Ich spiele E-Gitarre und habe eine Reihe der sogenannten Bodentreter, von denen immer mehr auf DSP-Basis, also in Software arbeiten. Ich würde mir gerne selber einiges bauen, habe auch schon Plattformen im Auge. Was mir aber ein wenig fehlt, sind die Kenntnisse, wie man Verzerrer baut, also mathematisch formuliert, dass sie klingen wie klassische E-Gitarre. Was ich gerne hätte, wären solche Klänge wie bei Carlos Santana, oder den opening Sound von Smoke on the Water. Kennt jemand Bücher, Literatur oder Links zu der genauen Schaltungstechnik dahinter?
Open Source Software Effektgeräte: Folgendes läuft meines Wissens gut auf einem RasPi https://guitarix.org Hier ein Video mit "Santana-ähnlichem" Effekt: https://www.youtube.com/watch?v=KEVs_P0Rglo&list=PLeRYlL4iVEr5BgF6-Lll6Baq-k5pgn17b&index=3 Oder ein Hardware-Effekt Gerät mit Guitarix als Basis: https://www.youtube.com/watch?v=TTiUe1wKj1M Oder ein Effektgerät mit PureData auch auf einem RsPi: https://www.youtube.com/watch?v=bLcW70tcBX8 Oder wolltest du Effektgeräte in Hardware selber bauen? Gerhard
Ich möchte schon eine eigene Hardware haben und die Effekte möglichst alle beisammen zum Kombinieren, aber vor allem um Eigenes zu kreieren. Dazu brauche ich die mathematischen Vorschriften / eine Schaltung der man das entnehmen kann. Viele ältere Sachen arbeiten noch in Analogtechnik mit OPs, Dioden und Allemmöglichen.
Andreas F. schrieb: > Was mir aber ein wenig fehlt, sind die Kenntnisse, wie man Verzerrer > baut, also mathematisch formuliert, dass sie klingen wie klassische > E-Gitarre. Die Setups der Musiker sind komplexer als ein simples Vout=f(Vin). Andreas F. schrieb: > möchte schon eine eigene Hardware haben und die Effekte möglichst alle > beisammen zum Kombinieren Aber erforscht, die DSP Effektgeräte die viele Setups, darunter die von dir genannten, kombinieren gibt es fertig. Leider hab ich vergessen wie die Kiste heisst. Heute gibt es aber viele ähnliche, billiger.
Auch auf die Gefahr hin als Spielverderber zu gelten - meine 2cents: Gitarrenequipement wird gerne überbewertet, besonders von Anfängern. Das selbst bauen von Equipment ist ein Nebenschauplatz, in derselben Zeit Gitarre üben bringt einen eher ans Ziel. Schreibt einer, der sein ganzes Leben über selbstgebaute Gitarrenamps gespielt hat und heute bei diesem Thema gähnen muß.
Da gab es mal zwei Bücher im Militärverlag der DDR. 1. Schulze/Engel "Moderne Musikelektronik" 2. Engel "Musikelektronik" Das zweite Buch habe ich selbst. Google mal nach diesen Büchern, die kann man noch antiquarisch erwerben - Preis liegt je nach Angebot zw. 30 - 40€. Ansonsten gab es immer mal wieder Beiträge zum Thema im Funkamateur und im Elekronischen Jahrbuch (Militärverlag). Andreas F. schrieb: > Was > mir aber ein wenig fehlt, sind die Kenntnisse, wie man Verzerrer baut, > also mathematisch formuliert, dass sie klingen wie klassische E-Gitarre. Über die mathematischen Grundlagen dieser Geräte hat man sich früher eher wenig Gedanken gemacht. Verzerrer für Gitarren waren in aller Regel einfache Vorverstärker die übersteuert wurden. Zusätzlichen waren dann oftmals einfache Klangformungsstufen eingebaut.
Hau einfach einen Dirac rein und schau was hinten raus kommt, dann kannst du es nachbauen
>Hau einfach einen Dirac rein und schau was hinten raus kommt, dann >kannst du es nachbauen Tatsächlich? Meinst Du, Gitarren und Verstärker sind LTI-Systeme?
Ein richtig geiles Teil wäre auch der Kemper-Amp. Weiss aber nicht, wie weit man da selber eingreifen kann. Nach meinem Wissensstand ist da noch ein guter alter 56k DSP drin. Mit dem Blackfin BF533 hab ich mal auf einem EZkit ein paar Effekte portiert, ging aber nicht über Flanger/Chorus hinaus. Da gibt's aber ne Menge Code aus dem 56k-Pool. Gab da auch mal irgend ein Projekt Rainbow o.ä. auf der Basis, das ist aber vermutlich in der Versenkung verschwunden.
MaWin schrieb: > Die Setups der Musiker sind komplexer als ein simples Vout=f(Vin). Das ist mir durchaus bewusst, aber alles, was irgendwie verbaut wird, muss sich ja auch nachbilden lassen und die DSP-Bodentreter arbeiten letztlich nur mit Software. Fitzebutze schrieb: > Ein richtig geiles Teil wäre auch der Kemper-Amp. > Weiss aber nicht, wie weit man da selber eingreifen kann. Vermutlich nicht, oder man muss das gesamte Gerät hacken. Muss aber nicht, die Algorithmen reichen.
Moin, Es gibt ein Buch über das Thema auf Amazon. Einfach mal suchen nach Effektpedale selbst gebaut. Da geht's auch um Grundlagen der Elektronik und ums Experimentieren und wie ein overdrive und so gebaut wird...
Andreas F. schrieb: > Kennt jemand Bücher, Literatur oder Links zu der genauen > Schaltungstechnik dahinter? Diese Arbeit könnte weiterhelfen: https://ccrma.stanford.edu/~dtyeh/papers/DavidYehThesissinglesided.pdf (T: DIGITAL IMPLEMENTATION OF MUSICAL DISTORTION CIRCUITS BY ANALYSIS AND SIMULATION )
"Folgende drei Effektpedal-Typen werden in diesem Buch vorgestellt: Booster Overdrive Distortion/Fuzz" Wahnsinn!
Ich bin heute über diese Seite gestolpert https://www.electrosmash.com/mxr-distortion-plus-analysis dort wird ein Distortion Pedal mit Germaniumdioden analysiert mit jeder Menge Mathematik. Auf dieser Homepage findest du die Analysen von verschiedenen Pedalen und Verstärkern.
> ein Distortion Pedal mit Germaniumdioden analysiert Ja ohne "gute" Mathematik kein "guter" Sound. Wer weiss schon, dass eine Besselfunktion 2. Ordnung beim Verzerren nur Oberwellen der "guten" Sorte erzeugt. Richtig, kaum einer bis keiner. Statt dessen wird ueber den "Roehrensound" und "Germaniumdioden" blasphemiert. Da der 56k hier ja schon oefter genannt wurde, @TO: Besorg dir halt ein antiquarisches 56002 Evalkit. Das ist der schnellste Weg zum Erfolg! Wenn die Mathematik um das Thema herum bei dir "sitzt", kann man Effekte auch ganz problemlos in Assembler schreiben. Falls du dann mehrere davon in ein Geraet konsolidieren willst, nimmst du eben entsprechend viele 56002 oder siehst dich nach etwas kraftvollerem wie einem FPGA um. Und lass blos die Finger von solchen Bastelplattformen wir RPi. Da hast du mehr mit der Umgebung zu kaempfen als mit der Implementierung des eigentlichen Effekts.
@TO Schau mal hier: http://www.generalguitargadgets.com/effects-project https://www.tube-town.net/cms/?DIY/LoV-Projekte http://www.runoffgroove.com/articles.html Gerade beim letzten Link gibt es mehr als genug Bauvorschläge. Ansonsten gibt es hier https://www.musikding.de/Effektgeraete-Gitarre-Bausatz jede Menge Bausätze, deren Schaltpläne auch veröffentlich sind, man muß also keinen Bausatz kaufen. Ist Google bei Dir kaputt das Du nix findest?
Vielleicht noch ein grundsätzlicher Hinweis zum Analog-Sound und seiner Emulation. Man kann z.B. einen ganz guten Overdrive-Effekt auch mit dem Eingang vom Minimoog, oder auch mit einem analogen Mischpult hinbekommen. Beim analogen Minimoog kann man z.B.eine Basssequenz laufen lassen. Die Basssounds sind nie richtig gleich, sondern einer unterscheidet sich (sofern keine großen Stimmungsschwankungen auftreten) minimal oder etwas mehr ein wenig von anderen. Das ist ganz ähnlich auch bei Live-Musikern. Wenn ein Sound ständig gleich haargenau gleich klingt, stellt sich schnell Überhörung/Langeweile ein. Analog gibt es solche Variationen auch im Sternensystem. Die Umlaufbahnen der Planeten oder Sterne lassen sich zwar gut berechnen. Aber haargenau gleich sind die (stets gleichen) Umlaufbahnen nicht. https://de.wikipedia.org/wiki/Trajektorie_(Physik) Früher gab es verschiedene Ansätze, wie physikalische Modelle, oder Simulation der analogen Bauteile im Schaltkreis oder die Simulation der Schaltkreise selber. https://en.wikipedia.org/wiki/Physical_modelling_synthesis https://www.amazona.de/green-box-yamaha-vp1-physical-modelling-legende/
rbx schrieb: > Die Umlaufbahnen der Planeten oder Sterne lassen sich zwar gut > berechnen. Aber haargenau gleich sind die (stets gleichen) Umlaufbahnen > nicht. Das wäre ja auch langweilig mit der Zeit.
Percy N. schrieb: > Das wäre ja auch langweilig mit der Zeit. .. und wäre auch nie zu erreichen, weil es keine Möglichkeit gibt, in einen solchen Zustand hineinzusteuern. Alles was sich dort hineinbewegt, hat Schwung oder Impuls und tendiert immer zum Ausbrechen. Auch Satelliten muss man bei erreichen der Umlaufbahn immer abbremsen. In der Natur ist das auch so: Es gibt kein statisches Gleichgewicht, von dem immer alle reden. Es gibt nur eine Zeit mit geringen Änderungen und scheinbar statischen Schwingungen. Generell tendieren Systeme immer in einer Art und Weise aus einander. Selbst stark gedämpfte Systeme tun das, die scheinbar von selber einschwingen und damit sind wir bei der Gitarre: Die meisten Emulationen auf der Basis von ungedämpften Schwingungen und Amplitudenmodulation - sie sind letztlich unnatürlich und leblos.
