Ich benutze ab und zu mal eine naive Realisierung eines
FixedPoint-Datentyps in C++.
Das war aber eigentlich immer nur für unkritische Dinge.
Jetzt habe ich trotzdem mal einen Vergleich mit der C-Erweiterung _Accum
gemacht
(die es leider für IA32/64-Systeme nicht gibt).
Test in C (bm00.c):
1
#include<stdfix.h>
2
#include<stdint.h>
3
#include<stdbool.h>
4
5
volatileint16_tr1;
6
volatileint16_tr2;
7
8
typedefsignedshort_Accumfp_t;
9
10
intmain(){
11
fp_tsum=0;
12
while(true){
13
constfp_ta=r1;
14
constfp_tb=r1;
15
sum+=a*b;
16
r2=sum;
17
// r2 = sum / 2;
18
}
19
}
Test in C++ (bm01.cc):
1
#include<cstdint>
2
#include<cstddef>
3
#include<etl/fixedpoint.h>
4
5
usingt=int16_t;
6
usingfp_t=etl::FixedPoint<t,8>;
7
8
volatiletr1;
9
volatiletr2;
10
11
intmain(){
12
fp_tsum;
13
while(true){
14
constautoa=fp_t::fromRaw(r1);
15
constautob=fp_t::fromRaw(r1);
16
sum+=a*b;
17
// r2 = (sum / 2).integer();
18
r2=sum.integer();
19
}
20
}
Spaßeshalber mal auf einem attiny1614 ergibt:
1
$ avr-size *elf
2
text data bss dec hex filename
3
330 0 4 334 14e bm00.elf
4
318 0 4 322 142 bm01.elf
5
6
$ avr-nm -CS --size-sort *elf
7
bm00.elf:
8
00803802 00000002 B r1
9
00803800 00000002 B r2
10
00000138 00000004 T __usmulhisi3
11
00000100 0000000a T __muluha3_round
12
0000013c 0000000a T __usmulhisi3_tail
13
000000f2 0000000e T __mulha3
14
00000088 00000010 T __do_clear_bss
15
0000010a 00000010 T __mulhisi3
16
0000011a 0000001e T __umulhisi3
17
000000a4 0000004e T main
18
19
bm01.elf:
20
00803802 00000002 B r1
21
00803800 00000002 B r2
22
0000012c 00000004 T __usmulhisi3
23
00000130 0000000a T __usmulhisi3_tail
24
00000088 00000010 T __do_clear_bss
25
000000fe 00000010 T __mulhisi3
26
0000010e 0000001e T __umulhisi3
27
000000a4 0000005a T main
Die Assembler-Texte habe ich angehängt (bm00.asm, bm01.asm).
Ich kann nicht wirklich glauben, dass die C++-Version kürzer
(effizienter???) ist als die C-Version.
Also: was habe ich in dieser total naiven Implementierung falsch
gemacht?
Zur besseren Analyse hier die beiden Operatoren += und * für FixedPoint:
FixedPoint::Op*
Vergleich einfach mal den Code!
stdfix.h rundet korrekt (wie von ISO/IEC DTR 18037 gefordert), und das
braucht etwas mehr Code.
Außerdem ist das C++ main größer weil bestimmte Sachen bei jedem Aufruf
angepasst werden müssen, was stxfix.h schon selbst macht.
Johann L. schrieb:> Vergleich einfach mal den Code!>> stdfix.h rundet korrekt (wie von ISO/IEC DTR 18037 gefordert), und das> braucht etwas mehr Code.
Das Runden ist doch in beiden Fällen enthalten, so wie ich das am Code
sehe.
Gibt es denn eine Möglichkeit, auch fixed-point in g++ als Extension zu
aktivieren?
Ich habe es mal mit enable-fixed-point beim configure versucht, aber das
wirkt sich eben nur auf die Bibliotheken aus.
