Hallo zusammen,
ich bin zunächst auf der Suche nach einem einfachen
x86-Assemblerprogramm, das ein beliebiges Speicherwort in das Register
AX schreibt und einen anderen beliebigen Registerwert hinzuaddiert.
Würde mir hier jemand helfen?
Vielen Dank
Das ist einmal ein MOV, und einmal ein ADD Befehl. Die genaue Syntax
hängt etwas davon ab welchen Assembler man verwendet.
Hier zum Beispiel gibt es Erläuterungen zum Thema:
https://www.cs.virginia.edu/~evans/cs216/guides/x86.html
Danke für den Link.
ich habe es selbst versucht und bin zu folgendem Ergebnis bzw. Code
gekommen:
#Zuerst deklariere ich eine 8-Bit-Variable x, die den wert 96 enthält.
1
x DB 96
#Ich verschiebe diese Variable in ein internes Register
1
mov eax, x
#Nun addiere ich den Wert 42 zu diesem Register.
1
add eax, 42
Jetzt müsste sich IMHO der Wert 138 im Register eax befinden.
Ist das korrekt?
mov ax, <16 bit direkt>
add ax, <16 bit direkt>
also
mov ax,1234h
add ax,4321h
danach hat AX den Wert 5555h
Geht natürlich auch mit EAX und 32 Bit Werten.
oder ein klein wenig praktischer:
mov eax,1
mov ebx,2
add eax,ebx
danach hat EAX den Wert 3
Nehalem.
Das sind Prozessor-Internas, die für die Programmierung recht wenig
interessant sind. Aber ich würde davon ausgehen, daß der OpCode oder
µCode MOV EAX<-DIRECT in den Befehlscache wandert und der Wert 1 in den
Datencache.
Nein, der Wert 1 ist ein Immediate, also Bestandteil der Instruktion.
Die landet einfach komplett so wie sie ist im Befehls-Cache.
Im Datencache landen Zugriffe auf Speicher, also wenn man z.B. mit einem
weiteren MOV den Inhalt von EAX an irgendeine RAM-Adresse schreibt.
Ben B. schrieb:> Das kann auch sein, weiß nicht wie elementar der Prozessor die> Instruktionen zerlegt.
CPU Caches arbeiten blockweise, d.h. z.B. ein 4kB-Block (Page genannt)
des Hauptspeicher wird 1:1 in einen Cache Block abgebildet. Die
Instruktionen werden damit "am Stück", inklusive Immediate Werten, in
den Cache übernommen. Es wäre ziemlich sinnlos, den gleichen
Hauptspeicher Bereich sowohl im Daten- als auch Befehls Cache abzulegen.
Ein Aufteilen der Instruktionen beim Füllen des Cache findet nicht
statt, damit wäre auch nichts gewonnen.
Programmierer schrieb:> CPU Caches arbeiten blockweise, d.h. z.B. ein 4kB-Block (Page genannt)> des Hauptspeicher wird 1:1 in einen Cache Block abgebildet.
Die Grundstruktur von Caches sind nicht Pages, sondern Lines, und die
sind nicht 4kB gross, sondern z.B. 64 Bytes.
Pages gibts in der MMU, und die sind tatsächlich meist 4kB gross. Das
hat aber keinen Bezug zu I/D-Caches, sondern nur zu TLBs.
Müsste die Befehlsabarbeitung nicht streng nach dem Harvard-Prinzip
erfolgen? Was man aber konkret damit meint, kann ich nicht herausfinden.
Viele Quellen beschränken sich auf die Ausage, Programm-Speicher und
Datenspeicher seien getrennt.
Ben B. schrieb:> Das sind Prozessor-Internas, die für die Programmierung recht wenig> interessant sind. Aber ich würde davon ausgehen, daß der OpCode oder> µCode MOV EAX<-DIRECT in den Befehlscache wandert und der Wert 1 in den> Datencache.
Nein. Spannend wird es erst bei solchem Code, wenn also auf Code per
Datenbefehl zugegriffen wird:
mov al, [l1]
l1: nop
Oder in der verschärften Fassung als:
mov [l1], al
l1: nop
Was dann intern abgeht kann sehr interessant sein, geht aber
kilometerweise über diesen Thread hinaus.
torben_25 schrieb:> Müsste die Befehlsabarbeitung nicht streng nach dem Harvard-Prinzip> erfolgen? Was man aber konkret damit meint, kann ich nicht herausfinden.> Viele Quellen beschränken sich auf die Ausage, Programm-Speicher und> Datenspeicher seien getrennt.
