Hi, ich habe ein paar Sicherungsfestplatten (z.B. WD-Passwort 1TB) auf denen wichtige Daten liegen (meist in 2 oder gar 3-Facher Ausführung). Nun möchte ich die Platten, welche ansonsten eigentlich nur rumliegen, alle 3-6 Monate überprüfen. Wie kann ich schnell und effizient die Platten überprüfen, muss zwingenderweise der Dateninhalt überprüft werden oder kann auch z.B. SMART ausgelesen werden ... welche Tools eignen sich, womit bin ich schnell und effizient (idealerweise sogar automatisiert) und habe dennoch einen "halbwegs" hohen Standard... => da die einzelne Datei zu 90% (je nach wichtigkeit) so oder so mindestens 3x existiert, will ich hier nicht jede einzelne Datei auf Korrektheit prüfen, sondern lediglich die Platte prüfen.
bärchen schrieb: > will ich hier nicht jede einzelne Datei auf > Korrektheit prüfen, sondern lediglich die Platte prüfen. Das nützt nur leider so gut wie nichts: aus SMART geht natürlich nicht hervor, ob eine bestimmte Datei fehlerfrei lesbar ist, dazu muss man sie eben lesen. Und selbst dann ist das fürs nächste mal nicht garantiert. Dinge gehen nun mal kaputt, nicht nur elektronische. Und zwar vorwiegend dann wenn man nicht damit rechnet. SMART gibt nur eine Abschätzung ob sich die Platte ihrem Lebensende nähert. Kannst du natürlich machen und auffällige Platten vorbeugend ersetzen. Wenn du nicht die Zeit für eine 100%-Prüfung hast musst du damit halt zufrieden sein. Georg
Wenn Du Sicherheit willst legst Du nicht eine Datei dreimal auf eine Platte sondern je einmal auf drei Platten. Damit sollte sich Dein Prüfproblem auch erledigt haben.
SMART hilft hier nicht viel weil die interessanten Werte wie Schwebende-/Wiederzugewisene Sektoren sich nur was im Rahmen von Schreib-/Lesezugriffen was tut. Unter Windows wäre der Reguläre Weg eine "chkdsk" mit den entsprechenden Parametern das alle SeKtoren geprüft werden auszuführen. (und ggf. danach mal die SMART-Werte anschauen ob sich was geändert hat). Das ganze dauert aber schon so einige Zeit Alternativ eine Programm verwenden das für alle Dateien jeweils Prüfsummen generiert und die dann regelmäßig mit den Dateien vergleichen (dabei geht es vor allem darum das alles mal gelesen wird und die Platte dabei feststellen kann ob es irgendwo Probleme gibt). Und nebenbei waist du so auch gleich welsche Dateien du wegschmeißen kannst weil sie eh nicht mehr stimmen.
Das rumliegen schadet weniger, als die häufige Überprüfung. Lieber NUR vor dem aufspielen SMART und Filesystem überprüfen und 1x im Jahr eine vollständige Surface-Prüfung (dauert Stunden!) sollte reichen. Alle auf einen Haufen legen sollte man auch nicht. Besser an drei verschiedenen Orten (Häuser -> Brand etc.) lagern. Hast SSD, kannst du dir das alles sparen. Ausfälle kündigen sich da nur äußerst selten an! Die Tools der Hersteller nutzen, für den vollständigen Test!
bärchen schrieb: > muss > zwingenderweise der Dateninhalt überprüft werden Ja. Wenn Du mehrere Kopien hast und die sind unterschiedlich, welche ist dann die richtige ??? Du brauchst ein Hash-Tool, z.B.: https://github.com/gurnec/HashCheck https://www.digitalvolcano.co.uk/hash.html Ich hatte mal einen defekten RAM-Riegel, der wurde als Cache benutzt während Windows selber im fehlerfreien Riegel lief. Nach diversen Umkopieraktionen waren viele Backups nur noch Schrott.
Peter D. schrieb: > Ich hatte mal einen defekten RAM-Riegel, der wurde als Cache benutzt > während Windows selber im fehlerfreien Riegel lief. Nach diversen > Umkopieraktionen waren viele Backups nur noch Schrott. Verifizierung einschalten und nich so oft hin u. her Kopieren!
bärchen schrieb: > ich habe ein paar Sicherungsfestplatten (z.B. WD-Passwort 1TB) auf denen > wichtige Daten liegen (meist in 2 oder gar 3-Facher Ausführung). bärchen schrieb: > alle 3-6 Monate überprüfen. Wie wäre es mit einem NAS mit RAID5 oder sonstiger Redundanz (x Platten fallen aus und es fehlt trotzdem nix) ? Das lässt sich so einstellen, dass es jeden Monat zu einer bestimmten Zeit aufwacht und einen Selbsttest nach deinem Gusto durchführt. Oder du lässt es manuell an, speicherst deinen Kram und/oder startest einen Test?