Ups, was passiert denn nun? Ein ganzzahlige Division lässt den C-Code
explodieren:
C mit ganzzahliger Division (bm00.c):
1
intmain(){
2
fp_tsum=0;
3
while(true){
4
constfp_ta=r1;
5
constfp_tb=r1;
6
sum+=a*b;
7
// r2 = sum;
8
r2=sum/2;
9
}
10
}
C++ mit ganzzahliger Division (bm01.cc):
1
intmain(){
2
fp_tsum;
3
while(true){
4
constautoa=fp_t::fromRaw(r1);
5
constautob=fp_t::fromRaw(r1);
6
sum+=a*b;
7
r2=(sum/2).integer();
8
// r2 = sum.integer();
9
}
10
}
[pre]
$ avr-size *elf
text data bss dec hex filename
520 0 4 524 20c bm00.elf
320 0 4 324 144 bm01.elf
$ avr-nm -CS --size-sort *elf
bm00.elf:
00803802 00000002 B r1
00803800 00000002 B r2
000001f6 00000004 T __usmulhisi3
0000012e 0000000a T __muluha3_round
000001fa 0000000a T __usmulhisi3_tail
00000120 0000000e T __mulha3
00000088 00000010 T __do_clear_bss
000001c8 00000010 T __mulhisi3
000001b8 00000010 T __negsi2
000001d8 0000001e T __umulhisi3
00000138 0000003c T __divsa3
00000174 00000044 T __udivusa3
000000a4 0000007c T main
bm01.elf:
00803802 00000002 B r1
00803800 00000002 B r2
0000012e 00000004 T __usmulhisi3
00000132 0000000a T __usmulhisi3_tail
00000088 00000010 T __do_clear_bss
00000100 00000010 T __mulhisi3
00000110 0000001e T __umulhisi3
000000a4 0000005c T main
[pre]
Das ist doch nicht neu. wenn der Compiler die Templates übersetzt, dann
hat er alle Information und macht daraus den (seiner Ansicht nach)
bestmöglichen Code. Werden statt dessen RT-Funktionen benutzt, dann hat
man Call-Overhead, die RT macht mehr als eigentlich gebraucht, usw.
Mit der Größe des Programms verschiebt sich das Richtung RT, falls der
Call-Overhead nicht den gerufenen Funktionsumfang überwiegt. Wenn man
nur einen Fixed-Typ (z.B. hier 8.8 ) benutzt, dann hat die Maschine kaum
mehr zu tun als bei Integer. Besonders wenn der Dezimalpunkt auf
Bytegrenzen liegt.
Und ist nicht die Antwort, wenn man nach den C-Erweiterungen Fixed,
Namen Memspaces, ... fragt, immer: das kann man in C++ selbst schreiben
und braucht keine spezielle Sprachunterstützung. Stimmt fast immer, also
kein Wunder, daß es geht.
BtW, ähnliches wurde auch schon beim Sortieren entdeckt qsort() vs.
std::sort(). Einmal generisch und in C++ mit kompletter Typisierung der
Daten.
Wilhelm M. schrieb:> Also: was mache ich falsch?
So ziemlich alles :)
Der C++-Code unterscheidet sich insbesondere in den folgenden beiden
Punkten vom C-Code:
1. signed short _Accum hat beim AVR-GCC 7 Nachkomma-Bits,
etl::FixedPoint<t, 8> hingegen 8. Damit ist natürlich viel leichter
zu rechnen. Ändere das in etl::FixedPoint<t, 7>.
2. Im C-Code ist die Konvertierung von int16_t nach _Accum
werterhaltend. Aus r1=42 wird also a=b=42.0. Dazu müssen die
16-Bit-Werte um 7 Bit nach links geschoben werden, was für den AVR
jeweils 5 Instruktionen erfordert. Die fromRaw-Funktion im C++-Code
hingegen geht offensichtlich davon aus, dass der Wert in r1 bereits
im Fixes-Point-Format vorliegt, so dass die Konvertierung entfällt.
Ersetze also fromRaw durch fromInteger (oder wie auch immer die
entsprechende Funktion bei dir heißt).
Allein schon Punkt 2 vergrößert den C++-Code von 318 auf 338 Bytes,
womit er 8 Bytes größer als der C-Code wird. Punkt 1 fällt vermutlich
noch stärker ins Gewicht. Das kann zwar in dem einfachen Beispiel durch
Inlining teilweise kompensiert werden, was sich aber bei mehrfacher
Nutzung der Fixed-Point-Operationen erst recht negativ auswirkt.
