leo schrieb:> Peter D. schrieb:>> uint8_t lpctr = 0;>> do>> {>> }>> while (++lptr);>> Nope. Doppelt falsch.>> leo
Obschon er seinen ursprünglichen Fehler bereits retuschiert hat.
leo schrieb:> Peter D. schrieb:>> uint8_t lpctr = 0;>> do>> {>> }>> while (++lptr);>> Nope. Doppelt falsch.
Ich sehe nur einen Tippfehler (fehlendes "c" in "lptr"), den aber der TE
sicher leicht korrigieren kann.
Wo aber ist der zweite Fehler?
Yalu X. schrieb:> Ich sehe nur einen Tippfehler (fehlendes "c" in "lptr"), den aber der TE> sicher leicht korrigieren kann.>> Wo aber ist der zweite Fehler?
Das fehlende c habe ich nicht gerechnet.
- Test auf Schleifenende fehlt am Anfang der Schleife, bzw ist an
falscher Stelle
- durch Praeinkrement gibt es trotzdem 256 Durchlaeufe
leo
leo schrieb:> - durch Praeinkrement gibt es trotzdem 256 Durchlaeufe
Genau das war allerdings das Desingziel.
Im Gegensatz zum vorgenannten Test auf 255 (sofern ihn der Compiler
nicht gerade auf die Peda-Variante optimiert) ist der Test auf 0 nach
dem Inkrementieren jedoch bei den meisten Maschinen "billiger" da das
Z-Flag implizit gesetzt wird, insofern könnte Peters Variante einen Tick
schneller sein.
James schrieb:> for(uint8_t lpctr = 0;lpctr <= 255;lpctr++)> {> }>> Wird 256 mal durchlaufen
Nein, das ist eine Endlosschleife. Evtl. merkt der Compiler an, dass
lpctr<=255 immer true ist.
leo schrieb:> - Test auf Schleifenende fehlt am Anfang der Schleife, bzw ist an> falscher Stelle
Das ist ja gerade der Trick, um auf die gewünschten 256 Durchläufe zu
kommen.
leo schrieb:> Rechent also ev. schneller was falsches.
Du hast die Aufgabenstellung wohl nicht verstanden. Anders kann man dein
Beharren auf einem angeblichen Fehler Peters (abgesehen vom Tippfehler)
nicht deuten.
Jörg W. schrieb:> Du hast die Aufgabenstellung wohl nicht verstanden.
"Wie oft wird diese Schleife ausgeführt?"
Ehem, nur die Haelfte der Fragen ;-)
leo
Yalu X. schrieb:> James schrieb:>> for(uint8_t lpctr = 0;lpctr <= 255;lpctr++)>> {>> }>>>> Wird 256 mal durchlaufen>> Nein, das ist eine Endlosschleife. Evtl. merkt der Compiler an, dass> lpctr<=255 immer true ist.>> leo schrieb:>> - Test auf Schleifenende fehlt am Anfang der Schleife, bzw ist an>> falscher Stelle>> Das ist ja gerade der Trick, um auf die gewünschten 256 Durchläufe zu> kommen.
Mal eine Frage wieso ist "lpctr<=255 immer true" ?
uint8_t kann doch den wert 255 erreichen
Alexander schrieb:> Mal eine Frage wieso ist "lpctr<=255 immer true" ?>> uint8_t kann doch den wert 255 erreichen
... aber den Wert 256 nicht mehr. Der "nächstgrößere" Wert nach 255 ist
0, was die Schleifenbedingung erfüllt. Da fängt wieder alles von vorne
an.
Jörg W. schrieb:> leo schrieb:>> - durch Praeinkrement gibt es trotzdem 256 Durchlaeufe>> Genau das war allerdings das Desingziel.>> Im Gegensatz zum vorgenannten Test auf 255 (sofern ihn der Compiler> nicht gerade auf die Peda-Variante optimiert) ist der Test auf 0 nach> dem Inkrementieren jedoch bei den meisten Maschinen "billiger" da das> Z-Flag implizit gesetzt wird, insofern könnte Peters Variante einen Tick> schneller sein.
Gut.
Peter D. schrieb:> uint8_t lpctr = 0;> do> {> }> while (++lptr);
Warum gibt's eigentlich kein do … for()? Wenn's das gäbe, könnte man es
so schreiben:
1
do
2
{
3
}
4
for(uint8_tlpctr=0;lcptr<255;++lcptr);
Alexander schrieb:> Mal eine Frage wieso ist "lpctr<=255 immer true" ?>> uint8_t kann doch den wert 255 erreichen
Ja. Und wenn es den Wert 255 hat, ist es doch "kleiner oder gleich" 255,
oder nicht? Also läuft die Schleife weiter.
Die Bedingung sagt, wenn lpctr (was ist das eigentlich für ein blöder
Name?) kleiner oder gleich 255 ist, soll die Schleife weiter laufen. Ein
uint8_t ist aber immer kleiner oder gleich 255, denn einen größeren
Wert kann er gar nicht annehmen. Also läuft auch die Schleife für immer.
Jörg W. schrieb:> Auf welche magische Weise sollte sich diese Schleife nach 256> Durchläufen beenden?
