Hallo,
gibt es so etwas wie eine Vorschrift oder eine Regel für bestimmte
Rückgabewerte von Funktionen bei einer erfolgreichen / fehlerhaften
Ausführung?
Die main-Methode liefert ja im Erfolgsfall eine 0 (EXIT_SUCCESS) zurück
(und eine 1 (EXIT_FAILURE) falls etwas schief läuft). Das braucht wohl
das Betriebssystem.
Und diese Festlegung (return 0 == keine Fehler und return 1 == Fehler)
wird anscheinend auch bei anderen Funktionen benutzt.
1
if(rename(oldname,newname)!=0){
2
//error
3
}
Aber warum? Die if-Bedingung würde doch besser und logischer aussehen,
wenn man diese Zahlen vertauscht (return 0 = keine Fehler, return 1 ==
Fehler).
1
if(!rename(oldname,newname)){
2
//error
3
}
4
5
if(!delete(my_file)){
6
//error
7
}
Also quasi die Rückgabewerte als bool-Werte betrachten (1 == true ==
alles in Ordnung, 0 == false == Fehler).
zitter_ned_aso schrieb:> Die if-Bedingung würde doch besser und logischer aussehen,> wenn man diese Zahlen vertauscht (return 0 = keine Fehler, return 1 ==> Fehler).
Korrektur:
return 0; ----> Fehler
return 1; ----> kein Fehler
Hab ich mich auch schon gefragt ob es da eine Konvention gibt.
Allerdings kenne ich auch negative Rückgabewerte für Fehler (int) und
über den Wert (z.b -1; -2; -3;....) wird auch gleich die Fehlerursache
mitgeliefert.
Eine nicht uninteressante Frage, auf die ich auf die Schnelle auch keine
Antwort im Netz finden konnte, Vermutlich wird man aber beim Studium
sehr früher OS Dokumentationen Unix, BSD, CP/M etc. möglicherweise auf
eine Erklärung stossen.
Bis dahin würde ich mir das so erklären:
Angenommen, es wäre so, wie Du vorschlägst. Also:
> return 0; ----> Fehler> return 1; ----> kein Fehler
und ich will die Fehler detailliert unterscheiden können, dann ergäbe
sich zusätzlich (das sind jetzt nur so Hausnummern):
2 --- falsche Eingabe
3 --- Underflow
4 --- Out of memory
etcpp.
also folgende Bereiche:
1 ist kein Fehler
aber 0 und {2, 3, ..., n} ---> Fehler
Der Test
1
if(!errorcode){...}
würde also nicht immer dann wahr sein, falls kein Fehler aufgetreten
ist.
Man könnte noch fragen, ob es nicht anders herum, mehrere Möglichkeiten
des Erfolgs gibt, aber das kompliziert die Sache nur (je nachdem man das
für kompliziert hält), weil man dann das Unterschreiten (oder
Überschreiten) einer Schwelle testen müsste.
So also kann ich mit
1
if(!errorcode){...}
falls, das Ergebnis wahr ist, grundsätzlich davon ausgehen das alles
OK ist. Andernfall muss (oder kann ich wenigsten) die Fehler
differenzieren; was ich, wie ich oben unterstellte, bei Erfolg nicht tun
will. Es gibt vielleicht in einigen Fällen mehrere Möglichkeiten des
Erfolgs, aber die werden dann einfach erledigt (die Erfolge) und ich
will hinterher garnicht wissen, was genau den Erfolg ausgemacht wird
bzw. ich erkenne das an ganz anderen Dingen (Datei wurde erzeugt, Inhalt
ist wie erwartet, Gerät tut was ich will).
Das ist nur eine Erklärung der bestehenden Situation, keine darüber, was
sich die ersten Entwickler so dabei gedacht haben, Aber ich vermute, sie
wird ziemlich gut passen.
Ein Hinweis noch. Es gibt tatsächlich Systeme, die das etwas anders
machen und auch Erfolge differenzieren (können): Etwa
https://en.wikipedia.org/wiki/HRESULT
Theor schrieb:> Ein Hinweis noch. Es gibt tatsächlich Systeme, die das etwas> anders machen und auch Erfolge differenzieren (können)
Dann gibt es noch so Systeme, die unspezifisch "Fehler" zurückgeben und
dann erwarten, dass man eine bestimmte Funktion (z.B. GetLastError,
SDL_GetError) aufruft oder eine bestimmte Variable (errno) untersucht,
um die genaue Ursache herauszufinden. Solche Systeme sind unpraktisch,
weil sie ohne weiteres nicht thread-safe sind.
