Hallo Programmierer!
Ich wollte schnell eine SW schreiben, die mir die kürzesten Verbindungen
berechnet. Aber ich komme momentan nicht weiter, bzw. weiss die
entsprechenden Begriffe nicht zum Suchen.
Konkret möchte ich eine G-Code Datei so ummodeln, dass ich pro Lage
immer die kürzesten Leerfahrten habe. Leider musste ich feststellen,
dass die gängigen Slicer da ein bisschen chaotisch sind, und z.B. für
eine winzige Ecke über das ganze Stück fahren um danach wieder
zurückzufahren.
Dazu lese ich die Datei ein und separiere Header (inkl. Brim/Raft/Skirt)
und Footer, den Rest kommt Lagenweise in eine Struktur, die ich momentan
folgendermassen aufgebaut habe:
1
StructureEbene
2
Reihenfolge.w
3
Koordinaten_Anfang.f[2]
4
Koordinaten_Ende.f[2]
5
Zeilen.s[100]
6
EndStructure
Das Parsen war anspruchsvoll, aber interessant und erfolgreich. Es kam
zugute, dass der Slicer vor jeder Leerfahrt ein "G92 E0" macht, also den
Extruder auf 0 setzt. So kann ich alles schön separieren und beliebig
wieder zusammensetzen.
In der Struktur behalte ich im ersten Feld die letzte Koordinaten vor
dem Lagenwechsel (Koordinaten_Ende.f), und möchte danach die insgesammt
kürzesten Verbindungen jeweils von Koordinaten_Ende.f zu
Koordinaten_Anfang.f des nächsten Feldes berechnen. Ich würde dann die
optimale Reihenfolge in Reihenfolge.w einsetzen und dann die Datei
entsprechend wieder zusammensetzen. Hier stehe ich aber an.
Die Distanz berechne ich mit:
1
Sqr(Pow(x2-x1,2)+Pow(y2-y1,2))
Ich verwende PureBasic, sollte höchstens wegen der Syntax relevant sein.
Problematik ist hier geschildert:
https://reprap.org/forum/read.php?247,821852
Danke und Gruss Chregu
Edit: Sollte wohl eher in "PC-Programmierung"
Naja einen Algorithmus dafür zu schreiben, der das mit wenigen Punkten
schafft, ist einfach. Schwierig wirds, wenn man eine große Anzahl an
Punkten hat und die Aufgabe in endlicher Zeit abgeschlossen sein soll.
Dirk K. schrieb:> Um wieviele Distanzen pro Lage geht es denn?
Vielen Dank für Eure Antworten! Es handelt sich um die 60-70 Distanzen
pro Lage.
Thomas F. schrieb:> Das ist das klassische Handlungsreisenden-Problem, oder auch Travelling> Sales Man Problem.
Danke, das war wohl das Stichwort. Etwas ernüchternd...
Die Unterschiede sind wohl:
-der Endpunkt muss nicht mit dem Startpunkt zusammenliegen, und
-die einzelnen Strecken sind nicht zusammenhängend
Bisher dachte ich, man kann vom ersten Anfang die Distanzen zu allen
Enden berechnen und dann die Kürzeste nehmen, dann der nächste Anfang
usw.
Aber die letzten Distanzen könnten ja wieder sehr lange werden.