Man drückt im richtigen Moment den RESET-Knopf? ;-)
Wenn man aus der Assemblerecke kommt, sieht das scheinbar nach ner
riesigen Verschwendung aus. Aber oftmals ist die Routine überhaupt nicht
zeitkritisch und dann sollte man der Lesbarkeit immer den Vorzug geben.
Ob man mit 256 vorlädt oder auf <256 vergleicht, ist reine
Geschmackssache. Hauptsache, die 256 steht als Klartext da, wenn 256
gemeint ist.
Heiko L. schrieb:> Um 256 Durchläufe abzuzählen sollte man idR einen Datentyp nehmen der> 256 auch darstellen kann....
Aus der FPGA-Ecke kommend würde ich sagen: damit verschenkt man ein
komplettes Flipflop. Denn mit 8 Bit kann man zuverlässig 256 Zustände
darstellen. Den vorgeschlagenen 257. Zustand braucht man dafür nicht...
;-)
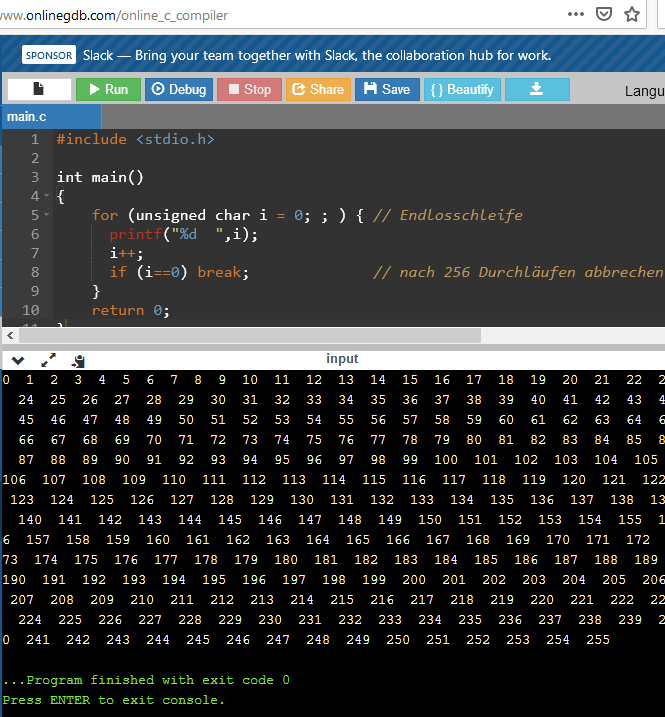
Auf einem 8-Bit µC würde ich das so angehen (inklusive der Kommentare!):
1
for(unsignedchari=0;;){// Endlosschleife ...
2
printf("%d ",i);
3
if(++i==0)break;// ... nach 256 Durchläufen abbrechen
Lothar M. schrieb:> Denn mit 8 Bit kann man zuverlässig 256 Zustände darstellen. Den> vorgeschlagenen 257. Zustand braucht man dafür nicht
Streng genommen braucht man 1 Zustand für jeden Schleifendurchlauf plus
1 Zustand für den Abbruch, so dass man mit einem 8-Bit-Zähler eigentlich
nur 255 Durchläufe realisieren kann.
Wenn man aber – wie in deinem oder dem do-while-Beispiel – die Prüfung
auf Abbruch ans Ende der Schleife stellt, wird der erste Durchlauf
unabhängig vom Zustand (d.h. von der Zählvariablen) ausgeführt, so dass
er keinen eigenen Zustand benötigt. Das hat einen ähnlichen Effekt wie
wenn man bei einer Pre-Checked-Loop eine Kopie des Schleifenrumpfs vor
die eigentliche Schleife stellt. Auf diese Weise erhöht sich die
maximale Anzahl der Schleifendurchläufe um 1, so dass tatsächlich auch
256 Durchläufe möglich sind.
Yalu X. schrieb:> Streng genommen braucht man 1 Zustand für jeden Schleifendurchlauf
Ich wuerde das pragmatischer sehen: mit 8 bits kann man:
- von 0 - 255 oder
- von 1 - 256
zaehlen (usw), also max 256 Durchlaeufe.
Von 0 - 256 geht daher nicht.
leo
>> Wenn man aus der Assemblerecke kommt, sieht das scheinbar nach ner> riesigen Verschwendung aus.
Ist es auch.
> Aber oftmals ist die Routine überhaupt nicht> zeitkritisch
Das ist ja nur ein Aspekt. Es wird auch mehr Codespace sinnlos
verbraten.
> Hauptsache, die 256 steht als Klartext da, wenn 256> gemeint ist.
Bitteschön:
1
ldi R16,Low(256)
2
loop:
3
;insert loop body here
4
subi R16,1
5
brcc loop
6 Bytes Codespace und 256*3 Takte Schleifenoverhead. Und die 256 im
Klartext kommt auch vor...
Für den Schleifenindex würde sich uint_fast8_t anbieten, da dann der
Compiler den effizientesten / schnellsten Datentyp für die jeweilige
Architektur nutzen kann.
