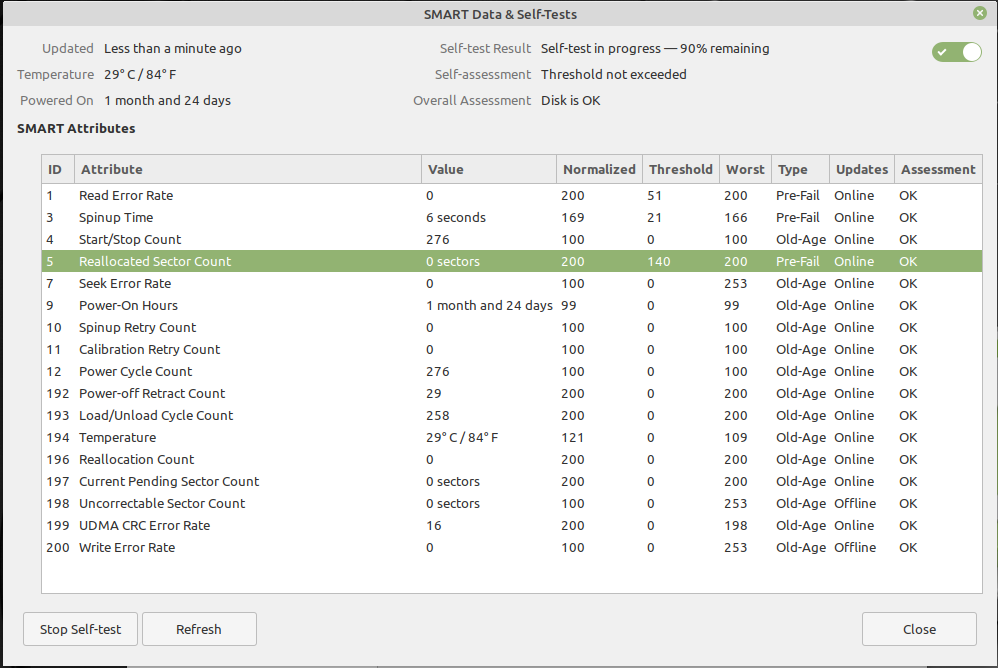
Heute Mittag nicht lange nach dem Einschalten ist mir zweimal hintereinander der Rechner wg. r/o gemounteter root-Partition abgeschmiert. Das passierte vor 2 Wochen, oder so, schonmal. Heute ließ sich die Kiste nach dem 2. Absturz nicht mehr booten und deswegen habe ich ein Debian 10 Mate auf einer anderen Platte gestartet, die Platte gemountet, was erfreulicherweise problemlos ging und ein gutes TB Daten gesichert – das dauert ewig und in der Zeit ist der Rechner völlig lahm gelegt. Noch nichtmal die Maus funktioniert mehr. Nachdem das alles durch war, habe ich wieder von der spinnerten Platte gebootet und bis jetzt läufts. Möglicherweise hängt das Problem mit der Temperatur zusammen, denn der Rechner hat es nachts nicht gerade warm. Ich habe dann sofort die SMART-Daten ausgelesen – außer einer UDMA CRC Error Rate von 16 ist da nichts zu sehen, was auf den ersten Blick bedenklich aussieht. Ein kurzer Selbsttest änderte nichts, einen ausführlichen habe ich gerade laufen, der wird vermutlich bei der 4 TB-Platte erst nächstes Jahr fertig sein. Als die Kiste zum 2. mal umgefallen war, schaltete ich mit ALT-CTRL F1 auf eine Textkonsole und dort lief das Log, dem zu entnehmen war, dass Schreiboperationen auf den Superblock des Filesystems wegen r/o scheiterten. Nach dem ersten heutigen Absturz hatte ich mir die Log-Files angesehen – die enthielten nichts von den Ereignissen, außer ein paar NUL-Zeichen dort, wo der erste Absturze folgte. Was macht man in so einem Fall, außer in kurzen Intervallen die Daten zu sichern?
Angehängte Dateien:
-

SMART-Daten.png
97 KB
Hast du mal das SATA Kabel getauscht? Hatte schon öfter ein madiges SATA Kabel, welches Monate/Jahrelang problemlos ging.
Das ist ne Idee. Dazu muss ich die Platte eigentlich nur in einen anderen Schacht im Wechselrahmen stecken… Aus dem Schacht gezogen und wieder reingesteckt hatte ich sie nach den Abstürzen.
Hi, natürlich nervig so etwas! Wie alt ist denn die Platte überhaupt? Muss man ggf. schon mit solchen Erschainungen rechnen?
Solche krummen Sachen riechen mir auch nach HW-Fehler / Kabelunterbrechung, Wackelkontakt o.Ä.
jens m. schrieb: > Wie alt ist denn die Platte überhaupt? Das siehst du an den SMART-Daten: Knapp 2 Monate gelaufen bei 276 Power-Zyklen. Gekauft im Oktober.
oh, das ist wenig. Zumindest noch Garantie. Aber gibt es mögliche Einflüsse von "aussen" die dieses Fehlerbild erzeugen? Bin mir unsicher, ob Kabel oder gar Controller auf MB so etwas auslösen? Read-Error ja, aber Realocation ... Gibt es andere, sehr alte Komponenten im Rechner? MB, CPU?
