Hallo,
wie aus anderen Themen von mir erkennbar versuche ich mich gerade daran
Bibliotheken für mich selbst aufzubauen. Jetzt noch einen Schritt weiter
mit Objektorientierter Programmierung in C++.
Ich bin gerade an ein Problem gestoßen wo ich keinen "hübschen"
Lösungsweg finde. Da ich mit DMA arbeite, muss ich irgendwie
organisieren wann welches Gerät an der Reihe ist, damit nicht das
nächste sendet obwohl das erste noch nicht fertig ist. Außerdem noch ein
paar weiter Features, wie Priorität, Schnittstelle sperren, etc.. Das
geht noch mit einer einfachen Klasse zu lösen.
//Memberdeklaration
Gerät portexpander1();
Gerät portexpander2();
//Abfrage in mainloop
if (portexpander1.darfIchSenden() == true)
...
if (portexpander2.darfIchSenden() == true)
...
o.ä.
Jetzt hat aber so ein STM32 je nach Modell etliche Schnittstellen, wobei
mehrere Geräte an einer Schnittstelle hängen können. Wie bekommt man es
hin, dass alle Geräte an Schnittstelle i2c1 auf die Freigabevariable von
i2c1 zugreifen, die von i2c2 auf i2c2?
ungefähr so stelle ich mir das vor:
//Memberdeklaration
Gerät portexpander1(Schnittstelle1);
Gerät portexpander2(Schnittstelle1);
Gerät portexpander3(Schnittstelle2);
Schnittstelle i2c1();
Schnittstelle i2c2();
//Abfrage in mainloop
if (portexpander1.darfIchSenden() == true)
...
if (portexpander2.darfIchSenden() == true)
...
//in Bibliothek
Gerät::darfIchSenden()
{
SchnittstelleX.wieSchautsMitDemTrafficAus();
}
Aber wie sage ich dem Gerät dass es zu Schnittstelle x gehört, ohne die
Vorteile der endlosen Erweiterbarkeit bei Objektorientierter
Programmierung zu verlieren?
Heinz M. schrieb:> Aber wie sage ich dem Gerät dass es zu Schnittstelle x gehört
Indem du die zugehörige Schnittstelle beim Konstruktor übergibst.
1
Schnittstellei2c1();
2
ErweiterteSchnittstellei2c2();
3
Geraetportexpander1(i2c1);
4
Geraetportexpander2(i2c1);
5
Geraetportexpander3(i2c2);
Niemand hindert dich daran, die Schnittstelle zu erweitern. Du kannst
den Portexpander auch (einfach so) mit einer erweiterten Schnittstelle
konstruieren.
Kleiner Tipp: Ich würde mich bei Bezeichnern auf US-ASCII zeichen
beschränken. Das erspart einem Stress mit Zeichensätzen, wenn du mal das
Betriebssystem wechselst oder die Dateien jemand anderem gibst, dessen
Rechner anders konfiguriert ist.
Das oben ist nur Pseudocode und zur besseren Lesbarkeit mit ä
geschrieben.
Als was soll i2c1 bzw. i2c2 übergeben werden? String, Variable, Pointer?
Würde es große Probleme machen Member einfach nur mit Zahlen zu
bezeichnen? Mit Variablen hantieren ist einfacher und schneller, als mit
strings. 255 Schnittstellen mit je 64 Geräten sind mehr als ausreichend.
Im Beispiel unten müsste ich dann noch "uint8_t schnittstelle" als
Variable/String bei PriorityDevice ergänzen. Die Abfragen würden dann
über PriorityDevice geschehen, welches einen Funktionsaufruf auf
PrioritySchnittstelle in Abhängigkeit der gespeicherten Schnittstelle
enthält. Bei i2c1.readFlag(); müsste das i2c1 als Pointer oder Variable
übergeben werden. Konnte bis jetzt nichts im Internet dazu finden. Hat
evtl. jemand einen Begriff wonach ich da suchen könnte?
Hier mal die aktuelle Klassendefinition:
1
class PrioritySchnittstelle
2
{
3
private:
4
5
public:
6
uint64_t flag; // Binärkodierung, welche Geräte Bedarf haben
7
// Größerer Wert = höhere Priorität
8
uint8_t device; // Gerät das gerade alles sperrt (0 ist frei)
9
10
void setFlag(uint8_t device); // Bedarf anmelden
11
bool readFlag(uint8_t device); // Gibt zurück, ob Device was machen soll und Berechtigung hat (Priorität und Sperrung testen)
uint8_t counter; //Aktionen oder Nachrichten die ohne Unterbrechung hinteinander geschickt werden müssen (z.B. I2C 1. Register aufrufen 2. Daten empfangen)
27
28
uint8_t prioLesen();
29
void degCounter(); // verringert counter um 1
30
31
32
// Priorität wird zur Memberdeklaration festgelegt, Rest in Funktionen
Habe inzwischen herausgefunden, dass Aggregation das richtige sein
könnte. Aber eine richtig gute Anleitung bzw. Beispiel konnte ich noch
nicht finden.
Heinz M. schrieb:> Als was soll i2c1 bzw. i2c2 übergeben werden?
Als Referenz auf das Objekt. Pointer würde auch gehen.
Mit deinem Priority Zeugs hast du mich abgehängt, kann Dir gedanklich
nicht mehr folgen.
Priorität ist ganz einfach:
An einer Schnittstelle hängen mehrere Geräte, wovon aber nur eins
gleichzeitig angesteuert werden kann. Einige Geräte müssen in weicher
Echtzeit laufen, bei anderen ist es egal. Die mit Echtzeitanforderung
brauchen Vorrang. Jetzt kann ich nicht die Übertragung unterbrechen um
das zeitkritische zu übertragen. Möchte aber gewährleisten, dass das
zeitkritische als nächstes kommt. Deswegen die Priorität.
Beispiel:
An i2c1 hängt besagter Portexpander. Daran mehrere Drehencoder. Damit es
nicht zum Eingabelag kommt müssen diese zeitnah abgefragt werden. Am
gleichen Bus hängt ein Display, wo die per Drehencoder eingestellten
Werte als Zahlen angezeigt werden. Eine halbe Sekunde Verzögerung ist da
völlig egal.
Deswegen möchte ich bei der Memberdeklaration jedem Gerät pro
Schnittstelle eine Priorität zuweisen können, die ja nach Anwendung
unterschiedlich sein kann.
Heinz M. schrieb:> Als was soll i2c1 bzw. i2c2 übergeben werden?https://en.wikipedia.org/wiki/Dependency_injection (der deutsche
Artikel ist Mist)
Heinz M. schrieb:> Deswegen möchte ich bei der Memberdeklaration jedem Gerät pro> Schnittstelle eine Priorität zuweisen können, die ja nach Anwendung> unterschiedlich sein kann.
Nicht zielführend. Eine Klasse/Modul/Funktion etc. sollte genau nur ein
Thema verarbeiten.