Ich probiere derzeit einiges in die Richtung aus, je nach verfügbarer Zeit. Basis ist ein STM32L475, wobei ich erstmal die internen PGA, ADC und DAC verwende. Der ADC läuft über 64-fach Oversampling, um die Auflösung zu verbessern, beim DAC nutze ich dafür beide Kanäle parallel mit unterschiedlicher Gewichtung. Das vom ADC erhaltene Eingangs-Signal wird via Integration von DC-Anteilen befreit und nach Long gewandelt. Danach geht es in die Effektkette, die momentan 4 frei belegbare Plätze hat. Beim Verzerrer habe ich einmal einstellbares Gain + Clipping, aber auch mathematische Funktionen wie y = 22400 * atan(x / 7680) (per lookup-table realisiert) implementiert. Aber ohne einen Tiefpass dahinter klingt das alles eher "rauh". Bei den Filtern habe ich inzwischen gemerkt, dass 32 Bits wohl nicht ausreichen oder ich z^(-1) und z^(-2) begrenzen muss, was wiederum Störgeräusche mit sich bringt. Also werde ich als nächstes die Filter auf 64 Bits intern (Koeffizienten, Zustände) umstellen. Jörg
> dass 32 Bits wohl nicht ausreichen Das deutet eher auf Fehler in der ADC/DAC-Hardware oder in der restlichen Implementation hin. Selbst mit 16 bit DSPs und 16 bit Koeffizientenlaenge der Filter, kann man vorzueglich klingende Effekte bauen. Die 24 bit eines 56002 reichen auch gehobenen Anspruechen. Die ADCs und DACs des STM32 haben doch nur 12 bit? Du solltest vielleicht einen audiotauglichen Codec verwenden.
Cartman schrieb: > ie ADCs und DACs des STM32 haben doch nur 12 bit? Das würde ich auch empfohlen haben. Da bringen auch 64-fach oversampling nicht viel. Ein Faktor 8 geht statistisch in die Auflösung, ein weiterer Faktor 8 in das Spektrum. Bei richtiger Filterung und weißem Rauschen sollte es 3 < X < 6 Bit bringen. Das wären 15-18 Bit Auflösung. Eigentlich ausreichend für Audio weil das Spektrum eher Rosa ist, aber bei der Dynamik eines Gitarrensignals sicher zu wenig. Wie stark lenkt ein Gitarrist eine Saite beim Zupfen aus? 1cm? Wie stark schwingt die dann am Ende? 1mm?
> Das würde ich auch empfohlen haben.
Ja was denn? :)
Mit einem "antiquarischem" 56002 EVM haette der TO sich auf
*seine" Effekte konzentrieren koennen. Statt dessen wird mit
murksiger Hardware (AD/DA) ein voellig unnoetiges Problemfeld
eroeffnet.
Ein 56002 EVM hat einen 16 bit Codec und im mitgelieferten
Samplecode gibt es wirklich einfache Routinen um ihn zu
benutzen. Genau genommen braucht man nur zwei:
InitCodec und ReadWriteAudioData.
Letztere kuemmert sich "semiautomagisch" auch um die Samplerate.
Zur Nutzung muss man nichtmal das Datenblatt des Codecs lesen.
12 bit reichen bei vorverarbeitetem(!) Audiomaterial. Viele Sampler (Roland, Dream) benutzen nur 12 bit fuer ihre Sampledaten. Fuer eine live gespielte Gitarre vielleicht doch etwas wenig. Und das "Schoenrechnen" eines 12 bit AD bringt es auch nicht. Mein DAT-Recorder benutzt z.B. einen 20 bit Wandler von denen "nur" 16 bit aufs Band geschrieben werden. Mit den unteren 4 bit wird dann noch eine quasi PWM versucht, um das Rauschen weiter zu minimieren. Das nennt sich dann "Super Bit Mapping".
Ich habe meine Routinen generell so ausgelegt, dass sie mit 16 Bit (signed) arbeiten können, den STM32L4 hatte ich halt gerade rumliegen... Bei 48KHz Sampling-Rate hat halt (lt. Octave) ein IIR Butterworth-Bandpass 2.Grades mit 2KHz Mittenfrequenz Koeffizienten von ungefähr -3,6 a(1) und 5,1 a(2), während die b(n) Werte eher Richtung 0 gehen. Wenn ich jetzt die Koeffizienten mit 32768 skaliere, bekomme ich halt ggf. Überläufe bei Zwischenergebnissen, wenn ich mit weniger skaliere, werden die b(n)-Werte zu ungenau repräsentiert. Das ist übrigens kein Problem heutiger Mikrocontroller, das ist schon länger bekannt und auch der 56xxx rechnet Zwischenergebnisse nicht nur mit 24 Bits: "... the data paths are 24 bits wide, providing 144 dB of dynamic range; intermediate results held in the 56-bit accumulators can range over 336 dB." Ich sehe das momentan sowieso eher als Experimentierfeld und finde es interessant, dass mir ca. 30 Jahre nach dem Automatisierungstechnik-Studium wieder eine Z-Transformation "über den Weg läuft". Jörg
Ein M3 ARM und erst recht ein M4 ARM haben durchaus Befehle deren Resultat in 2 Register geschrieben wird. Das sind mithin 64 bit.
1 | ldrd r2,r3,[r0,#0] |
2 | smull r1,r2,r2,r3 |
3 | ldr r1,[r0,#8] |
4 | str r3,[r0,#8] |
Daran sollte es also nicht scheitern. Ich zweifle nur daran, dass ein C-Compiler da immer die passenden Zugriffssequenzn parat hat, obwohl ich aus reiner Bequemlichkeit auch so etwas schon in C geschrieben habe. Da war mit aber die Perfomance schlicht egal.
1 | tmp = (((long long)co * (long long)s1) >> 30) - s2; |
Beim 56002 ist es halt bequemer, weil der 56 bit Akku grundsaetzlich benutzt wird. Wenn der/ein DSP nicht mehr reicht und ein FPGA das leicht und viel besser kann, wird einem 56002 Assembler noch wie ein sonntaeglicher Spaziergang vorkommen gegenueber VHDL.
Tja, bei der Frage nach dem Sound von Charlos Sananta fällt mir doch glatt die alte Frage der Bassisten ein, „wie bekomme ich den Sound von Marcus Miller?“ . . . . … Antwort: Üben Aber trotzdem danke für die eigentliche Fragestellung und die sinnvolle Betrachtung mit Besselfunktionen… Grüße Georg
Georg schrieb: > Frage nach dem Sound von Charlos Sananta fällt Wenns weiter nichts ist: Einfach nur so spielen wie Carlos Santana, die Technik drumherum ist ein weit überschätzter Nebenschauplatz.
Cartman schrieb: > 12 bit reichen bei vorverarbeitetem(!) Audiomaterial. > Viele Sampler (Roland, Dream) benutzen nur 12 bit fuer ihre > Sampledaten. Alte Sampler taten das und die neueren verwenden aus gutem Grund hochauflösenderes Material. Gerade das ist ein wesentlicher Erfolg für die Softwaresampler auf Windows-Basis: Ausreichend RAM, 32 Bit-Verarbeitung, etc. > Fuer eine live gespielte Gitarre vielleicht doch etwas wenig. > Und das "Schoenrechnen" eines 12 bit AD bringt es auch nicht. Das Problem mit niedrig auflösenden ADCs ist nicht nur das Rauschen, sondern auch die Lineariät. Mit Überabtastung ist das nicht beliebig klein zu kriegen und die NL ist ab einem gewissen Punkt selbst mit selbst erstellter Kalibierung nicht mehr zu beseitigen. > Mein DAT-Recorder benutzt z.B. einen 20 bit Wandler von denen > "nur" 16 bit aufs Band geschrieben werden. Das gilt aber nicht generell. DAT-Recorder wie wir sie in den 90ern benutzten, schrieben volle 20Bit auf das Band - schon deshalb, damit man hinterher noch Pegeln und echte 16 Bit rausbekommen konnte. Es gab natürlich MODI mit eingeschränkter Auflösung und auch Bandbreite, z.B einen 30ksps-Modus. > Mit den unteren 4 bit wird dann noch eine quasi PWM versucht, > um das Rauschen weiter zu minimieren. > Das nennt sich dann "Super Bit Mapping". Allgemein nennt sich das Dithern und es ist eine Pulsdichtemodulation. Das wurde und wird praktisch bei jedem Vorgang angewendet, bei dem Bits reduziert werden, um unschöne Spektralanteile zu vermeiden, welche durch einfaches Runden entstehen würden. Man macht sich dabei auch das ungleichmäßig verteilte Spektrum bei Audio zunutze, das nach oben hin ausläuft.
Cartman schrieb: > Wenn der/ein DSP nicht mehr reicht und ein FPGA das leicht > und viel besser kann, wird einem 56002 Assembler noch > wie ein sonntaeglicher Spaziergang vorkommen gegenueber VHDL. Vom Code sicher, aber was das Programmieren eines Algorithmus angeht, kommt es ein bisschen darauf an, was man tun will. So manche Dinge gehen eben im FPGA durchaus einfacher, weil man die Parallelität hat und sich bestimmte Verrenkungen sparen kann. Habe ja ursprünglich auch mal mit C und DSP angefangen. Der hier hat z.B. so eine 563xx Motorla-CPU: http://www.96khz.org/htm/chameleonsynth.htm Mark S. schrieb: > Georg schrieb: >> Frage nach dem Sound von Charlos Sananta fällt > Wenns weiter nichts ist: Einfach nur so spielen wie Carlos Santana, die > Technik drumherum ist ein weit überschätzter Nebenschauplatz. Den Sound so hinzubekommen, ist aber schon eine Herausforderung. Gerade bei den klassischen Songs aus den 1970ern und 1980ern, die exzessiv mit Effektgeräten gearbeitet haben, wurden meistens analoge Geräte eingesetzt, die nicht nur speziell eingestellt, sondern vereinzelt auch noch modifiziert worden waren. Das nachzubauen ist nicht so ganz trivial. >Charlos Sananta Heisst der neuerdings so?
> DAT-Recorder wie wir sie in den 90ern > benutzten, schrieben volle 20Bit auf das Band - schon deshalb, damit man > hinterher noch Pegeln und echte 16 Bit rausbekommen konnte. Das waren dann aber keine (DAT-)Consumergeraete. Und sicher auch nicht auf denen abspielbar. Insoweit ist deine Aussage auch nutzlos, weil sie auf Geraetetechnik abzielt, die allein schon vom Preisrahmen kommerzieller Nutzung vorbehalten war. http://www.hifi-classic.net/review/sony-dtc-60es-537.html > und die neueren verwenden aus gutem Grund > hochauflösenderes Material Und der gute Grund waere Windows? Es sind recht wenige Instrumente denen die bessere Aufloesung wirklich hoerbar gut tut. Also so etwas wie Konzertfluegel etc. Einem geloopten A mit -1 dB FS hoert man da keinen Unterschied an, ob das A mit 12 bit, 16 bit, 24 bit oder 32 bit FP aus der Tabelle kommt. Ich wuerde deswegen meine 12 bit Geraete auch keineswegs weniger benutzen. Bei den VST-Instrumenten scheint es ja der Trend zu sein gigabyteweise Samples hineinzupacken und fuer die herstellenden Softwarefirmen der einfachste Weg auf dem Markt praesent zu bleiben. Was natuerlich nicht gerade innovativ ist.