Und dann gibt es noch Verfahren, die nicht zuverlässig zwischen Erfolgen
und Fehlern unterscheiden können, z.B. liefert atoi() im Fehlerfall -1
zurück, was aber auch einen Erfolg kennzeichnen kann. Solche Systeme
sind große Scheiße.
In moderneren Programmiersprachen gibt es häufig die Möglichkeit
mehrerer Rückgabewerte und dort bekommt man dann oft einen Vektor
[Status, Rückgabewert] zurück.
Aber in C ist "0 ist Erfolg" eine weit verbreitete Konvention, gerade
weil sie verschiedene Fehlerfälle ohne Aufwand unterscheiden kann.
Wenn Du keinen Rückgabewert brauchst, ist bool gut (0 ist schlecht,
alles andere gut)
Wenn Du echte, positive Rückgabewerte brauchst, ist 0, <0 oder <=0 als
Fehler gut.
Bei Pointern ist es meistens 0=Fehler.
Wenn Du keinen Rückgabewert brauchst, aber dem Benutzer Fehlerhinweise
geben willst, dann ist 0 für OK gut: es gibt nicht DEN Grund, warum
etwas funktioniert, aber einen ersten (oder wichtigsten), warum etwas
nicht funktioniert.
Für embedded sollte man m.E. nur OK/nicht OK zurück liefern, wenn es
keinen Benutzer gibt, der direkt eingreift. Die Fehlerinfos gehören
stattdessen in irgendeiner Weise geloggt, gezählt, gespeichert. Sonst
wird jeder Aufruf (Einzeiler) von 30 Zeilen was ist wenn zugemüllt.
A. S. schrieb:> Die Fehlerinfos gehören> stattdessen in irgendeiner Weise geloggt, gezählt, gespeichert. Sonst> wird jeder Aufruf (Einzeiler) von 30 Zeilen was ist wenn zugemüllt.
Warum?
Fehlerfrei = 0
Fehler <> 0, ob der Grund für den Fehler interessiert und dekodiert
werden muss, hängt vom Aufrufer ab. Die "30 Zeilen" sind also nur
notwendig, wenn die Fehlerursache ermittelt werden muss und können auch
in eine Funktion gepackt werden.
Moin,
Jetzt hab' ich natuerlich nicht in alle diese Files reingeguckt, geh'
aber mal stark davon aus, dass die alle voll bis unters Dach sind mit
faulen Ausreden warum irgendwas (mutmasslich ein Funktionsaufruf) nicht
funktioniert hat...
Wenn was funktioniert hat, interessierts erfahrungsgemaess keine Sau,
warum. Es hat ja funktioniert.
Wolfgang schrieb:> Die "30 Zeilen" sind also nur> notwendig, wenn die Fehlerursache ermittelt werden muss und können auch> in eine Funktion gepackt werden.
Merkst Du?
Da gibt es keine GESETZE.
Aber sinnvolle und weniger schlaue Verhaltensregeln:
Bei kleinen Aufgaben ist der Rückgabewert direkt brauchbar:
- Welche Taste wurde gedrückt?
- Wieviele ms hat es gedauert?
- Der Rückgabewert Null = 0 wäre dann kein Fehler-Code, sondern
hieße nur: Da kam nix, da war nix...
Bei komplexeren Funktionen ist eher interessant, ob sie
fehlerfrei abliefen (Error = 0), oder weshalb es nicht geklappt
hat.
ERROR = 0 = OK = OHNE PROBLEM ist sehr sinnvoll:
Wenn es gut gelaufen ist, will keiner wissen, warum!
ERROR != 0, (oder <> 0,) bedeutet: Da liegt ein Problem vor.
- Und wenn der Programmierer sich Mühe gegeben hat, ist der
Error-Code vielleicht eine Hilfe zur künftigen Fehlervermeidung!
zitter_ned_aso schrieb:> gibt es so etwas wie eine Vorschrift oder eine Regel für bestimmte> Rückgabewerte von Funktionen bei einer erfolgreichen / fehlerhaften> Ausführung?