Uhu U. schrieb: > die Platte gemountet, was erfreulicherweise problemlos ging und ein > gutes TB Daten gesichert – das dauert ewig und in der Zeit ist der > Rechner völlig lahm gelegt. Noch nichtmal die Maus funktioniert mehr. Das ist meiner Meinung nach ungewöhnlich, hatte ich aber auch schon, und zwar bei alten Core2Duo Notebooks, bei denen ich neue SSDs nachgerüstet habe. (Bei einem über eine USB 3 PCI Express Card). Die schaffen die Datenraten einfach nicht. Bei einem halbwegs modernen PC dürfte dies aber eigentlich nicht passieren, schon gar nicht mit einer verhältnismässig langsamen Festplatte. Schon geschaut, ob dmesg Fehler ausgibt? Das gibt meist etwas aus, was weiter hilft... mfg Andreas
Der ausführliche Selbsttest lief problemlos und ohne Fehler durch. Die Platte läuft im Moment in einem anderen Schacht des Wechselrahmens – bis jetzt ohne Problem. Man wird sehen… ping schrieb: > tune2fs -l /dev/sdXY| grep state das funktioniert nur auf der /boot-Partition, die ist clean. Das eigentliche Dateisystem ist auf einer LUKS-Partition, damit kann tune2fs offenbar nichts anfangen, bei /dev/sda3 kommt Bad magic number in super-block while trying to open /dev/sda3 und /dev/sda3_crypt kennt es gleich gar nicht.
zeig mal /etc/crypttab u. /etc/fstab das man eine Idee vom Aufbau bekommt. > Der ausführliche Selbsttest smart? Das wird mit Hardware nichts zu tun haben. https://serverfault.com/a/375095
/etc/crypttab:
1 | sda3_crypt UUID=<uuid> none luks,discard |
/etc/fstab:
1 | /dev/mapper/mint--19.2--vg-root / ext4 errors=remount-ro 0 1 |
2 | # /boot was on /dev/sda2 during installation |
3 | UUID=<uuid> /boot ext4 defaults 0 2 |
4 | /dev/mapper/mint--19.2--vg-swap_1 none swap sw 0 0 |
ro gemounted und lesbar ist sie ja offensichtlich. Werde root, probiere falls noch nicht geschehen; fsck /dev/mapper/dev/mapper/mint--19.2--vg-root good luck
ping schrieb: > ro gemounted Nein, das ist sie nicht – im Moment läuft sie als Systemplatte. Sie wird nur im Fehlerfall ro gemountet und das ist bisher 3 mal passiert.
Schau Dir mal im BIOS die Pegel der Versorgungsspannungen an. Die Ursache fast aller Probleme die ich in den letzten Jahren (auf drei verschiedenen Rechnern) mit Festplatten hatte, lag darin, dass die Spannungen zu niedrig waren. Wenn ich den Stecker, der vom Netzteil zum Mainboard geht, abgezogen und neu aufgesteckt habe, waren die Spannungen normalerweise wieder OK und die Platten liefen für einige Monate wieder problemlos. Gruß, Bernd
Uhu U. schrieb: > ping schrieb: >> ro gemounted > > Nein, das ist sie nicht – im Moment läuft sie als Systemplatte. zeig halt die Ausgabe von mount > Sie wird > nur im Fehlerfall ro gemountet und das ist bisher 3 mal passiert. Und fsck ist dann beim reboot direkt angesprungen und hat repariert? Geh halt in den single-user mode mach ein mount -o remount,ro lass dann fsck laufen. >> ... und dort lief das Log, dem zu entnehmen war, dass >> Schreiboperationen auf den Superblock des Filesystems wegen r/o >> scheiterten. >> Nach dem ersten heutigen Absturz hatte ich mir die Log-Files angesehen >> die enthielten nichts von den Ereignissen, ... ro ;)
ping schrieb: > Und fsck ist dann beim reboot direkt angesprungen und hat repariert? Er hat sehr lange gebraucht, bis die Passwortabfrage kam, irgend welche Meldungen gab es nicht.
Uhu U. schrieb: > Was macht man in so einem Fall[…]? Ins richtige Log schauen und gucken, warum es ro gemountet wurde.
Jack V. schrieb: > Ins richtige Log schauen und gucken, warum es ro gemountet wurde. Witzbold – wie soll das Log geschrieben werden, wenn die Platte ro-gemountet ist?
Uhu U. schrieb: > Witzbold – wie soll das Log geschrieben werden, wenn die Platte > ro-gemountet ist? Indem man’s so konfiguriert, dass das Log in einem tmpfs, auf einem anderen Datenträger oder auf einer anderen Maschine landet – was am besten passt. Witzig war’s eigentlich nicht gemeint, ich hab nur den Fehler gemacht, eigenständiges Denken anzunehmen. Dessen Fehlen hätte ich aber erkennen können, weil Textausgaben als bunte Bilder gepostet wurden. Entschuldigung dafür, kommt nicht wieder vor – ich werde in Zukunft aufmerksamer sein.
Jack V. schrieb: > Witzig war’s eigentlich nicht gemeint, ich hab nur den Fehler gemacht, > eigenständiges Denken anzunehmen. Ich habe im Eingangsposting genau beschrieben, wie die Situation im Log ist – Ausreden sind also fehl am Platz…
Uhu U. schrieb: > Ich habe im Eingangsposting genau beschrieben, wie die Situation im Log > ist – Ausreden sind also fehl am Platz… Du hast ins falsche, oder in ein unvollständiges Log geschaut – es lässt sich nicht mit Sicherheit sagen, welches von beiden, weil du die entsprechende Information vorenthältst. Wenn ein Dateisystem ro-remounted wird, steht im (vollständigen/richtigen) Log die Ursache. Du könntest dich nun drum kümmern, an die Informationen zu kommen, oder weiter Leuten Blödheit unterstellen, die dir helfen wollen – aber Ausreden sind hier fehl am Platz.