Cartman schrieb: > Und der gute Grund waere Windows? Der Grund ist die grundsätzlich bessere Qualität, die man mittels dedizierten Interpolationsverfahren aus höher aufgelösten Samples gewinnen kann, welche Dank der PCs ja entsprechend speicherbar und abrufbar sind. Diese haben bekanntlich klassische Sampler komplett abgelöst. Seit etwa 2005 fährt man mit einem eigenen PC statt einem Sampler bei gleicher Qualität billiger (mit einem extra PC wohlgemerkt) und spätestens mit den 64Bit-CPUs ist die Qualität absolut besser, als bei klassischen Samplern, weil spektrale Interpolationen in Echtzeit möglich sind und diese sogar, während der PC noch als DAW arbeitet, d.h. der Sampler ist als plugin eingearbeitet, was ihn nochmal billiger macht. > Insoweit ist deine Aussage auch nutzlos, weil sie auf > Geraetetechnik abzielt, Die Aussage ist keineswegs "nutzlos", sondern beschreibt genau das Problem: Die Consumer-Billig-Dinger orientieren sich an einer anderen Klientel. Im Übrigen haben die genau das Problem ständig gut gepegelt werden zu müssen, um hinreichende Qualität speichern zu können. Es hat schon seinen Grund, warum es gute und weniger gute Technik gibt: Cartman schrieb: > Einem geloopten A mit -1 dB FS hoert man da keinen Unterschied an, > ob das A mit 12 bit, 16 bit, 24 bit oder 32 bit FP aus der Tabelle > kommt. Da widerspreche ich ausdrücklich! Es lässt sich leicht akustisch zeigen, wie groß die Unterschiede sind, wenn man ein gutes Sample beim Abspielen unterschiedlich dezimiert. Es lässt sich im Übrigen auch mathematisch quantisieren, welche Spektralanteile mit welchen Amplituden entstehen. Dass da manch einer beim Probehören keinen Unterschied erkannt haben will, liegt oft daran, dass: - das urspüngliche Sample gar nicht derart hochauflösend war und nur umformatiert wurde, um es kompatibel zum Sampler zu machen - es schon 5mal umgearbeitet und verhunzt wurde - die Abspiel-Ausstattung, speziell die Lautsprecher, nichts taugen, um Unterschiede überhaupt zu transportieren - das Gehör des Nutzers durch ständiges Hören von Konservenmusik- besonders durch oberwellenverarmtes MP3s, derart abgestumpft ist, dass man Qualität nicht mehr erkennt. Besonders Punkt 3 greift mehr und mehr um sich. Wann man sich so manchmal Tonproduktionen anhört, was einem da als Geige ets verkauft wird, erinnert immer mehr an Bontempi! Wenn man mit wenigen Bits auskommen will, muss man Samples überblenden, weil insbesondere die Transiente eine sehr hohe Dynamik hat. Ausgehend von 100% Aussteuerung am Beginn des Anreißens einer Saite klingt diese sehr schnell auf wenige Prozente ab und der bleibende Sustainklang ist überwiegend Ergebnis von Reflektionen der Schwingen aus den unterschiedlichen Ecken des Instruments, die die Energien austauschen. Will man das in ein Sample integrieren sind 16 Bit schon nicht wirklich ausreichend.
> Die Consumer-Billig-Dinger orientieren sich an einer anderen > Klientel. Ein nicht unbetraechtlicher Teil der CDs weist mehr oder weniger Clipping auf, scheint also von "Hausfrauen" am "Kuechentisch" mit "Consumer-Billig-Dingern" gemastert worden zu sein. Auf der anderen Seite, wer mit -4 bit unter FS mit 20 bit aufzeichnet, und meint dass da dann noch 16 bit drin sind, ist genauso ein handwerklicher Pfuscher. Weil an den gesamten 20 bit von unten das Rauschen doch schon heftig zehrt und er sich genau das in seinen Mix holt. Der oben referenzierte DTC-60ES war uebrigens eins sicher nicht: billig. Das weiss ich aus eigener Erfahrung. > Da widerspreche ich ausdrücklich! Das steht dir frei. > Ich wuerde deswegen meine 12 bit Geraete auch keineswegs weniger > benutzen. Eben weil sie nicht nach "Bontempi" klingen. Ich habe freilich aber auch Sampler mit hoeherer Aufloesung. Aber es eben nicht so, dass deren Instrumente automatisch einen "besseren" oder "authentischeren" Klang haetten.
Jürgen S. schrieb: > Will man das in ein Sample integrieren sind 16 Bit schon nicht wirklich > ausreichend. Ganz abgesehen davon, meistens auch viel zu rudimentäre Nachbearbeitungsmöglichkeiten - falls überhaupt. Auf der anderen Seite gab es diese spannenden Filtertabellen beim Yamaha TX16W. So interessant die waren - besonders musikalisch waren die eigentlich nicht. Bei dem Typhoon OS wurde die Musikalität des Filters überarbeitet. Der Entwickler hatte auch was dazu geschrieben, ungefähr "..versucht, das beste draus zu machen.." Das ist ihm gut gelungen - vor dem Hintergrund der Musikalität auf jeden Fall. Darüberhinaus ist das Nachbearbeiten bei 12 Bit schon noch einfacher - jedenfalls von der Datengröße her, und hier waren auch Kompromisse gefragt (beim Loopen z.B.). Beim Original OS konnte man aber alle möglichen Samples aus der Liste auf einer Taste/als Wellenform überlagern - so dass man schnell ein paar gute Soundmischungen als Grundlage zusammen hatte.
Cartman schrieb: > Ein nicht unbetraechtlicher Teil der CDs weist mehr oder weniger > Clipping auf, scheint also von "Hausfrauen" am "Kuechentisch" > mit "Consumer-Billig-Dingern" gemastert worden zu sein. Das ist richtig, widerspricht aber nicht dem, was ich einwarf. Mithin ist das Clipping, dass die CDs scheinbar aufweisen, Ergebnis eines Limiters, also eines "weichen" Clippers und gemacht wird es, um laut zu sein. Siehe "loudness war". Wir entfernen uns aber vom Thema. Cartman schrieb: > Der oben referenzierte DTC-60ES war uebrigens eins sicher > nicht: billig. Das weiss ich aus eigener Erfahrung. Eben und das war er, weil diese Aufzeichnungsqualität damals teuer war, man es eben aber brauchte. Und dies eben, weil mit nur 16 Bit Speicherung nichts anzufangen war. Genau genommen sind selbst 16 Bit Endergebnis auf CD nicht geeignet, weil die Dynamik nicht rein passt. Bei klassischen Konzerten sind die Unterschiede von Maximal- und Minimalpegel im Bereich Faktor 10-15, d.h man hat für einen ppp-Passage gerade mal die hier diskutierten 12 Bit, die aber müssen das komplette Spektrum abdecken und nicht etwa nur einen Gitarrenton mit reduziertem Oberwellenspektrum.
rbx schrieb: > Darüberhinaus ist das Nachbearbeiten bei 12 Bit schon noch einfacher - Das war vielleicht mal so. Ich sehe keinen wesentlichen Vorteil gegenüber 16 Bit, weil diese 3/4 a) nicht viel ausmachen und man b) noch jederzeit verlustfrei komprimieren könnte, wodurch der Faktor statistisch auf die Wurzel (3/4) zusammenpurzelt. Zu dem Thema Samples abschließend noch 2 Dinge: 12 Bit für ein Sample sind erheblich mehr, als 12 Bit für die Aufnahme, denn a) man setzt Musik in der Regel aus mehreren Samples zusammen, wodurch sich die Qualität addiert. Theoretisch bekommt man mit 16 Musikspuren schon einen peak mit 16 Bit. Praktisch sind es etwas zwischen 30-50 Spuren, die die Amplitude und damit die effektive Auflösung um 4-5 Bit steigern. b) man hat durch eine gewichtete Überlagerung jederzeit die Möglichkeit, den Einschwingvorgang mit hohen Amplituden / Spektralanteilen mit anderem Pegel abzuspielen, als den späteren Sustainteil, wie oben schon mal angedeutet. Generell bleibt aber das Problem, das selbst per Dithering vorbereitete Samples bei modifizierten Abspielgeschwindigkeiten Probleme bereiten, weil das Dithern / Runden zu einem Fehlspektrum führt, das nicht mehr weggefiltert werden kann, weil die zufällig generierten spektralen Komponenten nicht von denen zu unterscheiden sind, die im Originalklang enthalten sein müss(t)en. ----------------------- Wir waren mit den "12 Bit" aber eigentlich deshalb zugange, weil damit aufgezeichnet werden soll, und dabei hat man eben das Problem der sich stark ändernden Amplitude bei Gitarren. Wenn man so einen Vorgang in EIN Sample packen will (also nicht Methode "b" von oben) dann braucht man Faktor 10 mehr, als das, womit man den Sustainteil abspielen will. Ein gut eingepegelter Wandler mit 16 Bit Auflösung (und Analogqualität!) ist da das Mindeste.
von Jürgen S. (engineer) >a) man setzt Musik in der Regel aus mehreren Samples zusammen, wodurch >sich die Qualität addiert. Das ist eine interessante Formulierung. Wenn man viele schlechte Qualitäten addiert, wird's eine gute Qualität ;-)
Das gilt aber so nur für Sinusschwingungen, oder? Ich meine, ein Ton mit 50Hz in 10Bit + ein weiterer mit 5000Hz in ebenfalls 10 Bit, sind maximal 11 Bit Amplitude. Für ein Gemisch, bei dem die Frequenzen enger beisammen sind, sehe ich das anders: 400 Hz + 500 Hz ergeben eine heftige Interferenz und erreichen während es Tones eventuell gar nicht die völlige Addition.
