Grüß euch
Ich benötige Hilfe bei der Umstellung eines Modells von double hin zu
float oder noch besser einem fixed-point Typen. Den Code des Modells hab
ich als "cauer.hpp" angehängt. Es handelt sich dabei um das thermische
Modell eines FETs.
Die Eingangsparameter werden in jeweils in "Milli" übergeben und
betragen
0-16000mV sowie
0-2000mA
Aktuell funktioniert das Modell zwar einwandfrei, nur leider dauert die
Berechnung auf einem Cortex-M4 ohne double Unterstützung in Hardware
recht lahme 2030 Zyklen. Eine Umstellung zu float führte leider dazu,
dass das Modell auf Grund von Rundungsfehlern recht flott davon läuft.
Eine Umstellung zu int64 machte das System überhaupt instabil und es
fängt an zu schwingen...
Anbei auch noch der Test-Code mit dem ich das Modell aktuell befeuere:
Ich würde vorschlagen, dass du dir einen eigenen Datentyp für deine
Werte anlegst. Also eine Klasse, die alle Operationen, die du brauchst
unterstützt. Mit Operatorüberladung siehst du in den Formeln auch keinen
Unterschied.
Die erste Implementierung ist nur ein Wrapper um ein double. Verwendet
du diese statt double in deinem Code, dann sollte es sich so verhalten,
wie double direkt (inlining vorausgesetzt).
Dann kannst du das umbauen und intern mit fixpoint rechnen. Da kannst du
dann ausprobieren, welche Genauigkeit du brauchst.
Vincent H. schrieb:> Eine Umstellung zu int64 machte das System überhaupt instabil und es> fängt an zu schwingen...
Wie oben gesagt und beu der Genauigkeit mit uint64 musst Du den ganzen
Wertebereich ausschöpfen, z.B.
0 .. 16000mV = 0 .. 16000000000000000000
Ich stell Mal blöde Fragen:
Wie kommst du denn auf die Koeffizienten?
Ist es denkbar dass Modell durch eine andere Darstellung weniger
anfällig auf Rundungsfehler zu machen? Es hat schon seinen Grund warum
oft biquads für digitale Filter verwendet werden.
Alternativ als FIR?
Hast du das Modell nach Umstellung auf float formal auf Stabilität
geprüft?
Hast du das Modell nach Quantisierung formal auf Stabilität geprüft?
Dass es mit float anders rechnet ist soweit nicht verwunderlich. Wenn
die Genauigkeit nicht reicht, kannst du versuchen den Rundungsfehler
durch bessere Wahl der Koeffizienten zu kompensieren. Ebenso kann es
zielführend sein nur die kritischen Berechnungen mit höherer Genauigkeit
ausführen. An sich wundert es mich aber schon, das ein float nicht
reichen soll.
> IEEE 754 float precision: 23 bits stored> IEEE 754 double precision: 52 bits stored
Beides ist dem TO zu langsam.
Ich bilde mir ein, dass 64 Bits Integer schneller und genauer sind, bei
richtiger Skalierung (Beispiel oben).
Torsten C. schrieb:> IEEE 754 float precision: 23 bits stored> IEEE 754 double precision: 52 bits stored>> Beides ist dem TO zu langsam.>
Nö, das Kodell mit floats scheint laut TO durch Rundungsfehler zu
divergieren.
> Ich bilde mir ein, dass 64 Bits Integer schneller und genauer sind, bei> richtiger Skalierung (Beispiel oben).
Kommt auf den Algorithmus und die Hardware (fpu?) an. Kann zb ein auf
floating point basierender Algorithmus 1 zu 1 auf fixed point umgestellt
werden?
Torsten C. schrieb:>> IEEE 754 float precision: 23 bits stored>> IEEE 754 double precision: 52 bits stored>> Beides ist dem TO zu langsam.>> Ich bilde mir ein, dass 64 Bits Integer schneller und genauer sind, bei> richtiger Skalierung (Beispiel oben).
Steht das da? Sehe ich nicht, oder besser: interpretiere ich anders.
Double als Software Emulation ist zu langsam. Float in Hardware ist
schnell genug aber nicht genau genug.
Int64 ist auf einem Cortex M4 mit FPU langsamer als float. Wenn man die
CPU in Integer richtig nutzen will braucht es schon was in der Form
32*32+64=64. Mit etwas Glück erkennt es der Compiler. Sonst gibt es
intrinsics oder Assembler. Int 64 ist aber keinesfalls die pauschale
Antwort auf Performance oder Genauigkeitsprobleme.
Das da ...
Torsten C. schrieb:> 0 .. 16000mV = 0 .. 16000000000000000000
... ist obendrein eine ziemlich ungeschickt gewählte Skalierung, weil
die Multiplikation 64 Bit Mal x Bit nicht so einfach vom Compiler
erledigt wird.
Hab ich dich falsch verstanden?
Karl schrieb:> Ich stell Mal blöde Fragen:> Wie kommst du denn auf die Koeffizienten?
Mehr oder weniger direkt vom Hersteller des FETs. Nur halt digitalisiert
usw.
Karl schrieb:> Hast du das Modell nach Umstellung auf float formal auf Stabilität> geprüft?> Hast du das Modell nach Quantisierung formal auf Stabilität geprüft?
