Hi,
meine PIC32-Applikation läuft deutlich langsamer als erwartet, selbst
wenn ich -O2 aktiviere, erreiche ich nicht die
Ausführungsgeschwindigkeit, die bei 120 MHz zu erwarten wäre.
Google spuckt mir jetzt zwei Funktionen
SYSTEMConfig(120000000, SYS_CFG_ALL) und
SYSTEMConfigPerformance(120000000) aus, welche sämtliche Peripherie
(inklusive RAM) ordnungsgemäß und zur Taktfrequenz passend
initialisieren sollten. Allerdings: SYSTEMConfigPerformance() benötigt
irgend eine veraltete externe Bibliothek, SYSTEMConfig() ist noch nicht
mal mehr in irgend welchen Headerfiles zu finden.
Deswegen meine Frage: Wie wäre der korrekte und aktuelle Weg, den PIC
vernünftig zu initialisieren, so dass er entsprechend seiner
Möglichkeiten ausreichend schnell läuft?
Danke!
Hi,
ich verwende die PLIB von Microchip.
Ist eigentlich veraltet, ich komme mit dem Harmony aber nicht
zurecht....
bei mir sieht die Initialisierung dann so aus:
Harstad schrieb:> Wie wäre der korrekte und aktuelle Weg, den PIC> vernünftig zu initialisieren, so dass er entsprechend seiner> Möglichkeiten ausreichend schnell läuft?
Hmmm. Verwendest du Harmony?
Dann kannst du doch in der MPLAB X IDE den Takt komfortabel
konfigurieren, mitsamt den Peripherietakten.
Und wie kommst du zu dem Schluss, dass er zu langsam läuft? Kommt bei
USART irnkwie eine zu niedrige Baudrate raus?
Ohne diese Funktionsaufrufe mit den veralteten Libs kommt der PIC32 mit
Defaults hoch. Also maximum waitstates auf SRAM und Flash, als Beispiel.
Wenn er einen Cache hat, wird dieser nicht initialisiert.
Was waitstates auf SRAM heißt: Wenn 4 waitstates eingestellt sind,
benötigt ein SRAM-Zugriff 4 Clockcycles.
Waitstates sind für alle schnelleren CPUs nötig, weil Flash/SRAM keine
120MHz können. Dafür hat deine CPU einen Cache (der deaktiviert ist...)
und Prefetching (das per Default ebenfalls deaktiviert ist).
Dadurch ist die CPU natürlich viel zu langsam. Ich habe Faktor 7
Leistungssteigerung zwischen nicht initialisierter und initialisierter
CPU gehabt.
Die Lösung lautet:
Entweder du schaust in der veralteten Lib nach, was die Funktionen genau
tun (keine Angst, viel ist es beim PIC32MX noch nicht).
Oder du schaust im Datenblatt nach, wie du Waitstates und dergleichen
initialisierst. Dazu gibt es ein eigenes Datenblatt für den Core.
Oder du benutzt Harmony (die neue Lib).
Ich habe Variante 2 benutzt.
Das kann so aussehen:
1
#include<xc.h>
2
#include<stdint.h>
3
#include<sys/attribs.h>
4
#include<stdbool.h>
5
#include<proc/p32mx370f512h.h> //<-- Das ist für dich anders!
6
7
/*set cache, flash and RAM waitstates*/
8
voidsetupCore(uint32_tsysclk){
9
//enable instruction and data caching
10
CHECONbits.DCSZ=0b11;//enable data caching with 4 lines
11
//enable instruction prefetch
12
CHECONbits.PREFEN=0b11;//enable prefech for chachable and non cachable regions
13
//set SRAM / Flash waitstates
14
if(sysclk<=40000000)CHECONbits.PFMWS=0;//zero waitstates for f<40MHz
Weil das meinem Verständniss des Datenblattes entspricht, muss das nicht
richtig sein.
Viel bingt der Cache. Viel mehr als eine Reduktion der waitstates.
Bau bei der Gelegenheit gleich Exception-Handler ein. Sehr praktisch,
diese Exceptions.
Viel Erfolg :-)
Nick M. schrieb:> Hmmm. Verwendest du Harmony?
Nein, bei Harmony scheitere ich schon daran, ein neues Harmony-Projekt
anzulegen: er akzeptiert den Framework-Path einfach nicht, obwohl ich
über den Framework-Downloader alles dort hinein heruntergeladen habe,
was relevant sein sollte.