Jack V. schrieb: > Du hast ins falsche, oder in ein unvollständiges Log geschaut – es lässt > sich nicht mit Sicherheit sagen, welches von beiden, weil du die > entsprechende Information vorenthältst. Aha, ins falsche… Welches ist das falsche, wenn man sich alle ansieht? Genau das habe ich nämlich gemacht. > Wenn ein Dateisystem ro-remounted wird, steht im (vollständigen/richtigen) > Log die Ursache. Was ist daran so schwierig zu begreifen, dass ins Log nichts geschrieben werden kann, nachdem das Dateisystem, auf dem es liegt, ro gemountet wurde? Wie war das doch gleich mit dem "eigenständigen Denken"? Jack V. schrieb: > Indem man’s so konfiguriert, dass das Log in einem tmpfs Rat mal, was mit einem tmpfs passiert, wenn man neu booten muss, weil das System ro wurde…
Uhu U. schrieb: > Aha, ins falsche… Welches ist das falsche, wenn man sich alle ansieht? Leider schreibst du ja nicht, welche du dir wie angeschaut hast. Sonst könnte man möglicherweise mit‘m Finger draufzeigen, welches fehlt. Wäre das schlimm, oder wieso schwafelst du nur rum, statt einfach aufzulisten, was genau getan worden ist? Uhu U. schrieb: > Was ist daran so schwierig zu begreifen, dass ins Log nichts geschrieben > werden kann, nachdem das Dateisystem, auf dem es liegt, ro gemountet > wurde? Was ist so schwierig daran zu begreifen, dass man das System einfach so konfigurieren kann, dass das Log eben nicht auf dem betreffenden Dateisystem liegt? Jemand könnte dir sogar genau sagen, wie’s geht – wenn du die Information, um welche Distri/Version es sich eigentlich handelt, nicht auch noch vorenthalten würdest. > Rat mal, was mit einem tmpfs passiert, wenn man neu booten muss, weil > das System ro wurde… a) würd’s mich nicht wundern, wenn das System durchaus weiter zugreifbar ist (tatsächlich spricht alles dafür – wenn du auf ’n tty wechseln kannst, wie du im Eingangsbeitrag geschrieben hast) und b) wurden ebenso zwei andere Varianten genannt. Unterm Strich: Dir geht’s gar nicht darum, den Fehler zu finden, oder? Ich meine, wenn’s darum ginge, würdest du die Infos in Erfahrung bringen und liefern, wenn sie dir selbst nix sagen sollten. Aber … worum geht’s dir dann? Ich versteh’ sowas nicht …
Jack V. schrieb: > Was ist so schwierig daran zu begreifen, dass man das System einfach so > konfigurieren kann, dass das Log eben nicht auf dem betreffenden > Dateisystem liegt? Es ist nun mal so konfiguriert, wie es konfiguriert ist. Dagegen helfen auf altkluge Sprüche im Nachhinein nichts. Zusammengefasst: hättest du das Eingangsposting vollständig gelesen, dann hättest du dir deine dumme Bemerkung verkniffen. Nachträgliche Versuche, deinen unüberlegten Schnellschuss schön zu reden, kannst du dir sparen. Damit ist die Debatte für mich beendet.
Uhu U. schrieb: > Es ist nun mal so konfiguriert, wie es konfiguriert ist. Dagegen helfen > auf altkluge Sprüche im Nachhinein nichts. Ach, und die Konfiguration ist in Kristall gelasert? Ich denke nicht, zumindest habe ich noch kein Linuxsystem gesehen, das man nicht umkonfigurieren könnte¹. Zumal deines ja offensichtlich noch bootet, bevor’s später irgendwann in den Fehler läuft – da bräuchte man noch nicht mal mit ’nem Livesystem zu hantieren. Uhu U. schrieb: > Zusammengefasst: hättest du das Eingangsposting vollständig gelesen, > dann hättest du dir deine dumme Bemerkung verkniffen. Zusammengefasst: hättest du meine Beiträge gelesen und verstanden (oder einfach normal nachgefragt), hättest du uns diese dumme, zeitfressende Diskussion ersparen können, und wüsstest nun schon lange, wo der Fehler ist. Möglicherweise hättest du ihn gar schon beheben können. ¹) stimmt allerdings nicht ganz: bei embedded-Sachen ist’s teils sehr, sehr aufwendig, da was umzukonfigurieren. Aber darum ging’s hier ja nicht. Oder ist das eine weitere Scheibe Salami, die immer noch fehlt?
Wenn man nach sowas noch irgendwie auf die Konsole kommt, dort "dmesg" eintippen. Wen was länger blockiert, es irgendwelche Zugriffsfehler, Dateisystemfehler, vom kernel getroffene Massnahmen, oder sonst was fürs ganze System problematisches gibt, dan findet man es normalerweise dort. (Ist ein Ringbuffer im RAM, die Systemlogger loggen das aber in der regel auch mit.)