Nein. Ich wüsste ehrlich gesagt auch grad nicht wie. Ich schreib zwar
recht viele Algorithmen und auch Filtersachen, mit numerischer
Stabilität hatte ich bis dahin aber noch nie zu kämpfen.
Karl schrieb:> Ist es denkbar dass Modell durch eine andere Darstellung weniger> anfällig auf Rundungsfehler zu machen? Es hat schon seinen Grund warum> oft biquads für digitale Filter verwendet werden.
Das war ein ausgezeichneter Vorschlag. Ich hab auf die schnelle mal ein
IIR in Direct Form II ausprobiert dass lediglich in single precision
rechnet und der Fehler ist weg.
Moin,
Hm, warum werden wohl ueblicherweise IIR-Filter hoeherer Ordnung
runtergebrochen auf Kettenschaltungen von IIR-Teilfiltern hoechstens 2.
Ordnung...? Hmmmmm....
Gruss
WK
Vincent H. schrieb:> Nein. Ich wüsste ehrlich gesagt auch grad nicht wie. Ich schreib zwar> recht viele Algorithmen und auch Filtersachen, mit numerischer> Stabilität hatte ich bis dahin aber noch nie zu kämpfen.
Schon länger her, aber die Pole der z Transformation sollten im
Einheitskreis liegen, oder?
Vincent H. schrieb:> Das war ein ausgezeichneter Vorschlag. Ich hab auf die schnelle mal ein> IIR in Direct Form II ausprobiert dass lediglich in single precision> rechnet und der Fehler ist weg.
Danke für die Rückmeldung. Freut mich, dass ich auch Mal helfen könnte
:)
Zu früh gefreut... Sowohl ein 2-stufiger IIR mit float als auch einer