Und ein <= in der for-Schleife kann Compiler-Optimierungen (Stichwort:
Loop-Unrolling) beeinträchtigen, da der Compiler dann vom worst-case
einer Endlosschleife ausgehen muss...
c-hater schrieb:>> Wenn man aus der Assemblerecke kommt, sieht das scheinbar nach ner>> riesigen Verschwendung aus.> Ist es auch.
Wenn man mit 8 Bit Prozessoren rummacht.
c-hater schrieb:> Übrigens: das ist ein Fehler versteckt! ;o)
Man sollte nicht den Überlauf bzw. Unterlauf abfragen, sondern wie schon
erwähnt das Zero-Flag.
A. S. schrieb:> der läuft vorhersagbar und effizient bei 255 über?fast, wie der Name schon sagt... ?
A. S. schrieb:> Michael F. schrieb:>> Für den Schleifenindex würde sich uint_fast8_t anbieten,>> Und der läuft vorhersagbar und effizient bei 255 über?
Auf 8 Bit Systemen ja.
Auf 16 oder 32 Bit Systemen läuft uint_fast8_t nicht bei 255 über, ist
aber wenigstens effizient, während bei uint8_t der Überlauf über
Maskierung erledigt wird, was zu Lasten der Performance geht.
Wobei die Frage ist, ob man hinsichtlich Portabilität und Effizienz in C
mit Überläufen arbeiten sollte.
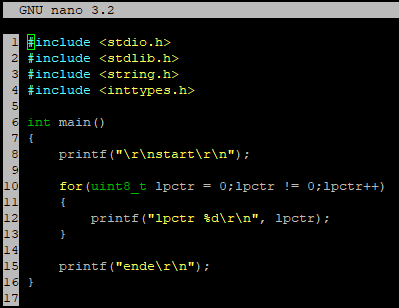
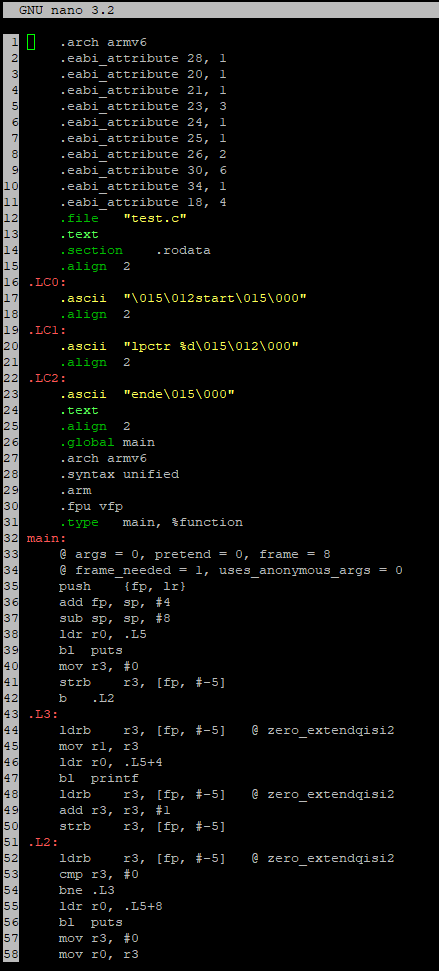
Im Assemblercode test.s sieht man deutlich, dass zuerst die Bedingung
(Code nach .L2) abgefragt wird. .L3 ist der Code in der Schleife.
1
.archarmv6
2
.eabi_attribute28,1
3
.eabi_attribute20,1
4
.eabi_attribute21,1
5
.eabi_attribute23,3
6
.eabi_attribute24,1
7
.eabi_attribute25,1
8
.eabi_attribute26,2
9
.eabi_attribute30,6
10
.eabi_attribute34,1
11
.eabi_attribute18,4
12
.file"test.c"
13
.text
14
.section.rodata
15
.align2
16
.LC0:
17
.ascii"\015\012start\015\000"
18
.align2
19
.LC1:
20
.ascii"lpctr %d\015\012\000"
21
.align2
22
.LC2:
23
.ascii"ende\015\000"
24
.text
25
.align2
26
.globalmain
27
.archarmv6
28
.syntaxunified
29
.arm
30
.fpuvfp
31
.typemain,%function
32
main:
33
@args=0,pretend=0,frame=8
34
@frame_needed=1,uses_anonymous_args=0
35
push{fp,lr}
36
addfp,sp,#4
37
subsp,sp,#8
38
ldrr0,.L5
39
blputs
40
movr3,#0
41
strbr3,[fp,#-5]
42
b.L2
43
.L3:
44
ldrbr3,[fp,#-5]@zero_extendqisi2
45
movr1,r3
46
ldrr0,.L5+4
47
blprintf
48
ldrbr3,[fp,#-5]@zero_extendqisi2
49
addr3,r3,#1
50
strbr3,[fp,#-5]
51
.L2:
52
ldrbr3,[fp,#-5]@zero_extendqisi2
53
cmpr3,#0
54
bne.L3
55
ldrr0,.L5+8
56
blputs
57
movr3,#0
58
movr0,r3
59
subsp,fp,#4
60
@spneeded
61
pop{fp,pc}
62
.L6:
63
.align2
64
.L5:
65
.word.LC0
66
.word.LC1
67
.word.LC2
68
.sizemain,.-main
69
.ident"GCC: (Raspbian 8.3.0-6+rpi1) 8.3.0"
70
.section.note.GNU-stack,"",%progbits
r3 enthält die Laufvariable lpctr
In Anhang run.png sieht man, dass der Code (.L3 bis .L2) innerhalb der
Schleife nicht ausgeführt wird.
