Moin,
Ich hab' ein paar gemessenen Temperaturen eines konstant beheizten Oinks
ueber ein paar Zeiten:
z.B. sowas:
0 : 23
2 : 28
4 30
7 34
10 37
15 40
20 44
30 48
45 53
50 54
60 55
75 57
90 58
105 58
Hat jemand grad zufaellig einen wenigzeiler fuer GNU Octave parat, wie
ich aus diesen Daten mir die Groessen A und Z rausapproximieren kann,
wenn ich glaub', dass das Oink ein PT1 Verhalten hat - also sowas von
dem Kaliber:
Temp(zeit)=Temp(0)+A*(1-exp(-zeit/Z)
Gruss
WK
Mach doch den quadratischen Fehler und variiere A und Z zufällig und nimm den Treffer mit dem kleinsten Fehler. Ansonsten kannst Du es auch mit Gradientenabstieg versuchen
Mit Octave kann ich nicht dienen, aber hier eine Loesung mit maxima.
1 | load(lsquares); |
2 | |
3 | M : matrix( [0,23],[2,28],[4,30],[7,34],[10,37],[15,40],[20,44],[30,48],[45,53],[60,55],[75,57],[90,58],[105,58] ); |
4 | |
5 | lsquares_estimates( M, [x,y], y = B + A * (1-exp(-x/Z)), [B,A,Z]); |
ergibt: [[B = 24.50205474148759, A = 33.71562608547086, Z = 23.47286576998589]]
Natuerlich mit Startwert temp(0)=23: lsquares_estimates( M, [x,y], y = 23 + A * (1-exp(-x/Z)), [A,Z]); ergibt: [[A = 34.73653966932802, Z = 21.17559226183299]]
Moin, Josef schrieb: > [[A = 34.73653966932802, Z = 21.17559226183299]] Ha, sogar schon vorgekaut, danke! Gruss Wolfram
Bei Octave laeuft das wohl unter lsqcurvefit. Ein Beispiel mit einer Exponentialfunktion ist in der Doku von Octave.
Da brauchts' keine schwere Artillerie wie von Josef gezeigt, das kann
man on the fly mit jedem Mikrocontroller und linearer Algebra
erschlagen.
>>>>>Temp(zeit)=Temp(0)+A*(1-exp(-zeit/Z)
A krieg ich raus 34.59 und Z 23.76.
math rulez!
Cheers
Detlef
clear
w=[ 0 23 2 28 4 30 7 34 10 37 15 40 20 44 30 48 .....
45 53 50 54 60 55 75 57 90 58 105 58 ];
t=w(1:2:end);
temp=w(2:2:end);
plot(t,temp,'r.-')
endwert=58.5;
y=(endwert-23)-(temp-23);
y=y(:);
x=t(:);
x=x(1:end);
y=y(1:end);
n=length(y);
M=[x(:) ones(n,1)];
coff=inv(M'*M)*M'*log(y);
a=coff(2);
b=coff(1);
plot(x,log(y),x,M*coff);
xr=x;
yr=exp(a)*exp(b.*xr);
yr=23-(yr-(58.1-23));
semilogy(x,y,'b.-',xr,yr,'r.-')
plot(t,temp,xr,yr)
return
Angehängte Dateien:
-

ErrorSurface_L0.jpg
27 KB -

ErrorContour_L4.jpg
33 KB
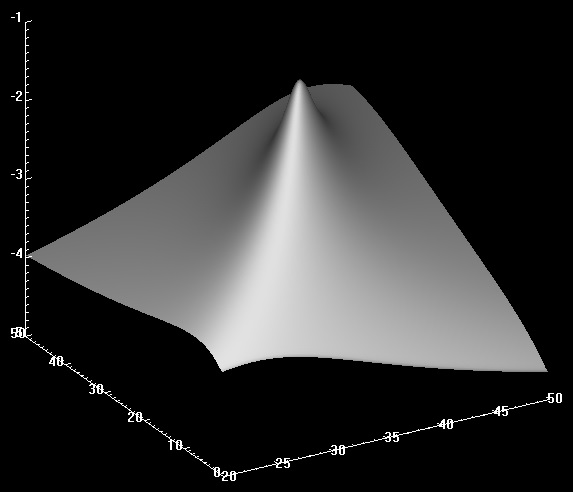
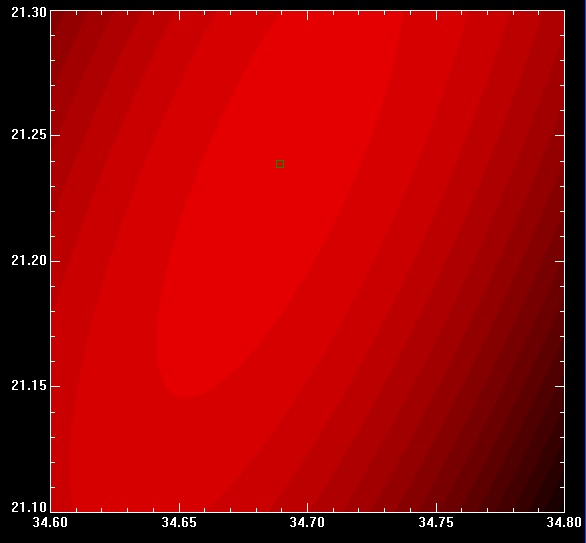