> Wenn man viele schlechte Qualitäten addiert Wenn man einige zehn bis hundert emulierte SIDs arbeiten laesst, klingt das durchaus interessant. Ich hoffe du weisst was ein SID ist. Es muessen auch "emulierte" SIDs sein. Das Original ist viel zu ungenau steuerbar. > ist das Clipping, dass die CDs scheinbar aufweisen, Ergebnis eines > Limiters Eher nicht, wenn man sich das im Audioeditor ansieht. Da wird "hart" an den Poller gefahren.
das hatte ich mal: https://picclick.de/Moderne-Musikelektronik-Milit%C3%A4rverlag-DDR-analog-synthesizer-Moog-Sequencer-263131103009.html
Cartman schrieb: > Eher nicht, wenn man sich das im Audioeditor ansieht. > Da wird "hart" an den Poller gefahren. Da war aber dann ein richtiger Amateuer dran. Richtig ist, die Limitierung so zu setzen, dass die maximale Steilheit nicht überschritten wird, welche dann die Bandlimitierung für die sich bildenen Oberwellen definiert. Das macht man i.d.R. mit einem guten Softkompressor, wenn er das kann - oder klassisch "analog" mit einem schnellen Kompresser und Bandfilter + gefiltertem Signal in der sidechain. Übrigens ist genau so eine Schaltung ein recht oft eingesetzer -> Gitarreneffekt, womit wir ganz elegant wieder beim Thema wären. chris_ schrieb: > Das ist eine interessante Formulierung. Wenn man viele schlechte > Qualitäten addiert, wird's eine gute Qualität ;-) Die Qualität wird nicht wirklich besser, es ist nur eben so, dass bei komplexem Frequenzgefüge in einem Musikstück jede einzelne Frequenz eine sehr viel geringere Auflösung hat, als die 16 Bit mit der abgespielt werden. Deshalb gilt auch: Messtechniker schrieb: > Für ein Gemisch, bei > dem die Frequenzen enger beisammen sind, sehe ich das anders: > 400 Hz + 500 Hz ergeben eine heftige Interferenz und erreichen während > es Tones eventuell gar nicht die völlige Addition. Man muss alle Fälle statistisch betrachen: Je nach Phase addieren sich dieselben Wellenanteile eines Dreiklangs unterschiedlich und brauchen eine andere maximale Amplitude und Auflösung. Deshalb sind viele Samples, die sich aus wenigen Klanganteilen zusammensetzen, spektral bearbeitet, um die Auflösung auszulasten. So oder so bleibt der Umstand, dass jedes Sample sein eigenes Spektrum hat und sich die Oberwellen zu allenmöglichen Konstellationen addieren könnten - jeweils zwischen totaler Auslöschung und totaler Addition. Das kann man jetzt für alle erdenklichen Klänge untersuchen. Erfahrungsgemäß entwickelt sich die Gesamtlautstärke mit der Zahl der Tracks bei gleicher Pegelung ungefähr wurzelförmig. Wenn man jetzt als Beispiel 8 Geigen mit ähnlichem Ton mit je 16 Bit Auflösung mischt, erhält man Aussteuerungen von über 18 Bit (statt theoretischer 19). Bei 64 Geigen sind es aber nicht nochmal gut 2 Bit mehr, sondern nur knapp 2 und damit insgesamt gut 20. Bei 512 Geigen (das kann mein Synthesizer) kriegt man keinesfalls 22 Bit zusammen und schon gar nicht die theoretischen 25. Bei unterschiedlichen Samples mit abweichenden Spektren ist es nochmal anders.
>Messtechniker schrieb: >> Für ein Gemisch, bei >> dem die Frequenzen enger beisammen sind, sehe ich das anders: >> 400 Hz + 500 Hz ergeben eine heftige Interferenz und erreichen während >> es Tones eventuell gar nicht die völlige Addition. Jürgen S. schrieb >Man muss alle Fälle statistisch betrachen: >Je nach Phase addieren sich dieselben Wellenanteile eines Dreiklangs >unterschiedlich und brauchen eine andere maximale Amplitude und >Auflösung. Deshalb sind viele Samples, die sich aus wenigen >Klanganteilen zusammensetzen, spektral bearbeitet, um die Auflösung >auszulasten. So einfach ist es eh nicht: Bei MP3 wird eine psychoakustisches Hörmodel verwendet, bei dem einer von zwei Tönen vollständig weggelassen wird, wenn er etwas leiser ist, weil man den dann nicht mehr hört. Die einfache Argumentation über die Addition von Bits reicht also für die Beschreibung der Wirkung auf das Gehör nicht aus. http://docplayer.org/38266200-Mp3-grundlagen-psychoakustik.html
Was ist eigentlich so schwierig daran, auch nur halbwegs vernünftig zu zitieren?
Percy N. schrieb: > Was ist eigentlich so schwierig daran, auch nur halbwegs vernünftig zu > zitieren? Wen meinst du mit deinem Zitat? Meinen Beitrag wohl nicht, oder?
chris_ schrieb: > über die Addition von Bits reicht also für die > Beschreibung der Wirkung auf das Gehör nicht aus. Gehör ist eine ganz andere Sache. Egal ob ein Klang in einem Frequenzsalat gehört werden kann, oder nicht - er ist enthalten. In meinem Beispiel hatte ich darauf abgezielt, wieso die Auflösung sich verbessert, wenn zwei Signalquellen gleicher Amplitude und Auflösung addiert werden. Das ist mal definitiv so, dass 10 Bit + 10 Bit immer 11 Bit sind. Das Gleiche gilt für 3 Quellen mit 10 Bit + 10 Bit + 11 Bit, also 25% + 25% + 50%. Die haben dann eine Signalgüte von 12 Bit. Diese ist durch das unterste Bit / digit und dessen Fehler definiert. Es ist deshelb egal, ob es mit den Phasen und Frequenzen so passt, dass es irgendwo eine Addition zu 100% gibt. Deshalb frage ich micht, wie das hier funktionieren soll: Jürgen S. schrieb: > Deshalb sind viele Samples, die sich aus wenigen > Klanganteilen zusammensetzen, spektral bearbeitet, um die Auflösung > auszulasten. Dann müssten die Quellen in einer noch viel höheren Auflösung vorliegen, damit man sie nach der Bearbeitung hochskalieren kann, bevor sie auf die festgelegte Auflösung quantisiert werden. Wie auch immer, wäre das ein tontechnischer Spezialfall. Allgemein sehe ich nach wie vor das Problem, wenn die Frequenzen zu nahe beieiander liegen. In der Musik spielen die Instrumente bekanntlich nicht irgendwelche Noten, sondern quasi immer dieselbe (zu einem Zeitpunkt). Dann werden 4 gleichzeitig tönende Gitarren ganz sicher nicht die 4 fache Amplitude erreichen, was du ja auch beschreibst. Was aber vergessen wird, ist daß sie sich aber auch teilweise auslöschen, d.h. Teile der Klänge haben kurzfristig die gleiche Frequenz und verschwinden und dabei wird der Fehler meiner Ansicht nach größer. Jede einzelne Gitarre hat ihr eigenes Störspektrum, dass sich absolut zu dem der anderen addiert.
Messtechniker schrieb: > Wen meinst du mit deinem Zitat? Meinen Beitrag wohl nicht, oder? Nein, ich meinte den, der u.a. Dich zu zitieren versucht. Auf dem Handy sind die Zitate in eine Ebene zusamnengerutscht; ich sehe gerade, dass die,Desktopansicht funktioniert.
Messtechniker schrieb: > Dann müssten die Quellen in einer noch viel höheren Auflösung vorliegen, > ... bevor sie auf die festgelegte Auflösung quantisiert werden. Ja und das wir auch genau so gemacht, daher hatte ich weiter oben auch schon angemerkt, dass aufgenommene 12 Bit nicht zwingend dem entsprechen, was man mit (präparierten) 12 bit Samples erzielen kann (weil das als Beispiel eingeworfen wurde). > Wie auch immer, wäre das ein tontechnischer Spezialfall. Nun ja, kommt drauf an. Die Skalierung wird eigentlich immer maximiert und dann dem Sample mitgegeben, wie "laut" es ist. Das macht man auch in anderen Bereichen der Wellenformerzeugung so. Jedes Sample hat Eigenschaften wie Amplitude, RMS und Energieinhalt, worauf man sie optimieren kann. > Allgemein sehe ich nach wie vor das Problem, wenn die Frequenzen > zu nahe beieinander liegen. Da kann ich nicht mitgehen. Es ist aus meiner Sicht egal, welche Frequenzen ich mische oder betrachte. Die Fehler der Samples mischen sich genau so statistisch, wie die guten Anteile es tun. Nach meiner Auffassung muss man alle Kombinationen von Frequenzgemischen durchgehen, dann hat man den Raum komplett abgetastet. Im Spezialfall sieht es natürlich anders aus: 2x genau das gleiche Sample addiert bringt keine Änderung im S/N Verhältnis. > 4 gleichzeitig tönende Gitarren ganz sicher nicht die 4 > fache Amplitude erreichen, was du ja auch beschreibst. Was aber > vergessen wird, ist daß sie sich aber auch teilweise auslöschen, d.h. > Teile der Klänge haben kurzfristig die gleiche Frequenz und verschwinden > und dabei wird der Fehler meiner Ansicht nach größer. Die Auslöschung von Oberwellen ist ein Grund, warum mit zunehmender Zahl der Spuren die Amplitude nicht so steigt, wie es statistisch erwartbar ist. Da das dan passiert, wenn die Anteile in Gegenphase sind, kann / solle sich auch der Fehler auslöschen, je nachdem, wie die anderen Frequenzanteile anhalten waren, die mit zur Rundungsentscheidung beigetragen haben. Das kann theoretisch zum doppelten Fehler werden. Es kann aber auch zu Null werden, wenn sich diese Komponente weglöscht und dies auch dann, wenn die Gutkomponente es nicht tut. Es gibt also die beiden Extreme: A + B = 2 A deren Fehler F(A) + F(B) = 0 sowie A + B = 0 und dafür F(A) + F(B) = 2 x F(A) Diese beiden Extreme für das Nutzsignal und das Fehlersignal bilden 4 Ecken in einem Wahrscheinlichkeitsfeld. Daraus müsste man den wahrscheinlichsten Fehler berechnen. Das hatte ich mal irgendwann mit einer SQL-Abfrage durchsimuliert und auch berechnet. Ich meine es kommt Wurzel (0,707) wegen 2-Achsen heraus. Bei der Amplitude sind es ebenfalls zwischen 0 ... 2 -> Wurzel (1,41). Macht Faktor 1,41 Verbesserung für 2 Wellen im statistischen Mittel. > Jede einzelne Gitarre hat ihr eigenes Störspektrum, dass sich absolut zu dem der anderen addiert. Über alle Kombis gesehen aber eben statistisch und damit teilweise auslöschend. Wie genau sich das abbildet, hängt ja von der Aussteuerung und der Vorbereitung des Samples ab.
Joerg W. schrieb: > y = 22400 * atan(x / 7680) Eine Frage: Woher kommt diese Formel? Warum gerade ARCTAN?
