Hallo zusammen, ich habe eine Homeautomation Zentrale auf Basis eines Raspberry Pi, eines selbstgebauten RFM69 "Hat", das 868 Mhz funkt. Und auf dem Raspi seit neuestem Docker-Container z.B. mit einer REST-API, die Befehle entgegennimmt und per RFM69 rausfunkt. Warum Docker-Container? Einerseits einfach so, wollte ich immer schon mal machen. Und andererseits um jederzeit schnell mal das Betriebssystem zu tauschen, zu upgraden etc. ohne immer eine komplette Installation aller benötigten Faxen durchführen zu müssen. Docker-Container drauf, fertig. Jetzt würde ich gerne Daten sammeln von Sensoren oder z.B. der aus dem Internet ermittelten lokalen Außentemperatur sowie der dazu ermittelten Vorlauftemperatur der Heizung. Und sie dann in Diagrammen visualisieren. Da würde ich jetzt ein einfaches Framework suchen, das dafür alles schon mitbringt, so wie der ELK-Stack / Kibana für das System Monitoring. https://www.elastic.co/de/products/kibana Gibt's sowas simpel und fertig? Also so in der Art: - DB installieren - Framework installieren - von meinen Python-Scripts die Daten reinschieben - auf eine Url gehen und ankucken Was ich dabei nicht suche sind HA-Frameworks wie OpenHAB oder FHEM, das schaue ich mir unabhängig davon mal an. Vg, Conny
Da habe ich sogar gerade auch gleich selber was gefunden. Der hier macht es genau so wie ich es vorhabe, dass er jede Komponente als eigenen Docker-Container als Microservice startet. Und er benutzt eben gerade Kibana für's Monitoring... https://github.com/sylvek/domotik
Hi, bei mir läuft: Webdfrontend: Grafana Datenbank: influxDB DB_Connector: dooblr MQTT: mosquitto Sensoren: Mittels ESP*, Raspi Die Daten vom Server laufen auch in die Datenbank (DHCP, Apache, Temperaturen usw.)
Blabla schrieb: > Hi, > > bei mir läuft: > > Webdfrontend: Grafana > Datenbank: influxDB > DB_Connector: dooblr > MQTT: mosquitto > Sensoren: Mittels ESP*, Raspi > Die Daten vom Server laufen auch in die Datenbank (DHCP, Apache, > Temperaturen usw.) Hört sich gut an, schaue ich mir an!
Bei mir läuft auch: Grafana & InfluxdDB InfluxDB hat wohl degenerierende Datenbanken wg. Speicherplatz aber Grafana kann auch andere Datenbanken abfragen. Installation und einrichtung war auf dem Pi einfacher als erwartet. :) EDIT: Chronograf hab ich mir auch mal angesehen, war irgendwie das gleiche wie Grafana
Grafana und InfluxDB benutze ich auch, Logik kann man gut in Node Red machen, vor allem wenn man JavaScript mag.
Warum nutzt ihr InfluxdDB? Warum nicht mysql? Kannte InfluxdDB nicht und finde auf die schnelle nichts was dafür spricht... Würde mich über eine kleine Erläuterung freuen.
Dgf schrieb: > Warum nutzt ihr InfluxdDB? Warum nicht mysql? Weil Influxdb exakt für diese Anwendung entwickelt und optimiert wurde. Mysql geht zwar auch, braucht aber für ähnliche Performance viel viel VIEL mehr RAM, Festplattendurchsatz und CPU. Beispiel: Messwert alle 100ms geloggt, du willst einen Trend-Graph über das letzte Jahr. Influxdb lacht über die Query, und gibt dir die Daten in wenigen ms. Mysql rödelt auf der Platte, legt vieleicht noch temporäre Tabellen für's 'group by' und 'sort' an wenn das RAM nicht reicht ... Dafür kannst du Mysql fragen: Wie war der Messewert am 5.5.2015 um 5:55:55.5 Uhr, und kriegst eine exakte Antwort. Influx hat für den Zeitpunkt vermutlich nur noch einen interpolierten Wert.
> Warum nutzt ihr InfluxdDB? Warum nicht mysql?
Speicherplatz ist auf so einem RasPi auch ein Thema,
das SmartHome soll ja ein paar Jahre laufen und möglichst
Wartungsfrei sein.