Detlef _. schrieb: > Da brauchts' keine schwere Artillerie wie von Josef gezeigt, das kann > man on the fly mit jedem Mikrocontroller und linearer Algebra > erschlagen. > >>>>>>Temp(zeit)=Temp(0)+A*(1-exp(-zeit/Z) > > A krieg ich raus 34.59 und Z 23.76. Nein, um Gottes Willen! Das Problem ist (leider, wie so oft) nicht linear, d.h. nicht linear in den zu optimierenden Parametern A und Z. Wenn's z.B. um die Form A*exp(-z+Z) gehen würde, dann könnte es einfach auf eine lineare Form reduziert werden (und z.B. per PseudoInverse invert(M^T*M)*M^T das Optimum bestimmen). Man hätte aber immer noch grössere numerische Probleme. Vlt. eine kleine Analogie: du willst ein Integral per Aussummieren grob berechnen, änderst dann aber die Skala von x nach exp(x). Dadurch ändern sich ja die "Boxen" unter der Kurve, und zwar in X-Richtung. Die Summe entspricht damit überhaupt nicht mehr dem Integral. Beim obigen Problem ist es genauso. Durch deine "Linearisierung" änderst du die Topologie im L2 extrem stark. Sie ist nicht mehr isotrop und nicht mehr ortsunabhängig. Ich habe mal ein einfaches Programm geschrieben, dass A und Z variiert und je Paarung den Fehler ausrechnet. Die Bilder im Anhang zeigen dann die Fehler, zur besseren Visualisierung habe ich den Logarithmus des Fehlers geplottet. Bild 1 zeigt den groben Überblick, Bild2 einen feineren Ausschnitt als Kontourplot. Das so bestimmte Optimum ist A=34.68 und Z=21.236, deckt sich also mit der Lösung aus Octave. Man könnte per Verfeinerung das Optimum noch besser eingrenzen, aber in Anbetracht der schlechten Eingangsbedingung (Addition mit Temp(0) !!, ich würd's umformulieren) spielt das kaum eine Rolle.
Angehängte Dateien:
-

exp.png
30 KB
>>>>>
Nein, um Gottes Willen! Das Problem ist (leider, wie so oft)
nicht linear, d.h. nicht linear in den zu optimierenden
Parametern A und Z.
<<<<<<<<
Das ist nicht das Optimum, ist mir bekannt. Seit 200Jahren lösen
Ingenieure das Fitting einer Exponentialfunktion mit der Logarithmierung
und damit Reduktion auf ein lineares Problem.
Aktuell machen das auch die Seuchenforscher genauso, die logarithmieren
und legen ne Gerade in die Fallzahlen.
Das hat noch nie nicht funktioniert.
Ein linearer Fit geht auf einem uC, eine nichtlineare Optimierung nicht.
Im Übrigen ist meine Optimierung, obwohl linear, bisschen besser als
Deine. Das dürfte eigentlich nicht sein.
math rulez
Cheers
Detlef
clear
w=[ 0 23 2 28 4 30 7 34 10 37 15 40 20 44 30 48 .....
