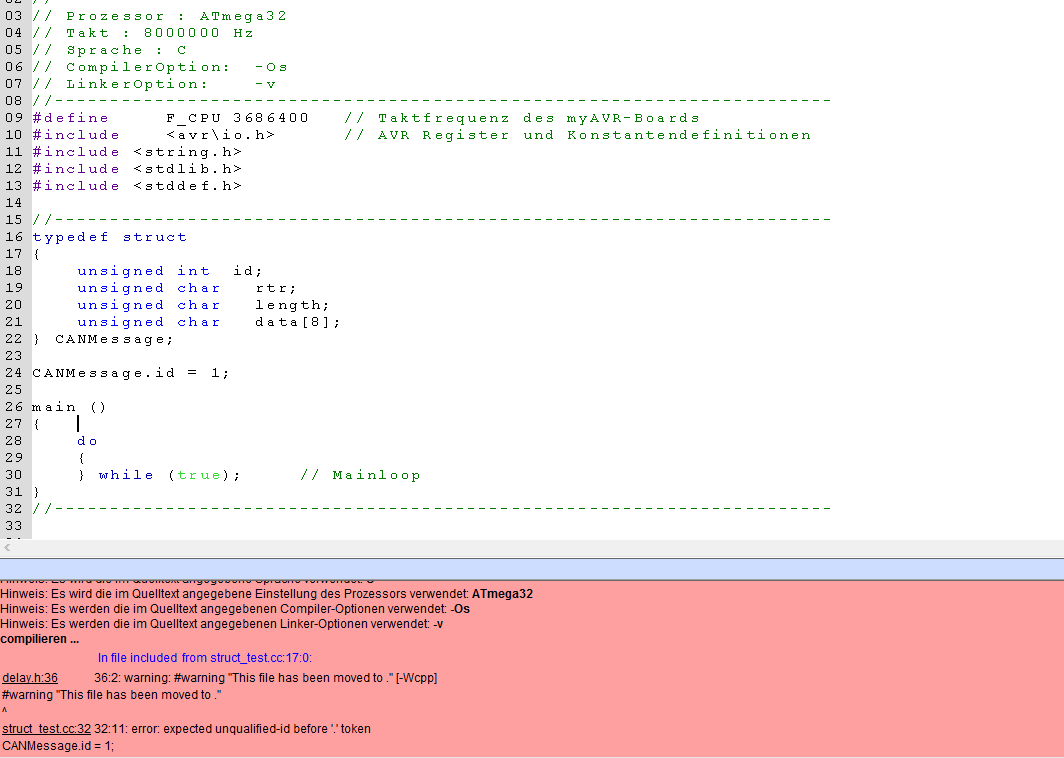
Hallo zusammen,
ich bin mit meinem Latein am Ende, vielleicht weiß hier noch jemand
einen Rat.
Ich möchte in mein Projekt ein simples Struct einbringen, jedoch fährt
mir beim Übersetzen ständig der Compiler (GCC 4.7.2) in die Parade mit
der Meldung: "error: expected unqualified-id before '.' token".
Dabei ist doch hieran nichts auszusetzen oder?
Nein, das ist keine unzulässige Initialisierung, sondern das ist eine
Typdefinition und dann der Versuch, dieser Typdefinition ein Wert
zuzuweisen.
Also so etwas wie
Du solltest dich mal intensiv mit der Frage auseinandersetzen, wie die
Struktur eines C-Programms aussieht.
Insbesondere damit, was in C außerhalb von Funktionen passieren darf
bzw. zwingend innerhalb von Funktionen passieren muß.
Rufus Τ. F. schrieb:> Nein, das ist keine unzulässige Initialisierung, sondern das ist eine> Typdefinition und dann der Versuch, dieser Typdefinition ein Wert> zuzuweisen.
ich verstehe unter Initialisierung das erste Zuweisen eines Wertes zu
einer Variablen.
Und genau das hat er - wie Du auch vollkommen richtig erkannt hast -
versucht.
Was ist dann am Begriff "unzulässige Initialisierung" falsch?
Hätte nämlich der Threadersteller Typdefinition mit Deklaration nicht
fälschlicherweise gleichgesetzt - hätten wir an seiner Fehlerstelle eine
Initialisierung.
... und ich hätte es wohl so geschrieben :-)
typedef struct
{
unsigned int id;
unsigned char rtr;
unsigned char length;
unsigned char data[8];
} CANMessage_t;
CANMessage_t CANMessage = { //init mit Defaultwerte
0x1
, 0
, 8
, {0x1, 0x2, 0x3, 0x4, 0x5, 0x7, 0x8}
};
...
int main(){
...
CANMessage.id = 0x75;
}
Hmm, ist es Absicht, dass das IDE Bit in dem Typ fehlt?
Dass das Bit fehlt, ist egal, es war nur ein Beispiel. Habe mit CAN
nichts zu tun. Aber danke euch, der Fehler war natürlich, dass ich die
Zuweisung nicht im Main gemacht habe. Oh je...
Jetzt funzt es natürlich!
Hier geht es um die Wurst, genauer wieder mal um die Salami.
Wer hat denn behauptet, es wäre ein C-Programm? :D
Der Filename ist struct_test.cc und es gibt ein Compilerflag -Wcpp,
sieht man im Bild.