Und nicht zuletzt: Bei der Google Querry "influxDB defekt"
finden sich keinen Tipps wie sie zu reparieren ist. :)
Geschwindigkeit kann ich bestätigen.
Eine Jahresübersicht aufzurufen lässt einem keine Zeit zum Kaffee holen.
;)
Dann werde ich mir influxDB und Grafana mal ansehen. Mir ist wichtig, dass es kompakt ist, idealerweise ein Docker oder als Docker erstellbar. Habe gerade angefangen meine Home Automation Scripts als Docker zu deployen, klappt prima. Sogar das Thema Start bei Boot und Autostart bei Crash haben sich von selbst erledigt, macht Docker alles. Und der Kernvorteil ist: wenn mir mal die SD oder das OS die Grätsche machen, dann spiele ich ein neues OS drauf, werfe die Docker Container drauf und fertig. Musste historisch nämlich aus wechselnden Gründen meinen Raspi ca. 1x im Jahr neu installieren und das nach einer Setup-Anleitung, die ich mir dafür gemacht habe, für ein paar Stunden. Und davon habe ich die Nase voll. Man kann einen Raspberry Pi nicht als stabiles System betrachten. Und die ganze Installierei ist ein Hemmnis das OS zu aktualisieren und so ist es dann immer Jahre alt... Der Volkszähler sieht zwar funktionell passend aus, scheint vom Setup aber genau so „Frickelkram“ zu sein, was ich nicht wollen würde. Da muss man ja für 2-3h zig Dinge installieren und konfigurieren. Es gibt anscheinend auch noch größere Frameworks als OpenSource, die sogar schon in Docker vorbereitet sind. Nur leider nicht für Raspbian. Und irgendwie sind die auch monströs, schon mit Message Bus und allem, soweit wollte ich (noch) gar nicht.
ThingsBoard ist so ein größeres Teils, das als OpenSource und in Docker kommt: https://thingsboard.io/ Und der Ansatz mit Docker ist wohl nicht nur mir sehr recht. Hier einer der ersten Seiten, wo es einer genau so macht, wie ich mir das vorstelle: http://www.mauroalfieri.it/elettronica/influxdb-grafana-docker-raspberry.html Je InfluxDB und Grafana in einem Docker-Container auf dem Raspi. Allerdings braucht das wiederum die "Hypriot" OS Variante von Raspbian um die Container schon alle fertig dabei zu haben. Auch doof.
Hier ist ein Repo, wo das passende docker-compose.yml schon vorbereitet ist, genau das ist es, was ich suche: https://github.com/gonzalo123/iot.grafana Enthält Grafana, InfluxDB, MQTT/Mosquitto - perfekt. Das werde ich jetzt mal testen. Nach genauerer Durchsicht ist es ein Prototyp, der ein Logging mit Grafana/Influx implementiert, einen Client der etwas über MQTT loggt, ein Alerting durch Grafana und einen Client, der das Alert über MQTT empfängt. Das ist doch ein perfektes Setup für den Start und bringt gleich MQTT mit, was ich mir als nächstes ansehen wollte. Interessanterweise lädt sich das docker-compose die Influx-DB sogar von Hypriot:
1 | $ docker ps |
2 | CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES |
3 | 64cce60f987a pascaldevink/rpi-mosquitto "/bin/sh -c '/usr/sb…" 17 minutes ago Up 16 minutes 0.0.0.0:1883->1883/tcp, 0.0.0.0:9001->9001/tcp moquitto |
4 | 2ec63c3cc098 hypriot/rpi-influxdb "/usr/bin/entry.sh /…" 17 minutes ago Up 16 minutes 0.0.0.0:8083->8083/tcp, 0.0.0.0:8086->8086/tcp influxdb |
5 | 7cbdb72e9824 fg2it/grafana-armhf:v4.6.3 "/run.sh" 17 minutes ago Up 16 minutes 0.0.0.0:3000->3000/tcp grafana |
> Man kann einen Raspberry Pi nicht als stabiles System betrachten.
Ja, blöde Sache...
Ich hab das so gelöst:
einen USB-CardReader in dem eine SD steckt
und der Pi macht alle 3 Tage ein Image auf die 2.SD-Card.
Jetzt muss ich beim Crash nur noch die Karten untereinander
tauschen.(hatte allerdings seit 2 Jahren keinen.)
Wenn mir mal langweilig genug ist werd ich auch was mit Docker basteln..
Daten laufen schon mal rein...