Probier es einfach mal aus und berichte über die Ergebnisse (benötigte
Bytes und Taktzyklen).
Wilhelm M. schrieb:> Ups, was passiert denn nun? Ein ganzzahlige Division lässt den C-Code> explodieren:
Ja, der GCC scheint die Fix-Point-Division durch eine Zweierpotenz
nicht zu optimieren. Schade.
Du kannst das von Hand optimieren, indem du
1
r2=sum/2;// 32-Bit-Fix-Division
durch
1
r2=sum/2hk;// 16-Bit-Fix-Divsion
oder besser durch
1
r2=sum*0.5hk;// 16-Bit-Fix-Multiplikation
oder noch besser durch
1
r2=hkbits(bitshk(sum)/2);// 16-Bit-Int-Division per Shift
ersetzt. Alle vier Varienten liefern dasselbe Ergebnis, auch bei
negativen Werten von sum.
Schöner wäre es natürlich, wenn der Compiler diese Optimierungen
selbstständig durchführen könnte.
Ok, das war klar, dass ich das naheliegendste nicht beachtet habe.
Dann habe ich das mal kurz umgestellt:
1) auf Qs8.7
2) werterhaltende Wandlung in beide Richtungen
und habe die Testprogramme etwas auf diese Situation angepasst, damit es
sinnvoll ist:
C (bm00.c):
Wilhelm M. schrieb:> Mir stellt sich die Frage, warum ich dann die (umständlichere) Qs8.7> nehmen soll. Mit Qs7.8 ergibt sich dann (die C-Version kann man ja nicht> ändern):
Ich bin mir nicht so ganz sicher ob ich deine Frage richtig verstehe,
aber ist die offensichtliche Antwort nicht "Weil es andere Formate mit
anderem Wertebereich und Auflösung sind."?
Was hindert euch alle daran einfach die eingebauten 16- und 32-Bit
Datentypen zu nehmen beim Rechnen mit Festkomma? Man muss doch nur den
Überblick darüber behalten um wieviel Bits geshiftet wurde (wieviele
Nachkommabits es hat) und dann kann man ganz normal mit Integern rechnen
ohne sich noch irgendwelche libs reinzuziehen?
Bernd K. schrieb:> Was hindert euch alle daran einfach die eingebauten 16- und 32-Bit> Datentypen zu nehmen beim Rechnen mit Festkomma?
Wahrscheinlich genau der gleiche Grund, warum wir nicht alles in
Assembler scheiben?
Bernd K. schrieb:> Man muss doch nur den> Überblick darüber behalten um wieviel Bits geshiftet wurde (wieviele> Nachkommabits es hat)
Das ist jetzt ein Witz, gell?
Bernd K. schrieb:> und dann kann man ganz normal mit Integern rechnen> ohne sich noch irgendwelche libs reinzuziehen?
S.o., oder sollte man Deiner Meinung nach etwa auch für sin(x) jedesmal
eine for-Schleife mit der Potenzreihe oder cordic hinschreiben?
(BTW: es ist Integerarithmetik und den Überblick hat der Compiler).
Wilhelm M. schrieb:> Das ist jetzt ein Witz, gell?
nein, das ist ganz einfach. Die Wertebereiche kann man mit etwas
Erfahrung sogar im Kopf überschlagen und die Rechnungen kann man einfach
so hinschreiben. Mit normalen Integern. Das haben Generationen von
Programmierern schon so gemacht ohne mit der Wimper zu zucken bis zum
heutigen Tag!
> BTW: es ist Integerarithmetik und den Überblick hat der Compiler
Ja offensichtlich wohl doch nicht wenn er plötzlich den "integer" nicht
mal mehr durch zwei dividieren kann.
> oder sollte man Deiner Meinung nach etwa auch für sin(x)
Wenn ich nen Sinus brauche nehm ich ne Lookup-Tabelle.
Bernd K. schrieb:> Ja offensichtlich wohl doch nicht wenn er plötzlich den "integer" nicht> mal mehr durch zwei dividieren kann.
Wo siehst Du das denn?
Wilhelm M. schrieb:> Bernd K. schrieb:>> Ja offensichtlich wohl doch nicht wenn er plötzlich den "integer" nicht>> mal mehr durch zwei dividieren kann.>> Wo siehst Du das denn?