Angehängte Dateien:
-

funktion.png
20 KB
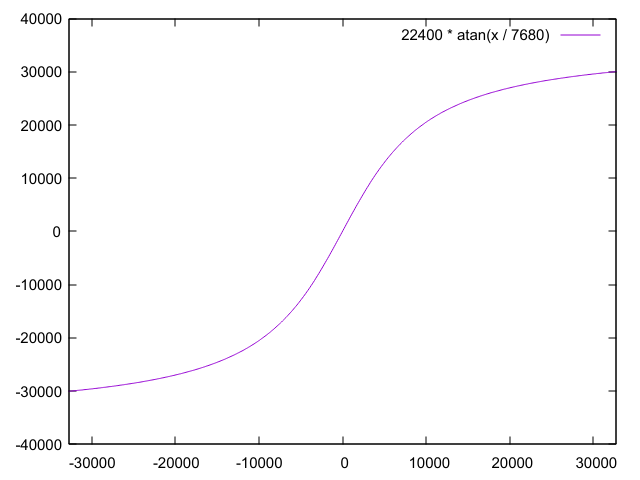
Ich hatte mal verschiedene Funktionen ausprobiert, um automatisch Lookup-Tabellen für die Übertragungsfunktionen erstellen zu können. Und da war halt auch das dabei ;-) Jörg
Joerg W. schrieb: > Ich hatte mal verschiedene Funktionen ausprobiert, um automatisch > Lookup-Tabellen für die Übertragungsfunktionen erstellen zu können. hm, ATAN ist ja nun nicht gerade sehr rechenfreundlich. Bietet auch klanglich nicht unbedingt wesentlich andere Komponenten als andere Verzerrer wie Wurzel z.B. Für Musik würde ich mit wenigen weiteren Oberwellen anfangen, z.B. mit solchen krummlinigen Kennlinien: http://www.96khz.org/oldpages/parametricsaturation.htm Die haben in der ersten Stufe nur X2 und X3, also die Oktave und die Quinte in der Oktave. Da bei Gitarren die Oberwellen auch anfänglich in der 3. 5. und 7. liegen wegen der dreiecksförmigen Elongation ergibt sich daraus schon genug "gefaltetes" Obst!
Danke für den Hinweis und Link, ich habe das mal implementiert (Der Code-Link funtioniert leider nicht) und es klingt ein ganzes Stück besser/angenehmer als meine ATAN-Geschichte. Was wiederum extensive Filterei hinterher erspart. Was mir dabei aufgefallen ist, an der Grenze zwischen linear und verzerrt wird der Ton plötzlich "rau". Das wird wohl auch daran liegen, dass meine ADC-Lösung (PGA + 12 Bit ADC mit Oversampling im STM32L475) letztendlich doch ungeeignet ist und an der Stelle im Wesentlichen zunächst das Rauschen verzerrt wird. Jörg
Joerg W. schrieb: > PGA + 12 Bit ADC Audioausgabe mit 12 Bit? Da fehlt gegenüber modernen Geräten die Hälfte - logarythmisch gesehen. D.h. du bist um Faktor 4000 zu grob. Die Quantisierung selber dürfte den Löwenanteil des Verzerrereffekts ausmachen. Joerg W. schrieb: > Das vom ADC erhaltene Eingangs-Signal wird via Integration von > DC-Anteilen befreit und nach Long gewandelt. Woher kommen dort DC-Anteile? Meine Gitarre liefert nur AC.
oly schrieb:
> Woher kommen dort DC-Anteile?
Ich nutze den internen OPV im PGA-Modus und kopple das Eingangssignal
kapazitiv auf einen Spannungsteiler, den ich auf 50% ADC ohne
Eingangssignal abgleiche. Weil das aber alles andere als perfekt ist,
bleibt ein kleiner Offset, den ich dann mit relativ großer Zeitkonstante
kompensiere.
Auf der Ausgabeseite nutze ich beide DAC-Kanäle parallel mit
unterschiedlicher "Gewichtung", um einen höhere Auflösung zu erhalten.
Das funktioniert eigentlich ganz gut.
Jörg
Mark S. schrieb: > Gitarre üben bringt einen eher ans Ziel. Gitarre üben bringt einen an das Ziel Effekte zu bauen...? Steile These.
master schrieb: > Mark S. schrieb: > >> Gitarre üben bringt einen eher ans Ziel. > > Gitarre üben bringt einen an das Ziel Effekte zu bauen...? Steile These. In der Tat, und warscheinlich genau deshalb stand da auch etwas anderes. Ja, die deutsche Prache kann manchen vor Schwierigkeiten stellen ...
Angehängte Dateien:
-

pga.png
110 KB
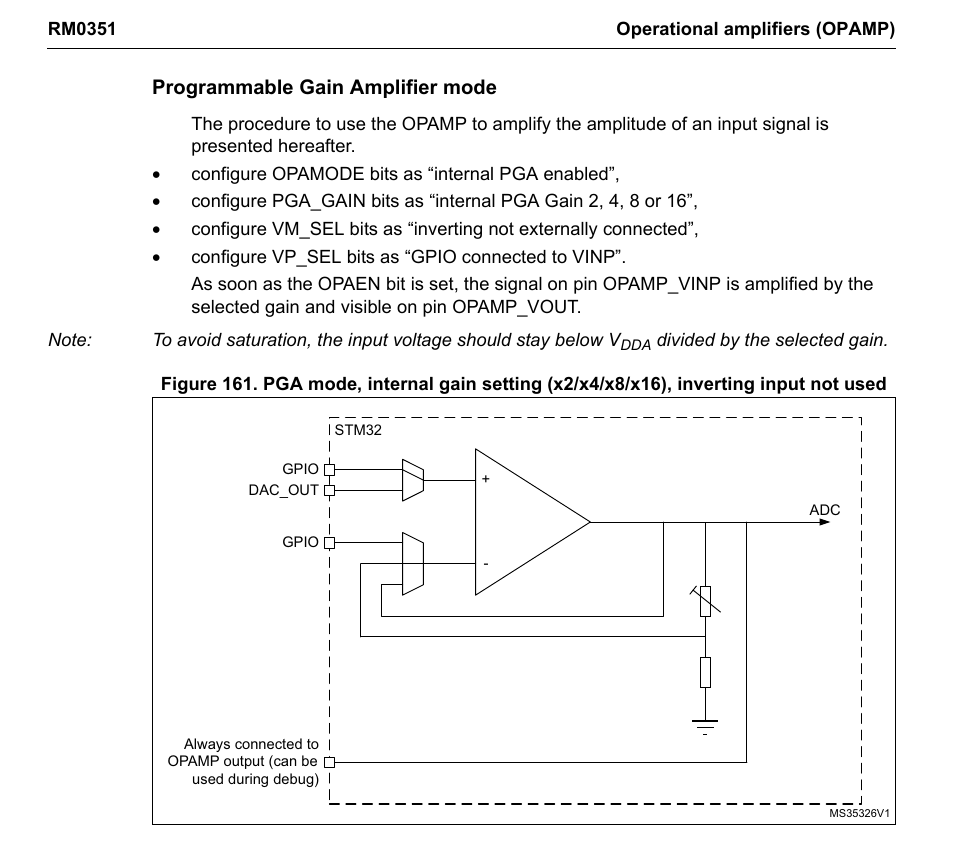
Der STM32L475 hat Opamps drin und die lassen sich in einem "PGA-Mode" mit unterschiedlichen fixen Verstärkungen betreiben. Programmable Gain Amplifier mode auf Seite 691 im Reference Manual Jörg
Das haben eigentlich viele ADCs und Schaltungen mit Vorverstärkern. Interessant wird es, wenn man die Modi zwischendrin in der Signalübertragung umschaltet.
master schrieb: > Mark S. schrieb: >> Gitarre üben bringt einen eher ans Ziel. > Gitarre üben bringt einen an das Ziel Effekte zu bauen...? Steile These. anders herum: Gitarrenüben und An Effekten herumdrehen bringt einen dahin, Songs zu schreiben, da beides inspirierend ist. Mit Effekten wie Echos kann man schöne Harmonien generieren. Ein Beispiel wäre "Nautilus" von Willy Astor.
Cartman schrieb: > Wer weiss schon, dass eine Besselfunktion 2. Ordnung beim > Verzerren nur Oberwellen der "guten" Sorte erzeugt. Wieso ist das deiner Ansicht so und was sind den "Oberwellen der guten Sorte"?
Rolf S. schrieb: > Wieso ist das deiner Ansicht so und was sind den "Oberwellen der guten > Sorte"? Was, außer selbstgefälliger Warmluft erwartest Du von jemandem, der sich diese Frage sofort selbst mit Cartman schrieb: > Richtig, kaum einer bis keiner. > ... blasphemiert beantwortet?
oly schrieb: > Meine Gitarre liefert nur AC. Dann musst du dir ne bessere kaufen. Die von Angus Young kann AC und DC. SCNR
Stefan W. schrieb: > Dann musst du dir ne bessere kaufen. Die von Angus Young kann AC und DC. Der ist gar nicht so schlecht, finde ich. Aber dazu eine ernste Frage: Liefern Gitarren wirklich auch DC, also einen offset? Der Tonabnehmer dürfte AC liefern und spätestens der Gitarreneingang kann nur AC, wenn ich richtig liege. Gibt es Elektrogitarren mit eingebautem Verstärker, die eventuell was anderes bringen? Joerg W. schrieb: > Ich nutze den internen OPV im PGA-Modus und kopple das Eingangssignal > kapazitiv auf einen Spannungsteiler, den ich auf 50% ADC ohne > Eingangssignal abgleiche. Weil das aber alles andere als perfekt ist, > bleibt ein kleiner Offset, den ich dann mit relativ großer Zeitkonstante > kompensiere. Wieso wird das gemacht? Wenn ein DC-Verstärker genutzt wird, dann wird der notwendige Offset am OPV intern beaufschlagt. Selbst, wenn das nicht symmetrisch liegt, also z.V. auf 6V bei einem OP von 0...10V, funktioniert es bei Eingangsspannungen <4V perfekt, wenn der OP linear ist. Am Ausgang einfach wieder kapazitiv ankoppeln.
Manni T. schrieb: > Gibt es Elektrogitarren mit > eingebautem Verstärker, die eventuell was anderes bringen? Es gibt aktive Pickups, aber auch die sollten das übliche Ausgangssignal liefern – schließlich ist der Rest der Kette darauf ausgelegt.
Manni T. schrieb: > Liefern Gitarren wirklich auch DC, Nein, natürlich nicht. Jack V. schrieb: > Es gibt aktive Pickups, Ja, aber selbst deren Ausgang wird kondensatorgekoppelt sein.
Michael B. schrieb: > Ja, aber selbst deren Ausgang wird kondensatorgekoppelt sein. Die Frage die sich stellt ist, welche untere Grenzfrequenz daraus jeweils resultiert. Das hat dann auch durchaus Auswirkungen auf die nachfolgenden Effektgeräte, insbesondere, wenn es Limiter oder andere direkt amplitudenabhängige Effekte sind.