Auf die realen x86 Prozessoren der letzten gut 2 Jahrzehnte sind die
Begriffe Harvard / von Neumann nicht sinnvoll anwendbar. Einer meint,
getrennte I/D-Caches machen Harvard draus, ein Anderer sieht dank des
gemeinsamen RAMs und Adressraums darin von Neumann.
Wäre möglich, daß die eigentliche Abarbeitung für den Cache
uninteressant ist. Aber diese Prozessoren sind bestimmt in der Lage,
bestimmte Speicherbereiche, die möglicherweise gleich benötigt werden,
in den Cache vorzuladen wenn dafür freie Speicherbandbreite zur
Verfügung steht.
Man könnte auch fragen, ob die Verarbeitungs-Pipeline eigene Caches
hat...
Ben B. schrieb:> Aber diese Prozessoren sind bestimmt in der Lage,> bestimmte Speicherbereiche, die möglicherweise gleich benötigt werden,> in den Cache vorzuladen wenn dafür freie Speicherbandbreite zur> Verfügung steht.
Ja. Nur ist das für die Sicht des Programmierers auf den prinzipiellen
Programmablauf völlig irrelevant. Hat nur Einfluss auf die Laufzeit,
nicht auf das Ergebnis.
> Man könnte auch fragen, ob die Verarbeitungs-Pipeline eigene Caches> hat...
Trace caches und solche für decoded instructions. Sonst jede Menge
Puffer aller Art, aber nichts, was man gemeinhin als Cache bezeichnet.
Alles was über Rolfs Antwort hinaus geht, ist für Torben erst einmal
nicht relevant und führt nur zu Verwirrung.
Ich möchte noch einmal die meine letzte Frage aufgreifen. Im Daten-Cache
liegen die Daten, im Befehl-Cache die Befehle.
Die Autoren Schiffmann, Bähring und Hönig sind im Buch Technische
Informatik 3 der Meinung, die Intel-Core-Architektur sei intern eine
Harvard-Architektur, denn sie weise mit den beiden getrennten Caches für
Instruktionen und Daten die typischen Merkmale dafür auf.
Kann es aber sein, dass die beiden Caches damit gar nichts zutun haben?
Wenn ich das folgende x86-Programm
mov R04, 125
mov EAX, R04
ADD EAX, R01
betrachte, dann muss ich feststellen, dass sich die Trennung von Daten
und Befehlen ja schon aus der Tatsache ergibt, dass die Werte (wie z. B.
125 ) in einzelne separate Register geschrieben werden, in denen keine
Vermischung von daten und Befehlen stattfindet.
A. K. schrieb:> Auf die realen x86 Prozessoren der letzten gut 2 Jahrzehnte sind die> Begriffe Harvard / von Neumann nicht sinnvoll anwendbar. Einer meint,> getrennte I/D-Caches machen Harvard draus, ein Anderer sieht dank des> gemeinsamen RAMs und Adressraums darin von Neumann.
Danke, habe ich erst gesehen, nachdem ich meinen Beitrag gepostet habe.
Für mich ist das weiterhin ganz klar eine von-Neumann-Architektur. Code
ist Daten und Daten sind Code, der komplette Hauptspeicher kann variabel
für beides genutzt werden, beides kann jederzeit gegeneinander
ausgetauscht werden. Das kann die Harvard-Architektur nicht. Ein
Harvard-Computer kann keinen Code im Datensegment ausführen, man müsste
ein solches Programm erst vom Datensegment in das Codesegment kopieren.
Durch Mechanismen wie Speicherschutz usw. werden zwar bestimmte Vorteile
der Harvard-Architektur kopiert (z.B. daß der Prozessor daran gehindert
wird, Code außerhalb von Codesegmenten auszuführen), aber das ist
Programmierung und hat mit dem grundlegenden Aufbau nichts zu tun.
Ben B. schrieb:> Für mich ist das weiterhin ganz klar eine von-Neumann-Architektur.
Und für Torbens Lehrbuch ist es eindeutig Harvard. Woraus man den
Schluss ziehen sollte, dass diese Klassifizierung sinnlos geworden ist,
oder man explizit ranschreiben sollte, ob man sich auf L1-Caches oder
Adressräume bezieht.
Wobei es selbst bei Caches schwierig sein kann, das klar zu erkennen.