mit internem 64bit Accu haben Probleme kleine Werte über längere
Zeiträume aufzusummieren. Die float Variante plagt sich weiters mit
Quantisierungsfehlern die zu leichtem Schwingen führen.
Kann ich dieses Probleme irgendwie umgehn? Rechenleistung hät ich nun
noch übrig. Die float Variante braucht nur noch 1/10 der Zyklen im
Vergleich zu vorher.
Versuche teile des Filters auf double umzustellen waren leider nicht
sehr erfolgreich.
Mir ist nicht ganz klar, was man auf den Bildern sieht. Magst du das
erklären? Am besten mit dem relevanten Stück Quellcode dazu.
Als Schwingen im klassischen Sinn würde ich das auf Bild 2 übrigens
nicht bezeichnen.
Generell: wenn Double nicht reicht machst du meistens irgendetwas
falsch.
Errr... Ich meinte natürlich Teile des Filters auf float(!) umzustellen.
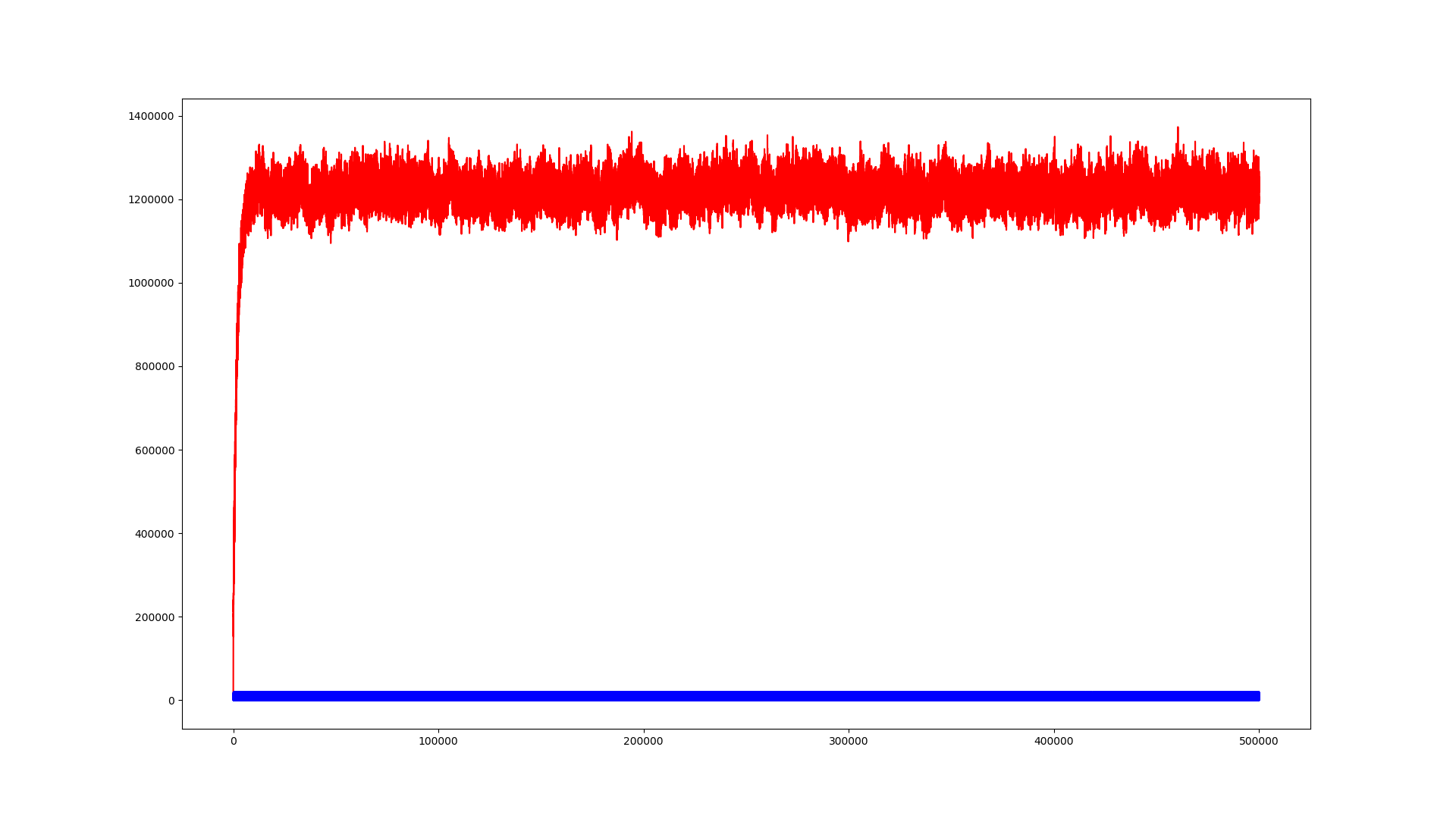
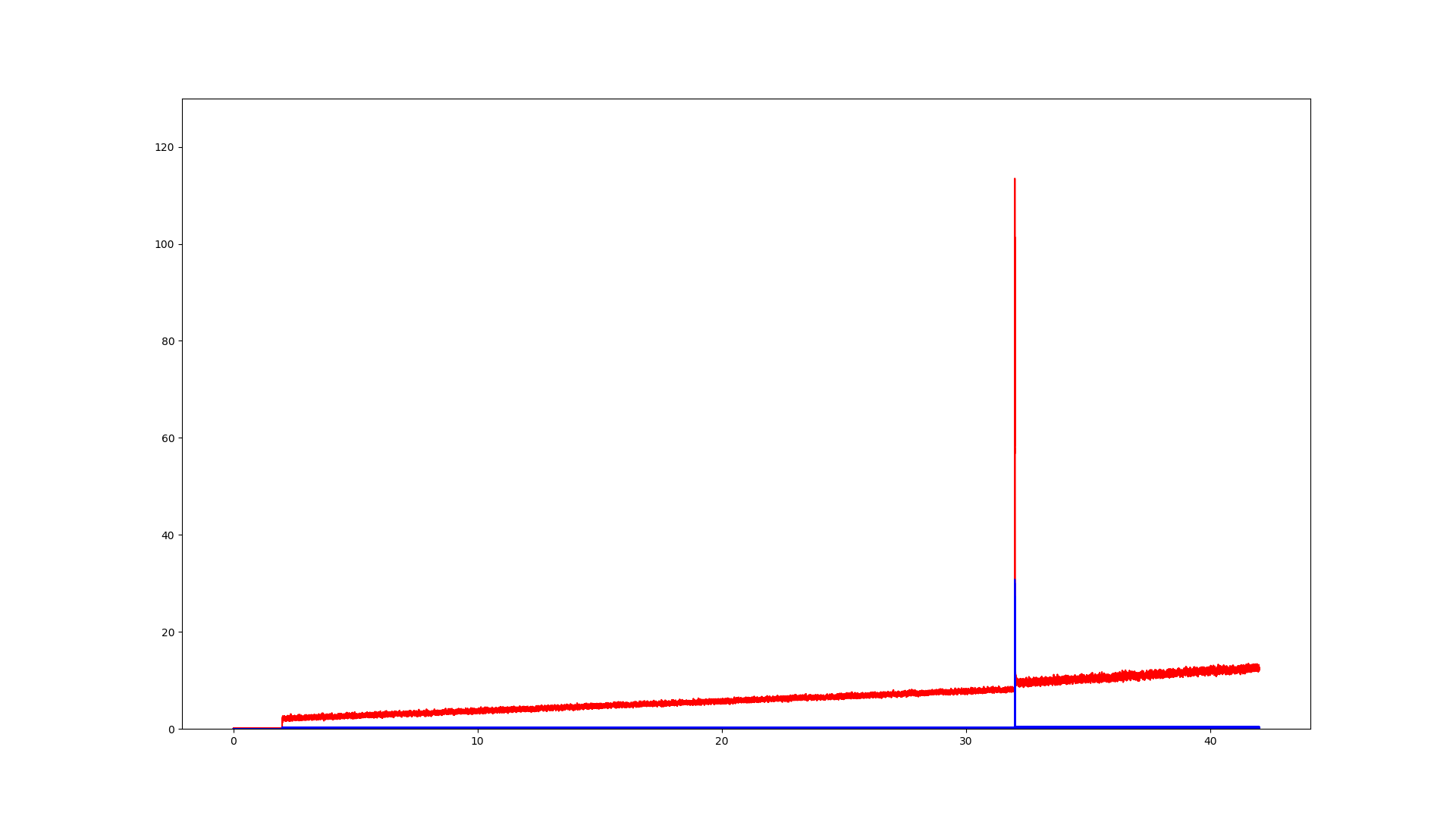
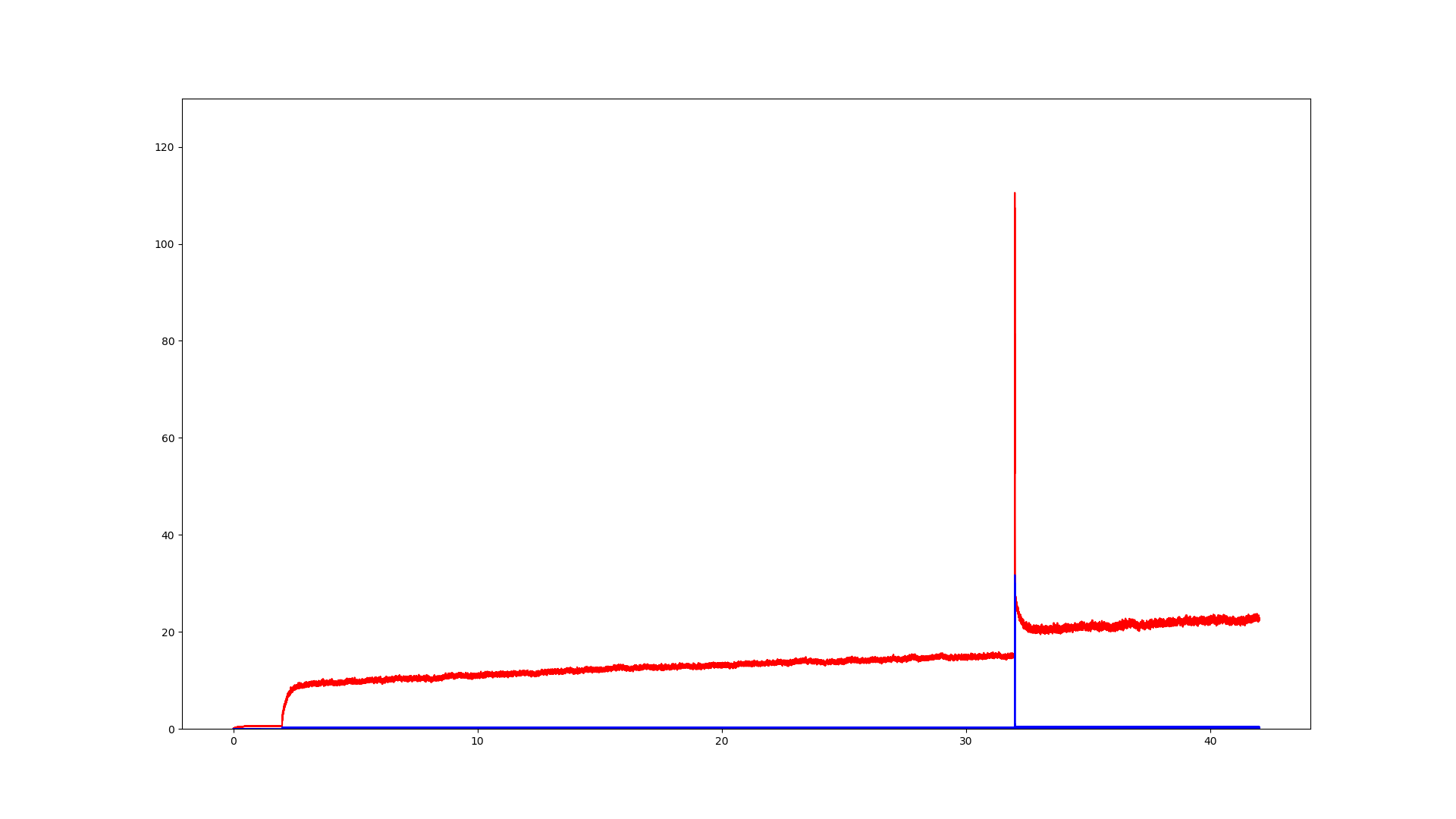
Bild 1:
direct-form 1 IIR mit internen 64bit Accu fixed-point
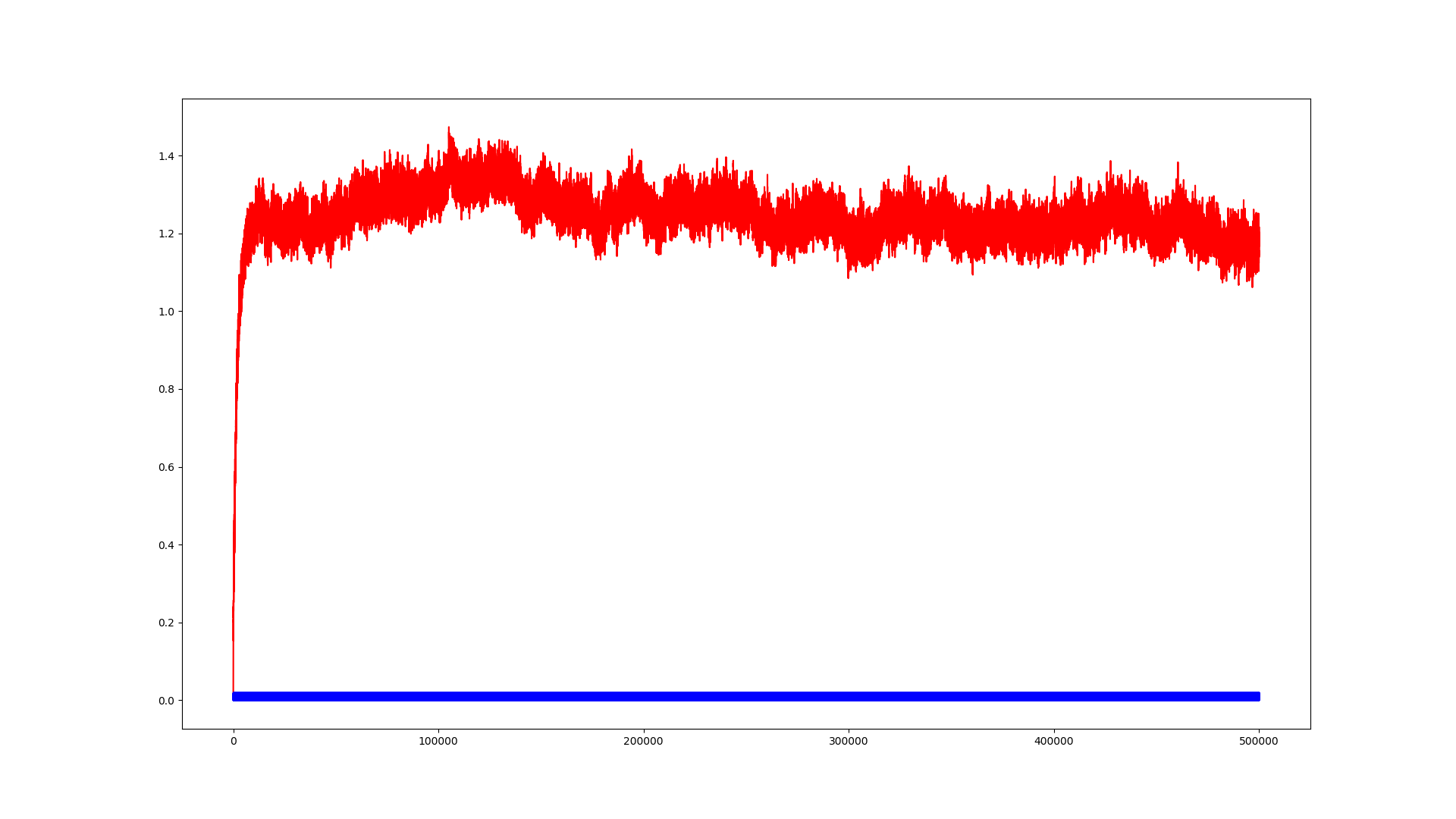
Bild 2:
direct-form2 transposed IIR in single precision
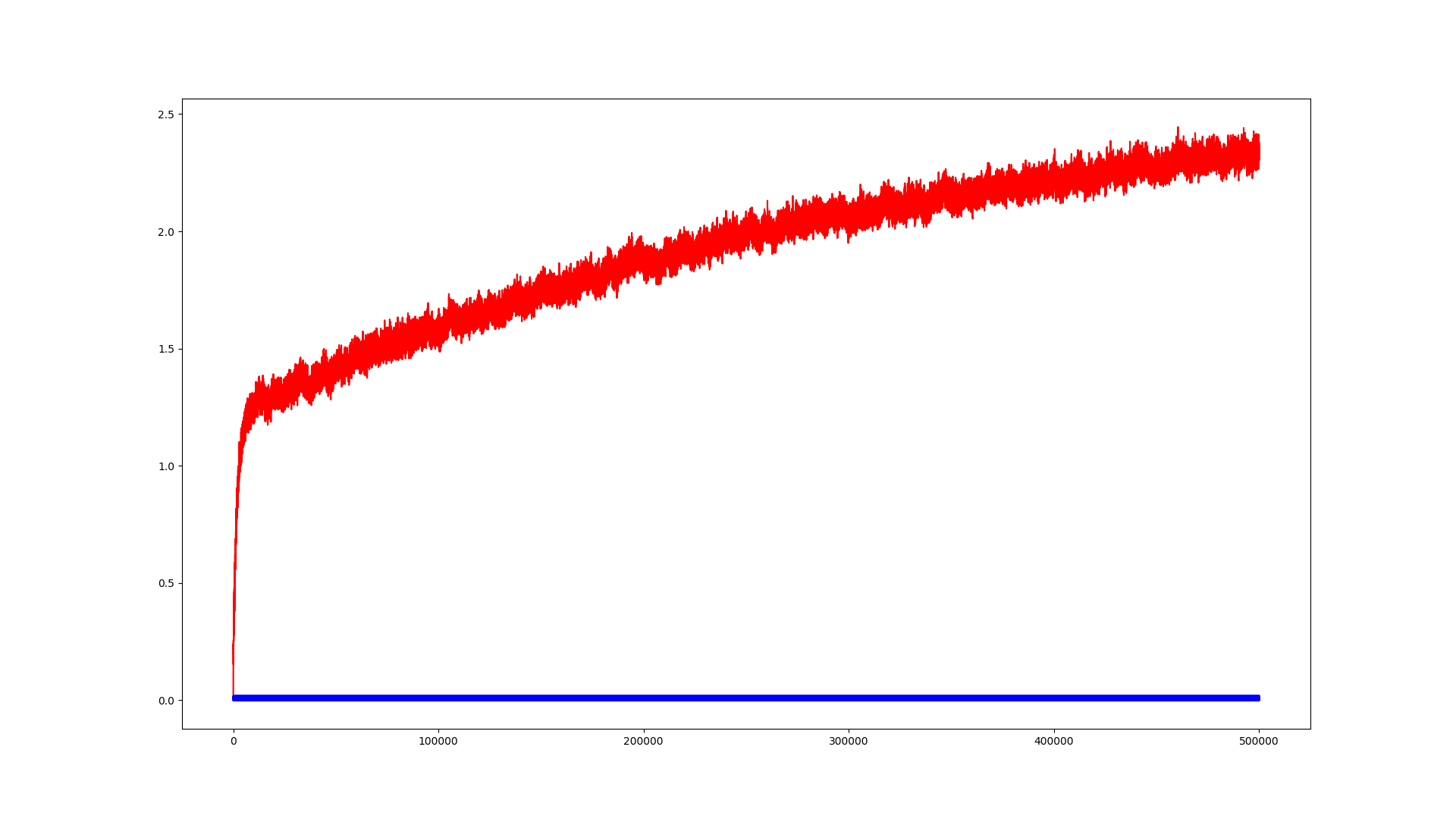
Bild 3:
direct-form2 transposed IIR in double precision
Schwingen im klassischen Sinne ist sicher nicht. Aber offensichtlich
führen numerische Probleme zu irgendwelchen Quantisierungseffekten. Vor
allem im Vergleich mit dem 1.Bild wird das deutlich.
