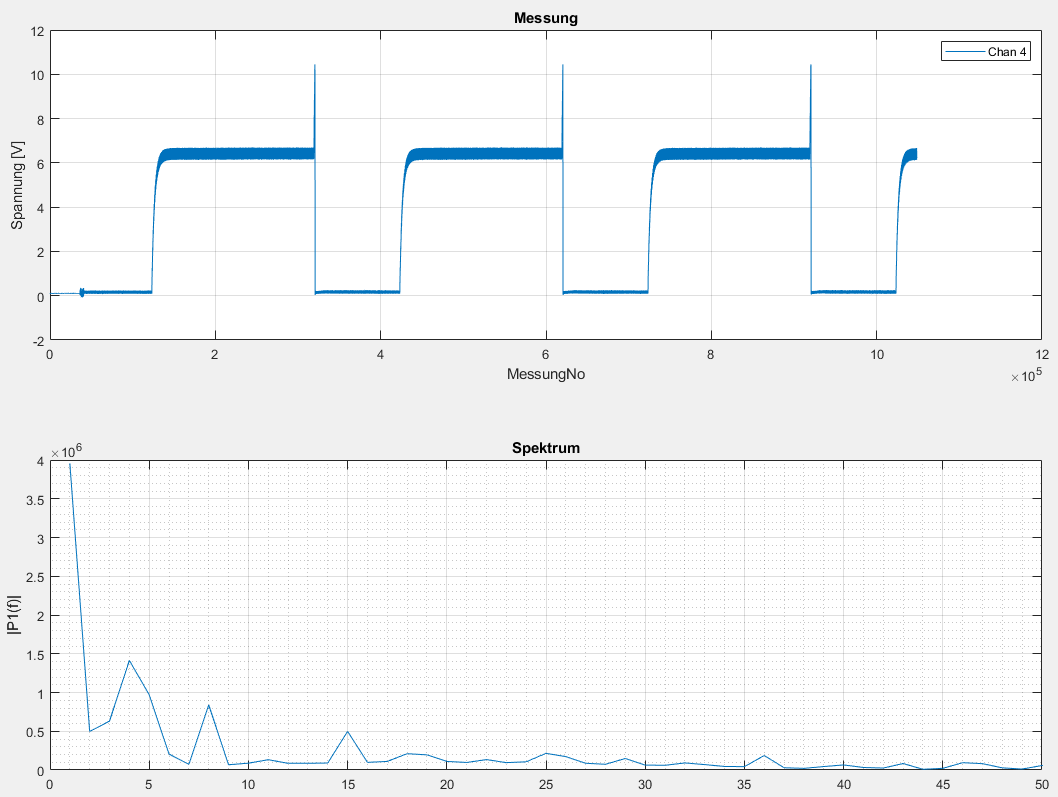
Guten Morgen, ich habe eine Druckkurve einer Pumpe aufgenommen und möchte nun über den Datensatz eine FFT jagen (Raspberry PI, Python). Funktioniert auch, nur das Problem ist, dass die y-Achse falsch oder garnicht skaliert ist (Amplitunden im Bereich von 10^6???). Meine Frage ist, wie ich nun die Achse skalieren kann. Zudem ist am Anfang des Plots ein riesiger Peak zu erkennen? Was hat der da zu suchen? Kann ich den Peak entfernen, indem ich einen Filter (Hoch-/Tiefpass) auf die Daten erst anwende? Oder erstmal den Mittelwert subtrahieren? Ich bitte um Tipps. Viele Grüße Max
Angehängte Dateien:
-

Ergebnisse.PNG
18 KB
Lass das doch mal über einen schönen Sinus (mit einer Frequenz die schön mittig in einem Bin landet) laufen. Dann siehst du ja wo die Amplitude landet und kannst auf Fehlersuche gehen. Wir können das mangels Code ja nicht.
Max U. schrieb: > Kann ich den Peak entfernen, indem ich einen Filter > (Hoch-/Tiefpass) auf die Daten erst anwende? Der bei 0Hz sollte logischerweise durch einen Hochpass verschwinden ja. Die Frage ist, ob du das wirklich willst. Wenn dich der DC Anteil nicht interessiert, kannst du den ja immernoch einfach nicht-auswerten. Max U. schrieb: > Oder erstmal den Mittelwert > subtrahieren? Das wäre ein Hochpass, ja.
mb schrieb: > Lass das doch mal über einen schönen Sinus (mit einer Frequenz die schön > mittig in einem Bin landet) laufen. > > Dann siehst du ja wo die Amplitude landet und kannst auf Fehlersuche > gehen. > > Wir können das mangels Code ja nicht.