Der Cyrix M2 hatte einen gemeinsamen 64kB I/D-Cache, dem aber ein 256B
L0-Cache für Befehle vorgeschaltet war. Rechnet man den Winzling mit,
war es Harvard, sonst von-Neumann.
Wenn man es so betrachtet, ist es aber generell die Frage, ab wo ich die
Betrachtung ansetze. Sobald ich die Prozessor-intern ansetze, wirds
natürlich schwammig, weil spätestens in den eigentlichen Recheneinheiten
µCode und Daten physikalisch nebeneinander vorliegen. Wenn man so
rangeht, dürfte es gar keine Von-Neumann-Architektur geben.
Mal ein Gegenbeispiel: Der AVR-µC ist ein klassischer Vertreter der
Harvard-Architektur. Daten und Code liegen in verschiedenen
physikalischen Speicherbereichen (sogar mit verschiedener
Speichertechnologie). Deswegen ist das Teil auch recht schnell, auf
Befehle und Daten kann gleichzeitig zugegriffen werden. Und egal wieviel
Mühe ich mir geben würde, es ist nicht möglich, Befehlscode aus dessen
RAM heraus auszuführen. Ich müsste solchen Code erst ins Flash kopieren
und dadurch zu Code wandeln.
Der x86 als klassischer Von-Neumann-Rechner muß Code und Daten
nacheinander aus dem Hauptspeicher laden. Er benötigt daher mehr
Speicherzyklen (wo eine Harvard-Architektur immer nur einen einzigen
Zyklus braucht). Irgendwo im Prozessor wird dann natürlich in Code und
Daten aufgeteilt, ob das nun im Cache oder erst in den Recheneinheiten
passiert finde ich unrelevant. Dazu kann der x86 ohne jedes Problem im
gesamten Adressbereich herumspringen, im Real Mode kennt er keinen
Speicherschutz. Er kann nicht zwischen Code und Daten unterscheiden, ein
Harvard-Rechner kann das.
Ben B. schrieb:> Mal ein Gegenbeispiel: Der AVR-µC ist ein klassischer Vertreter der> Harvard-Architektur.
Jo, aber das Ding ist ja auch nicht komplexer als die Rechner aus der
Ära, aus der die Begriffe stammen.
> Der x86 als klassischer Von-Neumann-Rechner muß Code und Daten> nacheinander aus dem Hauptspeicher laden.
Nö. Also der 8088 schon, aber heutige x86 nicht. I- und D-Strukturen mit
ihren Caches operieren völlig getrennt, somit parallel. Und auch wenn du
auf die Schnittstelle zum externen DRAM raus willst, passt es nicht,
denn da kannst du mehrere unabhängig operierende DRAM-Busse haben.
Allerdings brauchst du mich nicht davon zu überzeugen, allenfalls
Adressräume als Kritierium zu betrachten. Meine Rede seit Jahren. Nur
sind die Begriffe in der Fachliteratur unverrückbar an sogenannten
Bussen festgenagelt - die es heute überhaupt nicht mehr gibt. Frei
interpretiert landet man bei Adressräumen. Orthodox wirds willkürlich,
an welcher Struktur man ansetzt.
Doch, bei der Harvard-Architektur gibt es genau das. Hardwareseitig
getrennte Daten- und Befehlscode-Busse, die ausschließlich eines von
beiden transportieren und auch nicht umgeschaltet werden können.
Naja egal, einen Konsens darüber wird es wohl nicht geben und heutige
Prozessoren mögen Hybride aus beidem sein, um die Vorteile von beiden
Ideen nutzen zu können.
Oder anders, man könnte es auch auf die Spitze treiben und einen alten
x86 mit einem AVR simulieren. Dann bleibt es ein Von-Neumann-Rechner,
obwohl die "CPU" eigentlich streng der Harvard-Architektur folgt.
Ben B. schrieb:> Doch, bei der Harvard-Architektur gibt es genau das. Hardwareseitig> getrennte Daten- und Befehlscode-Busse, die ausschließlich eines von> beiden transportieren und auch nicht umgeschaltet werden können.
Dann ist AVR von-Neumann, denn man kann mit einem speziellen Befehl auf
den Codespeicher zugreifen. Bei den 16-Bit PICs, eigentlich klar
Harvard, auch mit normalen Befehlen.
Aber verlassen wir mal die 50er Jahre: Welche heute verwendete
Architektur ist deiner Definition nach Harvard, kann also nicht auf
Codespeicher anders als in Form von Befehlen zugreifen?
