichen Stellen einsortieren ließen. Oder man hätte halt etliche Kopien. Mit symbolischen Links oder z.B. svn:externals kann man zwar echte Dateikopien vermeiden, sieht aber nicht auf die Schnelle, an welchen anderen Stellen Kopien liegen, was z.B. beim Aktualisieren von Datenblättern relevant wäre. Wo legt man einen einfachen Optokoppler ab? Wo legt man einen Optokoppler mit Schmitt-Trigger-Ausgang ab? Wo legt man einen für Linearbetrieb geeigneten Optokoppler ab? Wo legt man einen analogen Trennverstärker ab? Wo legt man einen kapazitiven Koppler ab? Wo legt man einen induktiven Koppler ab? Wo legt man einen Koppler mit EIA485-Leitungstreibern ab? Wo legt man einen Koppler mit integriertem DC/DC-Wandler ab? Und wo legt man all diese Koppler ab, wenn sie von demselben Hersteller sind?
Andreas S. schrieb: > Solch eine hirarchische Organisation ist nur bedingt > sinnvoll, da sich viele Bauelemente an unterschiedlichen > Stellen einsortieren ließen. Naja, der Witz ist: Das KANN man ja auch -- Hardlinks existieren schon lange. > Oder man hätte halt etliche Kopien. Mit symbolischen > Links oder z.B. svn:externals kann man zwar echte > Dateikopien vermeiden, Genau. Natürlich will man ein Werkzeug haben, das einen dabei unterstützt -- aber das ist ja kein Hexenwerk. > sieht aber nicht auf die Schnelle, an welchen anderen > Stellen Kopien liegen, was z.B. beim Aktualisieren von > Datenblättern relevant wäre. Brauche ich auch nicht. Eine "neue Version" eines Datenblattes ist in meinem System ein "anderes Datenblatt", wo im Namen zufällig derselbe Typ und derselbe Hersteller, aber ein anderes Datum steht. Das läuft rein auf der semantischen Ebene; eine "Versions- verwaltung" in dem Sinne gibt es nicht. Das war bis jetzt auch kein Problem; die Abfrage läuft zwar nach Typen, aber als Ergebnismenge werden alle Dateien in einer Liste präsentiert, bei denen das Typ-Feld passt. Bis jetzt werden also unterschiedlich alte Ausgaben desselben Datenblattes alle einzeln aufgelistet; man könnte da aber einen Filter vorsehen, wenn das Not tut. > Und wo legt man all diese Koppler ab, wenn sie von > demselben Hersteller sind? Völlig egal. Jeder "Aliasname" (=Hardlink) besteht aus Typ, Hersteller und Datum.
Vka schrieb: > Ich habe pro Projekt einen Datenblatt-Ordner. Da lege > ich die komplette Doku für einen Baustein ab, also: > - Datenblatt > - Reference Manual > - Errata > - Footprint > - Relevante Appnotes > - ggf. Tools, Firmware-Config Okay, kann man machen. > Wie würde das sinnvoll strukturiert in dein System > passen? Genauso, wie Du gesagt hast: Es gäbe sinnvollerweise ein Sammelverzeichnis "Projekte"; in diesem findet sich ein Unterverzeichnis für das konkrete Projekt, um das es gerade geht; darin beliebig viele weitere Unter- verzeichnisse. Alle Dokumente, die Du im Projekt brauchst, bekommen einen Hardlink. Wenn Du das Projektverzeichnis auf USB-Stick kopierst oder auf CD brennst, sind dort sämtliche verlinkten Dokumenten gespeichert. > Wie verwalte ich verschiedene Versionen? Gar nicht -- Versionen gibt's nicht. Wenn Du auf ein bestimmtes Datenblatt verlinkst, dann ist auf GENAU DIESE Datei verlinkt. Mein Projekt "SubCat" ist ein "subject catalog", ein Schlagwortkatalog -- keine komplette Dokumentenverwaltung. > Z.B. hat ein Mikrocontroller xyz-B zu xyz-C Typ ein > anderes Errata und evtl. neue Register. Du kannst zusammengehörige Dateien in dasselbe Unter- verzeichnis stopfen, dann siehst Du beim Blick in das Verzeichnis, dass sie zusammengehören. > Wie kann ich festlegen welcher Datenbestand zu welchem > Projekt gehört? Indem Du für jedes Projekt ein eigenes Projektverzeichnis anlegst. > Z.B. brauche ich zur Wartung eines alten Projekts alle > Daten zum Hardware Stand von damals, neue Infos will > ich dann nicht bekommen. Genau. Hardlinks leisten genau das.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.