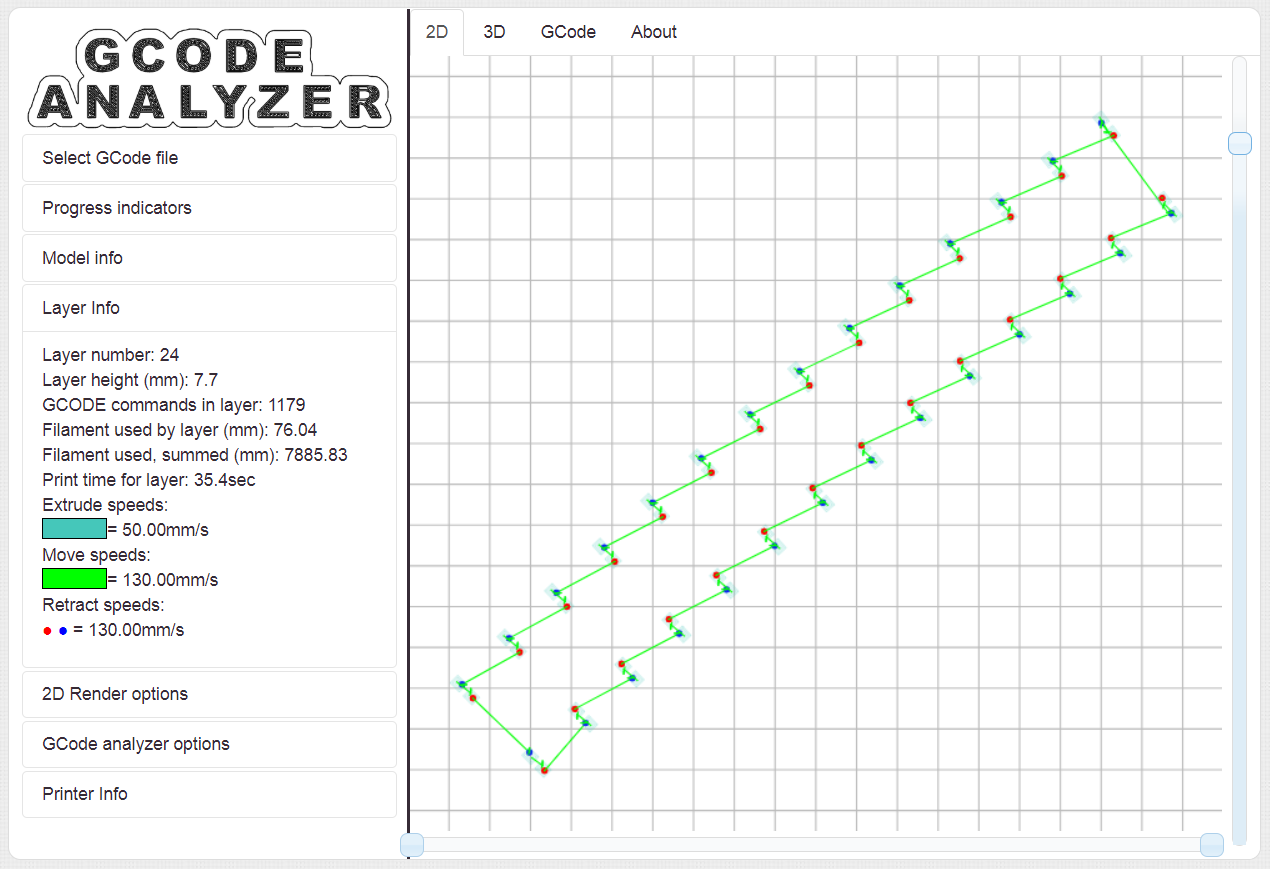
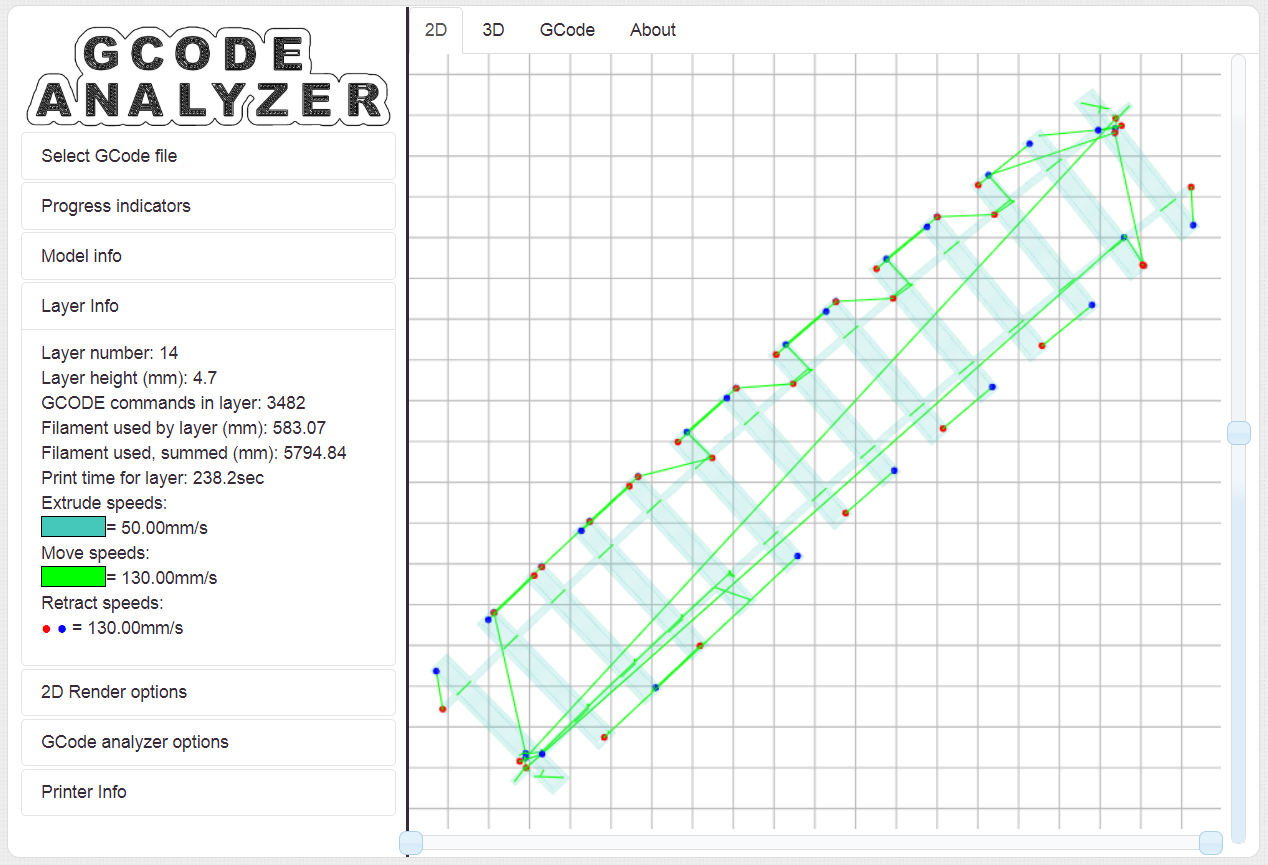
Eine gewisse Optimierung macht der Slicer, aber halt nicht so, wie ich
wünschte. Angehängt ein Layer wie aus dem Bilderbuch und Einer mit
Travels, die nicht nötig wären. Erstellt mit http://gcode.ws/
Gruss Chregu
Ich gehe mal davon aus, dass der Startpunkt relativ leicht
ermittelt werden kann (kürzeste Entfernung vom Endpunkt der
vorherigen Lage). Damit steht der erste Startpunkt einer
Leerfahrt auch fest. Jetzt in einer Schleife für alle möglichen
nächsten Punkte die Entferung ermitteln (entweder absolut mit
deiner o.g. Gleichung oder optimiert nach Verfahrrichtung).
Die kürzeste Entfernung gewinnt und die nächste Strecke
und damit der Startpunkt der nächsten Leerfahrt steht fest.
Jetzt wieder Entfernung berechnen mit den Startpunkten der
restlichen Strecken.
Das Verfahren wird sicherlich nicht das Handlungsreisenden-
Problem lösen, weil ja nicht alle Varianten durchgerechnet
werden. Aber ich würde das mal als Anfang nehmen, vielleicht