Um diese Frage zu beantworten müsste man sich anschauen, wie der
"Datenzugriff" auf den Flash beim PIC oder AVR elektrisch realisiert
ist. Das Datenblatt des AVR gibt dazu nichts her, dort gibt es keine
Verbindung zwischen Flash und Datenbus.
Wahrscheinlich landet man dann wieder bei der Frage an welcher Stelle
man die Betrachtung ansetzt.
Und wie ist das beim STM32F7? Der hat zwei getrennte RAM Blöcke ITCM und
DTCM, welche man als schnellen Speicher für Instruktionen bzw. Daten
nutzen kann, welche über getrennte Busse an die CPU angebunden sind.
Also klassisch Harvard. Allerdings kann man auch Datenzugriffe auf den
ITCM machen, also doch etwas Neumannig. Dann gibt es noch den L1 Cache,
der beides beinhalten kann. Dann noch getrennte Busse für Daten und
Instruktionen für Flash und normalen SRAM. Doch Harvard?
Rolf M. schrieb:> Im Datencache landen Zugriffe auf Speicher, also wenn man z.B. mit einem> weiteren MOV den Inhalt von EAX an irgendeine RAM-Adresse schreibt.
Wenn Rolf Recht hat, dann kann ich nicht nachvollziehen, was I-Cache und
D-Cache mit der Harvard-Architektur zutun haben.
Ich hatte mir das irgendwie so vorgestellt:
Zuerst müsste sämtlicher Hauptspeicherinhalt, der zum Cache
transportiert wird, erstmal von oben nach unten untersucht werden, ob es
sich bei der jeweiligen Bitfolgen um Befehle oder Daten handelt.
Dann hätte ich im I-Cache die Befehle und im D-Cache die Daten. Man
müsste dann irgendwie noch sicherstellen, dass sich die
Speicheradressen, die in den jeweiligen Befehlen zur Adressierung der
Operanden angegeben wurden, auf den D-Cache beziehen. Tatsächlich
beziehen sie sich aber auf die internen Register (EAX etc..) oder den
Hauptspeicher. Hier bricht dann mein Luftschloss zusammen.
torben_25 schrieb:> Wenn Rolf Recht hat, dann kann ich nicht nachvollziehen, was I-Cache und> D-Cache mit der Harvard-Architektur zutun haben.
Man kann sich darüber zwar ewig streiten, aber nutzlos.
> Zuerst müsste sämtlicher Hauptspeicherinhalt, der zum Cache> transportiert wird, erstmal von oben nach unten untersucht werden, ob es> sich bei der jeweiligen Bitfolgen um Befehle oder Daten handelt.
Wozu? Schräges Konzept. Die instruction fetch unit will Befehle, die
load/store units wollen Daten. Damit ist der Fall ja wohl klar. Die L1
caches sind sowieso dicht in diese Units integriert, die kann man kaum
isoliert betrachten. Abgesetzt ist erst ein L2 cache.
Bissel komplizierter wird es, wenn die betreffenden Daten vorher im
falschen Cache liegen (siehe Beispiel oben). Damit bei einem
Schreibbefehl in den Code Ordnung statt Chaos herrscht. Aber wenn du es
gerne noch komplizierter haben willst, dann betrachte den Fall mehrerer
Cores, einer führt die Bytes als Befehl aus, der andere modifiziert
genau diesen Code.
> Hier bricht dann mein Luftschloss zusammen.
Besser so. Völlig falsche Vorstellung.
torben_25 schrieb:> Zuerst müsste sämtlicher Hauptspeicherinhalt, der zum Cache> transportiert wird, erstmal von oben nach unten untersucht werden, ob es> sich bei der jeweiligen Bitfolgen um Befehle oder Daten handelt.
Woran sollte das erkannt werden? Jede beliebige Bitfolge kann Daten
sein. Da wird auch nichts durchlaufen. Der Cache soll sich nur
Ergebnisse von Zugriffen merken, um sie beim nächsten mal schneller
ausführen zu können.
> Dann hätte ich im I-Cache die Befehle und im D-Cache die Daten. Man> müsste dann irgendwie noch sicherstellen, dass sich die> Speicheradressen, die in den jeweiligen Befehlen zur Adressierung der> Operanden angegeben wurden, auf den D-Cache beziehen. Tatsächlich> beziehen sie sich aber auf die internen Register (EAX etc..) oder den> Hauptspeicher. Hier bricht dann mein Luftschloss zusammen.
Es ist eigentlich ganz einfach. Der Prozessor führt Instruktionen aus.
