Ich hoffe dies ist hier richtig, evtl. wäre ot besser. Also: gegeben ist diese http://wot-news.com/stat/server/eu/norm/en#server-main-2 Graphik. Sie stellt die Häufigkeit dar, wieviele der 4.200.000 Spieler in welches Leistungslevel (WN8) Rating fallen. Die Werte werden für 50er-Rating-Schritte in % der Spieler und absolut in Spieler angegeben. Die absoluten Werten habe ich in Excel eingegeben und kann mir per Trendlinie eine Funktion ausgeben lassen. um so genau wie möglich zu sein nehme ich Polynom 6. Grades. Nun möchte ich ein Array [1..4200000] erstellen (programmieren), wo für jeden Spieler der Skill berechnet wird, so dass insgesamt dieselbe Skillverteilung über alle wie in der Graphik rauskommt. Ich tue mich grad bei der Funktion Skill(i) (i=1..4200000) schwer. Habt ihr eine Idee?
Du möchtest ein 4.2mio zellen breites Array? hmkay aber ich versteh die Frage nicht, Du hast für jedes Skill-level (50-er Sschritt) die Anzahl der Spieler in diesem Level, korrekt? Also array 0 - 224894 füllste mit 50, array 224895 - 224895+284283 mit 100, array 509187 - 509187+201895 mit 150 array 711073 - 711073+222277 mit 200 etc.pp aber ganz ehrlich, ich frage mich wozu?
sid schrieb: > Du möchtest ein 4.2mio zellen breites Array? lang, besteht aus 4.2Mio Einträge mit id und dem Rating also 2 x 4.200.000 groß id: longword (uint32) 4bytes rating: single (float) 4bytes 128MB > aber ich versteh die Frage nicht, > Du hast für jedes Skill-level (50-er Sschritt) die Anzahl der Spieler in > diesem Level, korrekt? > Also > array 0 - 224894 füllste mit 50, > array 224895 - 224895+284283 mit 100, > array 509187 - 509187+201895 mit 150 > array 711073 - 711073+222277 mit 200 etc.pp ja so hab ich mir das auch anfangs gedacht, aber durch die stückelung weiß ich nicht, ob ich genau genug bin, da es tatsächlich ja ein fließender Verlauf ist und nicht z.B. 224894 Spieler genau rating von 50 haben > aber ganz ehrlich, ich frage mich wozu? Simulation
Mike B. schrieb: > Nun möchte ich ein Array [1..4200000] erstellen (programmieren), wo für > jeden Spieler der Skill berechnet wird, so dass insgesamt dieselbe > Skillverteilung über alle wie in der Graphik rauskommt. Aus welchen Daten soll das berechnet werden.
wie ich schrieb, kann ich ja in Excel die Trendlinie als Funktion ausgeben lassen i.M. auf die Darstellung Anzahl der Spieler welche rating x haben also die 224894 auf rating 0..50 daraus ergibt sich eine gewählte Trendlinie als Polynomfunktion 6. Grades Anzahl=f(rating) für die i.M. umgestellte Grafik Anteil in % = f(rating) ergibt sich die Trendlinie y= -2E-22x6 + 3E-18x5 - 2E-14x4 + 6E-11x3 - 7E-08x2 - 1E-05x + 0,0599 ich suche halt die korrekte Berechnungsfunktion für das Rating des Spielers i für alle i=1..4200000
Mike B. schrieb: > wie ich schrieb, kann ich ja in Excel die Trendlinie als Funktion > ausgeben lassen Teste die erstmsl aus. Hab's schon öfter erlebt, dass die viel genauer aussehen, als sie sind. Alternative: Pandas und Numpy
Mike B. schrieb: > wie ich schrieb, kann ich ja in Excel die Trendlinie als Funktion > ausgeben lassen > i.M. auf die Darstellung Anzahl der Spieler welche rating x haben > also die 224894 auf rating 0..50 > daraus ergibt sich eine gewählte Trendlinie als Polynomfunktion 6. > Grades Anzahl=f(rating) Trendlinie Anzahl Spieler = f(rating) ergibt sich y = -2E-15x6 + 4E-11x5 - 2E-07x4 + 0,0007x3 - 1,0408x2 + 485,88x + 128828
Ich hätte auch gerne eine Antwort auf die Frage wozu. Vielleicht gibt es da eine andere Lösung. Du kannst sowieso keinem Spieler mehr "seinen Level" zuweisen, da diese Information in Deinen Rohdaten gar nicht zur Verfügung steht. Daher kannst Du alle Skills gemessen an ihrer prozentualen Verteilung und linearen Skalierung der 50er-Schritte in den Rohdaten beliebig in Deinem Array verteilen. Aus diesem Array kannst Du dann einen zweiten Graphen analog zu den Rohdaten fertigen und "Generierung" der einzelnen "genauen Skills" für einen Bereich wiederholen, wo Dir die Abweichung zu hoch erscheint.