Scroll hoch bis zu dem Beispiel wo er eine Divisions-Library reinzieht
beim Ausdruck sum/2.
Wenn der Compiler wüsste daß das ein ganz normaler Integer sein soll
wäre das nicht passiert. Weiß der Geier als welche verbloateten
Strukturen diese Festkommazahlen da in dieser Lib gespeichert werden,
anscheinend haben die es wirklich geschafft den zugrunde liegenden
integer so gut vor dem Compiler zu verstecken daß selbst der es nicht
mehr mitbekommt. das führt den eigentlichen Zweck der Festkommarechnung
vollkommen ad absurdum!
Wilhelm M. schrieb:> Schau es Dir an, und Du wirst feststellen, dass da ein klein wenig> mehr gemacht wird .
Und auf genau das "klein wenig mehr" kann man gut verzichten, es ist
nämlich die eigentliche Motivation hinter Festkomma daß man das mit
stinknormalen Integern rechnen kann! Also tut man es auch! Sonst könnte
man auch gleich mit Fließkomma rechnen und ne CPU mit
Fließkomma-Koprozessor nehmen.
Bernd K. schrieb:> Also tut man es auch!
Du lebst offensichtlich in dieser Welt, in der
1) alles ein int ist, und
2) falls 1) nicht zurifft, dann eben ein String.
Jedenfalls macht mein template FixedPoint genau das, was Du forderst,
nämlich Integerarithmetik. Und _Accum wohl auch, wie auch _Fixed und
_Sat (was Du wohl auch jedesmal zu Fuß machst).
Wilhelm M. schrieb:> Ließ Mal die Überschrift
Der Fehler trat im C-Beispiel auf. Da gehört schon was dazu den
C-Compiler so an der Nase herumzuführen daß er eine banale
Integerdivision durch 2 nicht mehr als solche erkennt, wie haben die es
überhaupt geschafft in C den Divisionsoperator zu überladen? So ein
Hokuspokus kann mir getrost gestohlen bleiben wenn ich nichts anderes
will als ein bisschen mit Integern zu rechnen. da nehm ich normale
Integerdatentypen, genau dafür wurden die nämlich erfunden!
Bernd K. schrieb:> Wilhelm M. schrieb:>> Bernd K. schrieb:>>> Ja offensichtlich wohl doch nicht wenn er plötzlich den "integer" nicht>>> mal mehr durch zwei dividieren kann.>>>> Wo siehst Du das denn?>> Scroll hoch bis zu dem Beispiel wo er eine Divisions-Library reinzieht> beim Ausdruck sum/2.
Ich kann nirgends eine Stelle finden, wo behauptet wird, der Compiler
könne nicht dividieren. Lediglich, dass eine Optimierung nicht
funktioniert. Das ist aber ein Problem des Compilers.
Im Übrigen ist das keine Bibliothek.
> Wenn der Compiler wüsste daß das ein ganz normaler Integer sein soll> wäre das nicht passiert. Weiß der Geier als welche verbloateten> Strukturen diese Festkommazahlen da in dieser Lib gespeichert werden,> anscheinend haben die es wirklich geschafft den zugrunde liegenden> integer so gut vor dem Compiler zu verstecken daß selbst der es nicht> mehr mitbekommt.
Es handelt sich um eine Funktionalität, die im Compiler eingebaut ist.
Da wird's schwierig, die vor ihm selbst zu "verstecken".
Bernd K. schrieb:> Wilhelm M. schrieb:>> Ließ Mal die Überschrift>> Der Fehler trat im C-Beispiel auf. Da gehört schon was dazu den> C-Compiler so an der Nase herumzuführen daß er eine banale> Integerdivision durch 2 nicht mehr als solche erkennt, wie haben die es> überhaupt geschafft in C den Divisionsoperator zu überladen?
Genauso, wie "die" das bei int und float auch gemacht haben.
> So ein Hokuspokus kann mir getrost gestohlen bleiben wenn ich nichts> anderes will als ein bisschen mit Integern zu rechnen. da nehm ich> normale Integerdatentypen, genau dafür wurden die nämlich erfunden!