1 | http://<ip>:8086/query?&epoch=ms&db=iot&q=select+*+from+heater&pretty=true |
2 | |
3 | {
|
4 | "results": [ |
5 | {
|
6 | "statement_id": 0, |
7 | "series": [ |
8 | {
|
9 | "name": "heater", |
10 | "columns": [ |
11 | "time", |
12 | "value" |
13 | ], |
14 | "values": [ |
15 | [ |
16 | 1549111616862, |
17 | 63 |
18 | ], |
19 | [ |
20 | 1549112217372, |
21 | 61 |
22 | ], |
23 | [ |
24 | 1549112817883, |
25 | 61 |
26 | ] |
27 | ] |
28 | } |
29 | ] |
30 | } |
31 | ] |
32 | } |
Angehängte Dateien:
Erste Daten werden angezeigt. Läuft! :-)
Conny G. schrieb: > Und der Kernvorteil ist: wenn mir mal die SD oder das OS die Grätsche > machen, dann spiele ich ein neues OS drauf, werfe die Docker Container > drauf und fertig. > Musste historisch nämlich aus wechselnden Gründen meinen Raspi ca. 1x im > Jahr neu installieren und das nach einer Setup-Anleitung, die ich mir > dafür gemacht habe, für ein paar Stunden. Und davon habe ich die Nase > voll. Warum nicht einfach ein Skript schreiben? Dann läuft das ganze voll automatisiert (ohne dieses komische Docker-Geraffel) :-)
Kuehnast schrieb: > Warum nicht einfach ein Skript schreiben? Dann läuft das ganze voll > automatisiert (ohne dieses komische Docker-Geraffel) :-) Das wäre die Alternative, wenn es das Docker-Geraffel nicht gäbe. War früher mal mein langfristiger Plan. Inzwischen hat mich da Docker "überholt". Docker ist einfach cool, weil dann das Installations-Geraffel vom OS getrennt bleibt. Ist ja eigentlich furchtbar, wenn man irgendwas was man macht immer ins Betriebssystem "einbrennen" muss und das ist dann für immer "versaut". Und mit Docker-Geraffel kann ich sogar die verschiedenen Dienste einfach auf verschiedene Raspis deployen, wenn ich das bräuchte.
für InfluxDB gibt es noch ein einfaches Windows Verwaltungswerkzeug mit GUI: https://github.com/CymaticLabs/InfluxDBStudio Wenn man die Tables (Measurements) anlegt ist es wichtig sofort die indizierten Felder als Tags anzulegen. Nachträglich umwandeln oder Felder indizieren wie bei SQL-DB geht nicht. Oder ich habe es nicht gefunden. Für Node Red gibt es fertige Nodes für InfluxDB lesen/schreiben, das macht das benutzen der DB sehr einfach. Die c't hatte diese Kombi auch mal vorgestellt und auch ein Docker Image mit diesen ganzen Komponenten erstellt.
Johannes S. schrieb: > für InfluxDB gibt es noch ein einfaches Windows Verwaltungswerkzeug mit > GUI: > https://github.com/CymaticLabs/InfluxDBStudio Kein Interesse, hab Mac :-) Aber guter Tipp, sollte mal nach einem Tool schauen. > Wenn man die Tables (Measurements) anlegt ist es wichtig sofort die > indizierten Felder als Tags anzulegen. Nachträglich umwandeln oder > Felder indizieren wie bei SQL-DB geht nicht. Oder ich habe es nicht > gefunden. Danke, schaue ich mir an.
Tags braucht es nur, wenn man die Daten nach Tag filtern will. https://docs.influxdata.com/influxdb/v1.7/introduction/getting-started/
1 | Conceptually you can think of a measurement as an SQL table, where the primary index is always time. tags and fields are effectively columns in the table. tags are indexed, and fields are not. The difference is that, with InfluxDB, you can have millions of measurements, you don’t have to define schemas up-front, and null values aren’t stored. |
Also Measurement "Temperatur", aber Tag ist welcher Server usw. Ich habe gerade jede Serie als einzelnes Measurement, da brauche ich noch keine Tags. Als supereinfache UI habe ich gerade gefunden: https://github.com/danesparza/influxdb-ui Das kann man auch über Amazon S3 abrufen: http://influxui.s3-website-us-east-1.amazonaws.com/#/ Und es speichert die Verbindungen also Cookie, ich kann da einfach meine lokale IP eintragen, cool :-)
Conny G. schrieb: > Das wäre die Alternative, wenn es das Docker-Geraffel nicht gäbe. War > früher mal mein langfristiger Plan. Inzwischen hat mich da Docker > "überholt". > > Docker ist einfach cool, weil dann das Installations-Geraffel vom OS > getrennt bleibt. Ist ja eigentlich furchtbar, wenn man irgendwas was man > macht immer ins Betriebssystem "einbrennen" muss und das ist dann für > immer "versaut". Aber wie machst du dann die Konfiguration der Dienste in den Containern? Passt du die ganzen Configs von Hand an? Oder baust du dir eigene, vorkonfigurierte Docker-Images?