1 | import numpy as np |
2 | import matplotlib.pyplot as plt |
3 | import pandas as pd |
4 | from tkinter import filedialog |
5 | from tkinter import * |
6 | import sys |
7 | import warnings |
8 | if not sys.warnoptions: |
9 | warnings.simplefilter("ignore") |
10 | #choose csv file
|
11 | root = Tk() |
12 | root.filename = filedialog.askopenfilename ( initialdir = "/home/pi", title = "Datei auswählen", filetypes = (("Comma Seperated Values (CSV)", "*.csv"), ("Alle Dateien", "*.*")) ) |
13 | # Import csv file
|
14 | df = pd.read_csv(root.filename, delimiter = ';') |
15 | #convert Voltage to Bar
|
16 | df_echt = df/0.01 |
17 | #preparation for fft
|
18 | df_neu = df.as_matrix() |
19 | time = df_neu[:,0] |
20 | voltage = df_neu[:,0]/df_neu[:,0].max() |
21 | df_tr = df_neu.T |
22 | #fft
|
23 | amplitude = np.fft.rfft (voltage) |
24 | freq = np.fft.rfftfreq(len(time),np.diff(time)[0]) |
25 | #plot time signal and fft
|
26 | plt.xlabel ('Messung No.') |
27 | plt.ylabel('Druck [Bar]') |
28 | plt.plot (df_echt, lw = 0.8) |
29 | plt.legend (df) |
30 | plt.figure (2) |
31 | plt.xlabel('Frequenz [Hz]') |
32 | plt.ylabel('Amplitude') |
33 | plt.plot(np.absolute(amplitude), lw = 0.8) |
34 | plt.show() |
Also das ist der Code. Hier ist sogar die y-Achse des Zeitsignlas skaliert. Was ist der Unterschied zwischen einem Hochpass (also direkt aus der Library) und der MEthode wenn ich per Hand den Mittelwert berechne und dann vom Datensatz abziehe? Es sind doch prinzipiell zwei identische verfahren? Gibt es da irgenwelche Vor-/ bzw. Nachteile?
Max U. schrieb: > Was ist der Unterschied zwischen einem Hochpass (also direkt aus der > Library) und der MEthode wenn ich per Hand den Mittelwert berechne und > dann vom Datensatz abziehe? Mittelwert subtrahieren wäre ein idealer HP mit einer Grenzfrequenz von 0Hz. Entfernt also wirklich nur genau die DC-Komponente und fasst das Signal ansonsten nicht an. Was der HP der Library macht weiß ich nicht, aber ich vermute mal dass es da eher um die Simulation eines realen Hochpasses geht, d.h. Grenzfrequenz != 0 und mit einer begrenzten Steilheit von soundso vielen dB pro Dekade. Der würde dann auch niederfrequente Anteile reduzieren.
Interessehalber: kannst du deine Daten in numerischer Form posten (CSV o. ä)?
Btw. dein Signal hat einen Mittelwert von grob 4 und du hast etwas über 10*10^5 Samples. Komplett aufsummiert also etwa 4*10^6 Die Amplitude deines DC bins ist...? Da fehlt also offensichtlich eine Normierung.
mb schrieb: > Btw. dein Signal hat einen Mittelwert von grob 4 und du hast etwas über > 10*10^5 Samples. Komplett aufsummiert also etwa 4*10^6 > > Die Amplitude deines DC bins ist...? > > Da fehlt also offensichtlich eine Normierung. Genau das ist ja die Frage. Wie bekomme ich diese Normierung hin? Ich habe mal bisschen recherchiert und gelesen, dass ich noch durch den Faktor N teilen muss, um die physikalisch korrekte NOrmierung hinzubekommen. Wobei
1 | N = len (amplitude)/2+1 |
ist. Und dann nachher beim plotten
1 | plt.plot (2.0*np.abs(amplitude[:N])/N) |
Dann kriege jedoch folgenden Fehler:
1 | Traceback (most recent call last): |
2 | File "/home/pi/Desktop/fft.py", line 46, in <module> |
3 | plt.plot(2.0*np.abs(amplitude[:N]/N), lw = 0.8) |
4 | TypeError: slice indices must be integers or None or have an __index__ method |
Was ist denn hier fehlerhaft? Oder sind meine Überlegungen falsch? Wie würdet Ihr die Skalierung vornehmen?
Da steht's doch: Max U. schrieb: > slice indices must be integer Aber Max U. schrieb: > len (amplitude)/2+1 Spuckt halt nicht zwingend eine ganze Zahl aus, das musst du im Zweifel z.B. durch int() erzwingen. Man kann doch nicht aus kleinen Programmierfehlern gleich schließen, dass der Ansatz falsch ist, hör mal... So kommt man doch auf nix.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.