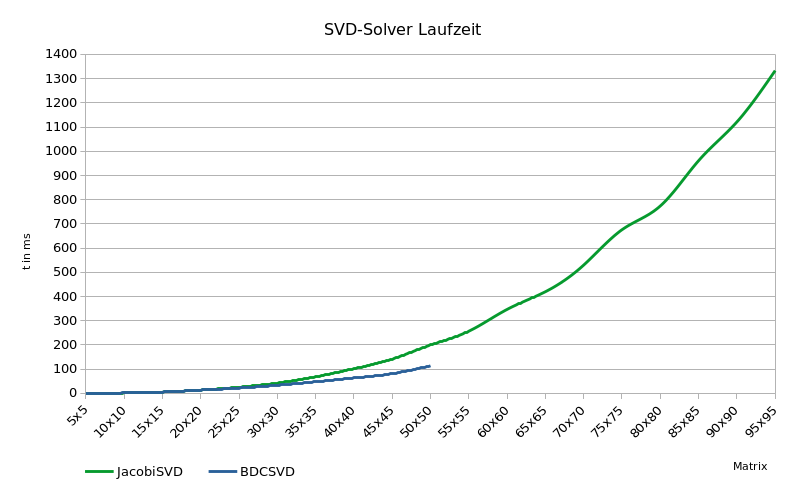
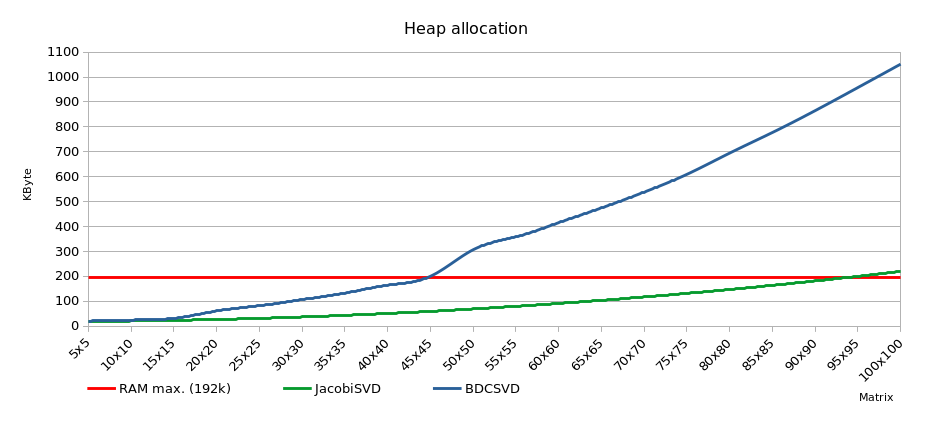
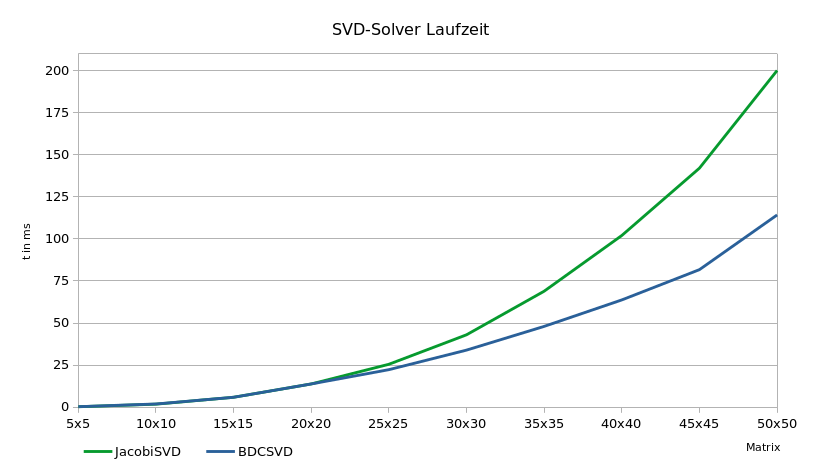
1 | Hello from DISCO_F429ZI
|
2 | Mbed OS version: 5.14.2
|
3 |
|
4 | mSize init bdcSvd jacobiSvd
|
5 | ---------------------------------------
|
6 | 3 0.010 ms 0.136 ms 0.114 ms
|
7 | 4 0.013 ms 0.242 ms 0.220 ms
|
8 | 5 0.016 ms 0.376 ms 0.349 ms
|
9 | 6 0.018 ms 0.719 ms 0.690 ms
|
10 | 7 0.022 ms 0.995 ms 0.965 ms
|
11 | 8 0.026 ms 1.385 ms 1.352 ms
|
12 | 9 0.031 ms 2.002 ms 1.966 ms
|
13 | 10 0.035 ms 2.463 ms 2.424 ms
|
14 | 11 0.041 ms 3.487 ms 3.443 ms
|
15 | 12 0.048 ms 4.407 ms 4.358 ms
|
16 | 13 0.055 ms 5.222 ms 5.170 ms
|
17 | 14 0.061 ms 6.734 ms 6.676 ms
|
18 | 15 0.069 ms 7.397 ms 7.335 ms
|
19 | 16 0.077 ms 10.118 ms 8.983 ms
|
20 | 17 0.086 ms 11.792 ms 11.844 ms
|
21 | 18 0.096 ms 12.791 ms 12.675 ms
|
22 | 19 0.105 ms 15.192 ms 15.038 ms
|
23 | 20 0.116 ms 16.968 ms 17.911 ms
|
24 | 21 0.126 ms 17.886 ms 20.408 ms
|
25 | 22 0.138 ms 21.057 ms 23.333 ms
|
26 | 23 0.149 ms 23.246 ms 25.638 ms
|
27 | 24 0.161 ms 26.239 ms 31.462 ms
|
28 | 25 0.175 ms 28.459 ms 32.017 ms
|
29 | 26 0.188 ms 31.814 ms 34.661 ms
|
30 | 27 0.202 ms 34.920 ms 38.958 ms
|
31 | 28 0.215 ms 38.295 ms 44.780 ms
|
32 | 29 0.230 ms 41.039 ms 47.973 ms
|
33 | 30 0.245 ms 44.506 ms 52.626 ms
|
34 | 31 0.261 ms 48.930 ms 57.163 ms
|
35 | 32 0.279 ms 51.144 ms 63.501 ms
|
36 | 33 0.295 ms 56.137 ms 71.446 ms
|
37 | 34 0.313 ms 59.824 ms 77.364 ms
|
38 | 35 0.330 ms 64.021 ms 79.684 ms
|
39 | 36 0.348 ms 69.526 ms 84.994 ms
|
40 | 37 0.368 ms 71.627 ms 90.017 ms
|
41 | 38 0.387 ms 77.980 ms 106.611 ms
|
42 | 39 0.407 ms 82.666 ms 117.184 ms
|
43 | 40 0.428 ms 89.102 ms 121.475 ms
|
44 | 41 0.449 ms 95.082 ms 130.688 ms
|
45 | 42 0.470 ms 98.353 ms 138.925 ms
|
46 | 43 0.491 ms 107.733 ms 147.745 ms
|
47 | 44 0.514 ms 114.439 ms 162.254 ms
|
48 | 45 0.537 ms 121.967 ms 167.670 ms
|
49 | 46 0.562 ms 126.507 ms 180.827 ms
|
50 | 47 0.585 ms 134.981 ms 183.637 ms