NAS schrieb: > NAS mit RAID5 RAID5 ist so "sicher" wie Deine Weihnachtsbaumbeleuchtung. Besser 3 Platten an sicheren Ort legen bevor der Blitz ins NAS einschlagt. :-) HashCheck ?
Das Zauberwort heißt BTRFS. Legt automatisch Checksummen für die Dateien an (Standardmäßig sogar doppelt). Mit einem BTRFS Scrub werden sämtliche Dateien gelesen und mit den Checksummen verglichen.
Linux mit fsck, (bzw. der extended filesystemcheck) prüft und repariert falls möglich verschiedene Filesysteme.
georg schrieb:> > SMART gibt nur eine Abschätzung ob sich die Platte ihrem Lebensende > nähert. Das ist nicht ganz richtig. Es gibt den Smart Extended self-test, den kann man bei smartctl mit der Option "-t long" starten und der macht dann einen Test der gesamten Plattenoberfläche. Wenn er fehlerhafte Sektoren findet, dann registriert er das in seinen Smartdaten und sucht nach einem freien Sektor, wo er die Daten dann hinkopiert. Der Nachteil des Smart Extended Test ist, dass er das Dateisystem nicht versteht. Es ist daher besser einen Test der Festplatte auf Dateisystemebene zu machen, da manche Dateisysteme wie bsw. zfs oder btrfs zusätzliche Metadaten speichern und Fehler daher erkennen und teilweise auch reparieren können. Für letzteres empfiehlt sich eine RAID Kombination. bärchen schrieb: > Wie kann ich schnell und effizient die Platten überprüfen, muss > zwingenderweise der Dateninhalt überprüft werden oder kann auch z.B. > SMART ausgelesen werden ... welche Tools eignen sich, womit bin ich > schnell und effizient (idealerweise sogar automatisiert) und habe > dennoch einen "halbwegs" hohen Standard... Du wirst nicht darum herum kommen, regelmäßíg alle Daten zu überprüfen. Zeit sparen kannst du durch die Prüfung auf Dateiebene, anstatt auf eben des gesamten Dateisystems oder der gesamten Festplattenoberfläche, da auf Dateiebene nur das geprüft wird, was auch als Datei vorhanden ist. Bei einer nur zu 10 % vollen Festplatte, bedeutet das also 1/10 weniger Arbeit. Gänzlich drumherum kommst du aber um diese Prüfung nicht, wenn du wirklich wissen willst, ob die Dateien kaputt sind oder nicht. Mit einem Kurztest z.B. per smartctl -t short kriegst du nur heraus, ob die Festplatte ansich noch funktioniert, nicht aber, ob jeder mm² auf der Platte die Daten noch richtig speichert oder speichern kann. Manche Dateisysteme bieten sogar die Option des scrubbing an. Dabei werden die Daten gelesen und an anderer Stelle neu geschrieben. Dadurch erneuert sich die Magnetisierung für die zu speichernden Daten.
Peter D. schrieb: > Ich hatte mal einen defekten RAM-Riegel, der wurde als Cache benutzt > während Windows selber im fehlerfreien Riegel lief. Nach diversen > Umkopieraktionen waren viele Backups nur noch Schrott. Das schöne an ECC RAM ist, dass es so etwas verhindern hätte können.
mehrere festplatten zum sichern, mindestens eine davon an einem anderen ort gelagert. den inhalt der platten mit einem geeigneten checksummenprogramm prüfen. google liefert z.b. https://superuser.com/questions/1133078/how-to-checksum-and-verify-all-files-on-a-filesystem
c.m. schrieb: > den inhalt der platten mit einem geeigneten checksummenprogramm prüfen. Checksummen können allerdings nur kaputte Daten erkennen, sie können kaputte Daten nicht wiederherstellen oder rekonstruieren. Dafür braucht man so Dateisysteme wie Btrfs oder besser ZFS. Auf Dateiebene gibt es noch Archivformate die die Daten mit Redundanz speichern können. Bei denen kann man dann die Daten auch rekonstruieren, wenn etwas verloren wurde. Der Platzbedarf ist damit aber höher. PAR2 kann das zum Beispiel. https://de.wikipedia.org/wiki/PAR2
Nano schrieb: > Checksummen können allerdings nur kaputte Daten erkennen, sie können > kaputte Daten nicht wiederherstellen oder rekonstruieren. > so Dateisysteme wie Btrfs oder besser ZFS. Deine auf Dateiebene heimlich reparierte Daten könnten aber auch einen Fehler haben, der erst durch DIE falsche Checksumme auffällt (siehe Beispiel RAM-Fehler oben)? Es ist jedenfalls nicht schädlich, im Zweifel die Prüfsummen schnell zu vergleichen, um Differenzen zu finden.