45 53 50 54 60 55 75 57 90 58 105 58 ];
t=w(1:2:end);
temp=w(2:2:end);
plot(t,temp,'r.-')
endwert=58.5;
y=(endwert-23)-(temp-23);
y=y(:);
x=t(:);
x=x(1:end);
y=y(1:end);
n=length(y);
M=[x(:) ones(n,1)];
coff=inv(M'*M)*M'*log(y);
a=coff(2);
b=coff(1);
plot(x,log(y),x,M*coff);
xr=x;
yr=exp(a)*exp(b.*xr);
yr=23-(yr-(58.1-23));
semilogy(x,y,'b.-',xr,yr,'r.-')
zr=23+34.68*(1-exp(-x/21.236))
plot(t,temp,'b.-',xr,yr,'r.-',xr,zr,'k.-')
grid
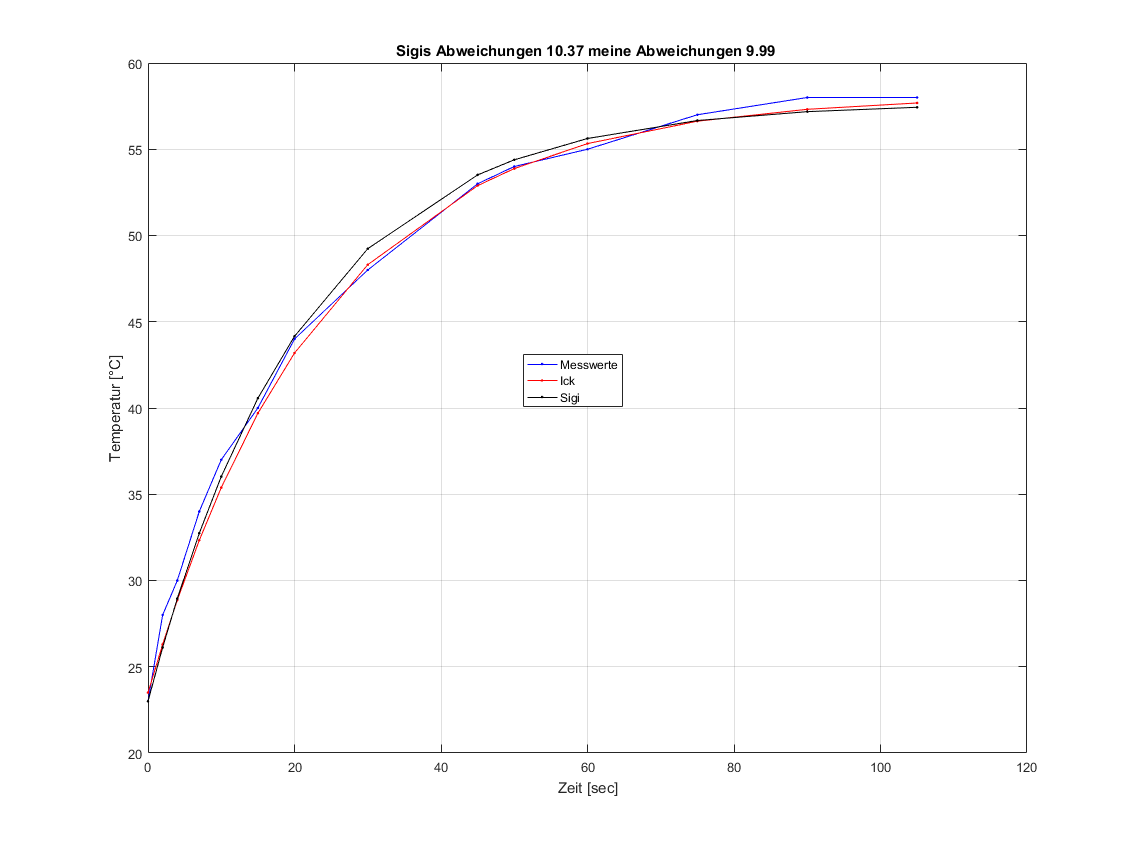
title(sprintf('Sigis Abweichungen %.2f meine Abweichungen %.2f ',....
sum(abs(temp-zr.')),sum(abs(temp-yr.'))))