Du hast zwei Themen:
a.) Abstraktion der Hardware für den Portexpander
b.) Reihenfolge/Priorität welche Ports abgefragt werden.
Zwei Aufgaben, zwei Klassen:
https://de.wikipedia.org/wiki/Single-Responsibility-Prinzip
Heinz M. schrieb:> Beispiel:> An i2c1 hängt besagter Portexpander. Daran mehrere Drehencoder. Damit es> nicht zum Eingabelag kommt müssen diese zeitnah abgefragt werden. Am> gleichen Bus hängt ein Display, wo die per Drehencoder eingestellten> Werte als Zahlen angezeigt werden. Eine halbe Sekunde Verzögerung ist da> völlig egal.
Da steckt schon eine Denkfehler drin.
Input und Output gehören nicht an den gleichen Bus.
Wenn Du mehrere Busse betreibst macht es Sinn die Aufgaben zu verteilen.
Inputs pollen an dem einen, und nur Inputs.
Outputs bei Änderungen schreiben auf einem anderen.
Und natürlich darfst Du der Klassen die Daten im Konstruktor übergeben.
Pro Aufgabe ne Klasse mag theoretisch toll sein aber in der Praxis muß
man die Infos auch irgendwie zusammen führen.
Ergo wird es ein Objekt mit mehreren Attributen geben, is schon ok.
@ unausgelasteter Programmierer:
Ok für den Wikiartikel brauch ich länger.
Eine Klasse soll doch ein in sich funktionales Objekt darstellen, wovon
verschiedene ähnliche Member erzeugt werden. Schnittstelle und Geräte
bekommt man doch unmöglich in eine Klasse.
Zwei Themen stimmt, aber andere Aufteilung:
a) Schnittstellen und die Verwaltung der Zugriffe und Prioritäten
dieser.
b) Geräte und die Verwaltung der Eigenschaften dieser (Wozu
Zugriffswunsch und Prioritätslevel zählt).
@ NichtWichtig:
Genau da liegt der Haken, warum ich es universell per OOP möchte. Die
Bibliothek soll bei verschiedenen Mikrocontrollern (alles STM32) zum
Einsatz kommen. Wie viele Schnittstellen der jeweilige hat, weiß ich
jetzt noch nicht. Der STM32F042F6P6 hat zum Beispiel nur 1x I2C.
Außerdem macht es keinen Sinn generell alle Inputs an einen Bus und alle
Outputs an einen anderen. Das muss je nach Situation entschieden werden.
- Wieviele Schnittstellen gibt es
- Welche Geschwindigkeit können die Geräte
- Zu erwartende I/O Last
- Kabelführung
- ...
Jupp, das Umfeld und die Möglichkeiten sind wichtig bei der Zuordnung.
Ich mußte an einem ARM7 (LPC2119) mit einem i2c Bus ca. 30 Chips
managen, da kam die Trennung via Bus-Switches In/Out sehr gelegen.
Und OOPs bietet sich an diese Details zu verstecken.
Sauberes Software-Design ist der Schlüssel zum Erfolg.
Ich verstehe noch nicht, warum du überhaupt mit Konflikten rechnest, und
somit eine Prioritäten-Steuerung brauchst.
Ich gehe doch mal stark davon aus, dass du ein single-master System
hast. Und außerdem schreibst du von einer Hauptschleife, also wohl kein
RTOS.
Wie können da überhaupt Zugriffskonflikte auftreten?
Andersrum. Es geht nicht darum welches am Bus angeschlossene Gerät das
Senderecht erhält um einen Konflikt zu vermeiden, sondern es geht darum
welches am Bus angeschlossene Gerät der Master zuerst bedient.
DMA heißt mein Konflikt. Damit ist die Abarbeitung nicht mehr Linear.
Während der DMA Controller sendet arbeitet die CPU an anderen Sachen
weiter, so dass es vorkommen kann, dass bis der DMA Controller fertig
ist mehrere Sachen anfallen, die über ein und die selbe Schnittstelle
übertragen werden sollen. Und da soll zuerst das dringliche verschickt
werden und dann das unwichtige.
Wenn bei DMA munter drauf los gesendet wird, dann hängt sich der µC
verständlicherweise auf, weil sich die Nachrichten überschneiden. Man
könnte natürlich auch hintereinander senden wie es anfällt oder eine
feste Reihenfolge, aber Priorität bringt bessere Reaktionszeiten.
Heinz M. schrieb:> da soll zuerst das dringliche verschickt werden und dann das unwichtige.> Man könnte natürlich auch hintereinander senden wie es anfällt oder eine> feste Reihenfolge, aber Priorität bringt bessere Reaktionszeiten.
Ok, jetzt habe ich es verstanden.
In diesem Fall würde ich auch dazu raten, die Steuerung der Prioritäten
in eine separate Klasse zu schreiben. Ich würde darin alle Anfragen in
Form einer Warteschlange verwalten, wo jeder Eintrag eine Priorität
bekommt. Diese werden dann entsprechend ihrer Priorität abgearbeitet.
Diese Logik gehört weder in die I²C Schnittstellenklasse rein, noch in
deren Konsumenten. Es muss eine zentrale Klasse sein.
Bei der Abgrenzung haben wir uns wohl etwas missverstanden. Die
Schnittstellen nehme ich von HAL und werden auch nicht in der
Prioritätenklasse aufgerufen und die Geräteklassen kommen extra. Also so
wie du es schreibst.
Was du gerade beschrieben hast wäre dann für eine Schnittstelle, da jede
Schnittstelle ihren DMA Channel hat und daher die Schnittstellen
unabhängig arbeiten können. Deswegen die zwei Klassen. Übergeordnet: Wie
viele Schnittstellen (egal was das für welche sind) gibt es.
Untergeordnet: Wieviele Geräte (egal was die tun) hängen an einer
Schnittstelle.
Ich hatte erst vor die Schnittstellenklasse nur dazu zu verwenden, dass
da eine große Variable drin steht (uint64_t) und jedes Bit ist die
Priorität eines anderen Gerätes. Danach wird beim Gerät nachgeschaut was
es ist.
Gerade überlege ich aufgrund deines Posts, ob es nicht doch mit einer
Klasse bzw. mit zwei getrennten Klassen geht. Wenn die Priorität
gleichzeitig die ID ist, dann müsste beim Zugriff nur geprüft werden, ob
die ID passt und ob es eine größere gibt. Ich denke das ist mit Code
einfacher:
1
0010 // Gerät 1 möchte senden
2
0100 // Gerät 2 möchte senden (hohe Priorität)
3
0110 // beide möchten senden
4
5
6
//Abfrage in mainloop
7
//Gerät 1
8
if (i2c1.darfIchSenden(GeräteID))
9
{
10
Senden
11
}
12
13
//Gerät 2
14
if (i2c1.darfIchSenden(GeräteID))
15
{
16
Senden
17
}
18
19
//in Bibliothek
20
darfIchSenden(GeräteID)
21
{
22
...