oszi40 schrieb: > Nano schrieb: >> Checksummen können allerdings nur kaputte Daten erkennen, sie können >> kaputte Daten nicht wiederherstellen oder rekonstruieren. >> so Dateisysteme wie Btrfs oder besser ZFS. > > Deine auf Dateiebene heimlich reparierte Daten könnten aber auch einen > Fehler haben, der erst durch DIE falsche Checksumme auffällt (siehe > Beispiel RAM-Fehler oben)? Es ist jedenfalls nicht schädlich, im Zweifel > die Prüfsummen schnell zu vergleichen, um Differenzen zu finden. Dateisysteme die die Fehler reparieren können, enthalten selbst schon Prüfsummen um die Fehler zu erkennen und dann die Reparatur anzustoßen. Ein weiterer Prüfsummenvergleich ist also unnötig, wenn man die Prüffunktion des Dateisystems verwendet. Und wenn dein RAM kaputt ist, können deine Prüfsummen auch gaga sein. Es ist sogar möglich, dass eine korrekte Datei als fehlerhaft gemeldet wird, weil wegen dem kaputten RAM die Berechnung nicht stimmt.
qwerzuiopü+ schrieb: > Das Zauberwort heißt BTRFS. Legt automatisch Checksummen für die Dateien > an (Standardmäßig sogar doppelt). Mit einem BTRFS Scrub werden sämtliche > Dateien gelesen und mit den Checksummen verglichen. Also meine letzte Backup-Festplatte mit btrfs hat ja als ich mal ein Backup haben wollte die Herausgabe desselben mit einem Segfault des btrfs-Kernel- Treibers quittiert ... btrfs ist zwar hip, aber wenn es (wie bei Backups) auf Zuverlässigkeit ankommt, würde ich eher zu was anderem greifen.
Sven B. schrieb: > btrfs ist zwar hip, aber wenn es (wie bei Backups) auf Zuverlässigkeit > ankommt, würde ich eher zu was anderem greifen. Aus dem Grund hat Red Hat den Support für btrfs wieder entfernt. Meine Empfehlung wäre daher zfs.
zfs ist halt auch irgendwie ziemlich unhandlich mit diesen Pools und so ... für externe Festplatten im Hausgebrauch ist das definitiv nicht entworfen. Ich würd' einfach ext4 nehmen und rsync oder so. rsync kann auch einen Haufen Checksum-Kram um Integrität sicherzustellen.
Sven B. schrieb: > rsync kann > auch einen Haufen Checksum-Kram um Integrität sicherzustellen Der sichert aber nur die Übertragung ab. Gegen bit-rot(*) helfen nur zusätzlich gespeicherte Prüfsummen/Korrektur-Codes, egal ob nun im Dateisystem integriert oder extern. *) Von 10^14 gelesenen Bits ist im Schnitt eins falsch.