Die Laufvariable wird nach dem Schleifencode (drei Zeilen vor .L2 bis
.L2)
inkrementiert.
Michael F. schrieb:> Auf 16 oder 32 Bit Systemen läuft uint_fast8_t nicht bei 255 über, ist> aber wenigstens effizient,
Ah, d.h. er macht die 4E10 Durchläufe genausi schnell, und dann ist das
okay.
Die Schleifen in beiden Funktionen laufen von 0 - 255, was der Bedingung
im Ausgangspost entspricht.
Hier ein Auszug aus dem List-File der IAR Embedded Workbench für Arm
8.40.1 bezüglich Flash-Nutzung der beiden Funktionen (Cortex-M3, no
optimization):
1
BytesFunction/Label
2
-------------------
3
28uint8
4
20uintfast8
Somit spart die Nutzung von uint_fast8_t in diesem Beispiel 8 Bytes ein
und der generierte Code sollte auch schneller sein...
Michael F. schrieb:> (Cortex-M3, no> optimization):
Wenn der Compiler mit angezogener Handbremse und ausgeworfenem Anker
läuft, interessieren die Zahlen niemanden. Nimm "-Os".
Peter D. schrieb:> Wenn der Compiler mit angezogener Handbremse und ausgeworfenem Anker> läuft, interessieren die Zahlen niemanden. Nimm "-Os".
Zumal der Code ja extra weired ist für uint8 mit 256 Durchläufen, wo
Peter D. schrieb:
Peter D. schrieb:> Nimm "-Os".
"-Os" bei IAR?
"high optimization for size (-Ohz)" liefert:
1
BytesFunction/Label
2
-------------------
3
26uint8
4
20uintfast8
Und "no optimization" interessiert Leute, die im Bereich Functional
Safety unterwegs sind und deswegen keine Optimierung nutzen sollen /
dürfen, bzw. Leute, die sich Gedanken über die prinzipiellen
Auswirkungen ihres C-Codes auf den generierten Code machen, bevor der
Compiler da irgendwas dran herum optimiert...
A. S. schrieb:> Zumal der Code ja extra weired ist für uint8 mit 256 Durchläufen
Wenn ich den Unterschied zwischen uint8_t und uint_fast8_t aufzeigen
möchte, dann bringt es (meiner Meinung nach) wenig, wenn ich
unterschiedliche Implementierungen für die beiden Datentypen nutze,
weshalb die beiden beschriebenen Funktionen bis auf den gewählten
Datentyp für den Schleifenindex identisch sind.
Das
1
while(++temp)
bringt keinerlei Vorteile bei der Größe des generierten Codes, ist aber
(ebenfalls wieder meiner Meinung nach) schlechter lesbar, als ein klares
1
while(temp++!=255)
weil so explizit der Startwert 0 und Endwert 255 der Schleife angegeben
ist.
Michael F. schrieb:> Und "no optimization" interessiert Leute, die im Bereich Functional> Safety unterwegs sind und deswegen keine Optimierung nutzen sollen /> dürfen
"No optimization" ist dazu da, um kaputten Code als funktionierendes
Produkt verkaufen zu können.
Michael F. schrieb:> Und "no optimization" interessiert Leute, die im Bereich Functional> Safety unterwegs sind und deswegen keine Optimierung nutzen sollen /> dürfen
Heißt das, du hast einen Compilerhersteller, der dir ohne Optimierung
eine Garantie auf den generierten Code gibt, mit jedoch nicht mehr?
Das wäre mir neu …
Dass das unbedingte Einzwängen auf einen 8-Bit-Datentyp auf einem
Cortex-M eine Pessimierung ist, ist ansonsten logisch, denn es kommen
zusätzliche Maskierungen hinzu, um die gewünschten 8 Bits aus den
"natürlichen" 32 des Registers zu extrahieren.
Jörg W. schrieb:> Heißt das, du hast einen Compilerhersteller, der dir ohne Optimierung> eine Garantie auf den generierten Code gibt, mit jedoch nicht mehr?
Ist jetzt sehr weit off-topic:
Das steht entweder in der FS-Norm oder im TÜV Report zur Toolchain, dass
Optimierungen nicht empfohlen werden und wenn sie doch eingeschaltet
werden, dann muss der optimierte Code für das komplette Debugging /
Testing genutzt werden und man muss sich über alle Auswirkungen der
Optimierung auf sein Projekt Gedanken machen, bzw. die Auswirkungen
abschätzen (oder so ähnlich...)
Michael F. schrieb:> dann muss der optimierte Code für das komplette Debugging / Testing> genutzt werden
Das wiederum würde ich für völlig selbstverständlich halten – das
handhaben wir auch ganz ohne TÜV-Vorschrift so. ;-)
Unklar ist mir, warum es eine Forderung gibt, sich über die Auswirkung
der Optimierung zu vergewissern, aber keine, sich über die Auswirkung
der Nichtoptimierung zu vergewissern: neben größerem und langsameren
Code verhindert ja das Ausschalten der Optimierung die Ausführung von
Compilerschritten, die bestimmte Warnungen aktivieren, sodass am Ende
dadurch u.U. Programmierfehler kaschiert werden können, die mit
Optimierung entweder als Warnung oder Fehlfunktion schnell erkannt
würden.