23
if (Priority & GeräteID == GeräteID) //Prüfen ob überhaupt Sendebedarf besteht
24
if (Priority < 2* GeräteID -1) //Prüfen ob es jemanden mit höherer Priorität gibt
25
if (Gesperrt == GeräteID || Gesperrt == 0) //Prüfen ob noch jemand einen Rest senden muss
26
Senden = ja
27
}
Wenns unübersichtlicher ist, könnte ich die zweite Klasse noch
nachprogrammieren und die Funktionen der 2 Klassen im Doppelpack
schreiben:
i2c1.darfIchSenden(Portexpander1.meineID())
Zwar nicht ganz so geil, wie wenn er selbst nachschauen würde, welche
Schnittstelle ein Gerät hat, aber eine akzeptable Lösung.
Ich habe das Gefühl, dass du dir da zu viel Gedanken über die Struktur
machst. Schreibe erstmal ein funktionierendes Programm und überdenke
danach die Struktur. Wenn sie richtig schlecht ist, schreibe den Teil
nochmal neu. Ansonsten lasse ihn so.
Du läufst sonst Gefahr, vor lauter Perfektionismus nicht fertig zu
werden. Wenn man nicht aufpasst, beschäftigt man sich zu sehr mit der
OOP an sich, anstatt mit der Aufgabe die man eigentlich damit erledigen
wollte. OOP verleitet leider viele Leute dazu.
Ich frage dann: Warum hast du das so unnötig komplex gemacht? Die
erhliche Antwort lautet dann oft: "Weil ich dachte, man muss das so
machen." Lernt man ja so auf der Uni. Oder auch: "Weil ich duplizierten
Code vermeiden wollte." Nur: Was nützt die Vermeidung von ein bisschen
copy-paste, wenn man sich dafür einen Wolf planen und tippen muss?
Niemand wird für perfekt durchgestylte Programmstrukturen bezahlt,
sondern dafür, dass das Produkt gut funktionierend zum Zieltermin
abgeliefert wird.
Ich kenne kein beeindruckend gutes Programm, das von Anfang an
tippitoppi durchgeplant und in einem Rutsch entwickelt wurde. Im echten
Berusleben ist das stets ein Prozess von mehreren Verbesserungs-Runden,
der sich nicht selten über Jahre verteilt.
Als Copy&Paste funktioniert es bereits. Etwas mehr Gedanken wollte ich
reinstecken, weil ich es als Bibliothek nutzen möchte und das halt "die"
Grundfunktion in Zukunft wird.
Deswegen schrieb ich ja, dass das so akzeptabel sein könnte. Weil
Aggregation, Komposition, etc. ist mir jetzt doch etwas zu viel.
PrioritySchnittstelle i2c1 (0, 0); //Fehler: Type 'PrioritySchnittstelle' could not be resolved
49
while (1)
50
{
51
i2c1.setFlag(2); //Fehler: Method 'setFlag' could not be resolved
52
if(i2c1.readFlag(10) == 10) //Fehler: Method 'readFlag' could not be resolved
53
HAL_Delay(100); //Fehler: undefined reference to `PrioritySchnittstelle::device'
54
else
55
HAL_Delay(1000); //Kein Fehler!
56
57
HAL_GPIO_TogglePin(GPIOB, GPIO_PIN_8);
58
}
59
}
Die Fehler würden mir sagen, dass er es nicht findet. Eine einfache
Funktion in allgemein.cpp funktioniert. Also müsste die Bibliothek
richtig eingebunden sein. Tippfehler konnte ich auch keine finden.
So langsam gefallen mir die Code Guide lines im Job immer besser, was
hier mitunter an kryptischen Zeugs präsentiert wird ist haarsträubend.
Wozu
static uint8_t priorityflag; //später 64
static uint8_t device; //Gerät das sperrt (0 ist frei)
?
Wozu braucht die Klasse
#include <stdio.h>
?
Was soll device als Parameter?
void PrioritySchnittstelle::setFlag(uint8_t device)
{
priorityflag = 10;
}
Was soll device als Parameter ?
uint8_t PrioritySchnittstelle::readFlag(uint8_t device)
{
return priorityflag;
}
Viel Erfolg!
Wenn du static meinst: Damit er sich merkt, welche Geräte gerade Bedarf
haben.
stdio.h wegen uint8_t.
Parameter device hat noch keine Funktion. Macht keinen Sinn da weiter zu
programmieren, so lange ich den eigentlichen Fehler nicht gefunden habe.
Ich verdiene nicht mein Geld mit Programmierung, möchte es aber dennoch
halbwegs sauber machen. Als Programmierer wäre sowas inakzeptabel ist
klar.
Hab rausgefunden, wo der Fehler liegt, aber finde nichts, wie ich es
lösen kann.
Das static ist das Problem, weil static in der Klasse eine völlig andere
Bedeutung hat als das static außerhalb der Klasse (wer denkt sich diesen
Mist aus?)
Ich brauche jedoch pro Objekt eine Variable, die auch nach der
Abarbeitung der Funktion erhalten bleibt, weil später wieder drauf
zugegriffen wird. Also eben eine statische (bzw. nicht flüchtige)
Variable.
Die Variable muss von allen Funktionen der Klasse gelesen werden können,
deshalb funktioniert es nicht, diese in die Funktion zu schreiben. Und
die Variablen der Objekte in main zu speichern wäre am OOP Konzept
vorbei.
Wenn ich im Internet suche, kommt alles mögliche und sehr oft eben das
static für Klassen. Aber static für Objekte finde ich absolut nichts.
Bitte etwas genauer. Oben im Code ein Beispiel wäre super.
Aber ich denke das es nicht das richtig ist, weil wie gesagt steht
static bei OOP dafür, dass eine Variable für alle Objekte einer Klasse
identisch ist.
Ich möchte jedoch für jedes Objekt eine eigene Variable, die ihren Wert
nicht nur zur Laufzeit der Funktion, sondern zur Laufzeit des gesamten
Programms behält.
1. Für jedes Objekt eine eigene Variable.
2. Von jeder Funktion aus schreib und lesbar (für das jeweilige Objekt).
3. Werte bleiben erhalten.
Wenn damit eine "normale Klassenvariable" gemeint ist.
Problem ist der dritte Punkt. Wenn ich static im Beispiel oben weg
machen, kann ich alles machen wie es sein soll, nur eben dass egal was
ich reinschreibe immer 0 rauskommt, wenn ich es lese, weil er nach der
Funktion die Variable gleich wieder verwirft.
Heinz M. schrieb:> wer denkt sich diesen Mist (mit static) aus?
Das habe ich mich auch mal gefragt. Ich denke, das kommt daher, dass
C/C++ den Spagat gewagt hat, einerseits hardwarenah zu sein, und
andererseits eine Hochsprache sein wollte. Das Ergebnis davon ist
nichts halbes und nichts ganzes.
Betrachte das mal aus der Hardware Sicht:
Statische Variablen liegen in dem Speichersegment, dass nur einmal beim
Programmstart initialisiert wird.