Uhu U. schrieb: > ping schrieb: >> Und fsck ist dann beim reboot direkt angesprungen und hat repariert? > > Er hat sehr lange gebraucht, bis die Passwortabfrage kam, irgend welche > Meldungen gab es nicht. Mmh du kannst das auch im Betrieb laufen lassen, darf man eben nichts ändern lassen. [-n] fsck -n /dev/mapper/mint--19.2--vg-root der meckert dann zwar in der Art Warning! /dev/xy is mounted. /dev/xy was not cleanly unmounted, check forced. aber wenn er was findet Free blocks count wrong ... Fix? no Free inodes count wrong ... Fix? no macht er nichts. ---- von weiter oben, geht eigentlich tune2fs -l /dev/mapper/mint--19.2--vg-root
ping schrieb: > > Mmh du kannst das auch im Betrieb laufen lassen, Jo, die Verwertbarkeit des output (auf einer aktiven root) hält sich in Grenzen: skip! >>> /dev/mapper/mint--19.2--vg-root / ext4 ... sollte das aber eigentlich zulassen: > > tune2fs -l /dev/mapper/mint--19.2--vg-root
DPA schrieb: > Wenn man nach sowas noch irgendwie auf die Konsole kommt, dort > "dmesg" > eintippen. Wen was länger blockiert, es irgendwelche Zugriffsfehler, > Dateisystemfehler, vom kernel getroffene Massnahmen, oder sonst was fürs > ganze System problematisches gibt, dan findet man es normalerweise dort. > (Ist ein Ringbuffer im RAM, die Systemlogger loggen das aber in der > regel auch mit.) Gute idee... mit weniger Senf in der Ausgabe, konzentriert auf ata: hans@wurst:~$ dmesg | grep \ ata könnte das in etwa so aussehen (ist natürlich gefaked aus einem uralten Log, und kondensiert auf ata3, meinem damaligem Problemsteckplatz): Dec 1 23:56:52 wurst kernel: [ 0.913122] ata3: SATA max UDMA/133 abar m2048@0xf3ff7000 port 0xf3ff7200 irq 42 Dec 1 23:56:52 wurst kernel: [ 2.407156] ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Dec 1 23:56:52 wurst kernel: [ 2.408583] ata3.00: ATA-8: Hitachi HDS5C3030BLE630, MZ6OAAB0, max UDMA/133 Dec 1 23:56:52 wurst kernel: [ 2.408648] ata3.00: 5860533168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA Dec 1 23:56:52 wurst kernel: [ 2.410171] ata3.00: configured for UDMA/133 Dec 1 23:56:52 wurst kernel: [ 4.342724] ata3.00: exception Emask 0x10 SAct 0x1 SErr 0x400101 action 0x6 frozen Dec 1 23:56:52 wurst kernel: [ 4.342742] ata3.00: irq_stat 0x08000000, interface fatal error Dec 1 23:56:52 wurst kernel: [ 4.342757] ata3: SError: { RecovData UnrecovData Handshk } Dec 1 23:56:52 wurst kernel: [ 4.342771] ata3.00: failed command: WRITE FPDMA QUEUED Dec 1 23:56:52 wurst kernel: [ 4.342798] ata3.00: cmd 61/08:00:00:08:00/00:00:00:00:00/40 tag 0 ncq 4096 out Dec 1 23:56:52 wurst kernel: [ 4.342880] ata3.00: status: { DRDY } Dec 1 23:56:52 wurst kernel: [ 4.342906] ata3: hard resetting link Dec 1 23:56:52 wurst kernel: [ 4.832330] ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Dec 1 23:56:52 wurst kernel: [ 4.835227] ata3.00: configured for UDMA/133 Dec 1 23:56:52 wurst kernel: [ 4.835240] ata3: EH complete Wenn sowas ("frozen", "interface fatal error" bis hin zum "hard resetting link") öfters passiert wundert mich das nicht wenns zu fehlern auf Dateisystemebene kommt. Zumindest zu extremen Verzögerungen. In extremo war im Sekundentakt jeweils für eine halbe Sekunde die Maschine blockiert, hat mich fast in den Wahnsinn getrieben während Umzug auf eine viel grössere Platte. (genau deswegen ja diesen Steckplatz mal wieder benutzt). Meine Lösung damals: reinigen (nass waschen/abrubbeln mit Glasreiniger und Küchentuch) der Steckkontakte an der Platte und des Wechselrahmens. War wohl wegen zu langer Nichtbenutzung verstaubt umd nikotinverklebt; hans raucht, wurst raucht auch manchmal :D HTH
2 Cent schrieb: > Gute idee... mit weniger Senf in der Ausgabe, konzentriert auf ata: > hans@wurst:~$ dmesg | grep \ ata Aus dem Eingangsposting: Uhu U. schrieb: > Nach dem ersten heutigen Absturz hatte ich mir die Log-Files angesehen – > die enthielten nichts von den Ereignissen, außer ein paar NUL-Zeichen > dort, wo der erste Absturze folgte. Bitte erst lesen, dann gute Ratschläge geben! "Geniale" Schüsse in den Nebel helfen keinem.
Uhu U. schrieb: > 2 Cent schrieb: >> ~$ dmesg | grep \ ata > > Aus dem Eingangsposting: > Uhu U. schrieb: >> Nach dem ersten heutigen Absturz hatte ich mir die Log-Files angesehen – >> die enthielten nichts von den Ereignissen, außer ein paar NUL-Zeichen >> dort, wo der erste Absturze folgte. > > Bitte erst lesen, dann gute Ratschläge geben! Ich kann deine Logfiles weder lesen noch interpretieren, das musst du schon selbst tun! Und solange deine vorhandenen Logfiles (wegen remount ro, auch deine Baustelle) nicht den Anlass aufzeichnen interessieren diese hier wohl auch niemanden wirklich, deswegen schlugen Andreas, DPA, und schliesslich auch ich die Benutzung von dmesg vor. Eine Lesehilfe und Suchbegriffe hast du ja nun bekommen, die Platte unter Kommunikationsstress zu setzen (zB Kopiervorgang) musst du auch selbst durchführen. > "Geniale" Schüsse in den Nebel helfen keinem. Was erwartest du denn von diesem Thread? Möchtest du einen ssh-login zur Verfügung stellen, damit andere für dich deiner Maschine auf den Zahn fühlen können?
2 Cent schrieb: > Ich kann deine Logfiles weder lesen noch interpretieren, das musst du > schon selbst tun! Na lesen scheinst zu zumindest rudimentär zu können, aber beim Textverständnis hapert es schwer. > Und solange deine vorhandenen Logfiles (wegen remount ro, auch deine > Baustelle) nicht den Anlass aufzeichnen interessieren diese hier wohl > auch niemanden wirklich, deswegen schlugen Andreas, DPA, und > schliesslich auch ich die Benutzung von dmesg vor. Au weia… Wie oft muss ich noch schreiben, dass wegen des ro-mount eben keine Log-Einträge mehr geschrieben werden konnten. Da hilft dann hinterher auch dmesg nicht weiter. Aber das scheint irgendwie in manche Köpfe einfach nicht hinein zu gehen… > Was erwartest du denn von diesem Thread? Die, die vernünftige Vorschläge gemacht haben, taten das ziemlich am Anfang. Mittlerweile läuft die Platte in einem anderen Schacht; ob das so bleibt, wird sich zeigen. Das Filesystem ist jedenfalls gesund und SMART ist auch der Meinung, die Platte sei OK. Man wird sehen…
… und du möchtest auch weiterhin nicht dafür sorgen, selbst an die relevanten Informationen zu kommen? Ich bin immer noch ein wenig erstaunt, weil ja deine Frage war, was man in so einem Fall machen würde, und genau das es ist, was man einem solchen Fall sinnvollerweise macht. Da stellt sich dann doch schon irgendwie die Frage, was du denn nun überhaupt möchtest. Würd’s dir viel ausmachen, sie zu beantworten?