Walter K. schrieb:> Rufus Τ. F. schrieb:>> Nein, das ist keine unzulässige Initialisierung, sondern das ist eine>> Typdefinition und dann der Versuch, dieser Typdefinition ein Wert>> zuzuweisen.>> ich verstehe unter Initialisierung das erste Zuweisen eines Wertes zu> einer Variablen.
Das ist es aber eigentlich nicht. Zuweisung und Initialisierung sind
zwei verschiedene Dinge. Initialisierung passiert bei Erstellen einer
Variable, Zuweisung danach:
1
inti=4;// Initialisierung
2
i=5;// Zuweisung
Initialisierungen sind außerhalb von Funktionen zulässig, Zuweisungen
nicht.
Andreas W. schrieb:> ... und ich hätte es wohl so geschrieben :-)>> typedef struct> {> unsigned int id;> unsigned char rtr;> unsigned char length;> unsigned char data[8];> } CANMessage_t;>> CANMessage_t CANMessage = { //init mit Defaultwerte> 0x1> , 0> , 8> , {0x1, 0x2, 0x3, 0x4, 0x5, 0x7, 0x8}> };
Ich so:
Rolf M. schrieb:> Ich so:
Das setzt halt C99 oder neuer voraus, was durchaus auch 2018 noch nicht
unbedingt überall möglich ist. Die andere Variante bedeutet weniger
Tipparbeit und lässt sich sowohl von fossilen C89-Compilern als auch
neueren Compilern gleichermaßen übersetzen.
Rufus Τ. F. schrieb:> Rolf M. schrieb:>> Ich so:>> Das setzt halt C99 oder neuer voraus, was durchaus auch 2018 noch nicht> unbedingt überall möglich ist. Die andere Variante bedeutet weniger> Tipparbeit und lässt sich sowohl von fossilen C89-Compilern als auch> neueren Compilern gleichermaßen übersetzen.
Ist aber eben nicht so übersichtlich. Man muss sich immer erst die
Typdefinition ansehen, um zu wissen, welches Element jetzt welchen Wert
bekommt. Solange das wie oben direkt untereinander steht, ist das ja ok,
aber das ist ja meist nicht der Fall.
Ich konnte mir bisher glücklicherweise immer Compiler raussuchen, die
nicht auf dem Stand von vor knapp 30 Jahren stehen geblieben sind.
Rolf M. schrieb:> Ist aber eben nicht so übersichtlich.
Ist halt so. Einen Tod muss man sterben.
Statt 30 Jahren sind es übrigens nur 18. Vor dem Jahr 2000 wirst Du kaum
an einen C99-konformen Compiler gekommen sein, und die ersten produktiv
tatsächlich einsetzbaren Varianten dürften noch 'ne Weile länger
gedauert haben.
Du brauchst nicht zwingend einen Typen generieren, empfiehlt sich aber.
Wobei, ... ich bin mitlerweile wie Linus der Meinung, dass ein struct
möglichst nicht per typedef camouflaged werden sollte.
Das ist eine anonyme Strukturdeklaration, d.h. so etwas kann man
nirgendswo z.B. zur Übergabe an Funktionen o.ä. weiterverwenden.
Besser wäre es schon, der Struktur selbst einen Namen zu geben.
1
structcanmessage_t
2
{
3
unsignedintid;
4
unsignedcharrtr;
5
unsignedcharlength;
6
unsignedchardata[8];
7
}CANMessage;
Dann nämlich kann man Strukturdeklaration und Variablendefinition auch
voneinander trennen (und die Strukturdeklaration gegebenenfalls in eine
Headerdatei auslagern):
Rufus Τ. F. schrieb:> Rolf M. schrieb:>> Ist aber eben nicht so übersichtlich.>> Ist halt so. Einen Tod muss man sterben.>> Statt 30 Jahren sind es übrigens nur 18.
Vor 29 Jahren kam C89 raus. Wenn der Compiler nur das kann, ist es daher
der Stand von vor knapp 30 Jahren.
> Vor dem Jahr 2000 wirst Du kaum an einen C99-konformen Compiler gekommen> sein, und die ersten produktiv tatsächlich einsetzbaren Varianten dürften> noch 'ne Weile länger gedauert haben.
Es gab schon Jahre vorher entsprechende Drafts, so dass es den
Compiler-Herstellern durchaus möglich war, früh genug mit der
Entwicklung anzufangen, um mit der Freigabe von C99 schon einen Großteil
der Feature zu unterstützen. Dass es eine signifikante Zahl von
Compilern gibt, die das selbst im Jahre 2018 noch nicht geschafft haben,
ist peinlich, vor allem bei Compilern, die richtig Geld kosten.
Ich sage es immer wieder: C89/C90 ist keine ANSI- oder ISO-Norm. Die
wurden mit Erscheinen von C99 für ungültig erklärt und vollständig durch
dieses ersetzt.
Achim S. schrieb:> Wobei, ... ich bin mitlerweile wie Linus der Meinung, dass ein struct> möglichst nicht per typedef camouflaged werden sollte.
Ich mache in der Regel auch kein typedef dafür.
Rufus Τ. F. schrieb:> Das ist eine anonyme Strukturdeklaration, d.h. so etwas kann man> nirgendswo z.B. zur Übergabe an Funktionen o.ä. weiterverwenden.
