Guten Abend,
ich versuche einen Profiling-Code auf einem Cortex-M1 zum laufen zu
bekommen.
Der verwendet armv6-m und den Code, den ich gefunden habe, verwendet
armv7-m.
1
push {r0, r1, r2, r3, lr} /* save registers */
2
bic r1, lr, #1 /* R1 contains callee address, with thumb bit cleared */
Scheinbar kann armv6-m1 nur Thumb-Instruction und das sind
ARM-Instructions vom armv7.
Ich hab bisserl rumgespielt, komm aber auf die schnelle auf keinen
grünen Zweig.
Könnte das mir bitte jemand für armv6-m abändern?
Ich vermute, ich würde unendlich viele Fehler machen und würde dafür
ewig brauchen ... Irgendwann würde es schon klappen, aber ich vermute
einen Aufwand von mindestens einem halben Tag, bis ich mich da
eingelesen habe.
Normalerweise bin ich nicht so faul!
Danke!
Mampf
Ich hab mich jetzt mal durchgekämpft ... vlt doch nicht so schlimm, wie
gedacht :-)
Dieses Condition-Flag bei zB movs und bics ist mir noch ein Rätsel, da
ich die Auswirkungen nicht kenne.
Aber die CPU hard-faultet zumindest nicht mehr ...
Falls jemand noch eine Idee hat oder sieht, dass ich was falsch gemacht
habe, wäre ich über einen Hinweis dankbar.
VG
Mampf
Dennis H. schrieb:> Das S bei MOVS steht für setze Flags.> Beim ARMv6-M gibt für MOV R,#Konstante nur die MOVS-Version (Thumb1).
ok, Danke!
Wenn mein Cortex M1 nur thumb kann, machen die BIC keinen Sinn, bzw sind
sogar falsch, weil die adressen alle bit0 gesetzt haben müssen ...
Bei thumb scheint es keinen pop lr zu geben sondern nur einen push lr +
pop pc
Dennis H. schrieb:> Wieso wird ein POP zuviel gemacht ?
Glaub das ist C Calling Convention ... die Rücksprungadresse liegt wohl
auf dem Stack - wobei dafür sollte LR da sein?
Aber eine Frage ...
Das versteh ich einfach nicht^^
Wie soll man LR vom Stack runterholen, wenn man keine Register
manipulieren darf?
Hätte pop {r0} und mov lr,r0 gemacht, aber dabei wird r0 verändert.
Kann man LR direkt laden über den Stackpointer?
Zudem kommt noch, dass die Reihenfolge der push und pop wohl egal ist,
da sie nicht hintereinander auf den Stack gepusht werden, sondern quasi
in dedizierte Slots?
Mampf F. schrieb:> Zudem kommt noch, dass die Reihenfolge der push und pop wohl egal ist,> da sie nicht hintereinander auf den Stack gepusht werden, sondern quasi> in dedizierte Slots?
Es ist egal, in welcher Reihenfolge du sie in den push/pop Befehl
schreibst, weil das eine Bitmaske im Befehl ist.
Mampf F. schrieb:> Wie soll man LR vom Stack runterholen, wenn man keine Register> manipulieren darf?
Du darfst R12 verändern und du kannst temporär Platz auf dem Stack
schaffen um dort Register abzuladen.
A. K. schrieb:> Mampf F. schrieb:>> Wie soll man LR vom Stack runterholen, wenn man keine Register>> manipulieren darf?>> Du darfst R12 verändern und du kannst temporär Platz auf dem Stack> schaffen um dort Register abzuladen.
Aaah, ich bin so dumm! Stand ja sogar in dem Bild, das ich gepostet
hatte ...
Danke!
Jetzt sollte ich problemlos damit zurecht kommen
Guten Morgen!
eine kleine Verständnisfrage habe ich noch ...
Also laut dem Bild aus einem der letzten Postings muss man ganz zum
Schluss LR vom Stack holen und die funktion verlassen.
Die multi-Push und -Pops verwirren mich noch.