Jack V. schrieb: > Würd’s dir viel ausmachen, sie zu beantworten? Ich hatte zuerst auf einen Fehler in der Platte getippt, aber nicht an die Kabel gedacht – das taten netterweise Timmo H. und Mark S. Damit waren die wahrscheinlichen Fehlerquellen in Betracht gezogen. Mit Datensicherung hatte die Maschine den Tag verbracht und das lief alles glatt, also eher kein Mainboard-Problem. Man kann dann eigentlich nur das Filesystem und die Platte selbst testen – das habe ich auch gemacht, ohne Fehler zu finden. Dann kann man sich leider nur noch in Geduld üben, regelmäßig Daten sichern und beobachten, was die Kiste macht. Das ist es, was derzeit tue. Da ich hier nachgefragt habe, sehe ich mich in der Pflicht, zu berichten, was weiterhin passiert, damit auch andere die Erfahrungen nutzen können. Was aber nicht sein muss, ist eine ewige Schleife mit Blitzmerkern, die es noch nichtmal schaffen das Eingangsposting mit eingeschaltetem Verstand zu lesen, von den restlichen Beiträgen ganz zu schweigen.
Nochmal ganz ohne Drama: es gibt heutzutage die Möglichkeit, den Ort des Logs in der Konfiguration festzulegen. Das kann ein anderer Datenträger sein, oder sogar eine komplett andere Maschine. Wenn du das machen würdest, hättest du eine erheblich höhere Wahrscheinlichkeit, die nahezu an Sicherheit grenzen würde, die Ursache des Fehlers nach seinem Auftreten im Log nachlesen zu können. Was die Erwähnung von ›dmesg‹ seitens anderer User anging: du selbst schriebst im Eingangsbeitrag, dass du TTY1 erreichen konntest. Die Leute gingen nun davon aus, dass du dort eine Shell zur Verfügung gehabt haben könntest – dazu schreibst du leider nichts. Wenn das der Fall sein sollte, hättest du dort mit ›dmesg‹, ggf. in Verbindung mit ›less‹ (oder ›more‹ oder, wenn du weißt, wonach du suchst, auch mit ›grep‹) die Möglichkeit, an Informationen zu kommen. Es handelt sich nicht um eine Logdatei, so dass der Mount-Status des Dateisystems unerheblich wäre. Wenn du nun immer noch der Meinung sein solltest, ich hätte deinen Eingangsbeitrag nicht gelesen und wollte dir nur Böses, bzw. klugscheißen, dann weiß ich auch nicht.
Nochmal ganz ohne Drama: Es handelt sich um einen Fehler, der jetzt 3 mal aufgetreten ist innerhalb eines Monats und das System war eben so konfiguriert, dass das /var-Verzeichnis auf der root-Partition liegt. (Linux Mint 19 Standard-Konfiguration.) > Wenn du das machen > würdest, hättest du eine erheblich höhere Wahrscheinlichkeit, die nahezu > an Sicherheit grenzen würde, die Ursache des Fehlers nach seinem > Auftreten im Log nachlesen zu können. Wenn er denn nochmal auftritt… Das hat er bisher nicht gemacht. Wäre die Ursache ein defekter Sektor oder ein nicht behebbarer Lesefehler gewesen, hätte man das den SMART-Daten entnehmen können – das Einzige, was dort vermerkt ist, sind 16 CRC-Fehler. Ratschlag von https://kb.acronis.com/content/9135 dazu:
1 | This parameter is considered informational by the most hardware vendors. Although degradation of this parameter can be an indicator of drive aging and/or potential electromechanical problems, it does not directly indicate imminent drive failure. Regular backup is recommended. Pay closer attention to other parameters and overall drive health. |
> du selbst > schriebst im Eingangsbeitrag, dass du TTY1 erreichen konntest. Die Leute > gingen nun davon aus, dass du dort eine Shell zur Verfügung gehabt haben > könntest – dazu schreibst du leider nichts. Einloggen ging leider nicht, weil die Log-Meldungen im Dauerbetrieb über den Schirm rauschten. Umschalten auf eine andere Konsole half auch nichts, denn dort war es nicht anders. (Dass ein Login ohne Schreibzugriffe auf die Systemplatte vonstatten gehen kann, halte ich im Übrigen für wenig wahrscheinlich.) Man konnte den huschenden Meldungen gerade so entnehmen, dass die Platte ro war, was zumindest das Fehlerbild kurz nach dem Zusammenbruch erklärte: man konnte beliebige Programme mit einem einfachen Mausklick irgendwo ins Fenster "wegzaubern" – ohne Fehlermeldung. Nach einem Klick aufs Menü, war auch das abgestürzt… > Wenn das der Fall sein > sollte, hättest du dort mit ›dmesg‹, ggf. in Verbindung mit ›less‹ (oder > ›more‹ oder, wenn du weißt, wonach du suchst, auch mit ›grep‹) die > Möglichkeit, an Informationen zu kommen. Eben nicht. Wenn die Log-Patition ro ist, dann wird das nix, weil nichts ins Log geschrieben werden kann – wie oft habe ich das jetzt hier schon geschrieben? Das, was drin steht, kann man sich aber nach dem nächsten Boot ansehen, dank Zeitmarken kann man sogar sehen, wo es geknallt hat – dort stehen besagte NUL-Zeichen und die letzte Meldung davor sagt nichts über Plattenprobleme. > Wenn das der Fall sein > sollte, hättest du dort mit ›dmesg‹, ggf. in Verbindung mit ›less‹ (oder > ›more‹ oder, wenn du weißt, wonach du suchst, auch mit ›grep‹) die > Möglichkeit, an Informationen zu kommen. Es handelt sich nicht um eine > Logdatei, so dass der Mount-Status des Dateisystems unerheblich wäre. Die Konfigurationsdateien von rsyslogd sagen zwar ganz eindeutig:
