Ich habe ein größeres Projekt für einen C-basieren MicroProzessor, welches in verschiedenenen Konfigurationen läuft und dabei auf unterschiedliche C-File ins allerlei Libs und Unterordnern zugreift. Wie kann ich einfach einen Strukur erstellen lassen, die die statischen Abhängigkeiten zeigt? Wie kann ich ein Ablaufdiagramm erzeugen lassen, welches die Aufrufe in sequenzieller Form zeigt? Es müsste sozusagen durchsimuliert werden. Heraus sollte sowas kommen: Statische Struktur Hauptprogramm.c (Ordner A) --Hauptprogramm.h (Ordner H) --Unterprogramm1.c (Ordner B) ----Unterprogramm1.h (Ordner H) --Unterprogramm2.c ----Unterprogramm2.c ----UnterUnterprogrammX.c -------UnterUnterprogrammX.h --Unterprogramm3.c ----Unterprogramm3.c Dynamische Struktur Start main - Aufruf Funktion1 (Hauptprogramm.c) - Aufruf Funktion2 (Hauptprogramm.c) ---- Aufruf FunktionX (LibA.c) ---- Aufruf FunktionY (LibA.c) ---- Aufruf FunktionZ (LibB.c) - Aufruf Funktion3 (Hauptprogramm.c) ---- Aufruf Funktion M (Unterprogramm1.c) ------- Aufruf Funktion K (LibH.c) ------- ---- Aufruf Funktion P (Unterprogramm1.c) ---- - Aufruf Funktion4 (Hauptprogramm.c) ... u.s.w. also einen statisch Trace, wer wen wann aufruft, um zu erkennen, welche Funktionen wann benutzt werden. Ich muss wissen, welche Libs angefahren werden, welche C-Programme benutzt werden und wo sie liegen, damit ich alles Benötigte zusammenpacken kann. Das Projekt ist leider vollkommen undokumentiert, enthält auch keinerlei Marker für z.B. Doxygen oder so. ----------- Mit welchem freien Programm lässt sich das am einfachsten analysieren? Es ist ein wenig viel, um das per Hand zu machen.
Schön wäre es, wenn die Pragmas mitverarbeitet würden, also beim Setzen bestimmter Randbedingungen wie Prozessor = ARM7 nur die Sachen eingeblendet und gelistet werden, die auch verbleiben und durchgeführt werden, weil sie die zahlreichen bedingten Anweisungen (ifdef) passiert haben. Der Code ist nämlich teilweise für verschiedene Prozessoren ausgelegt, passt sich an PCB-Randbedingungen und andere Parameter durch den User, sowie Betriebsarten an.
Luug mal nach Sourcetrail, ist sehr hilfreich bei solchen Problemen - in fremden Code einarbeiten. Ggf. Understand for C/C++ wobei ersteres für Private Anwender kostenlos ist.