xlabel('Zeit [sec]')
ylabel('Temperatur [°C]')
legend('Messwerte', 'Ick','Sigi')
return
Zu meinem "Optimum" muss natürlich auch gesagt werden, dass es kein Optimum im math. Sinne ist. Ich suche ja nur das Optimum in einem 2D-Array mit endlicher Auflösung. Zu deiner Lösung: ich habe mir einen Maier gesucht, bis ich auf deine 9.9 statt 14.78 als Fehlerwert kam. Für meine Berechnungen hatte ich nur die TO-Formel von ganz Oben verwendet, du verwendest dagegen yr=exp(a)*exp(b.*xr); yr=23-(yr-(58.1-23)); Ausserdem nimmst du als Formel für den Fehler die L1-Norm, das verändert alles (ich habe nach L2 optimiert). Wenn ich mein Array-Ansatz (was ja mit Mathe nichts zu tun hat, ist nur eine Holzhammermethode) gegen unterschiedliche Normen anwende (L1, L2 und L-Unendlich), dann komme ich auf folgende Tabelle mit Fehlerwerten: ------------------------------------------------------- TO-Formel: z = temp[0] + A*(1-exp(-x/Z)) ------------------------------------------------------- User: L1 L2 Linf ------------------------------------------------------- IKE : 14.782785 22.886193 2.2075594 IKE2: 9.9540454 11.449178 1.6975611 ------------------------------------------------------- L1 : 9.6679087 12.787407 2.0401627 L2 : 10.379489 10.966322 1.8822150 Linf: 11.959534 13.987099 1.6848860 ------------------------------------------------------- IKE: dein Optimum mit TO-Formel IKE2: dein Optimum mit deiner Formel I1: mein Optimum bzgl. L1-Norm I2: mein Optimum bzgl. L1-Norm Iinf: mein Optimum bzgl. L-Unendlich-Norm Bei meinen 3 Optima sieht man dann sehr schön, das je nach Norm auch ein "gutes" Optimum gefunden wird, dessen Fehler auch besser ist als die anderen. Das dein Fehler bei L1 trotzdem noch besser ist als meiner liegt an deiner Formel, die von der TO-Formel abweicht. Prüf mal bitte dein Optimum-Paar a,z mit der TO-Formel, dann müsstest du wie ich auf 14.78 kommen.
Detlef _. schrieb: > Ein linearer Fit geht auf einem uC, eine nichtlineare Optimierung nicht. Mit meiner Array-Methode wäre ein uC schnell überfordert, ich würde aber obiges Optimum z.B. per Gradientenmethode bestimmen. Und das geht, je nach Formulierung, sogar schneller als über den linearen Ansatz.
Hi Sigi, ja, alles mit der heissen Nadel gestrickt bei mir, das war ein hack. Zwei Sachen möchte ich sagen: Erstens: Exponentialfkt. mit Logarithmierung und Fit mit Pseudoinversen funktioniert immer, auf dem kleinsten uC. Zweitens: Iterationen nach Qualitätskriterien ( Gradientenverfahren, Echocanceller, Channel Equalizer) zicken immer, dauert 8 Wochen bis der Sch läuft. Been there, done that. War so, ist so und wird solange bleiben, bis die Mathematiker mal bessere nichtlineare Optimierungsverfahren basteln. Kann dauern ;)). math rulez, anyhow. Cheers Detlef
Angehängte Dateien:
-

PT1_Gradient_L2.png
5,1 KB -

PT1_EXP_Error.png
3,6 KB
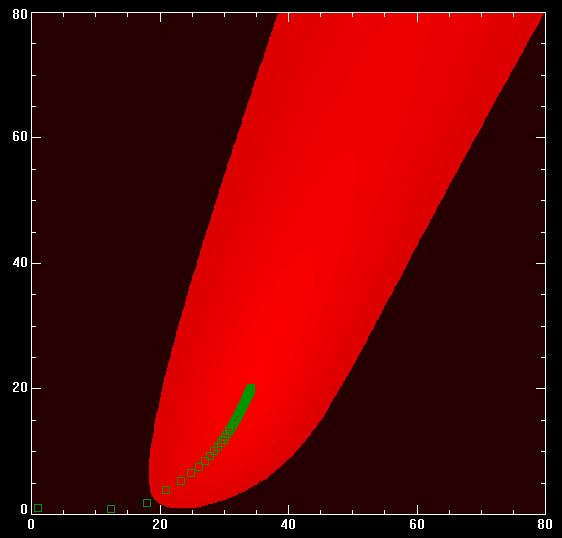
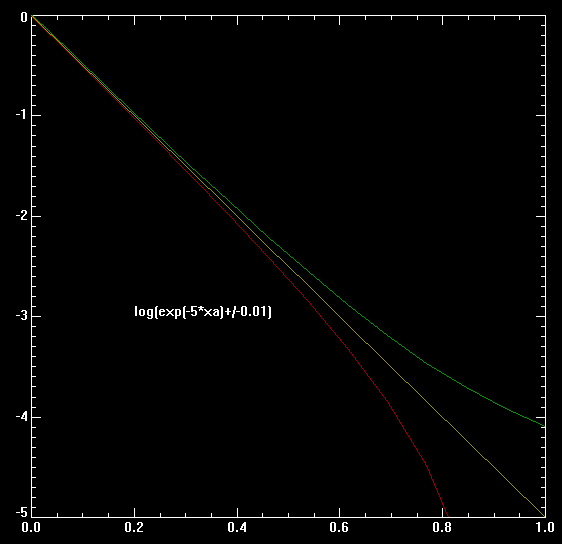