1 | # |
2 | # Emergencies are sent to everybody logged in. |
3 | # |
4 | *.emerg :omusrmsg:* |
In der Praxis heißt das offensichtlich, dass rsyslogd im vorliegenden Fall seine Meldungen einfach auf jede geöffnete Konsole "kotzt", wobei man noch nichtmal eingeloggt sein muss. Wie man in dem Fall mit less & Co. was machen soll, erschließt sich mir nicht. Zudem sind die Meldungen über das auslösende Ereignis garantiert schon 1000 weggerollt, bis man eine Konsole offen hat. Die Fehlerkonstellation kommt zum Glück nicht so oft vor und folglich ist das Systemverhalten in solchen Fällen auch nur wenigen bekannt. Auf der anderen Seite ist aber das Konzept "ro" relativ leicht zu verstehen und wenn es die Partition trifft, auf der die Log-Files liegen, dann sollte es eigentlich jedem sofort klar sein, dass keine Log-Meldungen mehr gespeichert werden. rsyslogd umkonfigurieren? Dafür käme eigentlich nur eine weitere Festplatte oder ein USB-Stick in Frage. Welche Konsequenzen das für die Logs während der Startphase hat, überschaue ich nicht. Nicht dass man dann für Boot-Probleme blind ist, weil die Log-Partition noch nicht gemountet ist…
Der ausführliche SMART-Test liest laut https://www.thomas-krenn.com/de/wiki/SMART_Tests_mit_smartctl die komplette Platte – der lief fehlerfrei durch. Die SMART-Daten waren hinterher unverändert, also scheint die Platte keine Probleme zu haben. Die Hypothese mit den Kabeln halte ich im Moment für die wahrscheinlichste. Die Platte läuft jetzt in einem anderen Schacht über andere Kabel auf einen anderen Port auf dem Mainboard. Mal sehen, was passiert.
Uhu U. schrieb: > Eben nicht. Wenn die Log-Patition ro ist, dann wird das nix, weil nichts > ins Log geschrieben werden kann – wie oft habe ich das jetzt hier schon > geschrieben? > Das, was drin steht, kann man sich aber nach dem nächsten Boot ansehen, Entschuldige, aber dass die Daten von ›dmesg‹ nicht von der Platte kommen, wurde hier mehr als fünfmal dargelegt. Entsprechend kann man die Daten auch nach dem nächsten Boot nicht mehr ansehen. Solange solche Basics nicht klar sind und das Grundverständnis fehlt, braucht man wohl auch kein Umkonfigurieren zum Erhalt der relevanten Logeinträge zu erwarten – damit bin ich auch wieder raus. Man kann mir nicht vorwerfen, es nicht versucht zu haben :( Ein Tipp zum Abschied noch: SMART ist nicht das Maß der Dinge, und hat mit dem Dateisystem auch nicht direkt etwas zu tun. Es gibt einige Arten von Fehlern, die Dateisysteme zerschießen können – was zum remount,ro führt –, die aber nie im SMART auftauchen werden.
Jack V. schrieb: > Entschuldige, aber dass die Daten von ›dmesg‹ nicht von der Platte > kommen, wurde hier mehr als fünfmal dargelegt. Sorry, aber wenn man sich nicht einloggen kann, dann geht auch kein dmesg. Das war aber auch gar nicht nötig, denn die Meldungen kamen ja über jede offene Konsole. Nur anhalten oder gar irgend was damit zu machen, ging nicht, aber das war auch nicht weiter wild, denn es wiederholte sich immer dieselbe Sequenz von erfolglosen Schreibversuchen auf den Superblock, weil das Dateisystem ro war. Fazit: Damit, dass die ersten Meldungen nach Auftreten des Problems weg waren, war der Hase gelaufen. > SMART ist nicht das Maß der Dinge, und hat mit dem Dateisystem auch nicht > direkt etwas zu tun. Wenn die Grundlage – das korrekte Adressieren der Sektoren und fehlerfreies Lesen – nicht funktioniert, dann muss man sich über das Dateisystem, das mal auf der Platte war, wohl keine Gedanken mehr machen. Deswegen war ein kompletter Lesetest durchaus ein richtiger Ansatz, um festzustellen, ob die Voraussetzungen für einen fsck überhaupt erfüllt sind. Nachdem SMART keine Fehler fand und danach auch fsck nicht, gehe ich zumindest mal von keinen permanenten Fehlern aus.
Uhu U. schrieb: > Nachdem SMART keine Fehler fand und danach auch fsck nicht, gehe ich > zumindest mal von keinen permanenten Fehlern aus. Aus Felern wirt mann kluck. Man könnte aber vorbeugend ein Log woanders speichern, um den Fehlern einer toten Maschine nachgehen zu können.
oszi40 schrieb: > Man könnte aber vorbeugend ein Log woanders > speichern, um den Fehlern einer toten Maschine nachgehen zu können. Meine Idee: Ändern des Emergencies-Eintrag, dass im Fall, wo nichts mehr geht, die Log-Ausgabe auf einen USB-Stick umgelenkt wird. Statt
1 | # |
2 | # Emergencies are sent to everybody logged in. |
3 | # |
4 | *.emerg :omusrmsg:* |
müsste dann irgendwas in der Art in die Konfigurationsdatei:
1 | *.emerg /media/<user>/<stick-name>/log |
Dann wäre das Logsystem im Normalbetrieb unverändert. Fragt sich nur, ob der Log-Dämon auch mit FAT32 klar kommt, oder ob es da Beschränkungen gibt.