Es geht aber nicht um Integer-Rechnung, sondern darum, mit
Fixkommazahlen zu rechnen, und das ohne dass man alles, was über
Addition und Subtraktion hinaus geht, zu Fuß nachbilden muss.
Bernd K. schrieb:> Rolf M. schrieb:>> Es geht aber nicht um Integer-Rechnung, sondern darum, mit>> Fixkommazahlen zu rechnen>> Das IST Integerrechnung!
Nein. Man kann die Festkommaarithmetik zwar mittels Integer-Arithmetik
realisieren, deswegen ist es aber noch lange nicht dassselbe. Auch
Gleitkommaarithmetik wird softwaremäßig auf Integer-Operationen
abgebildet. Trotzdem ist auch Gleitkommaarithmetik etwas anderes als
Integer-Arithmetik.
Yalu X. schrieb:> Nein. Man kann die Festkommaarithmetik zwar mittels Integer-Arithmetik> realisieren, deswegen ist es aber noch lange nicht dassselbe.
Es ist exakt das selbe! Man skaliert die Werte einfach nur anders damit
man genug Auflösung behält und trotzdem bequem in ganz normalen Integern
rechnen kann. Die Abstraktionen vernebeln anscheinend den Blick aufs
Wesentliche.
Bernd K. schrieb:> Yalu X. schrieb:>> Nein. Man kann die Festkommaarithmetik zwar mittels Integer-Arithmetik>> realisieren, deswegen ist es aber noch lange nicht dassselbe.>> Es ist exakt das selbe! Man skaliert die Werte einfach nur anders damit> man genug Auflösung behält und trotzdem bequem in ganz normalen Integern> rechnen kann. Die Abstraktionen vernebeln anscheinend den Blick aufs> Wesentliche.
Es gibt eben mehr als nur "Strich"-Operationen.
Yalu X. schrieb:> Nein. Man kann die Festkommaarithmetik zwar mittels Integer-Arithmetik> realisieren, deswegen ist es aber noch lange nicht dassselbe.
Eigentlich doch. Statt mit 1,3m rechne ich mit 130cm oder auch 1300mm.
Das Komma kann ich bei fixed point immer vermeiden, wenn ich eine
kleinere Einheit wähle.
MfG Klaus
Carl D. schrieb:> Es gibt eben mehr als nur "Strich"-Operationen.
So ist es.
Beschränkt man sich nur auf Addition und Subtraktion, hat Bernd
natürlich recht.
Bei Multiplikation und Division kommen aber noch die Skalierung und die
Rundung des Ergebnisses hinzu. Wenn die Rechenzeit wichtig ist, sollte
man auf die bestehenden Routinen für Integer-Multiplikation und
-Division komplett verzichten und welche schreiben, die auf die
Wertebereiche und die Anzahl der Nachkommastellen der verwendeten
Festkommadatentypen zugeschnitten sind.
Yalu X. schrieb:> Bei Multiplikation und Division kommen aber noch die Skalierung und die> Rundung des Ergebnisses hinzu.
Vielleicht will ich aber gar nicht daß er bei jeder Multiplikation oder
jeder Division stur jedesmal hinterher gleich automatisch shiftet,
vielleicht will ich ein paar Rechenoperationen am Stück hintereinander
ausführen und dabei gar nicht shiften müssen weil ich aufgrund
vorheriger Planung(!) genau beweisen kann daß ich den Wertebereich
meiner Integer dabei niemals verlassen werde und als Sahnehäubchen
hinterher vielleicht sogar "zufällig" gleich die gewünschte Skalierung
des Ergebnisses von selbst richtig rauskommt weil ich "zufällig" die
Koeffizienten schon genau dafür geignet skaliert hatte! Weil ich den
Rechenweg und die Wertebereiche in jedem einzelnen Schritt vorher bis
zum letzten Bit genau geplant habe!
Weil ich mich einmal einen Tag lang hinsetze und den Rechenweg Schritt
für Schritt genau plane anstatt blind in nem Tool auf "Generate Bloat"
zu klicken bekomme ich hinterher in 100000facher Ausführung die halben
Kosten oder den halben Stromverbrauch oder die doppelte
Schaltgeschwindigkeit!