Kuehnast schrieb: > Aber wie machst du dann die Konfiguration der Dienste in den Containern? > Passt du die ganzen Configs von Hand an? Oder baust du dir eigene, > vorkonfigurierte Docker-Images? Ja, genau das wäre der Witz davon.
Zum Konzept von InfluxDB ist das interessant zu lesen: https://docs.influxdata.com/influxdb/v1.7/concepts/key_concepts/ Dann wird klar, dass das keine normale SQL-DB ist und was sie von MySQL unterscheiden. "InfluxDB is a time series database."
Conny G. schrieb: > Man kann einen Raspberry Pi nicht als stabiles System betrachten. > Und die ganze Installierei ist ein Hemmnis das OS zu aktualisieren und > so ist es dann immer Jahre alt... Deswegen läuft bei mir inzwischen ein UDOO x86 mit Centos, der verwaltet das ganze Netzwerk und stellt alle Dienste bereit. Einfach ne alte SSD von einem Kaputten Laptop dran und es läuft und läuft und läuft. Ich benutze kein Docker, dafür schreibe ich mir dann lieber systemd skripte. Conny G. schrieb: > Ist ja eigentlich furchtbar, wenn man irgendwas was man > macht immer ins Betriebssystem "einbrennen" muss und das ist dann für > immer "versaut". Für immer versaut ist für Linux ja zum Glück nicht so gegeben wie bei dem Fenster System. Wenn dich das stört solltest du dir mal Fedora Silverblue anschauen. Die bauen einen sozusagen unveränderbaren Systemkern. Werde ich wohl demnächst mal ausprobieren.
Tags: aber wenn man normalisierte Tabellen haben möchte braucht man die. Also zb Temp, Humidity, Messstelle: dann sollte Messstelle auch indiziert sein.
Angehängte Dateien:
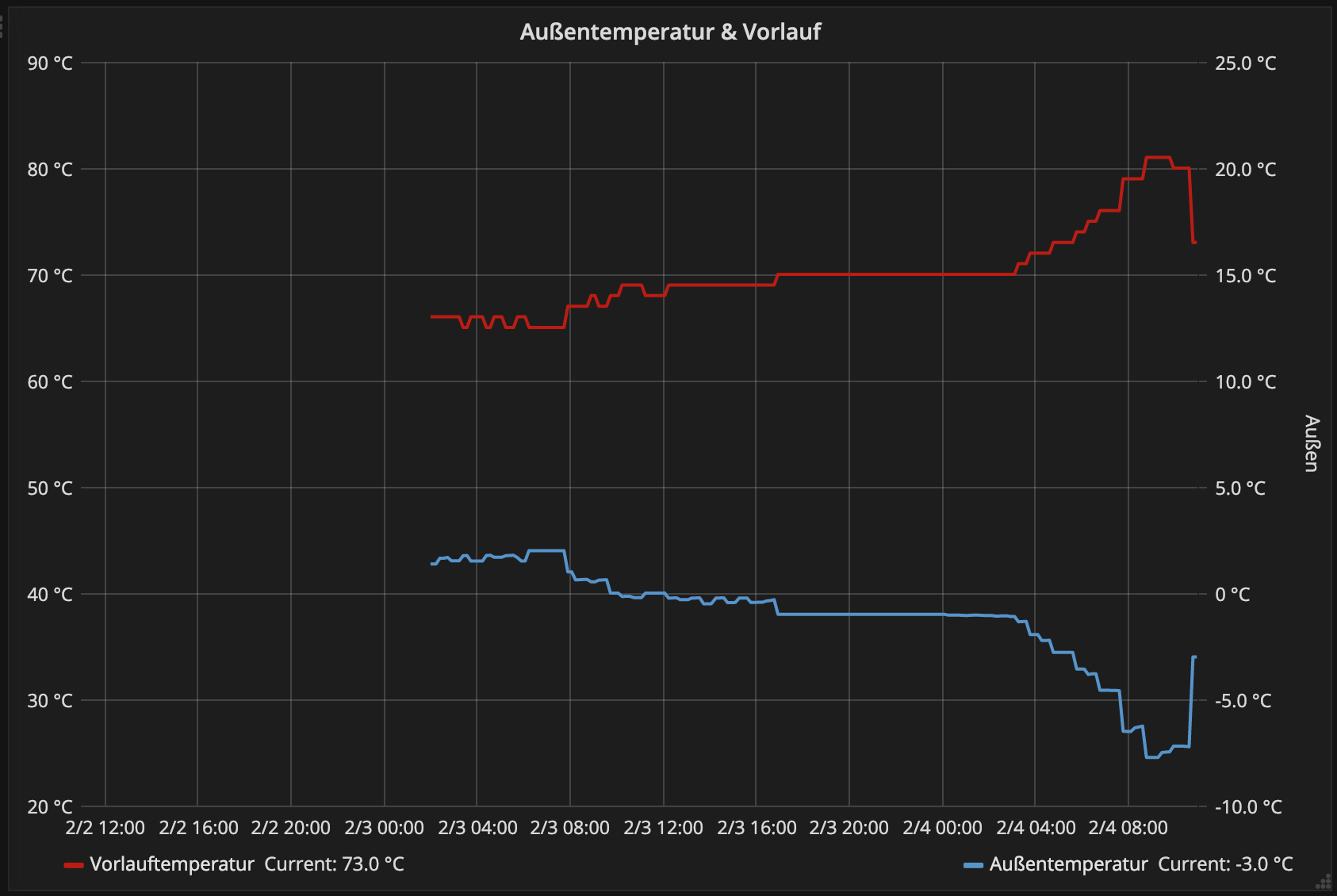