|
51 | 48 0.611 ms 181.772 ms 197.213 ms
|
52 | 49 0.634 ms 218.934 ms 212.051 ms
|
53 | 50 0.660 ms 228.997 ms 231.479 ms
|
54 | 51 0.686 ms 241.682 ms 234.837 ms
|
55 | 52 0.713 ms 264.418 ms 262.289 ms
|
56 | 53 0.739 ms 271.519 ms 269.971 ms
|
57 | 54 0.768 ms 281.938 ms 289.610 ms
|
58 |
|
59 |
|
60 | Hello from NUCLEO_H743ZI
|
61 | Mbed OS version: 5.14.2
|
62 |
|
63 | mSize init bdcSvd jacobiSvd
|
64 | ---------------------------------------
|
65 | 3 0.005 ms 0.048 ms 0.039 ms
|
66 | 4 0.005 ms 0.081 ms 0.073 ms
|
67 | 5 0.006 ms 0.124 ms 0.114 ms
|
68 | 6 0.007 ms 0.233 ms 0.222 ms
|
69 | 7 0.008 ms 0.318 ms 0.308 ms
|
70 | 8 0.009 ms 0.436 ms 0.424 ms
|
71 | 9 0.012 ms 0.624 ms 0.613 ms
|
72 | 10 0.013 ms 0.760 ms 0.747 ms
|
73 | 11 0.016 ms 1.066 ms 1.054 ms
|
74 | 12 0.018 ms 1.338 ms 1.323 ms
|
75 | 13 0.021 ms 1.583 ms 1.562 ms
|
76 | 14 0.024 ms 2.014 ms 1.995 ms
|
77 | 15 0.027 ms 2.198 ms 2.182 ms
|
78 | 16 0.030 ms 3.117 ms 2.649 ms
|
79 | 17 0.034 ms 3.652 ms 3.477 ms
|
80 | 18 0.037 ms 3.882 ms 3.690 ms
|
81 | 19 0.040 ms 4.632 ms 4.364 ms
|
82 | 20 0.045 ms 5.129 ms 5.167 ms
|
83 | 21 0.049 ms 5.272 ms 5.864 ms
|
84 | 22 0.053 ms 6.321 ms 6.670 ms
|
85 | 23 0.058 ms 6.970 ms 7.306 ms
|
86 | 24 0.063 ms 7.850 ms 8.884 ms
|
87 | 25 0.068 ms 8.492 ms 9.031 ms
|
88 | 26 0.074 ms 9.498 ms 9.736 ms
|
89 | 27 0.079 ms 10.358 ms 10.911 ms
|
90 | 28 0.084 ms 11.283 ms 12.472 ms
|
91 | 29 0.090 ms 11.961 ms 13.326 ms
|
92 | 30 0.096 ms 12.974 ms 14.560 ms
|
93 | 31 0.102 ms 14.294 ms 15.759 ms
|
94 | 32 0.109 ms 14.936 ms 17.461 ms
|
95 | 33 0.116 ms 16.637 ms 19.623 ms
|
96 | 34 0.122 ms 17.701 ms 21.172 ms
|
97 | 35 0.129 ms 18.796 ms 21.752 ms
|
98 | 36 0.136 ms 20.337 ms 23.159 ms
|
99 | 37 0.143 ms 20.657 ms 24.480 ms
|
100 | 38 0.151 ms 22.550 ms 29.024 ms
|
101 | 39 0.160 ms 23.783 ms 31.959 ms
|
102 | 40 0.167 ms 25.711 ms 33.068 ms
|
103 | 41 0.176 ms 27.451 ms 35.641 ms
|
104 | 42 0.184 ms 28.136 ms 37.923 ms
|
105 | 43 0.192 ms 30.970 ms 40.407 ms