Ja, das ist der Nachteil. Ich benutze sowas aber durchaus auch, wenn ich
es nur an einer Stelle brauche. In C++ benutze ich es manchmal, um
innerhalb einer Klasse die Membervariablen zu gruppieren. Das gibt dann
so eine Art eigener Namespace innerhalb der Klasse. Dazu braucht der Typ
nicht unbedingt einen Namen.
Rolf M. schrieb:> Ich so:
Das geht aber in C++ nicht, um das es hier vermutlich geht:
.. schrieb:> Der Filename ist struct_test.cc und es gibt ein Compilerflag -Wcpp,> sieht man im Bild.
Man kann sich mit Konstruktoren, und Call-Chaining behelfen, ist aber
auch gewöhnungsbedürftig:
Dr. Sommer schrieb:> Rolf M. schrieb:>> Ich so:>> Das geht aber in C++ nicht, um das es hier vermutlich geht:
Bei GCC geht's auch in C++, ist aber natürlich nicht standardkonform.
Merkwürdigerweise bricht er selbst bei -std=c++17 -pedantic -Wall
-Wextra nicht mit Fehlermeldung ab, sondern warnt nur, dass der
Konstrukt nicht erlaubt ist.
> Man kann sich mit Konstruktoren, und Call-Chaining behelfen, ist aber> auch gewöhnungsbedürftig:
Ja, ist schade, dass C++ keine designated initializers kennt. Ich finde,
sie verbessern die Übersichtlichkeit deutlich.
mh schrieb:> Ab C++20:
Ah, ok. Mich wundert allerdings das:
1
structA{intx;inty;intz;};
2
Aa{.y=2,.x=1};// error; designator order does not match declaration order
3
Ab{.x=1,.z=2};// ok, b.y initialized to 0
Warum gibt es einen Zwang, die Reihenfolge der Deklaration einzuhalten?
Ein Vorteil wäre doch gerade, dass ich die Elemente über die Namen
unhabhängig von der Deklarationsreihenfolge initialisieren kann. Ich
müsste nicht zwingend die Reihenfolge der Elemente kennen. Wenn ich die
Namen weiß, würde das reichen.
Soweit ich weiß, hat C so eine merkwürdige Einschränkung nicht.
Rolf M. schrieb:> Warum gibt es einen Zwang, die Reihenfolge der Deklaration einzuhalten
Wenn die Elemente nicht-triviale Konstruktoren haben, spielt die
Reihenfolge eine Rolle. Da diese von der Definition der Klasse (struct
und Klasse sind identisch bis auf default visibility) vorgegeben ist,
wäre es für den Leser verwirrend wenn die geschriebene Folge sich von
der tatsächlichen unterscheiden würde.
Dr. Sommer schrieb:> Da diese von der Definition der Klasse vorgegeben ist,
PS: da der Destruktor die Destruktoren der Elemente in exakt umgekehrter
Reihenfolge aufrufen muss, muss die Reihenfolge der Konstruktoren fix
sein (und ist daher durch die Definition der Klasse vorgegeben), da der
Destruktor ja sonst nicht weiß, mit welcher Reihenfolge die
Initialisierung jetzt tatsächlich erfolgt ist.
Dr. Sommer schrieb:> Wenn die Elemente nicht-triviale Konstruktoren haben, spielt die> Reihenfolge eine Rolle.
Aber davon sehe ich im Eröffnungspost rein garnix.
Dort haben wir es mit einem stinknormalen struct zu tun, wo ein unsigned
int und ein paar unsigned char's enthalten ist.
Und daß der TO offenbar nicht verstanden hat, was der Unterschied
zwischen Typdeklarationen, Variablen und Zuweisungen ist, hat ihn trotz
ausdrücklicher Fehlermeldung nicht stutzen lassen.
CANMessage.id = 1;
"error: expected unqualified-id before '.' token".
Also, er hätte einen bereits bekannten Identifier (sprich ne Variable)
erwartet, bevor er den Punkt zu fressen bekommen hat.
Ich sag's mal wieder: Das Wort typedef ist derart MISSVERSTÄNDLICH, daß
man es niemals hätte einführen sollen. Wenn schon, dann hätte man es
rename nennen sollen.
Normal geht das ja so:
struct T_MeinKrempel
{ int A;
char B;
double X;
char emil[10];
};
und
struct T_MeinKrempel Karlheinz;
KarlHeinz.A = 4711;
Und wenn man sich dran gewöhnt, bei Typen_ ein T oder T
voranzustellen, dann fällt einem gelegentlich auch auf, was der TO glatt
übersehen hat.
Das Nachstellen wie KarlHeinz_t scheint mir da deutlich weniger
auffällig und nützlich zu sein, weil man beim Lesen zunächst die
Wort-Anfänge anschaut. Das ist fast dasselbe wie die Diskussion über die
Anordnung öffnender Klammern.
W.S.
W.S. schrieb:> Ich sag's mal wieder: Das Wort typedef ist derart MISSVERSTÄNDLICH, daß> man es niemals hätte einführen sollen. Wenn schon, dann hätte man es> rename nennen sollen.
Das ist genauso blödsinnig. Der originale Name ist dadurch ja nicht weg.
Ein sinnvolleres Wort wäre z.B. 'alias' gewesen.
W.S. schrieb:> Das Nachstellen wie KarlHeinz_t scheint mir da deutlich weniger> auffällig und nützlich zu sein,
Ich gehe da den Weg des kleineren Widerstandes, und schließe mich an den
etablierten Standard an, der ein kleines "_t" anhängt.