genügt es ja deinen Ansprüchen.
merciless
Das chaotische Verhalten ist schon richtig und oft irgendetwas mit
simulated annealing (zufällige/ plumpe erste Lösung, fortlaufende
Verfeinerung/ systematisches Probieren von Alternativen mit
Fitnessfunktion, Mindestmaß der Verbesserung steigt beständig). Ant
Algorithms könntest du auch ausprobieren, wenn du etwas Freizeit und ein
paar CPU-Kerne hast.
Am Ende läuft es auf Kosten-Nutzen-Verhältnis hinaus. Wieviel Rechenzeit
(=Energie) willst du investieren um welche Einsparung (=lohnenswert) zu
erhalten? Einfachste Routing-Algorithmen genügen den meisten
Software-Herstellern.
Verrückterweise gibt es noch heute Optimierungsprobleme, die von der
Maschine nur vorbereitet werden. Ein menschlicher Profi stellt dann noch
ein paar Kleinigkeiten ein und landet tatsächlich vor der Maschine
(verzahnte Schichtplanung in großen Unternehmen wie der Deutschen Bahn).
Randbedingungen sind da eher die Regel, als die Ausnahme, sogar solche
wie Robustheit der Lösung. Für eine Werkstückbearbeitung ist das sicher
uninteressant.