Wie oft hat es denn gescheppert? ;) last -x |grep crash | wc -l --- Gibts ein 'boot fragment' /run/initramfs ? Muss es ja eigentlich wenn fsck vor dem mount der verschluesselten Datei die das eigentliche fs enthaelt laufen soll. Da müßte sich wenn es gelaufen ist das fsck.log befinden, was dann nat. verloren geht.
Uhu U. schrieb: > Fragt sich nur, ob der Log-Dämon auch mit FAT32 klar kommt, oder ob es > da Beschränkungen gibt. Kein Platz auf der boot partition? /boot muss ja nicht dauerhaft sein, solange bis du der Sache wieder traust :)
Ja, eine fsck.log gibts dort mit folgendem Inhalt:
1 | /dev/mapper/mint--19.2--vg-root: clean, 1707425/244080640 files, 421757517/976313344 blocks |
Die stammt von heute. Ich versuche gerade, einen USB-Stick mit ext3 zu formatieren. Das sollte dann im Notfall funktionieren. oszi40 schrieb: > Kommt auf die Dateilänge an. 8 GB sollten locker ausreichen…
So, jetzt habe ich den emerg-Eintrag in /etc/rsyslog.d/50-default.conf so umgebogen, dass die Emergency-Einträge (hoffentlich) auf dem USB-Stick landen.
Uhu U. schrieb: > Na lesen scheinst zu zumindest rudimentär zu können, aber beim > Textverständnis hapert es schwer. Das scheint eher dein Problem zu sein, du bist im Modus READ-ONLY, nachdem du gefragt hast: "Was macht man in so einem Fall?" Deine Wissens- und Verständnislücken sind ja erstmal nicht schlimm, was du nicht weisst kanst du ja noch lernen, aber dazu musst du auch mitmachen, dieses Forum ist kein Nürnberger Trichter! Es kann ja wohl kaum deine Absicht sein den zahlreichen hier helfenden ans Bein pissen zu wollen. > Die, die vernünftige Vorschläge gemacht haben, taten das ziemlich am > Anfang. Mittlerweile läuft die Platte in einem anderen Schacht; ob das > so bleibt, wird sich zeigen. Eines ist sicher: Von alleine wird sich die Platte nicht in den Schacht bewegen, in welchem die Probleme auftraten. Ich verstehe deine Unlogik wirklich nicht. Wenns jetzt (in einem anderen Schacht) für ein paar Tage läuft, was dann? Wirst du dann den vorher Benutzten Schacht "auf Verdacht" mit Bauschaum befüllen, oder willst du warten bis bei der nächsten, zufälligen, Benutzung dieses Schachtes Probleme auftreten? Uhu U. schrieb: > Nochmal ganz ohne Drama: Es handelt sich um einen Fehler, der > jetzt 3 mal aufgetreten ist innerhalb eines Monats Aha, also eine ganze Menge an Logfiles! >> Wenn du das machen... Zitate bitte mit Quellenangabe! > Wenn er denn nochmal auftritt… Das hat er bisher nicht gemacht. Warten auf Godot. > Wäre die Ursache ein defekter Sektor oder ein nicht behebbarer > Lesefehler gewesen, hätte man das den SMART-Daten entnehmen können Auch das. >> Shell zur Verfügung > Einloggen ging leider nicht, weil die Log-Meldungen im Dauerbetrieb über > den Schirm rauschten. Umschalten auf eine andere Konsole half auch > nichts, denn dort war es nicht anders. > (Dass ein Login ohne Schreibzugriffe auf die Systemplatte vonstatten > gehen kann, halte ich im Übrigen für wenig wahrscheinlich.) Das geht, allerdings Tippst du blind solange messages auf dein Terminal einprasseln. Nach dem login (ebenfalls noch blind zu tippen solange rsyslogd reinspammt): hans@wurst:~$ sudo service rsyslog stop oder hans@wurst:~$ sudo systemctl stop rsyslog je nachdem was deinem OS schmeckt...und schon ist ruhe im Karton. > Das, was drin steht, kann man sich aber nach dem nächsten Boot ansehen, > dank Zeitmarken kann man sogar sehen, wo es geknallt hat – dort stehen > besagte NUL-Zeichen und die letzte Meldung davor sagt nichts über > Plattenprobleme. Ich hatte mir ja schon gedacht das du nur die letzte Zeile deines logs (welches log auch immer das war) gelesen hattest, deswegen meine Tipps.....erwartest du dort etwa eine Lastline wie "Das obere Ende am Lila Kabel sorgt für Probleme"? So findest du deinen Problemauslöser (Steckverbindungen am Wechselrahmen, Kabel, Steckverbindung am Board, furtbar gealterte Leitungstreiber [Stichwort i7-Sandy Bridge]) niemals. > rsyslogd im vorliegenden Fall seine Meldungen einfach auf jede geöffnete Konsole "kotzt" Kann man im Vorfeld abstellen, muss man aber nicht. Uhu U. schrieb: > oszi40 schrieb: >> Kommt auf die Dateilänge an. > > 8 GB sollten locker ausreichen… Jetzt hast du korrekterweise den Urheber deines Zitates genannt, gut. Nur ist das Zitat leider völlig aus dem zusammenhang gerissen, deine Frage lautete: "ob der Log-Dämon auch mit FAT32 klar kommt". Die Antwort: Nein, der Log-Dämon interessiert sich nicht für Dateisystemformate, dies ist Aufgabe des Kernels. Und ja, ein aktueller Linuxkernel sollte schon mit FAT32 durchaus klar kommen, allerdings liegen die Limits für Filegrössen unter FAT32 Dateisystembedingt bei 2GB, unabhängig vom Kernel. Sollte für logfiles sehr lange reichen, mithilfe von einem vernünftig konfiguriertem logrotate sogar ewig. Zumindest solange der USB-Speicherstick die Schreiblast überlebt...Für den hiesigen Thread: egal! Nunja, mit deinem "versuche gerade, einen USB-Stick mit ext3 zu formatieren" (solltest du denn Erfolg haben LOL) darf ein einzelnes File dann auch recht gross werden, allerdings hätte ich an deiner Stelle ext4 bevorzugt. Für den hiesigen Thread: egal! Uhu U. schrieb: > Dann kann man sich leider nur noch in Geduld üben, regelmäßig Daten > sichern und beobachten, was die Kiste macht. Das ist es, was derzeit > tue. Was zu tun ist wurde ausführlichst erklärt. Mach es, oder lass es, mir kanns egal sein. Wie auch immer: Lebe lang und in Frieden!
ping schrieb: > Kein Platz auf der boot partition? Davon würde ich in diesem speziellen Fall eher abraten, ein anderes Speichermedium als ausgerechnet diese Platte (wenn man denn überhaupt Logfiles braucht um das Problem statistisch zu erfassen) ist eine Wasserdichte Lösung.