Bei der ersten Instruktion wird diese und die folgenden als eine
Cache-Line in den Cache kopiert. Die zweite Instruktion steht dann
bereits im Cache. Und wenn später nochmal dieser Codeteil ausgeführt
wird, steht er komplett im Cache. Das ist alles I-Cache.
Nun greift das Programm auch auf Variablen im RAM zu. Diese laufen dann
über den D-Cache. Der arbeitet als write-back-Cache, d.h.
Schreibzugriffe gehen erstmal nur in den Cache und landen irgendwann
später dann im RAM. Auch hier kann man Vorteile aus Cache-Lines ziehen,
weil oft sequenziell zugegriffen wird, z.B. beim Durchlaufen eines
Arrays.
Somit hat man eine strikte Trennung von Code und Daten bei den Caches,
wobei ein in der Instruktion enthaltener Immediate-Wert zum Code gehört,
wie bei einer Harvard-Architektur ja auch.
Ich habe es jetzt verstanden. Der Punkt mit Load/Store hat mir gefehlt.
Ich bedanke mich bei allen, die mir bei meiner Frage hier weitergeholfen
haben!
Hallo zusammen,
Gegeben ist ein fiktives Assembler-Programm.
1
mov EAX, 200
2
add EAX, [x+2]
3
4
section .data
5
x DD 2F1000
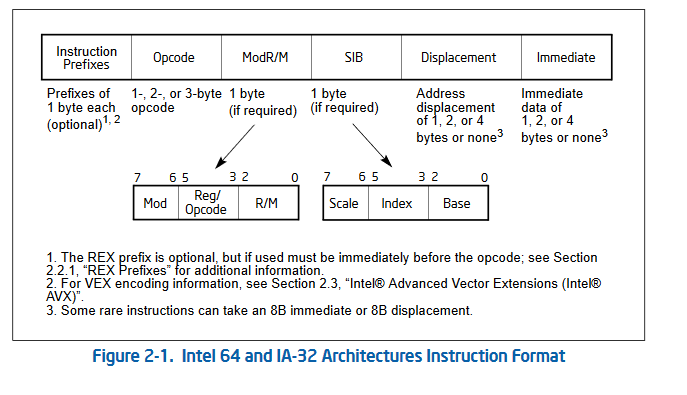
Ich möchte die ersten zwei Zeilen in Maschinen-Code überführen. Liege
ich richtig mit der Annahme, dass ich das Befehlsformat verwenden muss,
das ich diesem Beitrag als Bild angehängt habe?
Kann man eigentlich die ganzen Threads zu ein und dem selben Thema nicht
mal zusammenfassen?
Zu zum Beispiel "Torben lernt x86-ASM" oder so?
Nimm mir das nicht übel aber demnächst erscheint womöglich für die
Erklärung von mov, add, nop etc.. Noch jeweils ein Thread.
Rene K. schrieb:> Nimm mir das nicht übel aber demnächst erscheint womöglich für die> Erklärung von mov, add, nop etc.. Noch jeweils ein Thread.
ich gelobe Besserung!
Ein Assembler-Befehl wie
1
mov EAX, 200
besteht doch aus ASCII-Zeichen. Welcher Zusammenhang existiert denn
zwischen diesem Befehl und dem Befehlsformat, der im x86-Manual
abgebildet ist?
Präfix|Opcode|ModR/M|SIB|Displacement|Immediate
Beide haben doch einen völlig unterschiedlichen Aufbau.
Das ist Maschinencode. Benutze doch einen Assembler, um deinen
Assemblersprachen-Code in Maschinencode zu überführen. Das von Hand zu
machen macht sehr wenig Sinn.
torben_25 schrieb:> Beide haben doch einen völlig unterschiedlichen Aufbau.
Das spielt überhaupt keine Rolle, denn ein Befehl wie mov muss von einem
Übersetzungsprogramm, das ganz zufällig Assembler heisst, in den
Maschinencode übersetzt werden. Daher ist es auch egal, ob der Befehl
zum Bewegen einer Zahl mov, ld, cp oder sonstwie heisst, das muss man
nur dem Assemblerprogramm sagen.
Georg
Dürfte ich zu diesem Thema noch einmal Eure Nerven strapazieren.
Ich komme irgendwie durcheinander. In meinem Buch ist das Befehlsformat
des Core i7 abgebildet.
Die Autoren geben folgendes Format an:
PREFIX | OPCODE | MODE | SIB | DISPLACEMENT | IMMEDIATE
Kurz darauf zeigen sie ein beispielhaftes i7-Assembler-Programm, in dem
unter anderem der Befehl
1
add eax, 42
vorkommt.