Harstad schrieb:> Nein, bei Harmony scheitere ich schon daran, ein neues Harmony-Projekt> anzulegen:
OK, kenn mich nur mit Harmony aus. Die Probleme hab ich aber nicht
(verwende aber auch nicht die 3.x-Version.
Ich hab aber mitbekommen, dass paar Leute damit scheitern. Hier gibt es
bestimmt eine Lösung dafür: https://www.microchip.com/forums/f291.aspx
Allerdings muss man bei der 3.x aufpassen, ob der Prozessor (schon)
unterstützt wird, lies also genau nach!
OK, trotz aller Optimierungen bekomme ich nicht die Performance, die ich
benötige. Für eine windige Schleife in der nur zwei Zähler hochgezählt
und je drei Bytes über SPI1 und SPI2 rausgeschoben werden, geht jede
Menge Zeit drauf, wo ich nur ein paar hundert Taktzyklen erwarten würde.
Für 2^20 Durchläufe benötigt er eine halbe Minute.
Ich habe das Gefühl, dass der PIC nicht auf den 120 MHz läuft, die ich
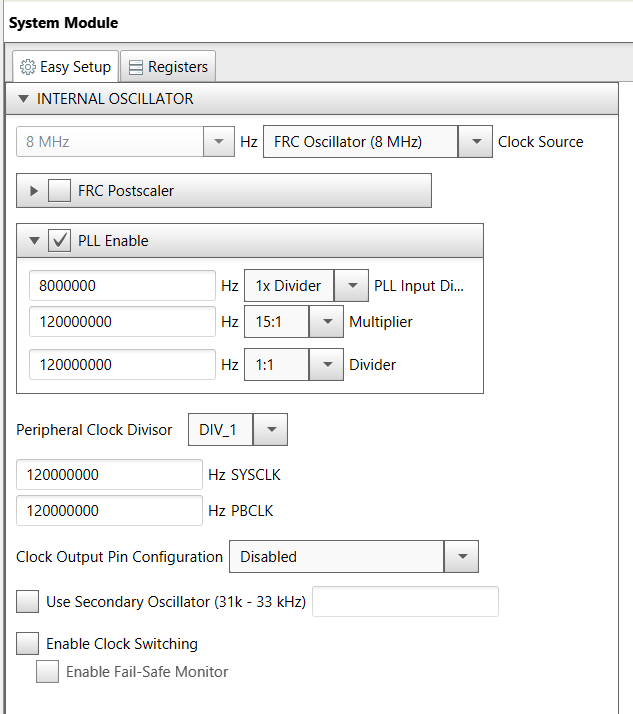
eigentlich meine eingestellt zu haben (siehe Screenshot des MCC).
Kann es sein, dass da mit meine Clock-Konfiguration was nicht stimmt?
Danke!
Harstad schrieb:> OK, trotz aller Optimierungen bekomme ich nicht die Performance, die ich> benötige. Für eine windige Schleife in der nur zwei Zähler hochgezählt> und je drei Bytes über SPI1 und SPI2 rausgeschoben werden, geht jede> Menge Zeit drauf, wo ich nur ein paar hundert Taktzyklen erwarten würde.> Für 2^20 Durchläufe benötigt er eine halbe Minute.>> Ich habe das Gefühl, dass der PIC nicht auf den 120 MHz läuft, die ich> eigentlich meine eingestellt zu haben (siehe Screenshot des MCC).>> Kann es sein, dass da mit meine Clock-Konfiguration was nicht stimmt?>> Danke!
Ich kann dir aus einem Projekt mit PIC32MX370 versichern, dass PIC32MX
zumindest 80MHz die angepriesene Performance bringen. Ich decodiere
damit mp3s in Software, was problemlos nebenher geht.
Wenn du Performance testen willst, solltest du dir die
"Stopwatch-Funktion" von MPLABX ansehen. Damit kannst du die
Durchlaufzeit in Taktzyklen zwischen zwei Breakpoints messen, auch mit
dem PICkit. Das reicht schon mal für eine Plausibilitätsprüfung, und um
Schwachstellen zu identifizieren.
Außerdem kannst du den Takt auf einen Timer geben, und zu einem Pin
einen um ein definiertes Verhältnis heruntergeteilten Takt ausgeben, und
mit dem Oszilloskop oder sogar einer Stoppuhr messen.