Der Code ist vorerst 1:1 aus der CMSIS DSP Bibliothek.
Was man auf den Bildern recht deutlich siehst ist, dass sich alle
Modelle gleich verhalten solang der interne Zustand des Systems noch
großen Änderungen unterliegt. Umso kleiner jene Zustandsänderungen
jedoch werden, umso mehr scheinen Änderungen geschluckt zu werden bis an
einen Punkt wo sie irgendwo in den Berechnungen untergehn und sich der
Ausgangszustand des Systems gar nich mehr ändert.
Moin,
Ich werd' aus den Bildern und den Erklaerungen bisher auch nicht so
recht schlau.
Sollen das Impulsantworten sein, oder Sprungantworten oder was ganz
anderes?
Die Achsenbeschriftungen geben nicht viel her.
Und was ist ein interner 64bit akku bei einem IIR?
Haste mal ein Pol/Nullstellendiagramm von dem Filter?
Gruss
WK
Ja meine Posts waren zugegebenermaßen etwas wirr... Also nochmal von
Anfang an:
1.) Das Filter mit der ursprünglichen Übertragungsfunktion ist
ausschließlich in double precision stabil. Die Pole liegen leider auch
teils sehr nah am Einheitskreis...
1
p=[1.000000.999520.979620.80339]
2
z=[-1.000000.999990.997580.92755]
2.) Übersetzt man die Übertragungsfunktion in eine SOS Struktur, dann
ist das Filter zwar stabil, schluckt aber irgendwann kleine Änderungen
in den Ausgangszuständen.
Das sieht man dann an den oben bereits geposteten Grafiken. Lediglich
bei double precision steigt der Ausgangswert kontinuierlich an. Bei den
anderen beiden Filtern reicht die Dynamik irgendwann nicht mehr aus und
das was am Ausgangswert dazu addiert werden müsste verschwindet in der
Quantisierung.
Ein "interner 64bit" Akku heißt dass der Filterzustand intern in 64
statt in 32bit gespeichert wird. Genau das soll eigentlich
Quantisierungsfehler vorbeugen.
Moin,
Vincent H. schrieb:> Die Pole liegen leider auch> teils sehr nah am Einheitskreis...
Naja, das sollte man halt vermeiden... Durch die Quantisierung fangen
Pole und Nullstellen an, so ein bisschen in der naeheren Umgebung
"herumzuwandern" - und das ist halt dann doof, wenns da die ganz genaue
Position von P/N entscheidend fuer die Stabilitiaet ist.
Ich schaetz' mal, dass es ab hier schon schief geht:
Vincent H. schrieb:> Karl schrieb:>> Ich stell Mal blöde Fragen:>> Wie kommst du denn auf die Koeffizienten?>> Mehr oder weniger direkt vom Hersteller des FETs. Nur halt digitalisiert> usw.
Probier' die Herstellerangaben anders zu approximieren, evtl. durch ein
Filter mit hoeherer Ordnung.
Gruss
WK
Hallöchen,
hab mal ein paar Tests gemacht, siehe angehängte PDF (wollte mal Matlab
Live Scripts testen). Das Filter wird instabil bei float Koeffizienten.
Auch interessant ist, dass die Pole sogar komplexwertig werden im Falle
von 32 Bit, was die Schwingungsneigung erklärt.
Moin,
Wer hat denn diese 4. Ordnung Cauerfilter aus dem Hut gezaubert und
warum? Geht da evtl auch eines 6. oder 8. oder n-ter Ordnung? Oder was
anderes?
Gruss
WK
Die Koeffizienten des Modells kommen von einem thermischen PSpice
Modell. Welches genau muss ich nachschaun wenn ich wieder daheim bin...
Rohm Qs6...k21 oder so.
Ja mit float ginge sich bezüglich Rechenleistung auch 6/8. Ordnung aus.
Danke schon mal für die kompetente Hilfestellung!
Moin,
Cauerfilter kannst du unter Matlab/Octave mit der Funktion "ellip"
berechnen.