Doch dieser Befehl entspricht doch gar nicht dem obigen Format.
Wo ist mein Denkfehler?
Das Problem ist: Ich habe deine Quellen gelesen und habe das, was du
sagst, dort auch so verstanden. Ich bin aber durcheinander gekommen,
weil in dem Buch, das ich durcharbeite, keine Rede davon ist, dass
dieses Format Maschinencode ist. Die Autoren schreiben die ganz Zeit
über Assembler-Code und dann präsentieren sie das Befehlsformat in
Maschinencode. Wie passt das zusammen?
Kann mir jemand sagen, was man in diesem Zusammenhang unter Offset
versteht?
torben_25 schrieb:> Wie passt das zusammen?
Dann ist das kein besonders gutes Buch. Da ja Assemblersprache und
Maschinensprache (mehr oder weniger) 1:1 aufeinander abbildbar sind,
werden die oft durcheinander gebracht. Nach den Beispiel von Wikipedia
ist z.B.
"48 89 E5" Maschinensprachen-Code (im Format aus dem Buch), und
"mov rbp, rsp" der zugehörige Assemblersprachen-Code.
Da das zweite deutlich besser lesbar ist, schreibt man meistens nur
Assemblersprache, unter der Annahme, dass man beides simpel ineinander
konvertieren kann (mittels Assembler bzw. Disassembler).
Bei z.B. C gilt das aber nicht - ein Stück C-Code lässt sich auf viele
Weisen in Assemblersprache (und danach in Maschinensprache) überführen,
und die Kunst besteht darin, die effizienteste Art zu finden. Dabei wird
oft die Struktur auch derart durcheinander geworfen, dass die
Rückführung Assemblersprache -> C auch kaum möglich ist.
Je nach Architektur gibt es allerdings auch bei der Assemblersprache
durchaus Mehrdeutigkeiten, so kann z.B. mancher
ARM-Assemblersprachen-Code auf verschiedene Arten in Maschinensprache
ausgedrückt werden; bei x86 weiß ichs nicht.
torben_25 schrieb:> Kann mir jemand sagen, was man in diesem Zusammenhang unter Offset> versteht?
Das kann alles mögliche sein. Vermutlich ist damit der "Abstand"
zwischen zwei Adressen gemeint; indem man auf eine Basisadresse einen
Offset addiert, erhält man die finale Adresse. Wenn z.B. ein Register
einen Zeiger auf ein C-struct enthält, könnte man einen Offset von 4
addieren um das 4. Byte des structs zu laden. Viele
Speicher-Zugriffs-Instruktionen können diese Addition zusammen mit dem
Zugriff durchführen, um zusätzliche Rechen-Instruktionen zu vermeiden;
der AVR kann sowas aber z.B. nicht.
Es gibt zumindest bei der x86 Familie die Offset Adressierung.
Also
Effektive Adressierung (Record) = Segment + Index
Effektive Adressierung (Record Element) = Segment + Index + Offset
Das Erste ist das Objekt zB ein Record, ein Record auf dem Stack,
Dann ist das Zweite die Adresse des Elementes des Records.
Bei einem RISC waere das ein zusaetzlicher Rechenschritt, hier macht die
Adressiereinheit das.
ADD EAX,42 hat kein Präfix.
Mit Präfix (Busblockierung) wäre es zB. LOCK ADD EAX, 42 wobei ich jetzt
nicht nachgesehen habe ob LOCK bei ADD erlaubt ist.
Ein Offset ist einfach nur eine Adresse im Speicher, beim x86 meistens
relativ zum Anfang eines Segments. Beispielsweise wenn man Variablen im
RAM benutzt:
MOV word ptr ds:[variable1],AX oder
MOV word ptr ds:[offset variable1],AX
Ein Displacement hast Du bei manchen Speicherzugriffen. Wenn Du z.B.
Werte auf dem Stack ändern möchtest, kommt häufig sowas wie
ADD SS:[SP+10h],20h
In dem Beispiel wäre +10h das Displacement und 20h das Immediate.
Sowas wie ADD AX,BX z.B. hat nur einen Opcode, sonst nichts.
Programmierer schrieb:> Je nach Architektur gibt es allerdings auch bei der Assemblersprache> durchaus Mehrdeutigkeiten, so kann z.B. mancher> ARM-Assemblersprachen-Code auf verschiedene Arten in Maschinensprache> ausgedrückt werden; bei x86 weiß ichs nicht.