Vergiss nicht die Compilersettings! Wenn die Optimierungen ausgeschaltet
sind, produziert der Compiler sehr, sehr langsamen Code. Schon Stufe 1
bringt eine Menge.
Ich compiliere mit -O2, die Peripherals sind per
SYSTEMConfigPerformance(120000000) auf 120 MHz konfiguriert und die
relevanten Funktionen sind alle mit _ramfunc_ in den RAM verschoben,
an der Stelle sehe ich also keine Probleme.
Was ich halt nicht verstehe, sind die komischen Clock-Settings und was
da ganz oben die 8 MHz zu sagen haben - wenn das der Takt für die
Programmcode ist und die 120 MHz nur auf irgend welche Peripherie
wirken, kann es natürlich nicht schnell sein...
Die Verwendung des FRC (8MHz) und einem PLL Input Divider von 1
widerspricht der Spezifikatione des MX350 Oscillators/PLL (siehe DB
Figur 4.1).
Die Eingangsfrequenz der PLL muss zwischen 4 und 5 MHz liegen, also muss
der PLL Input Divider auf 2 gestellt werden (PLL-Input = 4MHz), der
Multiplier auf 24 (PLL-Output 96MHz) und der OutputDivider bleibt auf 1.
Dann läuft der MX350 mit 96MHz.
Was bei 8MHz PLL Input passiert?? keine Ahnung, vielleicht werden
einfach die 8MHz "durchgereicht".....
Chris B. schrieb:> Die Eingangsfrequenz der PLL muss zwischen 4 und 5 MHz liegen, also muss> der PLL Input Divider auf 2 gestellt werden (PLL-Input = 4MHz), der> Multiplier auf 24 (PLL-Output 96MHz) und der OutputDivider bleibt auf 1.> Dann läuft der MX350 mit 96MHz.
OK, wenn ich das so einstelle, zeigt er mir einen PBCLK von 96 MHz an.
Der wird mit einem Teiler von 6 als SPI-Clock verwendet, trotzdem
erhalte ich auf SCLK nur eine Frequenz von ca. 3,8 MHz. Heißt das nicht,
dass ich gar keine 96 MHz habe, sondern nur auf ca. 22.8 laufe?
Und wie bekomme ich den PIC auf die Maximalfrequenz von 120 MHz - geht
das nur mit externem Clock?
Habe das mit einem PIC32MX340F512H gestestet. Bei einem SysClock von
96MHz und einem Teiler von 16 in der SPI Konfiguration messe ich einen
SPI-Clock von 3MHz (genau 2,85MHz).
Nachtrag:
Im DB findet sich unter 17.2.5 die Formel zur Berechnung von F_SCK
(SPI-Clock):
F_SCK = F_PB / (2 * (SPIxBRG + 1) ) ergibt bei 96MHz SPI1BRG = 16:
96 / (2 * (16 + 1) ) = 2,82....MHz
Passt also so ziemlich zur Messung!
OK, dann passt das so weit - was mich aber zu meinem ursprünglichen
Problem zurück bringt: wieso läuft mein Code so langsam? Ich habe mal
nachgemessen, er benötigt für ein paar Zähler und um den SPI-FIFO zu
füllen tatsächlich 0,5 msec (das wären also 48000 Taktzyklen wenn der
Code mit 96 MHz läuft).
Ich mache eigentlich nichts dramatisches, eine Schleife, um zwei Zähler
hochzuzählen (sieht hier etwas kompliziert aus, da es für die
eigentliche Funktion vorbereitet ist):
1
struct raw_data
2
{
3
union
4
{
5
unsigned char bData[4];
6
unsigned int iData;
7
} d;
8
};
9
10
static struct raw_data rawX[2],rawY[2];
11
static bufferOK[2]={0,0};
12
13
void __longramfunc__ main_loop(void)
14
{
15
uint_fast32_t cntX=0,cntY=0;
16
uint_fast8_t shift;
17
18
for (;;)
19
{
20
cntX+=1;
21
cntY+=2;
22
bufferOK[1-buffer]=1;
23
rawX[1-buffer].d.iData=cntX;
24
rawY[1-buffer].d.iData=cntY;
25
useBuffer=1-buffer;
26
if (bufferOK[useBuffer])
27
{
28
DAC_LDAC_SetLow();
29
DAC_CS_SetLow();
30
bufferOK[useBuffer]=0;
31
shift=33-bitCnt[useBuffer];
32
rawX[useBuffer].d.iData=rawX[useBuffer].d.iData<<shift; // shift up to 24 bit data length and align at top
33
rawY[useBuffer].d.iData=rawY[useBuffer].d.iData<<shift; // shift up to 24 bit data length and align at top
//while (SPI1STATbits.SPITBE==0); assumption: when SPI2 is empty, SPI1 must be empty too as it started sending slightly earlier
11
while (SPI2STATbits.SPITBE==0);
12
//while (SPI1STATbits.SPITBF!=0); assumption: when SPI2 is empty, SPI1 must be empty too as it started sending slightly earlier
13
while (SPI2STATbits.SPITBF!=0);
14
// leave only when transmit buffer is empty and all data have been sent
15
}
Optmiierung mit -O2 bringt keinen wesentlichen Gewinn, die Fuktionen
liegen alle schon mit _ramfunc_ im RAM - also wo könnte ich die
Geschwindigkeit verlieren?