Moin, hier geht vieles durcheinander. Bei externen Festplatten treten Fehler im Dateisystem ohne Hardwaredefekte m.E. nur extrem selten auf. Einzelne Sektorfehler (die von SMART erkannt werden können) treten auch nur selten auf, wenn es sie gibt, dann wird es aber allerhöchste Eisenbahn die Platte zu tauschen... Wesentlich wahrscheinlicher ist, daß sich Platte nach längerer Zeit gar nicht mehr nutzen läßt (Elektronik defekt). Daher würde ich die Platten 1-2x pro Jahr einige Stunden laufen lassen und spätestens nach drei Jahren alle Daten auf eine neue Platte umkopieren. Oder noch besser: jährlich 1x Kopie auf eine neue Platte. Wenn die Datenmengen klein sind, ggf. auch DVD als Medium nutzen. Wir hatten fünf Sicherheitskopien auf drei externen USB-Platten. Als diese nach mehreren Jahren benötigt wurden, stellte sich heraus, daß keine der drei Platten mehr funktionierte. Eine der Platten haben wir zum professionellen Datenretter geschickt, aber ohne Erfolg. Eine haben wir kaputtrepariert und eine wollte absolut nicht mehr. Daten verloren! Glücklicherweise hatte ich einen größeren Teil der Daten noch auf Magnetband. RAID hilft nur gegen technische Ausfälle und erhöht die Verfügbarkeit, ersetzt aber kein echtes Backup. Mein Tip: wenn RAID, dann nur mit echtem Controller. Grundsätzlich gilt aber: besser ein Backup auf einem unzuverlässigen Medium als gar keines. ;-))
svensson schrieb: > Bei externen Festplatten treten Fehler im Dateisystem ohne > Hardwaredefekte m.E. nur extrem selten auf. Das ist nicht richtig. Die Daten verrotten dir durch Bitrot. D.h. sie verlieren mit der Zeit bei einzelnen Bits ihre Magnetisierung. In der Gesamtbetrachtung ist die Demagnetisierung durchaus gering, aber einzelne Bits trifft es halt schon und dann sollte das Dateisystem in der Lage sein, dies zu erkennen und zu reparieren. ZFS und Btrfs können das. > Wir hatten fünf Sicherheitskopien auf drei externen USB-Platten. Als > diese nach mehreren Jahren benötigt wurden, stellte sich heraus, daß > keine der drei Platten mehr funktionierte. Wie wurden diese gelagert? Vertikal oder horizontal? > Mein Tip: wenn RAID, dann nur mit > echtem Controller. Dem widerspreche ich bei wichtigen Daten entschieden. Wenn RAID, dann mit ZFS ein zraid. Ein echter Controller macht nur dann Sinn, wenn Leistung über Sicherheit steht, aber dann kann man heutzutage auch SSDs nehmen.
Tastenklopper schrieb: > *) Von 10^14 gelesenen Bits ist im Schnitt eins falsch. Maximal eines. Das ist eine zugesicherte Eigenschaft des Disk-Herstellers, kein real zu beobachtender Wert. Die Übersetzung dieser recht verschlüsselten Aussage eines Datasheets in beobachtbares Verhalten von Disks ist dann nochmal ein ganz eigenes Thema.
svensson schrieb: > Mein Tip: wenn RAID, dann nur mit > echtem Controller. Auf garkeinen Fall! Ich mach das nun schon seit Jahrzehnten in etwas größeren Dimensionen, und wenn wir einen Storage-Bezogenen Ausfall/Downtime hatten, war IMMER, ja !!!IMMER!!! ein Hardware-Raidcontroller schuld. Platten sind nunmal Verschleißteile, da tauscht man schon mal eine aus. Super wenn der Raid-Controller das wohl nicht im Hot-Plug vorsieht... Neue Platte rein, Controller fängt nicht etwa das rebuilden an, nein, er schmeißt zusätzlich alle anderen Platten aus dem Verbund, die an derselben Backplane-Zeile hängen. Genial. Dann hilft das Raid6 aus 22Platten+2HotSpare auch nicht. Anderer Controller: verliert beim Reboot einfach so seine NVRAM-Config, meint er hätte lauter leere Platten vor sich. Hersteller-Support verrät dann eine geheime Buchstaben-Kombination, die man in das Ziffern-Only Passwort-Feld eintragen kann um in den Maintainer-Haxxor-Modus zu kommen... da das Raid "ohne Formatierung" neu aufbauen, und Daumen drücken, dass die Platten noch in derselben Reihenfolge stecken wie das beim ersten Initialisieren mal war... Anderer (schweineteurer) Controller: wurde mit super-billigem Ramsch-Speichermodul geliefert. Ohne funktionierendem ECC. Da hilft auch die Battery-Backup-Unit nix, Daten sind halt im A****. Toll wenn man das erst nach einer vollständigen Rotation der Backupmedien merkt. Anderer Controller: Raid-Rebuild bricht ab, wenn das Hostsystem viel Datendurchsatz hat, und würde im nächsten Versuch wieder bei 0% anfangen. Perfekt. Wenn ich für einen Plattentausch das System zwei Tage offline nehmen muss, ist es mit der RAID-Verfügbarkeit nicht weit her. Anderer Controller: Hat es mal fertig gebracht, beim Rebuild die Daten von der leeren, neuen Platte auf die anderen zu "übertragen". Ursache war wohl: Platte wurde im ausgeschalteten Zustand gewechselt, der Controller kann nur Hot-Plug... usw, usf... Mit Software-Raid hast du (zumindest unter Linux) all diese Probleme nicht, und das bisschen XOR machen aktuelle CPUs einfach so nebenbei. Und wenn wirklich etwas schlimm schief geht (meist: wegen Fehlbedienung), dann hat mdadm jede Menge "--force","--i-know-what-im_doing" - Optionen... Mit "examine" kannst du den Zustand der einzelnen Raid-Member abfragen, damit ohne Stochern im Nebel herausfinden wo das Problem liegt, die Scherben zusammenkehren, "assemblen", läuft wieder, scrub-lauf drüber, fertig.