(Z.B. bei uint8_t & Co.)
Ich habe keine Probleme damit, beim Lesen Suffixe zu erkennen, und ich
halte C-Code, der unterschiedliche Konventionen wüst mischt für
minderwertig, potentiell fehlerträchtig und nur mit Spitzzangen
anzufassenden Murks.
Rufus Τ. F. schrieb:> W.S. schrieb:>> Das Nachstellen wie KarlHeinz_t scheint mir da deutlich weniger>> auffällig und nützlich zu sein,>> Ich gehe da den Weg des kleineren Widerstandes, und schließe mich an den> etablierten Standard an, der ein kleines "_t" anhängt.
Ich finde das auch nicht schlechter zu lesen. Bekanntlich sieht man beim
Lesen nicht nur den Anfang, sondern auch das Ende des Wortes zuerst.
Deshalb gibt's ja diese Texte, bei denen von jedem Wort alle Buchstaben
außer dem ersten und dem letzten zufällig vertauscht sind, die man
trotzdem noch flüssig lesen kann.
W.S. schrieb:> Aber davon sehe ich im Eröffnungspost rein garnix
Um den ging es auch nicht. C++ hat bei der benannten Initialisierung
keine Ausnahmen für structs die nur aus built-in Typen bestehen. Das
würde es nur noch komplizierter machen...
W.S. schrieb:> Wenn schon, dann hätte man es rename nennen sollen
Typaliase sind essentiell. z.B. für Typen wie off_t oder size_t oder
time_t. Nur das Schlüsselwort typedef an sich ist blöd gewählt. Aber das
ist nicht das einzige Element von C bei dem das so ist...
W.S. schrieb:> Und wenn man sich dran gewöhnt, bei Typen_ ein T oder T voranzustellen,> dann fällt einem gelegentlich auch auf, was der TO glatt übersehen hat.
Ich würde nicht den kompletten Code mir t oder T einsauen, nur um so
einen trivialen Fehler zu vermeiden. In strenger typisierten Sprachen
nutzt man noch viel mehr Typen; da ist auch nicht alles voller _t's. Das
ist mehr so eine Angewohnheit von C-Programmierern, für die es etwas
besonderes ist wenn man mal was anderes als void* oder int nutzt...
Bsp.:
C++ hat std::string, Java hat Java.lang.String, Ruby hat String... kein
String_t in Sicht.
Dr. Sommer schrieb:> Bsp.:> C++ hat std::string, Java hat Java.lang.String, Ruby hat String... kein> String_t in Sicht.
Ich denke, in Standard C steht das _t für typedef. Es gibt ja z.B.
einerseits char, andererseits wchar_t. Letzteres ist ein typedef
(allerdings nur in C. In C++ ist es dann ein Schlüsselwort).
Ähnlich sieht es bei den ganzen anderen Typen aus den Standard-Headern
aus (size_t, int16_t u.s.w.).
Rolf M. schrieb:> Ich denke, in Standard C steht das _t für typedef.
Ja. Ich finde es aber ziemlich unnötig. Der Sinn eines Alias ist ja
eigentlich, dass man ihn nicht als solches erkennt und er sich genau wie
ein "richtiger" Typ verhält.
Typnamen haben in C eine eigentümliche syntaktische Rolle, ein
Geburtsfehler der Deklarationssyntax. Ihnen Namen zu geben, die sie
eindeutig abheben, vermeidet unverständliche Fehlermeldungen.
A. K. schrieb:> Ihnen Namen zu geben, die sie> eindeutig abheben, vermeidet unverständliche Fehlermeldungen.
Wird das denn überhaupt irgendwo im großen Stil konsequent durchgezogen?
Bei Gtk+ heißt es auch GtkWidget und nicht GtkWidget_t, und äquivalent
bei den 1000 weiteren darin definierten Typen.
Solche Syntaxfehler sind doch halb so schlimm, die finden nur absolute
Anfänger nicht sofort. Das "_t" bei Typ-Aliasen scheint üblich zu sein,
da bei anderen Typen immer das "struct" bzw. "enum" davor steht und das
"_t" als Ersatz bei Aliasen steht. In allen anderen Sprachen, inklusive
C++, ist ein Typ einfach ein Typ und gleich zu verwenden unabhängig
davon ob Alias oder nicht, weshalb dort auch nie "_t" genutzt wird.
Selbst im heißgeliebten Pascal gibt es kein cardinal_t, oder?
Dr. Sommer schrieb:> In allen anderen Sprachen, inklusive> C++, ist ein Typ einfach ein Typ und gleich zu verwenden unabhängig> davon ob Alias oder nicht
Was meinst Du damit (bezogen auf C)?
Dr. Sommer schrieb:> Achim S. schrieb:>> Was meinst Du damit (bezogen auf C)?>> Dass das "_t" ziemlich überflüssig ist.
Ich meine, was ist bei C diesbezüglich anders als bei C++ (dass Du
aufzählst)?
Achim S. schrieb:> Ich meine, was ist bei C diesbezüglich anders als bei C++ (dass Du> aufzählst)?