|
106 | 44 0.202 ms 32.706 ms 44.375 ms
|
107 | 45 0.210 ms 35.043 ms 46.023 ms
|
108 | 46 0.219 ms 35.960 ms 49.642 ms
|
109 | 47 0.229 ms 38.108 ms 50.524 ms
|
110 | 48 0.239 ms 48.215 ms 54.245 ms
|
111 | 49 0.248 ms 55.326 ms 58.728 ms
|
112 | 50 0.258 ms 57.998 ms 64.025 ms
|
113 | 51 0.268 ms 61.431 ms 65.458 ms
|
114 | 52 0.279 ms 67.094 ms 72.578 ms
|
115 | 53 0.289 ms 68.222 ms 74.979 ms
|
116 | 54 0.300 ms 70.554 ms 81.274 ms
|
117 | 55 0.312 ms 75.299 ms 82.743 ms
|
118 | 56 0.322 ms 78.851 ms 84.632 ms
|
119 | 57 0.334 ms 82.780 ms 98.408 ms
|
120 | 58 0.345 ms 84.396 ms 98.985 ms
|
121 | 59 0.357 ms 89.510 ms 101.535 ms
|
122 | 60 0.369 ms 95.451 ms 108.328 ms
|
123 | 61 0.428 ms 97.379 ms 113.102 ms
|
124 | 62 0.394 ms 102.776 ms 122.268 ms
|
125 | 63 0.406 ms 106.267 ms 129.738 ms
|
126 | 64 0.419 ms 113.470 ms 142.612 ms
|
127 | 65 0.432 ms 117.002 ms 138.342 ms
|
128 | 66 0.445 ms 120.279 ms 144.480 ms
|
129 | 67 0.459 ms 126.243 ms 149.958 ms
|
130 | 68 0.472 ms 135.481 ms 165.676 ms
|
131 | 69 0.487 ms 137.607 ms 164.228 ms
|
132 | 70 0.501 ms 142.316 ms 175.621 ms
|
133 | 71 0.515 ms 148.183 ms 179.560 ms
|
134 | 72 0.530 ms 154.451 ms 190.410 ms
|
135 | 73 0.544 ms 160.569 ms 210.034 ms
|
136 | 74 0.558 ms 163.870 ms 199.332 ms
|
137 | 75 0.574 ms 168.268 ms 205.315 ms
|
138 | 76 0.589 ms 175.763 ms 222.522 ms
|
139 | 77 0.604 ms 182.049 ms 228.821 ms
|
140 | 78 0.620 ms 191.724 ms 234.706 ms
|
141 | 79 0.636 ms 196.732 ms 264.469 ms
|
142 | 80 0.651 ms 207.548 ms 254.842 ms
|
143 | 81 0.668 ms 210.594 ms 269.348 ms
|
144 | 82 0.684 ms 217.470 ms 284.311 ms
|
145 | 83 0.700 ms 228.048 ms 292.520 ms
|
146 | 84 0.718 ms 233.186 ms 299.705 ms
|
147 | 85 0.734 ms 242.007 ms 309.080 ms
|
148 | 86 0.751 ms 244.601 ms 318.726 ms
|
149 | 87 0.769 ms 253.876 ms 323.563 ms
|
150 | 88 0.787 ms 265.796 ms 343.603 ms
|
151 | 89 0.804 ms 274.344 ms 359.299 ms
|
152 | 90 0.822 ms 280.532 ms 362.168 ms
|
153 |
|
154 | ++ MbedOS Fault Handler ++
|