A. K. schrieb: > Maximal eines. Das ist eine zugesicherte Eigenschaft des > Disk-Herstellers, kein real zu beobachtender Wert. Hab den leider schon oft real beobachtet. Bei Server-Platten ist's mit 10^15 etwas besser. Die Hersteller tunen die Platten schon recht exakt auf "knapp besser" als der angegebene Wert. Grund: Ohne Fehlerkorrektur könnten aktuelle Platten kein einziges Megabyte mehr fehlerfrei lesen. Wieviele Fehler nach der FEC übrigbleiben, ist Einstellungssache, man kann ja mehr oder weniger Plattenplatz für Reperaturinformationen opfern. Ist ein einigermaßen feinfühliges Stellrad in der Firmware, und die Hersteller haben, Kapitalismus sei Dank, durchaus Grund das voll auszureizen. und Reklamationen von Consumer-Platten wegen erhöhten Bitrot müssen sie eher nicht fürchten. Bis der Anwender seine Platte für eine aussagekräftige Statistik oft genug überschrieben&gelesen hat, ist die Garantie eh abgelaufen.
Tastenklopper schrieb: > Hab den leider schon oft real beobachtet. Ich nicht. Bei über die Jahre mittlerweile dreistelliger Anzahl SATAs in Storage-Systemen, mit regelmässiger Überprüfung.
Hallo Peter D., Peter D. schrieb: > Ich hatte mal einen defekten RAM-Riegel, der wurde als Cache benutzt > während Windows selber im fehlerfreien Riegel lief. Nach diversen > Umkopieraktionen waren viele Backups nur noch Schrott. wie hast Du das geschafft, einen Speicherriegel explizit dem Cache-Betrieb zuzuteilen?
Peter M. schrieb: > wie hast Du das geschafft, einen Speicherriegel explizit dem > Cache-Betrieb zuzuteilen? Ich vermute mal, Windows nimmt sich erstmal den RAM, den es benötigt und alles dahinter nimmt es als Cache. Jedenfalls lief Windows trotz des fehlerhaften Riegels problemlos. Nur durch die zerstörten Dateien habe ich gemerkt, daß ein Riegel Rotte ist. Filme hatten plötzlich Bildstörungen. Ein Speichertest hat es dann bestätigt. Über den Gag mit ECC habe ich herzlich lachen müssen, sowas hat ein normaler PC nicht.
Wer von euch hatte mal auf einer Backup Festplatte Lesefehler - ausgenommen sind offensichtliche Defekte, wo man die Platte direkt wegwirft. Also mir ist das noch nie passiert.
Stefanus F. schrieb: > Wer von euch hatte mal auf einer Backup Festplatte Lesefehler - > ausgenommen sind offensichtliche Defekte, wo man die Platte direkt > wegwirft. > > Also mir ist das noch nie passiert. Ich hatte schon Bilder, die nur noch eine graue Fläche waren, Videos mit Bildfehlern u.ä. Ob "Bitrot" oder ein anderer Fehler lässt sich dann aber oft schwer nachvollziehen.
Peter D. schrieb: > Über den Gag mit ECC habe ich herzlich lachen müssen, sowas hat ein > normaler PC nicht. Dann lache ich über dich, denn diese PCs kannst du von der Stange kaufen. Da ist nichts spezielles zu dem der Normalsterbliche Privatmensch keinen Zugang hätte. Aber man muss es natürlich auch wollen. Das viele Konsumerzeugs kaufen ist klar, aber Konsumerzeugs ist kein Maß für "normal", wenn man problemlos ne Workstation mit ECC RAM erwerben kann ist die genauso "normal".
> Mein Tip: wenn RAID, dann nur mit echtem Controller.
Das sehe ich anders. Zumindest für Linux gibt es nichts besseres als
mdadm Software-RAID.