Also wenn zB push {r0-r3, lr} nichts anderes macht als
push {r0}
push {r1}
push {r2}
push {r3}
push {lr}
dann müsste pop {r0-r3, ip, lr} das hier machen?
pop {lr}
pop {ip}
pop {r3}
pop {r2}
pop {r1}
pop {r0}
Das wäre aber dann falsch, weil LR erst ganz zum Schluss gepoppt werden
muss, beim pop aber als erstes gepoppt wird?
Dann hab ich aber noch das hier gefunden:
> I'm trying to understand the start and end of functions in ARM> assembly:>> PUSH {R0-R2, LR}> POP {R0-R2, PC}> Looking at this piece of code in IDA here's what I understood (Lets> assume SP is 0x100):>> PUSH R0 ; sp = 0xFC> PUSH R1 ; sp = 0xF8> PUSH R2 ; sp = 0xF4> PUSH LR ; sp = 0xF0> POP R0 ; sp = 0xF4> POP R1 ; sp = 0xF8> POP R2 ; sp = 0xFC> POP PC ; sp = 0x100
mit der Antwort:
> When you PUSH or POP a bunch of registers, they always go into memory> in the same relative positions, regardless of direction. The lowest-> numberd register is stored at and loaded from the lowest address. So> in this example everything will go back to the original register,> except LR->PC.
Also wenn das stimmt, und ich keinen POP {LR} habe, dann kann ich aber
auch kein
mov r12, r0
pop {r0}
mov lr, r0
mov r0,r12
machen ... Das widerspricht meinem Verständnis für einen Stack, aber vlt
ist es bei ARM anders als bei allen anderen?^^
Sicher hab ich da nur ein ganz einfach zu lösendes Verständnisproblem
...
Versteht man das, womit ich meine Probleme hab? :-)
Viele Grüße,
Mampf
Ok, jetzt check ich es ...
> Registers are stored on the stack in numerical order, with the lowest> numbered register at the lowest address.
Super Formulierung ARM lol ...
D.h. gepusht wird vom höchsten zum niedrigsten Register und gepoppt
andersrum.
Dann passt der ursprüngliche Code, denn LR wird dann tatsächlich ganz
zum schluss gepoppt, wenn der Stack schon wieder leer ist.
Hach na endlich!
Das hier werde ich dann nachher testen:
1
push {r0, r1, r2, r3, lr} /* save registers */
2
// bic r1, lr, #1 /* R1 contains callee address, with thumb bit cleared */
Mampf F. schrieb:> mov r12, r0> pop {r0}> mov ip, r0
ip ist ein Alias für r12. Das ist so also relativ sinnlos. IP steht hier
für "Intra-Procedure-call scratch register" und nicht für "Instruction
Pointer" wie bei x86. Der heißt bei ARM "PC" ("Program Counter") und ist
ein Alias für r15.
Siehe dazu auch den AAPCS:
http://infocenter.arm.com/help/topic/com.arm.doc.ihi0042f/IHI0042F_aapcs.pdf
Hab jetzt nicht alles auseinander genommen, aber ich glaube da stimmt
noch was nicht, insbesondere verlierst du den alten "r0" Wert. So könnte
es gehen:
Echt knifflig, beim ARMv7-A ist das netter ;-) Der Trick ist hier, die
beiden Register "direkt" vom Stack per LDR zu laden, bevor man die
r0-r3 wiederherstellt und solange man die also noch nutzen kann. Nach
der Wiederherstellung springt man über diese 8 Bytes hinweg indem man 8
auf den SP addiert.
Das "BIC" Zeug könntest du auch in der _mcount_internal in C machen, das
spart die Assembler-Schnipselei.
Gab noch ein paar andere Sachen, die ich in dem gprof-Tutorial ändern
musste.