Angehängte Dateien:
-

square_waves_sin_x7.jpg
41 KB

Hier ein Beispiel dafür: 3. und 5.Oberwelle als Annäherung an ein Rechteck. Die analoge Schaltung (und auch die digitale Nachbildung) erfordern eine exakte, relative Amplitude im Bezug auf die Grundwelle, weil die Harmonischen sonst zu groß oder zu klein ausfallen und es Einbrüche oder Höcker gibt. Letztere führen dann noch weiter zu Übersteuerungen. Ein relevant großer Offsetfehler verhindert eine genaue Amplitude, bezogen auf die "lokale" Sinuswelle, die als Grundwelle herangezogen wird. Zum Bild: Links sind Grund- und Oberwelle (auch die 7.!) und rechts die erzeugte Rechteckwelle sowie deren 1. und 2. Ableitung. Eine moderat eingemischte 3. verschiebt den Sinusklang des Rohsignals in Richtung der ersten Klänge "run to the hills" von Iron Maiden, die 5. macht sie brilliant und die 7. gibt einen Zerrklang ... A. F. schrieb: > Was ich gerne hätte, wären solche Klänge wie bei Carlos Santana ... wie in "Samba Pa Ti".
J. S. schrieb: > Die Frage die sich stellt ist, welche untere Grenzfrequenz daraus > jeweils resultiert Deutlich unter 20Hz, oft 1Hz. Schliesslich will man auch nicht einen ewig langen Einschaltplopp
> Deutlich unter 20Hz, oft 1Hz.
Har har har. Dussel! ;)
Eine untere Grenzfrequenz von 1 Hz, fuehrt zu einem
mindestens 1 s langen Einschwingvorgang.
Fuer eine Gitarre reichen eigentlich Werte > 50 Hz.
Ist ja kein Bass. :)
Angehängte Dateien:
-

guitar_limiter.jpg
31 KB

Motopick schrieb: > Eine untere Grenzfrequenz von 1 Hz, fuehrt zu einem > mindestens 1 s langen Einschwingvorgang. > Fuer eine Gitarre reichen eigentlich Werte > 50 Hz. 1s geht in der Tat nicht. Allerdings sind 50Hz deutlich zu hoch, weil eine simple AC-Kopplung einen sehr flachen Frequenzgang hat. Damit würden auch 200Hz-Frequenzen noch durch den Ausgleich betroffen sein und einen falschen Offset "sehen". Günstig sind Werte im Bereich 10-20Hz und damit >=1 Oktave Abstand nach oben zur untersten Nutzfrequenz und trotzdem noch schnell genug, um im Bereich des Spiels (3-5 schnelle Noten pro Sekunde) mitzuhalten, d.h. die Symmetrierung ist schneller, als die Neuanregung durch eine Note. Gleichwohl ist das immer subjektiv und hat Einfluss auf den Klang: Unten die Kurve ist langsamer ausgeglichen, daher "schlägt" die Amplitude länger und einseitiger gegen den Begrenzer.
Motopick schrieb: > Fuer eine Gitarre reichen eigentlich Werte > 50 Hz. > Ist ja kein Bass. :) Auch "normale" Gitarren produzieren Frequenzanteile unter 50Hz. Ist deutlich auf dem Analyzer zu sein.
Vor allem Bass-Gitarren.
> Auch "normale" Gitarren produzieren Frequenzanteile unter 50Hz. Ist > deutlich auf dem Analyzer zu sein. Davon bleibt bei einem ueblichen "Gitarrenkofferverstaerker" blos nicht viel uebrig. Die sind naemlich, auch ueblicherweise, mit nach hinten "offenen" Lautsprechersystemen gesegnet. Und die verwendeten Lautsprecherchassis sind auch nicht so die "guten" Tieftoener... Bei in den Signalweg eingeschleiften Effektgeraeten, stoeren Anteile < 50 Hz auch wohl eher die Funktion, als zum Klang beizutragen.
Angehängte Dateien:

Motopick schrieb: > Und die verwendeten Lautsprecherchassis sind auch nicht so die > "guten" Tieftoener... ja, aber einige produzieren inzwischen auch einen psychedelischen Subbass als Ersatz (Oberwellen, die das Gehirn täuschen). Da geht schon einiges. Hier noch ein Beispiel zum eigentlichen Thema "Selberbauen": Es handelt sich um eine Implementierung in meinem Synth auf der Basis einer Idee Elektor 301 Schaltungen "dynamischer Verzerrer". Das Eingangssignal wird auf 6V verstärkt und über 2 Dioden auf jeweils einen Kondensator geführt, der sich über einen R entladen kann. Damit entstehen 2 Referenzspannungen in der Größenordnung der aktuellen Amplitude. (hellblau) Über ein Poti wird ein Spannungslevel eingestellt - hier 50% (dunkles blau), das als Referenz fungiert. Über 2 Komparatoren wird ein Limiter realisiert der die Diodenspannungen verfolgt und auf die Referenz begrenzt. Diese werden verodert (orange). Damit ist Signal bandbegrenzt verzerrt und folgt in etwa der Eingangsamplitude. Anders als bei einem statischen Begrenzer sind so auch die geringen Amplituden am Ende des Klangs in ähnlicher Weise verzerrt wie am Anfang. Alternativ kann man die Signale auch direkt über den Dioden abgreifen, verstärken und zusammenführen. Dann hat man in etwa ein Rechteck konstanter Amplitude. An der Stelle muss erwähnt werden, dass man für die "OPs" wegen ihrer Bandbrenzung einen IIR-Filter braucht und ein realistisches Diodenmodell nehmen sollte, also nicht einfach abschneiden, weil es sonst zu schnell mächtig klirrt.
Cartman schrieb: > Ein nicht unbetraechtlicher Teil der CDs weist mehr oder weniger > Clipping auf, Was nicht unbedingt so schlimm klingt, wie es aussieht: Der Analogverstärker im CD-Player kann diesen Clip nicht so eckig wiedergeben und rundet das ab.
Angehängte Dateien:
{kind=link}
Das Clipping erzeugt aber Oberwellen, die bis ans Ende des Hörbaren gehen, weil diese Frequenzen ja immer vom Analogpfad übertragen werden. ---- Hier noch ein Gitarreneffekt aus der Kiste: (ganz ohne Cipping) Es ist die Simulation für einen Verzerrer, den ich mit der Chameleon programmiert hatte und der auch später in VHDL übersetzt wurde. (Core erhältlich). Auch das ist eine uralte Schaltung aus den 1980ern, die auch auf Ideen aus ELO- / Elektor-Literatur basiert. - Gitarrensignal mit Tiefpass filtern, damit Rauschen erledigt, geschätzt GF bei 4-5kHz. Das ist Punkt A. - nachfolgenden Tiefpass mit etwas geringerer GF bei knapp 1kHz. Das ist Punkt B. - Differenzverstärker zwischen A und B liefert eine digitale Information über steigende und fallende Kurve. Im DSP kann man das ähnlich machen, z.B. mit 2 IIR-Filtern. Der 2. ist immer hinterher mit der Phase und Amplitude sodass das sicher ist. - Dann kommt ein Schmitt-Trigger, in SW als Hysterese. Dieser verhindert ein falsches Erkennen. Das ist dann Punkt C Nun kommt meine Modifikation: - Ein JK-Filter, das die Frequenz halbiert und Punkt D liefert. - Beide Signale C und D (statt nur einem) getrennt auf einen OP als einstellbarer Verstärker, - von dort einen 2R+R-Summierer und von dort auf einen OP-als Mischer = Multiplizierer - weiter auf einen Mischer als Addierer. Das so zugemischte Signal hat sowohl tiefere als auch höhere Frequenzanteile und wird bis zu 100% zuaddiert. In der Elektronik bestand das Problem, den Multiplizierer gut zu bauen, aus Musikersicht ist das ein VCA - in SW natürlich piece of cake. Im Bild sind die beiden digitalen Differenziationssignale und in rot die erzeugte Welle die aus dem Mischer kommt. Je nach Verhältnis von 1. und 2. Filterwelle bildet sich eine andere Störung. Die Zumischung zu Original ist hier 100% -> 1:1. in Lila. In SW ist das so präzise, dass bei bestimmen Verhältnissen eine Teilauslöschung geschieht. Macht man nun den Parameter für die Mischungsverhältnisse der DIFF-Wellen spannungsgesteuert, kann man dieses wieder durch einen LFO oder die Hüllkurve des Signals steuern. Der Klang verändert sich dann direkt linear mit dem Tonverlauf.
chris_ schrieb: > Bei MP3 wird eine psychoakustisches Hörmodel > verwendet, bei dem einer von zwei Tönen vollständig weggelassen wird, > wenn er etwas leiser ist, weil man den dann nicht mehr hört. ... weil gerne behauptet wird, dass man ihn nicht mehr hört. Richtigerweise ist es aber so, dass durch das Weglassen Information verloren geht, die anderer Stelle fehlt. Steff schrieb: > Hau einfach einen Dirac rein und schau was hinten raus kommt, dann > kannst du es nachbauen Ganz sicher nicht. Aus nur einer Impulsantwort kann man nicht das gesamte Systemverhalten bestimmen. Solange sich das System linear verhält, kommt etwas anderes heraus, als wenn es beginnt, unlinear zu werden.
Rolf S. schrieb: > Richtigerweise ist es aber so, dass durch das Weglassen Information > verloren geht, die anderer Stelle fehlt. Hinsichtlich der Ausgangsfrage oben: Andi F. schrieb: > Was ich gerne hätte, wären solche Klänge wie bei Carlos Santana, oder > den opening Sound von Smoke on the Water. Der fette Sound bei Smoke on the Water kommt nicht allein von der E-Gitarre, sondern zusammen mit einer ebenfalls sehr gut klingenden verzerrten Orgel + gewissermaßen viel Spaß am Spielen mit hoher Ausdruckskunst. Bei Carlos Santana spielt auf jeden Fall auch die überdurchschnittlich hohe Spielkunst und die Musikalität hinein. Man sollte sich die zugehörigen Sounds nicht unabhängig davon denken. Das war ja bei Kraftwerk ganz ähnlich, die waren schon musikalisch sehr erfahren/talentiert unterwegs und hatten verfügbare Techniken / Technikerhilfen bis in die "Überhöhung" musikalisch ausreizen können. In einem Keyboards-Heft gab es mal ein Interview mit einem Tontechniker der meinte mal sowas wie "Du möchtest so einen Bass(Sound) wie den von X im Mix haben?" Es wäre für mich kein Problem, wir könnten X auch einfach herholen, und den Basspart spielen lassen. Der Witz dahinter war, dass man sich auch zutrauen sollte, etwas eigenes zu machen, zu entdecken, zu feiern.. Ich hatte selber auch lange herumgerätselt, wie Human League diesen fetten Bass-Sound bei Being Boiled hinbekommen hatte. Dank YT konnte man feststellen, dass dieser Basssound direkt mit einem bestimmten Korg-Synthesizer zu tun hatte. Es kommt noch schlimmer: Ein anderer guter Song lebt praktisch aus einem (Bass-)"Sample" eines alten Analog-Drumcomputers heraus. Wenn wir hier im Forum so viele Röhrenexperten haben - wäre es da nicht schöner, was gutes (und pflegeleichtes) mit Röhren zu machen?