Da kommen als Parameter Filterordnung, Grenzfrequenz, Passband-Ripple
und Stopband-Attenuation rein. Raus kommen dann die a und b
Koeffizienten.
Jetzt muesstest du halt mal gucken, ob du diese Werte irgendwoher
kriegst und die dann halt zu einem Cauerfilter mit Ordnung >4 verwursten
kannst.
Gruss
WK
Hab das Modell nun in einer float/double Variante in 555 (:D) Zyklen
untergebracht. Das dürfte schnell genug sein und beansprucht nun alle
100µs nur noch 7µs statt wie bisher 25µs.
Danke für die rege Beteiligung!
Magst du etwas ausholen? Hast du also die Filterimplementation teilweise
auf doubles umgestellt?
Pole so nah am Einheitskreis sind dennoch keine besonders gute Idee. Ich
könnte nächste Woche mal probieren, die Ordnung zu erhöhen, vllt werden
die Pole gutmütiger.
Oder gibts kein Interesse mehr?
Schöne Grüße,
Jan
Ja im Prinzip recht simpel. Ich hab via trial&error ausprobiert was geht
und nur die Operationen mit den Koeffizienten nahe am Einheitskreis in
double lassen.
1
// Stage 1
2
constexprfloatb0{0.454389447881695};
3
constexprfloatb1{0.0329205560241321};
4
constexprfloatb2{-0.421468891857564};
5
constexprfloata1{-1.78301059580914*-1.0};
6
constexprfloata2{0.787017099330939*-1.0};
7
8
// Stage 2
9
constexprfloatb0{1.0};
10
constexprfloatb1{-1.99757469222298};
11
constexprdoubleb2{0.997574708046983};
12
constexprdoublea1{-1.99951872794428*-1.0};
13
constexprdoublea2{0.999518729388731*-1.0};
Da fallen dann schon recht viele weg.
Aber ja, ein reines float Filter wäre natürlich noch besser ;)
Hallöchen,
habe mal auf 3 second order sections (biquads) erhöht und auf single
gecastet:
sos2 = 3×6 single matrix
0.4544 0.45438 0 1 -0.80339
0
1 -1.9251 0.92531 1 -1.9791
0.97915
1 -0.99999 -3.0427e-07 1 -1
0
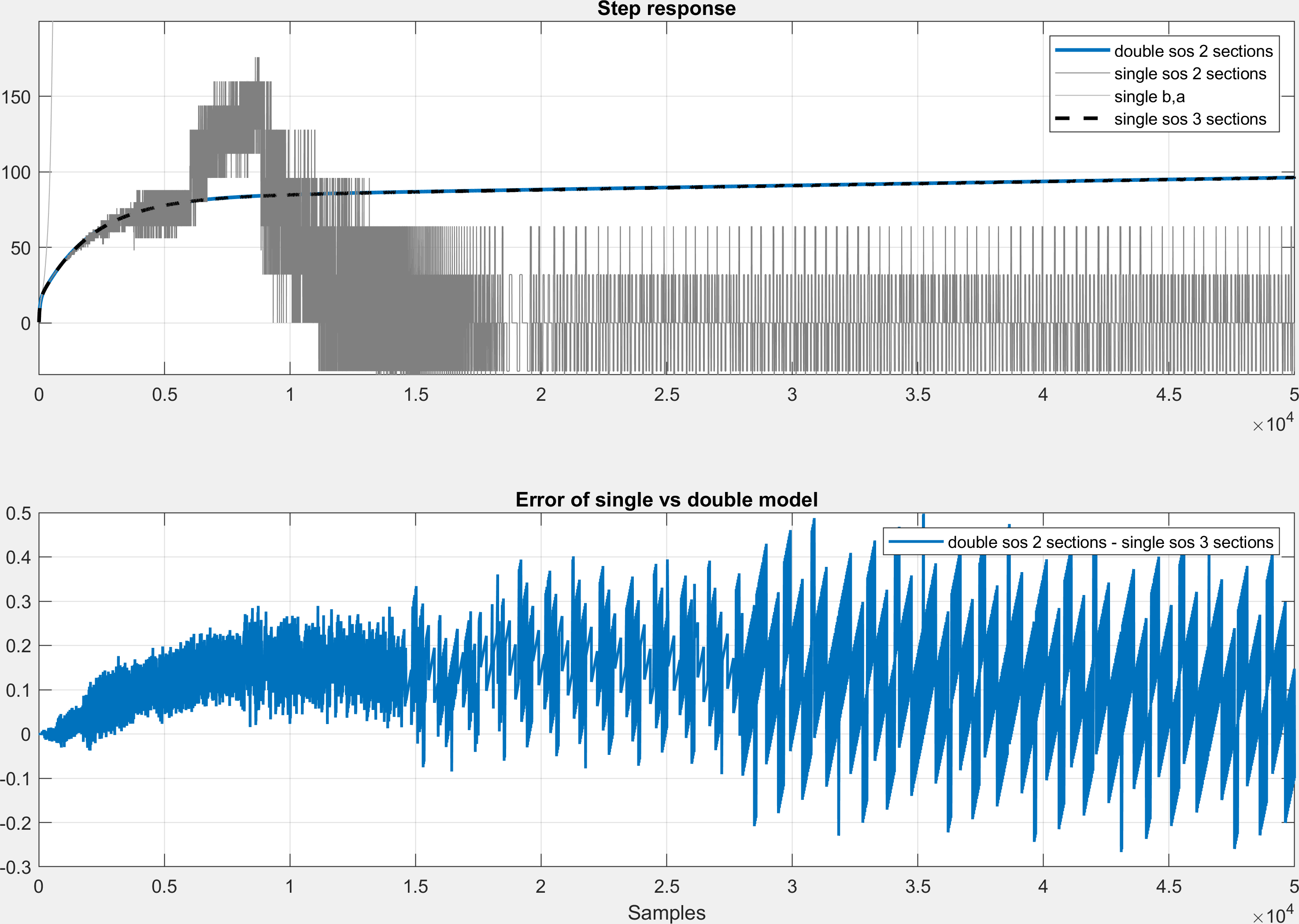
ist stabil, siehe angehängte PDF (ganz unten) oder die Step response (im
Anhang).