Bin mir nicht sicher, ob ich das Problem verstehe. Wenn du einfach ein Array mit der entsprechenden Verteilung haben willst, fügst du für jedes Ratinglevel gemäß der Anzahl der darunterfallenden Spieler Elemente in das Array ein. Triviale Sache. Ansonsten die Verteilungsfunktion integrieren und die Umkehrfunktion bestimmen… ähm, viel Spaß, ich würde die einfache Lösung nehmen.
Mike B. schrieb: > Trendlinie Anzahl Spieler = f(rating) ergibt sich > y = -2E-15x6 + 4E-11x5 - 2E-07x4 + 0,0007x3 - 1,0408x2 + 485,88x + > 128828 Jemand schrieb: > Ansonsten die Verteilungsfunktion integrieren und die Umkehrfunktion > bestimmen… ähm, viel Spaß, ich würde die einfache Lösung nehmen. Mike B. schrieb: Trendlinie Anzahl Spieler = f(rating) ergibt sich y = -2E-15x6 + 4E-11x5 - 2E-07x4 + 0,0007x3 - 1,0408x2 + 485,88x + 128828 Müsste das dann nach x=f(y) umstellen? kann das ein Matheprogramm wie octave?
Du musst das erst integrieren. Die Trendlinie erstellst du dann am besten gleich in die andere Richtung, dann musst du die nicht noch nach x lösen lassen. Also: Spalte A: WN8-Rating Spalte B: players amount Spalte C: =summe($A$1:A1) (kopieren in alle Zellen) Dann nen Graphen, X-Achse Spalte C, Y Spalte A Trendlinie davon machen lassen...
Mike B. schrieb: > Trendlinie Anzahl Spieler = f(rating) ergibt sich > y = -2E-15x6 + 4E-11x5 - 2E-07x4 + 0,0007x3 - 1,0408x2 + 485,88x + > 128828 > > Müsste das dann nach x=f(y) umstellen? kann das ein Matheprogramm wie > octave? Das was da rauskommt ist ja keine Funktion, es gibt einige Stellen, die mehrwertig sind. Stückweise linear liesse sich einfacher stückweise umstellen. Die Werte von 50-100 und 100-150 dürften Ausreisser sein, insgesamt sieht die Kurve wie eine Poisson-Verteilung aus.
Sollte natürlich > Spalte C: =summe($B$1:B1) (kopieren in alle Zellen) heißen. rµ schrieb: > Das was da rauskommt ist ja keine Funktion, es gibt einige Stellen, die > mehrwertig sind. Stückweise linear liesse sich einfacher stückweise > umstellen. Das muss eh integriert werden, dann ist die Funktion monoton und die Umkehrfunktion muss nicht stückweise definiert werden.
Die Kurve wird keine berechnete Kurve sein. Aber sie ist in etwa das, was ich bei so einer Statistik erwarten würde. Recht viele Gelegenheitsspieler, die Pro's im Mittelfeld und ein paar süchtige Veteranen an der Spitze.