Im PC-sampler wurde immer die falsche Adresse für die unterbrochene
Funktion ermittelt (auf der Webseite gibt es beim Systick-Sampler
irgendwo einen [14] Index, der musste bei mir [10] sein - ermitteln über
Disassembler, Memory-Map und Register ... Ich liebe die
Cortex-Debug-Möglichkeiten!)
https://mcuoneclipse.com/2015/08/23/tutorial-using-gnu-profiling-gprof-with-arm-cortex-m/
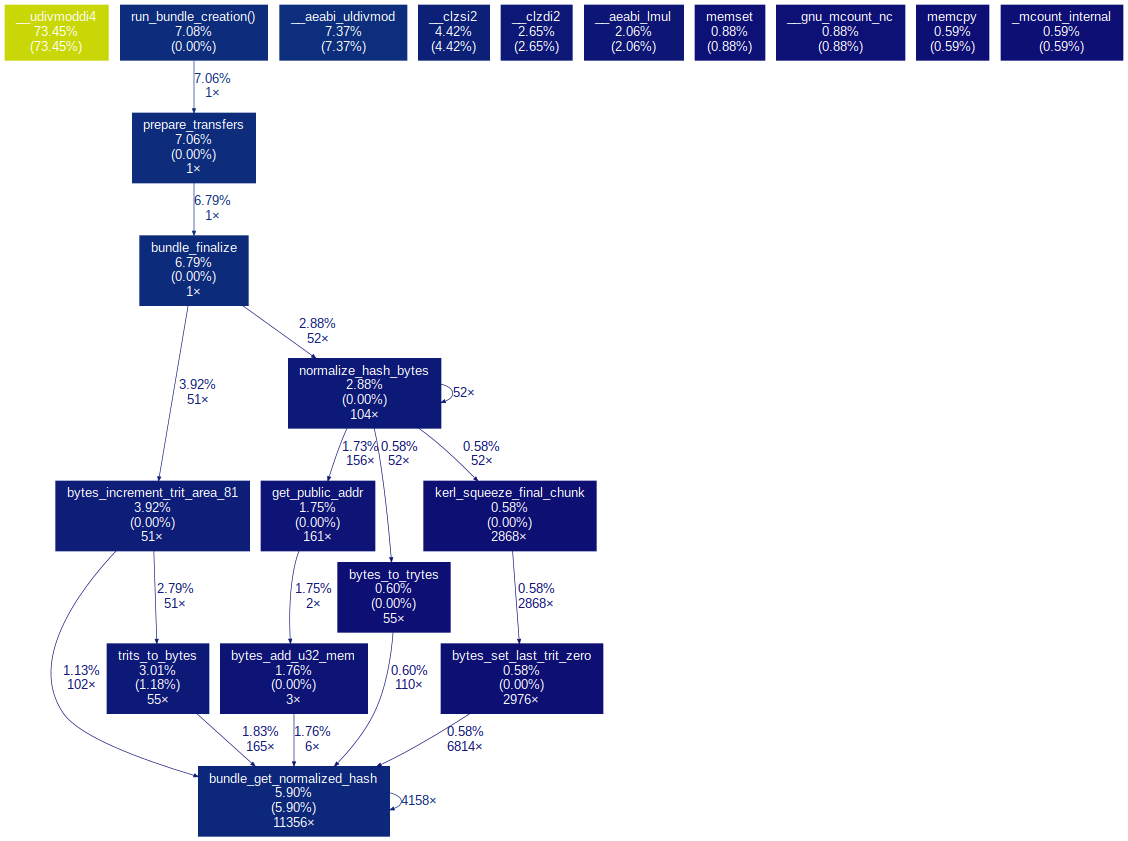
Dann lief es im Prinzip richtig und herausgekommen ist über gprof2dot
sowas wie im Anhang :)
Achja, da sieht man deutlich, wo 4/5tel der CPU-Leistung verschwindet xD
Also ich denke, das Profiling ist richtig **geil** :-)
Oh, gprof2dot kannte ich noch gar nicht, das sieht gut aus! Man könnte
das ganze vielleicht noch mit Segger SystemView verheiraten (in der
_mcount_internal SEGGER_SYSVIEW_OnUserStart aufrufen oder so) und das
(nahezu) live betrachten.