Bei x86-CPUs gibt es z.B. mov (=: mov1) speziell
für das A-Register (AL,AX,EAX) als Quelle/Ziel,
es gibt aber auch mov (=: mov2) in allgemeinerer
Form und der selben Funktion, bei der aber alle
Register als Quelle/Ziel spezifiziert werden
können. Hier gilt: mov1 ist kürzer als mov2
(bei mov2 wird das entsprechende Register per
ModRegRM spezifiziert).
Und aus solchen Beispielen ergibt sich für ein
Assembler das Problem der nichteindeutigen
Abbildung, Ziel sollte hier aber das möglichst
kürzeste Ergebnis sein.
Sigi schrieb:> Und aus solchen Beispielen ergibt sich für ein> Assembler das Problem der nichteindeutigen> Abbildung, Ziel sollte hier aber das möglichst> kürzeste Ergebnis sein.
Meiner Meinung nach sollte die Assemblersprache eindeutig sein, denn das
ist u.a. einer der Gründe, Assembler einzusetzen: dass man genau in der
Hand hatt, was als Maschinencode rauskommt. Also sollten in so einem
Fall 2 verschiedene Mnemonics verwendet werden. Ich möchte nicht es
drauf ankommen lassen, was ein "intelligenter" Assembler da
rausoptimiert, dann kann ich ja gleich C schreiben.
Ist meine Meinung, wahrscheinlich halten sich längst nicht alle
Entwickler daran.
Georg
Hallo torben_25,
ich kann dir dieses Buch empfehlen:
https://www.apress.com/gp/book/9781484224021
Low-Level Programming C, Assembly, and Program Execution on Intel® 64
Architecture
Authors: Zhirkov, Igor
Der Titel klingt abschreckend, aber es ist sehr gut erklaert mit guten
Beispielen.
georg schrieb:> Meiner Meinung nach sollte die Assemblersprache eindeutig sein, denn das> ist u.a. einer der Gründe, Assembler einzusetzen: dass man genau in der> Hand hatt, was als Maschinencode rauskommt.
Warum ist es so wichtig, dass der Maschinencode exakt kontrollierbar
ist? Es ist doch viel praktischer, wenn der Assembler automatisch die
optimale Möglichkeit nimmt. z.B. gibt es bei ARM eine ganze Reihe
"clevere" Möglichkeiten, Immediates in Register zu laden - jeweils mit
verschiedenen Codierungen verschiedener Instruktionen. Der Assembler
nutzt automatisch die für den jeweiligen Wert effizienteste; diese aber
jedes Mal von Hand zu ermitteln wäre ziemlich lästig, da einige
umständliche Bitfummeleien nötig sind. Das gilt besonders wenn die
konkreten Werte per Makro o.ä. ermittelt werden und sich die zu nutzende
optimale Vorgehensweise ändern kann...
Falls nötig kann man durch Nutzung spezieller Syntax den Assembler auf
eine bestimmte Instruktion festnageln. Macht man aber eher selten.
Es gibt Mnemonics beim x86 Assembler, die nicht so übersetzt werden wie
sie im Quelltext stehen.
LEA AX, variable1 z.B. wird zu
MOV AX, offset variable1
Ben B. schrieb:> LEA AX, variable1 z.B. wird zu> MOV AX, offset variable1
Und?
Apropos: Es könnte interessant sein, im 64-Bit Modus die Binärcodes
hiervon zu vergleichen:
lea eax, variable1
lea rax, variable1
Sicherlich interessant ist, wenn man im Hexeditor ein Assemblerprogramm
mit einem C-Programm vergleicht. Man bekommt einen ersten Eindruck, was
mit "Daten" gemeint sein könnte ;)
Aber ohne Datentypen (z.B. AX, Al, Ah, Byte oder Word Pointer) geht
nicht viel, so gesehen wären "Daten" zum Teil in die Prozessortechnik
eingebaut.
Programmiersprachen (und Zeiger oder Datentypen (z.B. die Typenhilfe bei
Haskell)) wären schon ein passendes Kapitel, aber das hilft nicht
sonderlich darüber hinweg, wenn man am Anfang mit dem Thema (z.B. BP, SP
navigation, LEA Anwendung usw.) sehr durcheinander kommt.
https://stackoverflow.com/questions/1658294/whats-the-purpose-of-the-lea-instruction
Und sind "Daten" nicht eher das, was die Computerlinguisten meinen, z.B.
eine Wörterliste, oder ein Video bzw. mp3?