Rbx schrieb: > Wenn wir hier im Forum so viele Röhrenexperten haben - wäre es da nicht > schöner, was gutes (und pflegeleichtes) mit Röhren zu machen? Natürlich nicht. Ein DSP macht heute alles auf Knopfdruck. Denn JA: viele Sounds hatten damals ganz speziell was mit der (damals neu) verfügbaren Hardware zu tun. Wer nicht dutzende teurer Vintage Setups kaufen will, fährt mit Emulation per DSP billiger und besser. Und NEIN: Einfach ein Effektgerät nach Schaltplan nachzubauen führt nicht zum Ziel: du weisst trotzdem nicht, ob dein Nachbau so funktioniert wie das Original, manche lebten einfach von schlechtem Aufbau weil Verstärkerstufen schwangen oder lange Zuleitungen Spannungsabfall brachten.
Michael B. schrieb: > Einfach ein Effektgerät nach Schaltplan nachzubauen führt > nicht zum Ziel: Welches Ziel denn? Belanglose 0815-Mucke, oder lieber etwas einzigartiges? So ein Minimoog klingt total geil, braucht nicht viel Anleitung, hat aber ein sehr gutes Manual, und man hat schnell die wichtigsten Handgriffe zusammen. Digitaltechnik und Filter sind natürlich auch toll - prinzipiell ist die Mathe und das Know How dahinter doch noch eine Menge "Holz" - da ist so ein gut klingender Röhrenschaltplan für den Anfang schneller zusammengestellt. Grundsätzlich kann man bei der Audio-Digitaltechnik auch erstmal mit der Mathe anfangen. (https://www.amazona.de/workshop-casio-czvz-und-die-grundlagen-der-phase-distortion-synthesis/) So um die 2 Jahre sollte man schon einplanen, wenn man einsteigen möchte. Außerdem empfehlen sich Musikinstrumenten-Lernkurse, denn gerade weil die Digitaltechnik in Richtung Beliebigkeit tendiert, muss man das mit Spielwitz und "Groove" ausgleichen können.
Rbx schrieb: > Wenn wir hier im Forum so viele Röhrenexperten haben - wäre es da nicht > schöner, was gutes (und pflegeleichtes) mit Röhren zu machen? Wir Gitarristen haben ja überwiegend Röhrenverstärker. Mir geht es um das erweitern des Spektrums der Klänge mit Software, die ich selber erstellen und ausbauen kann.
Andi F. schrieb: > Mir geht es um > das erweitern des Spektrums der Klänge mit Software, die ich selber > erstellen und ausbauen kann. Verstehe ich, Röhrenamps sind ja auch vielmehr 70er Jahre Hip. Der Bezug darauf ist eher Forenbezogen gemeint. Ein neuer Coversong auf der Liste, oder ein vertiefen in spielerische Ausdrucksstärke ist allerdings auch hervorragend dafür geeignet, das Ausdruckspotential und die Klangvielfalt zu verbessern. Unabhängig davon: der Thread ist ja zufälligerweise auch schon 2 Jahre alt, was hast du inzwischen gelernt? Falls du immer noch Einstiegsprobleme hast, würde ich diese beiden Videos empfehlen: (sind natürlich nur Vorschläge, ein Uni-Studium wäre noch besser) Learn Audio DSP 1: Getting started with Octave and making a sine oscillator https://www.youtube.com/watch?v=tx_cjBjZ2zM Running DSP Algorithms on Arm Cortex M Processors https://www.youtube.com/watch?v=PKdwQwBIv48
Rbx schrieb: > Verstehe ich, Röhrenamps sind ja auch vielmehr 70er Jahre Hip. Da täusch dich mal nicht! Es gibt immer noch Hersteller, die echte Analogtechnik bauen.
Bernd schrieb: > Da täusch dich mal nicht! Es gibt immer noch Hersteller, die echte > Analogtechnik bauen. Weiß ich doch. Wäre das anders, hätte ich auch was von Transistoren schreiben können ;) Ich habe auch ein DSP-Gerät, mit vielen Emulationsmöglichkeiten. Die sind interessant, aber eigentlich noch lange nicht so reizvoll, wie eine Transistor-Bodentreter-Overdrive-Session mit dem Minimoog. Gitarre spiele ich auch lieber die Akustische, die lenkt einen nicht so ab ;)
Andi F. schrieb: > Wir Gitarristen haben ja überwiegend Röhrenverstärker Kühne Behauptung, einfach mal von Dir auf den Rest der Welt geschlossen?
Wenn ich mir die Verteilung der Amps beim großen T so ansehe, dann kann man vermuten, dass die meisten heute Transistor-Verstärker benutzen, vorwiegend auch den Preisen geschuldet. Man bekommt ja mittlerweile schon vollständige Combos mit AMP, Gehäuse und sogar digitalen Effekten für 199,-. Das dürfte dann die große breite Palette der Musiker bedienen. Das ist nicht anders, als bei den Synth. Billige Teile sind am weitesten verbreitet. Was deren Qualität angeht, kann ich wenig sagen. Bin kein Gitarrist. Was ich auf Bühnen real sehe ist, aber durchaus "amtlich" = "traditionell". Je bekannter und erfolgreicher eine Band, desto weniger muss man aufs Geld schauen. Da haben die auch tatsächlich das Teuerste vom Teueren, als DSP-gesteuerte Röhrentechnik im Einsatz. Auch die PA-Verleiher, die ich kenne, welche Festivals und andere Events ausstatten, haben Röhren-AMPs im pool. Ich selbst würde sicher auch mehr investieren, als nur 500,- .. 700,-, was auf den Shopseiten der Durchschnittspreis zu sein scheint. Eine gute Gitarre liegt bei 2-3k aufwäerts und ein Gitarrist hat nicht nur ein Exemplar im pool! Da sollten es schon möglich sein, 1k in eine Combo zu investieren.
Rbx schrieb: > was hast du inzwischen gelernt? Dass es enorm schwierig ist, an konkrete Algorithmen heranzukommen.
Andi F. schrieb: > Dass es enorm schwierig ist, an konkrete Algorithmen heranzukommen. Gibt genug Open Source Software, in denen konkrete Algorithmen verwendet werden. Die darf man gerne für seine Zwecke hernehmen. Guitarix wäre ein recht prominentes Beispiel.
Jack V. schrieb: > Guitarix arbeitet aber mit https://faust.grame.fr/ und das muss auch erst einmal verstanden werden. Ob man da einfach die Algos herausziehen und in Microcontroller-C herauszuziehen kann, wage ich zu bezweiffeln. Dann eher PURE-Data oder gleich direkt Python. Das ist naheliegender, denke ich. Die Programmiersprache vereinfacht auch nur die Umsetzung und liefert noch keine Ergebnisse! Man muss ja berücksichtigen, dass die klangliche Wirkungen eines Algorithmus immer an seine Parameter und deren Nutzung gebunden ist. Man muss aus musikalischer Sicht erst einmal verstehen, was da passiert und wie man es einsetzen muss. Das ergibt sich nicht direkt aus dem Code und es ergibt sich schon gar nicht aus der lediglichen Nutzung des Codes, gleichgültig, ob er einfach kopiert und eingesetzt- oder ungefährt nachprogrammiert. Das Zielführendste, um zu neuen Klängen zu kommen, ist das Verständnis um die Wirkung von Oberwellen und Tansienten und sich dann zu überlegen, wie eine Schaltung aussehen muss, um diese zu produzieren und zu beeinflussen. Die Gitarre liefert ja eine Menge an Frequenzen und Verläufen, die man erst einmal analysieren muss, um zu mehr, als nur zu einem Signal zu kommen, dass man als stream pauschal dauerhaft in den Verzerrer schickt. Alles, was man mit so einer linearen chain machen kann, ist bereits in ausreichender Menge gemacht und getan und in Hülle und Fülle vorhanden. Auch bei der Beschreibung von Guitarix (Kompressor, Equalizer etc) entdecke ich absolut nichts, was es nicht schon seit 30 Jahren überall gibt. Gute Gitarreneffekte hast du heute ja sogar schon in vielen Keyboards, die einen Audioeingang haben, den sich damit traktieren.
Mal ein paar Ideen aus der Trickkiste: Man entnimmt dem Gitarrensignal durch z.B. Gleichrichtung eine Hüllkurveninformation, durch RMS-Bewertung eine Leistungsinformation und durch FFT eine Frequenzverschiebung während der ersten Zehntel. Diese 3 Informationen werden aufgearbeitet, limitiert, tranformiert und an 3 unterschiedlichen Stellen in der chain benutzt, z.B. Lautstärkeregelung, Filtersteuerung, und Einblendung von Effekten, oder die Steuerung deren Parameter. Erst damit ergibt sich richtige Dynamik. So einen Ansatz hatte ich u.a. hier beschrieben: Beitrag "Re: Gitarreneffekte selber bauen"
J. S. schrieb: > Jack V. schrieb: >> Guitarix > arbeitet aber mit https://faust.grame.fr/ und das muss auch erst einmal > verstanden werden. Wie jede andere Sprache auch. Abgesehen davon war Guitarix nur ein Beispiel – nahezu alle LADSPA- und LVM2-Plugins sind offen und einsehbar. Ohne Vorwissen wird’s alles nix, aber man kann halt nicht direkt behaupten, dass es „enorm schwierig“ wäre, an die Informationen zu kommen. J. S. schrieb: > Auch bei der Beschreibung von Guitarix (Kompressor, Equalizer etc) > entdecke ich absolut nichts, was es nicht schon seit 30 Jahren überall > gibt. Die Sache mit den Impulse Responses, bzw. dem Faltungshall, hat sich beispielsweise in den letzten zehn, fünfzehn Jahren erst verbreitet. Ansonsten: ja – Ziel von Guitarix ist’s, die alten Sachen digital nachzubilden. Also im Grunde das, was gefragt war, oder?