In C muss man so schreiben:
1
structFoo{
2
};
3
4
typedefstructFooFoo;
5
typedefstructFooFoo_t;
6
7
enumBar{BarA};
8
9
intmain(){
10
structFoof1;// Aha, ein struct
11
enumBarb;// Aha, ein enum
12
Foo_tf2;// Aha, ein Typ-Alias, d.h. struct oder enum
13
Foof3;// Oh nein, weder struct noch enum noch typedef, was kann es sein?
14
intc;// Oh nein, weder struct noch enum noch typedef, was kann es sein?
15
}
Um der "Verwirrung" vorzubeugen nutzt man hier ein "_t".
In C++ sind "struct" und "enum" überflüssig, und somit kann man das "_t"
auch gleich loswerden:
1
structFoo{
2
};
3
4
enumBar{BarA};
5
6
intmain(){
7
Foof1;// Irgendein Typ.
8
Barb;// Irgendein Typ.
9
intc;// Irgendein Typ.
10
}
Hier sind alle Typen einheitlich nutzbar und das zusätzliche Klimbim mit
"struct", "enum" und "_t" entfällt komplett, wie auch in anderen
Sprachen. Das kann man in C auch haben indem man für alle structs und
enums gleichnamige Aliase definiert (typedef) und auch das "_t"
weglässt. Bei size_t & Konsorten muss man es halt noch mitschleppen.
Dr. Sommer schrieb:> In C muss man so schreiben:> struct Foo {> };>> typedef struct Foo Foo;>> Foo f3; // Oh nein, weder struct noch enum noch typedef, was
Geht. Wo ist da das Problem?
A. K. schrieb:> Geht. Wo ist da das Problem?
Meine Aussage ist, dass das kein Problem ist. Manche Leute finden diese
Zeile aber unverständlich, weil sie mangels "struct", "enum" oder "_t"
nicht wissen was "Foo" hier ist:
Rufus Τ. F. schrieb:> Ich gehe da den Weg des kleineren Widerstandes, und schließe mich an den> etablierten Standard an, der ein kleines "_t" anhängt.
A. K. schrieb:> Dann mach es doch so wie du es für sinnvoll hältst und lass andere> Leute> es so machen, wie sie es für sinnvoll halten.
Dann lass mich auch hier schreiben, was ich für sinnvoll halte.
Dr. Sommer schrieb:> Manche Leute finden diese Zeile aber unverständlich, weil sie mangels> "struct", "enum" oder "_t" nicht wissen was "Foo" hier ist:
Nein. Das ist Dein Problem des Textverständnisses.
Ich bezog mich darauf, daß ich, wenn überhaupt, "_t" anhänge und nicht
"T_" voranstelle, weil das Anhängen von "_t" im Sprachstandard
gebräuclich ist und nicht das angeblich besser lesbarere Voranstellen
von "T_".
Dr. Sommer schrieb:> Ja, und warum überhaupt?
Kindchen, weil es der Sprachstandard bei Typen wie size_t, uint8_t
etc. vorgibt.
Wenn Dir das zu komplex ist, halt' Dich doch einfach aus der Diskussion
raus.
Danke.
Rufus Τ. F. schrieb:> Kindchen, weil es der Sprachstandard bei Typen wie size_t, uint8_t> etc. vorgibt.
Es ging um eigene Typen. Dass man das bei size_t nicht ändern kann,
hätte der aufmerksame Leser bemerkt:
Dr. Sommer schrieb:> Bei size_t & Konsorten muss man es halt noch mitschleppen.
Dr. Sommer schrieb:> Dass man das bei size_t nicht ändern kann, hätte der aufmerksame Leser> bemerkt:
Du hast immer noch nicht verstanden, was ich geschrieben habe. Lies es
doch einfach nochmal durch. Und nochmal. Vielleicht verstehst Du es ja
dann.
Und, wichtig, berücksichtige das, worauf ich mich bezogen habe.
Vielleicht fällt dann ja irgendwann auch bei Dir irgendeine kleine
obsolete Währungseinheit.
Rufus Τ. F. schrieb:> Ich gehe da den Weg des kleineren Widerstandes, und schließe mich an den> etablierten Standard an, der ein kleines "_t" anhängt.>> (Z.B. bei uint8_t & Co.)
War es so gemeint, dass du bei uint8_t wie üblich das _t anhängst? Weil
das gar nicht anders geht, bin ich davon ausgegangen dass du das
Anhängen auf eigene Typ-Namen beziehst. Naja, schade dass man hier auch
bei komplett sachlichen Diskussionen sofort für dumm verkauft wird.
Dr. Sommer schrieb:> In C++ sind "struct" und "enum" überflüssig, und somit kann man das "_t"> auch gleich loswerden:struct Foo {> };>> enum Bar { BarA };>> int main () {> Foo f1; // Irgendein Typ.> Bar b; // Irgendein Typ.> int c; // Irgendein Typ.> }
naja, Du brauchst in C doch auch nicht benamen, also
1
typedefstruct{}Foo;/* in C */
2
structFoo{};/* in C++ */
Dass jemand eine Struktur benamt und dann (parallel) einen typedef davon
anlegt ist meist sinnlos. Höchstens als Vorwärtsdeklaration.
Das Problem ist doch (nach Torvaldson) ein anderes: Wenn ich eine
Instanz von Foo auf den Stack lege, sehe ich nicht, ob es ein Basis-Typ
ist, oder eine Struktur von potentiell riesiger Größe. Deshalb möglichst
kein Typedef für ein struct.
Rufus Τ. F. schrieb:> Kindchen,...
kannst du auch mal ohne Animositäten auskommen?