Mike B. schrieb: > sid schrieb: >> Du möchtest ein 4.2mio zellen breites Array? > lang, besteht aus 4.2Mio Einträge mit id und dem Rating > also 2 x 4.200.000 groß > id: longword (uint32) 4bytes > rating: single (float) 4bytes > 128MB > >> aber ich versteh die Frage nicht, >> Du hast für jedes Skill-level (50-er Sschritt) die Anzahl der Spieler in >> diesem Level, korrekt? >> Also >> array 0 - 224894 füllste mit 50, >> array 224895 - 224895+284283 mit 100, >> array 509187 - 509187+201895 mit 150 >> array 711073 - 711073+222277 mit 200 etc.pp > > ja so hab ich mir das auch anfangs gedacht, aber durch die stückelung > weiß ich nicht, ob ich genau genug bin, da es tatsächlich ja ein > fließender Verlauf ist und nicht z.B. 224894 Spieler genau rating von 50 > haben > >> aber ganz ehrlich, ich frage mich wozu? > Simulation heidernei... also zunächst id brauchst Du nicht zweimal.. weil array[id] = value; genausoviel sinnvolle information enthät wie array[counter][id] = value; wenn du den counter tatsächlihc nur zum zählen benutzt Aus statistisch reduzierten Datenmengen kannst Du keine Daten extrapolieren ohne enorme Fehler einzubauen. Solltest Du es also nicht schaffen die realen Werte eines jeden users abfragen zu können, bleib bei den reduzierten werten, die sind genauer! Möchtest Du nur diagonale linien, empfehle Ich dir den Bresenham-Algorithmus damit kannst Du dann auf der "schnellen" x-Achse die User anlegen und auf der "langsameren" y-achse das Skill Level [jeweils im bereich der 50 Punkte pro Gruppe] also
1 | int err, min, max; |
2 | int maxskill = 9000; // was immer der höchste skilllevel ist den Du da hast |
3 | int anzahlusermitskill; |
4 | vector <unsigned int> myarray; |
5 | for (int skill = 50; skill <= maxskill; skil+=50) |
6 | {
|
7 | min = skill -50; |
8 | max = skill; |
9 | value = min; |
10 | anzahlusermitskill = getusercount(skill); // anzahlusermitskill musste Dir aus deiner excel in einen vector oder ne map speichern |
11 | err = anazhlusermitskill/2; |
12 | for( int i= 0; i < anzahlusermitskill; i++) |
13 | {
|
14 | err -= 50; |
15 | if(err < 0) |
16 | {
|
17 | value++; |
18 | err += anazhlusermitskill; |
19 | }
|
20 | myarray.push_back(value); |
21 | }
|
22 | }
|
23 | // und danach kannste schlicht
|
24 | for (int id = 0; id < anzahlalleruser; id++) |
25 | {
|
26 | std::cout << "id: " << id << ", skill: " << myarray[id] << std::endl; |
27 | }
|
und Platz gespart :D (16MB vector) ;) ist immernoch falsch, da du ja nicht weisst ob nicht 200000 user den skilllevel 0 haben und dann biste eben wieder im Abseits Aber nundenn, wenn Du mit Pseudodaten arbeiten willst... mach mal.. geht ja zum Glück nur um n Klospiel da floats zu benutzen halte ich allerdings für absolut bekloppt, Du hast weder die Informationen noch die Notwendigkeit. Aber auch hier.. wenn DU darauf bestehst... das singuläre increment in langsame Richtung ist 50/anzahlusermitskill (was bei 200000 usern also 0,00025 wäre) du kannst also auch
1 | float value = 0; |
2 | for (...) |
3 | {
|
4 | float valincrement = 50/anzahlusermitskill; |
5 | for(...) |
6 | {
|
7 | value +=valincrement; |
8 | myarray_pushback(value); |
9 | }
|
10 | }
|
wenn Du willst
sid schrieb: > myarray_pushback(value); uups zu schnell und dann vertippt muss natürlich
1 | myarray.push_back(value); |
heissen
Mike B. schrieb: > Algorythmus gesucht Hier gibt's Algorythmus :-) https://www.youtube.com/watch?v=IvUU8joBb1Q
Angehängte Dateien:
-

mm.gif
22 KB
{kind=link}
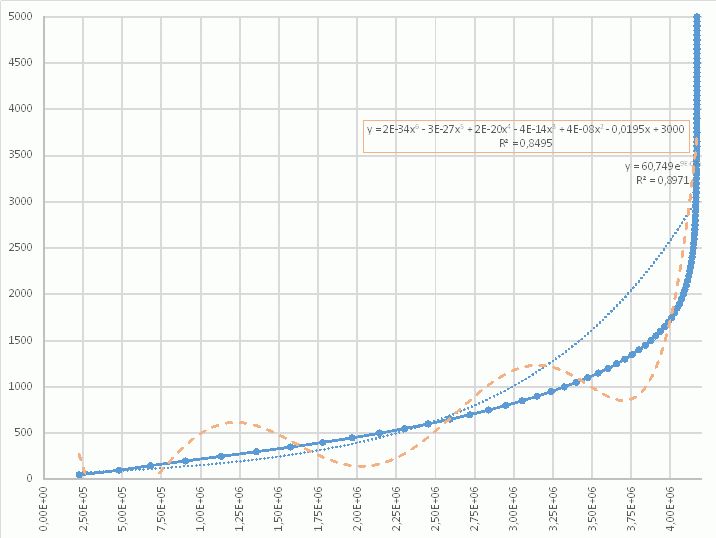
so, Mathias M. schrieb: > Du musst das erst integrieren. Die Trendlinie erstellst du dann am > besten gleich in die andere Richtung, dann musst du die nicht noch nach > x lösen lassen. Also: > Spalte A: WN8-Rating > Spalte B: players amount > Spalte C: =summe($A$1:A1) (kopieren in alle Zellen) > > Dann nen Graphen, X-Achse Spalte C, Y Spalte A > Trendlinie davon machen lassen... leider passt weder die exponentielle (dünn blau gepunktet) noch die polynomische (orange gestrichelt) Trendfunktion auch nur annähernd zum Graphen... Ein Bestimmtheitsmaß von >95% sollte es schon sein. Wie muss ich die exp-Funktion anpassen?