Nicht statische Variablen werden dynamisch erzeugt, beim Aufruf einer
Funktion/Methode oder beim Erzeugen einer Objekt-Instanz.
Wenn man das so betrachtet, ergibt es ein bisschen Sinn.
Wie man jedoch auf die Idee kam, das gleiche Schlüsselwort für einen
völlig anderen Zweck bei Methoden-Deklarationen zu benutzen und nochmal
wieder für einen anderen Zweck um die Sichtbarkeit von Variablen zu
beschränken, ist mir ein Rätsel.
Irgendwer muss es toll gefunden haben, da es teilweise in Java
übernommen wurde. Das ist die Sprache, die mit den Fallstricken aller
älteren Sprachen Schluss machen wollte.
Danke für die Erklärung.
Inzwischen funktioniert das mit den Prioritäten. Einmal Priorität
festlegen und man muss sicht nicht mehr drum kümmern, auf wieviele
Geräte gleichzeitig zugegriffen werden soll. Optimierungsbedarf besteht
aber noch.
Dazu bräuchte ich mal eine Idee.
Weil die HAL Bibliotheken je nach µC leicht unterschiedlich sind (i2c
vs. i2c1) und ich auch nicht die Bibliotheken für das Maximum an
möglichen Schnittstellen schreiben wollte, hatte ich vor die HAL
Funktionsaufrufe in der main zu lassen und dadurch meine Bibliothek
vollständig unabhängig zu lassen.
Das führt dazu, dass das löschen eines Displays schon mal 10 Zeilen in
Anspruch nimmt (verschachtelte for Schleifen wo ganz innen drin die HAL
Funktion steht). Schöner wäre es natürlich, wenn ich die for Schleifen
in die Bilbiothek packen könnte, ohne die HAL Funktionen da rein packen
zu müssen.
Meine Ideen wären:
(1) Aus der Bibliothek eine Funktion im Projekt aufrufen. Die Funktion
beinhaltete lediglich die HAL Funktion. Ich weiß aber nicht, wie die
Bibliothek die Funktion kennt, ohne dass ich alle Projekte da rein
packen muss.
(2) Am Ende der while Schleife in der mainloop für alle Schnittstellen
den Sendebefehl ein mal schreiben und vorher eine Abfrage, ob es was zu
schicken gibt. Jedoch müssen dafür die Bibliotheken recht umfangreich
sein. Außerdem wird es bei SPI ätzend mit den zusätzlichen Steuerpins.
(3) Eine do-while Schleife, die immer wieder die Bibliothek aufruft, was
als nächstes gemacht werden soll. Was gemacht werden soll ist binär in
einer Variable abgelegt. In der Bilbiothek selbst werden die Schritte
runtergezählt, was hintereinander passieren soll. Geht nicht mit DMA, es
sei denn es wird mit Variante 2 verknüpft.
1
do
2
{
3
wasTun = Bibliotheksaufruf();
4
if (wasTun & (1 << 1)) {resetPinSet()};
5
if (wasTun & (1 << 2)) {resetPinReset()};
6
if (wasTun & (1 << 3)) {csPinSet()};
7
if (wasTun & (1 << 4)) {csPinReset()};
8
...
9
if (wasTun & (1 << 7)) {SPI Sendebefehl};
10
}
11
while(wasTun > 0);
Gibt es eine bessere Möglichkeit?
Wenn nicht wird es wohl eine Kombination aus 2 und 3.
Bei anderen Bibliotheken wird das ja knallhart da rein gepackt und bei
z.B. SPI die Steuerpins vorgegeben, was die Flexibilität enorm
einschränkt.
Calls per Adapterklasse plus Interfaceklasse abstrahieren, deiner
Schnittstellenklasse eine Referenz auf das Interface verpassen, Adapter
in der main mit instanziieren und deiner Schnittstellenklasse übergeben.
Mehrere verschiedene Adapter können dann auch auf deine verschiedenen
HAL funktionen adaptieren und trotzdem das gleiche Interface fur deine
Schnittstellenklasse implementieren. Der kann dann völlig Rille sein,
welchen Adapter sie bekommt.
So mal wieder etwas weiter gemacht und gleich ein Problem, zudem ich
keine Lösung finde.
Und zwar möchte ich in der main ein Array deklarieren, welches die
Bibliothek dann nutzen soll. An die Funktion ein Array übergeben
funktioniert. Es wäre jedoch schöner, wenn ich das nur ein mal in der
Memberdeklaration machen müsste und im weiteren Programm alle Funktionen
des Objekts auf das Array zugreifen könnten. Das heißt ich muss den
Zeiger übergeben. In der Funktion mit den Speicheradressen rechnen und
auf die Daten hinter dem Zeiger zugreifen.
1
//main.cpp
2
uint8_t i2c1TxDaten [64];
3
4
SSD1306display display1(0x78, 0, i2c1TxDaten); // Adresse, Schnittstelle, zu verwendendes Array als Zeiger
datenArray = 0x40; // geht, macht aber keinen Sinn, müsste &datenArray oder datenArray [0] sein
29
}
Wenn ich Zeiger richtig verstanden habe:
i2c1TxDaten ist ein Zeiger -> Adresse
datenArray ist ein Zeiger -> Adresse
&(datenarray + i) sind die Daten von i2c1TxDaten
Aber warum meckert der da rum wenn ich das & davor setze "lvalue
required as left operand of assignment"
Hatte gestern leider keine Zeit.
"*initDatenArray" ist ein Zeiger, also die Adresse
Also müsste ich mit "datenArray = *initDatenArray;" in
datenArray die Adresse stehen haben oder nicht? Oder kann man Adressen
gar nicht speichern und es muss immer ein zeiger bleiben? Dann wäre
meine Frage, wie man einen Zeiger einem anderen übergibt oder wie man
den Konstruktor anders macht. Wäre sowieso meine Frage, wie man den
Konstruktor evtl. kürzer schreiben kann. Alle bisherigen Versuche haben
nicht funktioniert und ich finde es etwas umständlich extra
Übergabevariablen zu nehmen. Auch wenn ich datenArray als Zeiger mache
meckert er rum.
Soweit ich rausgefunden habe ist "&array)[10]" das gleiche wie "array".
Direkt an die Funktion übergeben funktioniert. Ich möchte jedoch ein
array einem Objekt in der Memberdeklaration zuweisen, so dass im laufe
der Mainloop das array nicht mehr zugewiesen werden muss.
Bzw. auf das Programm bezogen erklärt:
Ein I2C Portexpander braucht für die Kommunikation einen Sendepuffer mit
2 Stellen (was tun, Werte). Bei einem Grafikdisplay braucht man für 4
Zeichen schon ein Array der Größe 24. Um RAM zu sparen soll die
Arraygröße je nach Mikrocontroller und je nach Projekt angegeben werden
können. Bei I2C steht in der mainloop dann mal gut und gerne 50x die
Übergabe des Arrays mit drin. Wenn es nicht geht, dann würde ich es
jedes Mal übergeben.