Rolf M. schrieb:> Ein sinnvolleres Wort wäre z.B. 'alias' gewesen.
Ja, einverstanden. So ziemlich alles außer typedef hätte es getan.
Dr. Sommer schrieb:> struct Foo f1; // Aha, ein struct> enum Bar b; // Aha, ein enum
Tja. An dieser Stelle haben wir es MAL WIEDER mit einem Geburtsfehler
von C zu tun. Eigentlich ist der Zwang zum Hinschreiben von struct bei
Variablendeklarationen auch logisch völlig überflüssig, denn der Name
eines zuvor definierten Variablentyps sollte dem Compiler ausreichen, um
in seiner Liste nachzusehen, was sich dahinter verbirgt.
Ich nehme an, daß aus genau diesem Grunde viele Leute sich den
gedankenlosen Gebrauch von typedef angewöhnt haben. Vor geraumer Zeit
hatte sich deswegen hier jemand vergeblich darüber gewundert, daß er bei
einem struct für eine verkettete Liste es nicht geschafft hatte, Zeiger
für Vorgänger und Nachfolger in den struct zu kriegen. Logisch: sein
namenloser struct im typedef hat ja eben keinen Namen...
Und nochwas:
Da ich hauptsächlich in Pascal programmiere, sind mir Typbezeichner wie
TLabel weitaus lesbarer als sowas wie Label_t. Dabei ist es mir ziemlich
unerheblich, was Rufus besser lesen kann. Es gibt ja auch Leute, die
behaupten, daß man öffnende Klammern irgendwo am Zeilenende besser zu
deren schließendem Pendant am Zeilenanfang lesen könne.
Ich bezweifle auch, daß so ein angehängtes "_t" in irgend einem
Sprachstandard von C jemals als Typ-Kennzeichen festgeschrieben ist. Es
ist lediglich eine Art Gewohnheits-Konvention - jedenfalls in C (und C++
mache ich nicht).
W.S.
Achim S. schrieb:> Das Problem ist doch (nach Torvaldson) ein anderes: Wenn ich eine> Instanz von Foo auf den Stack lege, sehe ich nicht, ob es ein Basis-Typ> ist, oder eine Struktur von potentiell riesiger Größe. Deshalb möglichst> kein Typedef für ein struct.
Wo ist da der unterschied zwischen struct foo, foo_t oder Foo?
Achim S. schrieb:> Dass jemand eine Struktur benamt und dann (parallel) einen typedef davon> anlegt ist meist sinnlos. Höchstens als Vorwärtsdeklaration.>> Das Problem ist doch (nach Torvaldson) ein anderes: Wenn ich eine> Instanz von Foo auf den Stack lege, sehe ich nicht, ob es ein Basis-Typ> ist, oder eine Struktur von potentiell riesiger Größe. Deshalb möglichst> kein Typedef für ein struct.
Ersteres wird zumeist gemacht, um beim Deklarieren von Variablen das
"struct" weglassen zu können. Das ist für mich durchaus nachvollziehbar.
Letzteres ist eigentlich gar kein Problem an sich. Wenn jemand meint,
einen Riesenblob auf dem Stack anlegen zu müssen, dann ist es völlig
wurscht, ob er nun "struct" vor den Typbezeichner schreiben muß oder
nicht. Das hat mit typedef rein garnichts zu tun.
Nein, das Problem ist die mickrige Argumentverwaltung und die ebenso
mickrige Stringverwaltung in C. Argumente entweder als Kopie in voller
Größe oder als Zeiger - und Strings nur als simple Arrays. Nix
eleganteres vorhanden. So ein Komfort wie in Pascal ist in C unbekannt.
Beliebtetes Stichwort bisher: Pufferüberlauf auf dem Stack, gelle? Dabei
werden huge strings mittlerweile (in PC-Gefilden) im Heap geführt und
belasten deshalb nicht mehr den Stack.
Also das "Problem nach Torvaldson" ist eigentlich keines.
W.S.
W.S. schrieb:> Tja. An dieser Stelle haben wir es MAL WIEDER mit einem Geburtsfehler> von C zu tun.
Das ist schlecht möglich, denn zum Zeitpunkt der Geburt von C gab es
überhaupt kein typedef, keine präfixfreien Namen für eigene Typen. Das
kam erst viel später, allerdings noch vor K&R.
Mit Blick auf die Syntax ist auch nachvollziehbar, weshalb es keine
selbstständigen Typnamen gab. Die Einführung von typedef brach mit einer
vorher formal leidlich sauberen Syntax (sauber != schön oder gut).
Der eigentliche Geburtsfehler liegt darin, dass Deklarationen durch
einen Typnamen eingeleitet werden, statt durch sowas wie dcl, var, ...
A. K. schrieb:> Der eigentliche Geburtsfehler liegt darin, dass Deklarationen durch> einen Typnamen eingeleitet werden, statt durch sowas wie dcl, var, ...
Du hast das ab C++11 relevante"auto" vergessen ;-)
mh schrieb:> Wo ist da der unterschied zwischen struct foo, foo_t oder Foo?
1
structfoomyFoo;
2
foo_tmyFoo;
3
FoomyFoo;
4
5
DoWithFoo(myFoo);
Bei DoWithFoo gibt's kein Unterschied. Aber im Kontext oder spätestens
mit Cursor auf myFoo, erkenne ich bei erster Version, dass es ein Struct
ist. Das sind Torvaldsons Bedenken, die ich für unseren Code seit etwa
einem Jahr teile.