Dirk K. schrieb:> Jetzt in einer Schleife für alle möglichen> nächsten Punkte die Entferung ermitteln
Das wollte ich ja, irgendwann wird dann aber der letzte Punkt soweit vom
Zweitletzten entfernt sein, dass ich nichts gewonnen habe.
Ich kanns mal durchspielen, kann ja nur lernen daraus!
Gruss Chregu
Schau dir mal den A Star Algorithmus an, auch einfach A* genannt. Der
findet bei vorgegebenen Hindernissen und Wegkosten des preisgünstigsten
Weg.
Das Problem besteht dann eher darin, das aktuelle Wegenetz für den
Algorithmus anzupassen.
Matthias S. schrieb:> Schau dir mal den A Star Algorithmus an, auch einfach A* genannt.> Der> findet bei vorgegebenen Hindernissen und Wegkosten des preisgünstigsten> Weg.> Das Problem besteht dann eher darin, das aktuelle Wegenetz für den> Algorithmus anzupassen.
Nur, dass er keinen kürzesten Weg von A nach B durch einen Graphen
finden will, sondern einen kürzesten Weg (der auch nicht geschlossen
sein muss) durch alle (oder je nach Definition: eine Liste von) Knoten.
Was hier zusätzlich berücksichtigt werden muss, ist, dass es eine Menge
Nebenbedingungen gibt, aber auch überhaupt erstmal eine
Definitions/Modellierungsfrage:
Was überhaupt ein Knoten ist.
Ist ein Knoten eine Druckfahrt und die Kanten die Leerfahrten? oder ist
jeder auflösungstechnisch anfahrbare mögliche Punkt ein Knoten.
Jede Variante bringt eigene Schwierigkeiten mit.
Bei ersterer ist das Problem, dass die Knoten kein Punkt sind, sondern
eine Fläche, die selbst ein abzufahrender Pfad ist, dem es teilweise
egal ist, wo man anfängt und aufhört und außerdem die Kosten der Kanten
davon abhängig sind, wo der Extruder den diese Fläche betritt und
verlässt.
Bei Zweiter Variante ist die schiere Anzahl der Punkte problematisch und
dass man nur die mit aktivem Extruder anfahren muss, und die anderen nur
für die Wegfindung dazwischen benötigt werden - es sei denn man nimmt
nur die aktiven Punkte, verbindet sie mit ihren (max) 8 aktiven Nachbarn
und bei fehlenden Nachbarn (ist ein Randpunkt) verbindet man sie mit
allen anderen Randpunkten.
Darf die Düse durch bereits gedruckte Strecken auf der Ebene durchfahren
oder stößt die Düse da an und muss da außen herum kurven?
Christian M. schrieb:> Dirk K. schrieb:>> Jetzt in einer Schleife für alle möglichen>> nächsten Punkte die Entferung ermitteln>> Das wollte ich ja, irgendwann wird dann aber der letzte Punkt soweit vom> Zweitletzten entfernt sein, dass ich nichts gewonnen habe.>> Ich kanns mal durchspielen, kann ja nur lernen daraus!>> Gruss Chregu
Ich würde mal die oben beschriebene Lösung
ausprobieren. Wenn die nicht gut genug ist,
kann man jeden möglichen Punkt als Startpunkt
auswählen und durchrechnen. Das ergibt bei
n Punkten n Lösungen. Sollte das immer noch
nicht gut genug sein, kannst du noch alle
Lösungen durchrechnen, das ergibt aber n!
(Fakultät) Lösungen und das dürfte wohl nicht
mehr durchführbar sein.
merciless
Vlad T. schrieb:> Matthias S. schrieb:>> Schau dir mal den A Star Algorithmus an, auch einfach A* genannt.>> Der>> findet bei vorgegebenen Hindernissen und Wegkosten des preisgünstigsten>> Weg.>> Das Problem besteht dann eher darin, das aktuelle Wegenetz für den>> Algorithmus anzupassen.>> Nur, dass er keinen kürzesten Weg von A nach B durch einen Graphen> finden will, sondern einen kürzesten Weg (der auch nicht geschlossen> sein muss) durch alle (oder je nach Definition: eine Liste von) Knoten.