Zynq-Entwickler schrieb: > Das Projekt ist leider vollkommen undokumentiert, enthält auch keinerlei > Marker für z.B. Doxygen oder so. Ich würde trotzdem mal Doxygen versuchen: http://www.doxygen.nl/manual/config.html#cfg_call_graph Das kann auch ohne spezielle Marker Infos über den Code ermitteln. merciless
Angehängte Dateien:
-

sn.jpg
92 KB
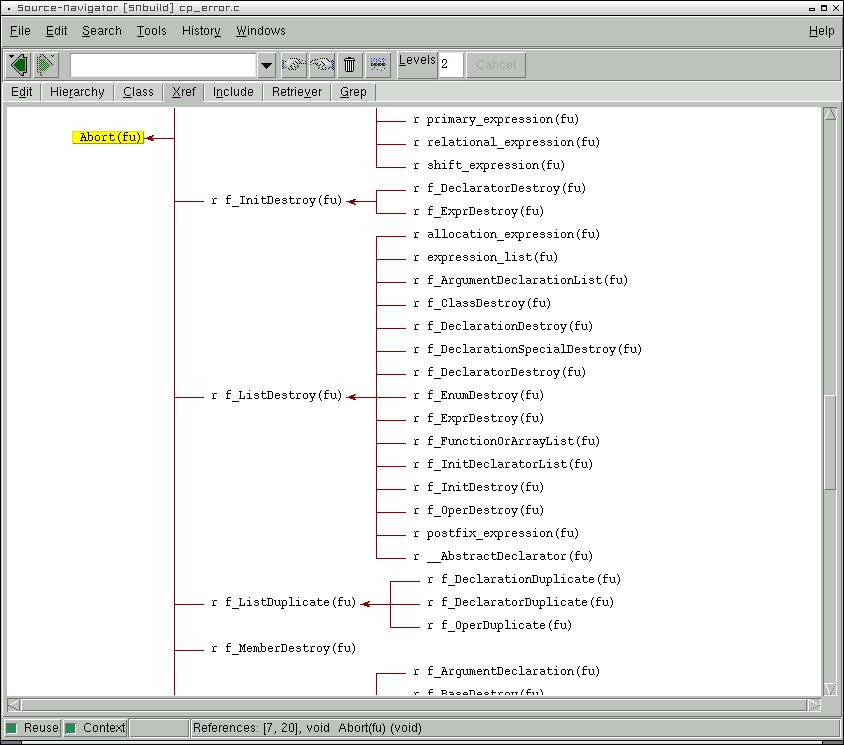
Hat eine gute Bewertung, ich glaube das ist das Richtige: https://sourceforge.net/projects/sourcenav/
Welche Lib-Funktionen (bzw. Files) überhaupt verwendet werden, sagt dir der linker-output. Die call-hirarchie kann oft schon der Editor. Am Ende gilt es, mit Editor, lint, Debugger, doxygen und ein paar weiteren Tools den Code einfach zu untersuchen. Das wichtigste bleibt aber ein guter Editor.
A. S. schrieb: > ...Das wichtigste bleibt > aber ein guter Editor. Genau deshalb gibt es so geile Sachen wir vim !!!
Dirk K. schrieb: > Ich würde trotzdem mal Doxygen versuchen: Habe ich und kenne ich. Leider zu wenig INfos. Die Struktur bringt er noch raus, aber nicht die Abläufe. Ich brauche sozusagen einen virtuellen Simulator, der den Code durchgeht und strikt nach der Reihe die Funktionsaufrufe protokolliert, so, wie es rauskommt, wenn jede Funktion eine Debugmeldung absetzen würde. Keine Ahnung, ob es das gibt. Es geht um ein dickes ARM-Projekt mit unzähligen files, von denen viele gar nicht benötigt werden, weil die Funktionen aufgrund der Konfiguration nicht angesprungen werden, die aber trotzdem im Projekt geliefert werden und als Code im Binasy eingebunden sind, weil der Compiler offenbar auch nicht 100% entscheiden kann, welche Aktititäten später vorkommen.