Detlef _. schrieb: > Zweitens: Iterationen nach Qualitätskriterien ( Gradientenverfahren, > Echocanceller, Channel Equalizer) zicken immer, dauert 8 Wochen bis der > Sch läuft. Was'n Blödsinn: Erstens, ich habe gerade 2 Verfahren implementiert. Beides PlainVanilla Gradientenabstieg, einmal nach L2 und einmal nach L_unendlich. Das Runterschreiben hat jeweils 10-20 Minute gedauert, dazu nochmal je 10-20 Minuten Testen. Zweitens, schau dir die Zielfunktion an (T0-A*(1-...)), die ist visuell extremst gutmütig. Ich habe nur die Ableitungen ausgerechnet, von den aktuellen Vektor (a,z) abgezogen und die Trajektorie beobachtet. Wie erwartet (war mir 99.9% sicher), kein gezicke, schnelle Konvergenz (in Bezug auf Rechenzeit als auch auf Anzahl Iterationsschritte). Ob das auf einem uC läuft oder nicht ist total schnuppe, war auch nicht gefordert, Ziel ist nur das Optimum. Du kannst jetzt auch noch ergänzende Verfahren wie adjungierte Gradienten oder 2teOrdungsverfahren (konvergiert noch schneller als das Adjungierte), und du kannst dich dabei im ggs zu den Ingenieursbasteleien darauf verlassen, dass sie auch von Profinumerikern verifiziert, publiziert, ebenfalls von Profis anerkannt und weltweit millionenfach getestet wurden, auch wieder von Profis. Detlef _. schrieb: > Erstens: Exponentialfkt. mit Logarithmierung und Fit mit Pseudoinversen > funktioniert immer, auf dem kleinsten uC. Du wirst zwar noch immer glauben, ich sei nicht dazu in der Lage, das ebenfalls so zu machen (in der Medizin etc. kann man so für eine schnelle Visualisierung vorgehen, für numerisch anspruchsvolle Geschichten aber nicht zu gebrauchen). Ich habe mal im Anhang eine Graphik hochgeladen, die deutlichst zeigt, warum. Zu sehen ist eine EXP-Kurve mit zwei Fehlerkurven (je +0.01 bzw -0.01 hinzuaddiert) und davon dann den Logarithmus geplottet. Du siehst ja hoffentlich ganz schön, dass der Fehler nach Hinten raus mit O(exp(x)) bzw. O(-exp(x)) wächst. In z.B. der Medizin kann das ja toleriert werden, sei's zur Visualisierung oder nur zur groben Abschäzungen für was weiss ich. Und damit nun zur schlechten Konditionierung des Problems, speziell bezogen auf die Addition mit Temp(0): Hier wackelt nicht der Schwanz mit dem Hund, sondern die Schwanzspitze. Der Fehler in Temp(0) überträgt sich auch das ganze Intervall. Und mit den Fehlern +/-O(exp(x)) bei deinem Verfahren hast du dir einen zweiten Schwanz an den Hund gebastelt, der auch noch stark am Wackeln ist. Schon das erste Problem würde mich sofort veranlassen, die Approximationsfunktion geeigneter zu wählen, aber ist ja nur meine bescheidene Meinung. Deine Implementierung hat noch weitere Probleme bzw. Fehler, die suchst du nun aber bitte selbst. Detlef _. schrieb: > Been there, done that. War so, ist so und wird solange bleiben, bis die > Mathematiker mal bessere nichtlineare Optimierungsverfahren basteln. > Kann dauern ;)). Also du optimierst (mit allen bereits diskutierten und wirklich leicht nachzuvollziehenden Fehlern) im L2, bemasst dein Ergebnis dann im L1 (weiss du überhaupt, was hier L1 macht, und wenn schon anderes Mass, dann BITTE L_unendlich, macht im ggS zu L1 wenigstens Sinn, bei all der Sinnlosigkeit in L(k1) zu optimieren und in L(k2) zu testen, k1!