Der A* Algorithmus ist da sehr flexibel. Es werden die geschätzten
Kosten um das Ziel zu erreichen verwendet. Diese Kostenschätzung ist
selbst zu implementieren und somit ist "kürzester" Weg nur eine
Anwendung für den Algorithmus... Genauso kann man damit Rucksack packen,
Missionare und Kanibalen über einen Fluß bringen, G-Code Dateien
optimieren, ....
>> Was hier zusätzlich berücksichtigt werden muss, ist, dass es eine Menge> Nebenbedingungen gibt, aber auch überhaupt erstmal eine> Definitions/Modellierungsfrage:>> Was überhaupt ein Knoten ist.
Ein Knoten ist ein "Schritt" vom Anfangszustand zum Ziel. Mittels des A*
Algorithmus werden sie (hoffentlich) zu einer optimalen Lösung
zusammengereiht.
...
> Bei Zweiter Variante ist die schiere Anzahl der Punkte problematisch
Der A* Algorithmus steht und fällt mit der Modelierung der
"Kostenfunktion" und der Knoten (Abstrahierung der Aufgabe). Ist dies
gut gewählt ist der Algorithmus sehr effizient.
Wenn nicht, degradiert er leicht in Richtung Brute Force
durchprobieren...
> und> dass man nur die mit aktivem Extruder anfahren muss, und die anderen nur> für die Wegfindung dazwischen benötigt werden -> ....> Darf die Düse durch bereits gedruckte Strecken auf der Ebene durchfahren> oder stößt die Düse da an und muss da außen herum kurven?
Das sind alles Randbedingungen die man Modellieren muß - genauso wie bei
jeder anderen Methode um hier eine Lösung zu finden.
Christian U. schrieb:> Der A* Algorithmus ist da sehr flexibel. Es werden die geschätzten> Kosten um das Ziel zu erreichen verwendet. Diese Kostenschätzung ist> selbst zu implementieren und somit ist "kürzester" Weg nur eine> Anwendung für den Algorithmus
Das ist schon klar, trotzdem löst A* ein anderes Problem, als dieses.
Je nach Modellierung, entspricht dieses Problem eher dem TSP. Bzw einer
Abwandlung davon, bei der es zusätzliche Knotenpunkte gibt, die
allerdings nicht angefahren werden müssen (und die Route muss nicht
geschlossen sein).
Christian U. schrieb:> Genauso kann man damit Rucksack packen,> Missionare und Kanibalen über einen Fluß bringen, G-Code Dateien> optimieren, ....
Zeig mir mal, wie du damit einen Rucksack packst, ohne dass dabei ein
Baum entsteht, an dem man das Ergebnis direkt ablesen kann.
Ben B. schrieb:> Naja einen Algorithmus dafür zu schreiben, der das mit wenigen Punkten> schafft, ist einfach. Schwierig wirds, wenn man eine große Anzahl an> Punkten hat und die Aufgabe in endlicher Zeit abgeschlossen sein soll.
Reich wird man wenn man einen Algorithmus findet der nicht darauf
basiert, alle möglichen Kombinationen zu berechnen (und trotzdem das
absolut optimalste Ergebnis leifert); denn genau das ist die Krux der
"Np-harten Probleme": Es gibt bislang keine Lösung die nicht im Endefekt
auf Bruteforce hinausläuft.
Mittels probabilistischen Algorithmen kann man natürlich trotzdem masiv
Zeit sparen, nur ist das Ergebniss dann nicht mehr garantiert optimal.
Zum Thema A*. Das ist doch "nur" für kürzesten Weg zwischen zwei
Punkten. Der erfüllt nicht die Bedingung alle Knoten zu durchfahren und
genau das braucht man bei 3D Druck!
Um alle Knoten zu durchfahren, müsste man den A* nach und nach für alle
Knoten anwenden. nach jeder Iteration die besuchten Knoten einfach raus
zu nehmen, wird am Ende zu keinem optimalen Ergebnis führen sondern zu
kreuz und quer-fahrten.
Alex G. schrieb:> Mittels probabilistischen Algorithmen kann man natürlich trotzdem masiv> Zeit sparen, nur ist das Ergebniss dann nicht mehr garantiert optimal.
Wie ich oben schon schrieb führt das zu ordentlich Rechenzeit/
Ressourcenbedarf vor der eigentlichen Durchführung. Wenn das Sinn machen
würde, hätte es schon jemand mit einem Arduino oder einen RaspberryPI
gemacht.