Jörg W. schrieb:> Unklar ist mir, warum es eine Forderung gibt, sich über die Auswirkung> der Optimierung zu vergewissern, aber keine, sich über die Auswirkung> der Nichtoptimierung zu vergewissern
Das muss man halt einfach so hinnehmen.
Manche Industrien haben halt etwas schräge Vorgaben, vor allem wenn es
um sicherheitskritische Systeme geht.
Mein Liebling ist immer:
In vielen Projekten ist die Verwendung der Standard-Library verboten.
Das führt dann dazu dass sich jeder Entwickler seineigenes memcpy usw
zusammenfrickelt.
Le X. schrieb:> Das führt dann dazu dass sich jeder Entwickler seineigenes memcpy usw> zusammenfrickelt.
Und das soll die Qualität erhöhen und die Entwicklungskosten senken?
Le X. schrieb:> In vielen Projekten ist die Verwendung der Standard-Library verboten.
Je öfter Libarys von verschieden Entwicklern in verschieden Projekten
verwendet werden, umso sicherer sind diese.
Alles selber zu machen ist ein altes Entwicklerleiden.
GEKU schrieb:> Je öfter Libarys von verschieden Entwicklern in verschieden Projekten> verwendet werden, umso sicherer sind diese.
Damizufolge sollte das zu allen Zeiten von allen Leuten verwendete
strcat äusserst sicher sein. ;-)
Lies: Wenn die Spezifikation schon scheisse ist, dann ändern Milliarden
Fliegen auch nichts mehr daran.
GEKU schrieb:> Alles selber zu machen ist ein altes Entwicklerleiden.
Das brauchst du mir nicht erzählen.
Aber solche Auswüchse findet man halt oft in sicherheitskritischen
Projekten.
Da wurden vor > 20 Jahren mal irgendwelche Regeln festgelegt (grade in
der stockkonservativen Automobilindustrie) und an die traut sich niemand
mehr ran.
Das läuft dann unter "defensive programming".
Z.B.:
- Keine Standardlib, denn die ist böse und könnte Fehler enthalten
- Keine Optimierung, denn der Compiler könnte sich ja verhaun (damit
maskiert man freilich viele Fehler die in nicht-optimierten Code nicht
sichtbar werden)
- dieses unsägliche if (FALSE != myConditionSatisfied()) anstatt eines
gut lesbaren (myConditionSatisfied()== TRUE)
Das muss man aber leider so hinnehmen.
Aber wir weichen ab.
A. K. schrieb:> Damizufolge sollte das zu allen Zeiten von allen Leuten verwendete> strcat äusserst sicher sein. ;-)
strcat() ist broken-by-design.
Trotzdem dürfte eine Standard-Implementierung immer noch besser sein als
ein selbstgepfriemeltes wo zu den Design-Schwächen noch die
Programmierfehler hinzukommen ;-)
A. K. schrieb:> GEKU schrieb:>> Je öfter Libarys von verschieden Entwicklern in verschieden Projekten>> verwendet werden, umso sicherer sind diese.>> Damizufolge sollte das zu allen Zeiten von allen Leuten verwendete> strcat äusserst sicher sein. ;-)
Wenn man die länge der Strings bereits kennt und geprüft hat, spricht
nichts gegen strcat. In dem Fall könnte man aber auch gleich memcpy oder
strcpy verwenden.
Das tolle ist dann, wenn Leute versuchen, die wegen einer linter Warnung
durch ein "sicheres" strncpy oder strncat zu ersetzen, und dass dann
total versauen, und ich das dann fixen muss. Beispiel:
https://github.com/dokan-dev/dokany/pull/677
Das hinzufügen von strncat und strncpy zum Standard war ein Fehler.
Diese verwendet man noch fiel eher falsch, als strcat und strcpy, weil
die Leute denken es würde die c string länge korrekt begrenzen, wofür
diese aber garnicht gemacht sind. Ein null byte setzt strcpy aber nicht
am Schluss: https://linux.die.net/man/3/strncpy
Und strncat ist auch super, das limitiert nicht auf n, sondern auf n+1
Zeichen (wenn man das 0 byte mitzählt):
https://linux.die.net/man/3/strncat
In BSD gibt es strlcat und strlcpy, die tun wenigstens was man erwarten
würde, aber die sind leider noch in keinem C Standard:
https://www.freebsd.org/cgi/man.cgi?query=strlcpy&sektion=3
Aber all das ist immer noch weniger problematisch, als wenn jeder seine
eigene falsche strlcat/strlcpy version schreibt.