Wie bekomme ich die Speicheradresse in das Objekt rein, damit ich es von
jeder Funktion nutzen kann?
Heinz M. schrieb:> Also müsste ich mit "datenArray = *initDatenArray;" in> datenArray die Adresse stehen haben oder nicht?
Nein.
Einem Zeiger weist man Adressen zu. Und die Adresse einer Variable
bekommst du mit dem "&" Zeichen.
1
intintegerVariable=123;
2
int*zeigerAufIntegerVariable=&integerVariable;
Und dann gibt es noch Referenzen:
1
voidmeineprozedur(int&referenzAufInteger);
2
{
3
int&nocheineReferenz=referenzAufInteger;
4
}
5
6
intintegerVariable=123;
7
meineprozedur(integerVariable);
Mit Arrays geht das ebenso.
1
voidmeineprozedur(int(&referenzAufArray)[]);
2
{
3
int(&referenzAufArray)[]=referenzAufArray;
4
}
5
6
intintegerArray[]={123,456,789};
7
meineprozedur(integerArray);
Bei Arrays benutze ich persönlich lieber Zeiger. Aber das soll jeder so
machen, wie er mag.
Mal ein paar allgemeine unsortierte Anregungen und Hintergründe.
_
Du lernst offensichtlich gerade C++ und benötigst noch ein wenig
fundamentales Grundwissen rund um Zeiger und Referenzen. Ich würde
vorschlagen da erst ein paar Stunden zu investieren um unnötigen Frust
zu vermeiden.
_
Wenn du C++ nutzt und eine Standard-Bibliothek zur Verfügung steht, dann
nutze sie. Es gibt keinen einzigen Grund ein built-in [] Array einem
std::array vorzuziehen.
_
Versuche möglichst gleich jenen "Dialekt" von C++ zu lernen den man als
modernes C++ bezeichnet. Ein klassisches Beispiel dafür ist etwa die
for-Schleife die du gepostet hast:
1
for(uint8_ti=1;i<anzahlSpalten;i++)
2
{
3
//
4
}
Modernes C++ besitzt sogenannte range-based for die in Kombinationen mit
den Container der Standard-Bibliothek (z.b. std::array) folgende
wesentlich simplere Syntax zulassen:
1
for(auto&spalte:datenArray)
2
{
3
//
4
}
Klassische off-by-1 Fehler lassen sich damit leicht vermeiden.
_
Externe Abhängigkeiten an Objekte zu übergeben heißt im Fachjargon
"dependency injection". Unter diesem Begriff lässt es sich leichter
googlen. Bedenke jedoch, auch in Hinblick auf den vorherigen Punkt,
woher soll die Display-Klasse wissen wo das I2C-Daten Array aufhört wenn
du ledigliche einen Zeiger übergibst?
@Stefanus:
Bei Funktionen funktioniert es mit Zeigern. Aber wie bei Objekten? Zu
Funktionen und Referenzen oder Zeigern findet man haufenweise Beispiele
im Internet. Aber wie man ein Array mit einem Objekt verknüpft, dazu
findet man absolut nichts.
Bei Funktionen reicht ein einfacher Zeiger und kann danach das Array in
der Funktion verwenden. Bei Objekten muss der Zeiger (oder was auch
immer) im Konstruktor sein. Und das so, dass man von der Funktion auf
diesen Zeiger (oder was auch immer) zugreifen kann.
Mal mit Referenz probiert:
liefert bei *1 "unused variable 'datenArray'". Wenn ich dort das uint8_t
weglasse, dann sagt er mir, dass etwas links vom "&" stehen muss.
In der Funktion geht es dann weiter mit Fehlern. Was sich alles darum
dreht, dass er "datenArray" nicht findet, inkompatible Typen oder oder
oder
@Vincent:
Mein Problem gerade ist, dass ich vom hundertsten ins tausendste komme.
Daher lasse ich das mit dem std::array. Und wenn ich bis Freitag keine
Möglichkeit gefunden habe ein Array einem Objekt zuzuweisen, dann wird
halt 50x das gleiche array der gleichen Funktion zugewiesen. Es nützt ja
nichts wenn man sich alles durchliest was möglich ist, aber ohne Praxis
zwischendrin festigt sich nichts.
1
for (auto& spalte : datenArray)
Liefert
"Symbol 'End' could not be resolved"
"Symbol 'Begin' could not be resolved"
Die Größe des Arrays ist egal, solange es groß genug ist. Im Beispiel
des Displays wird der Text in der mainloop eingegeben. Die Funktion
(hier wird die Textlänge übergeben) arbeitet die Buchstaben einfach der
Reihe nach ab. Wenn die Größe automatisch ginge wäre das natürlich auch
toll. Aber ich muss wohl mal einen Strich ziehen und mit den jetzigen
Mitteln etwas vorwärts kommen.
"dependency injection" scheint es zwar zu sein, aber was ich da zu
Arrays gefunden habe ist mir zu hoch.
Heinz M. schrieb:> Aber ich muss wohl mal einen Strich ziehen und mit den jetzigen Mitteln> etwas vorwärts kommen.
Da würde ich dir doch widersprechen. Lesen, verstehen, umsetzen. So
endlos kompliziert sind arrays und Zeiger jetzt nicht.
Was du wahrscheinlich möchtest:
Private Klassenvariable:
uint8_t * datenArray;
Konstruktor Parameter:
uint8_t * DatenArray
Zuweisung im Konstruktor:
datenArray = DatenArray;
Aufruf des Konstruktors:
SSD1306display display1(0x78, 0, &i2c1TxDaten[0]);
Nutzen der privaten Klassenvariable:
for (uint8_t i = 1; i < anzahlSpalten; i++)
{
datenArray[i] = 0x0f;
}
Beim Deklarieren einer Variable gilt:
typ *name oder
typ* name oder
typ * name
ist ein Zeiger auf ein Ding vom angegebenen typ. Das Ding kann eine
einfache Variable sein, oder ein Array. Irgendwas halt. Einem Zeiger
weist man die Adresse von dem Ding zu.
typ &name oder
typ& name oder
type & name
ist eine Referenz auf ein Ding. technisch (im Maschinencode) ist das mit
einem Pointer identisch. Aber im Quelltext werden Referenzen anders
benutzt, nämlich: Einer Referenz weist man das Ding zu.
1
intmeinInteger=123;
2
3
int*zeigerAufInteger;
4
zeigerAufInteger=&meinInteger;// Adresse der Variable -> Zeiger
an. Alle Variablen sind uint8_t.
@NichtWichtig:
Wenn C, warum nicht gleich C++.
Wenn C++, warum nicht gleich OOP.
Wenn OOP, warum nicht gleich Vererbung.
...
und dann wird der Code so kompliziert, dass man nicht mal eine LED zum
Blinken bekommt ;-)
Deswegen werde ich jetzt erst mal Kot aufräumen. Das sieht nach dem
Zeigermassacker aus wie auf dem Schlachtfeld.