Willst du den Algorithmus unbedingt selber machen, oder kommt es auch in
Frage, die Arbeit an ein anderes Programm / Bibliothek zu delegieren?
Dann könnte nämlich das Stichwort "SMT solver" vielleicht helfen.
Sebastian S. schrieb:> Willst du den Algorithmus unbedingt selber machen
Nein, das würde schon zeitlich nicht drinnliegen.
Sebastian S. schrieb:> oder kommt es auch in> Frage, die Arbeit an ein anderes Programm / Bibliothek zu delegieren?
Noch so gerne :-))
Gruss Chregu
Glaube wenn ich diese Aufgabe lösen müsste, würde ich nicht direkt auf
Graphentheorie setzen. Bei der Auflösung der Drucker ergibt das einfach
viel zu viele Knoten.
Interessanter wäre ein Clustering Algorithmus. K-Means o.ä. Diese
Algorithmen sind vergleichsweise schnell bzw. für riesige Datensätze
geeignet.
Damit könnte man die Bereiche finden wo viele anzufahrende Punkte nah
bei einander liegen und damit mehrere Gruppen finden die in sich
betrachtet, relativ kurze Wege haben. Die Gruppen kann der Drucker dann
nacheinander anfahren - oder noch besser, die paar Dutzend oder Hundert
Gruppen, als traveling-salesman Problem ansehen.
Alex G. schrieb:> Zum Thema A*. Das ist doch "nur" für kürzesten Weg zwischen zwei> Punkten. Der erfüllt nicht die Bedingung alle Knoten zu durchfahren und> genau das braucht man bei 3D Druck!> Um alle Knoten zu durchfahren, müsste man den A* nach und nach für alle> Knoten anwenden. nach jeder Iteration die besuchten Knoten einfach raus> zu nehmen, wird am Ende zu keinem optimalen Ergebnis führen sondern zu> kreuz und quer-fahrten.
Doch?
Habs gerade probiert mit einer alten A Stern Implementation von mir.
Hoffe ich habe die Problemstellung richtig verstanden
- es gibt eine Liste von Anfangs- und Endpunkten, zwischen denen
gedruckt wird
- Zwischen den obigen End- und Anfangspunkten sind die Leerfahrten
(gerade Linie?).
- Die Länge der Leerfahrten soll minimiert werden.
Wenns so ist, kann man das ziemlich einfach mit dem A* abbilden. Ich
habe mal nach dem Gesamtweg geteilt durch die Anzahl der "Fahrten"
minimiert - da konvergiert es um einiges schneller, als nach dem
gesamten Weg...
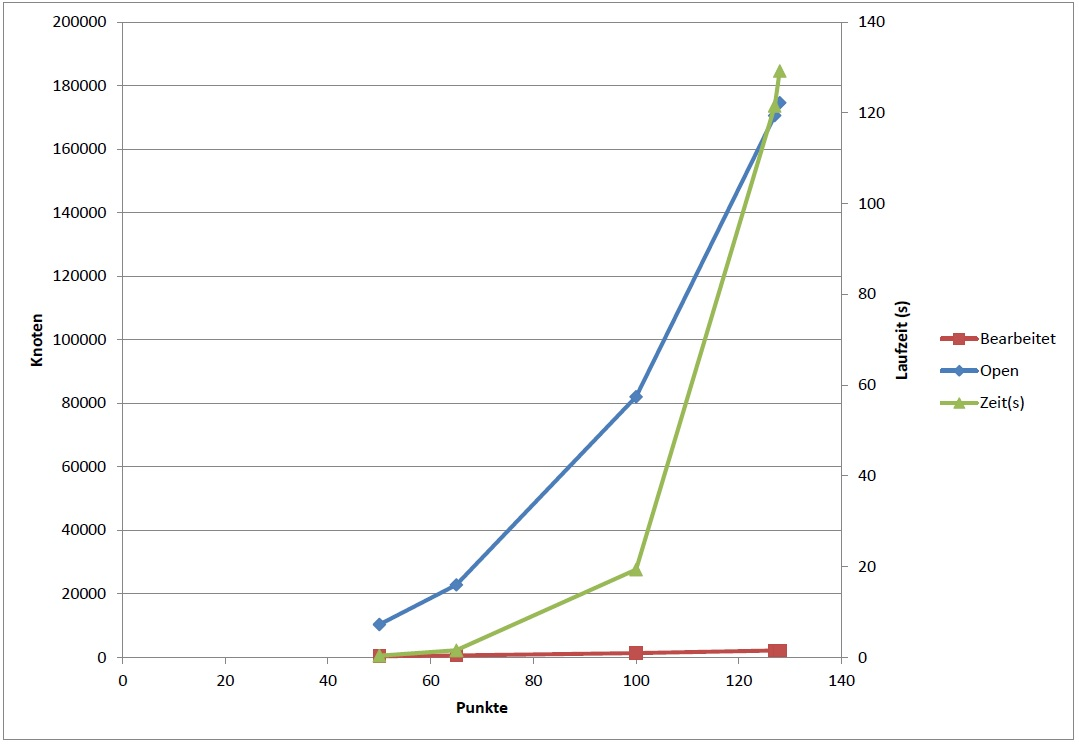
Ab ca. 100 Punkten fängt dann die Laufzeit an zu "entarten"... Mit
ordentlichen Implementationen (vor allem der Heap, nehm ich an...) kann
man sicher auch noch was rausholen.