Das ist aber ein separates Thema.
Unabhängig davon sollte man in C nur eine Form verwenden, und nicht ein
benamtes "struct foo{};" und "typedef struct foo foo" nochmals parallel,
egal ob letzteres mit oder ohne Fräfix.
W.S. schrieb:> Ich bezweifle auch, daß so ein angehängtes "_t" in irgend einem> Sprachstandard von C jemals als Typ-Kennzeichen festgeschrieben ist.
Da zeigt sich, daß Du mal wieder keine Ahnung von C hast. Die von mir
hier im Thread bereits ad nauseam wiederholten, dem Standard
entstammenden Beispiele muss ich jetzt nicht nochmal wiederkäuen.
Und wer sich so hartnäckig dem Verstehen von Texten verweigert, wie Du
oder "Dr. Sommer" es tun, und hartnäckig etwas in Texte
hineininterpretieren, was ich nie geschrieben habe, dem kann ich dann
auch nicht weiterhelfen.
Ein letztes Mal:
Ich erwähnte das Anhängen von "_t" als standardkonform und sowieso
schon üblich, und lehnte deswegen den Mischmasch mit einer anderen
Konvention (dem Voranstellen von "T_", wie hier im Thread vorgeschlagen)
ab.
Daraus abzuleiten, wie und was ich lesen und verstehen könnte, grenzt an
Unverschämtheit.
Achim S. schrieb:> mh schrieb:>> Wo ist da der unterschied zwischen struct foo, foo_t oder Foo?> struct foo myFoo;> foo_t myFoo;> Foo myFoo;>> DoWithFoo(myFoo);>> Bei DoWithFoo gibt's kein Unterschied. Aber im Kontext oder spätestens> mit Cursor auf myFoo, erkenne ich bei erster Version, dass es ein Struct> ist. Das sind Torvaldsons Bedenken, die ich für unseren Code seit etwa> einem Jahr teile.
Ich sehe den Unterschied nicht. Wenn man nicht weiß, was Foo ist, weiß
man auch nicht was foo_t oder struct foo ist und muss nachgucken. Oder
gibt es einen magischen Mechanismus, der es möglich macht die
Deklaration von struct foo auswendig zu kennen, die von Foo aber nicht?
In jedem Fall zeigt mir der Debugger (gdb) und/oder die IDE
(vim,kdevelop,qt creator,emacs) den Typ und die Deklaration von myFoo
und DoWithFoo.
mh schrieb:> Oder> gibt es einen magischen Mechanismus, der es möglich macht die> Deklaration von struct foo auswendig zu kennen, die von Foo aber nicht?
OK, dass war ein Missverständnis. Wir (Linus und ich ;-) vertreten die
Ansicht, nur skalare und Pointer (also maximal ~8 Byte) per Typedefs zu
aliasen. Für eine Timerbreite, Counter-Umfang, Functionpointer, einen
Handler, u8/16/32 etc. ... .
So dass für "Foo myFoo" klar ist, dass es kein struct ist (weder groß
noch klein).
Achim S. schrieb:> mh schrieb:>> Oder>> gibt es einen magischen Mechanismus, der es möglich macht die>> Deklaration von struct foo auswendig zu kennen, die von Foo aber nicht?>> OK, dass war ein Missverständnis. Wir (Linus und ich ;-) vertreten die> Ansicht, nur skalare und Pointer (also maximal ~8 Byte) per Typedefs zu> aliasen. Für eine Timerbreite, Counter-Umfang, Functionpointer, einen> Handler, u8/16/32 etc. ... .>> So dass für "Foo myFoo" klar ist, dass es kein struct ist (weder groß> noch klein).
Ok jetzt habe ich verstanden was du sagen willst. Es ergibt aber immer
noch keinen Sinn. Was bringt es zu wissen, dass myFoo kein struct ist,
ohne zu wissen was es wirklich ist. Der Unterschied zwischen u8 und
Funktionspointer ist irgendwie ... wichtig. Wenn man nicht weiß was Foo
ist, muss man nachgucken wie es definiert ist und dann kann es doch
problemlos ein struct sein.
Rufus Τ. F. schrieb:> Ein letztes Mal:>> Ich erwähnte das Anhängen von "_t" als standardkonform und sowieso> schon üblich,
Das mit dem "sowieso schon üblich" ist von allen Seiten unbestritten.
Aber deine Behauptung, es sei etwas standardkonform ist FALSCH. Zeige
mir mal den Standard, in dem so etwas festgeschrieben ist. Den gibt es
nämlich nicht. Du stellst wieder mal unhaltbare Behauptungen auf.
Erzähle mir nicht, was ein Standard ist und was nicht!
Und deine wiederkehrenden Behauptungen, "daß Du mal wieder keine Ahnung
von C hast" ist eine Beleidigung. Abgesehen davon ist sie falsch.
Merkst du eigentlich, daß du mit deinem Insistieren hier nur Unfrieden
stiftest?
Nein, Tatsache ist, daß dieses "_t" lediglich eine mehr oder weniger
verbreitete Üblichkeit ist. Nicht mehr und nicht weniger. Aber das trägt
rein garnichts zum eigentlichen Thema bei.