Üblicherweise macht man Festkomma meist wenns eh schon zeitkritisch ist,
da will man nicht noch unnötige Skalierungszwischenschritte automatisch
nach jeder einzelnen Operation eingebaut haben wenn man nach
sorgfältiger Planung vorher schon genau weiß daß mans genausogut mit
nem int32 komplett in einem Rutsch durchrechnen könnte oder nur an genau
einer einzigen Stelle mal 8 Bit runterschiften muß und sonst nirgends
mehr!
Und schon gar nicht will ich daß er beim Skalieren jedesmal umständlich
eine Divisionsroutine aufrufen muss wie im obigen Beispiel wenn die
Zielarchitektur eigentlich auch einen arithmetischen Rechtsshift bietet
den der Compiler auch benutzt hätte wenn man normal mit Integern
gerechnet hätte!
Wozu ist denn die Integerarithmetik denn überhaupt da wenn nicht genau
zu dem Zweck sie sinnvoll einzusetzen?!
Bernd K. schrieb:> Wozu ist denn die Integerarithmetik denn überhaupt da wenn nicht genau> zu dem Zweck sie sinnvoll einzusetzen?!Bernd K. schrieb:> Weil ich mich einmal einen Tag lang hinsetze und den Rechenweg Schritt> für Schritt genau plane anstatt blind in nem Tool auf "Generate Bloat"> zu klicken bekomme ich hinterher in 100000facher Ausführung die halben> Kosten oder den halben Stromverbrauch oder die doppelte> Schaltgeschwindigkeit!
Der zweite Teil ist arg übertrieben, aber ok. Beim ersten Teil vergisst
du zu erwähnen, dass es auch andere warten und erweitern müssen. Sollen
die sich auch jedes mal nen ganzen Tag hinsetzen und jeden Rechenschritt
nachvollziehen und anpassen, nur weil an einer Stelle jetzt mit 3 statt
2 multipliziert werden muss?
Klaus schrieb:> Eigentlich doch. Statt mit 1,3m rechne ich mit 130cm oder auch 1300mm.
Das mache ich typischerweise so, dass ich Typen für physikalische Größen
verwende. Also Basistyp kann man dann je nach Gusto Ganzzahl-,
Festkomma- oder Gleitkomma-Typen nehmen. Die jeweilige Skalierung und
Größenart wird als NTTP/Typ im template berücksichtigt. Damit hat man
ein komplettes Einheitensystem. Eine Ent-/Um-Skalierung der Werte findet
dann nur ein einziges Mal statt.
@Bernd K.:
Natürlich zwingt dich keiner, die vom Compiler bereitgestellte
Festkommaarithmetik zu nutzen. In einfachen Fällen (hauptsächlich
Additionen und Subtraktionen, nur wenige Multiplikationen) braucht man
sie auch nicht unbedingt, da hast du schon recht.
Aber wie würdest du folgenden (immer noch recht einfachen) Code mit
reiner Integer-Arithmetik auf einem 8-Bit-Prozessor wie dem AVR
implementieren?
1
#include<stdfix.h>
2
3
volatileshortaccumf1,f2,f3,f4,p;
4
5
intmain(void){
6
p=f1*f2*f3*f4;
7
}
Es wird das Produkt aus vier vorzeichenbehafteten Zahlen berechnet. Die
Operanden und das Ergebnis werden im Q8.7-Format (16 Bit mit 7 binären
Nachkommastellen) dargestellt. Die Werte der vier Faktoren seien so
beschaffen, dass das Ergebnis im Intervall [-256, +256) liegt und damit
ein Überlauf ausgeschlossen ist.
Genauso wie die Gleitkommaarithmetik bietet die Festkommaarithmetik für
einige Anwendungsfälle Vorteile, für viele andere nicht. Sie komplett
abzulehnen, nur weil sie für viele Anwendungen nicht benötigt wird, ist
ein wenig engstirnig.
Bernd K. schrieb:> Vielleicht will ich aber gar nicht daß er bei jeder Multiplikation oder> jeder Division stur jedesmal hinterher gleich automatisch shiftet,> vielleicht will ich ein paar Rechenoperationen am Stück hintereinander> ausführen und dabei gar nicht shiften müssen weil ich aufgrund> vorheriger Planung(!) genau beweisen kann daß ich den Wertebereich> meiner Integer dabei niemals verlassen werde und als Sahnehäubchen> hinterher vielleicht sogar "zufällig" gleich die gewünschte Skalierung> des Ergebnisses von selbst richtig rauskommt weil ich "zufällig" die> Koeffizienten schon genau dafür geignet skaliert hatte!