Aber für die
Christian M. schrieb:> Vielen Dank für Eure Antworten! Es handelt sich um die 60-70 Distanzen> pro Lage.
langts vollkommen.
Als Beispiel habe ich ca. die Anordnung wie vom TO gezeigt angenommen...
Vlad T. schrieb:> Darf die Düse durch bereits gedruckte Strecken auf der Ebene durchfahren> oder stößt die Düse da an und muss da außen herum kurven?
Die Antort darauf wäre noch interessant - falls das eine Einschränkung
ist, könnte das eine Erklärung sein, warum der Slicer so "komischen"
G-code erzeugt - damit die bereits gedruckten Stücke trocknen können?
Falls dem wirklich so ist, wirds um einiges "interessanter" ;( Dann holt
man sich mit jeder Linie neue Beschränkungen wo und wie man weiterfahren
kann...
Wie kommt ihr auf 60 bis 70 Distanzen?
Ein Druckbrett eines 3D Druckers hat meist 200 x 200mm bei einer
Auflösung von 0.1mm
D.h. bis zu 4 Millionen Punkte!
Alex G. schrieb:> Wie kommt ihr auf 60 bis 70 Distanzen?
Weil das der TE geschrieben hat. Seine g-code Dateien enthalten pro Z
Koordinate an die 60-70 "Fahrten" fürs Drucken. Davon interessieren nur
die Anfangs und Endpunkt um die Leerfahrten des Druckkopfes zu
minimieren - also die Reihenfolge der Druckfahrten besser/optimal
umzusortieren.
> Ein Druckbrett eines 3D Druckers hat meist 200 x 200mm bei einer> Auflösung von 0.1mm> D.h. bis zu 4 Millionen Punkte!
Das ist klar, hat aber mit diesem Thema nichts zu tun.
Ich fasse mal zusammen: Man hat Strecken S der Form A-B, D-F, ... sowie
eine Leerfahrtenfunktion D: SxS -> x und sucht eine Permutation P, so
dass die Summe der D(Pn, Pn+1) minimal wird.
Als Suchbaum sähe das dann irgendwie so aus
1
/ | \
2
/ | \
3
A-B A-C B-D
4
/ | \ /|\ /|\
Die Kosten für die Lehrfahrten kann man an die Kanten schreiben.
Auf dem Weg nach unten akkumulieren sich die Kosten.
Es fällt auf, dass man, wenn man schon ein paar Ergebnisse für
Gesamtkosten hat, schon vor dem Erreichen der letzten Ebene die Variante
verwefen kann, weil man schon mehr Kosten akkumuliert hat, als das beste
Ergebnis bisher.
Daraus ergibt sich, dass es entscheidend ist, gute Varianten zuerst
durchzurechnen, um beim Rest das Akkumulieren möglichst früh abbrechen
zu können. D.h. das man bei jedem Knoten gut überlegen sollte, welchen
Knoten man als nächstes zuerst betrachtet.
Hier verfolgt A* die Strategie eine Heuristik über die noch zu
erwartenden Kosten zu veranschlagen und auf Basis der Summe (Kosten
bisher + Heuristik) zu entscheiden, wo der Baum weiter expandiert wird.