Du hast zwei Konstruktoren mit jeweils einem oder zwei Parametern. Aber
du rufst einen (nicht existierenden) Konstruktor mit drei Parametern
auf.
Konkreten können wir werden, wenn du den betroffenen Quelltext zeigt.
[code]
//Konstruktoraufruf
SSD1306display display1(0x78, 0, &i2c1TxDaten[0]);
//Klasse
class SSD1306display
{
public:
void init();
uint8_t addrTx();
void clear(uint8_t zeile, uint8_t anzahlZeilen, uint8_t spalte,
uint8_t anzahlSpalten);
void ssd1306SendeBefehl(uint8_t zeile, uint8_t spalte);
SSD1306display(uint8_t initAdresse, uint8_t initSchnittstelle, uint8_t
*initDatenArray)
{
adresse = initAdresse;
schnittstelle = initSchnittstelle;
datenArray = initDatenArray;
};
private:
uint8_t adresse;
uint8_t schnittstelle;
uint8_t *datenArray;
};
[code]
Gibt doch nur einen Konstruktor.
Bei 4 Parametern zeigt er exakt den gleichen Fehler an.
Desweiteren zeigt er mir an, dass er eine Methode nicht mehr findet. Ich
habe die Methode von ssd1306Befehl in ssd1306SendeBefehl umbenannt, weil
es Aussagekräftiger ist. Wie kann ich Eclipse veranlassen das neu
einzulesen? Clean und Build hat nicht funktioniert.
Heinz M. schrieb:> Gibt doch nur einen Konstruktor.> Bei 4 Parametern zeigt er exakt den gleichen Fehler an.
Dann compilierst du wohl nicht den Code, den du glaubst zu compilieren.
Ich würde mir mal zuerst die zugehörige Header Datei anschauen.
Was ich bei Klasse geschrieben habe ist aus der Header Datei. Der Rest
darin ist von mir geschrieben und hat keinen Zusammenhang.
Kompilieren und Ausführen funktioniert. Macht auch das was er soll. Er
zeigt es mir nur als Fehler an.
Heinz M. schrieb:> class SSD1306display ist ja auch kein Funktionsrumpf.
Aber das ist einer:
1
{
2
adresse=initAdresse;
3
schnittstelle=initSchnittstelle;
4
datenArray=initDatenArray;
5
};
Eventuell erkennt dein Build Prozessor Änderungen in *.h Dateien nicht
automatisch. Make verhält sich auch so.
Ein Clean&Build könnte in deinem Fall helfen.
Für den Fehler: in Eclipse Rechtsklick auf das Projekt im Project
Explorer, Index->Rebuild. Warten.
Kann funktionieren, muss aber nicht. Der Indexer von Eclipse ist eine
Diva. Da kann man nicht so viel drauf geben.
Ich schreib einfach mal hier weiter
Mit der Bibliothek das funktioniert alles schon hervorragend.
Die mainloop ist inzwischen wieder extrem angewachsen, mit Inhalt den
ich nicht in die Bibliothek schieben kann (weil projektspezifisch).
Einen Teil möchte ich in eine extra Datei auslagern, aber so, als wenn
es in der mainloop stehen würde.
Hintergrund ist, dass ich an mehreren Stellen in der mainloop auf die
Objekte zugreife, bzw. verschiedenste Variablen beschreibe und diese am
Ende ausgeben lassen möchte. Dadurch müsste ich sehr viele Objekte bzw.
Variablen übergeben, was das Ganze zu unübersichtlich und
arbeitsintensiv macht. Ich suche also eine Art Sprungmarke, include
main.cpp oder ähnliches, um direkt auf die main.cpp zugreifen zu können.
Aktuell ist so eine Ausgabe 250 Zeilen lang. Ich rechne später mit 2000
Zeilen und mehr (Menüs mit verschiedenen Textbausteinen, die je nach
Menü andere Werte ausgeben oder die Werte anders aufbereiten).
Beispiel in Pseudocode:
Danke, aber ist nicht das was ich suche.
Ich müsste sämtliche Variablen und sämtliche Objekte, die ich in der
main.cpp deklariere in der globaleObjekte.h erneut deklarieren. Und
jedes Mal in beiden Dateien ändern.
weiteres Problem ist, dass ich in die ausgelagerten Dateien auch die
Aufrufe der Peripherie packen möchte.
z.B.:
HAL_I2C_Master_Transmit_DMA(&hi2c1, display1.ssd1306_getAddrTx(),
i2c1TxDaten, i2c1TxLaenge);
Den Error Handler &hi2c1 bekomme ich nicht eingebunden.
extern I2C_HandleTypeDef hi2c1;
I2C_HandleTypeDef does not name a type.
Ich suche mehr etwas, wo der die ausgabe1.cpp, ausgabe2.cpp, ... vor dem
Kompilieren in die mainloop verschoben werden, als wenn die dort stehen
würden. Nur wegen der Übersicht in einer extra Datei. Zusätzliche
Funktionen und Objekte verkomplizieren in dem Fall eher, als das sie
helben.
Heinz M. schrieb:> Ich suche mehr etwas, wo der die ausgabe1.cpp, ausgabe2.cpp, ... vor dem> Kompilieren in die mainloop verschoben werden, als wenn die dort stehen> würden.
Nunja...
Ich bin nicht dein "Wünsch dir was" Flaschengeist!
Kann dir nur zeigen, was geht....
(hoffentlich)
Heinz M. schrieb:> Ich suche mehr etwas, wo der die ausgabe1.cpp, ausgabe2.cpp, ... vor dem> Kompilieren in die mainloop verschoben werden, als wenn die dort stehen> würden. Nur wegen der Übersicht in einer extra Datei. Zusätzliche> Funktionen und Objekte verkomplizieren in dem Fall eher, als das sie> helben.
Rat mal was #include macht.
Ansonsten sollte man bei solchen Wünschen langsam realisieren dass am
Design was nicht stimmt.
Beim Mikrocontroller sind Hardware Schnittstellen in einer ganz
bestimmten Anzahl verfügbar. Dynamik ist hier selten bis nie gefragt.
Ich habe noch keine serielle Schnittstelle gesehen, die zwischendurch
mal weg läuft und durch eine andere Schnittstelle vertreten wird.
Deswegen macht es absolut Sinn, die zugehörigen Objekt-Instanzen (wie
bei Arduino) global und statisch verfügbar zu haben.
In C++ müssen Globale Variablen in einer *.cpp Datei stehen und alle
anderen Quelltexte binden sie mittels "external" Schlüsselwort ein.
Damit man hier Fehler und Code-Duplizierung vermeidet, erstellt man am
Besten eine dazu passende *.h Datei.
Das von Arduino Fanboy gezeigte Pattern mit globaleObjekte.cpp und
globaleObjekte.h hat sich seit zig Jahren bewährt, man hatte es schon
vor C++ so gemacht und tut es ebenso in einigen anderen
Programmiersprachen.