Du setzt voraus, dass du
(a) das Gesamtsystem vollständig überblicken kannst;
(b) deine vorherige Planung perfekt ist;
(c) deine Implementation perfekt ist;
(d) sich die Anforderungen nicht ändern.
Dann kannst du das so machen und dann funktioniert das auch.
Inwieweit alle diese Annahmen auf reale, etwas größere Projekte mit
mehreren Personen auch zutreffen, kannst du ja kurz selbst überlegen.
Deine Argumentation ist im Prinzip identisch zu "ich will Assembler weil
Hochsprachen sind bäh".
S. R. schrieb:> Du setzt voraus, dass du> (a) das Gesamtsystem vollständig überblicken kannst;> (b) deine vorherige Planung perfekt ist;> (c) deine Implementation perfekt ist;> (d) sich die Anforderungen nicht ändern.
Etwas Vorausplanung ist bei der Verwendung von Festkommaarithmetik wegen
des eingeschränkten Wertebereichs generell erforderlich, um Overflows zu
vermeiden. Der Vorteil fertiger Festkommaarithmetiken liegt vor allem
darin, dass man sich nicht explizit um die Skalierung und das Runden
kümmern muss. Dass diese Dinge automatisch in Hintergrund geschehen,
verbessert zudem die Lesbarkeit des Quellcodes, weil man statt
schreiben kann.
—————————————
¹) Für vorzeichenbehaftete Faktoren sind für das Runden zusätzlich noch
Fallunterscheidungen erforderlich, so dass die Berechnung nicht mehr
in einem einzelnen Ausdruck erfolgen kann.
Yalu X. schrieb:> das Runden
Das Runden kann man sich schenken wenn man 1 Bit mehr Auflösung
spendiert als man braucht. Wenn man mit 32 Bit Integern rechnet hat man
fast immer noch ausreichend Luft nach oben um Skalierungen zu finden mit
denen man mehr als ausreichend zurechtkommt.
Und ja: natürlich kenne ich die Anwendung die ich entwickle in- und
auswendig, ich weiß mit welchen Wertebereichen ich es überhaupt maximal
zu tun bekommen kann (zum Beispiel weiß ich vorher schon wieviel Bit
mein ADC hat, mein DAC, mein PWM-Register, etc. und ich habs bis jetzt
immer ohne große Verrenkungen geschafft nach oben stets ein oder zwei
Bits vom Überlauf entfernt zu bleiben und dennoch unten noch massenhaft
überflüssige Nachkommabits zu haben die ich am Schluss (oder mehrmals
zwischendrin) getrost unter den Tisch fallen lassen kann ohne mir über
korrektes Runden Gedanken machen zu müssen. Und ja: Man muß es im
Zweifelsfall vorher mal zu Fuß durchrechnen um zu sehen mit welchen
Werten man es überall zu tun bekommen kann.
Wenn man das ein paarmal gemacht hat bekommt man schon einen Blick
dafür, Festkomma ist schließlich keine Raketenwissenschaft, man kann
sich das schon ganz gut veranschaulichen, verstehen und nachvollziehen,
manch einer benutzt sogar intuitiv Festkomma ohne das überhaupt so zu
nennen, einfach weil es so naheliegend ist. Wie zum Beispiel der Kollege
oben der einfach in Millimetern rechnet statt in Metern (obwohl
Zehnerpotenzen oftmals weniger gut geeignet sind als Zweierpotenzen).
Ein Buchhalter käme vielleicht auf die Idee einfach in Cent statt Euro
zu rechnen und schon hat er Integer, auch das ist Festkomma.
Und ich finde es einfacher nachzuvollziehen wenn man die
Skalierungsoperationen an den notwendigen Stellen explizit hinschreibt
und sich die daraus resultierenden Integerwerte mit denen man rechnet
direkt als normale Integers (und nicht als Kommazahlen!) im Kopf
vorstellen und direkt sehen kann.