Harstad schrieb:> also wo könnte ich die Geschwindigkeit verlieren?
Hast du dir mal den erzeugten Assemblercode angeschaut? Und von wo bis
wo braucht dein uC nun die halbe ms? Ist da das Warten auf den SPI
Transfer auch mit dabei?
> // shift up to 24 bit data length
Hat dein uC einen Barrelshifter? Oder nimmt der jedes Bit einzeln in die
Hand?
Mit SPITBE wartest du, bis das FIFO leergelaufen ist. SPITBF ist
befremdlich, denn ein leeres FIFO ist jederzeit nicht voll. Für das
letzte Byte musst du zusätzlich das Schieberegister pollen (SRMT).
Die Geschwindigkeit hängt davon ab, was in SPIxBRG steht. Hast du hier
vielleicht etwas unpassendes eingetragen? Oder reduzierst du den Takt
über REFCLK?
Harstad schrieb:> void _ramfunc_ SPI_ExchangeBuffer(uint8_t *pSendX, uint8_t *pSendY)> {> SPI1BUF=pSendX[2];> SPI2BUF=pSendY[2];> SPI1BUF=pSendX[1];> SPI2BUF=pSendY[1];> SPI1BUF=pSendX[0];> SPI2BUF=pSendY[0];>> //while (SPI1STATbits.SPITBE==0); assumption: when SPI2 is empty,> SPI1 must be empty too as it started sending slightly earlier> while (SPI2STATbits.SPITBE==0);> //while (SPI1STATbits.SPITBF!=0); assumption: when SPI2 is empty,> SPI1 must be empty too as it started sending slightly earlier> while (SPI2STATbits.SPITBF!=0);> // leave only when transmit buffer is empty and all data have been> sent> }
das geht doch gar nicht, zeig mal deine SPI Konfiguration, du muss
mindesten
1
SPI2CONbits.ENHBUF=1;// 1 = Enhanced Buffer mode is enabled
einschalten. Erst dann kannst du SPIxBUF bis zu 128bit auf einmal laden.
hier mal Codeschnipsel (PIC32MX470):
Hermann U. schrieb:> das geht doch gar nicht, zeig mal deine SPI Konfiguration, du muss> mindesten> SPI2CONbits.ENHBUF = 1; // 1 = Enhanced Buffer mode is enabled
Das ist gesetzt, das Senden der Daten ist ja auch nicht das Problem.
> //SRMT:> // Shift Register Empty bit (valid only when ENHBUF = 1)> // 1 = When SPI module shift register is empty> // 0= When SPI module shift register is not empty> while (!SPI2STATbits.SRMT);
OK, Danke, das probiere ich mal - ich gehe aber davon aus, dass das
momentan (zufällig?) trotzdem funktioniert hat. Ich sehe am Oszi ja die
kurzen, schnellem SCLK-Pulse und zwischendrin die viel zu lange Zeit,
die er benötigt, um meine paar Variablen zu verschieben...
Harstad schrieb:> Ich sehe am Oszi ja die kurzen, schnellem SCLK-Pulse und zwischendrin> die viel zu lange Zeit, die er benötigt, um meine paar Variablen zu> verschieben...
Wenn du shcon ein Oszi hast, dann setze einfach mal an beliebigen
Stellen im Code einen Portpin und irgendwann später wieder zurück. Daran
kannst du dann leicht herausfinden, wo die Zeit verplempert wird.
Zusammen mit dem vom Compiler erzeugten Assemblerlisting lässt sich der
"Rechenzeitfresser" dann schnell aufspüren.