Die .h Datei habe ich erstellt und wenn ich dort alles als extern
hinterlege funktioniert es auch.
Was er aber nicht macht, ist wenn ich die Variablendefinition aus der
von CubeMX erzeugten main.cpp in die von CubeMX erzeugte main.h
verschiebe.
"First defined here"
"Multiple definitions of ..."
Wenn ich es bei der selbst erstellten .h so mache kommt das gleiche. Die
globale Suche findet auch keine weiteren Definitionen der Variable.
--------------------------
Hab den Grund gefunden. Wenn man in .h etwas definiert, wird in jeder
.c/.cpp die darauf zugreift eine eigene Variable definiert.
Dann geht das wohl leider nicht und ich muss mit der einen Dopplung
leben.
Super genau das was ich gesucht habe und funktioniert auch mit Objekten.
Jetzt kann ich 150 Zeilen Definition und 300 Zeilen Code aus der
main.cpp auslagern.
Er zeigt mir noch einen Warnhinweis an:
"inline variables are only available with -std=c++1z or -std=gnu++1z"
Ist damit die Version gemeint?
Definiere die Instanzen in der main und übergebe sie per Referenz den
Konstruktoren der Klassen, die sie brauchen. Damit musst du sie nirgends
global definieren und erhöhst gleichzeitig die Testbarkeit. Dazu sollten
die Referenzen dann noch vom Typ einer Interface Klasse sein damit fürs
testen auch Mock Instanzen verwendet werden können.
Heinz M. schrieb:> Hab den Grund gefunden. Wenn man in .h etwas definiert, wird in jeder> .c/.cpp die darauf zugreift eine eigene Variable definiert.>> Dann geht das wohl leider nicht und ich muss mit der einen Dopplung> leben.
Darum steht ja bei mir auch bei der Deklaration extra das extern
davor!
Damit die Variablen nur einmal in einer *.cpp definiert werden können.
Aber in allen Übersetzungseinheiten verwendet werden können.
---
Wenn dich inline Variablen glücklich manchen, dann schön...
Aber irgendwie passt das nicht zu deiner vorherigen Ansage, meine ich...
Was solls, du glücklich, und gut.
@ bdugfgj: Das macht keinen Sinn. Wie bereits geschrieben möchte ich die
main.cpp komprimieren.
Wenn ich alle Parameter an die ausgelagerte Datei übergebe, nur um es
dort 1:1 an die Library weiterzugeben, habe ich weder Platz gespart noch
ist es komfortabler.
Ich müsste Funktionen schreiben mit ca. 100 Parametern, wovon einiges
Arrays sind. Das wird also nicht nur umständlich sondern auch langsam,
weil ich immer alle Variablen übergeben müsste. Mit inline oder extern
greift er einfach auf die Variablen zu, die er braucht.
Vielleicht mal zur Erklärung:
Die ausgelagerte Datei kann man statt als reinen Quellcode mehr als
Konfigurationsdatei verstehen. Hier wird das Menü und die komplette
Ausgabe aufgebaut, aber ohne die konkrete Berechnung der Pixel für die
Anzeige, Menüsteuerung, Textbausteine, etc.. Diese Berechnung findet in
der Library statt und die Konfigurationsdatei vermittelt zwischen den
beiden.
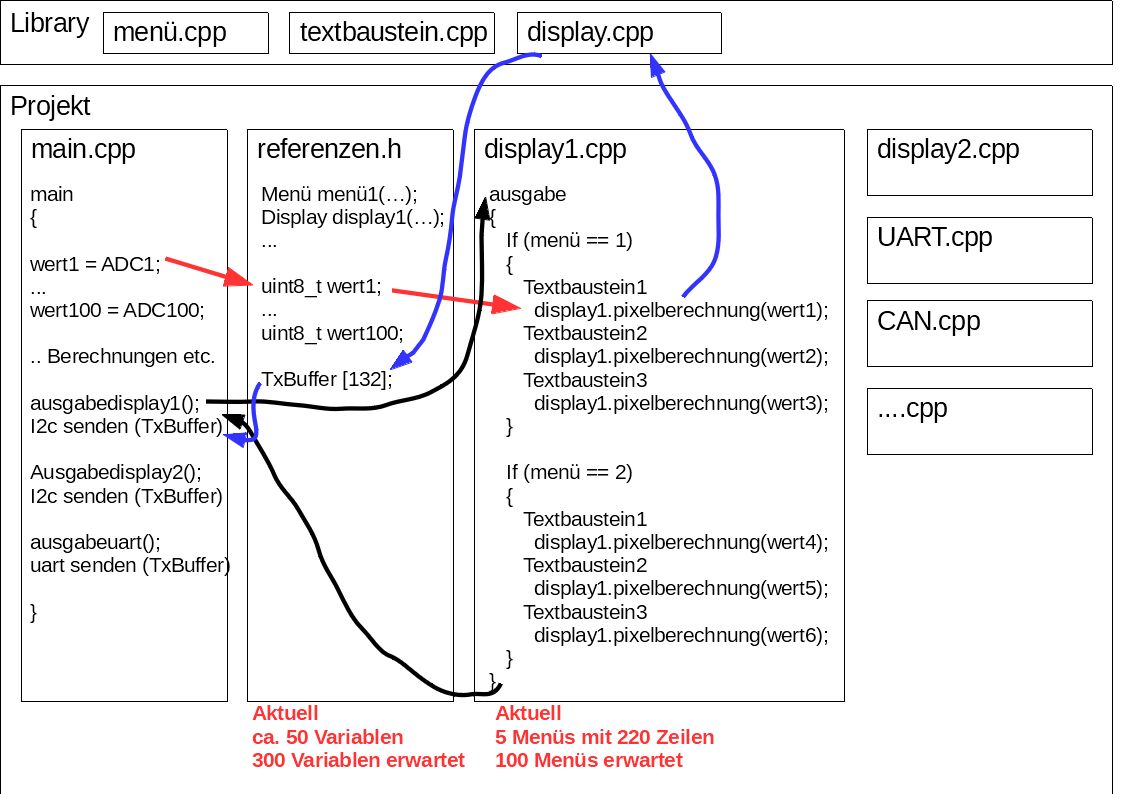
Im Anhang ist ein Bild mit Pseudocode zur Verdeutlichung.
Hier ein Beispiel für ein einziges Menü mit gerade mal 4 Textbausteinen:
1
if (menuDisplay1.readMenuNummer() == 4) // Wenn Menünummer ...
Auf die kleinen 128x64 OLED Displays passen gut 16 bis 32 Textbausteine
drauf. Bei den großen entsprechend mehr. Menüs funktionieren in 4 Ebenen
á 256 Menüs. Im Beispiel oben sind gerade mal 2 Variablen die ausgegeben
werden sollen. Da wäre ein Übergeben noch sinnvoll. Bei 200 ...