Le X. schrieb:> - dieses unsägliche if (FALSE != myConditionSatisfied())
Oder sogar (FALSE != myConditionNotSatisfied())
und dann der relevante Code im else-Zweig ;-)
> anstatt eines gut lesbaren (myConditionSatisfied()== TRUE)
Du meinst: (myConditionSatisfied()) // *Ohne!!* "== TRUE"
Volle Zustimmung, Eric
Eric B. schrieb:> Oder sogar (FALSE != myConditionNotSatisfied())> und dann der relevante Code im else-Zweig ;-)>>> anstatt eines gut lesbaren (myConditionSatisfied()== TRUE)
Das hat man schon vor 2000 Jahren nicht gemacht, denn das kann man
beliebig weit treiben:
(X)
(X==TRUE)
((X==TRUE)==TRUE)
(((X==TREU)==TRUE)==TRUE)
...
Wenn die Ampel rot ist, dann ... vs.
Wenn es wahr ist, dass die Ampel rot ist, dann ... vs.
Wenn es stimmt, dass es wahr ist, dass die Ampel rot ist, dann ...
> Du meinst: (myConditionSatisfied()) // *Ohne!!* "== TRUE"
wobei == TRUE (neben der schlechten Lesbarkeit) in C eine schlimme
Unsitte ist, da FALSE nicht immer das Gegenteil von TRUE (oder !FALSE)
ist.
A. K. schrieb:> Damizufolge sollte das zu allen Zeiten von allen Leuten verwendete> strcat äusserst sicher sein. ;-)
Wenn man mit einem Werkzeug nicht umgehen kann wird's gefährlich. Gilt
nicht nur für Entwicklungswerkzeuge.
Auch mit Zeiger kann man viel anstellen. Man muss sich der Gefahren
bewusst sein.
C ist mehr auf Geschwindigkeit als auf Sicherheit optimiert. Das gilt
noch mehr für Assembler Programmierung.
Codereviews sollten Probleme dieser Natur aufdecken und beseitigen.
GEKU schrieb:> Codereviews sollten Probleme dieser Natur aufdecken und beseitigen.
Verrate bitte mehr! Woher bekomme ich als Privatperson einen Codereview?
Wo kann man das kaufen?
Walter T. schrieb:> Woher bekomme ich als Privatperson einen Codereview?
Von anderen Privatpersonen? ;-) Lade es bei Github hoch, finde einen
möglichst interessanten Titel, und du wirst dich vor Reviewern nicht
retten können. :-))
Jörg W. schrieb:> Von anderen Privatpersonen? ;-) Lade es bei Github hoch, finde einen> möglichst interessanten Titel, und du wirst dich vor Reviewern nicht> retten können. :-))
Da braucht's kein github. Lade deinen Code (5 Zeilen reichen) hier
hoch und er wird nach allen (guten und schlechten) Regeln der Kunst
auseinandergenommen.
Jörg W. schrieb:> und du wirst dich vor Reviewern nicht> retten können. :-))
Hat das schonmal funktioniert?
Vielleicht sind da fortgeschrittenere Programmierer anders als ich. Aber
ich interessiere mich nur für GitHub-Projekte, die fortgeschrittener
sind als das, was ich selbst ohne weiteres hinbekäme. Wenn ich sehe,
dass das Projekt weit unter meinen eigenen Kenntnissen liegt, ist es
uninteressant, und ich widme mich wieder interessanteren Themen.
Nach der Logik wären allerdings die Leser nicht unbedingt eine Hilfe für
den Schreiber. *)
*) Ich habe auch schon bei fremden Projekten bei der Doku geholfen. Ein
guter Entwickler ist nicht unbedingt jemand, der gern Doku schreibt. Das
ändert aber am Kern nichts.
Markus F. schrieb:> Lade deinen Code (5 Zeilen reichen) hier> hoch
Scherzkeks. Das Signal-Rausch-Verhältnis hier im Forum ist so übel, da
ist schon ein Zweizeiler eine zweiseitige Diskussion, bei der am Ende
nur fünf oder so sinnvolle Beiträge stehen.
Für jemanden, der lieber entwickelt, als sich mit nervigen Menschen
herumzuschlagen, ist das Forum höchstens eine Notlösung, kein guter
Tipp.
Ich würde von einem Compiler anno 2019 erwarten, dass er das hier für
einen 8-Bit-Controller so optimiert, dass intern auch mit 8 Bit
gerechnet werden:
1
for(uint16_ti=0;i<256;i++){...}
Also, dass diese Schleife (die besser lesbar ist) letztlich den selben
Code erzeugt wie
1
uint8_ti=0;
2
do{...}while(++i);
Und auch, dass es egal ist, ob man im Code hoch- oder runterzählt
(sofern die Zählervariable sonst für nix anderes gebraucht wird
natürlich), weil automatisch das Zero-Flag benutzt wird.
Wahrscheinlich kann der gcc das ja auch. Habe es jetzt nicht getestet.
;)
Malte schrieb:> Ich würde von einem Compiler anno 2019 erwarten, dass er das hier für> einen 8-Bit-Controller so optimiert, dass intern auch mit 8 Bit> gerechnet werden:> for (uint16_t i = 0; i < 256; i++) {...}
Woher soll der Compiler wissen, dass Du ihm zwar mit uint16_t explizit
einen 16 Bit Datentyp für i vorgibst, eigentlich aber nur 8 Bit haben
möchtest?
Und die von Dir beschriebene for-Schleife läuft bis i = 256, bevor sie
auf Grund der false Condition abgebrochen wird und dann sind wir
außerhalb des 8 Bit Wertebereiches.