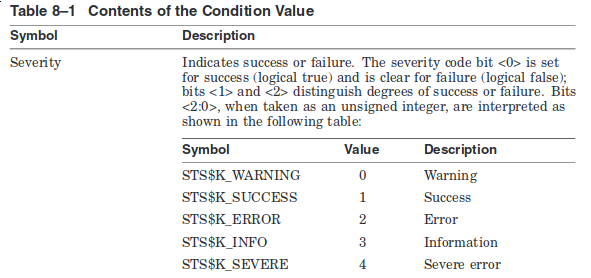
So um 1975 herum hat Digital Equipment festgelegt, wie Rückgabewerte
auszusehen haben (für VMS). Weil früher alles viel besser war, ist die
Vorschrift ein wenig umfangreicher geworden, 6 Seiten im Handbuch¹ (bzw.
35, wenn man Exceptions dazu zählt). Die Vorschrift gilt heute noch und
wurde von Microsoft für NT leicht modifiziert übernommen:
Theor schrieb:> Ein Hinweis noch. Es gibt tatsächlich Systeme, die das etwas anders> machen und auch Erfolge differenzieren (können): Etwa> https://en.wikipedia.org/wiki/HRESULT
1)
https://support.hpe.com/hpesc/public/docDisplay?docId=emr_na-c04621389
Eine Vorschrift oder gar Standard gibt es meines Wissens nicht. Das
kommt immer darauf an, wie eine API/Library das per Konvention umsetzt.
Da C keine Ausnahmen oder ähnliches kennt, behilft man sich oft mit
Rückgabecodes. Bei Vulkan z.B. ist es VkResult (eine simple Enumeration)
oder bei Microsofts COM das HRESULT (ein strukturierter 32-bit
Ganzzahl-Fehlercode). Das Prinzip ist i.d.R. immer das gleiche: Ein Wert
von 0 zeigt den Erfolg an, jeder andere Wert einen Fehler, den man
entweder als positiven oder negativen Integerwert ablesen kann. Einige
alte Windows APIs geben auch "bool" (hier ein 32-bit Integer) zurück,
tritt dort ein Fehler auf kann man dann mit GetLastError() den damit
verbundenen Fehlercode für den aktuellen Thread abrufen. Warum "0" als
Erfolgsmeldung? Weil es die Bedingung einfacher macht. Man muss so nur
auf "0" prüfen, ob etwas schief gelaufen ist, völlig egal was der Fehler
war.
Da so eine Funktion nicht direkt einen Wert zurückgeben kann, werden
diese meist als letzter Paramter mit einem Pointer-to-Pointer übergeben.
Die klassischen Unix System-APIs verwenden folgende Konvention:
0: Erfolgreich
-1: Fehler
Für Calls die einen Wert zurückgeben:
>= 0: Gültiger Wert
-1: Fehler
Der eigentliche Fehlercode steht in errno.
In seltenen Fällen, wenn auch negative Werte gültige Rückgabewerte sind,
zählt nur errno. Dabei muss der Programmierer errno vor dem
Funktionsaufruf selber zurück setzen:
1
errno=0;
2
result=systemcall();
3
if(errno){
4
perror(NULL);
5
exit(EXIT_FAILURE);
6
}
Die klassischen Unix Library-APIs halten sich meist an eine ähnliche
Konvention:
-1 oder NULL-Pointer: Fehler
>=0 oder !NULL: Erfolgreich
Da mittlerweile eine ganze Reihe von Bastlern an den Linux-Libraries
tätig waren löst sich diese Konvention langsam auf.
> So um 1975 herum hat Digital Equipment festgelegt ...
Very interesting, but 45 years ago...
> zitter_ned_aso (Gast)
wollte aber wohl eher wissen, wie sie/er da selbst
erfolgsversprechend rangeht.
Da ist weniger ein 35-seitiges Pamphlet für Juristen gefragt,
sondern eher eine grundsätzlich einleuchtende Vorgehensweise.
Sinnfällige (!) Regeln sind erfahrungsgemäß für logisch denkende
IT-ler und Techniker leichter einzuhalten, als sich das logik-
ferne Fakultäten vorstellen können.