Schöne Grüße.
Hm schade & komisch. Der Fehler in der Sprungantwort war ja relativ
klein (siehe stepResp.png) und eigentlich ist das Filter damit
vollständig beschrieben.
Hast du die Zuordnung der Koeffizienten richtig rum?
1
SOS is an L by 6 matrix with the following structure:
2
SOS = [ b01 b11 b21 1 a11 a21
3
b02 b12 b22 1 a12 a22
4
...
5
b0L b1L b2L 1 a1L a2L ]
6
7
Each row of the SOS matrix describes a 2nd order transfer function:
8
b0k + b1k z^-1 + b2k z^-2
9
Hk(z) = ----------------------------
10
1 + a1k z^-1 + a2k z^-2
11
where k is the row index.
12
13
G is a scalar which accounts for the overall gain of the system. If
14
G is not specified, the gain is embedded in the first section.
15
The second order structure thus describes the system H(z) as:
16
H(z) = G*H1(z)*H2(z)*...*HL(z)
17
18
NOTE: Embedding the gain in the first section when scaling a
19
direct-form II structure is not recommended and may result in erratic
20
scaling. To avoid embedding the gain, use tf2sos with two outputs.
Gerade der letzte Satz ist interessant. Vielleicht ziehst du den gain
mal raus? Sieht dann so aus (nicht ausprobiert):
1
3×6 single matrix
2
3
1 0.999946 0 1 -0.8033887 0
4
1 -1.925131 0.9253066 1 -1.979144 0.9791538
5
1 -0.9999931 -3.042735e-07 1 -0.999997 0
6
7
g2 = 0.4544021
"Edit": ich habe dir nicht alle signifikanten Stellen verraten, sorry.
Oben in der Matrix sind alle angegeben.
Was zeigt bei dir welcher Plot und wie viele Samples hast du berechnet?
Wo kommen die Sprünge her?
Ah da haben wohl ein paar Stellen gefehlt! Nun sieht es wesentlich
besser aus und der Fehler ist tatsächlich winzig! Super danke vielmals!
Jan schrieb:> Was zeigt bei dir welcher Plot und wie viele Samples hast du berechnet?> Wo kommen die Sprünge her?
Die Plots sind mit einem c++ Wrapper um matplotlib entstanden mit dem
ich noch nicht wirklich warm bin. Deshalb immer die sehr... ehm "kruden"
Grafiken. Es handelt (und handelte) sich stets um gleichverteilte
Random-Inputs. An den Sprüngen hab ich nur jeweils das Intervall der
Verteilung geändert. Ich teste damit gleichzeitig in einem Unit-Test ob
die Outputs des Original-Filters mit den neuen Varianten übereinstimmen.
Mich würde jetzt noch interessieren nach welcher Methode du das neue
Filter erstellt hast? Matlab kann zwar viel, aber eine "Nimm jenes
System und mach was stabiles mit folgendem Datentyp draus"-Funktion
gibts leider noch nicht. :D
Vincent H. schrieb:> Ah da haben wohl ein paar Stellen gefehlt! Nun sieht es wesentlich> besser aus und der Fehler ist tatsächlich winzig! Super danke vielmals!>
Juhu :)
> Mich würde jetzt noch interessieren nach welcher Methode du das neue> Filter erstellt hast? Matlab kann zwar viel, aber eine "Nimm jenes> System und mach was stabiles mit folgendem Datentyp draus"-Funktion> gibts leider noch nicht. :D
Stimmt. Guck mal in die PDF rein, da steht das extra schon drin ;)
In Kürze: habe einfach die Sprungantwort mit der Steiglitz-McBride
Methode (https://de.mathworks.com/help/signal/ref/stmcb.html) gefittet
und die Nennerordnung erhöht. Das System nach single konvertiert (man
kann glücklicherweise mittlerweile auch Filter Objekte direkt nach
single/double casten, oder auch fixed point wenn man den Fixed Point
Designer hat - habe ich aber nicht ;)) und geschaut, ob es stabil ist.
Weitere Kombinationen von Nenner-/Zählerordnung habe ich aber nicht
probiert, möglich, dass auch andere funktionieren. Zählerordnung sollte
echt kleiner (<) Nenner- sein, sonst wird das System sprungfähig (=)
oder nicht kausal (>).
Es gibt noch einen Haufen anderer Methoden zum fitten/identifizieren von
dynamischen Systemen. Denke "Systemidentifikation" ist das Stichwort.
Und dann halt mit der Systemordnung herumspielen.