> Linux, Linux Ich rede grundsätzlich von einem Mischnetzwerk, in dem sich mindestens 50% Windows Server befinden. Das SW-RAID von Windows ist - zumindest auf älteren Versionen - eine Krücke. Noch schlimmer sind die Raidfunktionen, die das Mainboard anbietet. Das ist wie ein Ü-Ei - da sieht man erst später, was drin ist... Bei den RAID-Controllern hatte ich höchst selten Probleme. Platte defekt, HotSpare übernimmt, neues HotSpare hinein und gut ist. Außerdem benötigt man ab einer gewissen Anzahl an Platten ohnehin einen Controller, der genügend Kanäle bietet. > kein HotPlug Einen Controller, der das nicht beherrscht, würde ich nicht als "richtigen" RAID-Controller bezeichnen wollen. Aus Kostengründen habe ich aber auch schon Geräte gekauft, die keine Wechselrahmen hatten - dann muss die Kiste ausgeschaltet werden, um die Platten zu tauschen. Geht auch bei nachrangigen Systemen.
svensson schrieb: >> Linux, Linux > > Ich rede grundsätzlich von einem Mischnetzwerk, in dem sich mindestens > 50% Windows Server befinden. Linux installieren, libvirt/qemu installieren, alle Hardwaredevices ausser die Festplatten durchreichen, festplatten in mdadm Raid packen, Windows in der qemu Emulation auf dem md installieren, fertig. Und du bekommst Snapshots gratis dazu!!!
so, jetzt schalte ich mich mal wieder ein :=) ja, der Urlaub war gut :] ... wir sprechen hier von etwa 1,5TB Daten, das ganze sind Archivdaten, d.h. ein "spontaner" Zugriff wird nicht benötigt (wenn überhaupt die Daten jemals wieder gebraucht werden), dennoch halte ich mich an der 10 Jährigen Aufbewahrungspflicht. Klar habe ich die Daten auf mehreren Festplatten verteilt und nicht auf einer Kopiert ^^, aber die meisten haben das hier auch verstanden. Ebenso sind die Festplatten nicht im selben Gebäude und das sogar fern vom Strom. Die Inhalte der Festplatten sind Identisch und sollte mal eine Kaputt gehen, soll auch nichts repariert werden, sondern lediglich eine Kopie der beiden anderen (nicht defekten Platten) angelegt werden. Über einen tausch alle 2 Jahre habe ich ebenso nachgedacht, sind aber kosten welche ich eigentlich nur "ungern" tragen möchte (wenn dies aber notwendig ist, dann ists eben so). ... ich werde die unterschiedlichen Möglichkeiten mal antesten. Vermutlich lege ich einfach auf jeder platte noch die Checksums an und werde die beim testen immer mit den Daten selbst vergleichen...
Hallo Bärchen, zum Überprüfen, bzw Vergleichen der HDD gibt es z.B WinDiff, oder WinMerge. So mache ich das mit meinen BachUp's. Habe aber auch die Erfahrung gemacht, dass Festplatten, derzeit eine 80GB Maxtor nur durchs Nichtgebrauchen gestorben ist. Unzählige Sektoren nich mehr lesbar, usw. Also worauf man heutzutage setzt um langfristig BackUp's zu haben, weiß ich nun nicht mehr.
Thomas schrieb: > Habe aber auch die Erfahrung gemacht, dass Festplatten, derzeit eine > 80GB Maxtor nur durchs Nichtgebrauchen gestorben ist. Unzählige Sektoren > nich mehr lesbar, usw. Solch kleine Platten stammen wahrscheinlich noch aus dem vorigen Jahrtausend. Wichtige Daten sollte man besser alle 10 Jahre auf neue Platten überspielen.
@ Peter D. > Solch kleine Platten stammen wahrscheinlich noch aus dem vorigen > Jahrtausend. Wichtige Daten sollte man besser alle 10 Jahre auf neue > Platten überspielen. Und damit meinst Du, wäre das Problem passe? Platten mit 1 TB oder Größer sind hier wesentlich empfindlicher. Habe schon bei 1,5 TB WD Green und 6 TB (fast neu) Ausfälle gehabt. Aktuelle Platten geben Dir keine Sicherheit. WD-Red hatte z.B. mit Einführung der 3TB riesen Probleme mit der Firmware, wo z.B der LoadCycleCounter immens hochgezählt hat, und die HDD binnen 2 Monaten 'Schrott' war. Welchen Irrtum unterliegst Du, dass heutige Platten je das 10. Jahr erreichen?
Thomas schrieb: > Habe > schon bei 1,5 TB WD Green und 6 TB (fast neu) Ausfälle gehabt. Mir ist seit 1990 nur eine 120MB HDD im Notebook nach einer Bahnfahrt kaputt gegangen, vermutlich lag es am Dauermagneten im Klapptisch. Alle anderen laufen noch bzw. liefen bis zu ihrer Verschrottung. Ich bevorzuge günstige HDDs von Seagate, z.B. ST8000AS0002 (SMR, 8TB), STDR4000901 (2,5" extern 4TB).