Zynq-Entwickler schrieb: > Es geht um ein dickes ARM-Projekt mit unzähligen files, von denen viele > gar nicht benötigt werden, weil die Funktionen aufgrund der > Konfiguration nicht angesprungen werden, die aber trotzdem im Projekt > geliefert werden und als Code im Binasy eingebunden sind, weil der > Compiler offenbar auch nicht 100% entscheiden kann, welche Aktititäten > später vorkommen. Das klingt danach, als ob schon die physikalische Struktur des Codes (was in welchen Dateien zusammen steht) Mist ist und sich das auf das Linken auswirkt. Eigentlich ist es der Job des Linkers (nicht des Compilers) nur das einzubinden, was von anderem Code referenziert wird. Bei primitiven, klassischen Linkern werden allerdings immer kompletten .o-Dateien reingezogen, auch wenn von 10 Funktionen in einer .o-Datei nur eine referenziert wird. Wenn man dann beliebigen Müll in den .c-Dateien hat, zieht der Linker beliebigen Müll mit rein. Abhilfe: Mehr .c-Dateien mit weniger Inhalt pro Datei und in einer .c-Datei wirklich nur jeweils das haben, was garantiert immer zusammen benötigt wird. Wenn es nicht anders geht kommt einfach jede Funktion in ihre eigene .c-Datei. Damit hat man pro .o-Datei nur eine Funktion, die entweder hinzu gelinkt wird, oder die .o-Datei wird übersprungen. Erst moderne Linker können Dead-Code-Elimination. Je nach Umgebung muss man dass erst mal einschalten. Ich verwende zwar Dead-Code-Elimination wenn ich kann, aber - alte Schule - strukturiere meine .c-Dateien trotzdem so, dass nur dass, was wirklich zusammen gebraucht wird, zusammen in einer .c-Datei steht. Keine Sammelbecken von irgendwelchem Müll, der nur zusammen in einer Datei steht, weil ich keine Lust hatte eine weitere Datei anzulegen. Ich kenne nur ein Buch, dass die physikalische Organisation von Programmen im Detail behandelt. Es ist schon ziemlich alt und für (altes) C++. https://www.amazon.com/exec/obidos/ASIN/0201633620/ Im Prinzip hebt Lakos auf Modularität ab, so wie es zum Beispiel Wirth populär gemacht hat. Gelegentlich wird C abgesprochen Sprachkonstrukte für modulares Programmieren zu haben. Was einfach nicht stimme. Nur weil es kein Schlüsselwort "module" gibt heißt es nicht, dass man es nicht kann. Header, file-scope Static und projektinterne Bibliotheken sind die Mittel der Wahl.
Ach ja, vergessen: Wenn man sonst nichts hat, kann man mal GNU cflow versuchen um einen Call-Graph zu bekommen https://www.gnu.org/software/cflow/manual/cflow.html Das Ergebnis sollte man dann mit den Funktionssymbolen, die man im fertigen Binary findet, vergleichen. Bei einem linuxoiden Crosscompiler wäre nm aus der jeweiligen Toolchain das Werkzeug um die Funktionssymbole aus dem Binary zu bekommen.
Ich habe den Source Navigator NG schon Jahren für ein übernommenes Projekt, um es besser kennenzulernen, verwendet. Der Navigator erleichtert die Orientierung im Projekt. https://sourceforge.net/projects/sourcenav/
Danke für die bisherigen Tipps. - Die C-Codes kann ich leider nicht verändern und den "Müll" rauswerfen, weil der ja nicht wirklich Müll- sondern nur konkret nicht verwendet wird - Ich möchte ja wissen, welche der Files ich rauskopieren muss, um Ordnung zu bekommen, d.h. im neu zu erzeugenden Projekt nur die C-files übernehmen, die überhaupt nötig sind
Zynq-Entwickler schrieb: > Danke für die bisherigen Tipps. > > - Die C-Codes kann ich leider nicht verändern und den "Müll" > rauswerfen, weil der ja nicht wirklich Müll- sondern nur konkret nicht > verwendet wird > > - Ich möchte ja wissen, welche der Files ich rauskopieren muss, um > Ordnung zu bekommen, d.h. im neu zu erzeugenden Projekt nur die C-files > übernehmen, die überhaupt nötig sind Das ist ein bisschen ein Widerspruch in sich, entweder es gibt Müll in dem Projekt, dann lohnt es sich den zu Identifizieren, oder es gibt den nicht dann wirst Du alle Dateien Kopieren müssen, da sie gebraucht werden.
Jahre her das ich mal mit diesem Tool gearbeitet hatte, war sehr hilfreich. https://scitools.com/features/ FreeTrial-Version gibt es wohl für lau.
Man könnte auch ein Plugin für GCC oder clang schreiben. Ein Kollege hat das kürzlich mal gemacht (GCC) um Zugriffe auf ein struct-member im Linux kernel herauszufinden. Die Lernkurve war wohl steil, aber das Plugin am Ende nicht sonderlich komplex oder lang.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.