Jack V. schrieb: > ie Sache mit den Impulse Repsonses, bzw. dem Faltungshall, hat sich > beispielsweise in den letzten zehn, fünfzehn Jahren erst verbreitet. SEK'D Samplitude nutzte das bereits in den 1990ern. Ich hatte das in der ersten Version, die ich mit meiner PRODIF 1998 erworben hatte, schon drin. Das war seinerzeit der große neue Hype, das in den Heimstudios zu machen, aber eben schon damals nicht mehr neu. Es gab professionelle Geräte u.a. von SONY für die Studiotechnik, die mit Convolution Reverb arbeiten - halt für enormes Geld. Heute geht das natürlich mit Intel-CPUs im Handsteichm aber der Hype um CR hat sich inzwischen auch ziemlich gelegt, weil die Theorie an drei Grundproblemen krankt: 1) Der Hall ist nur sinnvoll auf trockene Signale anzuwenden, die also noch keine Reflektionen haben, weil sonst unkontrollierare Doppelechos entstehen, die den Eindruck zerstören zu etwas völlig anderem führen. Viele Reflektionen der falschen Art führen sofort zu Matsch, der sich auch einfacher und billiger herstellen und leicht übertrffen lässt. 2a) Die nötige Zerlegung in Einzelfrequenzen und das Wiederkombinieren mittels (i)FFT, bzw das Falten zu fortgesetzten Reflektionen erfolgt nur unvollständig, weil eine FFT immer eine Festerung drin hat, die Artefakte macht. Diese sind gerade beim Hall, der eine zeitliche Ausdehnung braucvt und hat, ziemlich eklatant und fatatl. Es braucht also eine sehr hohe Auflösung der FFT mit Rechenzeit. 2b) Das gleiche gilt für die Erzeugung der Impulse-Files: Das Analysieren per FFT erfordert eine geschickte Fensterung, die zu einem oft faulen Kompromiss führt. Tut und hat man 1 + 2, stellt sich die Frage, wie man sie aufnehmen soll: Ein Mikrofon erwischt immer auch Reflektionen im Raum. D.h. sowohl bei der Erstellung des Materials für die IR-Files also auch bei der Gewinnung des Materials, das später mal bearbeitet werden soll, gibt es Fehlinformationen. Dies summieren sich und stellen die Methode direkt infrage. Es kommt dann noch ein Aspekt hinzu: Ein Mikro erwischt allemöglichen Richtungen im Raum und bewertet diese Frequenzen je nach Richtung. Das führt dazu dass die IR-Files nur dann anwendbar sind, wenn man das Szenario einer solchen Mikrofonanordung 1:1 nach stellen will. Soweit die Methode also überhaupt funktioniert, klappt sie nur mit diesen Randbedingungen. Das will man aber eigentlich in der Regel nicht, weil die Mikroaufstellung an den Klangkörper angepasst wird. D.h. der Tonmann variiert die Mikropositionen und Richtungen passend zum Orchester. Nur dafür passt das dann optimal. Man könnte daher zwar theoretisch, wie es in einem bekannten Werbeneispiel heißt, die IR der Westmister Cathedral nutzen, um den eigenen Chor dort hin zu verfrachten und die Aufnahme dann genau so klingen zu lassen. Das würde insoweit klappen, wenn der eigene Chor ähnlich steht, wie der, der dort aufgezeichnet worden wäre, geht aber nicht, weil man den eigenen Chor nur mit Distanzmikrofonie aufgezeichnet bekommt und in jedem Raum daher Echos drin sind, die das Ganze konterkarieren. Funktionieren würde es nur in einem schalltoten Raum, wo Sänger aber wiederum nicht singen können, weil die Stimme nicht trägt. Im Produktionen verwenden wir CR daher meist für generische trocken Signale aus Synthesizern. Für Gitarren wäre das gut nutzbar - allerdings muss der Raumklang einer Gitarre zum Rest passen, was auch wieder Fragen nach dem Nutzen aufwirft.
J. S. schrieb: > SEK'D Samplitude nutzte das bereits in den 1990ern. In den von mir genutzten Versionen von Samplitude anfang der 2000er war’s irgendwie nicht drin … Aber ich schrieb schon recht bewusst: „hat sich verbreitet“ statt „wurde erfunden“. Das geschah nicht zuletzt aus den Gründen, die du ja selbst mit deinen Punkten unter 2) anführst, erst deutlich nach den Neunzigern. Zu 1) ist zu sagen, dass man genau das „trockene“ Signal im Kontext dieses Threads vorliegen hat. Letztlich verstehe ich allerdings deinen Roman zu diesem Punkt gerade nicht: Faltungshall ist nicht im Scope dieses Threads und wurde von mir nur als Beispiel gebracht, dass in Guitarix durchaus auch aktueller Kram drin ist. Vielleicht erinnerst du dich: es ging darum, dass jemand was mit Gitarreneffekten machen wollte. Meine von dir oben aufgegriffene Aussage bezog sich ausschließlich auf die Behauptung des TE, dass es „enorm schwierig“ wäre, an solche Algorithmen zu kommen – ist es halt nicht per se; die sind, wie du selbst ja auch schreibst, schon lange bekannt, und liegen bei den FOSS-Sachen im Quellcode vor. Dass man damit ohne Vorkenntnisse wenig anfangen kann, steht auf einem anderen Blatt. Nämlich auf dem, auf dem auch steht, dass man diese Vorkenntisse nunmal sowieso braucht, wenn man auf diese Weise eigene Effekte bauen will – und das daher überhaupt kein Problem darstellen sollte. Worauf möchtest du also hinaus?
Jack V. schrieb: > In den von mir genutzten Versionen von Samplitude anfang der 2000er > war’s irgendwie nicht drin … (PRO-)Version? Jack V. schrieb: > Worauf möchtest du also hinaus? ... dass das Benutzen der von dir beispielhaft erwähnten Convolution-Effekte - besonders in Sachen Hall - zwar für Gitarren passen könnte, aber nicht unkritisch angewendet werden kann. Gründe habe ich genannt. Jack V. schrieb: > Vielleicht erinnerst du dich: es ging darum, dass jemand was mit > Gitarreneffekten machen wollte. Ganz dunkel, ja. :-) Daher mein Kommentar zum a) Hall generell und warum es bei einem Gitarrensignal Sinn machen könnte und b) zum Thema Selberbauen. Das mit dem Selberbauen von CONF-Algos ist nicht so trivial wie es die Theorie suggeriert und generell sehe ich bei den LIBs und BlockBuilding-Anwendungen nicht so recht den idealen Zugang zum Selberbauen. Ein Handbuch für Tontechnik/ Audiotechnik und speziell der Gitarrenelektronik scheint mir besser geeignet. Jack V. schrieb: > Letztlich verstehe ich allerdings deinen Roman zu diesem Punkt gerade > nicht: Faltungshall ist nicht im Scope dieses Threads und wurde von mir > nur als Beispiel gebracht, In dem Moment, indem du ihn als Antwort auf die Frage nach Effekten beispielhaft erwähnst, ist er "im scope". Mit Faltung kann man ja noch wesentlich mehr tun, als nur verhallen. Soweit er es deiner Auffasung nach nicht ist, muss ich sofort die Frage stellen, wieso du das anschneidest, denn du wirst ja damit OT. :-) Um es mal OT zu machen: Faltungen kann man auch quer und diagonal über Frequenzen betreiben. Das Ergebnis ist von der Strategie ähnlich dem Ansatz, den ich weiter oben gepostet habe, nämlich Informationen aus Anteilen des Spektralverlaufes zu extrahieren und anderweitig zu nutzen - es passiert halt dann abstrahiert im Frequenzbereich. Da braucht es aber dann nochmal mal Grundverständnis musikalisch-technischer Art.
J. S. schrieb: > Soweit er es deiner Auffasung > nach nicht ist, muss ich sofort die Frage stellen, wieso du das > anschneidest, denn du wirst ja damit OT. :-) Wenn du meinen nebenläufigen, beispielhaften Hinweis auf Möglichkeit der Verwendung von IRs in Guitarix als Vorwand für deine ausschweifenden OT-Posts hier anführst, dann entschuldige ich mich hiermit beim TE in aller Form für die bloße Erwähnung dieser Funktionalität des Programms. Das hab ich nicht gewollt. Wobei ich allerdings bleibe, weil’s halt On-Topic ist: die Algorithmen für Gitarreneffekte sind nicht „enorm schwierig“ zu beschaffen, sondern liegen in vielfältigsten Varianten im Quelltext vor, wobei Guitarix eine gute Anlaufstelle ist. Entsprechend bin ich gespannt, was der TE daraus macht.
A. F. schrieb: > Rbx schrieb: >> was hast du inzwischen gelernt? > > Dass es enorm schwierig ist, an konkrete Algorithmen heranzukommen. Wie wäre es, die Gitarrenboxen aufzuschrauben und die Technik nachzuprogrammieren? Mehr als einige OPs und Dioden sind da ohnehin nicht drin.
Rolf S. schrieb: > Wie wäre es, die Gitarrenboxen aufzuschrauben und die Technik > nachzuprogrammieren? Mehr als einige OPs und Dioden sind da ohnehin > nicht drin. So einfach ist das nicht. Bei den Synthesizern hatten die digitalen üblicherweise auf Filterübersteuerungen, perkussive Resonanzpeaks oder auch einfache Inputs verzichtet. Wenn man allerdings brauchbares (Algo-/Code-)Material hat, kann man durchaus bei der Emulation konkrete Schaltungsbauteile und Setups mit in die Emulation nehmen. https://github.com/topics/guitar-effects https://github.com/lucaong/guitarstack https://www.reddit.com/r/DSP/comments/avgiil/want_to_make_digital_guitar_effect_pedals_where/ https://ses.library.usyd.edu.au/bitstream/handle/2123/7624/DESC9115_DAS_Assign02_310106370.pdf https://ccrma.stanford.edu/~orchi/Documents/DAFx.pdf https://www.ti.com/lit/ml/sprp499/sprp499.pdf https://hackaday.com/2023/08/23/guitar-distortion-with-diodes-in-code-not-hardware/ .. ..
Ließe sich denn eine Schaltung nicht einfach in pSPICE nachbauen und die Netzliste zusammen mit den Formen irgendwie extrahieren? Oder geht das mit MATLAB?
Rolf S. schrieb: > Wie wäre es, die Gitarrenboxen aufzuschrauben und die Technik > nachzuprogrammieren? Mehr als einige OPs und Dioden sind da ohnehin > nicht drin. Was hast du daran nicht verstanden, dass man manche Boxen eben NICHT so einfach nachbauen kann, weil ihr Klang sich aus Defiziten der verwendeten Bauteilen und Nebeneffekten im Aufbau (Zuleitungswiderstand, Einkopplungen, Oszillationen..) ergibt die aus dem Schaltplan und Simulationsmodellen nicht erkennbar sind ? Man kann aber originale alte Effektgeräte nachmessen und versuchen mathematisch zu simulieren. Das wird halt um so schwieriger, je mehr sich gegenseitig beeinflussende Knöpfe sie haben. K. F. schrieb: > Ließe sich denn eine Schaltung nicht einfach in pSPICE nachbauen > und die Netzliste zusammen mit den Formen irgendwie extrahieren? Nein. Oder zumindest nur bei manchen.
Rbx schrieb: > Wenn man allerdings brauchbares (Algo-/Code-)Material hat, kann man > durchaus bei der Emulation konkrete Schaltungsbauteile und Setups mit in > die Emulation nehmen. Den links gehe ich mal hinterher und sehe es mir an. Danke.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.