> leider passt weder > die exponentielle (dünn blau gepunktet) noch > die polynomische (orange gestrichelt) Trendfunktion > auch nur annähernd zum Graphen... Ach nee. Ich sags nochmal, das ist keine berechnete Kurve, die sich aus einer einfachen Funktionsgleichung ergibt.
Ben B. schrieb: > Ich sags nochmal, das ist keine berechnete Kurve, die sich aus einer > einfachen Funktionsgleichung ergibt. Zum ungefähren Nachsimulieren der echten Verteilung innerhalb eines Arrays würde eine Trendfunktion mit R²>95% reichen.
sid schrieb: > heidernei... > also zunächst id brauchst Du nicht zweimal.. weil > array[id] = value; genausoviel sinnvolle information enthät > wie > array[counter][id] = value; > wenn du den counter tatsächlihc nur zum zählen benutzt brauch ich später noch da die Spieler noch in anderen Listen individuell über ihre ids angesprochen werden > Möchtest Du nur diagonale linien, empfehle Ich dir den > Bresenham-Algorithmus yupp, das dürfte die beste Variante sein > int maxskill = 9000; // was immer der höchste skilllevel ist den Du da 5000 > Aber nundenn, wenn Du mit Pseudodaten arbeiten willst... nich so sarkastisch ;) echtdaten zu ermitteln ist nicht möglich da ich keine Ahnung von den ids der Spieler beim Spielebetreiber hab, gerade da es hier auch nur um die Auswahl der aktiven Spieler aus der Gesamtliste aller Spieler geht > da floats zu benutzen halte ich allerdings für absolut bekloppt, mir würde 1 odr 2 Stellen reichen, da ich den Skill später selbst weiter berechnen möchte/muss Dies ist ein wesentlicher Bestandteil der Simulation, und da reichen Ganzzahlen nicht, weil die inc's und dec's manchmal nur sehr gering sind. Danke für den Lösungsansatz!
Dann musst Du irgendwas mit sehr vielen Polynomen bauen oder so, ähnlich wie man eine Spannungskurve im Audio-Bereich nachbilden würde. Frag mich aber nicht wie das geht, hatte mich irgendwann mit Fourier-Transform usw. beschäftigt - wenn man das rückwärts macht (z.B. IFFT) würde es gehen - aber das ist so lange her, daß ich fast nichts mehr davon weiß.
Mike B. schrieb: > leider passt weder > die exponentielle (dünn blau gepunktet) noch > die polynomische (orange gestrichelt) Trendfunktion > auch nur annähernd zum Graphen... Hab ich irgendwo die Rohdaten übersehen? Hau die mal rein, dann guck ich mal. Das ist sicherlich keine einfache Funktion, so wie die Ableitung (=das was auf der Webseite angezeigt wird) schon so aussieht. Im Zweifelsfall ist stückweise linear inerpolieren nicht das schlechteste, ansonsten Splines. Hat beides ein Bestimmtheitsmaß von exakt 100% und ist zum Interpolieren sicherlich das sinnigste. Extrapolieren oder andere Aussagen sind dagegen evtl. gewagt.
Ben B. schrieb: > Dann musst Du irgendwas mit sehr vielen Polynomen bauen oder so, ähnlich > wie man eine Spannungskurve im Audio-Bereich nachbilden würde. Frag mich > aber nicht wie das geht, hatte mich irgendwann mit Fourier-Transform > usw. beschäftigt - wenn man das rückwärts macht (z.B. IFFT) würde es > gehen - aber das ist so lange her, daß ich fast nichts mehr davon weiß. Polynome und Frequenzanalyse sind aber zwei verschiedene Paar Schuhe. Für solche Approximationen sind Polynome besser geeignet, weil sie einfacher anzupassen sind. Es läuft auf eine Matrix mit allen Koeffizienten hinaus, die man mit dem Gauss-Algorithmus leicht lösen kann.
o.m.g. schrieb: > Mike B. schrieb: >> Algorythmus gesucht > > https://de.wikipedia.org/wiki/Algorithmus Der Dritte, der mir auf seltsam dämliche Weise zu sagen versucht, dass man Algorithmus mit i und nicht mit y schreibt Habt ihr's bald?
Mike B. schrieb: > Larry schrieb: >>> rythmus >> >> Ich biete mal 5/4-Takt. > > Ich lege den "Algo" obendrauf! Prost!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.