Na dann lass mal Crystal Disc über Deine Platten laufen. Mal sehen, was dann ist. Es gab Serien von Maxtor mit 80 GB - Diamond Max, die waren schneller tod, als voll geschrieben. Hatte früher Vertrauen zu WD, aber selbst hier mit den Firmware-Bug .... Und wenn jetzt aufkommt - RAID ?! - RAID macht ausschließlich Redundanz, und gewährleistet Verfügbarkeit, aber ist kein BackUp. Deine 4 TB und 8 TB (...Wolf ?) überleben vieleicht knapp die Garantie.
bärchen schrieb: > wir sprechen hier von etwa 1,5TB Daten, das ganze sind Archivdaten, > d.h. ein "spontaner" Zugriff wird nicht benötigt (wenn überhaupt die > Daten jemals wieder gebraucht werden), dennoch halte ich mich an der 10 > Jährigen Aufbewahrungspflicht. Also Langzeitarchivierung. Dafür sind Bandlaufwerke quasi prädestiniert mit postulierter 30-Jahre-Haltbarkeit der Bänder. Ein LTO-5 Band würde deine 1,5TB Daten aufnehmen (komprimiert noch mehr). Also einfach 2 oder 3 Bänder jeweils mit deinen Daten bespielen und ab in den feuerfesten Tresor, ins Bankschließfach oder unters Kopfkissen. Festplatten sind nicht dazu gedacht, spezifiziert und gebaut, um monate- oder jahrelang stromlos rumzuliegen. Die haben es am liebsten, wenn sie ständig am Strom hängen und ihre Platter sich drehen.
Thomas schrieb: > Na dann lass mal Crystal Disc über Deine Platten laufen. Mal sehen, was > dann ist. Siehe Anhang. Was kann man daraus erkennen?
Angehängte Dateien:
-

WD30_-_Smart.PNG
29 KB
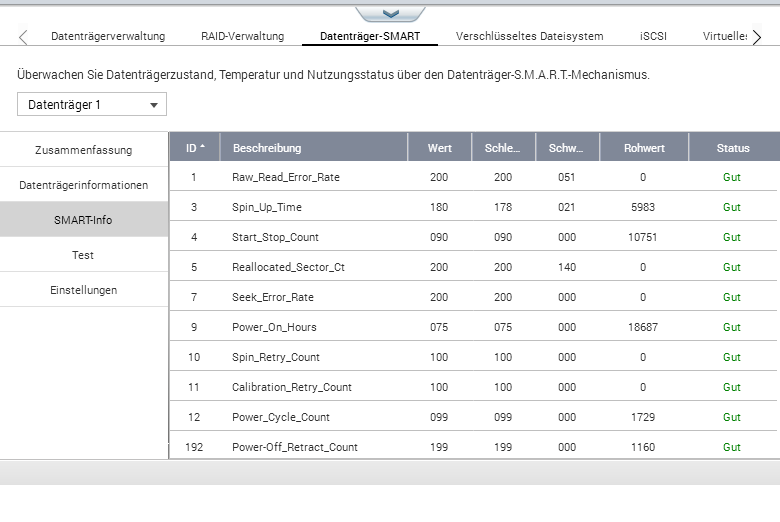
Hallo Peter, Dann sieh Dir mal folgendes an: ID Cur Wor Thr RawValues(6) Attribute Name 01 118 _99 __6 00000A6304A8 Lesefehlerrate -- <<<< sollte 0 sein 03 _91 _91 __0 000000000000 Mittlere Anlaufzeit 04 _96 _96 _20 000000001142 Start/Stopp-Zyklen der Spindel 05 100 100 _10 000000000000 Wiederzugewiesene Sektoren 07 _57 _45 _30 002A0178AE97 Suchfehler -- <<<< sollte 0 sein ID Cur Wor Thr RawValues(6) Attribute Name 01 117 _99 __6 000007749AE0 Lesefehlerrate -- <<<< sollte 0 sein 03 _90 _90 __0 000000000000 Mittlere Anlaufzeit 04 _98 _98 _20 000000000B32 Start/Stopp-Zyklen der Spindel 05 100 100 _10 000000000000 Wiederzugewiesene Sektoren 07 _75 _60 _30 000102647ED1 Suchfehler -- <<<< sollte 0 sein 09 _98 _98 __0 000000000810 Betriebsstunden Deine Platten sind nicht mehr heil. Eigentlich sollten beide Platten unter Status nicht mehr grün sein. Habe gerade meine HDD' nachgeschaut. Hier sind Lesefehlerrate - auf 0 Suchfehler - auf 0 Bild anbei. Solltest Dich mal um Deine Platten kümmern !!!