Arduino Fanboy D.:
extern nutze ich schon lange. Wenn es nur dafür ist, von der
stm32fxxx_it.cpp zur main.cpp eine Hand voll Variablen zu übergeben ist
das auch sehr praktisch. Wenn man 200 Variablen bzw. Objekte übergeben
möchte, macht das keinen Spaß mehr.
Deine Variablen in der referenzen.h sind dort falsch platziert. Mit dem
Ansatz kann das Ganze nur scheitern.
In Header Dateien gehören nur Sachen rein, die keinen Speicher belegen
und keinen Code erzeugen.
Variablen belegen aber Speicher. Die gehören alle in eine *.c (oder
*.cpp) Datei. Andere Dateien (gerne auch diese referenzen.h) müssen mit
extern auf die Variablen verweisen.
Weil: Wenn du diese fehlerhafte Header Dateil mehr als einmal direkt
oder indirekt in c/c++ Quelltexte einbindest, bekommst du mehrfache
Speicherbelegung (multiple definitions of...) mit gleichen Namen. Und
das ist unzulässig, das kann der Linker nicht verarbeiten.
Erinnerst du dich, dass ich Dir davon abgeraten hatte, allzu komplexe
"Frameworks" zu bauen, solange du noch keine Erfahrung hast? Ich bemerke
hier, dass du nicht einmal die Grundlegendsten Grundlagen der
Programmiersprache verstanden hast. Ich rate Dir erneut, ein gutes Buch
über C und noch ein über C++ zu kaufen und zu studieren. Schau Dich mal
beim Addison Wesley Verlag nach Bjarne Stroustrup um.
"Der 2. Punkt ist das Keyword inline. Das macht nichts anderes als dir
zu erlauben die Funktion in einer header Datei zu definieren. [...]"
https://www.c-plusplus.net/forum/topic/338032/inline-funktionen/5
Das ist typisch Mikrocontroller.net: "Wie kannst du nur sowas machen?
Das ist falsch!", "Kauf dir ein Buch!", "Such dir ein anderes Hobby!"
Irgendwelche Meinungen von irgend jemandem, wie man etwas zu tun oder zu
lassen hätte sind mir sowas von egal. Ich möchte sauberen Code, mit dem
ich gut und schnell arbeiten kann. Hinweise und Tipps nehme ich gerne
auf, aber bei offensichtlich kontraproduktiven Tipps gebe ich Kontra.
Mit inline und .h habe ich die Möglichkeit alles was ich global
brauche in wenige zentrale Dateien zu packen. Dadurch kann ich die .h
Datei neben der .c Datei öffnen und muss Änderungen nur an einer Stelle
eintragen. Es frisst nach meinem Test auch weder mehr Speicher, noch ist
es langsamer. Mit global habe ich auch kein Problem, weil ich mir dazu
eine ziemlich strikte Verwaltung ausgedacht habe und bis jetzt 0
Probleme mit sich plötzlich verändernden globalen Variablen.
Bei extern muss ich es in jeder Datei ändern. Mindestens aber in der
Datei, wo es definiert wird und in einer globalen .h. Warum sollte ich
den zusätzlichen Aufwand machen? Außerdem spare ich aktuell ca. 150
Zeilen in der main.cpp durch das inline.
Funktionen und Objekte sind eine super Sache. Aber zum große
Datenmengen hin und her schubsen werden zum einen die Funktionsaufrufe
unübersichtlich und zum anderen müsste ich bei Änderungen an jedem
Funktionsaufruf, an der Definition und an der Deklaration rumschrauben.
Fehler vorprogrammiert.
Meiner Meinung nach hat jede der 3 Methoden Vor- und Nachteile und
seinen Einsatzzweck. Deswegen verwende ich auch alle 3. Aber in dem Fall
ist inline das Maß der Dinge und funktioniert super. Danke Vincent H.
Und bezüglich der Größe: Ich könnte natürlich ausschließlich LEDs
blinken lassen, solange ich nicht das nötige Wissen habe. Aber ohne
anspruchsvolle Objekte lernt man nichts dazu.
Heinz M. schrieb:> Super genau das was ich gesucht habe und funktioniert auch mit Objekten.> Jetzt kann ich 150 Zeilen Definition und 300 Zeilen Code aus der> main.cpp auslagern.>> Er zeigt mir noch einen Warnhinweis an:> "inline variables are only available with -std=c++1z or -std=gnu++1z">> Ist damit die Version gemeint?
Damit sagt dein Compiler, daß er "inline"-Variable prinzipiell kennt,
sein Default-Modus aber noch nicht C++17 ist und er deshalb eine der
beiden Optionen gesetzt haben möchte.
"c++1z" zeigt, daß es keine ganz aktuelle GCC-Version ist, aus einer
Zeit, als die 7 von 17 noch nicht fest stand.
Heinz M. schrieb:> Bei extern muss ich es in jeder Datei ändern.
Nein, musst du gar nicht. Pass auf:
Datei globals.h:
1
#ifndef globals_h
2
#define globals_h
3
4
#include"serialport.h"
5
#include"stdbool.h"
6
7
externSerialPortserialPort1;
8
externSerialPortserialPort2;
9
externboolemergencyStop;
10
11
#endif
Datei globals.cpp:
1
#include"globals.h"
2
3
SerialPortserialPort1;
4
SerialPortserialPort2;
5
boolemergencyStop=false;
Alle anderen Quelltexte, z.B. main.cpp:
1
#include"globals.h"
2
3
intmain()
4
{
5
serialPort1=SerialPort(...);
6
serialPort2=SerialPort(...);
7
while(!emergencyStop)
8
{
9
serialPort2.send(serialPort1.receive());
10
}
11
}
Hier siehst du zwei Varianten der Initialisierung. Die Variable
"emergencyStop" wird in der globals.cpp initialisiert. Die beiden
seriellen Ports werden in der main.cpp initialisiert. "Zu hause" sind
sie aber alle in der globals.cpp. Wo immer du sie brauchst, bindest du
nur die globals.h ein.
Es sind also nur zwei Dateien, die beim Hinzufügen neuer globaler
Variaben synchron bearbeitet werden müssen.
> Warum sollte ich den zusätzlichen Aufwand machen?
Weil das kein zusätzlicher Aufwand ist, sondern dem Paradigma "es gibt
keine undefinierten Variablen" geschuldet ist. C/C++ ist alt und
hässlich, aber immer noch ein solides Arbeitsmittel. Aber wenn du dich
an solchen Sprach-Details ernsthaft störst, dann wechsle die Sprache,
z.B. nach Python.
C ist halt so. Punkt.
Spätestens wenn du mal echte Libraries benutzt (nicht das war Arduino
"Library" nennt), und diese 5 Jahre nach Programmerstellung
aktualisierst, wirst du den Sinn der Header Dateien einsehen. Dann wirst
du dankbar sein, dass der Compiler dir (fast) alle Inkompatibilitäten
meldet.

{kind=link}