In der Prozessortechnik kann man z.B. inc ax machen, oder eine
Listenabarbeitung beschleunigen - wenn man so will, dann sind die diese
impliziten "Daten" schon mit in die Planung eingeflossen.
Zunehmende Parallelisierung, Kryptohilfen/Packbeschleuniger könnten auch
in diese Richtung argumentieren.
Das herausragende Merkmal der Intels, nämlich seine Kompatibilität nach
unten oder oben werden bei der obigen Betrachtung m.E. nicht gewürdigt.
Teilweise kann man seine Trennung haben, wenn man Grafikkarten zur
Beschleunigung einsetzt und sich das Zusammenspiel von Cpu und
Grafikkarte denkt und daran denkt, dass die Grafikkarte eine bestimmte
Art von Daten braucht, wie z.B. ein Matheprogramm.
rbx schrieb:> Das herausragende Merkmal der Intels, nämlich seine Kompatibilität nach> unten oder oben werden bei der obigen Betrachtung m.E. nicht gewürdigt.
Heutige ARMs können auch alle alten ARM Programme ausführen. Der selbe
ARM Code kann auf den kleinsten Mikrocontrollern bis zum dicksten Server
lauffähig sein (wenn entsprechend kompiliert). Die
Abwärts-kompatibilität wird lediglich auf OS-Ebene eingeschränkt; hier
werden alte Zöpfe abgeschnitten. Unter solchen leidet x86 ziemlich...
Programmierer schrieb:> Heutige ARMs können auch alle alten ARM Programme ausführen.
Die Cortex M können kein ARM7 Programm ausführen.
Die ARM7 wiederum haben Probleme mit ARM2 Programmen.
> wenn entsprechend kompiliert
Entsprechen kompiliert, also in Hochsprache geschrieben, kann ein Cortex
A76 oft auch ein Program für AMD Ryzen ausführen, und umgekehrt.
A. K. schrieb:> Die Cortex M können kein ARM7 Programm ausführen.
Doch, wenn es in Thumb geschrieben ist.
A. K. schrieb:> Die ARM7 wiederum haben Probleme mit ARM2 Programmen.
Ach, wieso?
A. K. schrieb:> Entsprechen kompiliert, also in Hochsprache geschrieben, kann ein Cortex> A76 oft auch ein Program für AMD Ryzen ausführen, und umgekehrt.
Jeder Cortex-A sollte alle alten ARM-Anwendungs-Programme ohne
Neukompilierung ausführen können, da er sowohl ARM als auch Thumb Code
kann. Nur-Thumb-Prozessoren wie Cortex-M können nur alte
Thumb-Programme, das stimmt.
Die Intel-Quark können auch keinen IA-64-Code ausführen, obwohl sie
neuer sind...
Programmierer schrieb:> Rolf M. schrieb:>> IA-64 ist aber auch schon lange tot.>> Sorry, ich meinte AMD64.> Wobei das Argument mit IA64 auch nicht ganz falsch ist :-)
Naja, mit IA-64 hat Intel mal versucht, seine alten x86-Zöpfe
abzuschneiden und ist damit kläglich gescheitert. Zu ihrem Glück haben
sie das erstmal nur auf dem Server-Markt probiert und nicht gleich
überall, sonst wären sie wohl weg vom Fenster gewesen. Entsprechend
vorsichtig sind sie heute mit der Schere.
Programmierer schrieb:>> Die Cortex M können kein ARM7 Programm ausführen.>> Doch, wenn es in Thumb geschrieben ist.
Die früher verbreiteten ARMTDMI Microcontroller haben zwar das T und
damit Thumb. Startup und Exceptions sind aber völlig anders enthalten
zwingend non-Thumb code. Cortex M Programme und ARM7TDMI Programme sind
in diesem Bereich inkompatibel.
Nur bei Systemen mit klarer Trennung zwischen Betriebssystem und
Anwendungsprogrammen ist Kompatibilität der Anwendungsprogramme denkbar.
>> Die ARM7 wiederum haben Probleme mit ARM2 Programmen.>> Ach, wieso?
Weil anfangs PC, Flags und Modus-Bits zusammen in R15 steckten und der
Programmadressraum damit auf 64 MB begrenzt war. Flags und Modus-Bits
wurden später zugunsten des Adressraums in ein vorher nicht
existierendes PSR Register rausoperiert, was nicht ohne Folgen für die
Programmierung blieb.