2 Cent schrieb: > Zitate bitte mit Quellenangabe! Ich zitiere immer so, dass beim ersten Zitat aus einem Beitrag der Link darauf steht. Bei weiteren Zitaten aus demselben Beitrag, bin ich so frei, den redundanten Link zu löschen – mein Beitrag soll lesbar bleiben und nicht mit überflüssiger administrativer Information verstopft sein. Wenn im Text eine andere Quelle eingeflossen ist und anschließend wieder aus einer vorherigen Quelle zitiert wird, dann lasse ich wieder genau den ersten Link stehen. Logisch und eigentlich nicht schwer zu verstehen, oder?
Bernd B. schrieb: > Schau Dir mal im BIOS die Pegel der Versorgungsspannungen an. Die > Ursache fast aller Probleme die ich in den letzten Jahren (auf drei > verschiedenen Rechnern) mit Festplatten hatte, lag darin, dass die > Spannungen zu niedrig waren. Hatte ich auch schon erlebt. Alle Exemplare eines Server-Typs entwickelten nach vielen vielen Jahren Betrieb Unterspannung auf 5V, aufgrund von Netzteilalterung. Jene mit Linux drauf zeigten exakt dieses Verhalten: Filesystem r/o, liefen aber ansonsten brav weiter. Wer braucht heute noch 5V? Disks und USB. Der Rest kriegt 3,3V oder 12V. Folglich ist dann auch nur diese I/O betroffen.
2 Cent schrieb: > ping schrieb: >> Kein Platz auf der boot partition? > Davon würde ich in diesem speziellen Fall eher abraten, ein anderes > Speichermedium als ausgerechnet diese Platte (wenn man denn überhaupt > Logfiles braucht um das Problem statistisch zu erfassen) ist eine > Wasserdichte Lösung. Das kann nur ein Fehler sein der nach dem erfolgreichen mount des rootfs aufgetreten ist, nachdem der bootvorgang erfolgreich abgeschlossen wurde. Dieses fs befindet sich in einer verschlüsselten Datei auf einer Partion ohne eigenes fs, wäre das vorher aufgetreten bliebe ggf. das fs auf der bootpartion dirty und würde beim reboot normalerweise unübersehbar in einen fsck laufen, das oder die Ereignisse haben sich nach dem mount des ext4 in "mint--19.2--vg-root" abgespielt sonst wäre das nicht ro gemountet worden es hätte davon nichts mitbekommen. Wo das logging nun endet ist doch egal hauptsache man kann das einfach lesen.
ping schrieb: > Wo das logging nun endet ist doch egal hauptsache man kann das einfach > lesen. Nicht ganz. Wenn die Platte Probleme hat, dann ist hinterher womöglich auch die Bootpartition kaputt. Ich denke, meine Lösung mit dem USB-Stick gibt für den vorliegenden Fall mehr Sicherheit. Bernd B. schrieb: > Schau Dir mal im BIOS die Pegel der Versorgungsspannungen an. Das ist ein guter Tipp, den ich vergessen hatte, weil das Netzteil des Rechners noch ziemlich neu ist. Ich werde es nachholen…
Die Werte des Netzteils könnten kaum besser sein: CPU: 0,864 V 5V: 5,000 V 3,3V: 3,440 V 12 V: 12,000 V Bleiben also die Kontaktprobleme an den Kabeln als wahrscheinliche Ursache.
Beitrag #6098679 wurde von einem Moderator gelöscht.
Uhu U. schrieb: > 2 Cent schrieb: >> Zitate bitte mit Quellenangabe! > > Ich zitiere immer so, dass beim ersten Zitat aus einem Beitrag der > Link darauf steht... Offensichtlich nicht immer, deshalb die Schelte. ping schrieb: > Das kann nur ein Fehler sein der nach dem erfolgreichen mount des rootfs > aufgetreten ist, nachdem der bootvorgang erfolgreich abgeschlossen > wurde. Ein Fehler? Das sehe ich, wie schon geschrieben, anders. Oftmals treten Bitfehler auf Ebene des Satakabels auf ohne schädigende Auswirkungen (von Zeitverzögerungen mal abgesehen) auf das Dateisysten zu haben. > Wo das logging nun endet ist doch egal hauptsache man kann das einfach > lesen. Da gebe ich dir allerdings recht, lesen konnte man (allerdings nur Uhu selbst, nicht jeder) bis jetzt aber auch schon: 2 Cent schrieb: > Uhu U. schrieb: >> Nochmal ganz ohne Drama: Es handelt sich um einen Fehler, der >> jetzt 3 mal aufgetreten ist innerhalb eines Monats > Aha, also eine ganze Menge an Logfiles!
2 Cent schrieb: > Oftmals treten > Bitfehler auf Ebene des Satakabels auf ohne schädigende Auswirkungen > (von Zeitverzögerungen mal abgesehen) auf das Dateisysten zu haben. Das ist wohl die naheliegendste Interpretation: * Platte physikalisch gesund * Dateisystem unbeschädigt Bis jetz ist – in einem anderen Schacht – kein weiteres Problem aufgetreten. Mal sehen, ob das so bleibt…
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.