Läuft! Hier ein Temperaturchart meiner Heizungssteuerung für etwas mehr als 1 Tag. Gerade auch dabei die Daten meiner Homematic-Raumthermostaten einzusammeln und zu zeigen. Wenn ich das richtig gesehen habe in den Daten, dann sehe ich sogar die Ventilposition der Heizkörpersteller. D.h. ich kann dann Heizkurve, Vorlauftemperatur und die Öffnungsrate der Ventile pro Zeiteinheit in Bezug setzen und herausfinden, ob meine Vorlauftemperatur zu hoch, zu niedrig oder richtig ist... Das ist spannend. Die Heizungssteuerung besteht aus einer Schaltung mit ATMega 328 und RFM69 Funkmodul, das von der Zentrale (Raspberry Pi mit selbstgebautem Hat für ATMega 328/RFM69) alle 10min eine aktualisierte Vorlauftemperatur durchgefunkt bekommt und entsprechend eine analoge Spannung auf den 789-Port der Vaillant-Heizung gibt. Auf der Zentrale läuft ein Script, das alle 10min das aktuelle Wetter von openweathermap.org abholt und nach passender Heizkurve die richtige Vorlauftemperatur errechnet. Die Steuerung ist seit 1,5 Jahrem in Einsatz, bisher allerdings noch nie so transparent wie jetzt. Schön zuzusehen. Und seit 2 Wochen jetzt auch mit der neuen Heizung, die im Dezember installiert wurde. Denn der Installateur brachte da 700 Euro sündteures Zeugs von Vaillant, das sich nichtmal in die Heizung einbauen hätte lassen, sondern daneben geschraubt worden wäre. Und noch ein Steuergerät für's Aufstellen in irgendeinem Raum. Wofür das. Da wurde es mir dann zu doof - teuer, unpraktisch und unschick - und ich habe den Installateur damit wieder heimgeschickt und erstmal meine Steuerung wiederverwendet. Mit der übrigens auch der Kaminkehrer - der auch der örtliche "Energieberater" zur Überwachung der Energieeinsparverordnung ist - einverstanden. Als nächstes kommt was mit EBus dran, ist gerade in Entwicklung. Voraussichtlich ein "Hat" für einen Raspberry Pi Zero W. Der schickt dann alle Nachrichten vom Bus, die mich interessieren an die Zentrale bzw. setzt die Werte, die die Zentrale hinschickt.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.