Achim S. schrieb:> OK, dass war ein Missverständnis. Wir (Linus und ich ;-) vertreten die> Ansicht, nur skalare und Pointer (also maximal ~8 Byte) per Typedefs zu> aliasen.
Also im Klartext, daß du eine künstliche Grenze bei etwa 8 Bytes
einziehen möchtest, um gedankenloses Anordnen von größeren Dingen auf
dem Stack zu vermeiden? Und das dadurch, daß man bei größerem Zeug
struct davorschreiben muß und deshalb von seinem Ansinnen abgehalten
wird?
Das würde bedeuten, daß jemand, der sich daran halten will, diesen
Umstand bereits kennen und verstehen müßte und folglich ohnehin sich die
Frage bereits gestellt haben würde, ob das "Ding" denn nicht zu groß für
den Stack sei.
Mir kommt so etwas viel zu aufgesetzt vor. Weitaus wichtiger ist es
doch, daß eine Quelle gut leserlich und leicht erfaßbar ist, aber das
ist bei all dem, was das Beachten von weiteren zusätzlichen aufgesetzten
Üblichkeits-Regeln erfordert, kontraproduktiv.
Es ist mMn nichts anderes als das Aufstellen von weiteren überflüssigen
Fettnäpfchen - um die man dann auch noch herumeiern muß, um nicht
hineinzutreten.
W.S.
W.S. schrieb:> Aber deine Behauptung, es sei etwas standardkonform ist FALSCH.
Sieh Dir mal das hier an:
http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1124.pdf
Das ist ein draft des C-Standards "ISO/IEC9899". Es entspricht bis auf
kleine Abweichungen dem offiziellen ISO-Dokument, nur kommt man an das
ohne Geldeinwurf nicht 'ran.
Akzeptierst Du das trotzdem als Standard?
Und dort blätterst Du bitte auf Seite 255 (S. 267 von 550) und siehst
Dir den Abschnitt 7.18 an.
> Und deine wiederkehrenden Behauptungen, "daß Du mal wieder keine Ahnung> von C hast" ist eine Beleidigung.
Wenn Du es so oft belegst? Wie soll ich das bitte sonst formulieren?
> Abgesehen davon ist sie falsch.
Offensichtlich, aber sowas von offensichtlich ist sie das nicht.
Mampf F. schrieb:> Dann hat man auf dem PC das gleiche wie auf dem µC
Aber nur wenn PC und uC die gleiche Endianness und Sign-Formate haben.
Dann lieber so wie in Serialisierung machen.
Dr. Sommer schrieb:> Mampf F. schrieb:>> Dann hat man auf dem PC das gleiche wie auf dem µC>> Aber nur wenn PC und uC die gleiche Endianness und Sign-Formate haben.> Dann lieber so wie in Serialisierung machen.
Meinst du mit Sign-Formate two's complement, one's complement oder
sign&magnitude? Wenn ja, die "Exact-width integer types" sind als two's
complement definiert. Wenn die cpu das nicht kann, gibts kein int8_t und
co.
Da es sich um C++ handelt, könnte man C++11 (>=GCC 4.7.n) benutzen.
Konkret: "using", was als freundlichere Variante von "typedef"
vorgesehen ist. Es gibt auch die Empfehlung nur noch "using" zu
verwenden. Daß es "typedef" noch gibt, ist nur der Regel "don't break
bxisting code" geschuldet.
1
// ident Type
2
usingCANMessage_t=struct{
3
unsignedintid;
4
unsignedcharrtr;
5
unsignedcharlength;
6
unsignedchardata[8];
7
};
Eine Typdefinition hat dann den selben Aufbau, wie eine
Variablendefinition:
1
// ident value
2
automsg=CANMessage{4711,0,2,'a','!'};
Und bevor jemand den Aufruf des copy/move-constructors von msg beklagt,
einer der beiden muß zwar existieren, wird aber in der Regel
wegoptimiertauch, da er von einem temporären Objekt ausgeht.
mh schrieb:> Wenn ja, die "Exact-width integer types" sind als two's complement> definiert. Wenn die cpu das nicht kann, gibts kein int8_t und co.
Ah, wo im Standard steht das denn?
W.S. schrieb:> Also im Klartext, daß du eine künstliche Grenze bei etwa 8 Bytes> einziehen möchtest, um gedankenloses Anordnen von größeren Dingen auf> dem Stack zu vermeiden?
Nein. Anders rum. Bei Skalaren brauche ich oft ein Typedef, ders hat
aber auch nur maximal 8 Byte, so dass by Value oder Reference (für den
Stack) egal ist. Auch eine kleine Struktur mit 1 Byte typedefe ich
trotzdem nicht.
> Mir kommt so etwas viel zu aufgesetzt vor. Weitaus wichtiger ist es> doch, daß eine Quelle gut leserlich und leicht erfaßbar ist, aber das> ist bei all dem, was das Beachten von weiteren zusätzlichen aufgesetzten> Üblichkeits-Regeln erfordert, kontraproduktiv.>> Es ist mMn nichts anderes als das Aufstellen von weiteren überflüssigen> Fettnäpfchen - um die man dann auch noch herumeiern muß, um nicht> hineinzutreten.
Es ist ja keine "zusätzliche" Regel, sondern eine "führ kein
überflüssiges neues Token ein"-Regel.
https://yarchive.net/comp/linux/typedefs.html