Walter T. schrieb:> Aber ich interessiere mich nur für GitHub-Projekte,> die fortgeschrittener sind als das, was ich selbst> ohne weiteres hinbekäme. Wenn ich sehe, dass das> Projekt weit unter meinen eigenen Kenntnissen liegt,> ist es uninteressant, [...]
Tatsächlich?
Das bedeutet also, dass Programmieren für Dich reiner
Selbstzweck ist und keinesfalls damit zu tun hat, ein
für Dich selbst nützliches Produkt herzustellen?
> Markus F. schrieb:>> Lade deinen Code (5 Zeilen reichen) hier hoch>> Scherzkeks. Das Signal-Rausch-Verhältnis hier im Forum> ist so übel,
Nicht wirklich. Zudem ist das Signal-Rausch-Verhältnis
durchaus KEINE Konstante, sondern hängt auch davon ab,
wie Du Deine Diskussion pflegst.
Es gibt eine ganze Menge Teilnehmer, die sich nur bei
bestimmten Themen überhaupt zu Wort melden -- und auch
nur dann, wenn das Thema interessant genug und die Frage
intelligent genug ist.
> da ist schon ein Zweizeiler eine zweiseitige Diskussion,> bei der am Ende nur fünf oder so sinnvolle Beiträge> stehen.
Gegenfrage: Warum sollte man mit jemandem, der ein
dermaßen überhöhtes Anspruchsdenken hat, überhaupt
diskutieren wollen?
Statt zu honorieren, dass Du durch eine halbe Stunde lesen
vielleicht einen Denkanstoß bekommen hast, den Du allein
nicht gefunden hättest, beklagst Du Dich, dass es NUR fünf
oder sechs sinnvolle Beiträge sind.
> Für jemanden, der lieber entwickelt, als sich mit nervigen> Menschen herumzuschlagen, ist das Forum höchstens eine> Notlösung, kein guter Tipp.
Wenn Du ausschließlich für Dich selbst entwickelst, ist
das ja auch kein Problem.
Michael F. schrieb:> Malte schrieb:>> Ich würde von einem Compiler anno 2019 erwarten, dass er das hier für>> einen 8-Bit-Controller so optimiert, dass intern auch mit 8 Bit>> gerechnet werden:>> for (uint16_t i = 0; i < 256; i++) {...}>> Woher soll der Compiler wissen, dass Du ihm zwar mit uint16_t explizit> einen 16 Bit Datentyp für i vorgibst, eigentlich aber nur 8 Bit haben> möchtest?
Der Compiler könnte durchaus erkennen, dass die Variable nur dazu dient,
genau 256 Schleifendurchläufe zu erzeugen und dass das auch mit 8 Bit
geht, unter dieser Voraussetzung:
Malte schrieb:> (sofern die Zählervariable sonst für nix anderes gebraucht wird> natürlich)> Und die von Dir beschriebene for-Schleife läuft bis i = 256,
Sie läuft 256 mal. Der Wert, den i später zur Laufzeit hat, und ob es
die Variable überhaupt in der Form gibt, spielt dafür eigentlich keine
Rolle. Sofern der in der Schleife sonst nirgends verwendet wird, kann
sich der Optimizer da beliebig austoben, solange nur sichergestellt ist,
dass die Schleife genau 256 Durchläufe macht.
> bevor sie auf Grund der false Condition abgebrochen wird und dann sind> wir außerhalb des 8 Bit Wertebereiches.
Das beschreibt die Quellcode-Seite, also das was nach ISO C die
"abstrakte Maschine" macht. Das muss nicht mit dem übereinstimmen, was
nachher auf dem Prozessor passiert.
Wie schon erwähnt wurde, kann der Compiler auch loop-unrolling
betreiben, also den Schleifeninhalt einfach 256 mal hinternander ins
Executable schreiben. Dann gibt's zur Laufzeit gar kein i. Oder er kann
eine Mischform erzeugen, also z.B. 16 mal den Schleifenkörper, und das
in einer Schleife mit 16 Durchläufen. Dann steht zur Laufzeit was
vollkommen anderes in der Zählvariablen.
Malte schrieb:> dass er das hier für einen 8-Bit-Controller so optimiert, dass intern> auch mit 8 Bit gerechnet werden:
Er würde es vielleicht dann, wenn es sinnvoll wäre. Aber wozu sollte es
gut sein? Um ungenutzten Stack zu sparen?
Malte schrieb:> Ich würde von einem Compiler anno 2019 erwarten
Warum sollte die Jahreszahl daran etwas ändern?
Der AVR-GCC ist von Grund auf relativ, naja, eigenwillig aufgezogen
worden. Soweit ich Johann (Lay) mal verstanden habe, muss man ihm daher
alle entsprechenden Optimierungen einzeln als Mikrooptimierungen
beibringen, denn ihm ist intern nicht abstrakt klar, dass eine
16-Bit-Zahl eigentlich eine unnötige Verschwendung für die zugrunde
liegende Hardware ist.