=k2) und sprichst dann bei Mathematikern von basteln. Ich bin selbst kein Mathematiker, habe mich nur in verschiedenen Bereichen vertieft, uA auch in Numerik (I+II+nur0.25*III wegen uniteresanter Spezalisierung), da wird nichts gebastelt, also spar dir dein Fachbashing. Wenn du ein besseres Verfahren haben willst: 1. statt invert(M^T*M)*M^T verwende doch mal invert(M^T*V*M)*M^T*W mit W*W=W^T*W=V und V als Diagonalmatrix. Diese einfache Form ergibt sich, wenn in L2 nicht das cannonische Innenprodukt, sondern das gewichtete Innenprodukt verwendet wird. Die Diagonalelemente von V sind dann die Gewichte, die Diagonalelemente von W sind gleich den Wurzeln der Diagonalelemente von V. Diese Gewichte kannst du dann so wählen, dass sie den zweiten von mir beschriebenen Fehler ausgleichen. Leite das doch einfach mal aus der Optimierungsformel per Ableitung nach dem Lösungsvektor ab, dann kriegst du auch ein bischen Übung, kann nie schaden, braucht man immer. 2. Rechne damit dann eine Lösung aus, berechne die Differenz zum Ziel und Approximiere dann mit der selben Formel die Differenz. Das Ergebnis wird dann zum ersten Ergebnis hinzuaddiert und liefert dann wegen der Additivität ein wesentlich besseres Ergebnis. Diesen Schritt kannst du auch noch ein bis zweimal wiederholen, womit du dein ein sauschnelles und hochgenaues Iterationsverfahren hast (dazu gibt's viele Paper). Kann dauern: Du kennst Bücher wie z.B. Numerical Recipies? Oder überhaupt ein Buch über Numerik (habe hier den Hammerlin, für praktische Sachen besser als der Schwarz), dazu am Besten noch ein Funktionalanalysisbuch (habe hier die Einführungsbibel von Heuser, damit sind dann alle Fragen zu L(k) und allen damit verbundenen Ungleichungen erschlagen, braucht man wirklich immer)). Wenn du damit nicht fündig wirst.. Und da Mathematik auch immer mit Geschichte passenderweise zusammengelehrt wird: Detlef _. schrieb: > Seit 200Jahren lösen > Ingenieure das Fitting einer Exponentialfunktion mit der Logarithmierung > und damit Reduktion auf ein lineares Problem. So aus dem Kopf, Gauss hatte vor ca 200 seine Methode der kleinsten Quadrate entwickelt. Im ggs zu Cauchy war aber Gauss bzgl. Publizieren bekanntich eine faule Socke. Es hätte also so schon lange gedauert, bis die Methode gross Einzug in andere Wissenschafstbereiche gefunden hätte. Dazu kommt, dass diese Methoden erst durch die moderne Numerik grössere Verbreitung fand, und die ist grossteils erst in der zweiten Hälfte des letzten Jahrhunderts entstanden (ich weiss, Numerik gab's auch schon früher).
Und weil ich gerade die Maxima-Seite auf habe: Das Ergebnis meiner Optimierung ist ein wenig (eiglich deutlich) besser als das von Maxima. Das mag eine von wenigen Ausnahmen sein, aber hier sieht man dann doch ein, warum Profitools bzw. Bibliotheken für z.B. Mathematika etc. so gottverdammt teuer sind, eben wegen ihrer Zuverlässigkeit. Einige dieser Tools bzw. Libs kosten schnell 4-5stellig im Jahr an Lizenz. Den Ärger, den man sich damit aber einspart kompensiert das aber total.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.