Thomas schrieb: > 01 118 _99 __6 00000A6304A8 Lesefehlerrate -- <<<< sollte 0 sein Thomas schrieb: > 07 _57 _45 _30 002A0178AE97 Suchfehler -- <<<< sollte 0 sein Thomas schrieb: > 01 117 _99 __6 000007749AE0 Lesefehlerrate -- <<<< sollte 0 sein Thomas schrieb: > 07 _75 _60 _30 000102647ED1 Suchfehler -- <<<< sollte 0 sein Thomas schrieb: > Deine Platten sind nicht mehr heil. Eigentlich sollten beide Platten > unter Status nicht mehr grün sein. Und weil du das als Ahnungsloser meinst soll er seine Platten entsorgen? Nicht jeder Hersteller versteckt diese Werte nur um den Besitzer nicht zu überfordern mit der nackten Wahrheit. Grüner geht der Status nun wirklich nicht. Peter D. schrieb: > Was kann man daraus erkennen? Deinen Platten gehts gut. Seagate zeigt die von Thomas bemengelten Fehler wahrheitsgemäß an. Transparenz sollte man nicht schlimm finden.
Bei Seagate bedeuten die beiden 48 Bit Werte folgendes: Die höheren 16 Bit sind die Fehleranzahl, die restlichen 32 Bit die Anzahl der Vorgänge. Es ist also normal, daß die unteren 32 Bit im Betrieb ständig hochzählen. Ein Suchfehler bedeutet, daß der Kopf nochmal positioniert werden mußte. Bei HDDs mit hoher Spurdichte kann das mal passieren und ist kein Zeichen eines bevorstehenden Ausfalls.
Peter D. schrieb: > Bei HDDs mit hoher Spurdichte kann das mal passieren und ist kein > Zeichen eines bevorstehenden Ausfalls. Richtig. Es gibt keine optische und keine magnetische Datenaufzeichnung die beim lesen ohne eine Fehlerkorrektur auskommt.
Dass es nur bei Seagate anders ist, wusste ich nicht. Ich habe nicht geschrieben, dass er die 'schrotten' soll, sondern nur sich darum kümmern, wieseo der Zähler nicht null ist. Neu-formatieren hilft unter umständen. Ich VERBIETE MIR HIER ABER EINES - BELEIGUNG - Lasste eure verbalen Sprüche wo anders. Wenn alle anderen nicht auf eurem Niveau sind, so behandelt sie trotzdem nicht abwürfig. Ich weiß nicht, warum sich dieses Forum zu einem 'so schlechten' Portal entwickelt hat, wo das Benehmen 'unter der Gürtellinie' ist, und andere sofort angegriffen werden. VERSTANDEN !!!
Thomas schrieb: > Dass es nur bei Seagate anders ist, wusste ich nicht. Keiner weiß alles, nicht schlimm also. Thomas schrieb: > Neu-formatieren hilft unter > umständen. Ich müsste jetzt "Blödsinn" schreiben, lasse es aber. Thomas schrieb: > Ich VERBIETE MIR HIER ABER EINES - BELEIGUNG - Lasste eure verbalen > Sprüche wo anders. Eine Aussage von dir, daß du die Werte seltsam findest und diese bei deinen (hier Hersteller eintragen)-Platten auf 0 steht hätte die Formulierung "Ahnungsloser" (welche dir nicht Dummheit unterstellt!) verhindert. Thomas schrieb: > VERSTANDEN !!! Und das machts nicht besser. Also komm wieder runter.
Hallo Peter D., Peter D. schrieb: > Bei Seagate bedeuten die beiden 48 Bit Werte folgendes: > Die höheren 16 Bit sind die Fehleranzahl, die restlichen 32 Bit die > Anzahl der Vorgänge. Es ist also normal, daß die unteren 32 Bit im > Betrieb ständig hochzählen. > > Ein Suchfehler bedeutet, daß der Kopf nochmal positioniert werden mußte. > Bei HDDs mit hoher Spurdichte kann das mal passieren und ist kein > Zeichen eines bevorstehenden Ausfalls. ich kaufe zwar keine Seagate-Platten, aber vielen Dank für die Decodierung der proprietären SMART-Darstellung!
Peter D. schrieb: > Mir ist seit 1990 nur eine 120MB HDD kaputt gegangen Wer bloß eine hat, wird damit keine große Statistik machen können. Im letzten Jahrtausend hatte ich eine ganze Kiste 20GB mit Serienfehler. Unabhängig von diesem Fall gab es Platten, die ohne Ankündigung blitzschnell gestorben sind und welche die mit vielen SMART-Fehlern noch ewig gelaufen wären. Meine Erkenntnis daraus ist, daß man nicht so viele aus der gleichen Serie haben sollte.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.