Daran ändert auch das Jahr 2019 nicht,s diese Architektur hat er seit
ca. 20 Jahren. Solange keiner einen grundlegenden Rewrite der
Architektur macht (und da würde sich im Jahr 2019 schon die Frage nach
dem Verhältnis von Aufwand zu Nutzen stellen), werden sich solche Dinge
folglich nicht rein zufällig durch eine allgemein kluge Optimierung
ergeben.
Andere von GCC bediente Architekturen als AVR wiederum haben das Problem
sowieso nicht. Bei denen ist das Reduzieren eines "int" auf einen
8-Bit-Typ eher teurer als billiger.
Rolf M. schrieb:> Der Compiler könnte durchaus erkennen, dass die Variable nur dazu dient,> genau 256 Schleifendurchläufe zu erzeugen und dass das auch mit 8 Bit> geht, unter dieser Voraussetzung:
Nachdem dem Compiler über einen "fixed data type" gesagt wird, dass er
16 Bit für i nehmen soll, macht er das auch... Oder wie viel
Interpretationsspielraum möchtest Du dem Compiler einräumen, an den
Eckpunkten Deines Codes was anzupassen?
1
#include<stdint.h>
2
#include"intrinsics.h"
3
4
intmain(void)
5
{
6
for(uint16_ti=0;i<256;i++)
7
{
8
__no_operation();
9
}
10
11
12
uint8_tj=0;
13
do
14
{
15
__no_operation();
16
}
17
while(j++!=255);
18
19
return0;
20
}
Ergibt mit der IAR EWAVR 7.20.1 und high optimization for low size für
einen ATmega16:
1
// 4 int main( void )
2
main:
3
// 5 {
4
// 6 for (uint16_t i = 0; i < 256; i++)
5
LDI R30, 0
6
LDI R31, 1
7
// 7 {
8
// 8 __no_operation();
9
??main_0:
10
NOP
11
// 9 }
12
SBIW R31:R30, 1
13
BRNE ??main_0
14
// 10
15
// 11
16
// 12 uint8_t j = 0;
17
LDI R16, 0
18
// 13 do
19
// 14 {
20
// 15 __no_operation();
21
??main_1:
22
NOP
23
// 16 }
24
// 17 while (j++ != 255);
25
DEC R16
26
BRNE ??main_1
27
// 18
28
// 19 return 0;
29
LDI R16, 0
30
LDI R17, 0
31
RET
32
// 20 }
Im ersten Block werden zwei Register und die Wort-Operation SBIW
genutzt, während im zweiten Block dann nur noch ein Register für die
benötigten 8 Bit für j im Einsatz ist.
Michael F. schrieb:> Nachdem dem Compiler über einen "fixed data type" gesagt wird, dass er> 16 Bit für i nehmen soll, macht er das auch... Oder wie viel> Interpretationsspielraum möchtest Du dem Compiler einräumen, an den> Eckpunkten Deines Codes was anzupassen?
Die "as if rule" zur Optimierung gibt ihn einige Freiheit. Wenn das
resultierende Verhalten dem entspricht, was im Rahmen der Interpretation
anhand der Sprachdefinition im Quelltext steht, dann kann er den
implementieren wie er will. Der Typ der Schleifenvariable definiert nur,
was dabei rauskommen soll, also den Wertebereich, sie muss aber nicht
exakt so implementiert werden.
Er darf die Schleifenvariable verkehrt herum zählen lassen, wenn darauf
nicht zugegriffen wird, und wenn das günstiger ist. Er darf sie auch
ganz weglassen, wenn er die Anzahl Iterationen auch anders
implementieren kann.
Beispielsweise darf er eine stets Nx ausgeführte Schleife auch
vollständig ausrollen, d.h. Nx den Code des Schleifenkörpers
hintereinander schreiben und - sofern überhaupt verwendet - den
jeweiligen Iteratorwert als Konstante einbringen. Oder auch auch die
ganze Schleife weglassen, wenn das nichts am formalen Ergebnis ändert
(darauf fallen Anfänger bei delay loops gerne herein).
Es gibt Architekturen mit speziell optimierten Schleifenkonstruktionen.
Microchips 16-Bitter mit DSP Befehlssatz haben so etwas mit den DO
Befehlen. Ohne Zugriff auf die Schleifenvariable sind die sehr effektiv,
und durchaus zulässig:
1
do #256, l1
2
instr1
3
...
4
l1: instrN
Folglich darf er natürlich auch beim AVR über ein 8-Bit Register zählen,
obwohl ein 16-Bit Typ drinsteht. Wenn das Ergebnis gleich ist.
Michael F. schrieb:> Nachdem dem Compiler über einen "fixed data type" gesagt wird, dass er> 16 Bit für i nehmen soll, macht er das auch... Oder wie viel> Interpretationsspielraum möchtest Du dem Compiler einräumen, an den> Eckpunkten Deines Codes was anzupassen?
Wieviel ich im einräumen will, spielt keine Rolle, aber wieviel ISO C
erlaubt. Solange i nicht volatile ist, darf der Compiler damit machen
was er will. Wie gesagt: Es zählt nur, dass die Schleife genau 256 mal
durchlaufen wird. Wie der Compiler das umsetzt, da hat er komplett freie
Hand.
Dass der Compiler hier davon nicht Gebrauch macht, heißt nicht, dass er
es nicht darf.




{kind=link}