Bernd K. schrieb:> Das haben Generationen von> Programmierern schon so gemacht ohne mit der Wimper zu zucken bis zum> heutigen Tag!
es hat seinen Grund, warum floating point erfunden wurde.
schon ein einfaches Kalmanfilter bereitet dir mit integer arithmetik
ernsthafte Probleme, was die Dynamik der Werte angeht. Willst du das in
fixed point rechnen, brauchst du ziemlich große Ints.
Und die Fehlerwahrscheinlichkeit steigt enorm.
Analog Devices hat eine App-Note in denen sie eine schnelle floating
point implementierung voschlagen:
https://www.analog.com/media/en/technical-documentation/application-notes/EE.185.Rev.4.08.07.pdf
Basiert im Grunde nur darauf, Mantisse und Exponent in basisdatentypen
zu speichern, damit die Bitfummelei entfällt.
Bernd K. schrieb:> Das Runden kann man sich schenken wenn man 1 Bit mehr Auflösung> spendiert als man braucht.
Auch hier: Für einfache Berechnung ist das richtig. Werden aber mehrere
Rechenoperationen hintereinander ausgeführt, akkumulieren sich die
Einzelfehler. Ohne symmetrisches Runden (was einem Abrunden gleichkommt)
geschieht dies bei jeder Einzeloperation in die gleiche Richtung, mit
symmetrischem Runden gleichen sich die Fehler teilweise aus.
Der mittlere Fehler der Einzeloperationen ist ohne Runden die Hälfte der
Auflösung des verwendeten Zahlenformats. Mit symmetrischem Runden ist
der mittlere Fehler 0.
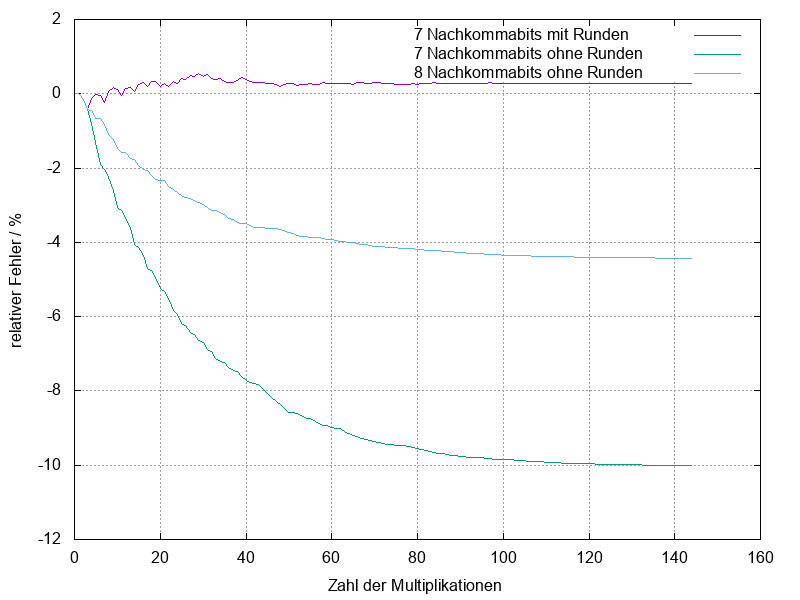
Sehr deutlich wird dies bei einem Produkt aus vielen Faktoren. Im
angehängten Beispiel habe ich die Potenz a**i für a=1+5/128=1,0000101₂
und i=0..144 durch schrittweise Multiplikation mit a berechnet und den
relativen Fehler zum exakten Wert in Abhängigkeit von i dargestellt.
Bei 7 Nachkommastellen wächst ohne Runden der Fehler auf 10%. Eine
zusätzliche Nachkommastelle reduziert den maximalen Fehler auf 4,4%,
symmetrisches Runden sogar auf 0,5%.
Eine Berechnung mit mehr als 100 Multiplikationen ist natürlich extrem,
aber man kann sehen, dass die drei Kurven schon ab vier Multiplikationen
deutlich auseinanderlaufen.
Wie wichtig korrektes Runden bei längeren Berechnungen ist, zeigt auch
die Norm IEEE 754, in der die Rundungsverfahren haarklein spezifiziert
sind.