Damit A* ein optimales Ergebnis liefert muss "Heuristik <= Reale Kosten
für den Rest" gelten, sonst expandiert man ggf. den falschen Ast und
kommt mit einem suboptimalen Ergebnis unten an. Das kann trotzdem eine
valide Strategie sein, wenn es keine "ordentliche" Heuristik gibt und
die Rahmenbedingungen der Aufgabe das zulassen: Wenn das dazu führte,
dass in der Massenproduktion über Jahre nur 20% langsamer produziert
werden kann, würde ich mich warm anziehen.
Jedenfalls bleibt festzuhalten, dass A* eine gute Heuristik bräuchte.
Und die gibt es hier nicht, soweit ich sehe. Es kann z.B. sein, dass die
letze Strecke anzufügen eine Fahrt quer über das Papier bedeutet.
Ohne Heuristik degeneriert A* zu einer uniformen Kostensuche. Man
expandiert einfach immer da weiter, wo die bisherige Kostensumme am
günstigsten war. Da der Verzweigungsgrad des Baumes relativ groß ist,
scheidet eine Breitensuche wohl aus. Wie ebenso angedeutet ist es - bei
einer Depth-First Suche umso mehr - entscheidend, die vermutlich besten
Kandidaten zuerst durchzurechnen. Hier wird doch wieder eine Heuristik
notwendig - jedoch ohne die Einschränkung, dass sie eine strikte
Anforderung erfüllen muss. Hier ruiniert eine schlechte Heuristik zwar
die Laufzeit des Algorithmus, führt aber nicht zu einem falschen
Ergebnis. Diese Heuristik zu bestimmen ist eine interessante Aufgabe für
sich: DeepMind verwendet z.B. die Monte-Carlo Methode: Man führt den
Baum einige Male mit zufällig gewählten Streckenfolgen zu Ende und
erhält so ein Maß, wie (un-)günstig es der schon traversierte Anteil des
Baumes macht, die restlichen Strecken auch noch anzufügen. Wenn "einige
Male" gegen Unendlich geht dürfte das deutlich werden: Dann erhält man
ein Maß, wie groß die für den Rest Kosten durchschnittlich sind. Die
eine geniale Lösung unter dem Rest der schlechten geht immer noch unter,
aber die Heuristik ist hier ja nicht so ausschlaggebend wie bei A*.
Interessant war auch die Idee mit dem Clustering. Man könnte, um den
Suchbaum radikal zu stutzen, die einzelnen Strecken durch "Strecken von
Cluster X zu Cluster Y" ersetzen. Damit würde man den Verzweigungsgrad
des Baumes verringern und erhielte so ggf. einen Ansatzpunkt, welche
tatsächlichen Streckenfolgen vermutlich günstiger sind. Hier gäbe es
dann viel zu tweaken, was die Größe der Cluster betrifft etc.
Wenn sich die Wege innerhalb eines Clusters signifikant aufaddieren
kommt man wieder zu einer schlechten Heuristik, bei zu vielen Clustern
ginge der Vorteil des Ansatzes verloren.
Statt Clustern könnte man hier aber auch ein einfaches Raster nehmen, da
man die Information über Ballungen von Punkten so eigentlich nicht
braucht.
Bei den an die Hundert zu betrachtenden Strecken habe ich Zweifel, dass
sich eine genaue Lösung in annehmbarer Zeit finden lässt. Besser als
zufällig aneinander gereihte Strecken dürfte es aber ziemlich leicht
werden.
Christian U. schrieb:> Ich> habe mal nach dem Gesamtweg geteilt durch die Anzahl der "Fahrten"> minimiert - da konvergiert es um einiges schneller, als nach dem> gesamten Weg...
Ja, dann werden tendenziell nur Lösungen, die mit der Form A-B, B-C, ...
anfangen, überhaupt weiter betrachtet werden. Das ließe sich noch
toppen, wenn man erstmal so viele "minimal"-Abstand-Strecken wie man
ad-hoc findet, aneinander reiht. Danach könnte man dann vllt. auch
vernünftig weiter machen.
Das ist vermutlich die Art von Grobschlächtigkeit, die man hier braucht.
Als Heuristik dann der Durchschnitt von minimalem und maximalem
Streckenabstand * n und man hat zumindest etwas, was schnell ein nicht
ganz schlechtes Ergebnis liefert (hoffentlich jedenfalls).